- 数据流元素">
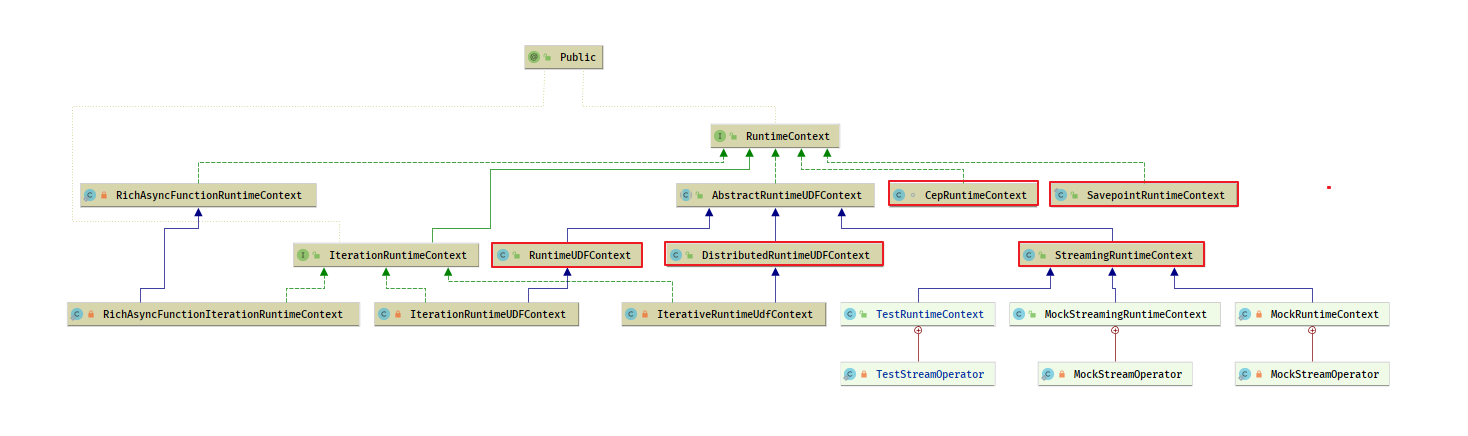 数据流元素
数据流元素 - StreamRecord
- Watermark
- StreamStatus
- Transformation
- 物理 Transformation
- SinkTransformation
- OneInputTransformation
- TwoInputTransformation
- SideOutputTransformation
- SplitTransformation
- SelectTransformation
- PartitionTransformation
- UnionTransformation
- FeedbackTransformation
- CoFeedbackTransformation
- 函数体系
- 连接器
- 分布式ID
数据流元素
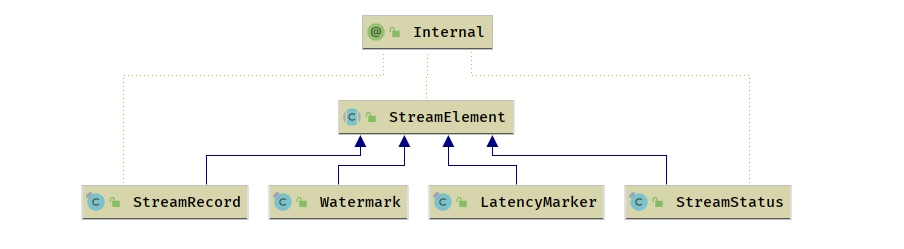
StreamRecord
- 表示数据流中一条记录(或者叫做一个事件),也叫作数据记录
包含
- 数据的值本身
时间戳 (可选) ```java /* The actual value held by this record. / private T value;
/* The timestamp of the record. / private long timestamp;
/* Flag whether the timestamp is actually set. / private boolean hasTimestamp;
<a name="Debfe"></a>#### LatencyMarker- 用来近似估计延迟,LatencyMarker 在 Source 中创建,并向下游发送,绕过业务处理逻辑,在 Sink 节点使用 LatencyMarker 估计在整个 DAG 图中流花费的时间,用来近似的评估总体上的处理逻辑- 包含- 周期性地在数据源算子中创造出来的时间戳- 算子编号- 数据源算子所在的 Task 编号```java/** The time the latency mark is denoting. */private final long markedTime;private final OperatorID operatorId;private final int subtaskIndex;
Watermark
WaterMark 是一个时间戳,用来告诉算子所有时间早于等于 WaterMark 的事件或记录都已经到达,不会再有比 WaterMark 更早的记录,算子可以根据 WaterMark 触发窗口的计算.清理资源等
/** The timestamp of the watermark in milliseconds. */ private final long timestamp;StreamStatus
用来通知 Task 是否会继续接收到上游的记录或者 WaterMark. StreamStatus在数据源算子中生成,向下游沿着 Dataflow 传播.
