问题待思考
状态数据的存储和访问
-
状态数据的备份和恢复
作业失败是无法避免的,那么如何高效地将状态数据保存下来,避免状态备份时降低集群的吞吐量
-
状态数据的划分和动态扩容
作业在集群内部并行执行,对于作业的 Task 而言如何使用统一的方式对状态数据做切分
在作业修改并行度导致 Task 数据改变的时候,如何确保将之前的状态正确的恢复到 Task
状态数据的清理
状态的使用都是有成本的,并且状态并不是永久有效的,对于过期的状态内部是怎么管理的
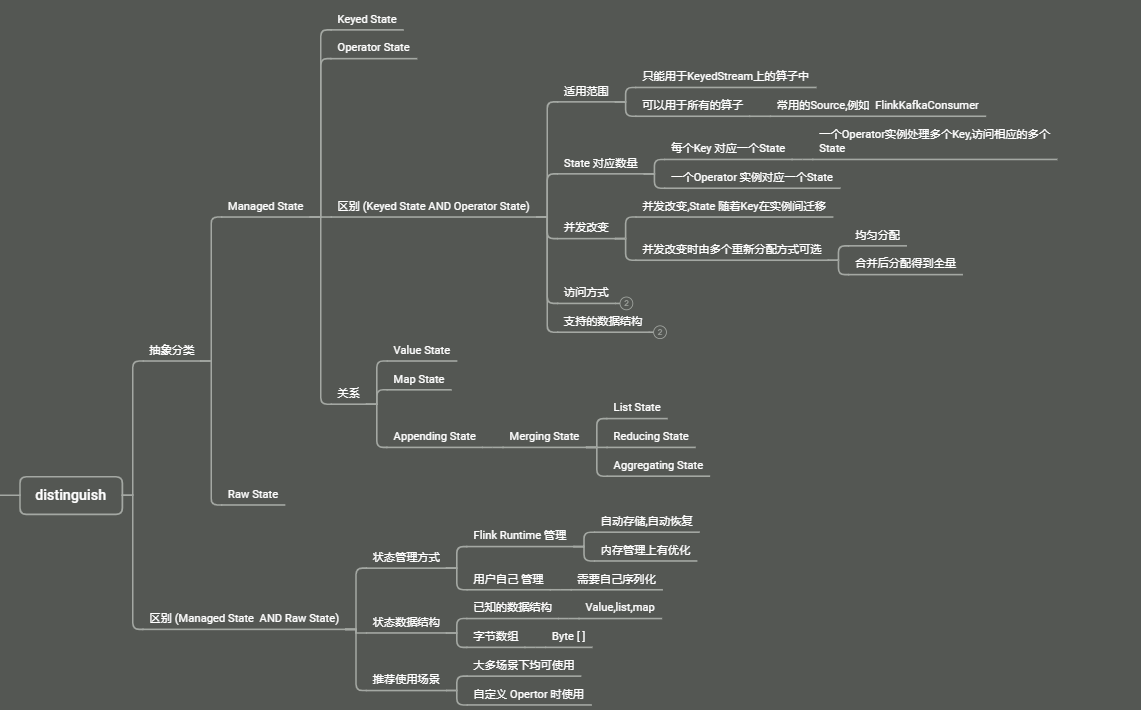
原始状态 与 托管状态
原始状态
- 用户自己定义的State Flink 在做快照时, 把整个State 当做一个整体, 需要开发者自己管理,使用 byte 数组来进行状态的读写
托管状态
- 由 Flink 框架管理的 State, 其序列化与反序列化都是由 Flink 框架提供支持, 无需用户感知/干预
状态描述
- State 是暴露给用户的,需要有一些属性指定
- State 名称
- State 中所存储数据的详细信息(序列化器与反序列化)
- State 的过期时间等
- 在对应的状态后端 (
StateBackend) 中,会调用对应的create方法获取到StateDescriptor中的值,在 Flink 中的状态描述叫做StateDescriptor
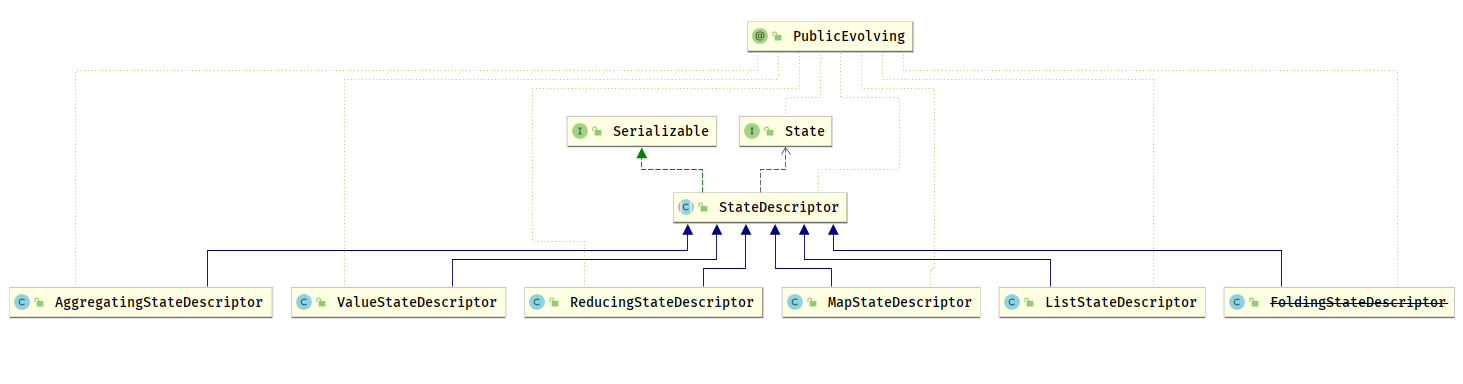
对于每一类 State, Flink 内部都设计了对应的 StateDescriptor,在任何使用 State 的地方,都需要通过 StateDescriptor 描述状态的信息
运行时,在RichFunction 与 ProcessFunction 中.通过 RuntimeContext 上下文对象,使用 StateDescriptor 从状态后端(StateBackend) 中获取实际的State 实例,然后在开发者编写的 UDF 中使用这个 State
StateBackend中有对应则返回现有的State- 没有则创建一个新的
State
