容错保证
容错保证语义
最多一次 [
At-Most-Once]- 不开启检查点就是最多一次的处理保证
最少一次 [
At-Least-Once]- 开启检查点不进行
Barrier对齐 就是最少一次的处理保证
- 开启检查点不进行
严格一次 [
Exactly-Once]- 源数据支持断点读取,则能支持从数据源到引擎处理完毕,再写出到外部存储之前的过程中的严格一次
端到端严格一次 [
End-to-End Exactly-Once]- 从数据读取、引擎处理、写入外部存储的整个过程中,数据不丢失、不重复
- 需要数据源支持可重放,外部存储支持事务机制,能够进行回滚.
检查点与保存点
Checkpoint 是容错的核心机制,根据配置周期性来通知 Stream 中各个算子的状态来生成检查点快照,从而将这些状态数据持久化存储下来.
Flink 程序一旦意外崩溃,重新运行程序时可以选择的从这些快照进行恢复,将应用恢复到最后一次快照的状态,从此刻开始重新执行,避免数据的丢失、重复
默认情况下,检查点不会被保留,取消程序时会删除它们,但是可以通过配置保留定期检查点
- 根据配置,当作业失败或者取消的时候,不会自动清除这些保留的检查点 ```java // TODO 取消删除检查点 (取消后手动清理检查点状态) DELETE_ON_CANCELLATION(true),
// TODO 取消作业时保留检查点 (只有在作业失败时检查点状态才可以用) RETAIN_ON_CANCELLATION(false);
_<br />`SavePoint`- 是基于 Flink 检查点机制的应用完整快照备份机制,用来保存状态- 保存点可以视为 一个算子 (`OperatorId` -> `State` ), 对于每一个有状态的算子 `Key` 是算子ID, `Value` 是算子的 `State`.---<a name="937e9e55"></a>### 作业恢复Flink 提供了应用- 自动容错机制- 手动作业恢复方式1) 外部检查点- 检查点完成时,在用户给定的外部持久化存储保存.- 当作业 `Failed` 或者 `Canceld` 时外部检查的检查点会保留下来- 用户在恢复时需要提供用于恢复的作业状态的检查点路径2) 保存点- 用户通过命令触发,由用户手动创建、清理 (路径)- 用户在恢复时需要提供用于恢复的作业状态的检查点路径---<a name="Xa7EO"></a>#### 检查点恢复1. 自动检查点恢复自动恢复可以在配置文件中提供全局配置2. 手动检查点恢复- 启动时通过设置 -s 参数指定检查点目录的功能- 让新的 `JobId` 读取该检查点源文件信息和状态信息<a name="WvVSw"></a>#### 保存点恢复从保存点恢复作业并不简单,尤其是在作业变更 (修改逻辑,修复 Bug ) 的情况下- 算子的顺序改变- 如果对应的 `UID` 没变,则可以恢复,如果对应的 UID 变了则恢复失败- 作业中添加了新的算子- 如果是无状态算子,没有影响,可以正常恢复.- 如果是有状态算子,则跟无状态算子一样处理.- 从作业中删除了一个有状态的算子- 默认需要恢复保存点中所记录的所有算子的状态,如果删除了一个有状态的算子,从保存点恢复的时候被删除的 `OperatorId` 找不到,所以会报错.- `--allowNonRestoredState` (`short:` `-n`) 跳过无法恢复的算子- 添加和删除无状态的算子- 如果手动设置了 `UID`,则可以恢复,保存点中不记录无状态的算子- 如果是自动分配的 `UID` , 那么有状态算子的 `UID` 可能会变 (Flink 使用一个单调递增的计数器生成 `UID`,`DAG` 改变后,计数器极有可能会变) , 很有可能恢复失败- 恢复的时候调整并行度- 没什么问题 /低版本 1.2x 以下 可能会有问题<a name="rPWCD"></a>#### 恢复时时间问题- 需要进行恢复时最好使用事件时间,而不是处理时间- `Flink` 集群停止时间太长,使用保存点进行恢复的时候,停止期间积压的数据,可能会在短时间之内处理完毕- 停止期间统计结果为 0- 短时间内统计结果暴涨了几十乃至上百倍---<a name="CfrPR"></a>### 关键组件<a name="9126dc89"></a>#### 检查点协调器 `CheckpointCoordinator`- 