2020
1.9 新特性
Hive
1. 访问Hive元数据
Hive的元数据是通过Hive Metastore来管理的。所以意味着Flink需要打通与Hive Metastore的通信。为了更好的访问Hive元数据,在Flink这边是提出了一套全新设计的Catalog API。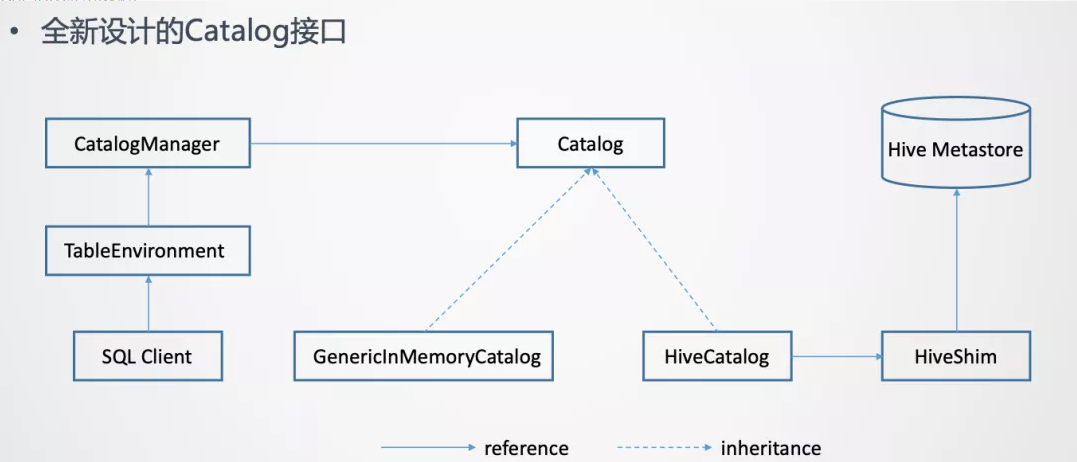
在一个Flink Session当中,是可以创建多个Catalog,每一个Catalog对应于一个外部系统
- 在Flink Table API或者如果使用的是SQL Client
- 可以在Yaml文件里指定定义哪些Catalog
- 然后在SQL Client创建TableEnvironment的时候,就会把这些Catalog加载起来
- TableEnvironment通过CatalogManager来管理这些不同的Catalog的实例
- 这样SQL Client在后续的提交SQL语句的过程中,就可以使用这些Catalog去访问外部系统的元数据了
- 在Flink Table API或者如果使用的是SQL Client
上面这张图里列出了2个Catalog的实现
- GenericlnMemoryCatalog