- StreamStatus 表示两种状态
- IDLE 空闲状态
- ACTIVE 活动状态
public static final int IDLE_STATUS = -1; public static final int ACTIVE_STATUS = 0;
Transformation
protected String name; // 转换器的名称,主要用于可视化
private String uid; // 用户指定的UID,目的在Job重启时再次分配与之前相同的uid,可以持久保存状态
protected long bufferTimeout = -1; // 超时时间
private int parallelism; // 并行度
protected final int id; // 跟属性uid 无关,生成方式是基于一个静态累加器
private String userProvidedNodeHash;
protected TypeInformation<T> outputType; // 输出类型 用来进行序列化数据
private String slotSharingGroup; // 给当前的 Transformation 设置 Slot共享组
物理 Transformation
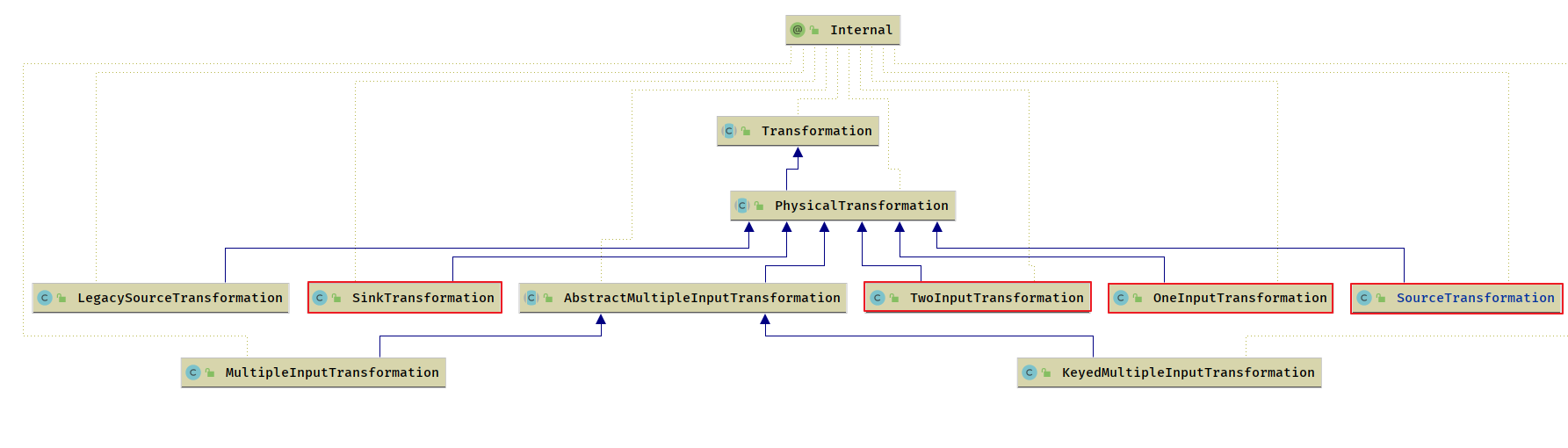
SourceTransformation
- 从数据源读取数据的
Transformation,是 Flink 作业的起点,SourceTransformation只有下游Transformation,没有上游输入Transformation 一个作业可以有多个
SourceTransformation, 从多个数据源读取数据[多流Join,维表Join,BroadcastState]SinkTransformation
将数据写入到外部存储的
Transformation,是 Flink 作业的终点,SinkTransformation只有上游Transformation,下游就是外部存储了-
OneInputTransformation
只接收一个输入流 同样需要
input和operator参数TwoInputTransformation
接收两个输入流作为输入

SideOutputTransformation
- 旁路输出中转换而来
上游的
SideOutputTransformation分流给下游的多个SideOutputTransformation,每一个OutPut通过OutPutTag进行标识.SplitTransformation
按照条件切分数据流,该转换用于将一个流拆分成多个流(通过
OutputSelector来达到这个目的)SelectTransformation
与
SplitTransformation配合使用,用来在下游选择SplitTransformation切分的数据流PartitionTransformation
-
UnionTransformation
合并转换器,该转换器用于将多个输入