负责协调 Flink 算子的 `State` 的分布式快照- 当触发快照时, `CheckpointCoordinator` 向 `Source` 算子中注入 `Barrier` 消息- 然后等待所有的 `Task` 通知检查点确认完成- 同时持有所有 `Task` 在确认完成消息中上报的 `State` 句柄---<a name="34nYo"></a>#### 检查点消息在执行检查点的过程中,`TaskManager` 和 `JobMaster` 之间通过消息确认检查点执行成功还是取消- `AbstractCheckpointMessage`- `AcknowledgeCheckpoint`- `DeclineCheckpoint`检查点消息中有 3 个重要信息- 该检查点所属的作业标识 (`JobID`)- 检查点编号- `Task` 标识 (`ExecutionAttempID`)`AcknowledgeCheckpoint` 消息- 该消息 从 `TaskExecutor` 发往 `JobMaster` ,告知算子的快照备份完成`DeclineCheckpoint` 消息- 该消息从 `TaskExecutor` 发往 `JobMaster`,告诉算子无法执行快照备份- 如 `Task` 成为 `Running` 状态但是内部还没准备好执行快照备份---<a name="ceo8w"></a>### 轻量级异步分布式快照`Flink` 采用轻量级分布式快照实现应用容错,采用这种方式有基本假设条件- 作业异常和失败极少发生,因为一旦发生异常,作业回滚到上一个状态的成本很高- 为了低延迟,快照需要很快就能完成- `Task` 与 `TaskManager` 之间的关系式静态的,分配完成之后,在作业运行过程中不会改变 (`Savepoint` 恢复几点)<a name="LrcSE"></a>#### 基本概念分布式快照最关键的是能够将数据流切分,`Flink` 中使用 `Barrier` 来切分数据流- `Barrier` 会周期性的注入数据流中,作为数据流的一部分,从上游到下游被算子处理- `Barrier` 会严格保证顺序,不会超过其前边的数据- `Barrier` 会将记录分割成数据集,两个 `Barrier` 之间的数据流中的数据属于同一个检查点- 每一个 `Barrier` 都携带一个其所属快照的 ID 编号- `Barrier` 随着数据向下流动,不会打断数据,因此非常轻量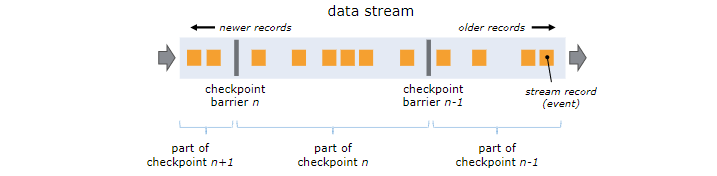- `Barrier` 会在数据源头被注入并行数据流中- `Barrier` n 所在的位置就是恢复时数据重新处理的起始位置- `Barrier` 接着向下游传递- 当一个非数据源算子从所有的输入流中收到快照 n 的 `Barrier` 时- 该算子就会对自己的 State 保存快照- 并向自己的下游广播发送快照 n 的 `Barrier`- 一旦 `Sink` 算子接收到 `Barrier` ,有两种情况- [x] Exactly-Once- 当 `Sink` 算子已经收到所有上游的 `Barrier` n 时- `Sink` 算子对自己的 `State` 进行快照- 然后通知检查点协调器 (`CheckpointCoordinator`)- 当所有的算子都向检查点协调器汇报成功之后- 检查点协调器向所有的算子确认本次快照完成- [x] End-To-End Exactly-Once- 当 `Sink` 算子已经收到所有上游的 `Barrier` n 时- `Sink` 算子对自己的 `State` 进行快照- 并预提交事务- 再通知检查点协调器 (`CheckpointCoordinator`)- 检查点协调器向所有的算子确认本次快照完成- `Sink` 算子提交事务,本次事务完成---<a name="Ho4Kl"></a>#### `Barrier` 对齐- 开始对齐- 对齐- 执行检查点- 继续处理数据---<a name="CjKxm"></a>## 检查点执行过程`JobMaster` 作为作业的管理者,是作业的控制核心- 在 `JobMaster` 中 `CheckpointCoordinator` 组件专门负责检查点的管理- 包括何时 触发检查点 / 检查点完成的确认- 检查点的具体执行者是作业的各个 `Task`- 各个 `Task` 