- 一个是GenericlnMemoryCatalog,把所有的元数据都保存在Flink Client端的内存里。
- 它的行为是类似于Catalog接口出现之前Flink的行为。
- 也就是所有的元数据的生命周期跟SQL Client**的Session周期是一样**的。
- 当Session**结束,在Session里面创建的**元数据也就自动的丢失**了**。
- GenericlnMemoryCatalog
- HiveCatalog
- HiveCatalog**背后对接的是Hive Metastore的实例,要与**Hive Metastore进行通信来做元数据的读写。
- 为了支持多个版本的Hive,不同版本的Hive Metastore的API可能存在不兼容。
- 所以在HiveCatalog和Hive Metastore之间又加了一个HiveShim,通过HiveShim可以支持不同版本的Hive。
2. 读写Hive表数据
- 读数据时实现了HiveTableSource
- 写数据时实现了HiveTableSink
希望尽可能去复用Hive原有的Input/Output Format、SerDe等,来读写Hive的数据。这样做的好处主要是2点,一个是复用可以减少开发的工作量。另一个是复用好处是尽可能与Hive保证写入数据的兼容性。目标是Flink写入的数据,Hive必须可以正常的读取。反之,Hive写入的数据,Flink也可以正常读取。
3. Production Ready

1.11 新特性
Hive
1. 简化的依赖管理
由于Hive的Connector 是需要添加若干个 jar 包的依赖,而使用的 Hive 版本不同,所添加的 jar 包就不同,不同版本的Hive 连接 从jar包的个数/版本/依赖都是不一样的(添加错误依赖会报出各种奇怪,难以理解的错误)
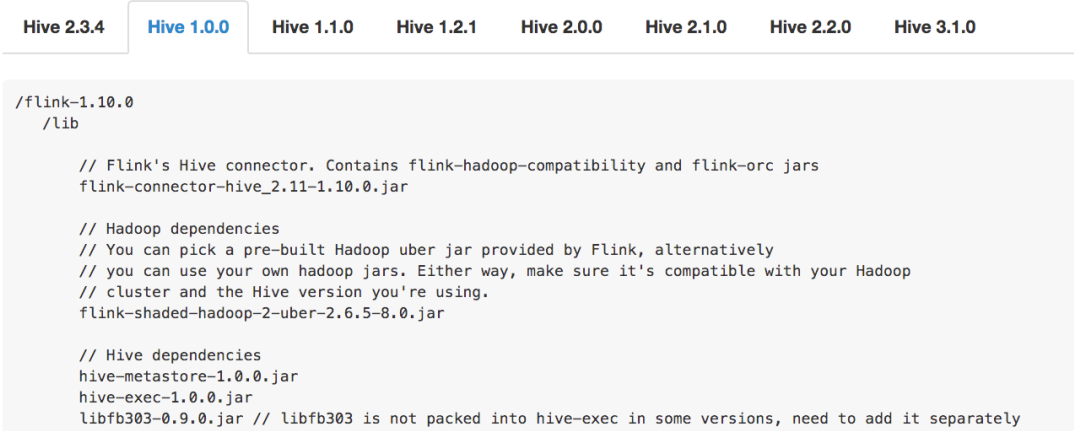
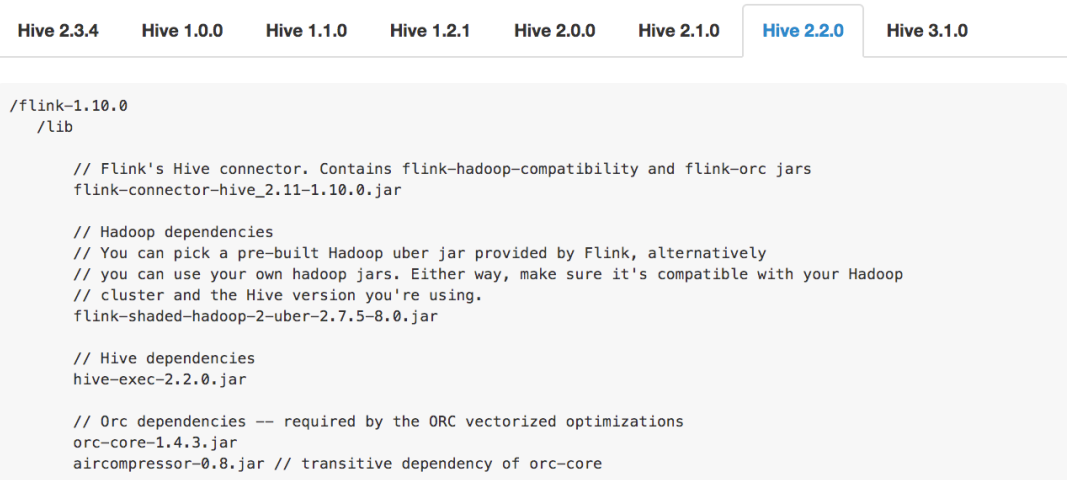
第一张图是使用的 Hive 1.0.0 版本需要添加的 jar 包。第二张图是用 Hive 2.2.0 版本需要添加的 jar 包
- 在1.11版本中 会提供一些预先打好的Hive 依赖包
- 用户可以根据自己的 Hive 版本,选择对应的依赖包就可以了。

2. Hive Dialect 的增强
由于1.10 引入的 Hive Dialect 功能比较弱
- 仅仅只有一个功能: 是否允许创建分区表的开关。就是如果设置了 Hive Dialect,那就可以在 Flink SQL 中创建分区表。如果没设置,则不允许创建。
