问题待思考
- Flink 作业是如何提交到集群的
- Flink 集群是如何在(各个)资源管理集群上启动起来的
- Flink 的计算资源是如何分配给作业的
- Flink 作业提交之后是如何启动的
大体框架
Flink 的 Jar 文件并不是 Flink 集群的可执行文件,需要经过转换之后提交给集群,其转换过程大概分两大步骤
- 在 Flink Client 中通过反射启动 Jar 中的 main 方法,生成
Flink StreamGraph\Job Graph将Job Graph提交给 Flink 集群 - Flink 集群收到
Job Graph之后将Job Graph转换成Execution Graph, 然后开始调度执行,启动成功之后开始消费数据
Flink 的核心执行流程,对用户 API 调用 通过4层抽象 进行转换
Stream Graph->Job Graph->Execution Graph-> 物理执行拓扑 (Task DAG)
提交流程
- Flink 作业在开发完毕之后,需要提交到 Flink 集群执行,
ClientFrontend是入口,触发用户开发的 Flink 应用 Jar 文件中的 main 方法,然后交给pipelineExecutor.execue()方法,最终会选择一个具体的PiplineExecutor执行
作业执行可以选择 Session 和 Per-Job 两种集群模式
Session模式的集群,一个集群中运行多个作业Per-Job模式的集群,一个集群中只运行一个作业,作业执行完毕则集群销毁
不同模式适用场景
Dispatcher和ResourceManager的占用- 集群资源的共享性
- 执行任务特性
| 运行模式 | 适用场景 |
| —- | —- |
| Session 模式 | 共享 Dispatcher 和 ResourceManager
按需申请资源,作业共享集群资源
适合执行时间短,频繁执行的短任务 | | Per-Job 模式 | 独享 Dispatcher 和 ResourceManager
长周期执行的任务,集群异常影响范围小 |
根据 Flink Client 提交作业之后是否还可以退出 Client 进程,提交模式又可以分为
- Detached
Flink Client创建完集群之后,可以退出命令行窗口,集群独立运行
- Attached
Flink Client创建完集群之火,不能关闭命令行窗口,需要与集群之间维持练连接,好处是能够感知集群的退出,集群退出之后还会做一些资源清理的工作
pipelineExecutor
pipelineExecutor 执行器是 Flink Client 生成 JobGraph 之后,将作业提交给集群的重要环节
Session模式 :AbstractSessionClusterExecutorPer-Job模式 : AbstractJobClusterExecutorMiniCluster模式 : LocalExecutor
Session 模式
该模式下,作业共享集群资源,作业通过 Http 协议进行提交
Flink 提供的会话模式:
- Yarn 会话模式
- K8s 会话模式
StandaloneStandalone模式比较特别,Flink 安装在物理机上,不能像在集群上一样,可以随时启动一个新集群,所有的作业共享Standalone集群,本质上就是一种Session模式,所以不支持Per-Job模式
在
Session模式- Yarn 作业提交使用
yarn-session.sh脚本 - K8s 作业提交使用
kubernetes-session脚本
- Yarn 作业提交使用
在启动脚本的时候就会检查是否存在已经启动好的
Flink Session模式集群- 如果没有: 则启动一个
Flihk Session模式集群 - 然后在
PipelineExecutor中通过Dispatcher提供的Rest接口提交JobGraph Dispatcher为每个作业启动一个JobMaster,进入作业执行阶段
- 如果没有: 则启动一个
Per-Job 模式
该模式下,一个作业一个集群,作业之间相互隔离
在 Flink 1.10 版本中,只有 Yarn 上实现了 Per-Job 模式
- 疑问: K8s 的
Per-Job?