再将检查点的执行交给算子- 算子是最底层的执行者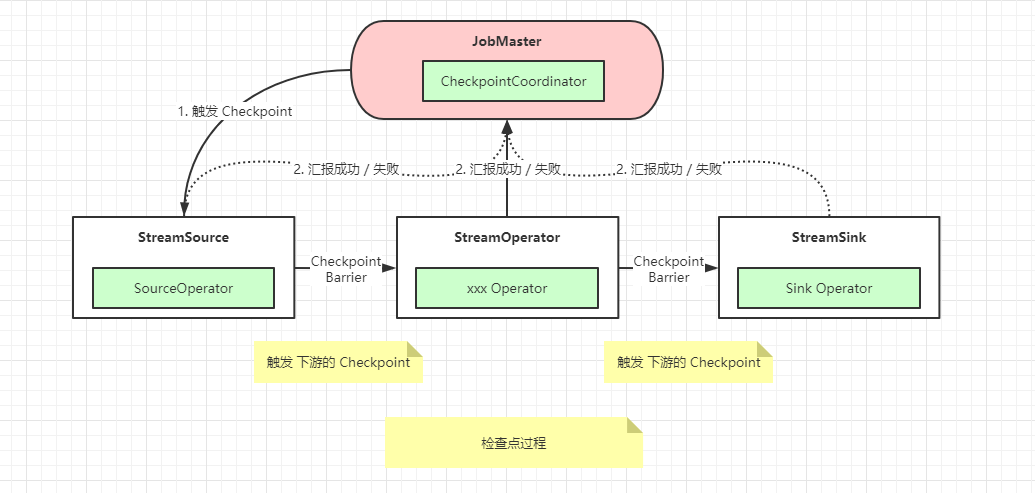<a name="crgg1"></a>### JobMaster 触发检查点在 `JobMaster` 开始调度作业的时候,会为作业提供一个 `CheckpointCoordinator`,周期性地触发检查点的执行<br />在 `CheckpointCoordinator`触发检查点的时候- 只需要通知执行数据读取的 `Task `(`SourceTask`)- 从 `SourceTask` 开始会产生 `CheckpointBarrier` 事件- 注入数据流中,数据流向下游流动时被算子读取- 在算子上触发检查点行为<a name="2na7n"></a>#### 前置检查在触发真正的执行之前要进行一系列检查,确保具备执行检查点的条件<br />检查逻辑如下:- 前置检查,确保作业关闭过程中不允许执行.- 如果未启用,或尚未达到触发检查点的最小间隔等,同样不允许执行- 检查是否所有需要执行检查点的 `Task` 都处于执行状态,能够执行检查点和向 `JobMaster` 汇报- 若不是则整个作业的检查点无法完成- 执行 `**long **``checkpointID = ``**checkpointIdCounter**``.getAndIncrement``**()**` 生成一个新的 id- 然后生成一个 `PendingCheckpoint`- `PendingCheckpoint` 是一个启动了的检查点,但是还没有被确认- 等到所有 `Task` 都确认了本次检查点,那么这个检查点对象转化为一个 `CompletedCheckpoint`- `JobMaster` 不能无限期等待检查点的执行,所以需要进行超时监视- 如果超时尚未完成检查点,则取消本次检查点- 触发 `MasterHooks` ,用户可以定义一些额外的操作,用来增强检查点的功能 (如准备和清理外部资源)- 再次执行步骤 1) 和步骤 2) 中的检查,如果一切正常,则向各个 `SourceStreamTask` 发送通知- 触发检查点的执行- 检查完毕,没有问题, `CheckpointCoordinator` 开始触发本次检查点,通知各个 `Source` 类型的 `Task` 开始执行快照```javaprivate void snapshotTaskState(long timestamp,long checkpointID,CheckpointStorageLocation checkpointStorageLocation,CheckpointProperties props,Execution[] executions,boolean advanceToEndOfTime) {final CheckpointOptions checkpointOptions =CheckpointOptions.forConfig(props.getCheckpointType(),checkpointStorageLocation.getLocationReference(),isExactlyOnceMode,unalignedCheckpointsEnabled,alignmentTimeout);// send the messages to the tasks that trigger their checkpoint// TODO 通知作业的各个 Source Task 触发 Checkpoint ,同步则触发 Savepoint,异步创建 Checkpointfor (Execution execution : executions) {if (props.isSynchronous()) {execution.triggerSynchronousSavepoint(checkpointID, timestamp, checkpointOptions, advanceToEndOfTime);} else {execution.triggerCheckpoint(checkpointID, timestamp, checkpointOptions);}}}
JobMaster 向 Task 发送触发检查点的消息
ExecutionVertex与 Task 是一一对应的
Execution表示一次ExecutionVertex的执行- 对应于