StreamTransformation进行合并,因此该转换器接收StreamTransformation的集合,其名称在内部也被固定为Union-
FeedbackTransformation
该转换器用于表示Flink DAG中的一个反馈点(
feedback point)。所谓反馈点,可用于连接一个或者多个StreamTransformation,这些StreamTransformation被称为反馈边(feedback edges)。处于反馈点下游的operation将可以从反馈点和反馈边获得元素输入。CoFeedbackTransformation
某种程度上跟
FeedbackTransformation类似。feedback元素的类型不需要跟上游的StreamTransformation元素的类型一致,因为CoFeedbackTransformation之后只允许跟TwoInputTransformations。上游的StreamTransformation将会连接到TwoInputTransformations第一个输入,而feedback edge将会连接到其第二个输入。因此上游的StreamTransformation其实是跟CoFeedbackTransformation无关的,它跟TwoInputTransformation有关。- 上游的
StreamTransformation跟CoFeedbackTransformation无关,从CoFeedbackTransformation构造器需要的参数就可以看出来。通常,其他的StreamTransformation的实现都需要传入上游的StreamTransformation作为其输入。但CoFeedbackTransformation却没有,它只需要上游的并行度:parallelism。另外一个需要的参数是feedbackType。
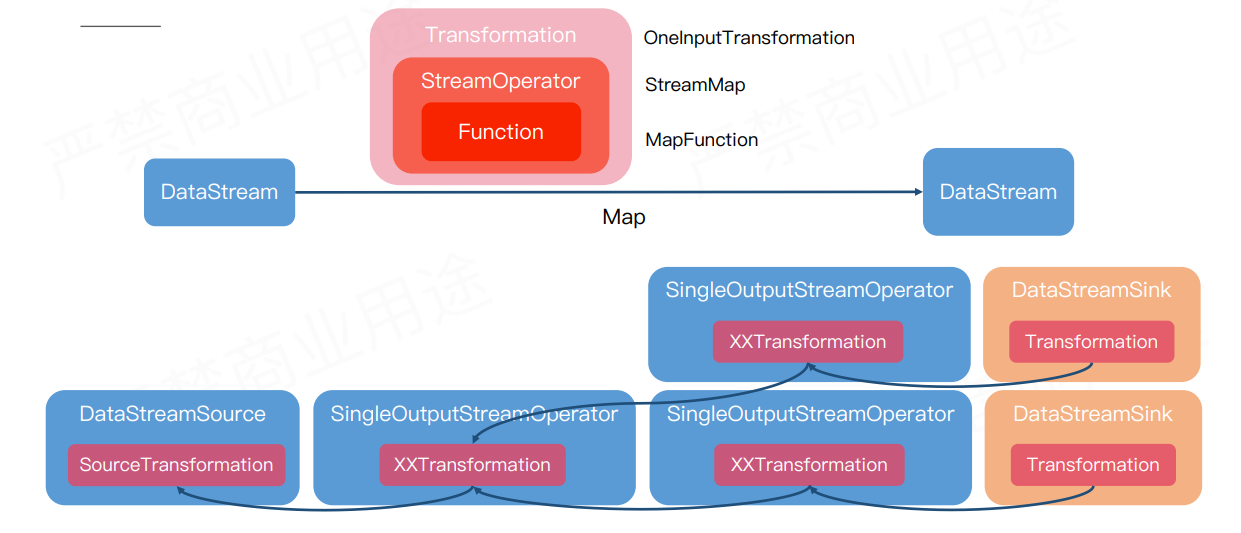
算子
所有算子都包含了
生命周期管理
- setup : 初始化环境,时间服务,注册监控等
- open : 当前操作由各个具体的算子负责实现,包含了算子的初始化逻辑
- close : 所有的数据处理完毕之后关闭算子,此时需要确保将所有的缓存数据向下发送
- dispose : 算子生命周期的最后阶段执行,此时算子已经关闭,停止处理数据,进行资源的释放
状态与容错管理
- 算子负责状态管理,提供状态存储,触发检查点的时候,保存状态快照,并将快照异步保存到外部的分布式存储
- 当作业执行失败时从保存的快照中恢复状态
数据处理
- 算子对数据的处理,不仅会进行数据记录的处理,同时也会提供对 WaterMark 和 Laten-cyMarker 的处理
- 算子按照单流输入 和 双流输入 走对应的接口
- OneInputStreamOperator
- TwoInputStreamOperator
- 算子融合优化策略
OneInputStreamOperator
@PublicEvolving
