Flink JobMaster 调度作业的 Task 到 TaskManager,所有 Task 启动后成功,进入执行状态,则整个作业进入执行状态.
从外部数据源开始读取数据,数据在 Flink Task DAG 中流转,处理完毕后,写出到外部存储. 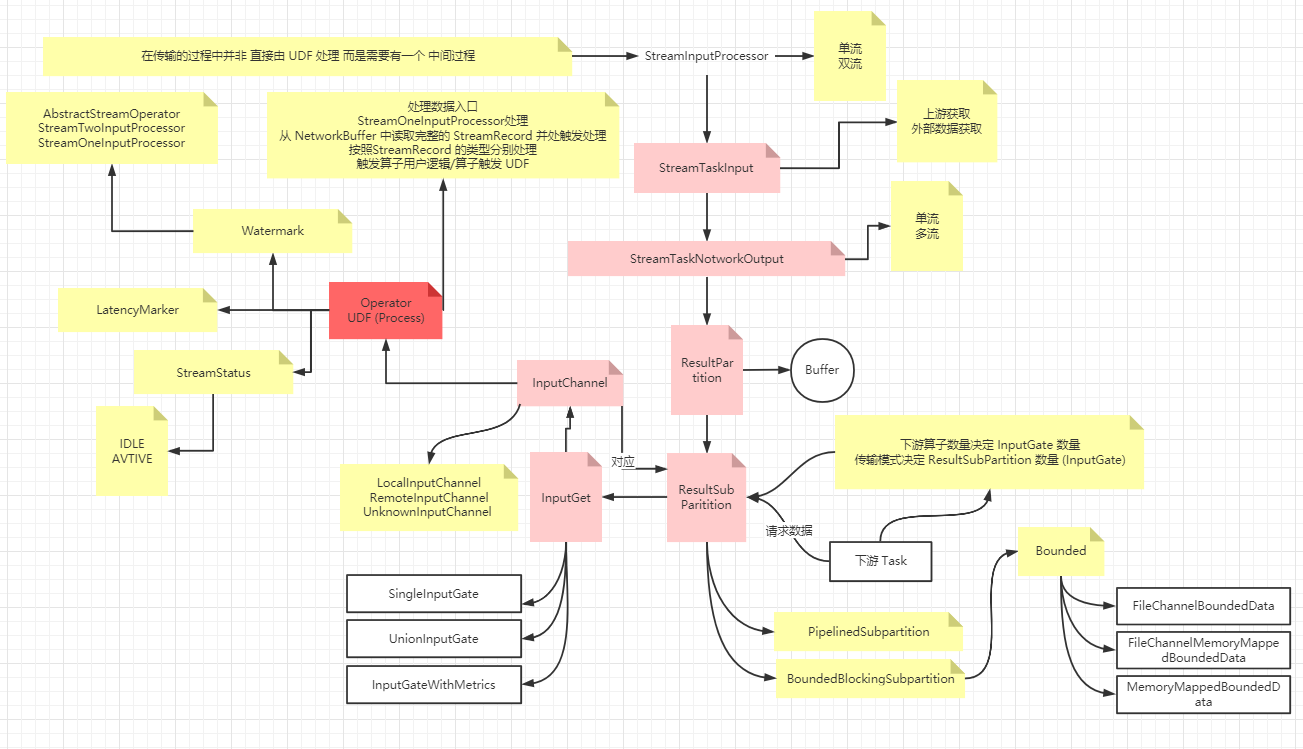
作业执行图
经过 Flink 的多层 Graph 转换之后,作业进入调度阶段,开始分发任务执行,最终会在集群中形成 执行 Graph
核心对象有
Task / ResultPartition & ResultSubPartition / InputGate & InputChannel
核心对象
输入处理器 <StreamInputProcessor>
输入处理器是 StreamInputProcessor , 是对 StreamTask 中读取数据行为的抽象,在其实现中要完成数据的读取、处理、输出给下游的过程,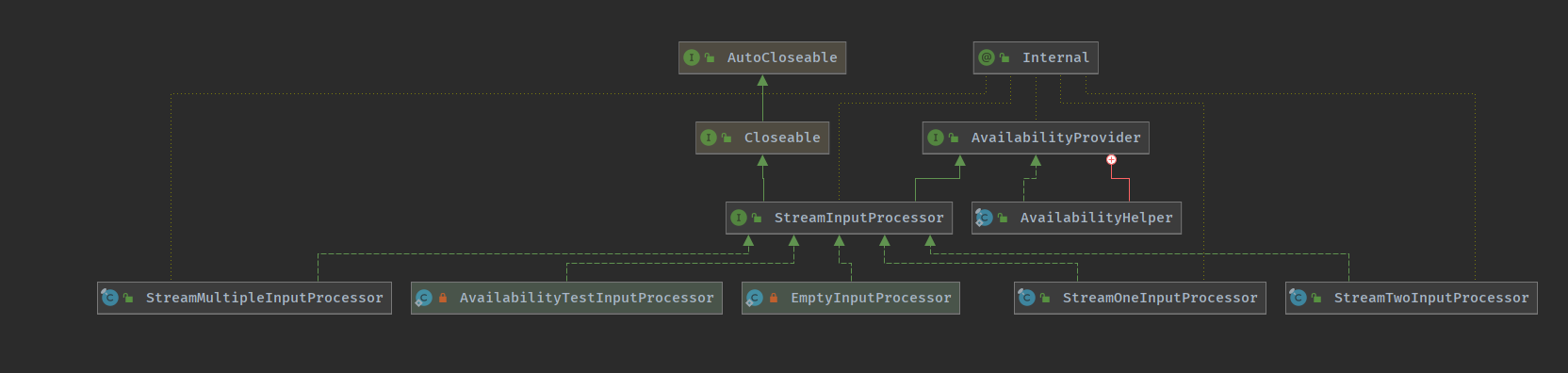
StreamOneInputProcessor : 用在 OneInputStreamTask 中 , 只有 1 个上游输入StreamTwoInputProcessor : 用在 TwoInputStreamTask 中, 有 2 个上游输入
Task 输入 <StreamTaskInput >
StreamTaskInput负责Task输入,是StreamTask的数据输入的抽象
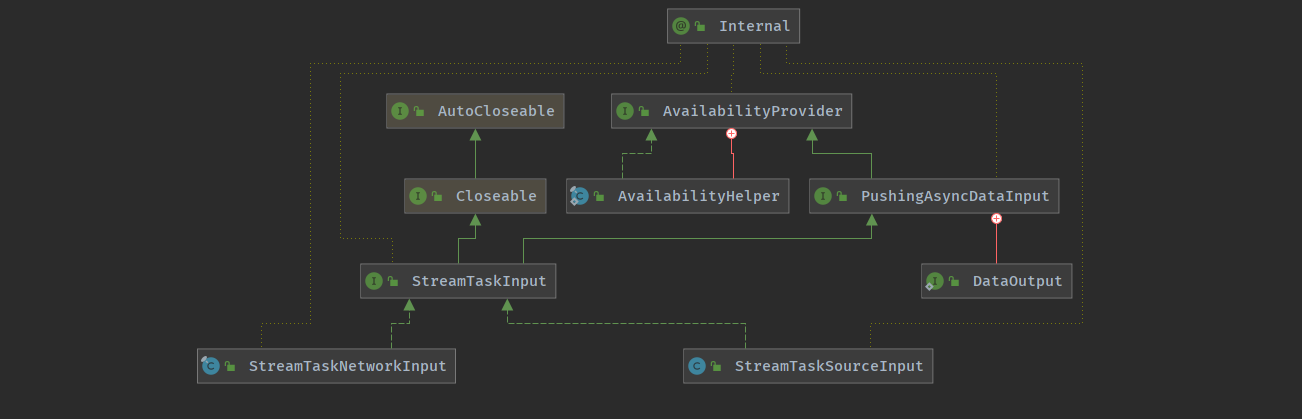
对于 Flink 中的 StreamTask 而言, 数据读取的行为有两种
StreamTaskNetworkInput (从上游 Task 获取数据,使用 InputGate 作为底层读取数据 )StreamTaskSourceInput (从外部数据源获取数据,使用 SourceFunction 读取数据, 交给下游的 Task)
Task 输出 <StreamTaskNetworkOutput >
StreamTaskNetworkOutput负责Task输出,是StreamTask的数据输出的抽象