Task的实例,在JobMaster端通过Execution的Slot可以找到对应的TaskManagerGateway 远程触发
Task的检查点private void triggerCheckpointHelper( long checkpointId, long timestamp, CheckpointOptions checkpointOptions, boolean advanceToEndOfEventTime) { final CheckpointType checkpointType = checkpointOptions.getCheckpointType(); if (advanceToEndOfEventTime && !(checkpointType.isSynchronous() && checkpointType.isSavepoint())) { throw new IllegalArgumentException( "Only synchronous savepoints are allowed to advance the watermark to MAX."); } final LogicalSlot slot = assignedResource; if (slot != null) { final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway(); taskManagerGateway.triggerCheckpoint( attemptId, getVertex().getJobId(), checkpointId, timestamp, checkpointOptions, advanceToEndOfEventTime); } else { LOG.debug( "The execution has no slot assigned. This indicates that the execution is no longer running."); } }
TaskExecutor 执行检查点
JobMaster 通过 TaskManagerGateway 触发 TaskManager 的检查点执行,TaskManager 则转交给 Task 执行
Task 层面的检查点执行
Task 类中的部分,该类创建了一个 CheckpointMetaData 的对象,确保 Task 处于 Running 状态,把工作转交给 StreamTask
public void triggerCheckpointBarrier(
final long checkpointID,
final long checkpointTimestamp,
final CheckpointOptions checkpointOptions,
final boolean advanceToEndOfEventTime) {
// TODO invokable = StreamTask
final AbstractInvokable invokable = this.invokable;
// TODO 创建了一个 CheckpointMetaData 对象 ?
final CheckpointMetaData checkpointMetaData =
new CheckpointMetaData(checkpointID, checkpointTimestamp);
// TODO 确保 Task 处于 Running 状态
if (executionState == ExecutionState.RUNNING && invokable != null) {
try {
// TODO 把工作交给 StreamTask
invokable.triggerCheckpointAsync(
checkpointMetaData, checkpointOptions, advanceToEndOfEventTime);
} catch (RejectedExecutionException ex) {
// This may happen if the mailbox is closed. It means that the task is shutting
// down, so we just ignore it.
