时间类型
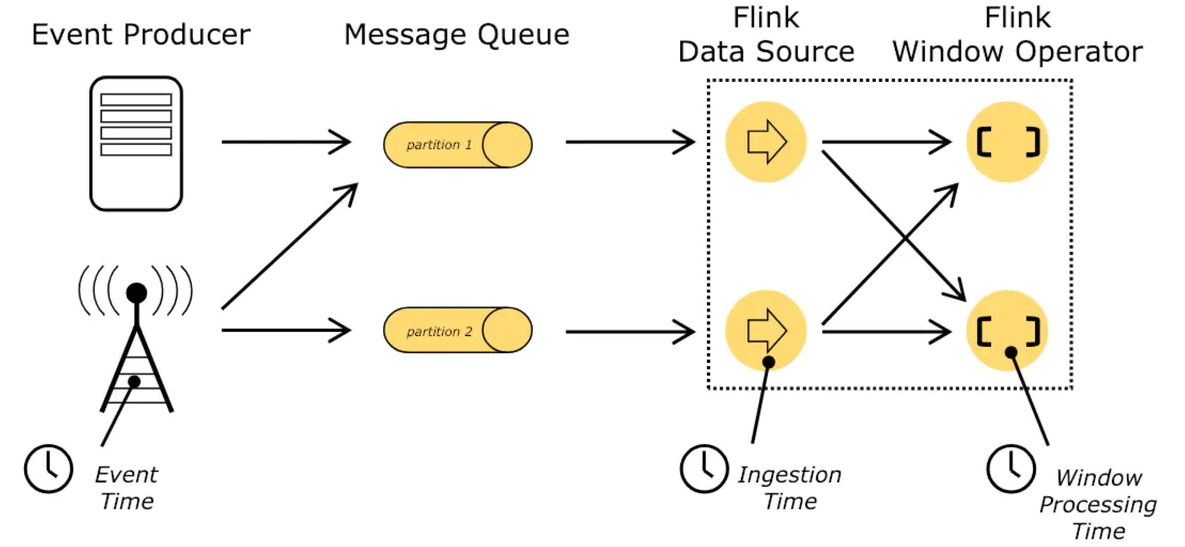
- 事件时间 (EventTime)
- 事件时间指事件发生时的时间,一旦确定之后再也不会改变
- 好处: 使用事件时间不依赖操作系统的时钟,无论执行多少次,都可以保证计算结果是一样的
处理时间 (ProcessTime)
- 处理时间指消息被计算引擎处理的时间,以各个计算节点的本地时间为准
- 好处: 逻辑简单,性能要好于事件时间,延迟也低于事件时间,只需要获取当前系统的时间戳即可
摄取时间 (IngestionTime)
- 摄取时间指事件进入流处理系统的时间,对于一个事件来说,读到的那一刻的时间作为摄取时间
- 好处: 如果数据本身不携带记录时间,又想使用事件时间的机制来处理该数据,就可以选择使用摄取时间
// 事件时间env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 处理时间env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);// 摄取时间env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
窗口类型
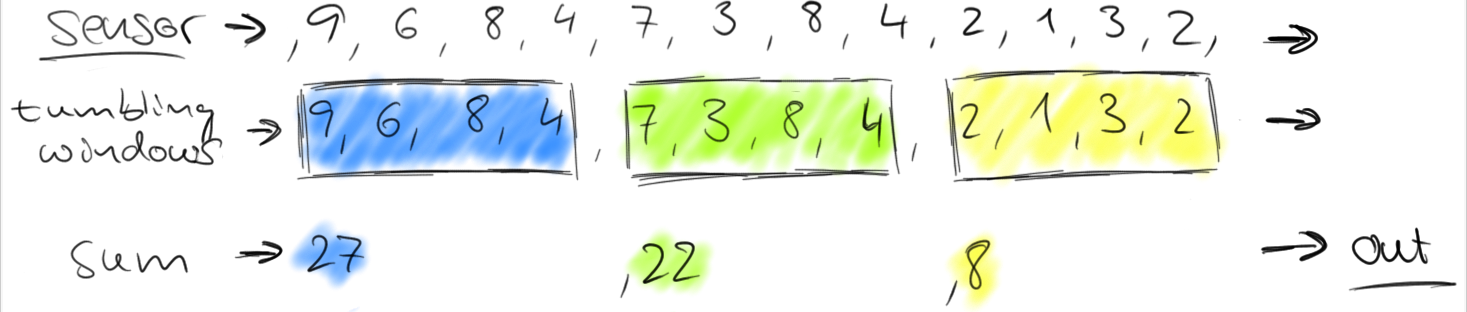
计数窗口 (Count Window)
Tumble Count Window (size)
- 累计固定个数的元素就视为一个窗口,该类型的窗口无法像时间窗口一样事先切分好

- Sliding Count Window (size,slide)
- 累计固定个数的元素视为一个窗口,每超过一定个数的事件,则会生成一个新的窗口
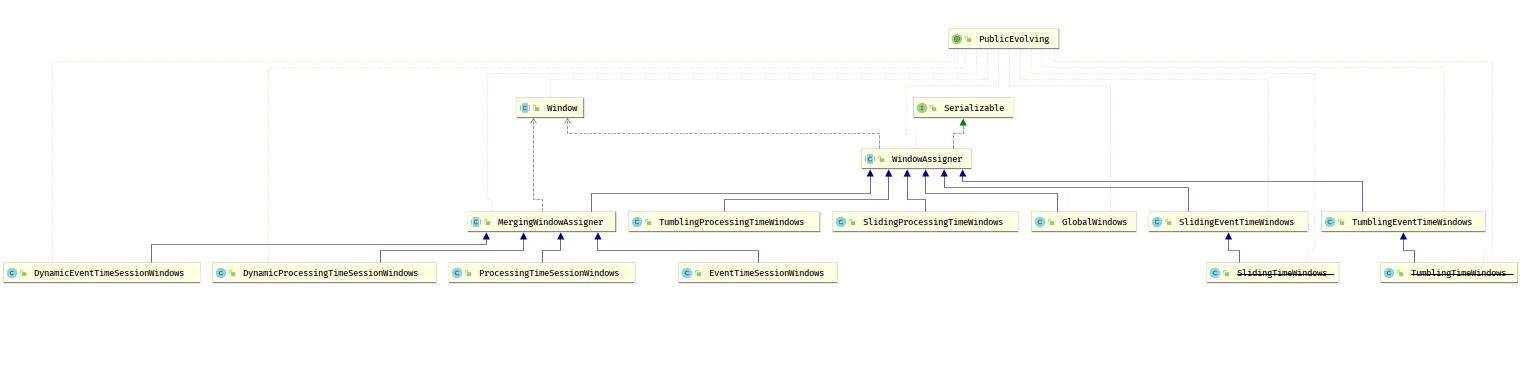
时间窗口 (Time Window)
- Tumble Time Window
- 在时间上按照事先约定的窗口大小切分的窗口
- 滚动窗口之间不会相互重叠
- Sliding Time Window
- 在时间上按照事先约定的窗口大小,滑动步长切分的窗口
- 滑动窗口之间可能会存在相互重叠的情况

会话窗口 (Session Window)
- Session Window
 ```java
Keyed Windows
```java
Keyed Windowsstream .keyBy(…) <- keyed versus non-keyed windows .window(…) <- required: “assigner” [.trigger(…)] <- optional: “trigger” (else default trigger) [.evictor(…)] <- optional: “evictor” (else no evictor) [.allowedLateness(…)] <- optional: “lateness” (else zero) [.sideOutputLateData(…)] <- optional: “output tag” (else no side output for late data) .reduce/aggregate/fold/apply() <- required: “function” [.getSideOutput(…)] <- optional: “output tag”