public interface OneInputStreamOperator<IN, OUT> extends StreamOperator<OUT> {
void processElement(StreamRecord<IN> element) throws Exception;
void processWatermark(Watermark mark) throws Exception;
void processLatencyMarker(LatencyMarker latencyMarker) throws Exception;
}
TwoInputStreamOperator
@PublicEvolving
public interface TwoInputStreamOperator<IN1, IN2, OUT> extends StreamOperator<OUT> {
void processElement1(StreamRecord<IN1> element) throws Exception;
void processElement2(StreamRecord<IN2> element) throws Exception;
void processWatermark1(Watermark mark) throws Exception;
void processWatermark2(Watermark mark) throws Exception;
void processLatencyMarker1(LatencyMarker latencyMarker) throws Exception;
void processLatencyMarker2(LatencyMarker latencyMarker) throws Exception;
}

数据处理
- OneInputStreamOperator
- TwoInputStreamOperator
生命周期,状态容错
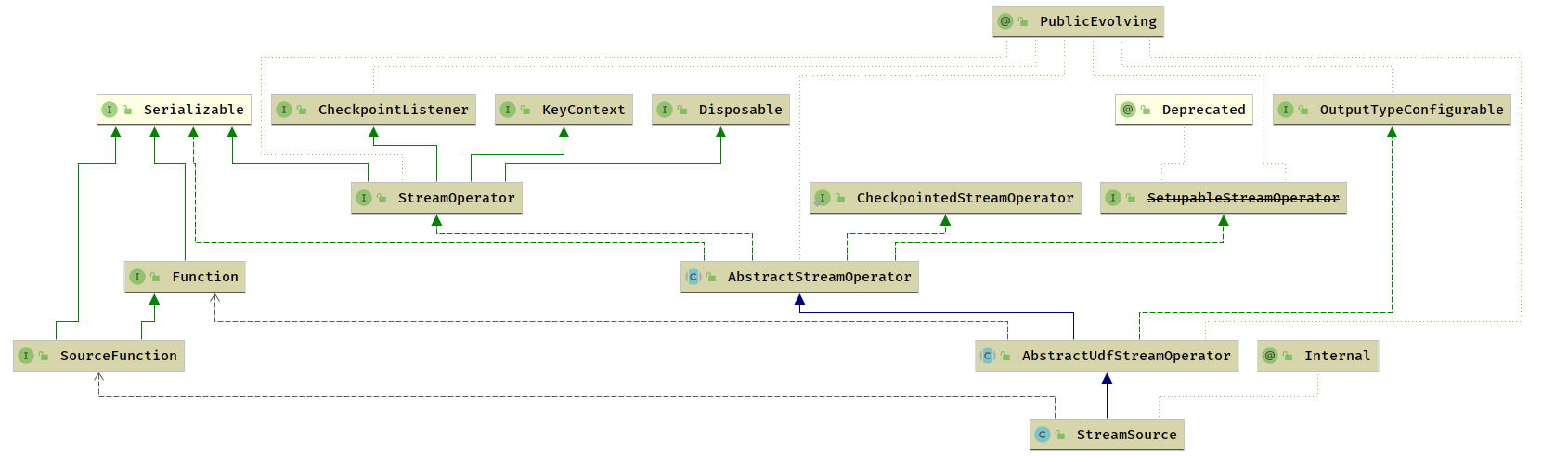
- AbstractStreamOperator 抽象类
- AbstractUdfStreamOperator 实现类
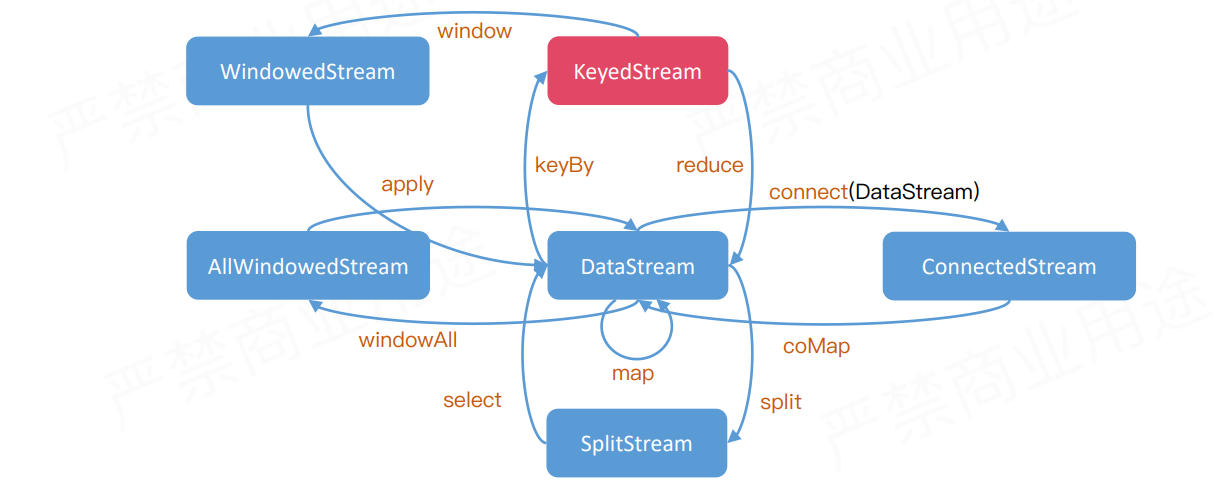
DataStream 的算子 从行为上来说分4类
- 单流输入算子
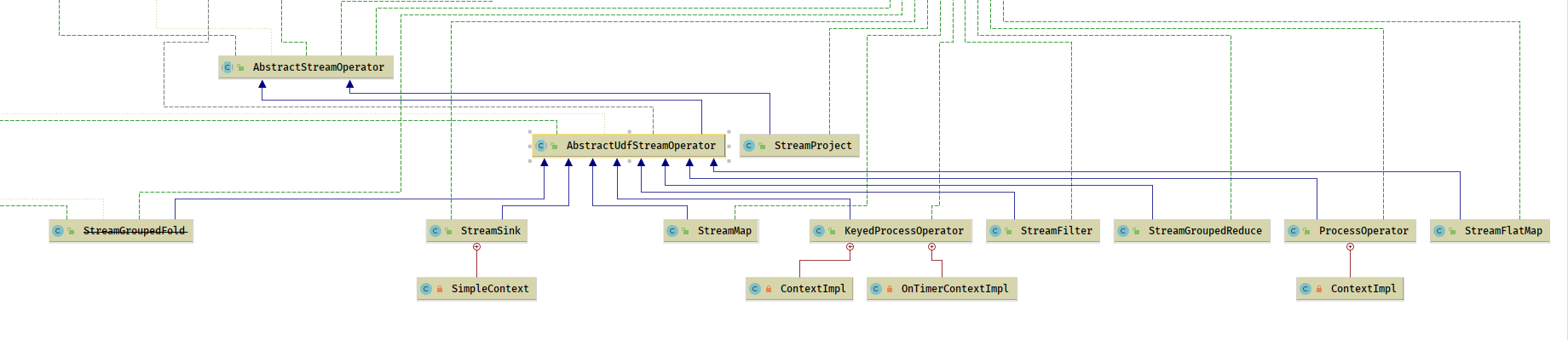
- 双流输入算子

- 数据源算子
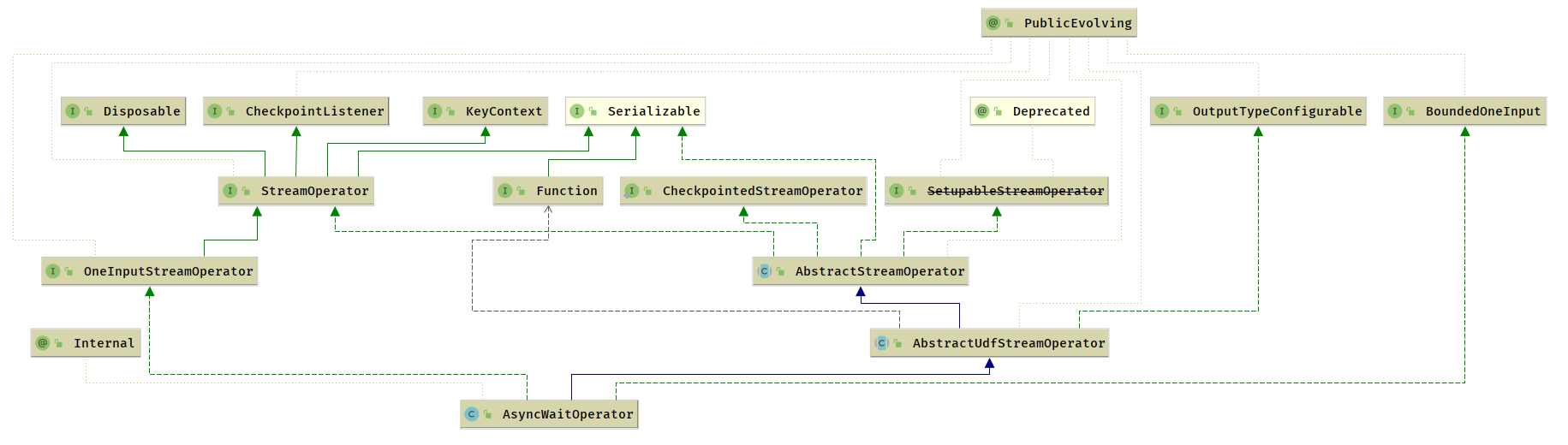
- 异步算子
Blink Join 算子

- HashJoinParameter

- TemporalProcessTimeJoinOperator 基于处理时间
TemporalRowTimeJoinOperator 基于事件时间
Sort算子
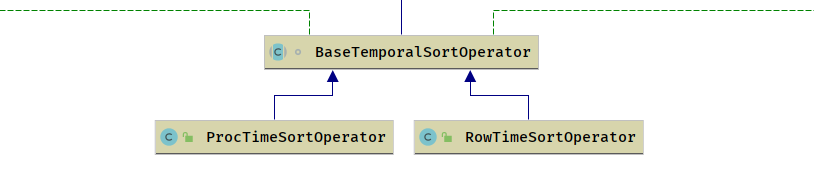
排序算子,分别为流批两种,排序是一种全局排序,对于流批而言无法共用相同的算子实现
流上包括 (支持时间+其他排序字段)
