TaskManager
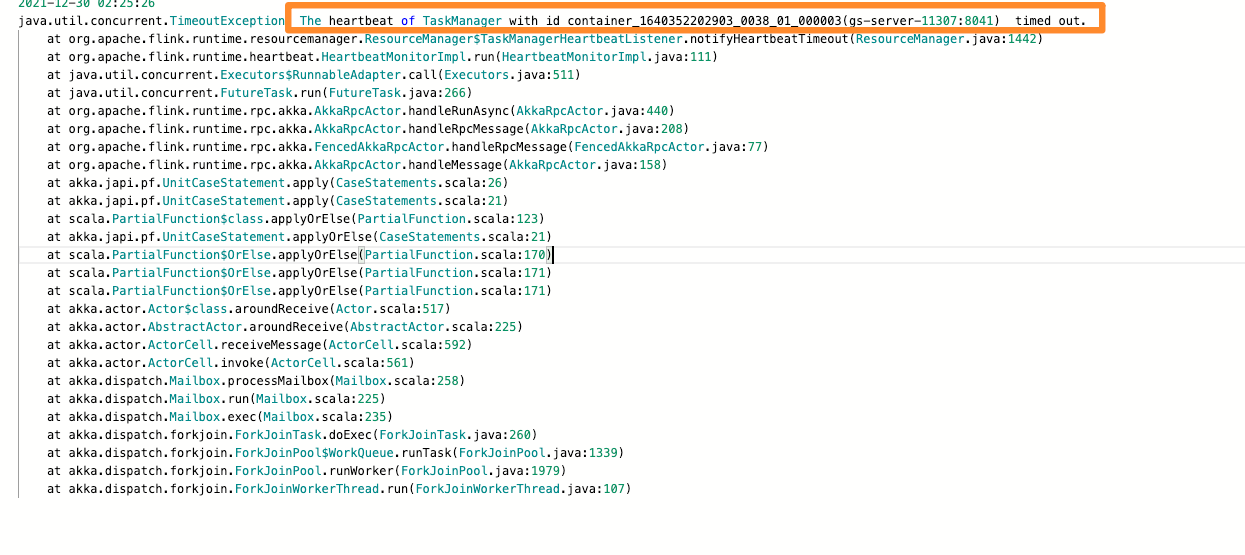
- 服务器的网络波动 不稳定 导致的
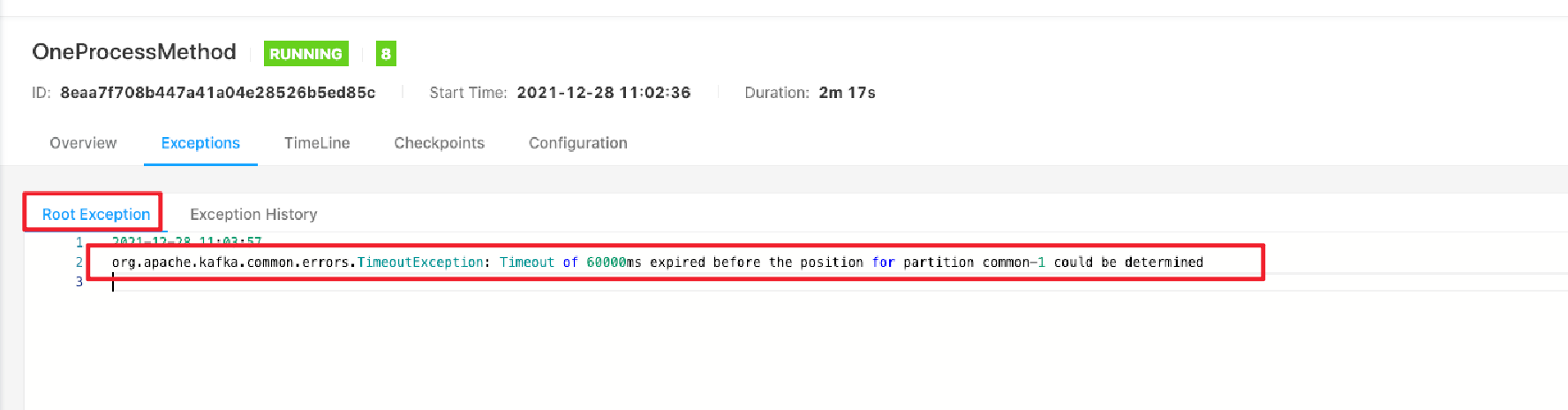
- kafka 集群不稳定 (也有可能是服务所在服务器本身也不稳定)