StreamTaskNetworkOutput 只是负责将数据交给算子来进行处理,实际的数据写出是在算子层上执行的StreamTaskNetworkOutput 也有对应于单流和双流输入的两种实现,作为私有的内部类定义在 OneInputStreamTask 和 StreamTwoInputProcessor 中
结果分区 <ResultPartition >
ResultPartition (结果分区) , 用来表示作业的单个 Task 产生的数据
ResultPartition 是运行时的实体, 与 ExecutionGraph 中的中间结果分区对应 (IntermediateResultPartition)
一个 ResultPartition 是一组 Buffer 实例, ResultPartition 由 ResultSubPartition 组成-
ResultSubPartition用来进一步将ResultPartition进行切分- 切分成 (与下游子任务的并行度/数据分发模式 决定) 数量的
ResultSubPartition
下游子任务消费上游子任务产生的 ResultPartition , 在实际请求的时候
- 是向上游请求
ResultSubPartition - 并不是请求整个
ResultPartition - 请求的方式有远程请求和本地请求两种
ResultPartition
对于流上的作业而言
ResultPartition在作业的执行过程中会一直存在
对于批而言
- 上游
Task输出ResultPartition - 下游
Task消费上游的ResultPartition消费完毕之后 - 上游的
ResultPartition就没有什么用了,需要进行资源回收,所以 Flink 增加了ReleaseOnConsumptionResultPartition
结果子分区 <ResultSubPartition >
ResultSubPartition (结果子分区) ,结果子分区是结果分区的一部分,负责存储实际的 Buffer