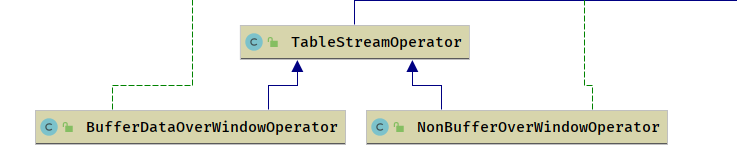
BufferDataOverWindowOperator
- Over 开窗运算经常需要用当前数据跟之前N条数据一起计算,所以需要采用将之前的数据缓存起来的方式,在内存不足的情况下自动溢出到磁盘
NonBufferOverWindowOperator
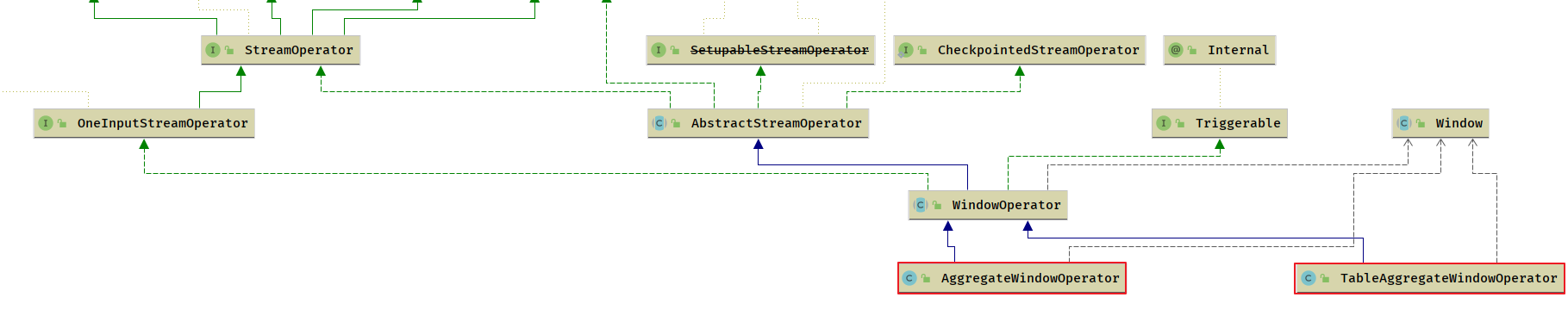
AggregateWindowOperator
- 使用普通聚合函数 (UDAF) 的窗口算子
TableAggregateWindowOperator
WatermarkAssignerOperator
- 从数据元素中提取时间戳,周期的生成 Watermark
- RowTimeMiniBatchAssginerOperator
- 用在 mini-batch 模式下,依赖上游的 Watermark ,基于事件时间周期性地生成 Watermark
ProcTimeMiniBatchAssignerOperator
Mini-batch 算子用微批来提升计算效率,提高吞吐量. 使用Java 的Map 来缓存数据,Map的Key 与 State 的Key保持一致,在进行聚合运算的时候可以批量操作,避免每一条数据都访问State.
- MapBundleOperator
- 应用于未按照 Key 分组的数据流
KeyedMapBundleOperator
SortOperator 实现批上的全局数据排序
- SortLimitOperator 实现批上的带Limit排序
- LimitOperator 实现批上的Limit 语义
- RankOperator 实现批上的 TopN 语义


其他模块算子
- ProcessOperator | KeyedProcessOperator
- CEPOperator
函数体系
- SourceFunction
- 无上游算子,SourceFunction直接从外部数据存储读取数据
- SinkFunction
- 无下游算子,SinkFunction直接将数据写入到外部存储
- 一般 Function (UDF)
- 一般的 UDF 函数用在作业的中间处理步骤中,一般UDF 有上游算子,也有下游算子
- 一般算子分为:
- 单流输入Function
- 双流输入Function
函数层次
Flink 提供的函数体系从接口的层级来看,从高阶 Function 到 低阶 Function
- 无状态Function
- UDF 接口 (MapFunction)
- RichFunction
- UDF接口 + 状态 + 生命周期 (RichFunction)
- ProcessFunction
- UDF接口 + 状态 + 生命周期 + 触发器 (JoinFunction)
- RichFunction 相比于 无状态Function 有两方面的增强
- 增加了 open 和 close 方法来管理 Function 的生命周期,在 open 方法中执行初始化,在Function 停止时,在 Close 方法中 执行清理,释放占用资源等