Per-Job 模式下,因为不需要共享集群,所以在 PipelineExecutor 中执行作业提交的时候,可以创建集群并将 JobGraph 以及所需的文件等一同提交给 Yarn 集群
- Yarn 集群在容器中启动 Flink Master 进程 (JobManager 进程)
- 进行一系列的初始化动作,初始化完毕之后从文件系统中获取
JobGraph - 交给
Dispatcher,之后的执行流程与Session模式下的执行流程相同
Yarn Session 提交流程
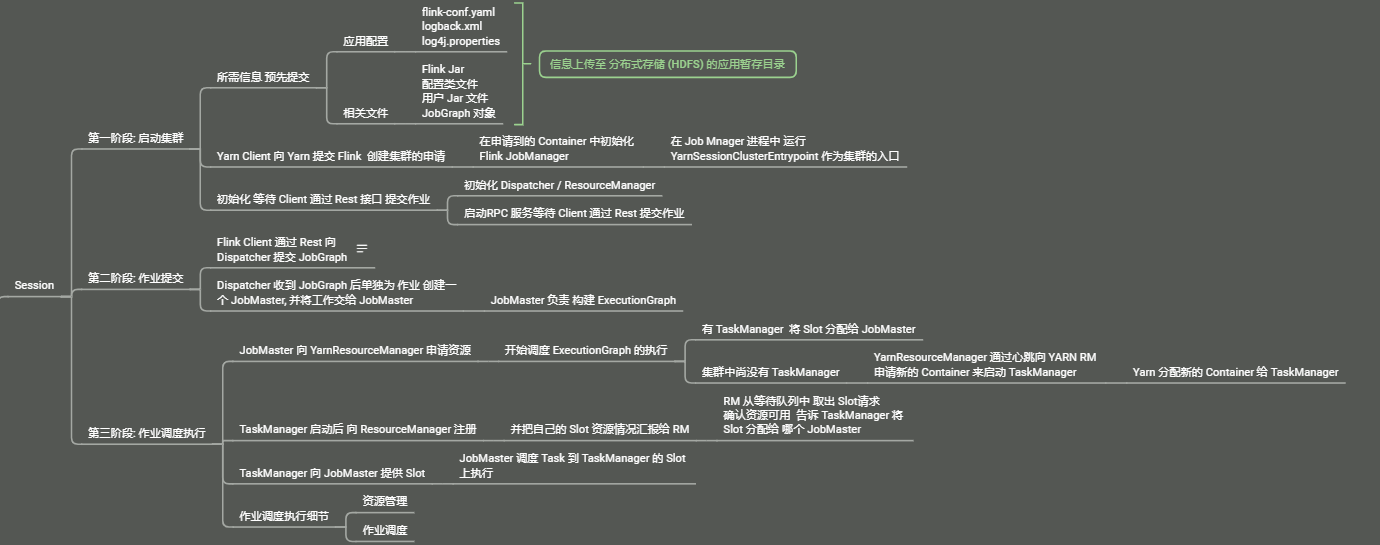
1. 启动集群
使用 bin/yarn-session.sh 提交会话模式的作业
如果提交到已经存在的集群,则获取 Yarn 集群信息/应用ID/ 并准备提交作业
- 如果启动新的
Yarn Sesssion则直接跳到 作业提交阶段 如果没有集群 则创建一个新的 Session 模式的集群
首先将 应用配置
flink-conf.yaml☺logback.xml☺log4j.properties和 相关文件Flink Jar☺ 配置类文件 ☺ 用户 Jar 文件 ☺JobGraph对象等信息上传至 分布式存储 (HDFS) 的应用暂存目录通过
Yarn Client向 Yarn 提交 Flink 创建集群的申请,Yarn 分配资源,在申请的Yarn Container中初始化并启动Flink JobManager进程,在Job Manager进程中运行YarnSessionClusterEntrypoint作为集群的入口初始化
Dispatcher/ResourceManager,启动相关的 RPC 服务等待Client通过 Rest 接口提交作业
2. 作业提交
Yarn 集群准备好后,开始作业提交Flink Client 通过 Rest 向 Dispatcher 提交JobGraph
Dispatcher 是 Rest 接口
- 不负责实际的调度/执行方面的工作,
- 当收到
JobGraph后,为作业创建一个JobMaster,将工作交给JobMaster- (负责 作业调度,管理作业 和 Task 的生命周期)
- 构建
ExecutionGraph(第三层物理Graph)
这两个步骤完成后,作业进入调度执行阶段
3.作业调度执行
JobMaster 向 YarnResourceManager申请资源,开始调度 ExecutionGraph 的执行,向 YarnResourceManager申请资源
- 初次提交作业集群中尚没有
TaskManager此时资源不足,需要先申请资源
YarnResourceManager 收到 JobMaster 的资源请求,如果当前有空闲 Slot 则将 Slot 分配给 JobMaster , 否则 YarnReSourceManager 将向 Yarn Master 请求创建 TaskManager