ResultPartition 是一个 Task 的输出,上游 Task 跟 下游 Task 之间的数据交换经常是一对多的关系,所以 Flink 在输出端将 ResultPartition 进行了切分. (下游如果有5个 Task , ResultPartition 就会生成5个 ResultSubPartition )
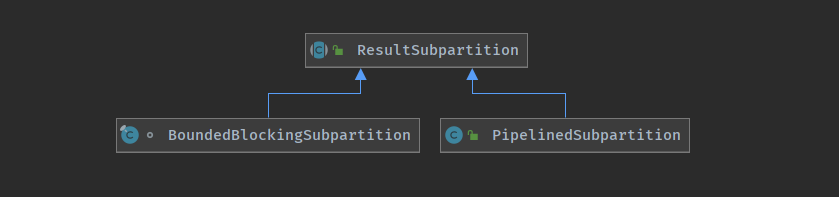
结果子分区有 PipelinedSubpartition 跟 BoundedBlockingSubpartition (流/批)
PipelinedSubpartitionPipelinedSubpartition 是纯内存型的结果子分区,只能被消费一次
当向 PipelinedSubpartition 中添加一个完成的 BufferConsumer 或者添加下一个 BufferConsumer 时 (默认前一个 BufferConsumer 是完成的), 会通知 PipelinedSubpartitionView 新数据到达,可以消费了
BoundedBlockingSubpartition
用作对批处理 Task 的计算结果的数据存储,其行为是阻塞式的,需要等待上游所有的数据处理完毕,然后下游才开始消费数据,可以消费 1 次 或者多次
- 这种
ResultSubPartition有多种存储形式,可以保存在文件中或者内存映射文件中
BoundedBlockingSubpartition不是线程安全的, Flink 网络栈是单线程模型,添加、刷新、完成都由单个Writer完成
- 如果在写入阶段需要
release, 则同样由该Writer的线程负责执行,所以能确保安全在实现中,支持多个并发的
Reader但是需要确保Reader是单线程的
ResultSubPartition 是持有数据的容器,其中的 BoundedData 属性是实际的数据操作接口,BoundedData 提供了几种不同的实现
有限数据集
BoundedData 定义了存储和读取批处理中建计算结果数据集的阻塞式接口, BoundedBlockingSubPartition 使用 BoundedData 接口来实现中间结果集的访问BoundedData 有 3 个不同的实现,分别对应于不同的 Buffer 的存储方式.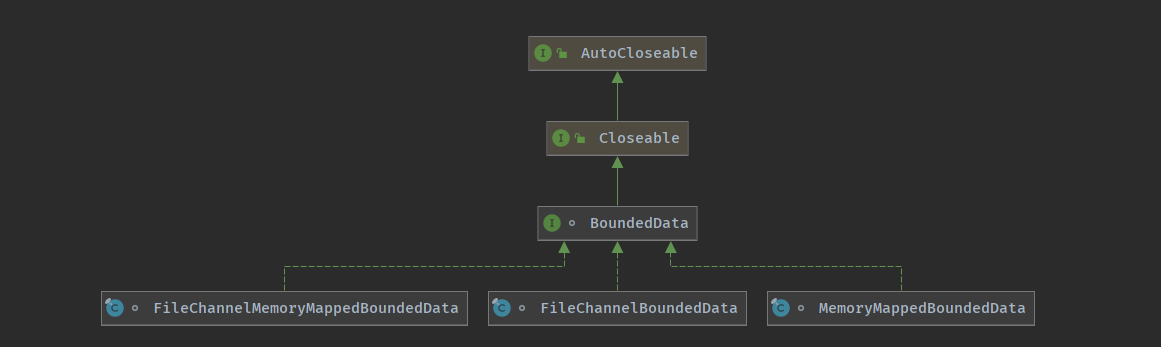