- 增加了 getRuntimeContext 和 setRuntimeContext , RichFunction 能获取到执行时作业级别的参数信息
处理函数
处理函数 (ProcessFunction) 可以访问流应用程序所有 基本构建块
- 事件 (数据流元素)
- 状态 (容错和一致性)
- 定时器 (事件时间和处理时间)
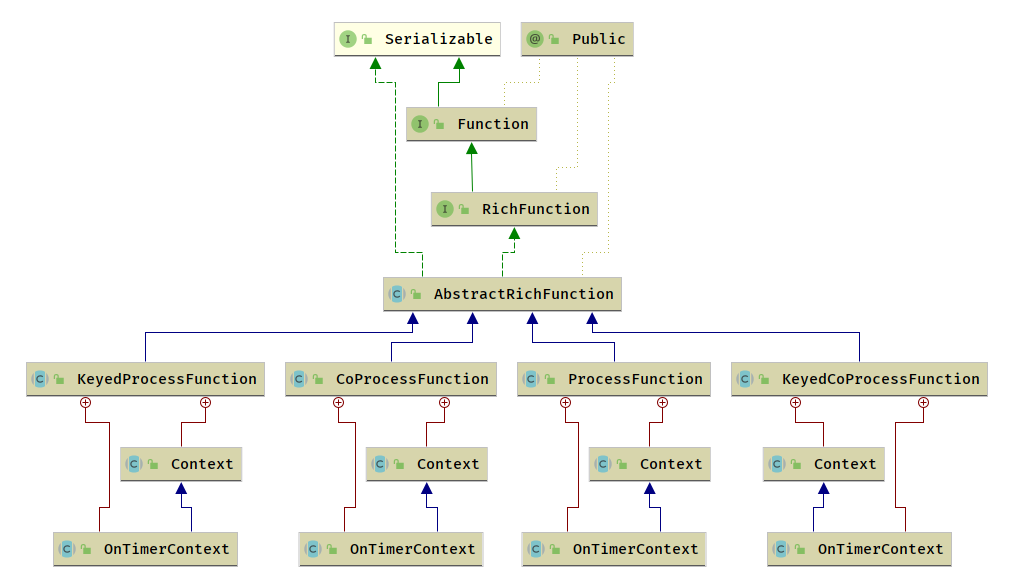
- KeyedProcessFunction 与 Non-KeyedProcessFunction 的区别是
- KeyedProcessFunction 只能应用于 KeyedStream
- ProcessFunction 与 CoProcessFunction 区别是
- CoProcessFunction 是双流输入
- ProcessFunction 是单流输入
CoProcessFunction 实现双流 Join
即时双流 Join
- 创建1个State对象
- 接收到输入流1 事件后更新 State
- 接收到输入流2 事件后 遍历 State,根据 Join 条件进行匹配,将匹配后的结果发送到下游
延迟双流 Join
- 在流数据里,数据可能是乱系的,数据会延迟到达,并且为了提供处理效率,使用小批量计算模式,而不是每个事件都触发一次 Join 计算
- 创建2个State对象,分别缓存输入流1和输入流2的事件
- 创建一个定时器,等待数据的到达,定时延迟触发Join计算
- 接收到输入流1事件后更新 State
- 接收到输入流2事件后更新 State
- 定时器遍历 State1 和 State2,根据Join 条件进行匹配,将匹配后的结果发送到下游
延迟计算
- 窗口计算 Watermark 和 Window 就是所谓的窗口计算(WindowOperator)
- 使用Window 暂存数据,使用Watermark 触发 Window 计算
**InternalTimerServiceImpl**public void advanceWatermark(long time) throws Exception { currentWatermark = time; InternalTimer<K, N> timer; while ((timer = eventTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) { eventTimeTimersQueue.poll(); keyContext.setCurrentKey(timer.getKey()); triggerTarget.onEventTime(timer); } }广播函数
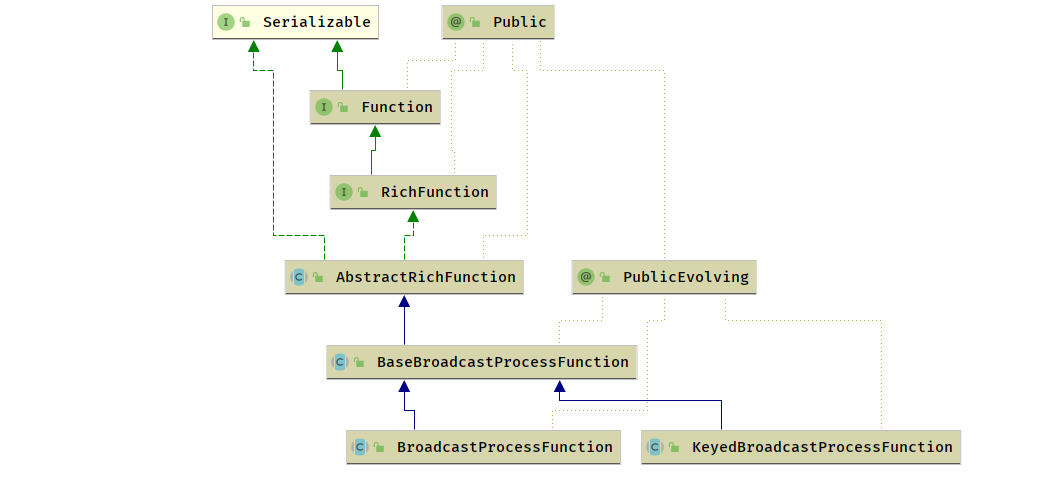
processElement() 和 processBroadcastElement() 方法区别在于:
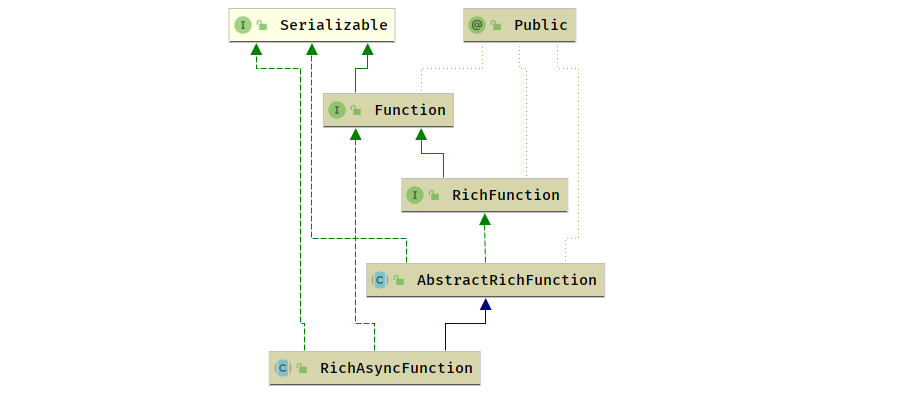
异步函数的抽象类 RichAsyncFunction 实现 AsyncFunction接口,继承 AbstractRichFunction 获取了生命周期管理和 FunctionContext 的访问能力
- 异步调用行为将结果封装到 ResultFuture 中,同时提供了调用超时的处理,防止不释放资源
- AsyncFunction
- RichAsyncFunction
- AbstractRichFunction
```java
@PublicEvolving
public interface AsyncFunction
resultFuture) throws Exception; default void timeout(IN input, ResultFuture resultFuture) throws Exception {
}resultFuture.completeExceptionally( new TimeoutException("Async function call has timed out."));
}
<a name="RjQrz"></a>
#### 数据源函数
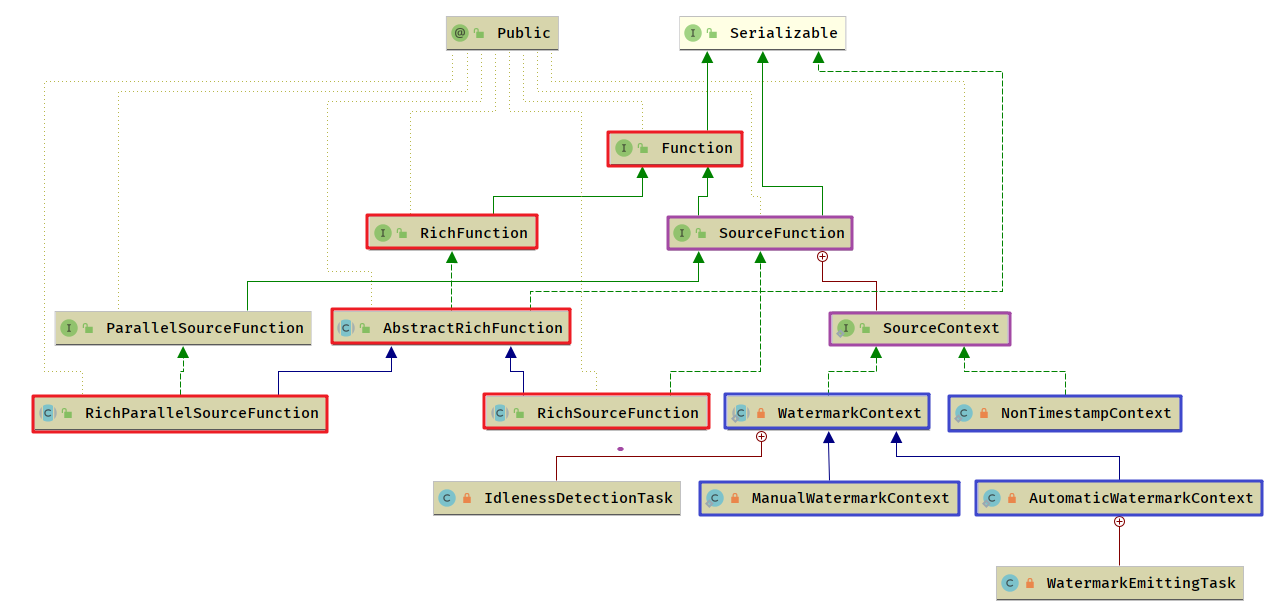
- SourceFunction
- 专门用来从外部存储读取数据,SourceFunction 是 Flink 的起点,一个作业可以有多个起点,即读取多个数据源的数据
- 一般使用 RichSourceFunction | RichParallelSourceFunction
- 这两个 抽象类 通过继承 AbstractRichFunction 获得了 Function的生命周期,访问 RuntimeContext 的能力
- RichSourceFunction 是不可以并行的,并行度限定为1,超过1则会报错
- RichParallelSourceFunction 是可以并行的,并行度可以按照需求设定,并没有限制
- SourceFunction 有几个比较关键的行为
> 1. 生命周期管理: open | close | cancle 生命周期方法中包含 相应的 初始化\清理
> 1. 读取数据: 持续的从外部存储读取数据
> 1. 向下游发送数据
> 1. 发送 Watermark : 生成 Watermark 向下游发送
> 1. 空闲状态标记: 如果读不到数据,则将该 Task 标记为空闲,向下游发送 Status 阻止 Watermark 向下游传播/
```java
public interface SourceFunction<T> extends Function, Serializable {
void run(SourceContext<T> ctx) throws Exception;
void cancel();
@Public // Interface might be extended in the future with additional methods.