广播状态
广播状态在 Flink 中叫做 BroadcastState, 在广播状态模式中使用
- 所谓广播状态模式,就是来自一个流的数据需要被广播到所有下游任务,在算子本地存储
- 在处理另一个流的时候,依赖与广播的数据
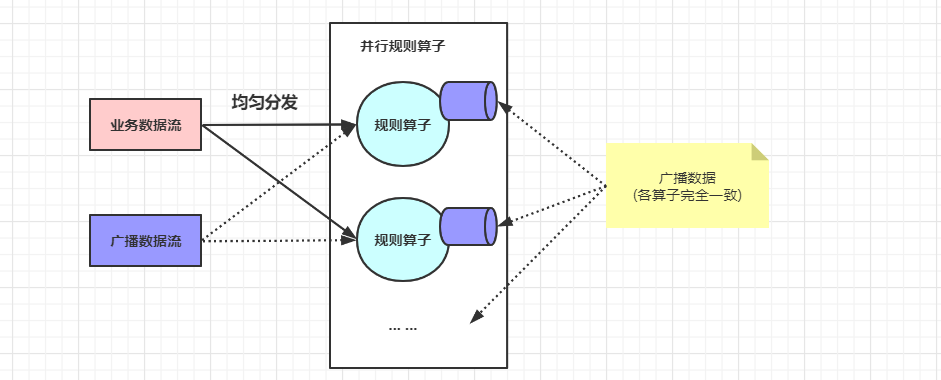
- 规则算子将规则缓存在本地内存中,在业务数据流记录到来时,便能够使用规则 (广播) 处理数据
- 广播
State必须是MapState, 广播状态模式需要使用广播函数进行处理,广播函数提供了处理广播数据流和普通数据流的接口
状态接口
在Flink 中使用状态,有两种典型场景
- 使用状态本身存储,写入,更新数据 (状态操作接口)
从
StateBackend获取状态对象本身 (状态访问接口)状态操作接口
Flink 中的 State 分两类
开发者使用 (面向应用开发者的 State 接口)
- 面向开发者的接口要保持稳定,考虑 Flink 升级的兼容性
- Flink 框架本身使用 (内部 State 接口)
- Flink 内部引擎使用,提供了更多 State 操作方法,可以根据需求灵活的扩展改进
1. 面向应用开发者的 State 接口
面向开发的 State 接口 只提供了对 State中数据的添加 / 更新 / 删除等基本操作接口
用户无法访问状态的其他运行时所需要的信息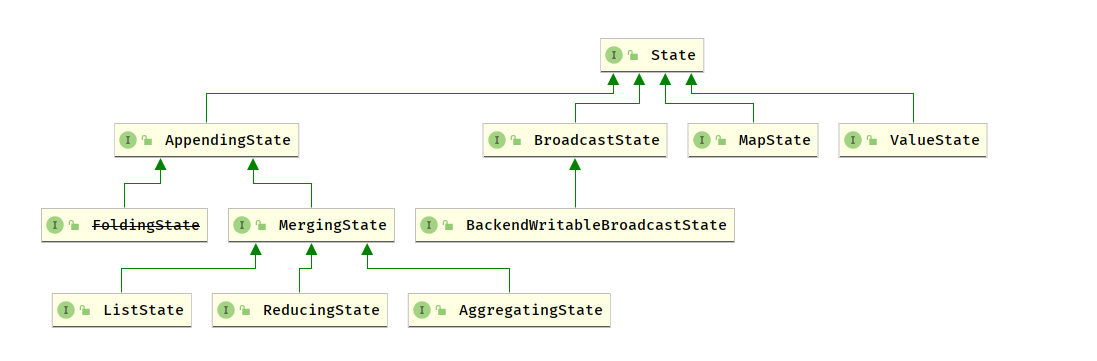
点击前往 查看详情
2. 内部 State 接口
内部 Flink 接口是给 Flink 接口用的,除了对 State 中数据的访问之外,还提供了内部运行时信息接口
State中数据序列化器State命名空间 (nameSpace)State命名空间的序列化器State命名空间合并的接口
内部 State 接口的命名非方式为 InternalxxxState, 内部 State 接口的体系非常复杂