YarnResourceManager将资源请求加入等待请求队列,并通过心跳向 YARN ResourceManager 申请新的 Container 资源来启动 TaskManager进程,Yarn 分配新的 Container 给 TaskManager
YarnResourceManager 启动,然后从 HDFS 加载 Jar 文件等所需的相关资源,在容器中启动 TaskManager
TaskManager 启动后 向 ResourceManager 注册,并把自己的 Slot 资源情况汇报给 ResourceManager
ResourceManager 从等待队列中取出 Slot 请求,向 TaskManager 确认资源可用情况,并告知 TaskManager 将 Slot 分配给了哪个 JobMaster
TaskManager 向 JobMaster 提供 Slot,JobMaster 调度 Task 到 TaskManager的 Slot 上执行
Yarn Per-Job 提交流程

1. 启动集群
使用 ./flink run -m yarn-cluster 提交 Per-Job 模式的作业
Yarn 启动 Flink 集群,该模式下 Flink 集群的入口是 yarnJobClusterEntryPoint
2. 作业提交
该步骤与 Session 模式不同, Client 并不会通过 Rest 向 Dispatcher 提交 JobGraph,由 Dispatcher 从本地文件系统获取 JobGraph , 剩下的一样
3.作业调度执行
略
K8s Session 提交流程
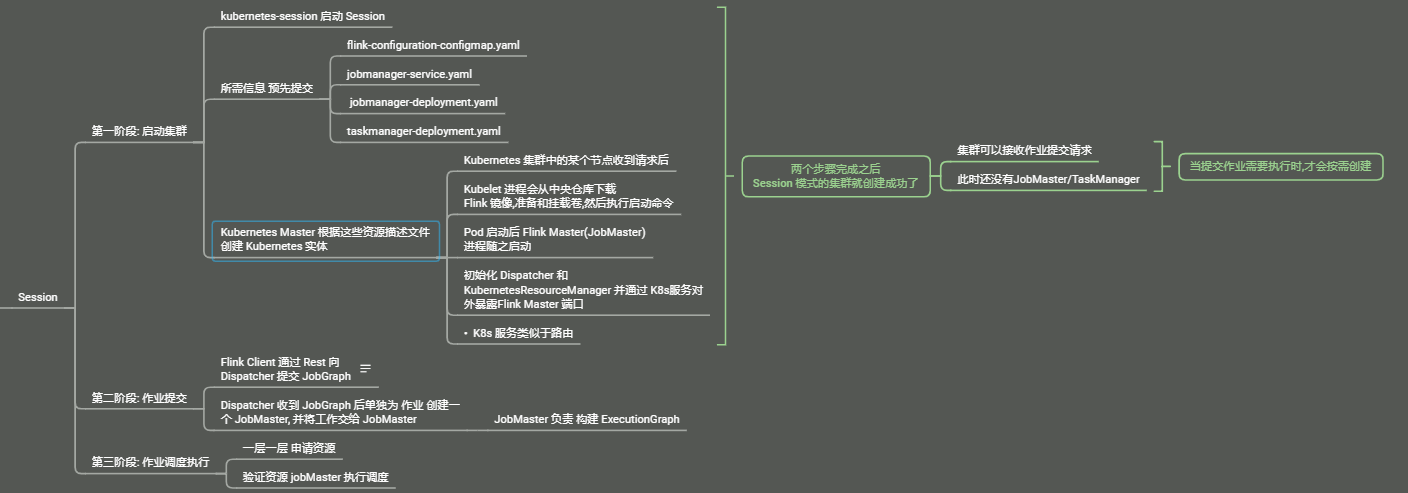
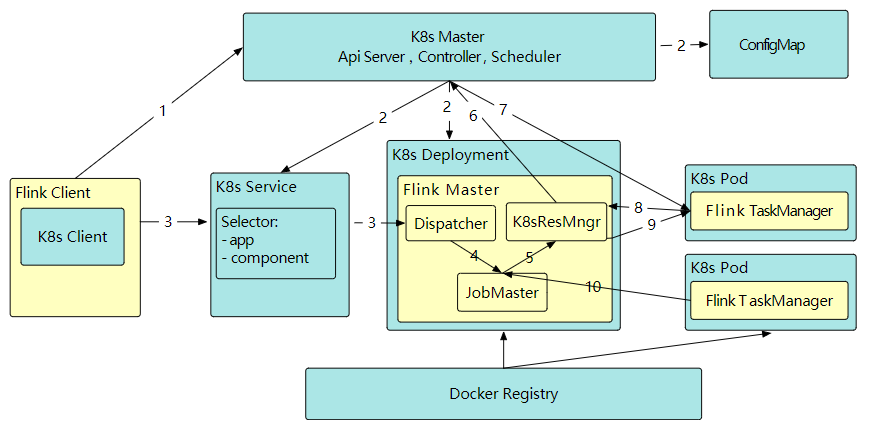
1. 启动集群
Flink 客户端首先连接 Kubernetes API Server,提交 Flink 集群的资源描述文件
flink-configuration-configmap.yaml/jobmanager-service.yaml/jobmanager-deployment.yaml/taskmanager-deployment.yaml
Kubernetes Master 会根据这些资源描述文件去创建对应的 Kubernetes 实体
以 JobMaster 部署为例
Kubernetes集群中的某个节点收到请求后Kubelet进程会从中央仓库下载 Flink 镜像,准备和挂载卷,然后执行启动命令- Pod 启动后
Flink Master(JobMaster) 进程随之启动 - 初始化
Dispatcher和KubernetesResourceManager并通过 K8s服务对外暴露Flink Master端口- K8s 服务类似于路由
两个步骤完成之后,Session 模式的集群就创建成功了,集群可以接收作业提交请求,但是此时还没有JobMaster/TaskManager, 当提交作业需要执行时,才会按需创建
2. 作业提交