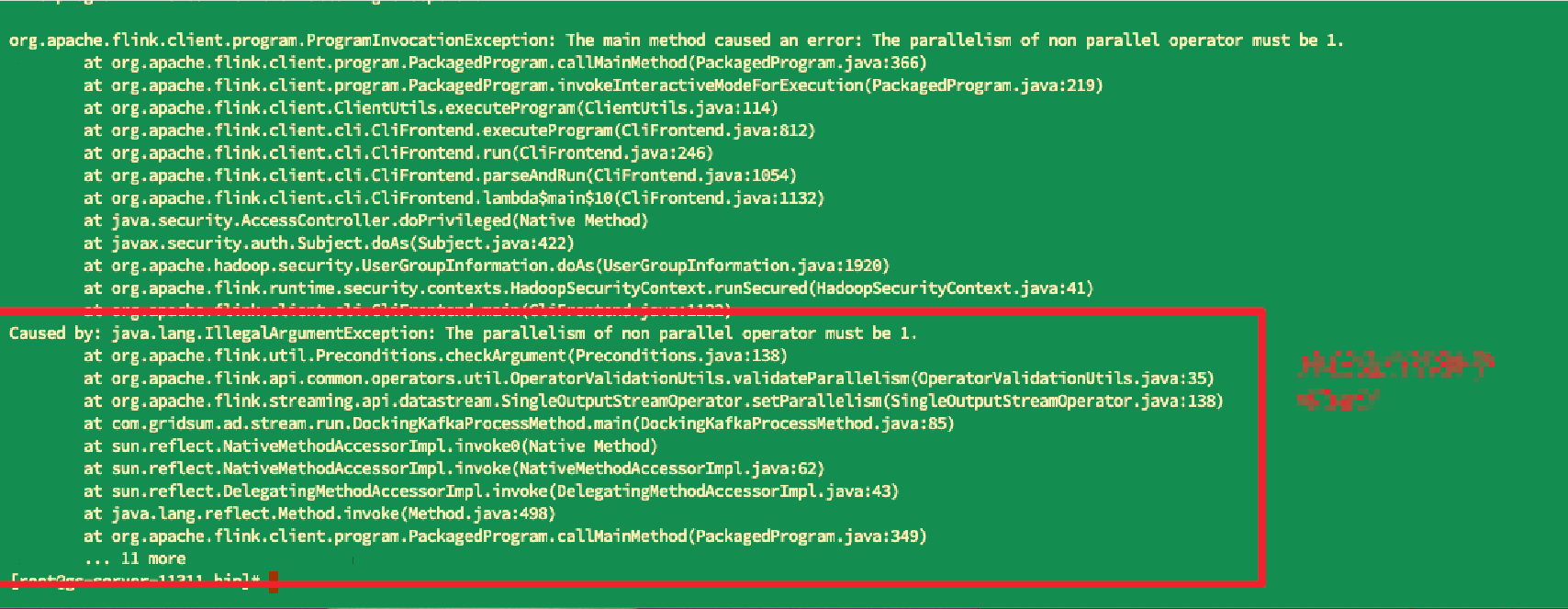
- 检查算子 是否给只有一个并行度的算子设置了多个 并行度 (比如 sink fs、writer kafka)
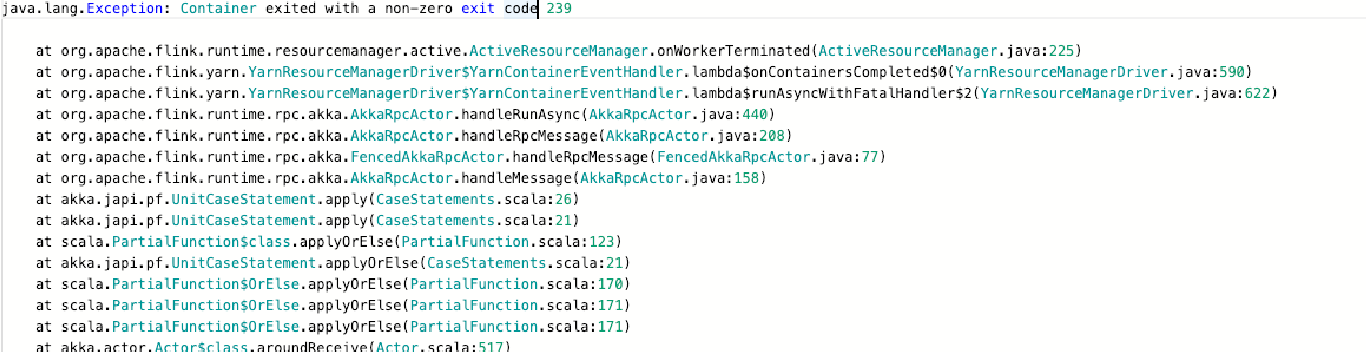
- 超过堆大小 任务被 container kill 掉 (扩大资源,或者减少代码对内存的依赖)