Non-Keyed Windows
stream .windowAll(…) <- required: “assigner” [.trigger(…)] <- optional: “trigger” (else default trigger) [.evictor(…)] <- optional: “evictor” (else no evictor) [.allowedLateness(…)] <- optional: “lateness” (else zero) [.sideOutputLateData(…)] <- optional: “output tag” (else no side output for late data) .reduce/aggregate/fold/apply() <- required: “function” [.getSideOutput(…)] <- optional: “output tag”
首先上图中的组件都位于一个算子(window operator)中,数据流源源不断地进入算子,每一个到达的元素都会被交给 WindowAssigner。WindowAssigner 会决定元素被放到哪个或哪些窗口(window),可能会创建新窗口 (有则放入,无则创建,会合并窗口)。
因为一个元素可以被放入多个窗口中,所以同时存在多个窗口是可能的。<br />注意,`Window`本身只是一个ID标识符,其内部可能存储了一些元数据,如`TimeWindow`中有开始和结束时间,但是并不会存储窗口中的元素。窗口中的元素实际存储在 Key/Value State 中,key为`Window`,value为元素集合(或聚合值)。为了保证窗口的容错性,该实现依赖了 Flink 的 State 机制(参见 [state 文档](https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming/state.html))。
每一个窗口都拥有一个属于自己的 Trigger,Trigger上会有定时器,用来决定一个窗口何时能够被计算或清除。每当有元素加入到该窗口,或者之前注册的定时器超时了,那么Trigger都会被调用。
Trigger 被调用后, 窗口中的元素集合就会交给Evictor(如果指定了的话)。Evictor 主要用来遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。剩余的元素会交给用户指定的函数进行窗口的计算。如果没有 Evictor 的话,窗口中的所有元素会一起交给函数进行计算。
计算函数收到了窗口的元素(可能经过了 Evictor 的过滤),并计算出窗口的结果值,并发送给下游。窗口的结果值可以是一个也可以是多个。DataStream API 上可以接收不同类型的计算函数,包括预定义的`sum()`,`min()`,`max()`,还有 `ReduceFunction`,`FoldFunction`,还有`WindowFunction`。WindowFunction 是最通用的计算函数,其他的预定义的函数基本都是基于该函数实现的。