Client 用户可以通过 Flink 命令行 (Flink Client),向这个会话模式的集群提交任务,此时 JobGraph 会在 Flink Client 端生成,然后和用户 Jar 包一起通过 RestClient 上传
作业提交成功后,Dispatcher 会为每个作业启动一个 JobMaster,将 JobGraph 交给 JobMaster 调度执行
这两个步骤完成后,作业进入调度执行阶段
3.作业调度执行
K8s Session 模式集群下, ResourceManager 向 K8s Master 申请和释放 TaskManager,除此之外 作业的调度与执行和Yarn 模式一样
JobMaster 向 KubernetesResourceManager 申请 Slot
KubernetesResourceManager 从 Kubernetes 集群分配 TaskManager
- 每个
TaskManager都是具有唯一标识的 Pod KubernetesResourceManager会为TaskManager生成一份新的配置文件- 里面有
Flink Master上的service name作为地址 - 这样在
Flink Master failover之后TaskManager仍然可以重新连上
Kuberbetes 集群分配一个新的 Pod 后,在上面启动 TaskManager
TaskManager 启动后注册到 SlotManager
SlotManager 向 TaskManager 请求 Slot
TaskManager 提供 Slot 给 JobMaster 然后任务就被分配到 Slot 上运行
Graph
1. 流计算应用的 Graph 转换
- 对于流计算应用来说,首先要将
DataStreamAPI的调用转换为Transformation然后经过StreamGraph
-> JobGraph -> ExecutionGraph ->Flink 调度执行
2. 批计算应用的 Graph 转换
- 对于批计算应用来说,首先将
DataSetAPI的调用转换为OptimizedPlan然后转换为JobGraph, 批处理和流处理在JobGraph上完成了统一
3. Table & SQL API 的 Graph 转换
Blink Table Planner中,批处理和流处理都依赖于流计算体系,所以无论是 流计算还是批处理 与 流计算应用的Graph转换过程都是一样的- 在旧的
Flink Table Planner中,流计算依赖于DataStreamAPI,其转换过程就是流式计算应用的Graph转换过程 - 批处理依赖于
DataSetAPI, 所以其转换过程就是批式计算应用的Graph转换过程
- 在旧的
流图 (StreamGraph)
- 使用
DataStreamAPI开发的应用程序,首先被转换为Transformation - 然后被映射为
StreamGraph

StreamGraph|StreamNode|StreamEdge
StreamGraph 核心对象
