- 调度器是 Flink 作业执行的核心组件,管理作业执行的所有相关过程
JobGraph到ExecutionGraph的转换- 作业生命周期管理 (作业的发布,取消,停止)
- 作业的
Task生命周期管理 (Task发布,Task取消,Task停止) - 资源的申请和释放
- 作业特殊情况处理 (
Failover)
调度
在调度体系中有几个非常重要的组件
- 调度器:
SchedulerNG及子类,实现类 - 调度策略:
SchedulingStrategy及其实现类 - 调度模式:
ScheduleMode包含流和批的调度,有各自不同的调度模式
调度器 <SchedulerNG>
作业调度器是 作业的执行 异常处理的核心
- 作业的生命周期管理 (开始调度,挂起,取消)
- 作业执行资源的申请,分配,释放
- 作业的状态管理,作业发布过程中的状态变化和作业异常时
FailOver等 作业的信息提供,对外提供作业的详细信息
public interface SchedulerNG {void setMainThreadExecutor(ComponentMainThreadExecutor mainThreadExecutor);void registerJobStatusListener(JobStatusListener jobStatusListener);void startScheduling();void suspend(Throwable cause);void cancel();CompletableFuture<Void> getTerminationFuture();boolean updateTaskExecutionState(TaskExecutionState taskExecutionState);SerializedInputSplit requestNextInputSplit(JobVertexID vertexID, ExecutionAttemptID executionAttempt) throws IOException;ExecutionState requestPartitionState(IntermediateDataSetID intermediateResultId, ResultPartitionID resultPartitionId) throws PartitionProducerDisposedException;void scheduleOrUpdateConsumers(ResultPartitionID partitionID);ArchivedExecutionGraph requestJob();JobStatus requestJobStatus();JobDetails requestJobDetails();}
Flink 中有两个调度器的实现
LegacyScheduler- 改调度器是遗留的调度器,实际上使用了原来的
ExecutionGraph的调度逻辑
- 改调度器是遗留的调度器,实际上使用了原来的
DefaultScheduler- 该调度器是当前版本的默认调度器
- 是
Flink新的调度设计,使用SchedulingStrategy来实现调度
调度行为 <SchedulingStrategy>
SchedulingStrategy 接口定义了调度行为
startSchedulingrestartTasksonExecutionStateChangeonPartitionConsumablepublic interface SchedulingStrategy {// 触发调度器的调度行为,调度入口void startScheduling();// 重启执行失败的 Task,一般是 Task执行异常导致的void restartTasks(Set<ExecutionVertexID> verticesToRestart);// 当 Execution的状态发生改变时void onExecutionStateChange(ExecutionVertexID executionVertexId, ExecutionState executionState);// 当 IntermediateResultPartition 中的数据可以消费时void onPartitionConsumable(ExecutionVertexID executionVertexId, ResultPartitionID resultPartitionId);}
调度模式 <ScheduleMode>
Flink 提供了 三种调度模式
EAGER调度- 分阶段调度 (
LAZY_FROM_SOURCES) - 分阶段 Slot 重用调度 (
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST)
EAGER
- 该模式适用于流计算
- 一次性申请需要所有的资源,如果资源不足,则作业启动失败
LAZY_FROM_SOURCES
- 该模式适用于批处理,申请资源的时候
- 一次性申请本阶段所需要的所有资源
- 上游
Task执行完毕后开始调度执行下游的Task - 读取上游的数据,执行本阶段的计算任务
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST
- 该模式适用于批处理
- 与
LAZY_FROM_SOURCES调度基本一致 - 区别: 可以在资源不足的情况下执行作业,但需要确保在本阶段的作业执行中没有
Shuffer行为
调度策略
流批的调度策略不同
- 流作业调度的时候需要一次性获取所有
Slot, 部署Task并执行 - 批作业调度的时候可以分阶段调度执行,上一个阶段执行完毕后,数据可以消费的时候,开始调度下游的执行
EagerSchedulingStrategy —-> 流调度策略LazyFromSourcesSchedulingStrategy —-> 批调度策略
执行模式
Flink 中有两类执行模式
Pipelined模式Batch模式
public enum ExecutionMode {// 流水线模式PIPELINED,// 强制流水线模式PIPELINED_FORCED,// 流水线优先模式// PIPELINED_WITH_BATCH_FALLBACK,// 批处理模式BATCH,// 强制批处理模式BATCH_FORCED}
ExecutionMode.PIPELINED
- 该模式以流水线方式(包括
Shuffer和Broadcast) 执行作业,但流水线可能会出现死锁的数据交换 - 如果可能会出现数据交换死锁,则数据交换以
Batch方式执行 - 当数据流被多个下游分支消费处理时,处理后的结果再进行
Join,如果以Pipelined模式运行,则可能会出现数据交换死锁
ExecutionMode.PIPELINED_FORCED
- 该模式以流水线方式(包括
Shuffer和Broadcast) 执行作业 - 即便流水线可能会出现死锁的数据交换时依然执行
- 一般情况下,
Pipelined模式是优先选择,确保不会出现数据死锁的情况下才会使用PIPELINED_FORCED
ExecutionMode.PIPELINED_WITH_BATCH_FALLBACK (该模式目前尚未实现)
- 该模式首先使用
Pipelined启动作业,如果可能死锁则使用PIPELINED_FORCED启动作业 - 当作业异常退出时,则使用
Batch模式重新执行作业
ExecutionMode.BATCH
- 该模式对于所有
Shuffer和Broadcast都是用Batch模式,仅本地的数据交换使用Pipelined模式
ExecutionMode.BATCH_FORCED
- 该模式对于所有的数据交换都是用
Batch模式,对于本地交换也不例外
数据交换模式
执行模式的不同该决定改了数据交换行为的不同,为了能够实现不同的数据交换行为, Flink 在 ResultPartitionType 中定义了 4 种类型的数据分区模式,与执行模式一起完成批流在数据交换层面的统一
public enum ResultPartitionType {//BLOCKING(false, false, false, false),BLOCKING_PERSISTENT(false, false, false, true),PIPELINED(true, true, false, false),PIPELINED_BOUNDED(true, true, true, false);}
ResultPartitionType.BLOCKING
BLOCKING类型的数据分区会等待数据完全处理完毕,然后才会交给下游进行处理- 在上游处理完毕之前,不会与下游进行数据交换
- 该类型的数据分区可以被多次消费,也可以并发消费
- 被消费完毕之后不会自动释放,而是等待调度器来判断该数据分区无人在消费之后,由调度器发出销毁指令
- 该模式适用于批处理,不提供反压流控能力
ResultPartitionType.BLOCKING_PERSISTENT
BLOCKING_PERSISTENT类型的数据分区类似于BLOCKING- 其生命周期由用户指定,调用
JobManager或者ResourceManager API进行销毁,而不是由调度器控制
ResultPartitionType.PIPELINED