LOG.debug(
"Triggering checkpoint {} for {} ({}) was rejected by the mailbox",
checkpointID,
taskNameWithSubtask,
executionId);
} catch (Throwable t) {
if (getExecutionState() == ExecutionState.RUNNING) {
failExternally(
new Exception(
"Error while triggering checkpoint "
+ checkpointID
+ " for "
+ taskNameWithSubtask,
t));
} else {
LOG.debug(
"Encountered error while triggering checkpoint {} for "
+ "{} ({}) while being not in state running.",
checkpointID,
taskNameWithSubtask,
executionId,
t);
}
}
} else {
LOG.debug(
"Declining checkpoint request for non-running task {} ({}).",
taskNameWithSubtask,
executionId);
// send back a message that we did not do the checkpoint
checkpointResponder.declineCheckpoint(
jobId,
executionId,
checkpointID,
new CheckpointException(
"Task name with subtask : " + taskNameWithSubtask,
CheckpointFailureReason.CHECKPOINT_DECLINED_TASK_NOT_READY));
}
}
代码里的 invokable 就是 StreamTask
Task类实际上是将检查点委托给了更具体的类去执行- 而
StreamTask也是将委托给更具体的类 - 直到最终执行用户编写的业务逻辑
StreamTask 执行检查点
从 StreamTask 开始,执行检查点就开始区分 StreamTask 类型了,其中 SourceStreamTask 是检查点的出发点,产生 CheckpointBarrier 并向下游广播,下游的 StreamTask 根据 CheckpointBarrier 触发检查点
检查点恢复过程
在作业发生异常自动恢复,从保存点恢复作业时,都会涉及从快照中恢复作业状态JobMaster 会将恢复状态包装到 Task 的任务描述信息中, Task 使用 TaskStateSnapshot 向 JobMaster 汇报自身的状态信息,恢复的时候也是使用 TaskStateSnapshot 对象.
作业状态以算子粒度进行恢复
OperatorState恢复KeyedState恢复- 函数
State恢复
恢复 OperatorState 是各算子的通用行为<br />
端到端严格一次
引擎内部可以保证严格一次处理,但无法保障 写出外部引擎的次数只有一次.所以从整体上来说 还是至少一次语义