StreamNode
StreamNode 是 StreamGraph 中的节点
- 从
Transformation转换而来,可以简单理解为 一个StreamNode表示一个算子 从逻辑上来说
StreamNode在StreamGraph中存在实体和虚拟的StreamNodeStreamNode可以有多个输入 也可以有多个输出
实体的
StreamNode会最终变成物理的算子- 虚拟的
StreamNode会附着在StreamEdge上
StreamEdge
StreamEdge 是 StreamGraph 中的边,用来连接两个 StreamNode
- 一个
StreamEdge可以有多个出边 , 入边 StreamEdge中包含了- 旁路输出
- 分区器
- 字段筛选输出 (与 SQL Select 中 选择字段的逻辑一样)
-
StreamGraph 生成过程
StreamGraph在Flink Client中生成,由Flink Client在提交的时候触发 Flink 应用的 main 方法
用户编写的业务逻辑组装成TransformationPipeline在最后调用StreamExecutionEnvironment.execute()的时候 开始触发StreamGraph的构建Code
StreamGraph入口StreamGraphGenerator生成StreamGraphStreamGraphGenerator转换Transformation- 单输入
Transformation的转换 (Node) - 虚拟
Transformation的转换 (Edge)
作业图 (JobGraph)
Job Graph 可以由流计算的 StreamGraph 和 批处理的 OptimizedPlan转换而来
流计算中: 在
StreamGraph的基础上进行了一些优化 通过OperatorChain机制 将算子合并起来- 在执行时调度在同一个 Task 线程上
- 避免数据的跨线程
- 跨网络的传递
Job Graph中 实现了 流和批的统一表达,从JobGraph的图里 可以看到,数据从上一个算子流到下一个算子的过程中,上游作为生产者提供了中间数据集(IntermediateDataset)而下游作为消费者需要JobEdgeJobEdge是一个通信管道,连接了上游生产的中间数据集和下游的JobVertex节点
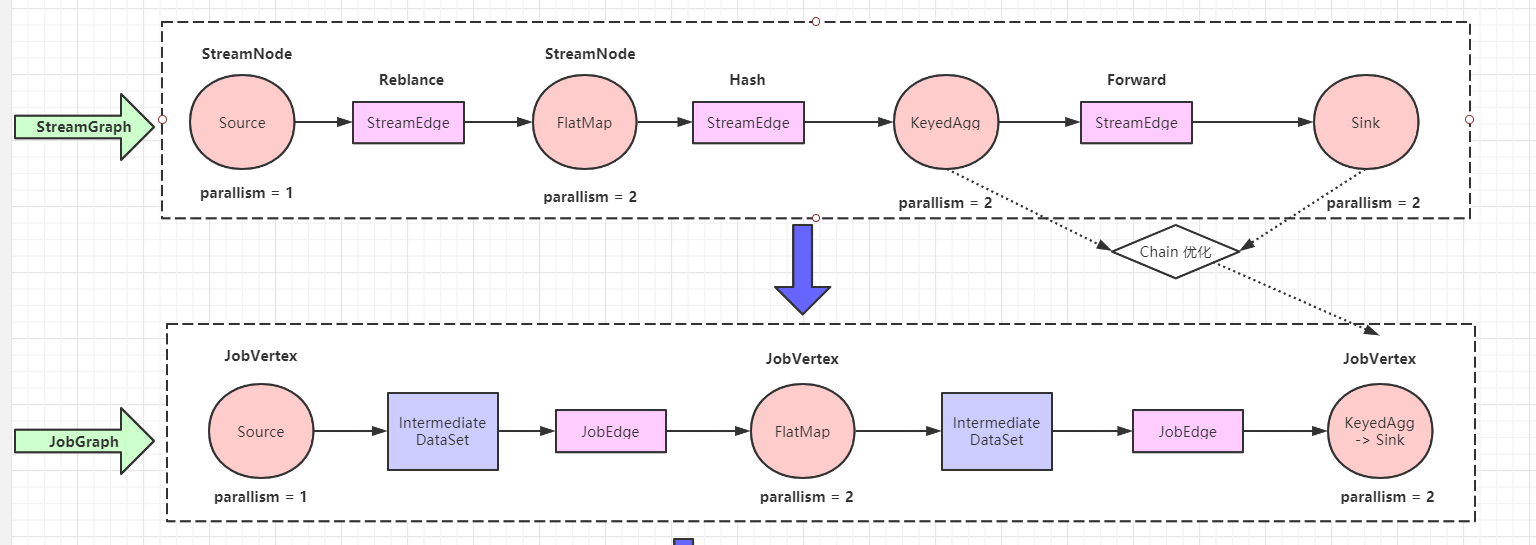
JobVertex|JobEdge|IntermediateDataSet
JobGraph 核心对象
JobVertex
经过算子融合优化后符合条件的多个 StreamNode 可能会融合在一起生成一个 JobVertex
即一个JobVertex 包含一个或多个算子,JobVertex 的输入是 JobEdge 输出是 IntermediateDataSet
JobEdge