PIPELINED式数据交换适用于流计算和批计算- 数据处理结果只能被1个消费者(下游的 算子) 消费 1次,当数据被消费之后即自动销毁
PIPELINED分区可能会保存一份数据- 与
PIPELINED_BOUNDED相反,此结果分区类型可以在运行中保留任意数量的数据 - 当数据量太大内存无法容纳时,可以写入磁盘中
ResultPartitionType.PIPELINED_BOUNDED
PIPELINED_BOUNDED是PIPELIEND带有一个有限大小的本地缓冲池- 对于流计算作业,固定大小的缓冲池可以避免缓冲太多的数据和检查点延迟太久
- 不同于限制整体网络缓冲池的大小,该模式下允许根据分区的总数弹性地选择网络缓冲池的大小
对于批作业来说,最好使用无限制的 PIPELINED 数据交换模式,因为在批处理模式下 没有 CheckpointBarrier ,其实现 Exactly-Once 与流计算不同
作业生命周期
有限状态机又叫做 Finite State Machine (FSM) , 表示有限个状态及在这些状态之间的转移和动作等行为的数学模型
现态
- 当前所处的状态
条件/事件
- 当一个条件被满足时,将会触发一个动作,或者执行一次状态的迁移
动作 :
- 条件满足后执行的动作,动作执行完毕后,可以迁移到新的状态,也可以依旧保持原状态
- 动作不是必须的,当条件满足后,也可以不执行任何动作,直接迁移到新状态
次态
- 条件满足后要迁往的新状态
作业生命周期状态
JobMaster 负责作业的生命周期管理,具体的管理行为在调度器和 ExecutionGraph 中实现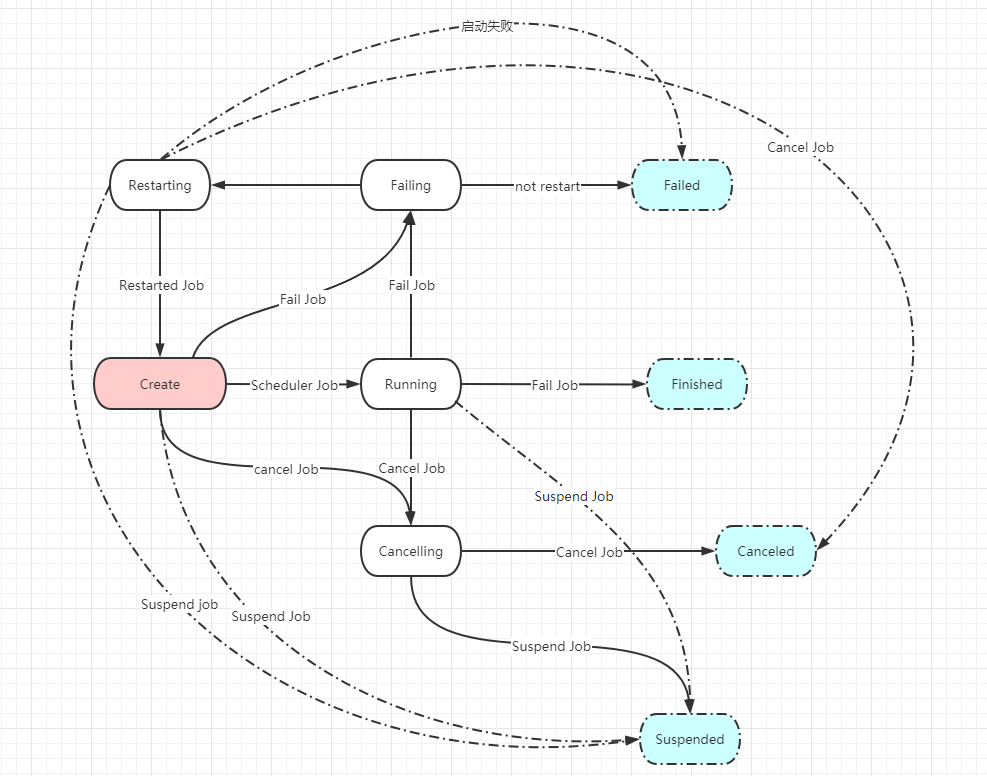
Created 状态
- 作业刚被创建,还没有
Task开始执行
Running 状态
- 作业创建完之后,就开始申请资源,申请必要的资源成功,并且向
TaskManager调度Task执行成功,就进入Running状态 - 在
Running状态下- 对于流作业而言,作业的所有
Task都在执行 - 对于批作业而言,可能部分
Task被调度执行, 其他的Task在等待调度
- 对于流作业而言,作业的所有
Restarting 状态
- 当作业执行出错,需要重启作业的时候,首先进入
Failing状态 - 如果可以重启则进入
Restarting状态 - 作业进行重置,释放所申请的所有资源,包含内存,
Slot等,开始重新调度作业的执行
Cancelling 状态
- 调度 Flink 的接口或者在 WebUI 上对作业进行取消,首先会进入此状态
- 此状态下: 首先会清理资源,等待作业的
Task停止
Canceled 状态
- 当所有的资源清理完毕,作业完全停止执行后,进入
Canceled状态 - 此状态一般适用于用户主动停止作业
Suspended 状态
- 挂起作业之前,取消
Running状态的Task Task进入Canceled状态,销毁掉通信组件等其他组件,但是任然保留ExecutionGraph, 等待恢复Suspended状态一般在 HA 下,主JobManager宕机 ,备JobManager接管继续执行时,恢复ExecutionGraph
Finished 状态
- 作业的所有
Task都成功执行完毕后,作业退出, 进入Finished状态
Failing 状态
- 作业执行失败后 进入
Failing模式 等待资源清理 - 作业执行失败,可能是因为作业代码中抛出的异常没有处理,或者是资源不足
Failed 状态
- 如果作业的
Failing状态的异常达到了作业自动重启次数的限制 - 或者其他更严重的异常导致作业无法自动恢复 则会进入
Failed状态
Task 的生命周期
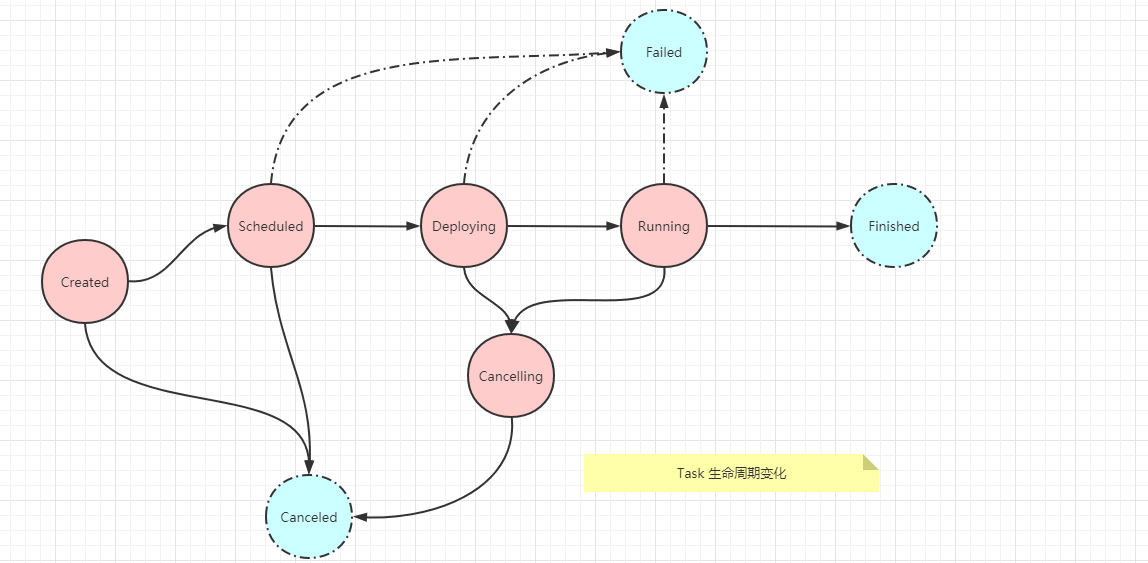
TaskManager 负责 Task 的生命周期管理,并将状态的变化通知到 JobManager , 在 ExecutionGraph 中跟踪 Execution 的状态变化,一个 Execution 对应与一个 Task
作业的生命周期的状态本质上来说就是各个 Task 状态的汇总
作业被调度执行发布到各个 TaskManager 上开始执行, Task 在其整个生命周期中有 8 种 状态,定义在 ExecutionState 中,其中 Created 是起始状态,Failed / ``Finished / Canceled 状态是 Final 状态
Created 状态
ExecutionGraph创建出来之后,Execution默认的状态 就是Created
Scheduled 状态
- 在
ExecutionGraph中有Scheduled状态, 在TaskManager上的Task不会有该状态 Scheduled状态表示被调度执行的Task进入Scheduled状态- 但并不是所有的
Task都会变成Scheduled状态, 然后开始申请所需的计算资源
Deploying 状态
Deploying状态表示资源申请完毕, 向TaskManager部署Task
Running 状态
TaskManager启动Task,并通知JobManager该Task进入Running状态JobManager将该Task所在的ExecutionGraph中对应的Execution设置为Running状态
Finished 状态
- 当
Task执行完毕,没有异常,则进入Finished状态 JobManager将该Task所在的ExecutionGraph中的Execution设置为Finished状态
Cancelling 状态
Cancelling与Scheduled / Deploying状态类似, 是ExecutionGraph中维护的一种状态- 表示正在取消
Task执行, 等待TaskManager取消Task的执行,并返回结果
Canceled 状态
TaskManager取消Task执行成功,并通知JobManagerJobManager将该Task所在的ExecutionGraph中对应的Execution设置为Canceled状态
Failed 状态
- 若
TaskManager执行Task时出现异常导致Task无法继续执行 Task会进入Failed状态 并通知JobManagerJobManager将该Task所在的ExecutionGraph中对应的Execution设置为Failed状态- 整个作业也将进入
Failed状态
关键组件
JobMaster
新版本中已经没没有
JobManager这个类对象,取而代之的是JobMasterJobManagerRunner则依旧延续旧的名称
- 用于启动
JobMaster- 提供作业级别的
Leader选举- 处理异常
旧版本中
JobManager的作业调度,管理等逻辑 现在由JobMaster实现 在之前的实现中所有的作业共享JobManager引入JobMaster之后,一个JobMaster对应一个作业,一个JobManager中可以有多个JobMaster,这样的实现能够更好地隔离作业,减少相互影响的可能性
Flink 的 JobManager 是一个独立运行的进程,该进程包含了一系列的服务,如 Dispatcher / ResourceManager 等JobMaster 负责单个作业的管理,提供了对作业的管理行为,允许通过外部的命令干预作用的运行,如提交/取消 等
同时 JobMaster 也维护了整个作业及其 Task 的状态,对外提供对作业状态的查询功能,JobMaster 负责接收 JobGraph 并将其转换为 ExecutionGraph 自动调度器执行 ExecutionGraph
1. 调度执行和管理
- 将
JobGraph转换为ExecutionGraph调度Task的执行,并处理Task的异常,进行作业恢复或者中止 - 根据
TaskManager汇报的状态维护ExecutionGraph
1) InputSplit 分配
- 在批处理中使用,为批处理计算任务分配待计算的数据分片
2) 结果分区跟踪
- 结果分区跟踪器 (
PartitionTracker) 跟踪非Pipelined模式的分区,其实就是跟踪批处理中的结果分区 - 当结果分区消费完之后,具备结果分区释放条件时,向
TaskExecutor和ShufferMater发出释放请求
3) 作业执行异常
- 根据作业的执行异常,选择重启作业或者停止作业
2. 作业 Slot 资源管理
Slot 资源的申请,持有和释放, JobMaster 将具体的管理动作交给 SlotPool 来执行,SlotPool 持有资源,资源不足时负责与 ResourceManager 交互申请资源
- 释放
TaskManager的情况: 作业的停止 / 限制的TaskManager/TaskManager心跳超时
3. 检查点与保存点
CheckpointCoordinator 负责进行检查点的发起,完成确认,检查点异常或者重复时取消本次检查点的执行
保存点由专业人士手动触发或者通过接口调用触发
4. 监控运维相关
反压跟踪 / 作业状态 / 作业各算子的吞吐量等监控指标
5. 心跳管理
JobMaster / ResourceManager / TaskManager 是3个分布式组件
- 相互之间通过网络进行通信,那么不可避免地会遇到各种导致无法通信的情况.