需要达到 数据处理 数据写出 的次数仅有一次
两阶段递交协议,能够保证从读取、计算到写出整个过程的端到端严格一次,无论是什么原因导致的作业失败,都严格保证数据仅影响结果一次,既不会重复计算,或者保证重复计算不影响结果的正确性.
两阶段提交协议
满足以下条件可以做到 端到端严格一次
- 数据源支持断点读取
能够记录上次读取的位置 (
offset或者其他可以标记的信息),失败之后能够从断点处继续读取[x] 外部存储支持回滚机制或者满足幂等性
- 回滚机制: 当作业失败之后能够将部分写入的结果回滚到写入之前的状态
- 幂等性: 当作业失败之后,重复写入不会带来错误的结果
1. 预提交阶段
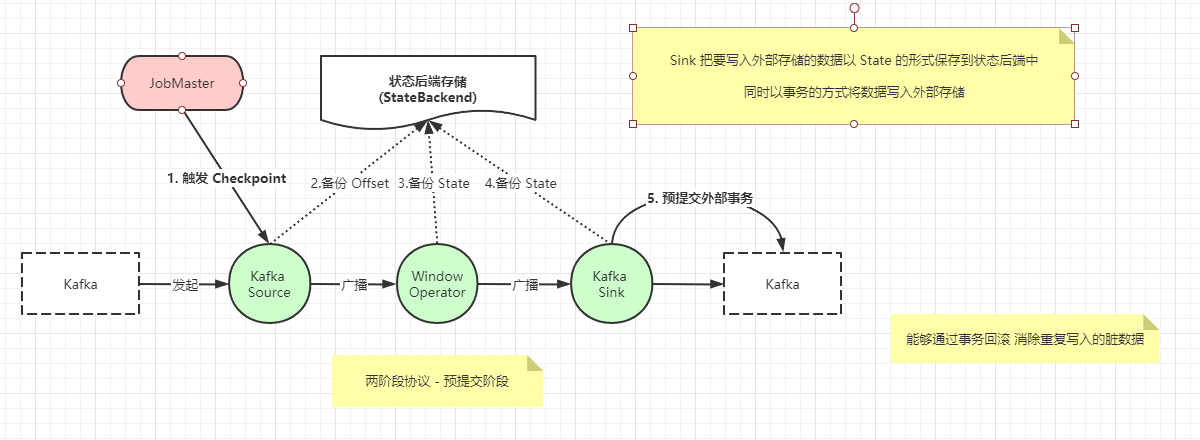
- 当开始执行检查点的时候进入预提交阶段,
JobMaster向SourceTask注入CheckpointBarrier Source Task将CheckpointBarrier插入数据流,向下游广播开启本次快照CheckpointBarrier在两阶段提交协议中,负责将流中所有消息分割成属于本次检查点的消息以及属于下次检查点的两个集合,每个集合表示一组需要提交的数据,属于同一个事务解决 能够通过事务回滚 消除重复写入的脏数据 问题
Sink 把要写入外部存储的数据以 State 的形式保存到状态后端中同时以事务的方式将数据写入外部存储
2. 提交阶段

- 预提交阶段完成之后,下一步就是通知所有的算子,确认检查点已成功完成,然后进入第二阶段—提交阶段
JobMaster会为作业中每个算子发起检查点已完成的回调逻辑
两阶段提交协议依赖于 Flink 的两阶段检查点机制
JobMaster触发检查点,所有算子完成各自快照备份即预提交阶段,在这个阶段 SInk 也要把待写出的数据备份到可靠的存储中,确保不会丢失- 向支持外部事物的存储预提交,当检查点的第一阶段完成之后,
JobMaster确认检查点完成,此时Sink提交才真正写入外部存储
两阶段递交实现

-
CheckpointedFunction 在预提交阶段,能够通过检查点将代写出的数据可靠地存储起来
[x]
CheckpointListener在提交阶段,能够接受
JobMaster的确认通知,触发提交外部事物[x] 若要实现端到端的严格一次的 SInk , 最重要的是 这几个方法:
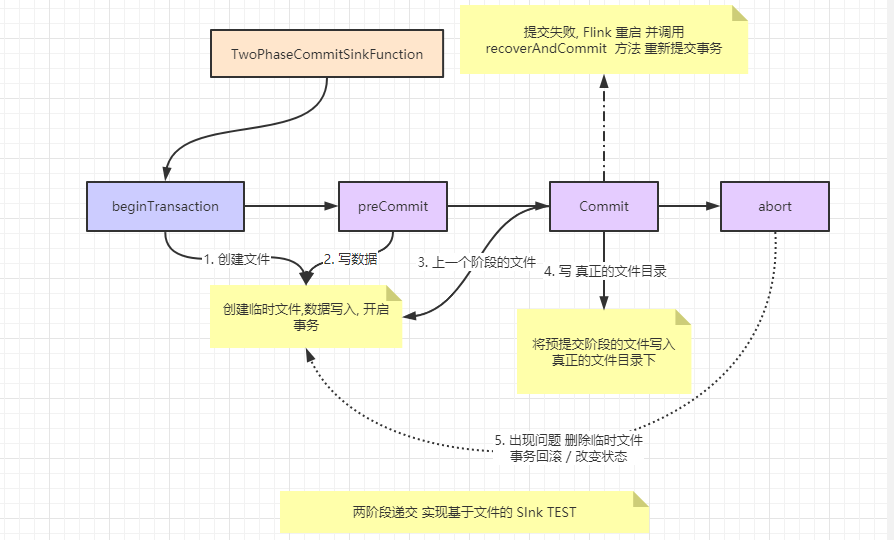
beginTransaction
- 开启一个事务.在临时目录下创建一个临时文件,之后写入数据到该文件中. (此过程为不同的事务创建隔离,避免数据混淆)
preCommit
- 在预提交阶段,将缓存数据块写出到创建的临时文件,然后关闭改文件,确保不再写入新数据到该文件,同时开启一个事务,执行属于下一个检查点的写入操作. (此过程用于准备需要提交的数据,并将不同事物的数据隔离开来)
commit
- 在提交阶段,以原子操作的方式将上一阶段的文件写入真正的文件目录下
- 如果提交失败,
Flink应用会重启,并调用TwoPhaseCommitSinkFunction.recoverAndCommit方法尝试恢复并重新提交事务
4.abort
- 一旦终止事务,删除临时文件
Flink应用预提交完成之后,若在提交完成之前崩溃了,会恢复到预提交的状态,进行事务回滚
Checkpoint 流程

若有收获,就点个赞吧
0 人点赞
