SparkSession & SparkContext
SparkSession是SparkContext的“进阶版”,是Spark 2.0以后新一代的开发入口。SparkContext通过textFile API把源数据转换为RDD,而SparkSession通过read API把原数据转换为DataFrame
RDD & DataFrame
RDD和DataFrame都是封装分布式数据集,DataFrame也是通过算子来实现不同DataFrame之间的转换,只不过DataFrame采用了一套与RDD算子不同的独立算子集
与RDD不同,DataFrame是一种带Schema的分布式数据集,因此,DataFrame比较像数据库中的二维表
DataFrame背后的计算引擎是Spark SQL,而RDD的计算引擎是Spark Core
DataFrame & DataSet
DataFrame的优化 + 强类型语法(编译时) = DataSet
Spark Core & Spark SQL
Spark Core特指Spark底层执行引擎(Execution Engine),它包括了调度系统,存储系统,内存管理,Shuffle管理等核心功能模块。而Spark SQL则凌驾于Spakr Core之上,是一层独立的优化引擎。
Spark Core负责执行,Spark SQL负责优化,Spark SQL优化后的代码,依然交付Spark Core执行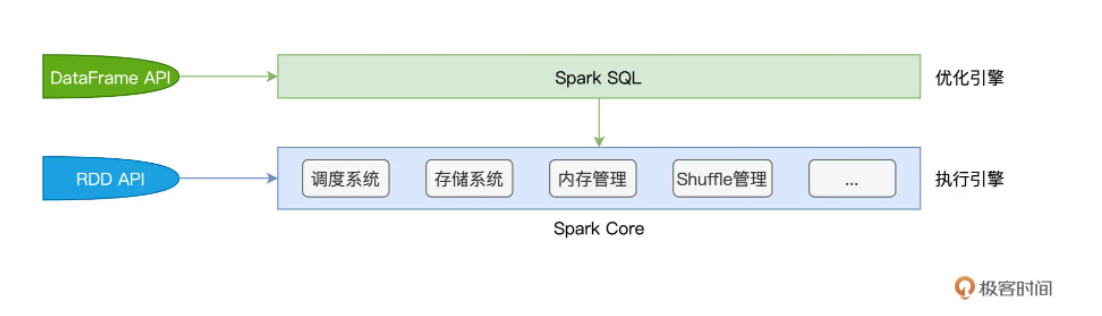
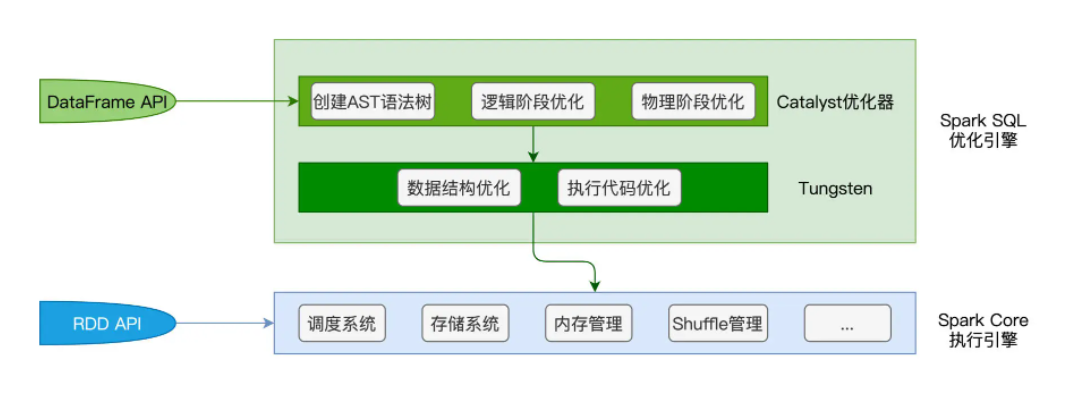
为什么会有DataFrame
RDD算子多采用高阶函数,高阶函数的优势在于表达能力强,它允许开发者灵活地设计并实现业务逻辑。
所谓高阶函数,就是形参为函数的函数,或是返回类型为函数的函数。比如:map, filter,他们都需要一个辅助函数f来作为形参,通过调用map(f), filter(f) 才能完成计算。以map为例,我们需要函数f来明确对哪些字段做映射,以什么规则映射。
但是这样依赖,Spark只知道开发者要做map, filter,并不知道开发者打算怎么做map和filter。
而DataFrame定义了一套DSL(Domain Specific Language),如:select, filter, agg, groupBy,这些算子都是为某一特定任务而设计。尽管DSL语言在表达能力方面更弱,但DataFrame每一个算子的计算逻辑都是确定的,比如select用于提取某些字段。这些计算逻辑对Spark来说,不再透明,因此Spark可以给予启发式的规则或策略,甚至是动态运行时的信息,去优化DataFrame的计算过程

若有收获,就点个赞吧
0 人点赞