- 所以三者通过两两心跳相互感知对方,一旦出现心跳超时,则进入异常处理阶段,或是进行切换,或是进行资源清理
TaskManager
TaskManager 是 Flink 集群中负责执行计算任务的角色,其实现类是 TaskExecutorTaskExecutor 在生命周期中需要
- 对外 与
JobMaster / ResourceManager通信 - 对内需要管理
Task及其相关的资源/结果分区等
TaskManager 是 Task 的载体,负责
- 启动
- 执行
- 取消
Task - 在
Task异常时向JobManager汇报
TaskManager 作为 Task 执行者,为 Task 之间的数据交换提供基础框架
从集群资源管理的角度, TaskManager 是计算资源的载体,一个 TaskManager 通过 Slot 切分 CPU/内存等计算资源
一个 Flink 集群 的 TaskManager 的个数从几十个到上万个 为了实现 Exactly-Once 和容错,从整个集群的视角来看, JobManager 是检查点的协调管理者,TaskManager 是检查点的执行者
从集群管理的角度
TaskManager与JobMaster之间通过心跳保持相互感知- 与
ResourceManager保持心跳,汇报资源的使用情况,以便ResourceManager能够掌握全局资源的分布和剩余情况 - 集群内部的信息交换基于 Flink 的 RPC 通信框架
TaskManager 提供的数据交换基础框架,最重要的是跨网络的数据交换,内存管理的申请和分配以及其他需要在计算过程中 Task 共享的组件 , (ShufferEnvironment…)
Task
Task 是 Flink 作业的子任务,由 TaskManager 直接负责管理调度, 为 StreamTask 执行业务逻辑的时候提供基础的组件, 如 内存管理器 / IO 管理器 / 输入网关 / 文件缓存等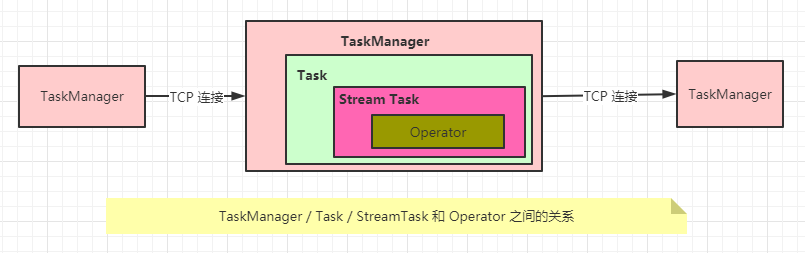
- 流计算 执行层面使用的是
StreamTask体系 - 批处理 执行层面使用的是
BatchTask体系
Task 所执行核心组件如下 :
TaskStateManager
- 负责
State整体协调,其中封装了CheckpointResponder, 在StreamTask中用来跟JobMaster交互,汇报检查点的状态
MemoryManager
Task通过该组件申请和释放内存
LibraryCacheManager
- 开发者开发的
Flink作业打包成jar提交给Flink集群 - 在
Task启动的时候需要从此组件远程下载所需的jar文件 - 在
Task的类加载器中加载,然后才能执行业务逻辑
InputSplitProvider
- 在数据源算子中,用来向
JobMaster请求分配数据集的分片,然后读取该分片的数据
ResultPartitionConsumableNotifier
- 结果分区可消费通知器,用来通知消费者生产的结果分区可消费
PartitionProducerStateChecker
- 分区状态检查器,用于检查生产端分区状态
TaskLocalStateStore
- 在
TaskManager本地提供State的存储,恢复作业的时候,优先从本地恢复,提高恢复速度 - 但是本地
State存储的方式可能因为硬盘问题丢失,所以如果不能从本地恢复,需要再从可靠分布式存储中恢复
IOManager
- IO 管理器 ,在批处理计算中 (如排序,Join 等场景) 遇到内存中无法放下所有数据的情况
IOManager就负责将数据溢出到磁盘,并在需要的时候将其读取回来
ShuffleEnvironment
- 数据交换的管理环境,其中包含了 数据写出 / 数据分区 的管理等组件
BroadcastVariableManager
- 广播变量管理器,
Task可以共享该管理器,通过引用计数跟踪广播变量的使用,没有使用的时候清除
TaskEventDispatcher
- 任务事件分发器,从消费者任务分发时间给生产者任务
StreamTask
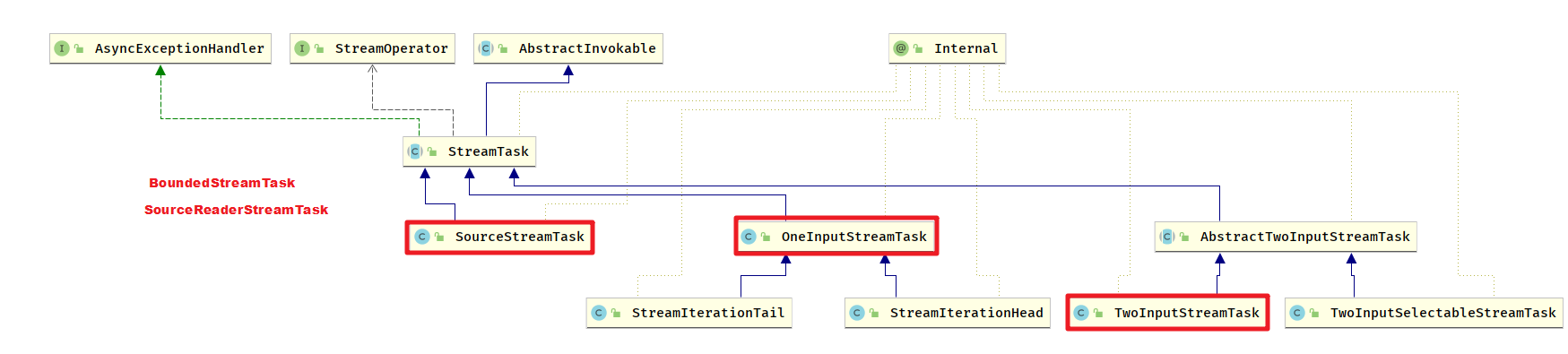
StreamTask 是 所有流计算作业子任务的执行逻辑的抽象基类,是算子的执行容器StreamTask 的类型与算子的类型—对应,
StreamTask 的实现分为几类
OneInputStreamTask
单个输入的 StreamTask , 对应于 OneInputStreamOperator
StreamIterationHeadStreamIterationTail- 其两个子类 用来执行迭代计算
TwoInputStreamTask
两个输入的 StreamTask , 对应于 TwoInputStreamOperator
SourceStreamTaskSourceStreamTask 是用在流模式的执行数据读取的 StreamTask
BoundedStreamTask
该 StreamTask 是用在模拟批处理的数据读取行为
SourceReaderStreamTaskSourceReaderStreamTask 用来执行 SourceReaderStreamOperator
StreamTask 的生命周期分3个阶段: 初始化 / 运行 / 关闭与清理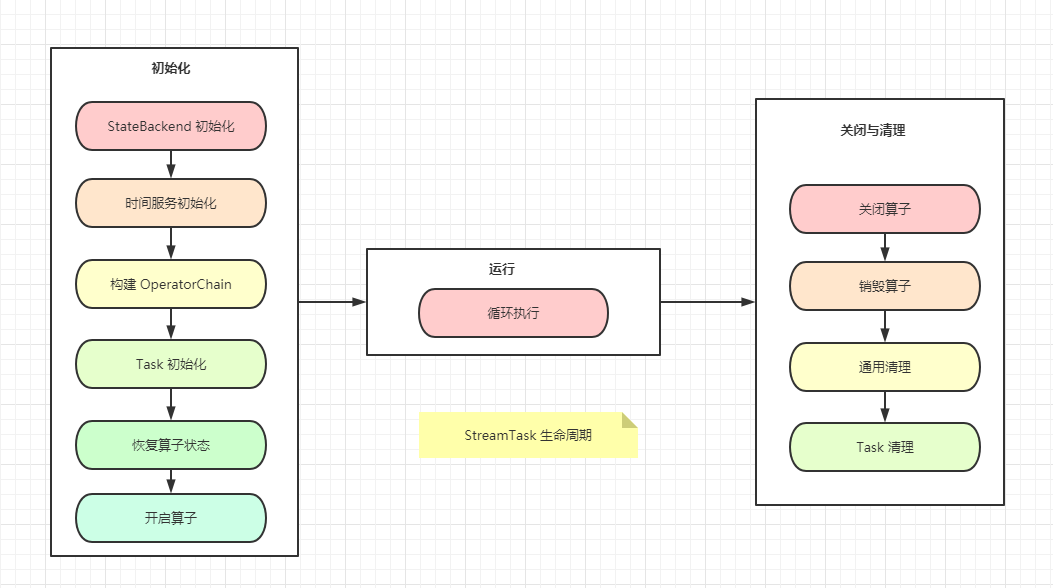
1. 初始化阶段
StateBackend初始化,—-> 实现 有状态计算和Exactly-Once的关键时间服务初始化,设置
Timer定时器, 此处的时间服务最终管理定时器的服务构建
OperatorChain实例化各个算子算子构建完毕,然后开始
Task的初始化, 根据Task类型的不同,其初始化策略有不同,
- 对于
SourceStreamTask而言,主要是启动SourceFunction开始读取数据,如果支持检查点,则开启检查点 - 对于
OneInputStreamTask和TwoInputStreamTask构建InputGate,包装到StreamTask的输入组件StreamTaskNetworkInput中,从上游StreamTask读取数据,构建Task的输出组件StreamTaskNetworkOutput,此处需要注意,StreamTask之间的数据传输关系由下游StreamTask负责建立数据传说通道,上游StreamTask只负责 写入内存 - 然后初始化
StreamInputProcessor将输入 (StreamTaskNetworkInput) / 算子处理数据 / 输出 (StreamTaskNetworkOutput) 关联起来, 形成StreamTask的数据处理的完整通道 - 之后设置监控指标,使之在运行时能够将各个监控数据域监控模块打通
- 对
OperatorChain中的所有算子恢复状态,
- 如果作业是从快照恢复的,就把算子恢复到上一次保存的快照状态
- 如果是无状态算子或者第一次执行,则无需恢复
- 算子状态恢复之后,开启算子,将
UDF函数加载 / 初始化进入执行状态
- 不同的算子会有一些特殊的初始化行为
2. 运行阶段
初始化 StreamTask 进入运行状态, StreamInputProcessor 持续读取数据,交给算子执行业务逻辑,然后输出
3. 关闭与清理阶段
当作业取消 / 异常 的时候,中止当前的 StreamTask 的执行, StreamTask 进入关闭与清理阶段
管理
OperatorChain中的所有算子,同时不再接受新的Timer定时器,处理完剩余的数据,将算子的数据强制清理销毁算子,销毁算子的时候 关闭
StateBackend和UDF通用清理,停止相关的执行线程
Task清理,关闭StreamInputProcessor本质上是关闭了StreamTaskInput, 清理InputGate/ 释放序列化器
作业启动
Flink 作业被提交之后, JobManager 中会为每个作业启动一个 JobMaster ,并将剩余的工作交给 JobMaster ,JobMaster 负责整个作业生命周期中的资源释放/调度/容错等细节
在作业启动过程中,JobMaster 会与 ResourceManager / TaskManager 频繁交互,经过一系列负责的过程之后,作业才真正的在 Flink 集群中运行起来,进入执行阶段 (开始读取/处理/写出数据的过程)
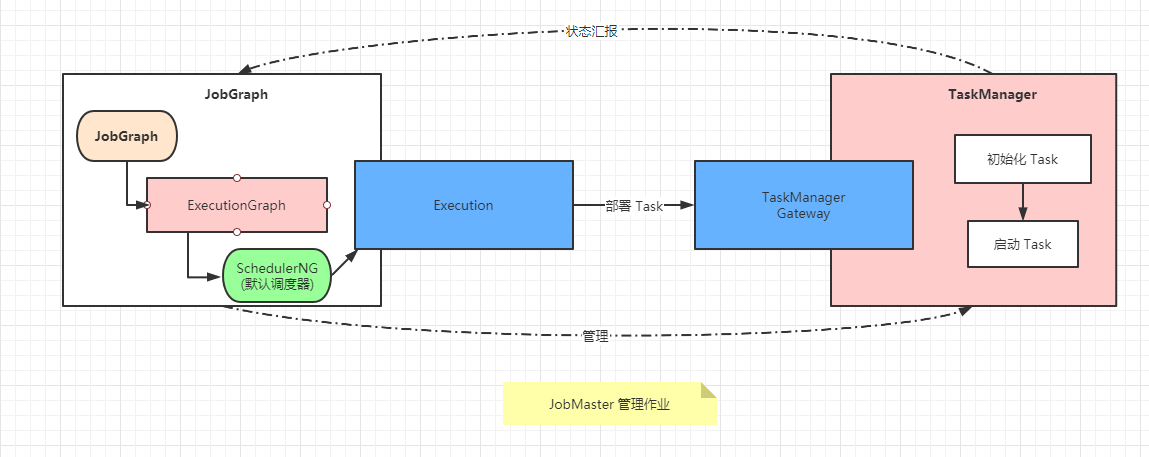
JobMaster 启动作业
作业启动涉及 JobMaster 和 TaskManager 两个位于不同进程的组件
在 JobMaster 中完成
- 作业图的转换并为作业申请资源
- 分配
Slot将作业的Task交给TaskManager
TaskManager 初始化和启动 Task ,通过 JobMaster 管理作业的取消/检查点保存等,Task 在执行过程中持续地向 JobMaster 汇报自身的状态,以便监控和异常时重启作业或者 Task
- JobMaster 启动调度
// JobMaster.Java
private void startScheduling() {checkState(jobStatusListener == null);// register self as job status change listener 将自身作为状态的监听器jobStatusListener = new JobManagerJobStatusListener();schedulerNG.registerJobStatusListener(jobStatusListener);schedulerNG.startScheduling();}
流作业启动调度
[x] 申请 Slot 部署 Task (
PipelinedRegionSchedulingStrategy)private void maybeScheduleRegions(final Set<SchedulingPipelinedRegion> regions) {final List<SchedulingPipelinedRegion> regionsSorted =SchedulingStrategyUtils.sortPipelinedRegionsInTopologicalOrder(schedulingTopology, regions);for (SchedulingPipelinedRegion region : regionsSorted) {maybeScheduleRegion(region);}}private void maybeScheduleRegion(final SchedulingPipelinedRegion region) {if (!areRegionInputsAllConsumable(region)) {return;}checkState(areRegionVerticesAllInCreatedState(region),"BUG: trying to schedule a region which is not in CREATED state");final List<ExecutionVertexDeploymentOption> vertexDeploymentOptions =SchedulingStrategyUtils.createExecutionVertexDeploymentOptions(regionVerticesSorted.get(region), id -> deploymentOption);// 流作业申请 Slot 部署 TaskschedulerOperations.allocateSlotsAndDeploy(vertexDeploymentOptions);}
[x] 流作业调度
- 部署所有 Task (