/*** The {@code InternalKvState} is the root of the internal state type hierarchy, similar to the* {@link State} being the root of the public API state hierarchy.*//** 内部状态类型层次结构的根*/
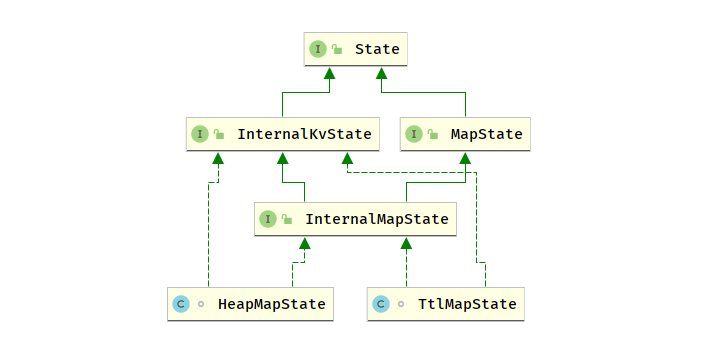
public interface InternalKvState<K, N, V> extends State {TypeSerializer<K> getKeySerializer();TypeSerializer<N> getNamespaceSerializer();TypeSerializer<V> getValueSerializer();void setCurrentNamespace(N namespace);byte[] getSerializedValue(final byte[] serializedKeyAndNamespace,final TypeSerializer<K> safeKeySerializer,final TypeSerializer<N> safeNamespaceSerializer,final TypeSerializer<V> safeValueSerializer) throws Exception;StateIncrementalVisitor<K, N, V> getStateIncrementalVisitor(int recommendedMaxNumberOfReturnedRecords);interface StateIncrementalVisitor<K, N, V> {boolean hasNext();Collection<StateEntry<K, N, V>> nextEntries();void remove(StateEntry<K, N, V> stateEntry);void update(StateEntry<K, N, V> stateEntry, V newValue);}}
问题
那么有了状态之后,在开发者自定义的 UDF 中是如何访问状态的