FileChannelBoundedData
- 使用
Java NIO的FileChannel写入数据和读取文件
FileChannelMemoryMappedBoundedData
- 使用
FileChannel写入数据到文件,使用内存映射文件读取数据
MemoryMappedBoundedData
- 使用内存映射文件写入、读取, 全都是内存操作
内存映射文件 (Memory-Mapped File) 是将一段虚拟内存逐步映射于一个文件,使得应用程序处理文件如同访问主内存(但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作),内存映射文件与磁盘的真正交互由操作系统负责
Java.io 基于流的文件读写
- 读文件会产生2次数据复制
- 首先是从硬盘复制到操作系统内核
- 然后从操作系统内核复制到用户态的应用程序
- 写文件也类似
Java.nio
- 一般情况下只有一次复制
- 内存分配在操作系统内核
- 应用程序访问的就是操作系统的内核内存空间
- 比基于流进行文件读写快几个数量级
FileChannel 是直接读写文件,与内存映射文件相比
FileChannel对小文件的读写效率高- 内存映射大文件则是针对大文件效率高
输入网关
InputGate —-> 输入网关,是 Task 的输入数据的封装,和 JobGraph 中的 JobEdge 一一对应,对应于上游的 ResultPartition
InputGate 中负责实际数据消费的是 InputChannel , 是 InputChannel 的容器,用于读取中间结果(IntermediateResult) 在并行执行时由上游 Task 产生的一个或多个结果分区 (ResultPartition)
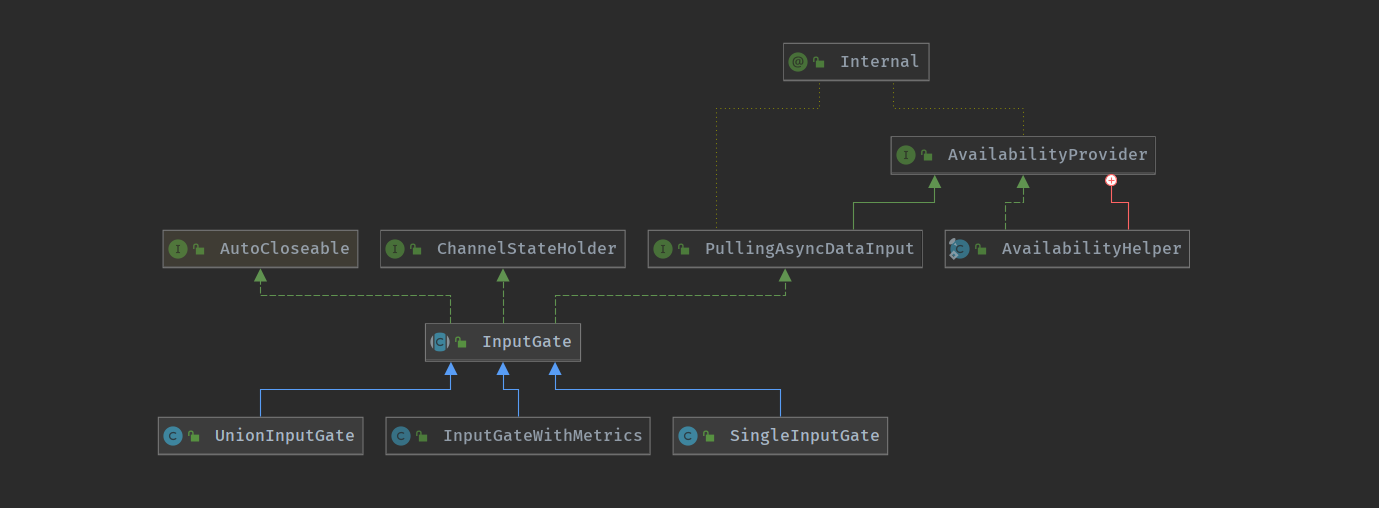
SingleInputGate 是消费 ResultPartition 的实体,对应于一个 IntermediateResult .