JobEdge 是 JobGraph 中连接 JobVertex 和 IntermediateDataSet 的边,表示 JobGraph 中的一个数据流转通道
其上游数据源是 IntermediateDataSet 下游消费者是 JobVertex
即数据通过 JobEdge 由 IntermediateDataSet 传递给目标 JobVertex
IntermediateDataSet
中间数据集 IntermediateDataSet 是一种逻辑结构,用来表示 JobVertex 的输出
即该 JobVertex 中包含的算子会产生的数据集
不同的执行模式下,其对应的结果分区类型不同,决定了在执行时数据交换的模式IntermediateDataSet 的个数与该 JobVertex 对应的 StreamNode 的出边数量相同,可以是一个或多个
JobGraph 生成过程
JobGraph 的生成入口是在 StreamGraph 中,流计算的 JobGraph 和批处理的 JobGraph 的生成逻辑不同
- 对于流而言: 使用的是
StreamingJobGraphGenerator -
Code
StreamGraph 中触发生成 JobGraph
- StreamingJobGraphGenerator 生成 JobGraph 预处理
- 构建 JobGraph 的 点和边
- JobGraph 构建与 OperatorChain 优化
Operator chain 融合
为了更好的分布式执行,Flink 会尽可能地将多个算子融合在一起,形成一个 OperatorChain,一个 OperatorChain 在同一个 Task 线程内执行OperatorChain 内的算子之间,在同一个线程内通过方法调用的的方式传递数据 好处有:
- 减少线程之间的切换
- 减少消息的序列化/反序列化
- 无序借助内存缓冲区
- 无需通过网络在算子间传递数据
- 可以减少延迟的同时提高整体的吞吐量
Operator chain 条件
- 上下游的并行度一致
- 下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
- 上下游节点都在同一个 slot group 中
- 下游节点的 chain 策略为
ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS) - 上游节点的 chain 策略为
ALWAYS或HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD) StreamEdge数据分区方式是 forward- 用户没有禁用 chain
执行图 (Execution)
ExecutioGraph 是调度 Flink 作业执行的核心数据结构,包含了
- 作业中所有并行执行的 Task 信息
- Task 之间的关联关系
- 数据流转关系
StreamGraph JobGraph 在 Flink 客户端中生成,然后提交给 Flink 集群 JobGraph 到 ExecutionGraph 的转换在 JobMaster 中完成,转换过程中的重要变化有