DefaultScheduler) ```java private BiFunctionfinal List<DeploymentHandle> deploymentHandles) {
return (ignored, throwable) -> {
propagateIfNonNull(throwable);
// 对所有的 Task 进行调用
for (final DeploymentHandle deploymentHandle : deploymentHandles) {
// 异步获取 Slot 获取完毕之后
final SlotExecutionVertexAssignment slotExecutionVertexAssignment = deploymentHandle
.getSlotExecutionVertexAssignment();
// CompletableFuture <1.8 新增的异步增强类>
final CompletableFuture<LogicalSlot> slotAssigned = slotExecutionVertexAssignment.getLogicalSlotFuture();
// 异步完成
checkState(slotAssigned.isDone());
// 异步部署 Task
FutureUtils.assertNoException(
slotAssigned.handle(deployOrHandleError(deploymentHandle)));
}
return null;
};
}
- [x] 部署 Task (`Execution`)
```java
public void deploy() throws JobException {
assertRunningInJobMasterMainThread();
final LogicalSlot slot = assignedResource;
checkNotNull(
slot,
"In order to deploy the execution we first have to assign a resource via tryAssignResource.");
// Check if the TaskManager died in the meantime
// This only speeds up the response to TaskManagers failing concurrently to deployments.
// The more general check is the rpcTimeout of the deployment call
if (!slot.isAlive()) {
throw new JobException("Target slot (TaskManager) for deployment is no longer alive.");
}
// make sure exactly one deployment call happens from the correct state
// note: the transition from CREATED to DEPLOYING is for testing purposes only
ExecutionState previous = this.state;
if (previous == SCHEDULED || previous == CREATED) {
//
if (!transitionState(previous, DEPLOYING)) {
// race condition, someone else beat us to the deploying call.
// this should actually not happen and indicates a race somewhere else
throw new IllegalStateException(
"Cannot deploy task: Concurrent deployment call race.");
}
} else {
// vertex may have been cancelled, or it was already scheduled
throw new IllegalStateException(
"The vertex must be in CREATED or SCHEDULED state to be deployed. Found state "
+ previous);
}
if (this != slot.getPayload()) {
throw new IllegalStateException(
String.format(
"The execution %s has not been assigned to the assigned slot.", this));
}
try {
// race double check, did we fail/cancel and do we need to release the slot?
if (this.state != DEPLOYING) {
slot.releaseSlot(
new FlinkException(
"Actual state of execution "
+ this
+ " ("
+ state
+ ") does not match expected state DEPLOYING."));
return;
}
LOG.info(
"Deploying {} (attempt #{}) with attempt id {} to {} with allocation id {} ",
vertex.getTaskNameWithSubtaskIndex(),
attemptNumber,
vertex.getCurrentExecutionAttempt().getAttemptId(),
getAssignedResourceLocation(),
slot.getAllocationId());
if (taskRestore != null) {
checkState(
taskRestore.getTaskStateSnapshot().getSubtaskStateMappings().stream()
.allMatch(
entry ->
entry.getValue()
.getInputRescalingDescriptor()
.equals(
InflightDataRescalingDescriptor
.NO_RESCALE)
&& entry.getValue()
.getOutputRescalingDescriptor()
.equals(
InflightDataRescalingDescriptor
.NO_RESCALE)),
"Rescaling from unaligned checkpoint is not yet supported.");
}
// 创建 Task 部署描述信息
final TaskDeploymentDescriptor deployment =
TaskDeploymentDescriptorFactory.fromExecutionVertex(vertex, attemptNumber)
.createDeploymentDescriptor(
slot.getAllocationId(),
slot.getPhysicalSlotNumber(),
taskRestore,
producedPartitions.values());
// null taskRestore to let it be GC'ed
taskRestore = null;
// TaskManager RPC 通信接口
final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway();
final ComponentMainThreadExecutor jobMasterMainThreadExecutor =
vertex.getExecutionGraph().getJobMasterMainThreadExecutor();
getVertex().notifyPendingDeployment(this);
// We run the submission in the future executor so that the serialization of large TDDs
// does not block
// the main thread and sync back to the main thread once submission is completed.
// 通过异步回调的方式,调用 TaskManagerGateway 的 RPC 通信接口 将 Task 发送给 TaskManager , 避免 TDD 作业描述信息太大,导致主线程阻塞.
CompletableFuture.supplyAsync(
() -> taskManagerGateway.submitTask(deployment, rpcTimeout), executor)
.thenCompose(Function.identity())
.whenCompleteAsync(
(ack, failure) -> {
if (failure == null) {
vertex.notifyCompletedDeployment(this);
} else {
if (failure instanceof TimeoutException) {
String taskname =
vertex.getTaskNameWithSubtaskIndex()
+ " ("
+ attemptId
+ ')';
markFailed(
new Exception(
"Cannot deploy task "
+ taskname
+ " - TaskManager ("
+ getAssignedResourceLocation()
+ ") not responding after a rpcTimeout of "
+ rpcTimeout,
failure));
} else {
markFailed(failure);
}
}
},
jobMasterMainThreadExecutor);
} catch (Throwable t) {
markFailed(t);
}
}
批作业调度
TaskManager 启动 Task
JobMaster 通过 TaskManagerGateway``.submit() RPC 接口将 Task 发送到 TaskManager 上, TaskManager 接收到 Task 的部署消息后,分为两个阶段执行
- 第一个阶段从部署消息中获取
Task执行所需要的信息- 初始化
Task然后触发Task的执行 Task完成一系列的初始化动作后- 进入
Task执行阶段
- 初始化
在部署和执行的过程中,
TaskExecutor与JobMaster保持交互,将Task的状态汇报给JobMaster, 并接受JobMaster的Task管理操作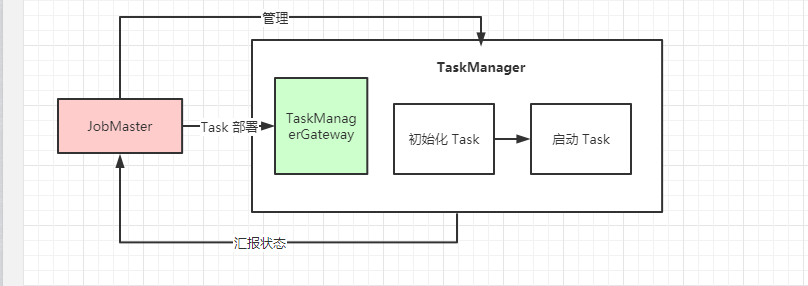
Task 启动**
(1) Task 部署
TaskManager的实现类是TaskExecutor,JobMaster将Task的部署信息封装为TaskDeploymentDescription对象, 通过SubmitTask消息发送给TaskExecutor, 而处理该消息的入口方法是submitTask方法.该方法的核心逻辑是初始化
Task, 在初始化Task的过程中,需要为Task生成核心组件,准备好Task的可执行文件.- 上边所有的核心组件的准备工作,目的都是实例化
Task
Task 在实例化的过程中,还进行了非常重要的准备工作.