UnionInputGate 主要充当 InputGate 容器的角色,将多个 InputGate 联合起来,当做一个 InputGate.
- 一般是对应于上游的多个输出类型相同的
IntermediateResult,对应于多个上游的IntermediateResult.
InputGateWithMetrics 本质上来说就是一个 InputGate + 监控统计,统计 InputGate 读取的数据量,单位为 Byte
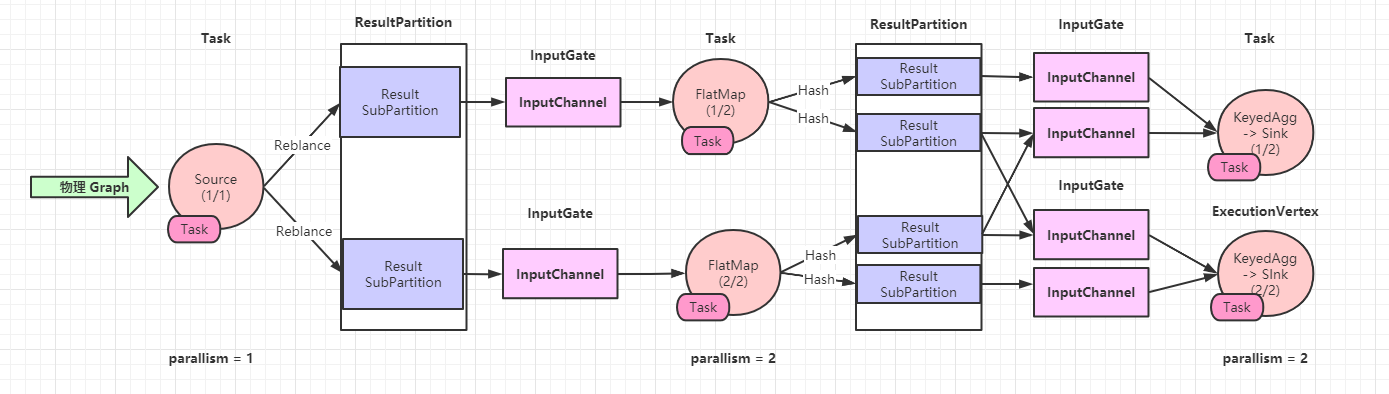
Flink 作业在集群中并行执行时,其并行状态下的逻辑关系,中间结果集会按照并行度切分为与并行度个数相同的结果分区,每个结果分区又进一步切分为一个或者多个结果子分区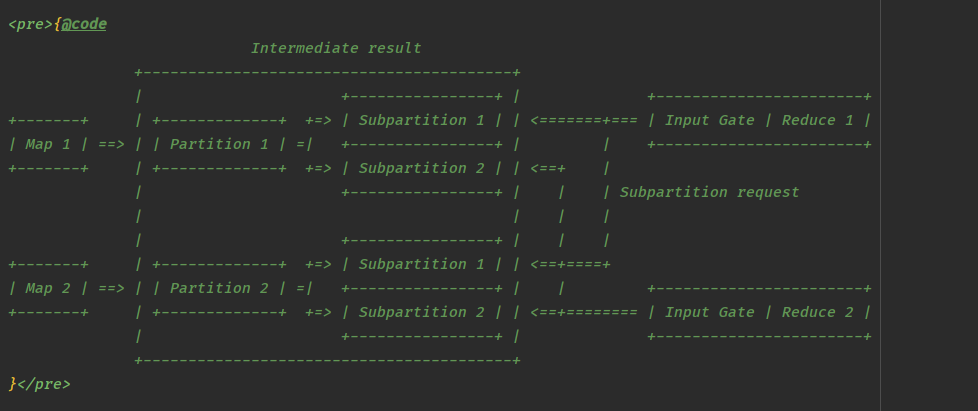
作业的并行度为 2, 有两个 map 字任务分切产生数据,生成两个 ResultPartition (ResultSubPartition1 , ResultSubPartition2)
每个 ResultPartition 又被切分为两个 ResultSubPartition
ResultSubPartition的数量与下游Reduce任务的子任务个数相同
每个 Reduce 的子任务都有一个 InputGate
- 负责从上游的所有
ResultPartition中获取该子任务所需要的ResultSubPartition
输入通道
InputChannel —-> 输入通道
每个 InputGate 会包含一个以上的 InputChannel , 和 ExecutionEdge 一一对应,也和结果子分区一对一相连,一个 InputChannel 接收一个结果子分区的输出
RemoteInputChannel
- 对应于远程的结果子分区的输入通道,用来表示跨网络的数据交换,底层基于
Netty
LocalInputChannel
- 对应于本地结果子分区的输入通道,用来在本地线程内不同线程之间的数据交换
UnknownInputChannel
- 一种位于占位目的的输入通道,需要占位通道是因为暂未确定向对于
Task生产者的位置,再确定上游Task位置之后- 如果位于不同的
TaskManager则替换为RemoteInputChannel - 如果位于相同的
TaskManager则替换为LocalInputChannel
- 如果位于不同的
Task
之前的 Task 执行模型依赖于锁机制,可能导致多个潜在的线程并发访问其内部状态
- 比如事件处理以及检查点的触发线程.
当前,他们都通过一个全局锁 (检查点锁) 来保证彼此互斥,这种机制有一些劣势
锁对象必须在类的各种互斥访问的代码段中进行传递
- 代码可读性很差
- 使用不当或者漏用容易造成难以定位的问题
设计不够优雅,锁对象暴露给了面向用户的 API (
SourceContext)
新的执行模型 类似与基于 (Mailbox) 单线程执行模型,取代现有的多线程模型
- 所有的并发操作都通过队列进行排队 (
Mailbox),单线程 (Mailbox线程) 依次处理,避免并发操作
Task 处理数据
- 启动
Task进入执行状态,开始读取数据,当有可消费的数据时,则持续读取数据
/ StreamTask /
protected void processInput(MailboxDefaultAction.Controller controller) throws Exception {InputStatus status = inputProcessor.processInput();if (status == InputStatus.MORE_AVAILABLE && recordWriter.isAvailable()) {return;}if (status == InputStatus.END_OF_INPUT) {controller.allActionsCompleted();return;}CompletableFuture<?> jointFuture = getInputOutputJointFuture(status);MailboxDefaultAction.Suspension suspendedDefaultAction = controller.suspendDefaultAction();assertNoException(jointFuture.thenRun(suspendedDefaultAction::resume));}
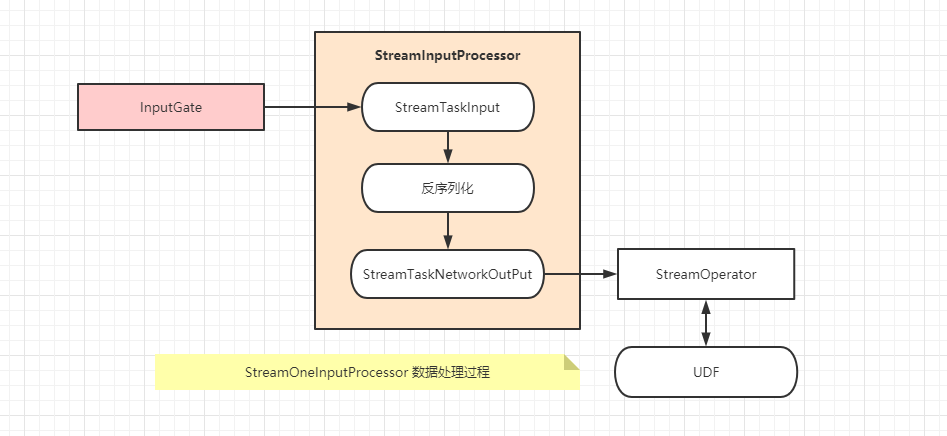