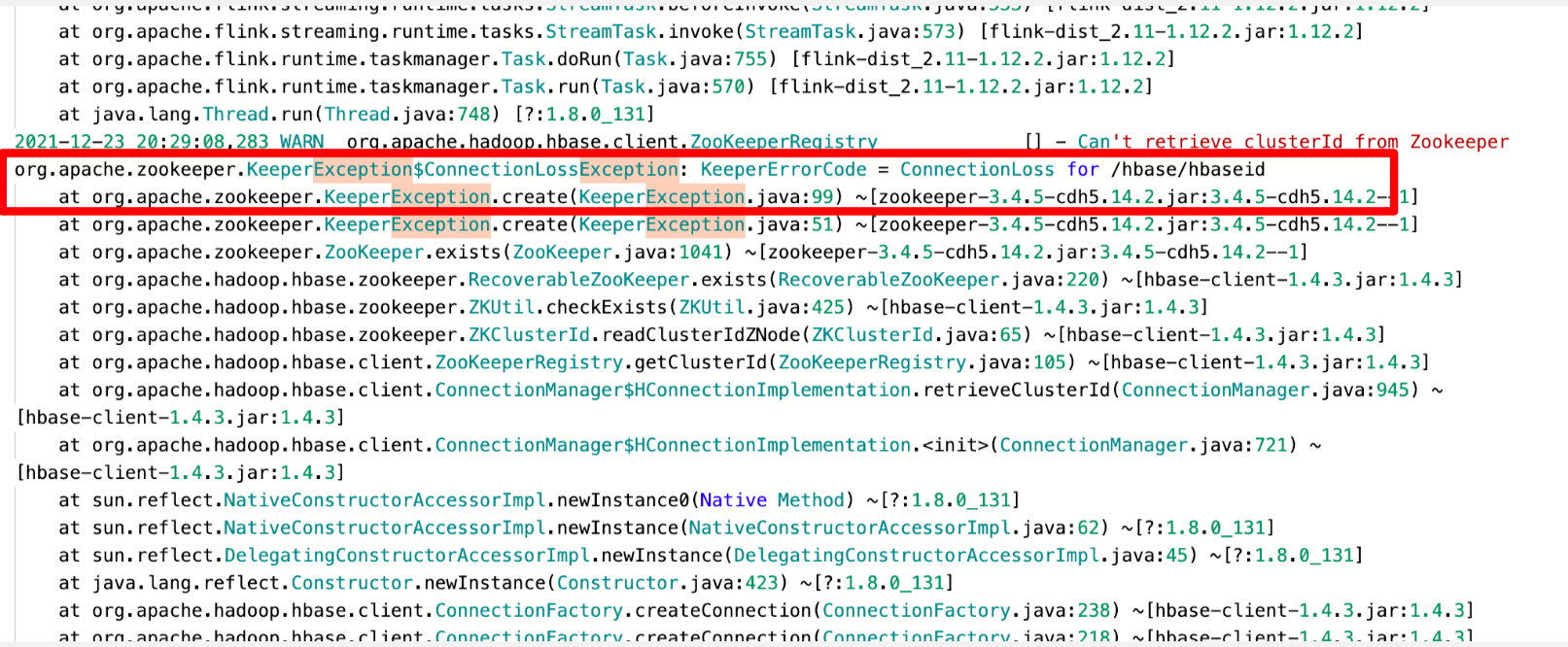
- 连接失败 查看防火墙是否关闭以及 Zookeeper 地址是否填写正确

- 没有设置 kafka 的 group id
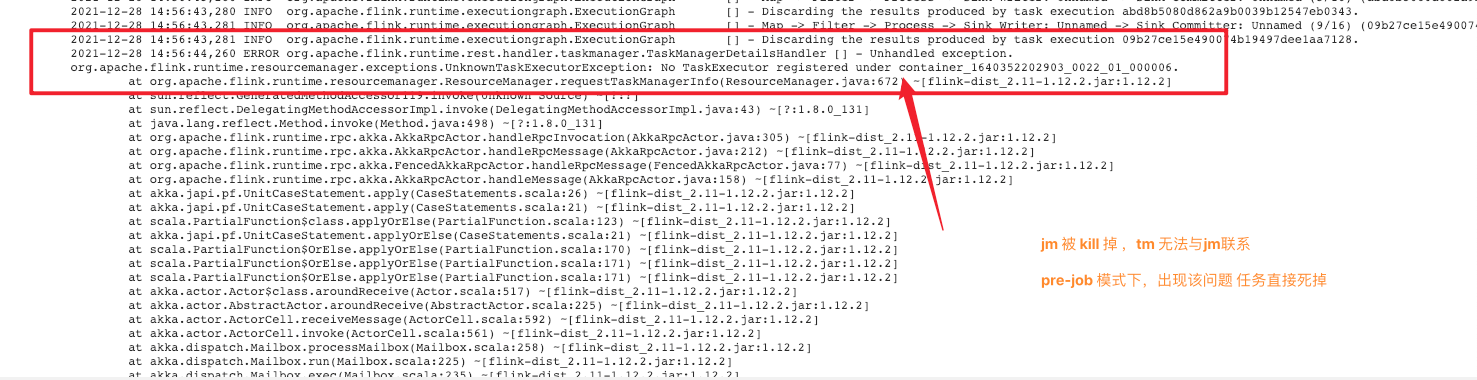