- 在
ExecutionGraph中 每一个Execution对应一个Task,ExecutionEdge代表Task之间的数据交换关系,所以在Task的初始化中, 需要ExecutionEdge的数据交换关系落实到运行层面上. - 在这个过程中,最重要的是建立上下游之间的交换通道,以及
Task如何从上游读取,计算结果如果输出给下游. - 读取上游数据 只用
InputGate,结果写出使用ResultPartitionWriter. ResultPartitionWriter和InputGate的创建,销毁等管理由ShuffleEnvironment来负责ShuffleEnvironment底层数据存储对应的是Buffer一个
TaskManager只有一个ShuffleEnvironment所有 Task 共享@Override public CompletableFuture<Acknowledge> submitTask( TaskDeploymentDescriptor tdd, JobMasterId jobMasterId, Time timeout) { try { final JobID jobId = tdd.getJobId(); final ExecutionAttemptID executionAttemptID = tdd.getExecutionAttemptId(); final JobTable.Connection jobManagerConnection = jobTable.getConnection(jobId) .orElseThrow( () -> { final String message = "Could not submit task because there is no JobManager " + "associated for the job " + jobId + '.'; log.debug(message); return new TaskSubmissionException(message); }); if (!Objects.equals(jobManagerConnection.getJobMasterId(), jobMasterId)) { final String message = "Rejecting the task submission because the job manager leader id " + jobMasterId + " does not match the expected job manager leader id " + jobManagerConnection.getJobMasterId() + '.'; log.debug(message); throw new TaskSubmissionException(message); } if (!taskSlotTable.tryMarkSlotActive(jobId, tdd.getAllocationId())) { final String message = "No task slot allocated for job ID " + jobId + " and allocation ID " + tdd.getAllocationId() + '.'; log.debug(message); throw new TaskSubmissionException(message); } // re-integrate offloaded data: try { tdd.loadBigData(blobCacheService.getPermanentBlobService()); } catch (IOException | ClassNotFoundException e) { throw new TaskSubmissionException( "Could not re-integrate offloaded TaskDeploymentDescriptor data.", e); } // deserialize the pre-serialized information final JobInformation jobInformation; final TaskInformation taskInformation; try { jobInformation = tdd.getSerializedJobInformation() .deserializeValue(getClass().getClassLoader()); taskInformation = tdd.getSerializedTaskInformation() .deserializeValue(getClass().getClassLoader()); } catch (IOException | ClassNotFoundException e) { throw new TaskSubmissionException( "Could not deserialize the job or task information.", e); } if (!jobId.equals(jobInformation.getJobId())) { throw new TaskSubmissionException( "Inconsistent job ID information inside TaskDeploymentDescriptor (" + tdd.getJobId() + " vs. " + jobInformation.getJobId() + ")"); } TaskMetricGroup taskMetricGroup = taskManagerMetricGroup.addTaskForJob( jobInformation.getJobId(), jobInformation.getJobName(), taskInformation.getJobVertexId(), tdd.getExecutionAttemptId(), taskInformation.getTaskName(), tdd.getSubtaskIndex(), tdd.getAttemptNumber()); InputSplitProvider inputSplitProvider = new RpcInputSplitProvider( jobManagerConnection.getJobManagerGateway(), taskInformation.getJobVertexId(), tdd.getExecutionAttemptId(), taskManagerConfiguration.getTimeout()); final TaskOperatorEventGateway taskOperatorEventGateway = new RpcTaskOperatorEventGateway( jobManagerConnection.getJobManagerGateway(), executionAttemptID, (t) -> runAsync(() -> failTask(executionAttemptID, t))); TaskManagerActions taskManagerActions = jobManagerConnection.getTaskManagerActions(); CheckpointResponder checkpointResponder = jobManagerConnection.getCheckpointResponder(); GlobalAggregateManager aggregateManager = jobManagerConnection.getGlobalAggregateManager(); LibraryCacheManager.ClassLoaderHandle classLoaderHandle = jobManagerConnection.getClassLoaderHandle(); ResultPartitionConsumableNotifier resultPartitionConsumableNotifier = jobManagerConnection.getResultPartitionConsumableNotifier(); PartitionProducerStateChecker partitionStateChecker = jobManagerConnection.getPartitionStateChecker(); final TaskLocalStateStore localStateStore = localStateStoresManager.localStateStoreForSubtask( jobId, tdd.getAllocationId(), taskInformation.getJobVertexId(), tdd.getSubtaskIndex()); final JobManagerTaskRestore taskRestore = tdd.getTaskRestore(); final TaskStateManager taskStateManager = new TaskStateManagerImpl( jobId, tdd.getExecutionAttemptId(), localStateStore, taskRestore, checkpointResponder); MemoryManager memoryManager; try { memoryManager = taskSlotTable.getTaskMemoryManager(tdd.getAllocationId()); } catch (SlotNotFoundException e) { throw new TaskSubmissionException("Could not submit task.", e); } Task task = new Task( jobInformation, taskInformation, tdd.getExecutionAttemptId(), tdd.getAllocationId(), tdd.getSubtaskIndex(), tdd.getAttemptNumber(), tdd.getProducedPartitions(), tdd.getInputGates(), tdd.getTargetSlotNumber(), memoryManager, taskExecutorServices.getIOManager(), taskExecutorServices.getShuffleEnvironment(), taskExecutorServices.getKvStateService(), taskExecutorServices.getBroadcastVariableManager(), taskExecutorServices.getTaskEventDispatcher(), externalResourceInfoProvider, taskStateManager, taskManagerActions, inputSplitProvider, checkpointResponder, taskOperatorEventGateway, aggregateManager, classLoaderHandle, fileCache, taskManagerConfiguration, taskMetricGroup, resultPartitionConsumableNotifier, partitionStateChecker, getRpcService().getExecutor()); taskMetricGroup.gauge(MetricNames.IS_BACKPRESSURED, task::isBackPressured); log.info( "Received task {} ({}), deploy into slot with allocation id {}.", task.getTaskInfo().getTaskNameWithSubtasks(), tdd.getExecutionAttemptId(), tdd.getAllocationId()); boolean taskAdded; try { taskAdded = taskSlotTable.addTask(task); } catch (SlotNotFoundException | SlotNotActiveException e) { throw new TaskSubmissionException("Could not submit task.", e); } if (taskAdded) { task.startTaskThread(); setupResultPartitionBookkeeping( tdd.getJobId(), tdd.getProducedPartitions(), task.getTerminationFuture()); return CompletableFuture.completedFuture(Acknowledge.get()); } else { final String message = "TaskManager already contains a task for id " + task.getExecutionId() + '.'; log.debug(message); throw new TaskSubmissionException(message); } } catch (TaskSubmissionException e) { return FutureUtils.completedExceptionally(e); } }
(2) 启动 Task
- 上一个阶段中,