StreamInputProcessor是数据读取,处理,输出的高层逻辑的载体
- 由其负责触发数据时读取,并交给算子处理,然后输出
/ StreamOneInputProcessor /
@Overridepublic InputStatus processInput() throws Exception {InputStatus status = input.emitNext(output);if (status == InputStatus.END_OF_INPUT) {endOfInputAware.endInput(input.getInputIndex() + 1);}return status;}
StreamInputProcessor实际上将具体的数据读取工作交给了StreamTaskInput
- 当读取了完整的记录之后就开始向下游发送数据
在发送数据的过程中,调用算子进行数据的处理** ```java public StreamOneInputProcessor(
StreamTaskInput<IN> input, DataOutput<IN> output, BoundedMultiInput endOfInputAware) {this.input = checkNotNull(input);this.output = checkNotNull(output);this.endOfInputAware = checkNotNull(endOfInputAware);
}
**
```java
@Override
public InputStatus emitNext(DataOutput<T> output) throws Exception {
while (true) {
// get the stream element from the deserializer
if (currentRecordDeserializer != null) {
DeserializationResult result;
try {
result = currentRecordDeserializer.getNextRecord(deserializationDelegate);
} catch (IOException e) {
throw new IOException(
String.format("Can't get next record for channel %s", lastChannel), e);
}
if (result.isBufferConsumed()) {
currentRecordDeserializer.getCurrentBuffer().recycleBuffer();
currentRecordDeserializer = null;
}
if (result.isFullRecord()) {
processElement(deserializationDelegate.getInstance(), output);
return InputStatus.MORE_AVAILABLE;
}
}
Optional<BufferOrEvent> bufferOrEvent = checkpointedInputGate.pollNext();
if (bufferOrEvent.isPresent()) {
// return to the mailbox after receiving a checkpoint barrier to avoid processing of
// data after the barrier before checkpoint is performed for unaligned checkpoint
// mode
if (bufferOrEvent.get().isBuffer()) {
processBuffer(bufferOrEvent.get());
} else {
processEvent(bufferOrEvent.get());
return InputStatus.MORE_AVAILABLE;
}
} else {
if (checkpointedInputGate.isFinished()) {
checkState(
checkpointedInputGate.getAvailableFuture().isDone(),
"Finished BarrierHandler should be available");
return InputStatus.END_OF_INPUT;
}
return InputStatus.NOTHING_AVAILABLE;