Flink 对于一些聚合类的窗口计算(如sum,min)做了优化,因为聚合类的计算不需要将窗口中的所有数据都保存下来,只需要保存一个result值就可以了。每个进入窗口的元素都会执行一次聚合函数并修改result值。这样可以大大降低内存的消耗并提升性能。但是如果用户定义了 Evictor,则不会启用对聚合窗口的优化,因为 Evictor 需要遍历窗口中的所有元素,必须要将窗口中所有元素都存下来。
<a name="FlHMw"></a>
#### WindowAssigner
windowAssigner 用来决定某个元素被分配到哪个窗口中去
<a name="CQMbj"></a>
#### WindowTrigger
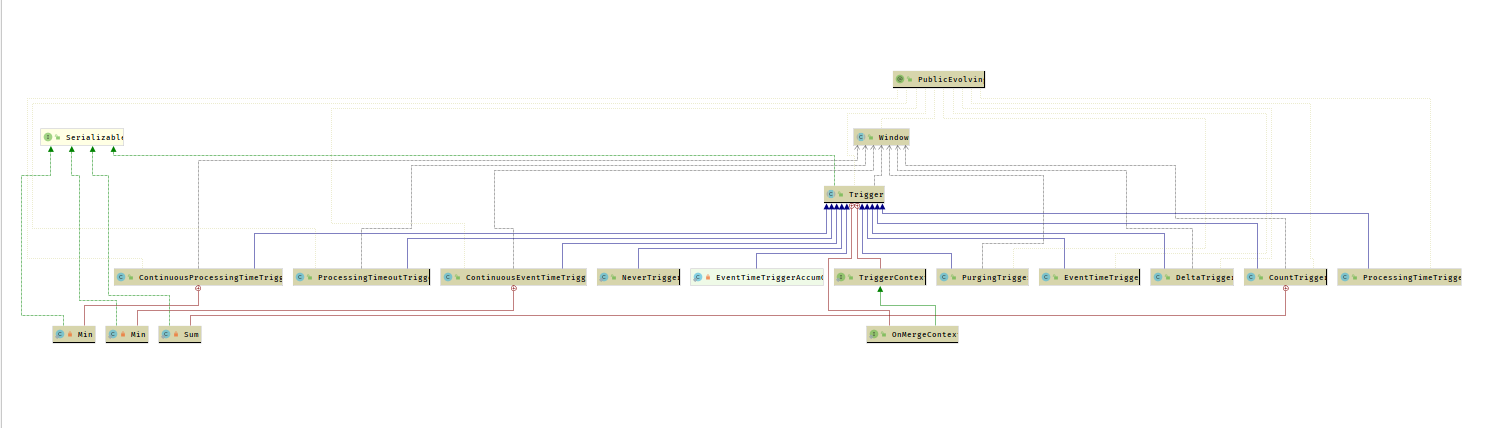
- Trigger用来决定一个窗口何时能够被计算或清除,每一个窗口都有一个属于自己的Trigger,Trigger上有定时器,用来决定窗口的触发
- Trigger 触发结果有这几类
- `CONTINUE`表示对窗口不执行任何操作。
- `FIRE`表示对窗口中的数据按照窗口函数中的逻辑进行计算,并将结果输出。注意计算完成后,窗口中的数据并不会被清除,将会被保留。
- `PURGE`表示将窗口中的数据和窗口清除。
- `FIRE_AND_PURGE`表示先将数据进行计算,输出结果,然后将窗口中的数据和窗口进行清除。
3种 典型延迟计算
1. 基于数据记录个数的触发
1. 等 Window 中的数据达到一定个数,则触发窗口的计算,对应的是 CountTrigger
2. 基于处理时间的触发
1. 在处理时间维度判断哪些窗口触发计算
3. 基于事件时间的触发
1. 基于事件时间 /Watermark 机制触发计算
```java
public abstract class Trigger<T, W extends Window> implements Serializable {
private static final long serialVersionUID = -4104633972991191369L;
public abstract TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception;
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception;
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception;
public boolean canMerge() {return false;}
public void onMerge(W window, OnMergeContext ctx) throws Exception {throw new UnsupportedOperationException("This trigger does not support merging.");}
WindowEvictor
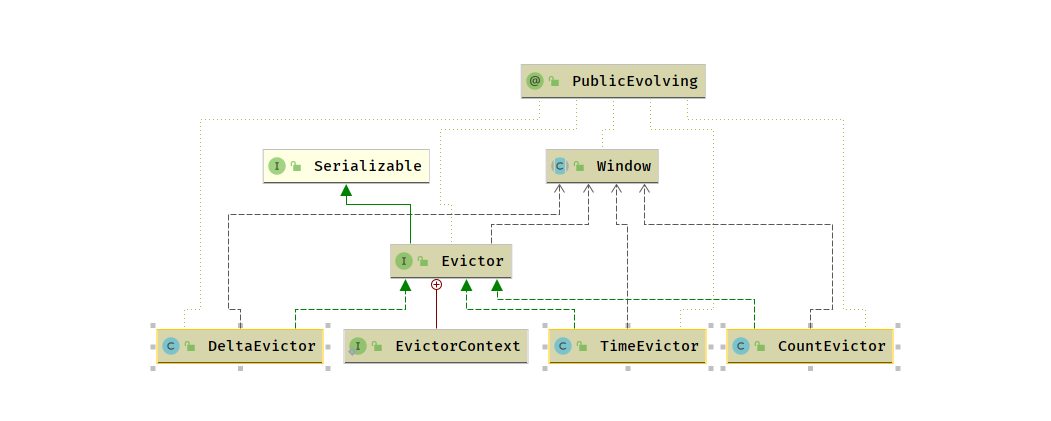
- 窗口数据的过滤器,Evictor 可以在 WindowFunction 执行前后,从 Window 中过滤元素
- CountEvictor : 计数过滤器
- 在 Window 中保留指定数量的元素,并从窗口头部开始丢弃其余元素