TaskExecutor准备好了Task, 然后进入Task调度阶段,在这个阶段中Task被分配到单独的线程中,循环执行. Task是容器,其中StreamTask才是 用户逻辑执行的起点,在Task中通过反射机制实例化StreamTask的子类,触发StreamTask.invoke()启动真正的业务逻辑的执行Task本身是一个Runnable对象, 由TaskMamager管理和调度,最终启动算子的逻辑封装在StreamTask和BatchTask中, 线程启动后 进入run()方法**private void doRun() { // ---------------------------- // Initial State transition // TODO 处理 Task 的状态变化 // ---------------------------- while (true) { ExecutionState current = this.executionState; if (current == ExecutionState.CREATED) { if (transitionState(ExecutionState.CREATED, ExecutionState.DEPLOYING)) { // success, we can start our work break; } } else if (current == ExecutionState.FAILED) { // we were immediately failed. tell the TaskManager that we reached our final state notifyFinalState(); if (metrics != null) { metrics.close(); } return; } else if (current == ExecutionState.CANCELING) { if (transitionState(ExecutionState.CANCELING, ExecutionState.CANCELED)) { // we were immediately canceled. tell the TaskManager that we reached our final // state notifyFinalState(); if (metrics != null) { metrics.close(); } return; } } else { if (metrics != null) { metrics.close(); } throw new IllegalStateException( "Invalid state for beginning of operation of task " + this + '.'); } } // all resource acquisitions and registrations from here on // need to be undone in the end Map<String, Future<Path>> distributedCacheEntries = new HashMap<>(); AbstractInvokable invokable = null; try { // ---------------------------- // Task Bootstrap - We periodically // check for canceling as a shortcut // ---------------------------- // activate safety net for task thread LOG.debug("Creating FileSystem stream leak safety net for task {}", this); FileSystemSafetyNet.initializeSafetyNetForThread(); // first of all, get a user-code classloader // this may involve downloading the job's JAR files and/or classes LOG.info("Loading JAR files for task {}.", this); // TODO 创建用户自定义的 ClassLoader,避免不同 Job 在相同的 JVM 中执行时的 Jar 版本冲突 userCodeClassLoader = createUserCodeClassloader(); final ExecutionConfig executionConfig = serializedExecutionConfig.deserializeValue(userCodeClassLoader.asClassLoader()); if (executionConfig.getTaskCancellationInterval() >= 0) { // override task cancellation interval from Flink config if set in ExecutionConfig taskCancellationInterval = executionConfig.getTaskCancellationInterval(); } if (executionConfig.getTaskCancellationTimeout() >= 0) { // override task cancellation timeout from Flink config if set in ExecutionConfig taskCancellationTimeout = executionConfig.getTaskCancellationTimeout(); } if (isCanceledOrFailed()) { throw new CancelTaskException(); } // ---------------------------------------------------------------- // register the task with the network stack // this operation may fail if the system does not have enough // memory to run the necessary data exchanges // the registration must also strictly be undone // ---------------------------------------------------------------- LOG.info("Registering task at network: {}.", this); // TODO 初始化 Partition / InputGate 并注册 Partition setupPartitionsAndGates(consumableNotifyingPartitionWriters, inputGates); for (ResultPartitionWriter partitionWriter : consumableNotifyingPartitionWriters) { taskEventDispatcher.registerPartition(partitionWriter.getPartitionId()); } // next, kick off the background copying of files for the distributed cache try { for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry : DistributedCache.readFileInfoFromConfig(jobConfiguration)) { LOG.info("Obtaining local cache file for '{}'.", entry.getKey()); Future<Path> cp = fileCache.createTmpFile( entry.getKey(), entry.getValue(), jobId, executionId); distributedCacheEntries.put(entry.getKey(), cp); } } catch (Exception e) { throw new Exception( String.format( "Exception while adding files to distributed cache of task %s (%s).", taskNameWithSubtask, executionId), e); } if (isCanceledOrFailed()) { throw new CancelTaskException(); } // ---------------------------------------------------------------- // call the user code initialization methods // ---------------------------------------------------------------- TaskKvStateRegistry kvStateRegistry = kvStateService.createKvStateTaskRegistry(jobId, getJobVertexId()); // TODO 初始化用户代码 Environment env = new RuntimeEnvironment( jobId, vertexId, executionId, executionConfig, taskInfo, jobConfiguration, taskConfiguration, userCodeClassLoader, memoryManager, ioManager, broadcastVariableManager, taskStateManager, aggregateManager, accumulatorRegistry, kvStateRegistry, inputSplitProvider, distributedCacheEntries, consumableNotifyingPartitionWriters, inputGates, taskEventDispatcher, checkpointResponder, operatorCoordinatorEventGateway, taskManagerConfig, metrics, this, externalResourceInfoProvider); // Make sure the user code classloader is accessible thread-locally. // We are setting the correct context class loader before instantiating the invokable // so that it is available to the invokable during its entire lifetime. // TODO 设置线程的 ClassLoader 避免不同 Job 的 Jar 冲突 executingThread.setContextClassLoader(userCodeClassLoader.asClassLoader()); // now load and instantiate the task's invokable code // TODO 加载业务逻辑执行代码,并赋予 RuntimeEnvironment invokable = loadAndInstantiateInvokable( userCodeClassLoader.asClassLoader(), nameOfInvokableClass, env); // ---------------------------------------------------------------- // actual task core work // ---------------------------------------------------------------- // we must make strictly sure that the invokable is accessible to the cancel() call // by the time we switched to running. // TODO 核心逻辑,启动 StreamTask 执行 this.invokable = invokable; // switch to the RUNNING state, if that fails, we have been canceled/failed in the // meantime // TODO 从 DEPLOYING切换到 RUNNING 状态 if (!transitionState(ExecutionState.DEPLOYING, ExecutionState.RUNNING)) { throw new CancelTaskException(); } // notify everyone that we switched to running // TODO 通知相关组件,Task 进入 Running 状态 taskManagerActions.updateTaskExecutionState( new TaskExecutionState(jobId, executionId, ExecutionState.RUNNING)); // make sure the user code classloader is accessible thread-locally // TODO 设置执行线程的 ClassLoader executingThread.setContextClassLoader(userCodeClassLoader.asClassLoader()); // run the invokable // TODO 启动业务逻辑的执行,执行线程中循环执行 invokable.invoke(); // make sure, we enter the catch block if the task leaves the invoke() method due // to the fact that it has been canceled if (isCanceledOrFailed()) { throw new CancelTaskException(); } // ---------------------------------------------------------------- // finalization of a successful execution // ---------------------------------------------------------------- // finish the produced partitions. if this fails, we consider the execution failed. // TODO 把尚未写出给下游的数据统一 Flush , 如果失败的话,Task 也会失败 for (ResultPartitionWriter partitionWriter : consumableNotifyingPartitionWriters) { if (partitionWriter != null) { partitionWriter.finish(); } } // try to mark the task as finished // if that fails, the task was canceled/failed in the meantime // TODO Task 正常执行完毕,迁移到 Finished 状态 if (!transitionState(ExecutionState.RUNNING, ExecutionState.FINISHED)) { throw new CancelTaskException(); } } catch (Throwable t) { // TODO 异常处理,取消 StreamTask 执行,切换状态到 Failed ,如果无法处理,则报告致命错误 // unwrap wrapped exceptions to make