- 它不提供 Hive 语法的兼容。如果设置了 Hive Dialect 并可以创建分区表,但是创建分区表的 DDL 并不是 Hive 的语法。
在1.11版本中做了如下改进
- 给 Dialect 做了参数化,目前参数支持 default 和 hive 两种值。default 是Flink 自身的 Dialect ,hive 是 Hive 的 Dialect
- SQL Client 和 API 均可以使用
- 可以灵活的做动态切换,切换是语句级别的
- 例如 Session 创建后,第一个语句想用 Flink 的 Dialect 来写,就设置成 default 。在执行了几行语句后,想用 Hive 的 Dialect 来写,就可以设置成 hive 。在切换时,就不需要重启 Session
- 兼容 Hive 常用 DDL 以及基础的 DML
- 提供与 Hive CLI 或 Beeline 近似的使用体验
3. 开启 Hive Dialect (Client/Yaml/Table 获取)
- 开启 Hive Dialect 的方法
- 1. 在 SQL Client 中可以设置初始的 Dialect
- 2. 在 Yaml 文件里设置
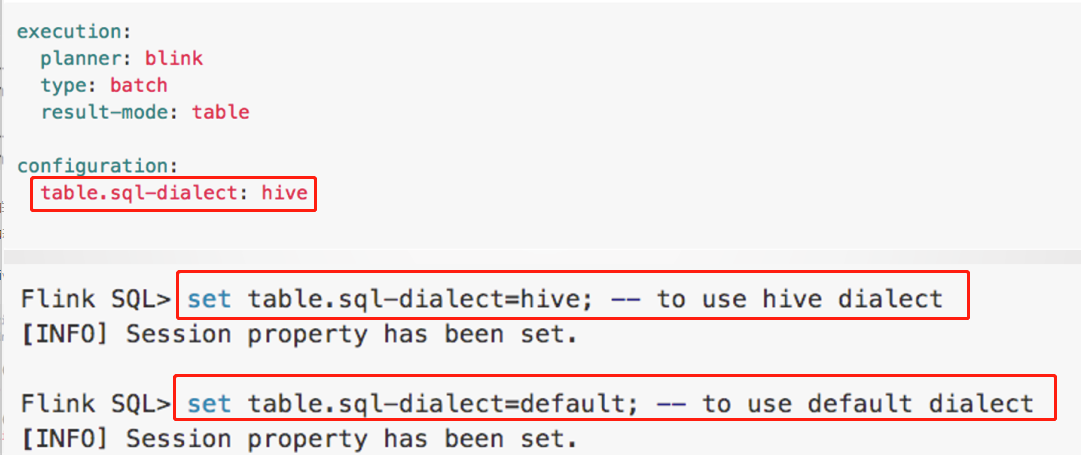
- 3. 以及通过Table API 方式开启