- TimeEvictor : 事件过滤器
- 保留Window 中最近一段时间内的元素,并丢弃其余元素
DeltaEvictor : 阈值过滤器
数据经过 WIndowAssigner 之后,就需要对数据进行处理了,窗口函数可以抽象成以下两种
增量计算函数
窗口保存一份中间数据,每流入一个新元素,都会与中间数据 “合并” ,生成新的中间数据,再保存到窗口中
- Function
- ReduceFunction
- AggregateFunction
- FoldFunction
优点/缺点
缓存窗口所有数据,窗口触发计算后,对窗口内的所有元素进行计算
- Function
- ProcessWindowFunction
优点/缺点
Watermark 用于处理乱序事件,正确的处理乱序事件,通常是通过 Watermark + Window 来实现的
- 从数据产生 -> Flink 读取数据 -> Flink 处理算子 整个过程中
- 受到 网络延迟 | 数据乱序 | 背压 | Failover 等多方面的影响 导致数据是乱序的
为了保证计结果的正确性,需要等待数据,而对于延迟太久的数据不能一直等下去,所以需要有一个机制,在保证特定时间后一定会触发窗口的计算,这个触发机制就是Watermark
DataStream Watermark
1. Source Function 中 生成 Watermark
Source Function 可以直接为数据元素分配时间戳.同时也会向下游发送 Watermark
// 略2. DataStream Api 中 生成 Watermark
DataStream API 中使用的 TimestampAssigner 接口定义了时间戳的提取行为
- AssignerWithPeriodicWatermarks
- 周期生成 Watermark 的 顶层抽象接口 - 周期的生成 Watermark , 而不是针对每一个事件都生成- 子类
- AscendingTimestampExtractor
- BoundedOutOfOrdernessTimestampExtractor
- 子类
AssignerWithPunctuatedWatermarks
- 每一个事件都会尝试生成 Watermark, 但是如果生成的 Watermark 是 null 或者 Watermark 小于之前的 Watermark,则不会将该 Watermark 往下发,下游也不会触发任何窗口的执行Flink SQL Watermark
Flink SQL 的 Watermark 生成主要是在 TableSource 中完成的, 定义了3类 Watermark 生成策略
- 周期性 Watermark 策略
- AscendingTimestamps: 递增 Watermark ,作用在 Flink SQL 的Rowtime属性上,Watermark = 当前收到的数据元素的最大时间戳-1, -1的目的是确保最大时间戳的事件不会被当做迟到数据丢弃
- BoundOutOfOrderTimestamps: 固定延迟 Watermark,作用在 Flink SQL 的 Rowtime 属性上,Watermark = 当前收到的数据元素的最大时间戳 - 固定延迟
- 每事件 Watermark 策略