stack traces more compact if (t instanceof WrappingRuntimeException) { t = ((WrappingRuntimeException) t).unwrap(); } // ---------------------------------------------------------------- // the execution failed. either the invokable code properly failed, or // an exception was thrown as a side effect of cancelling // ---------------------------------------------------------------- TaskManagerExceptionUtils.tryEnrichTaskManagerError(t); try { // check if the exception is unrecoverable if (ExceptionUtils.isJvmFatalError(t) || (t instanceof OutOfMemoryError && taskManagerConfig.shouldExitJvmOnOutOfMemoryError())) { // terminate the JVM immediately // don't attempt a clean shutdown, because we cannot expect the clean shutdown // to complete try { LOG.error( "Encountered fatal error {} - terminating the JVM", t.getClass().getName(), t); } finally { Runtime.getRuntime().halt(-1); } } // transition into our final state. we should be either in DEPLOYING, RUNNING, // CANCELING, or FAILED // loop for multiple retries during concurrent state changes via calls to cancel() // or // to failExternally() while (true) { ExecutionState current = this.executionState; if (current == ExecutionState.RUNNING || current == ExecutionState.DEPLOYING) { if (t instanceof CancelTaskException) { if (transitionState(current, ExecutionState.CANCELED)) { cancelInvokable(invokable); break; } } else { if (transitionState(current, ExecutionState.FAILED, t)) { // proper failure of the task. record the exception as the root // cause failureCause = t; cancelInvokable(invokable); break; } } } else if (current == ExecutionState.CANCELING) { if (transitionState(current, ExecutionState.CANCELED)) { break; } } else if (current == ExecutionState.FAILED) { // in state failed already, no transition necessary any more break; } // unexpected state, go to failed else if (transitionState(current, ExecutionState.FAILED, t)) { LOG.error( "Unexpected state in task {} ({}) during an exception: {}.", taskNameWithSubtask, executionId, current); break; } // else fall through the loop and } } catch (Throwable tt) { String message = String.format( "FATAL - exception in exception handler of task %s (%s).", taskNameWithSubtask, executionId); LOG.error(message, tt); notifyFatalError(message, tt); } } finally { // TODO 释放内存 占用的 Cache ,并进入 Final 状态 停止监控 try { LOG.info("Freeing task resources for {} ({}).", taskNameWithSubtask, executionId); // clear the reference to the invokable. this helps guard against holding references // to the invokable and its structures in cases where this Task object is still // referenced this.invokable = null; // free the network resources releaseResources(); // free memory resources if (invokable != null) { memoryManager.releaseAll(invokable); } // remove all of the tasks resources fileCache.releaseJob(jobId, executionId); // close and de-activate safety net for task thread LOG.debug("Ensuring all FileSystem streams are closed for task {}", this); FileSystemSafetyNet.closeSafetyNetAndGuardedResourcesForThread(); notifyFinalState(); } catch (Throwable t) { // an error in the resource cleanup is fatal String message = String.format( "FATAL - exception in resource cleanup of task %s (%s).", taskNameWithSubtask, executionId); LOG.error(message, t); notifyFatalError(message, t); } // un-register the metrics at the end so that the task may already be // counted as finished when this happens // errors here will only be logged try { metrics.close(); } catch (Throwable t) { LOG.error( "Error during metrics de-registration of task {} ({}).", taskNameWithSubtask, executionId, t); } } }
Stream Task 启动
StreamTask是算子的执行容器,在JobGraph中将算子连接在一起进行了优化,在执行层面上对应的是OperatorChain.在
Task启动之前无论是单个算子还是连接在一起的一组算子,都会首先被构造成OperatorChain,构造OperatorChain的过程中,包含了算子的实例化,同时也构造了算子的输出 (Output)[x] 一个算子的
OperatorChain
算子输出计算结果的时候,包含了两层 Output ,其中
CountingOutPut用来统计算子的输出数据元素个数RecordWriterOutput用来序列化数据, 写入NetworkBuffer,交给下游算子
同时计算两个监控指标
- 向下游发送的字节总数
向下游发送的
Buffer总数[x] 多个算子
OperatorChain
两个或以上算子构成的 OperatorChain ,算子之间包含了两层 Output
- 其中
CountingOutput用来统计上游算子 输出的数据元素个数 ChaingOutPut提供了Watermark的统计和下游算子 输入数据元素个数
Task 启动完毕之后,就进入了作业执行的阶段
作业停止
当作业执行完毕 (批处理作业),执行失败无法恢复时就会进入停止状态
当然也有手动停止作业的场景,此时作业都会进入停止状态
- 集群升级
- 作业升级
- 作业迁移
- 故障转移
- …
与作业的启动相比,作业的停止要简单许多,主要是资源的德清理和释放
JobMaster向所有的TaskManager发出取消作业的指令,TaskManager执行Task的取消指令,进行相关的内存资源的清理,当所有的清理作业完成之后,向JobMaster发出通知JobMaster停止,向ResourceManager归还所有的Slot资源,然后彻底退出作业的执行
作业失败调度
Flink 作为低延迟的分布式计算引擎,在流计算中引入了分布式快照容错机制,以满足低延迟和高吞吐的要求
Flink 所使用的容错机制使用分布式快照保存作业状态,与 Flink 的作业恢复机制相结合,确保数据不丢失,不重复处理.发生错误时,Flink 作业能够根据重启策略自动从最近一次成功的快照中恢复状态
Flink 对作业失败的原因归纳定义 有如下 4 种类型
NonRecoverableError
- 不可恢复的错误
- 此类错误意味着即使重启也无法恢复作业到正常状态,一旦发生此类错误,则作业执行失败,直接退出作业执行
PartitionDataMissingError
- 分区数据不可访问错误
- 下游
Task无法读取上游Task的产生的数据,需要重启上游的Task
EnvironmentError
- 环境的错误,问题本身来自机器硬件,外部服务等
- 这种情况需要在调度策略上进行改进 (排除有问题的机器,服务,避免将失败的
Task重新调度到这些机器上)
RecoverableError
- 可恢复的错误
目前 Flink 有两套调度策略
默认的作业失败调度和遗留的作业失败调度- 默认的作业失败调度: Flink 1.9.0 及以后版本的调度策略
- 遗留的作业调度: Flink 1.9.0 版本之前的调度策略
默认作业失败调度 <1.9.0 ↑>
在错误发生时,首先会尝试对作业进行局部恢复,如果无法恢复或者局部恢复失败,则会将整个作业进行重启,从保存快照中恢复
默认失败调度集成在 默认调度器 DefaultScheduleduler , 具体的调度行为 代理给 ExecutionGraph 来实现
在运行时, Task 是 Flink 作业的最小执行单位,一个作业有不定数量的 Task 取决于计算逻辑的复杂性和并行度,
在 DefaultScheduleduler 的恢复策略中 , Task 错误恢复策略
RestartAllStrategy
- 若
Task发生异常,则重启所有的Task,恢复成本高,但这是 恢复作业一致性的最安全策略
RestartIndividualStrategy
- 分区恢复策略,若
Task发生异常,则重启该分区的所有Task,恢复成本低,实现逻辑复杂
Flip1 引入的作业 Failover 机制,将整个作业的物理执行拓扑 Task DAG 切分为不同的 FailoverRegion.FailoverRegion 本质上是一组有相互关系的 Task ,失败恢复的时候按照 FailoverRegion 回溯,重新启动需要启动的 Task
1. FailoverRegion 切分
实现细粒度的 Failover , 首先需要对作业进行 FailoverRegion 的切分,具体切分策略有
- 带有
CoLocation限制的作业
- 在目前实现中,带有
CoLocation限制的作业不切分,所有的Task都位于同一个FailoverRegion - 若一个
Task发生了错误,全部Task都要重启
- 按照
ResultPartitionType纵向切分
- 纵向是指数据流转方向,以
Task间的数据传递方式来确定FailoverRegion的边界 - 简单理解 就是以
Shuffle作为边界
- 按照上下游的数据依赖关系横向切分
- 横向相互没有依赖关系的
Task隶属于不同的分区,没有相互依赖的Task可以相互独立恢复
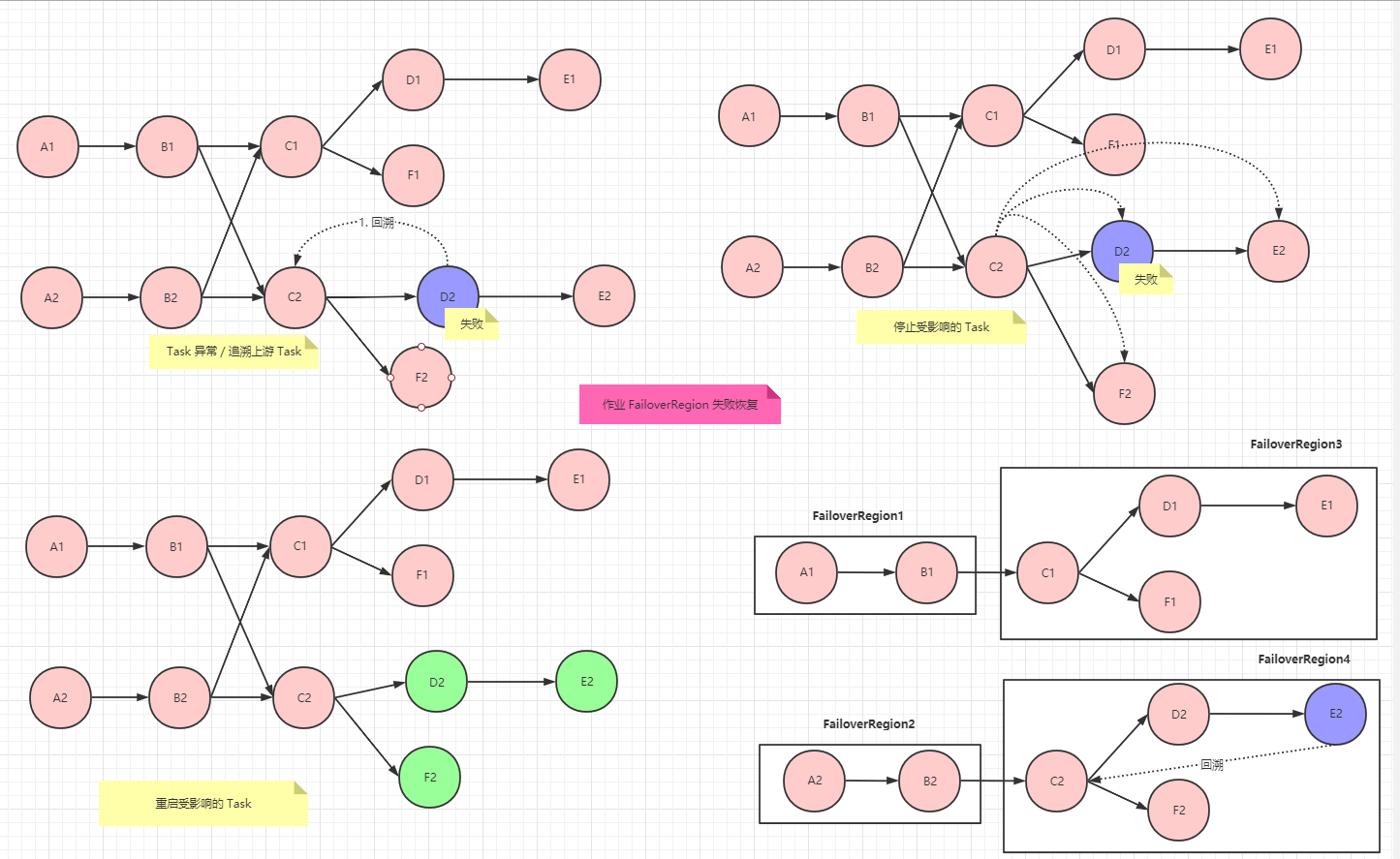
2. 作业恢复时的 FailoverRegion 回溯
假设 Task C1 由于错误执行失败,那么需要重新调度执行的 FailoverRegion 分析步骤如下
- Task 所在的
FailoverRegion整体恢复
- 由于
FailoverRegion内的Task被视作一个整体,因此FailoverRegion中的任何一个Task执行失败,整个FailoverRegion中的Task都需要恢复,重新调度执行
- 判断是否需要重新调度上游
- 对于 C1 的上游 B 而言,如果 B 的
ResultPartition是重复消费的,并且目前任然是可用的,那么 B 就无需重新调度 - 如果 B 的结果分区
ResultPartition已被销毁了,那么 B 就需要重新调度 - 此时对于 B 而言,需要与步骤1 中一行,递归地向上分析 A 是否重新调度执行
- …
- 下游
FailoverRegion分析
- D1 , D2 所在的
FailoverRegion与 C1 所在的FailoverRegion共同消费 B 的结果分区,如果要重新调度 B, 需要分析 B 的下游是否需要重新调度 此时需要注意 , D1 可能存在 3 种情况
- 情况1 :
Task D1正在执行, B 的结果分区ResultPartition可访问,此情况下 D1 无序重新调度, B 的结果分区可以继续访问情况2:
Task D正在执行, B 的结果分区ResultPartition不可访问,此种情况下, D1 需要重新调度执行,D1 所在的整个FailoverRegion也需要重新调度情况3:
Task D1执行完毕, D1 已经整个执行完毕,无论 B 的ResultPartition是否可以访问,都不影响Task D1以及以后的Task
以上情况,对于兄弟