}
}
}
- 读取到完成数据记录之后,根据其类型进行不同的逻辑处理
/ StreamTaskNetworkInput /
private void processElement(StreamElement recordOrMark, DataOutput<T> output) throws Exception {
if (recordOrMark.isRecord()) {
output.emitRecord(recordOrMark.asRecord());
} else if (recordOrMark.isWatermark()) {
statusWatermarkValve.inputWatermark(
recordOrMark.asWatermark(), flattenedChannelIndices.get(lastChannel), output);
} else if (recordOrMark.isLatencyMarker()) {
output.emitLatencyMarker(recordOrMark.asLatencyMarker());
} else if (recordOrMark.isStreamStatus()) {
statusWatermarkValve.inputStreamStatus(
recordOrMark.asStreamStatus(),
flattenedChannelIndices.get(lastChannel),
output);
} else {
throw new UnsupportedOperationException("Unknown type of StreamElement");
}
}
- 读取到数据,对于数据记录(
StreamRecord) ,会在算子中包装用户的业务逻辑,即时使用了DataStream编写的UDF
/ OneInputStreamTask /
@Override
public void emitRecord(StreamRecord<IN> record) throws Exception {
numRecordsIn.inc();
operator.setKeyContextElement1(record);
operator.processElement(record);
}
- 进入算子内部,由算子去执行用户编写的业务逻辑 (以
FlatMap为例)
/ StreamFlatMap /
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
collector.setTimestamp(element);
userFunction.flatMap(element.getValue(), collector);
}
- 在算子中处理完毕,数据要交给下一个算子或者
Task进行计算,此时就会涉及 3 种 算子之间数据传递的情形
OperatorChain内部的数据传递,发生OperatorChain所在本地线程内- 同一个
TaskManager不同Task之间传递数据,发生在同一个JVM的不同线程之间 - 不同
TaskManager的Task之间传递, 跨JVM的数据传递,需要使用跨网络的通信,即便TaskManager位于同一个物理机上,也会使用网络协议进行数据传递
Task 处理 Watermark
Task 处理 Watermark 的时候分为两种
- 一种是在
OneInputStreamOperator(单流输入算子) - 一种是在
TwoInputStreamOperator(双流输入算子)
单流输入逻辑比较简单,如果有定时器服务,则判断是否触发计算,并将 Watermark 发往下游
/ AbstractStreamOperator /
public void processWatermark(Watermark mark) throws Exception {
if (timeServiceManager != null) {
timeServiceManager.advanceWatermark(mark);
}
output.emitWatermark(mark);
}
双流输入从上游两个算子中接收到两个 Watermark ,input1Watermark1 表示第一个输入流的 Watermark ,input1Watermark2 表示第二个输入流的 Watermark,选择其中较小的那一个 Math.min(input1Watermark, input2Watermark) 作为当前的 Watermark , 之后的处理逻辑与单流输入一致.