- 每事件 Watermark 策略在Flink 中叫做 PuntuatedWatermarkAssigner,数据流中每一个递增的 EventTime 都会产生一个 Watermark ,在一定程度上对下游算子造成压力 (该模式在TPS很高的情况下会产生大量的 Watermark),所以只有在 实时性要求特别高的情况下才会采用此模式
无为 策略
当来自不同 Source 的相同 key 值会 shuffer 到同一个处理节点时,它们会有自己的 Watermark ,由于 Flink 内部需要保证 Watermark 保持单调递增,多个 Source 的 Watermark 汇聚到一起时可能不是单调递增的.解决该问题的方法
- FLink 内部实现每一个边上只有一个递增的 Watermark,当出现多流携带 EventTime 汇聚在一起时,Flink 会选择流入的 EventTime 中最小的一个向下流出, 从而保证 Watermark 的单调递增和数据的完整性
- Flink 作业是并行执行的,作业中包含多个 Task,每个Task运行一个或一组算子(OperatorChain)实例,Task 在生成 Watermark 的时候是相互独立的,也就是说在作业中存在多个并行的 Watermark
- Watermark 在作业的 DAG 从上游向下游传递,算子收到上游的 Watermark 之后会与自身维护的 Watermark 作比较, 当上游的 Watermark 大于当前 Watermark 时则会 更新自身的 Watermark 并将数据向下游发送
- 算子底层的执行模型上,会将多流输入会被分解为多个双流输入,所以对于多流 Watermark 的处理也就是 双流 Watermark 的处理
- 缺 图
时间服务 TimeService
需要有一个机制来触发 当到达某一时间点时的时候 需要做的一些额外操作 (定时器)
- 根据时间类型不同可以注册两种 Timer
- 基于事件时间 :
- 基于处理时间 :
在KeyedProcessFunction中 注册 Timer 然后重写其 onTimer方法 触发onTimer 回调
定时器服务
在 WindowOperator中 使用 InternalTimeService 来管理定时器,初始化是在 WindowOperator的open()中实现的
- 名称
- 命名空间类型N (及其序列化器)
- 键类型K (及其序列化器)
- Triggerable对象 (支持延迟计算的算子,继承了 Triggerable 接口来实现回调)
timeService.registerProcesssingTimeTimer(long time)
timeService.registerEventTimeTimer(long time)
- 保存
- InternalTimerService 接口的实现类是 InternalTimerServiceImpl
- Timer 的实现类是 InternalTimer,
- InternalTimerServiceImpl 使用了两个 TimerHeapInternalTimer 的优先队列 (HeapPriorityQueueSet),
- 分别用于维护 事件时间和处理时间的 Timer