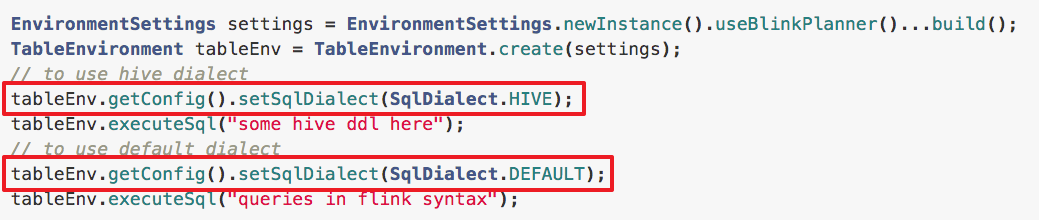
4. Hive Dialect 支持的语法
- DDL 方向进行了增强


5. 流式数据写入Hive

5.1 大体了解
- 流式数据写入 Hive 是借助 Streaming File Sink 实现的,它是完全 SQL 化的,不需要用户进行代码开发。流式数据写入 Hive 也支持分区和非分区表。
- Hive 数仓一般都是离线数据,用户对数据一致性要求比较高,所以支持 Exactly-Once 语义。
- 流式数据写 Hive 大概有 5-10 分钟级别的延迟。如果希望延迟尽可能的低,那么产生的一个结果就是会生成更多的小文件。小文件对 HDFS 来说是不友好的,小文件多了以后,会影响 HDFS 的性能。这种情况下可以做一些小文的合并操作。
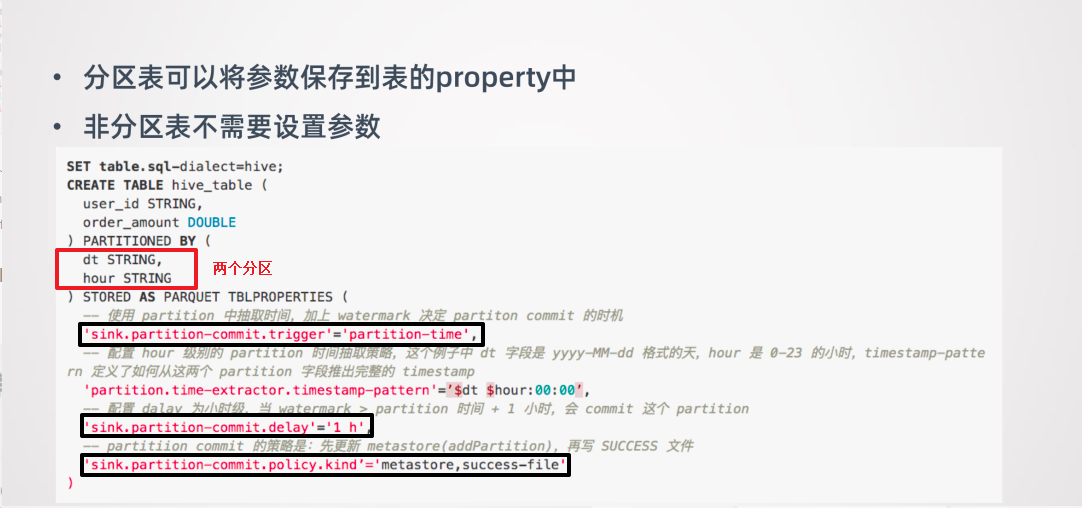
5.2 流式数据写入 Hive 需要有几个配置的地方:
- Partition Commit Delay
- 这个参数的意义就是控制每个分区包含多长时间的数据,例如可设置成天、小时等。
- Partition Commit Trigger (什么时候触发 Commit )
- Process-time