interface SourceContext<T> {
void collect(T element);
@PublicEvolving
void collectWithTimestamp(T element, long timestamp);
@PublicEvolving
void emitWatermark(Watermark mark);
void markAsTemporarilyIdle();
Object getCheckpointLock();
void close();
}
}
StreamSourceContext 中提供了两种不同类型的SourceContext的实例方法,从整体上按带不带时间分为两种
- NonTimestampContext: 为所有元素赋予-1 作为时间戳,意味永远不会向下游发送 Watermark (Processing Time)
- WatermarkContext
- 负责管理当前的 StreamStatus,确保 StreamStatus 向下游传递
- 负责空闲检测的逻辑,当超过设定事件间隔而没有收到数据或者 Watermark 时,认为 Task 处于空闲状态
WatermarkContext 有两个实现类
- AutomaticWatermarkContext
- 使用摄入时间(Ingestion Time)的时候,AutomaticWatermarkContext 会自动生成 Watermark
- 启动 WatermarkEmittingTask 向下游发送 Watermark,使用一个定时器 其触发时间= (作业启动的时刻+Watermark周期x n),一旦启动,WatermarkEmittingTask 会持续的自动注册定时器,向下游发送 Watermark
- ManualWatermarkContext
- AutomaticWatermarkContext
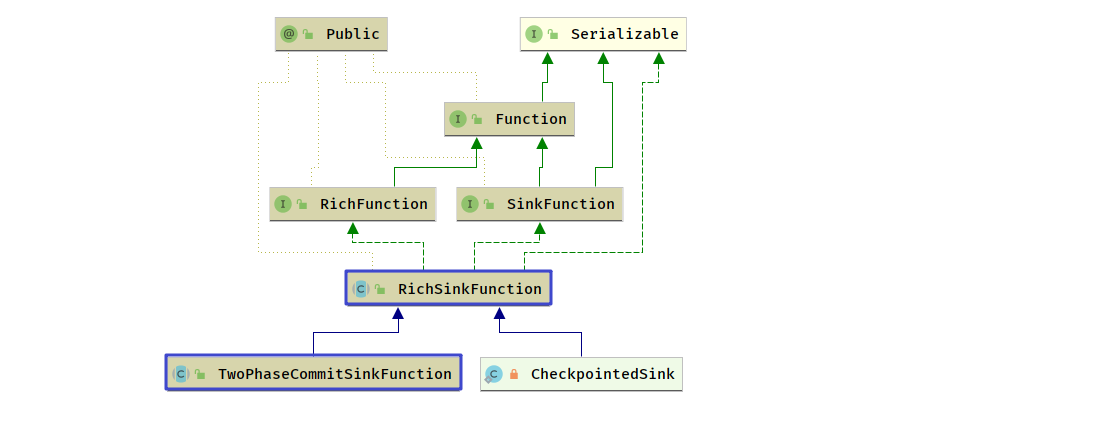
SinkFunction
- RichSinkFunction
-
检查点函数
支持函数级别状态的保存和恢复的函数
CheckpointedFunction
- 当保存状态之后,snapshotState() 会被调用,用于备份保存状态到外部存储
- 当恢复状态的时候,其initializeState() 方法负责初始化 State,执行从上一个检查点恢复状态的逻辑
public interface CheckpointedFunction { void snapshotState(FunctionSnapshotContext context) throws Exception; void initializeState(FunctionInitializationContext context) throws Exception; }
ListCheckpointed
- 该接口的行为 跟 Checkpoint 行为类似,除了提供状态管理之外,修改作业并行度的时候,还提供了状态重分布的支持
public interface ListCheckpointed<T extends Serializable> { List<T> snapshotState(long checkpointId, long timestamp) throws Exception; void restoreState(List<T> state) throws Exception; }数据分区

- CustomPartitionerWrapper
- ForwardPartitioner : 数据直接传递给下游
- CustomPartitionerWrapper
- 该接口的行为 跟 Checkpoint 行为类似,除了提供状态管理之外,修改作业并行度的时候,还提供了状态重分布的支持
ShufflePartitioner : 随机将元素进行分区,可以确保下游的Task 能够均匀的获取数据
RebalancePartitioner : 以Round-robin的方式为每个元素分配分区,确保下游的Task可以均匀的获取到数据
RescalingPartitioner :
BroadcastPartitioner : 广播给所有分区
KeyGroupStreamPartitioner : 该分词器不是提供给用户的,KeyedStream在构建Transformation时,默认使用KeyedGroup分区形式,从而在底层上支持作业 Resscale 功能
GlobalPartitioner :
连接器
略
分布式ID
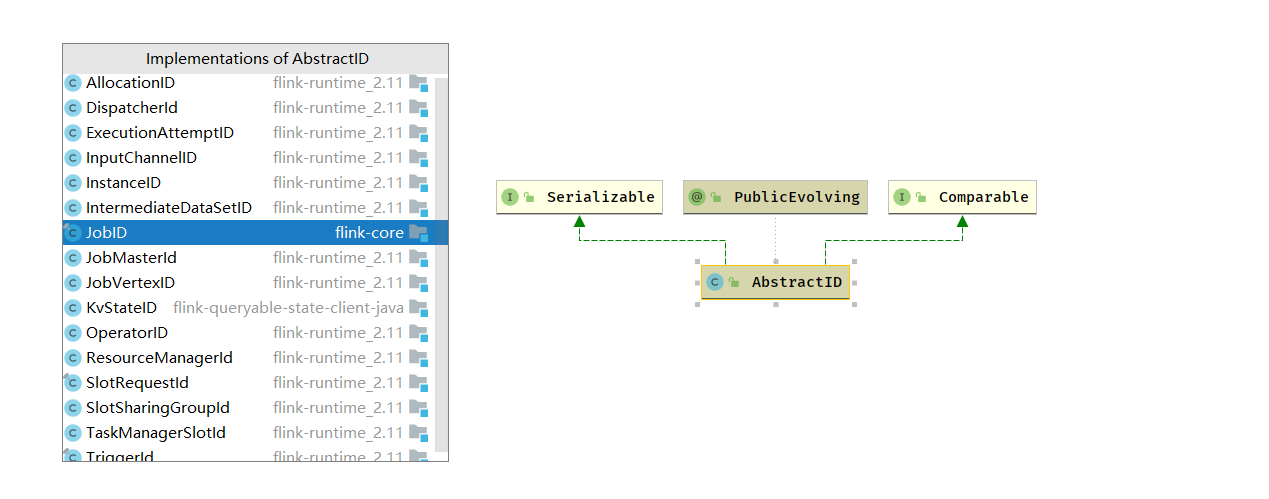
- 在分布式计算中,Flink 对所有需要进行唯一标识的组件,对象提供了抽象类 AbstractID,因为需要跨网络进行传输,所以实现了 Serializable 接口,需要比较唯一标识是否相同 所以也实现了 Comparable 接口 .
- Flink 作业
- 资源管理
- 作业管理器
- 资源管理器
- TaskManager

若有收获,就点个赞吧
0 人点赞