/ StreamTwoInputProcessor /
@Override
public void emitWatermark(Watermark watermark) throws Exception {
inputWatermarkGauge.setCurrentWatermark(watermark.getTimestamp());
if (inputIndex == 0) {
operator.processWatermark1(watermark);
} else {
operator.processWatermark2(watermark);
}
}
/ AbstractStreamOperator /
public void processWatermark1(Watermark mark) throws Exception {
input1Watermark = mark.getTimestamp();
long newMin = Math.min(input1Watermark, input2Watermark);
if (newMin > combinedWatermark) {
combinedWatermark = newMin;
processWatermark(new Watermark(combinedWatermark));
}
}
public void processWatermark2(Watermark mark) throws Exception {
input2Watermark = mark.getTimestamp();
long newMin = Math.min(input1Watermark, input2Watermark);
if (newMin > combinedWatermark) {
combinedWatermark = newMin;
processWatermark(new Watermark(combinedWatermark));
}
}
Task 处理 StreamStatus
StreamStatus 是 StreamElement 的一种,用来标识 Task 是活动状态还是空闲状态
当 SourceStreamTask 或一般的 StreamTask 处理空间状态 (IDLE) , 不会向下游发送数据或者 Watermark 时,就向下游发送 StreamStatus.IDLE 状态告知下游,依次向下传递
当恢复向下游发送数据或者 Watermark 前,首先发送 StreamStatus.ACTIVE 状态告知下游
- 如何判断 是 IDLE 还是 ACTIVE 状态
StreamStatus 状态变化在 SourceFunction 中产生
SourceTask如果读取不到输入数据,则认为是IDLE状态,如果Kafka Consumer未分配到数据分区 (Partition),则不会读取数据- 如果需要重新读取数据,则认为是
Active状态
/ FlinkKafkaConsumerBase /
@Override
public void run(SourceContext<T> sourceContext) throws Exception {
if (subscribedPartitionsToStartOffsets == null) {
throw new Exception("The partitions were not set for the consumer");
}
当 StreamTask 的所有上游 Task 全部处理 IDLE 状态的时候,认为这个 StreamTask 处于 IDLE 状态
只要有一个上游的 SourceTask 是 Active 状态,StreamTask 就是 Active 状态
- StreamStatus 对 WaterMark 的影响
由于 SourceTask 保证在 IDLE 状态和 Active 状态之间不会发送数据元素,所以 StreamTask 可以在不需要检查当前状态的情况下安全地处理和传播收到数据元素.
由于在 DataFlow 的任何中间节点都可能产生 watermark , 所以当前 StreamTask 在发送 WaterMark 之前必须检查当前算子的状态,如果当前的状态是 IDLE ,则 Watermark 阻塞不会向下游发送.
如果 StreamTask 有多个上游输入
- 上有输入的
Watermark状态为IDLE - 恢复到
Active状态,但是其Watermark落后与当前算子的最小Watermark,此时需要忽略这个特殊的Watermark- 在判断是否需要向前推进
Watermark和向下游发送的时候,这个特殊的Watermark不起作用
- 在判断是否需要向前推进
Task 处理 LatencyMarker
LatencyMarker 用来近似估计数据从读取到写出之间的延迟,但是并不包含计算的延迟.
在算子中只能将数据记录交给 UDF 执行,所以收到 LatencyMarker 就直接交给下游了.
/ AbstractStreamOperator /
protected void reportOrForwardLatencyMarker(LatencyMarker marker) {
// all operators are tracking latencies
this.latencyStats.reportLatency(marker);
// everything except sinks forwards latency markers
this.output.emitLatencyMarker(marker);
}

若有收获,就点个赞吧
0 人点赞