FailoverRegion(D1 所在的FailoverRegion) 情况 2 需要重新调度,情况1,3 无需重新调度- 但是情况 1,3 恢复策略保证结果正确有一个前提条件,
Task B产生的结果集分区ResultPartition是确定的,无论执行多少次,结果集都是一致的
- 但是情况 1,3 恢复策略保证结果正确有一个前提条件,
因为事先无法确定结果 B 的结果分区
ResultPartition是确定的还是非确定的,所以默认情况下,只要 B 被重新调用了, 下游Task所在的FailoverRegion也需要被重新调度,
3. Failover 过程
遗留的作业失败调度 <1.9.0 ↓>
组件容错
对于分布式系统来说,守护线程的容错是基本要求而且已经比较成熟,基本包括故障检测和故障恢复两个部分
- 故障检测通常通过心跳的方式来实现,心跳可以在内部组件间实现或者依赖与
Zookeepr等外部服务 - 故障恢复则通常要求将状态持久化到外部存储,然后在故障出现时用于初始化新的进程
最为常用的 Yarn 的部署模式为例,Flink 的关键守护进程有 JobManager 和 TaskManager 两个,其中 JobManager 的主要职责
- 协调资源 —->
ResourceManager - 管理作业执行 —->
JobMaster
在容错方面, 3 个角色两两之间相互发送心跳来进行共同的故障检测
- 在 HA 场景下,
ResourceManager和JobMaster都会注册到Zookeeper节点上以实现Leader锁
容错设计
Flink 中 Dispatcher / JobMaster / ResourceManager / TaskManager 都是非常重要的组件,所以需要高可用设计.使组件具备容错能力,防止单个组件故障导致整个集群宕机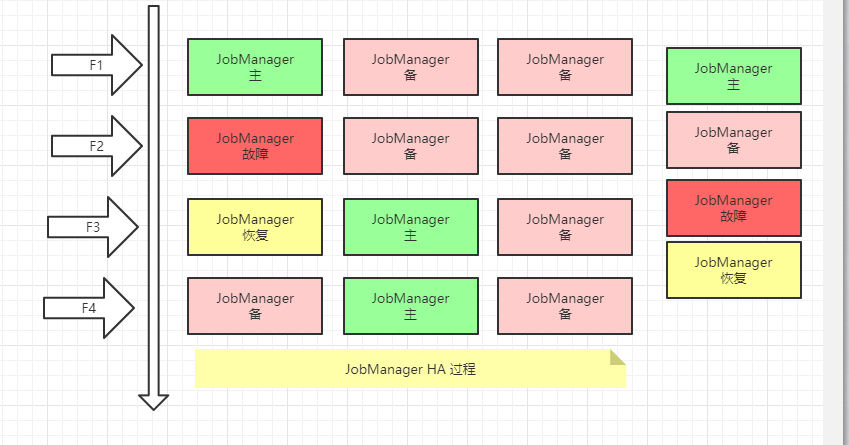
HA 服务
容错的基本原理是提供两个或以上的相同组件,选择其中一个作为 Leader , 其他的作为备选,当 Leader 出现问题的时候,各备选组件能够感知到 Leader 宕机 , 重新选举 并通知相关组件新的 Leader
leader 服务 (选举服务/变更服务)
对于 JobMaster 和 ResourceManager, Leader 选举服务和 Leader 变更服务是两项基本服务
- 前者用于切换到新的
Leader - 后者用于通知相关组件
Leader的变化,进行相应的处理
- Leader 选举服务
Leader选举最重要的行为是为竞争者提供选举和确认Leader

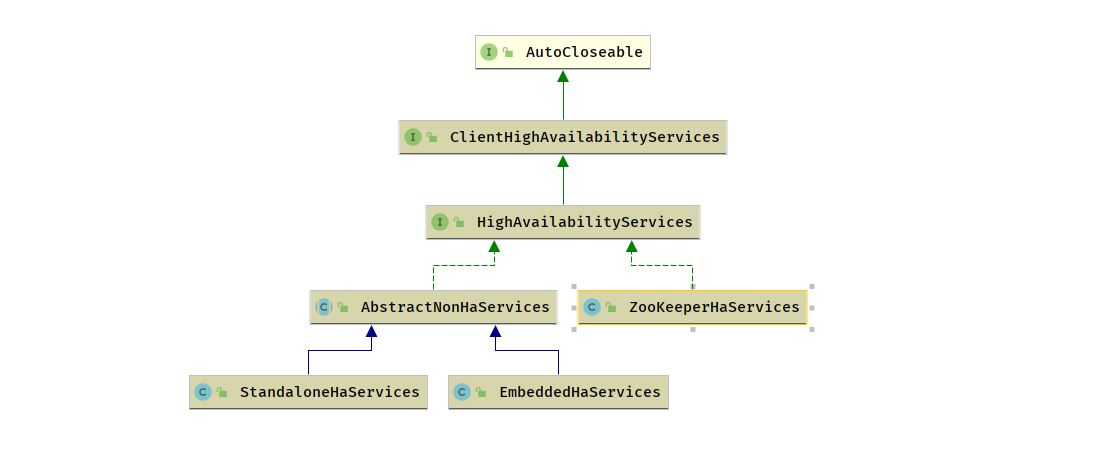
ZooKeeperLeaderElectionService : 基于 Zookeeper 的选举服务StandaloneLeaderElectionService : 没有 Zookeeper 情况下的选举EmbeddedLeaderElectionService : 内嵌的轻量级选举服务,在 Flink Local 模式中,主要用来本地代码调试和单元测试
- Leader 变更服务
HA 模式下出现组件故障,会进行新的 Leader 选举,选择主节点 选择完毕之后要通知其他的组件,LeaderRetrievalService 接口 —> 查找新的 Leader 节点的服务
LeaderRetrievalListener 用来通知选举了新的 Leader , 在选举过程中可能顺利选举出新的 Leader , 也可能因为内部或者外部异常 导致无法选举出新的 Leader ,此时也需要通知各相关组件
对于无法处理的故障,无法尽心恢复,作业进入停止状态LeaderRetrievalListener Code
public interface LeaderRetrievalListener {
// Leader 选举服务选举出新的 Leader, 通知其他相关组件
void notifyLeaderAddress(@Nullable String leaderAddress, @Nullable UUID leaderSessionID);
// 当 Leader 选举服务发生异常的时候通知各相关组件
void handleError(Exception exception);
}
心跳服务
心跳机制是分布式集群中组件监控的常用手段,Flink 各个组件的监控统一使用心跳机制来实现
一个完整的心跳机制需要有心跳的发送者和接收者两个实体
- 心跳目标 (
HeartbeatTarget)
- 心跳目标,用来表示心跳发送者和心跳接受者,同一个组件即时发送者也是接收者
public interface HeartbeatTarget<I> { // 接收监控目标发来的心跳请求信息 void receiveHeartbeat(ResourceID heartbeatOrigin, I heartbeatPayload); // 向监控目标发送心跳请求 void requestHeartbeat(ResourceID requestOrigin, I heartbeatPayload); }
- 心跳管理器 (
HeartbeatManager)
通用的心跳管理器用来启动或者停止监视
HeartbeatTarget,并报告该目标心跳超时事件,通过monitorTarget来传递并监控HeartbeatTarget,这个方法可以看成整个服务的输入,告诉心跳服务去管理哪些目标public interface HeartbeatManager<I, O> extends HeartbeatTarget<I> { // 开始监控心跳目标,若目标心跳超时,会报告给与 HeartbeatManager关联的 HeartbeatListener void monitorTarget(ResourceID resourceID, HeartbeatTarget<O> heartbeatTarget); // 取消监控心跳目标,ResourceID 被监控目标组件标识 void unmonitorTarget(ResourceID resourceID); // 停止当前心跳管理 void stop(); // 返回最近一次心跳时间,如果心跳目标被移除了则返回 -1 long getLastHeartbeatFrom(ResourceID resourceId); }在
JobManager / ResourceManager / TaskManager中 使用HeartbeatManager进行两两心跳监控
- 心跳监听器 (
HeartbeatListener)
心跳监控器是 HeartbeatManager 密切相关的接口,可以看成服务的输出,主要有以下作用
- 心跳超时通知
- 接收心跳信息中的 Payload
检索作为心跳相应输出的 Payload ```java public interface HeartbeatListener
// 心跳超时会调用该方法 void notifyHeartbeatTimeout(ResourceID resourceID);
// 接收到有关心跳的 Payload 就会 执行该方法 void reportPayload(ResourceID resourceID, I payload);
// 检索下一个心跳信息的 Payload O retrievePayload(ResourceID resourceID); }
```
JobMaster / ResourceManager / TaskManager都实现了该接口,心跳超时时触发异常处理
HA 服务
ZooKeeperHaServices
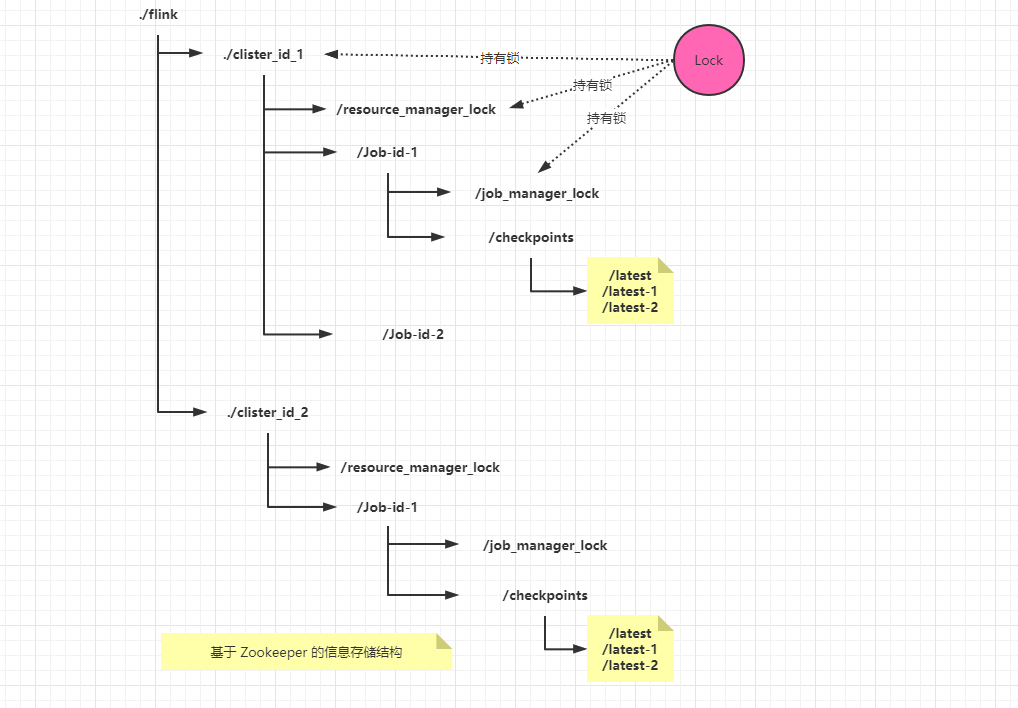
基于 Zookeeper 的高可用服务,Zookeeper 文件存储目录结构
- 集群级别有
ResourceManager的Leader锁 (/**resource_manager_lock**) - 作业级别有
JobMaster的Leader锁 (/**job_manager_lock**) - 在作业级别还保存了作业的最新检查点信息 (元信息/路径/时间等) —> 便于恢复时从最新的检查点恢复
StandaloneHaServices
- 基于内存和本地文件系统实现高可用服务,能在一定程度上实现高可用,在物理硬件故障的情况下,可能无法达到高可用的预期
EmbeddedHaServices
- 在 Flink 的 Local 模式中实现高可用服务,为了实现 Flink 的完整作业流程而实现的模拟服务
JobMaster 的容错
JobMaster 作为 Job 的管理节点, 负责 Job 的调度, 该组件故障会影响 Job 的运行,在 ResourceManager 和 TaskManager 中都与 JobMaster 保持心跳
1. TaskManager 应对 JobMaster 故障
TaskManager 通过心跳超时检测到 JobMaster 故障,或者收到 Zookeeper 的 JobMaster 节点失去 Leader 角色的通知时,就会触发超时的异常处理
TaskManager根据该JobMaster管理的 Job 的 ID, 将该TaskManager上所有隶属于该 Job 的Task取消执行Task进入 Failed 状态,但是仍然保留为 Job 分配的Slot一段时间,然后尝试连接新的JobMaster Leader- 如果新的
JobMaster超过了等待时间仍然没有连接上,TaskManager不再等待,标记Slot为空闲并通知ResourceManager ResourceManager在下一次的 Job 调度执行中分配这些Slot资源
2. ResourceManager 应对 JobMaster 故障
ResourceManager 通过心跳超时检测到 JobMaster 故障,或者收到 Zookeeper 的关于 JobMaster 失去 Leader 的通知时, ResourceManager 会通知 JobMaster 重新尝试连接, 其他不做处理
3. JobMaster 切换
JobMaster 保存了对作业执行至关重要的状态和数据
JobGraph/ 用户的 Jar 包. 配置文件 检查点数据等保存在配置的分布式可靠存储中- 检查点访问信息保存在 Zookeeper 中
JobMaster 出现故障之后要选举新的 JobMaster Leader
- 新的
Leader选举出来之后,会通知ResourceManager和TaskManager
JobMaster 的 首要任务是重新调度 Job
- 如果
Slot还没有被TaskManager释放掉,TaskManager向ResourceManager发送的心跳信息中告知资源的使用情况和当前的Slot属于哪个Job ID, JobMaster直接向ResourceManager申请,ResourceManager无需重新申请新的Slot
ResourceManager 容错
ResourceManager 负责 Job 资源的管理,ResourceManager 上维护着很多重要信息
- 可用的
TaskManager清单 等
这些信息是在内存中进行维护的,并不会持久化到存储上
JobMaster / TaskManager向ResourceManager发送心跳的过程中,心跳数据中心带有这些信息,很快就会将状态同步到ResouceManager中
在设计上, ResourceManager 的故障不会中断 Task 的执行,但是无法启动新的 Task (无法与 SlotManager 产生联系)
1. JobMaster 应对 ResourceManager 故障
JobMaster 通过心跳超市检测到 ResourceManager 故障 ,导致故障的原因有很多
- 简单的网络延迟问题
- 硬件问题?
在 HA 部署模式下,不会有新的 ResourceManager Leader 出现,所以 JobMaster 会首先尝试重新连接 ResourceManager
如果一直没有连接上,JobMaster 通过 Leader 选举通知的到新的 ResourceManager 地址,通过该地址重新与 ResourceManager 连接
在最后实在无法与 ResourceManager 取得联系的情况下,则整个集群就会停止
2. TaskManager 应对 ResourceManager 故障
TaskManager 通过心跳检测到 ResourceManager 的故障,同样也会首先尝试重新连接
如果一直没有连接成功,在 HA 模式下.选举出了新的 ResourceManager Leader
TaskManager也会得到通知,然后TaskManager会与新的ResourceManager取得连接,将自己注册到新的ResourceManager,并将其自身的状态同步到ResourceManager
在最后实在无法与 ResourceManager 取得连接的情况下,集群无法恢复到正常运行的状态,集群同样会停止
TaskManager 的容错
TaskManager 是集群的计算执行者,其上执行了一个或者多个 Job 的 Task
1. ResourceManager 应对 TaskManager 故障
ResourceManager 通过心跳超时检测到 TaskManager 故障,它会通知对应的 JobMaster 并启动一个新的 TaskManager 作为代替
ResourceManager 不会关心 Flink 作业的情况 , 它只管理 资源的分配, 管理 Flink 作业 要做何种反应是 JobMaster 的职责
2. JobMaster 应对 TaskManager 故障
JobMaster 通过心跳超时检测到 TaskManager 故障, 它首先会从自身的 Slot Pool 中移除该 TaskManager ,并释放该 TaskManager 的 Slot ,最终会触发 Execution 的异常处理,然后触发 Job 级别的恢复,从而重新申请资源,由 ResourceManager 启动新的 TaskManager 来重新启动 Job
结合作业失败调度过程,可以得知 TaskManager 的故障其实就是作业 Task 异常的 Failover 的过程
基于 Standalone 资源管理,TaskManager 的数量是固定的,必须有足够的空闲 Slot 资源才能将 Job 恢复执行.
基于 Yarn / K8s / Mesos 的资源管理,则可以向资源管理集群申请新的容器,在容器中启动 TaskManager ,然后将 TaskManager 的 Slot 分配给作业.
3. JobMaster 和 ResourceManager 同时故障
在 Yarn 部署模式下,因为 JobMaster 和 ResourceManager 都在 JobManager 进程中
如果 JobManager 出现了问题
- 通常是
JobMaster和ResourceManager同时故障 - 因为
ResourceManager故障不会影响已经运行的 Task,相比JobMaster故障影响小一些 - 所以
TaskManager会优先恢复与新的JobManager之间的连接,保留Slot一段时间- 再同时尝试着与
ResourceManager建立连接
- 再同时尝试着与
问题
流批有不同的调度模式?
Flink 跨网络的数据交换 是怎么做到的?
内存管理的申请和分配 是怎么做到的?

若有收获,就点个赞吧
0 人点赞