- Partition-time
- Partition Commit Policy (什么方式提交分区)
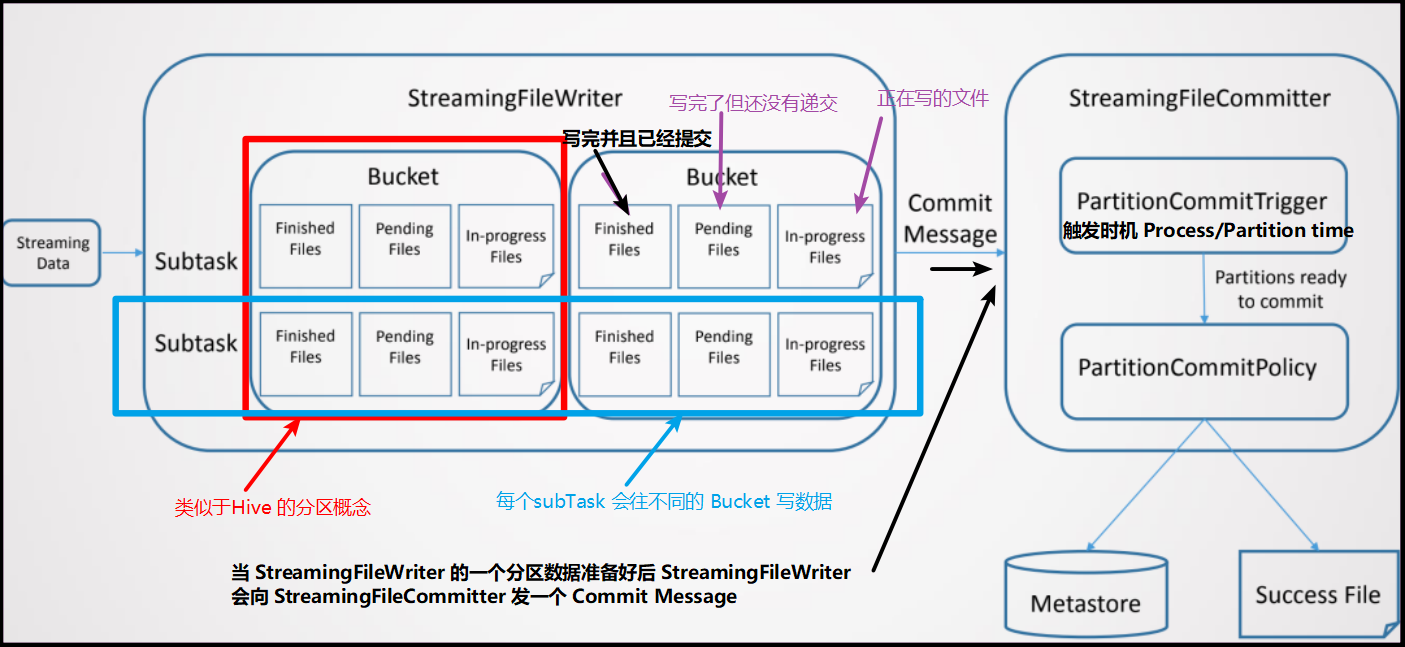
6. 流式消费 Hive

- 流式消费 Hive 支持分区表和非分区表。
- 对于非分区表会监控表目录下新文件添加,并增量读取。
- 对于分区表通过监控分区目录和 Metastore 的方式确认是否有新分区添加,如果有新增分区,就会把新增分区数据读取出来。
- 这里需要注意,读新增分区数据是一次性的。也就是新增加分区后,会把这个分区数据一次性都读出来,在这之后就不再监控这个分区的数据了。所以如果需要用 Flink 流式消费 Hive 的分区表,那应该保证分区在添加的时候它的数据是完整的。

- 流式消费 Hive 数据也需要额外的指定一些参数。
- 首先要指定消费顺序,因为数据是增量读取,所以需要指定要用什么顺序消费数据
- create-time
- partition-time
- 可以指定消费起点
- 类似于消费 kafka 指定 offset 这样的功能,希望从哪个时间点的数据开始消费
- Flink 去消费数据的时候,就会检查并只会读取这个时间点之后的数据
- 指定监控的间隔