1) 加入了并行度的概念,成为真正可调度的图结构
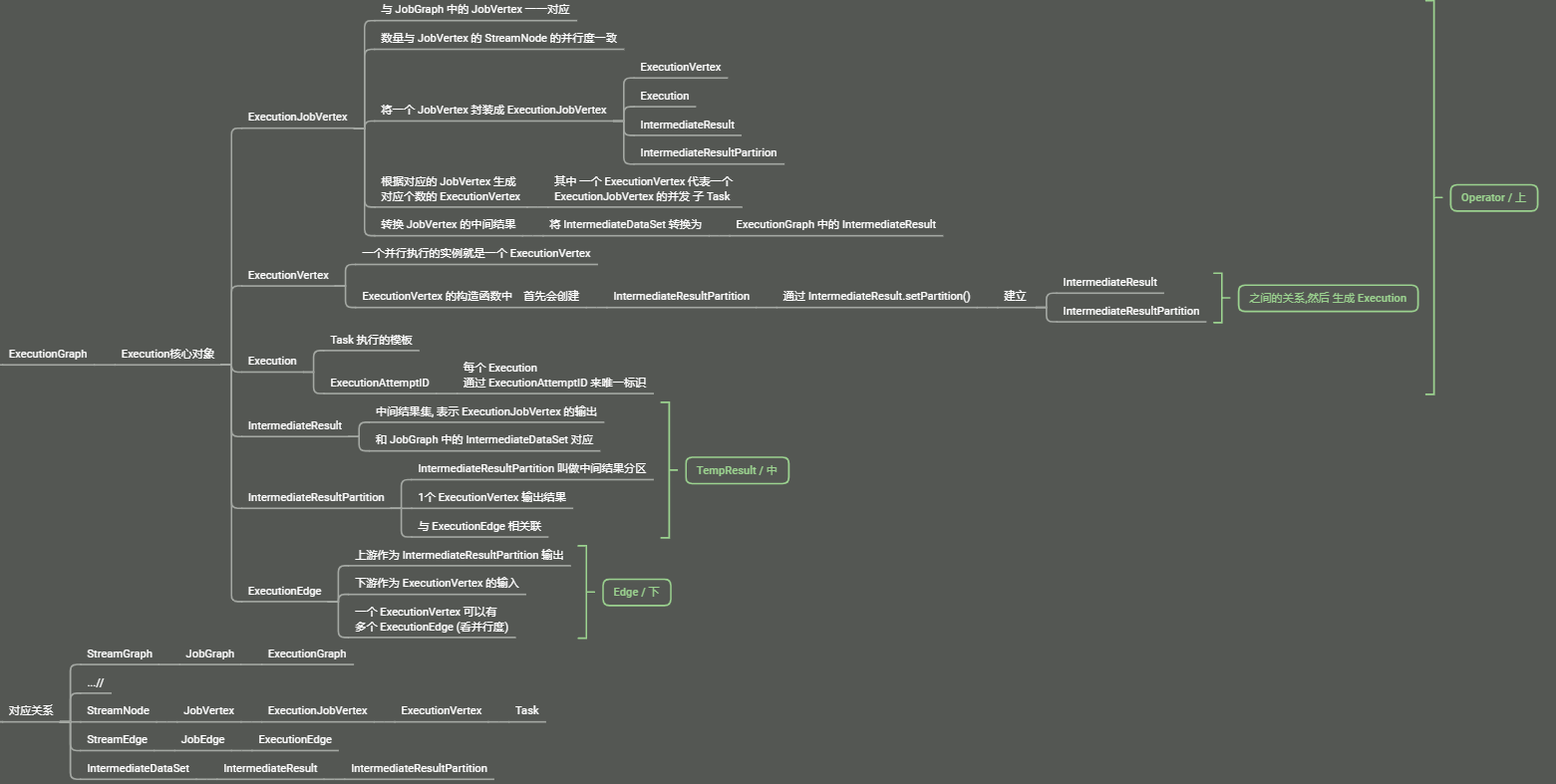
2) 与 JobGraph 的对应关系为:
JobVertex对应的ExecutionJobVertex和ExecutionVertexIntermediateDataSet对应的IntermediateResult和IntermediateResultPartition每个
Task对应一个ExecutionGraph的一个ExecutionVertexExecutionVertexTask用InputGate|InputChannel|ResultPartition对应了IntermediateResult和ExecutionEdge
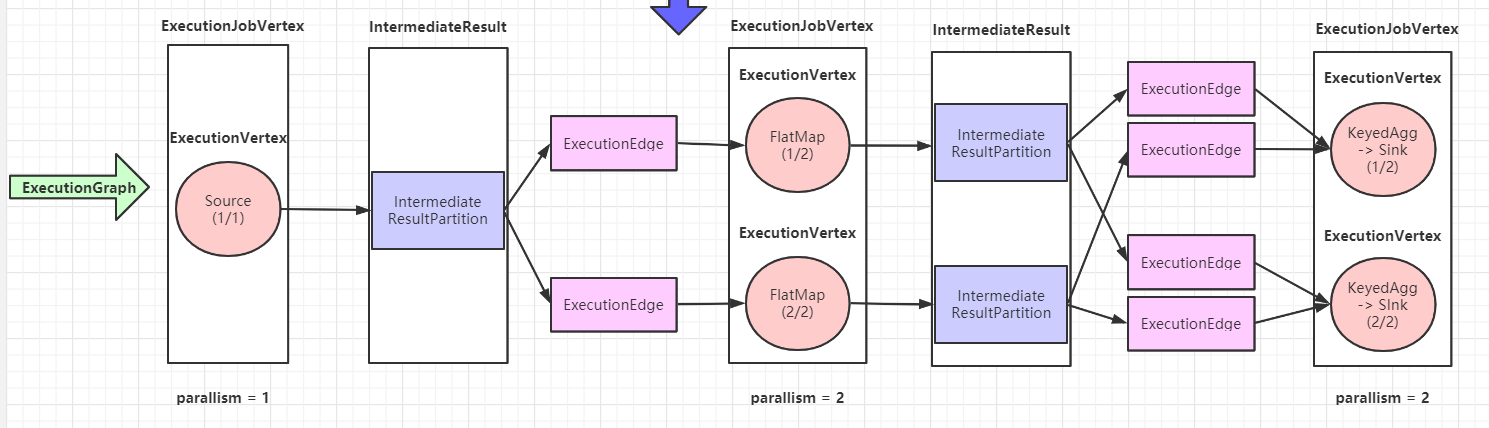
ExecutionGraph 核心对象
ExecutionJobVertex
ExecutionJobVertex 与JobGraph 中的 JobVertex 一一对应
数量与 JobVertex 中所包含的 StreamNode 的并行度一致
ExecutionJobVertex 用来将一个 JobVertex 封装成 ExecutionJobVertex
- 并依次创建
ExecutionVertexExecutionIntermediateResultIntermediateResultPartirion
在 ExecutionJobVertex 的构造函数中,首先是依据对应的 JobVertex 的并发度,生成对应个数的 ExecutionVertex
其中一个 ExecutionVertex 代表一个 ExecutionJobVertex 的并发子 Task
然后是将原来 JobVertex 的中间结果 IntermediateDataSet 转换为 ExecutionGraph 中的 IntermediateResult
ExecutionVertex
ExecutionJobVertex 中会对作业进行并行化处理,构造可以并行执行的实例,每一个并行执行的实例就是 ExecutionVertex
构建 ExecutionVertex 的同时, 也会构建 ExecutionVertex 的输出 IntermediateResult, 并且将 ExecutionVertex 的输出为 IntermediateResultPartition
ExecutionVertex 的构造函数中,首先会创建 IntermediateResultPartition 并通过 IntermediateResult.setPartition() 建立 IntermediateResult 和 IntermediateResultPartition 之间的关系,然后生成 Execution 并配置资源
Execution