- InternalTimerServiceManager 是 Task 级别提供的 InternalTimeService 集中管理器,其使用 Map 保存了当前所有的 InternalTimerService,Map 的key 是 InternalTimerService的名字
定时器
- 事件时间
- 根据 Watermark ,从维护的 事件时间队列中找比当前时间小的所有定时器,触发Timer 所在算子,算子调用 UDF中的 onTimer() 方法。
处理时间
由于Flink 在需要在优先队列中使用 KeyGroup,并且是按照 KeyGroup 去重的,并不是按照全局的Key去重,所以需要自己实现一个 PriorityQueue 。
- Flink 通过两种方式来实现 优先队列 管理 Timer
- 基于堆内存的优先队列 HeapPriorityQueueSet: 基于Java 堆内存的优先级队列,其实现思路与Java的PriorityQueue类似,使用了二叉树
- 基于RocksDB 的优先队列: 分为 Cache+RocksDB量级,Cache中保存了前N个元素,其余的保存在 RocksDB中, 写入时采用 Write-through策略,及写入 Cache 的同时要更新 RocksDB 中的数据,可能需要访问磁盘
- 前者 比后者 性能好,但受限于内存大小,无法容纳太多的数据
-
窗口实现
时间窗口
滚动窗口
- Offset: 窗口的起始时间
- Size: 窗口的长度
- 滑动窗口
- Offset: 窗口的起始时间
- Size: 窗口的长度
- Slide: 滑动距离
- Flink 会为每个元素分配一个或者多个TimeWindow对象,然后使用 TimeWindow 对象作为Key 来操作窗口对应的State
会话窗口
- 处理时间会话窗口
- 处理时间会话窗口,使用自定义会话间隔时长
- 事件时间会话窗口
时间时间会话窗口,使用自定义会话间隔时长
- 由于会话窗口不同于事件窗口,它的切分依赖于事件的行为,而不是时间序列,所以在很多情况下会因为事件乱序使得原本相互独立的窗口因为新事件的到来而导致窗口重叠,而必须要进行窗口合并
- 窗口合并涉及3个步骤
- 窗口对象合并和清理
- 窗口 State 的合并和清理
- 窗口触发器的合并和清理
对于会话窗口,因为无法事先确定窗口的长度,也不知道该将数据元素放到哪个窗口,所以对于每一个事件分配一个Sission Window
- 然后判断窗口是否需要与已有的窗口进行合并。窗口合并时按照窗口的起始时间进行排序,然后判断窗口之间是否存在时间重叠的窗口进行合并,然后将窗口合并到前序窗口中。延长前面窗口的长度,将后边窗口的结束时间作为前面窗口的结束时间并清理掉中间的窗口
- 窗口合并的同时,窗口对应的状态也需要进行合并,默认复用最早窗口的状态,也就是前面窗口的状态,将其他待合并窗口的状态,也就是后边的窗口状态,合并到前面窗口的状态中
- Trigger方法中,用于对触发器进行合并。触发器的合并实际上是删除合并窗口的触发器。删除合并前窗口的所有触发器,然后为新窗口创建新的触发器。触发时间为合并前最后一个窗口的触发器的触发时间
- Trigger的 Merge方法中,用于对触发器进行合并。触发器的合并实际上是删除合并窗口的触发器。删除合并前窗口的所有触发器,然后为新窗口创建新的触发器。触发时间为合并前最后一个窗口的触发器的触发时间
计数窗口

若有收获,就点个赞吧
0 人点赞