- 因为目前监控新数据的添加都是要扫描文件系统的,可能你希望监控的不要太频繁,太频繁会给文件系统造成比较大的压力 所以可以控制一个间隔
非分区表消费的原理: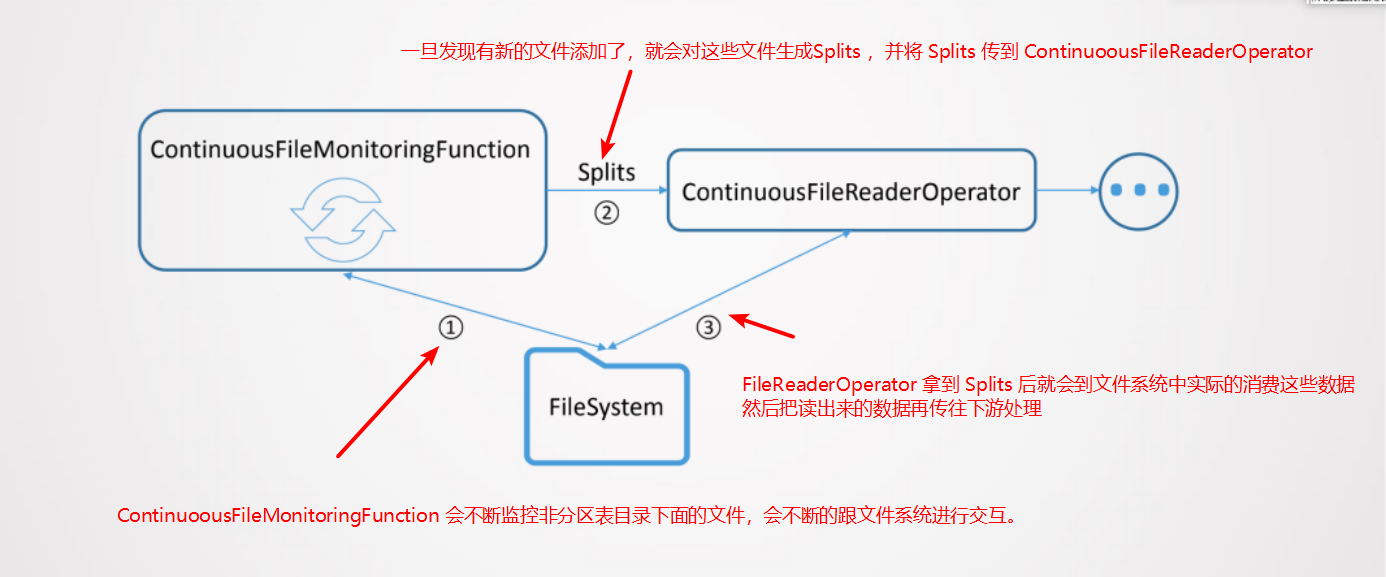
分区表消费的原理: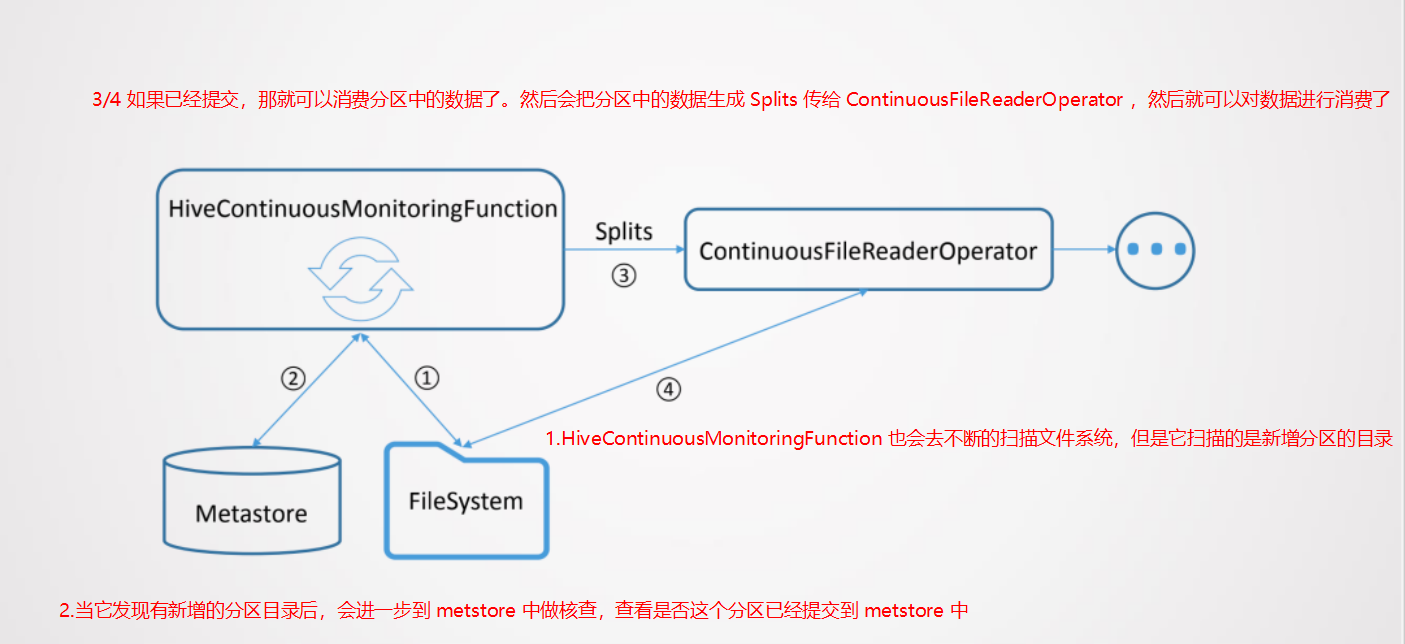
7. 关联 Hive 维表

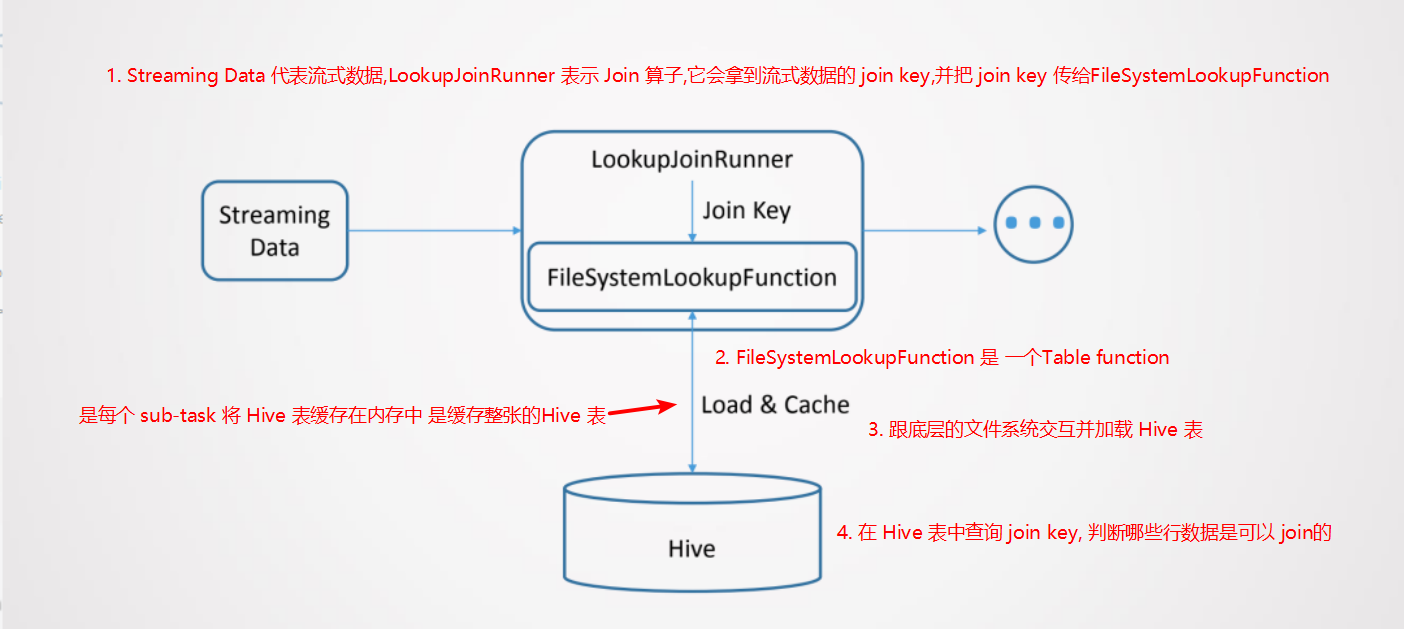
关联Hive维表采用了 Flink 的 Temporal Table 的语法,就是把 Hive 的维表作为Temporal Table,然后与流式的表进行 join
关联 Hive 维表的实现是每个 sub-task 将 Hive 表缓存在内存中,是缓存整张的Hive 表
如果 Hive 维表大小超过 sub-task 的可用内存,那么作业会失败
Hive 维表在关联的时候,Hive 维表可能会发生更新,所以会允许用户设置 hive 表缓存的超时时间
- 超过这个时间后,sub-task 会重新加载 Hive 维表
- 需要注意,这种场景不适用于 Hive 维表频繁更新的情况,这样会对 HDFS 文件系统造成很大的压力。所以适用于 Hive 维表缓慢更新的情况。缓存超时时间一般设置的比较长,一般是小时级别的

若有收获,就点个赞吧
0 人点赞