Execution Vertex 相当于每个 Task 执行的模板,在真正执行的时候,会将 ExecutionVertex 中的信息包装为一个 Execution 执行一个 ExecutionVertex
JobManager 和 TaskManager 之间关于 Task 的部署 和 Task 执行状态的更新都是通过 ExecutionAttemptID 来标识 实例的, 在发生故障或者数据需要重新计算的情况下, ExecutionVertex 可能会有多个 ExecutionAttemptID
一个 Execution 通过 ExecutionAttemptID 来唯一标识
IntermediateResult
IntermediateResult 又叫做中间结果集,该对象是个逻辑概念,表示 ExecutionJobVertex 的输出和 JobGraph 中的 IntermediateDataSet 一一对应
同样一个 ExecutionJobVertex 可以有多个中间结果 取决于当前 JobVertex 有几个出边 (JobEdge)
一个中间结果集包含了多个中间结果分区 IntermediateResultPartition 其个数等于 该 JobVertex 的并发度,或者叫做算子的并行度
IntermediateResultPartition
IntermediateResultPartition 又叫做中间结果分区,表示1个 ExecutionVertex 输出结果与 ExecutionEdge 相关联
ExecutionEdge
ExecutionEdge 表示 ExecutionVertex 的输入,连接到上游产生的 IntermediateResultPartition
一个 Execution 对应于唯一的 1个 IntermediateResultPartition 和 1个 ExecutionVertex
一个 ExecutionVertex 可以有多个 ExecutionEdge
ExecutionGraph 生成过程
初始化作业调度器的时候,根据 JobGraph 生成 ExecutionGraph
在 ScheduleBase 的构造方法中触发构建,最终调用 SchedulerBase.createExecutionGraph() 触发实际的构建操作,使用 ExecutionGraphBuilder 构建 ExecutionGraph
Code
- ExecutionGraph 构建入口
- 构建 ExecutionGraph 的核心逻辑
- 构建 ExecutionGraph 节点
构造 ExecutionEdge
点对点连接 < DistributionPattern.POINTWISE >
一对一连接 并发的 Task 数量与分区数相等
多对一连接 下游的 Task 数量小与上游的分区数
一对多连接 下游的 Task 数量多于上游的分区数
全连接 < DistributionPattern.ALL_TO_ALL >
- shuffle

若有收获,就点个赞吧
0 人点赞