- jm 死掉了 tm 无法注册 jm (可以适当调节
taskmanager.registration.timeout这个可能有点问题)- 直接重新启动 job 、从 chk 点启动
JobMaster

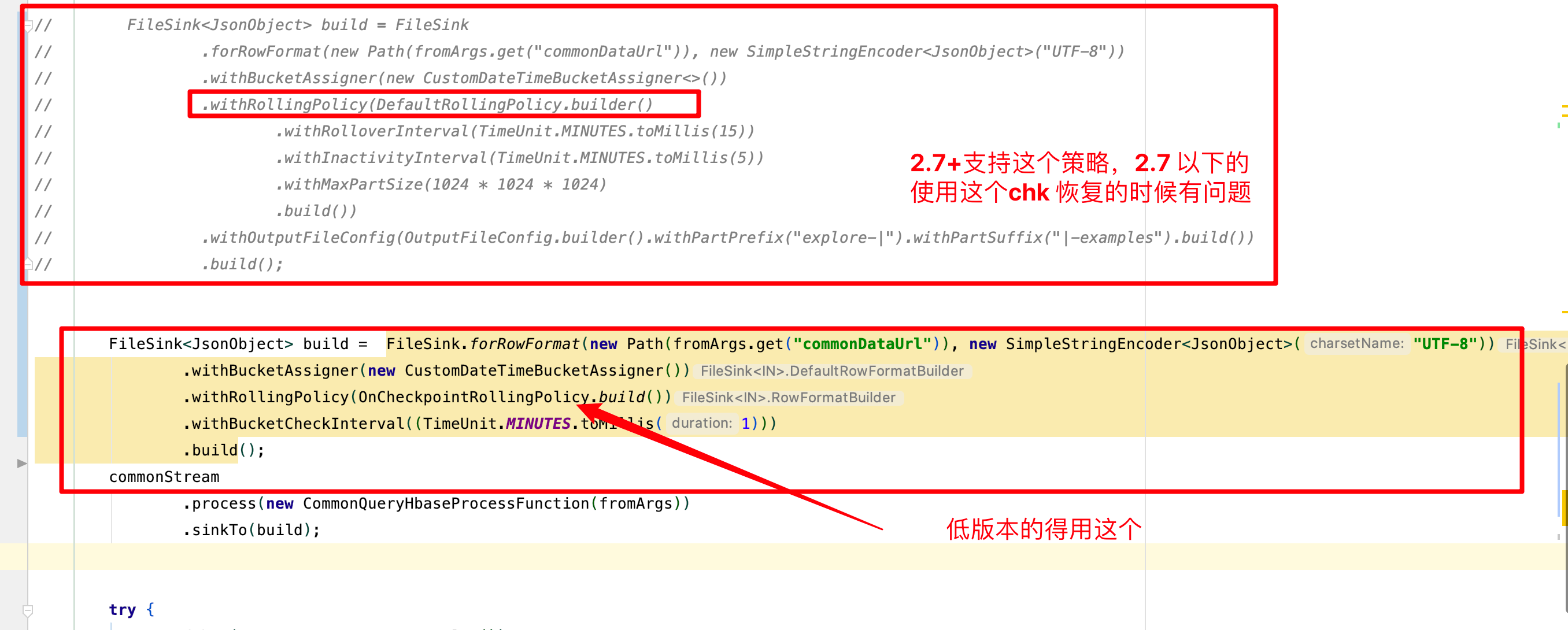
- stream 调用 File sink 算子滚动策略问题 (如图所示)

- uid 、name 重复
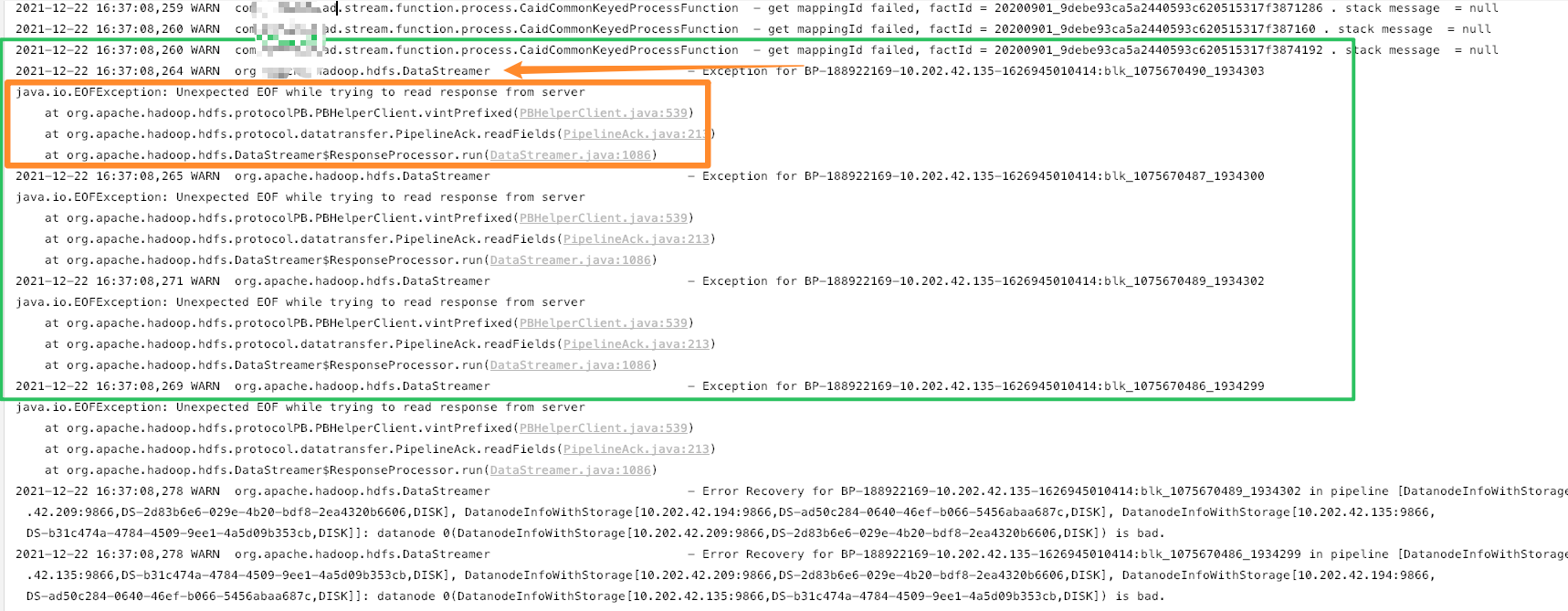
- 响应问题 ? 怀疑是 hadoop 集群不稳定,根据重试策略: 重试后该问题未发现

- 内存不足 (扩大资源,或者减少代码对内存的依赖)
checkpoint
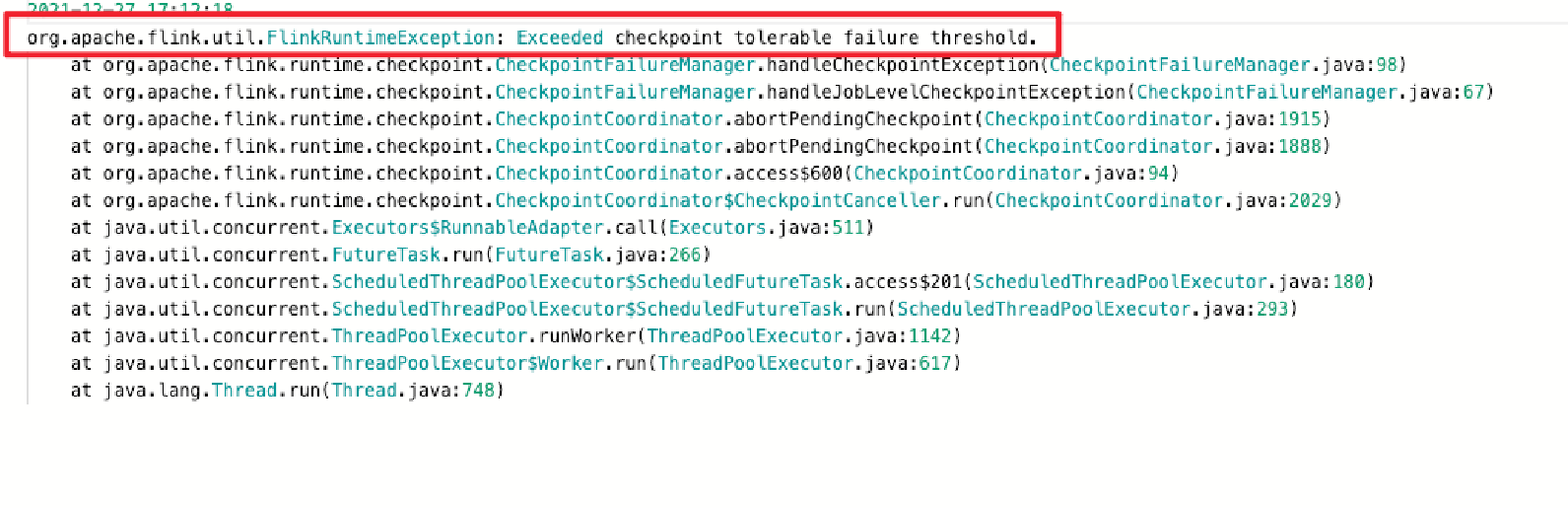
- checkpoint 未在规定时间内完成
- 增加超时时间
- 增加服务器性能
- 调整状态后端与存储资源
- key by 分流 避免某一个 operator 状态过大

若有收获,就点个赞吧
0 人点赞