状态保存在 StateBackend中,StateBackend 有三种不同类型,状态又划分为 OperatorState 跟 KeyedState,如果直接使用就会比较麻烦,所以 Flink 抽象了两个状态访问接口
OperatorStateStoreKeyedStateStore有了这两个接口,用户在 UDF 中就无须考虑到底是哪种
StateBackendOperatorStateStore
KeyedStateStore
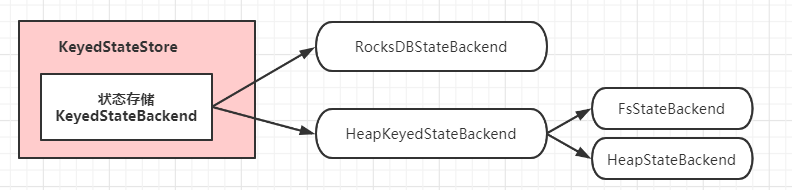
KeyedStateStore中获取/创建 状态都交给了具体的StateBackend来处理,KeyedStateStore更像是一个代理
状态存储
Flink 中无论哪种类型的 State, 都需要持久化到可靠的存储中去,才具备容错的能力,Flink 中 通过 StateBackend 来达到这种期望 StateBackend 需要具备的能力有:
- 在计算过程中提供访问
State的能力,并且在业务逻辑中能够使用StateBackend的接口读取数据 - 能够将
State持久化到外部存储, 提供容错能力
根据使用场景的不同,Flink 内置了 3种 StateBackend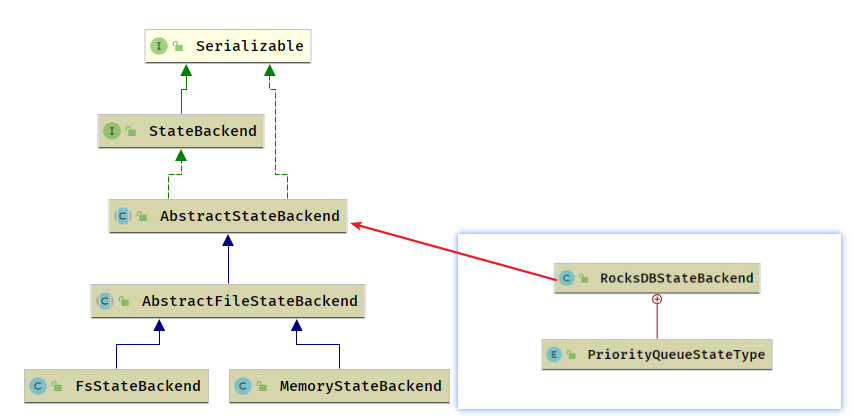
1) : 纯内存: MemoryStateBackend , 时用于验证/测试/不推荐生产环境
2) : 内存 + 文件: FsStateBackend / DefaultOperatorStateBackend,适用于周期较长规模较大的数据
3) : RocksDB : RocksDBStateBackend ,适用于周期较长规模较大的数据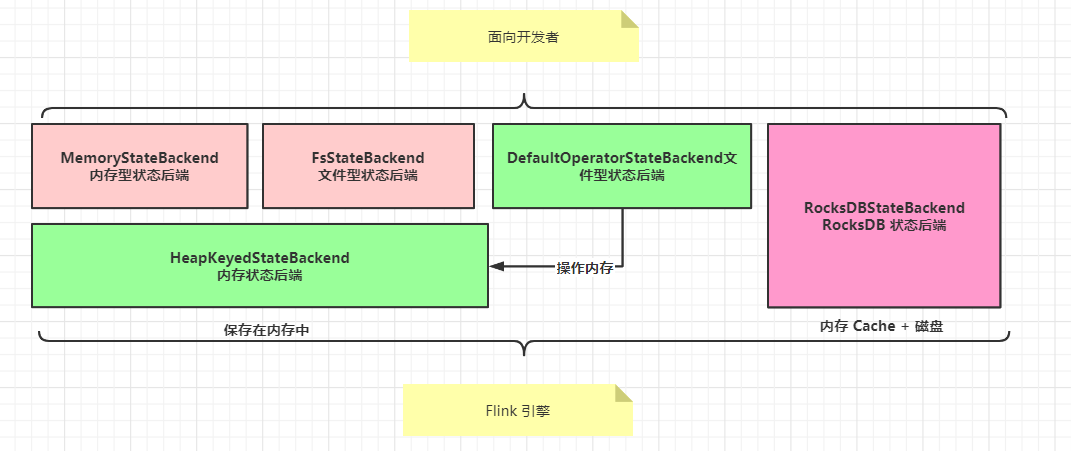
MemoryStateBackend 和 FsStateBackend 本地的 State 都保存在 TaskManager 内存中,所以其底层依赖于 HeapKeyedStateBackend, HeapKeyedStateBackend 面向引擎底层使用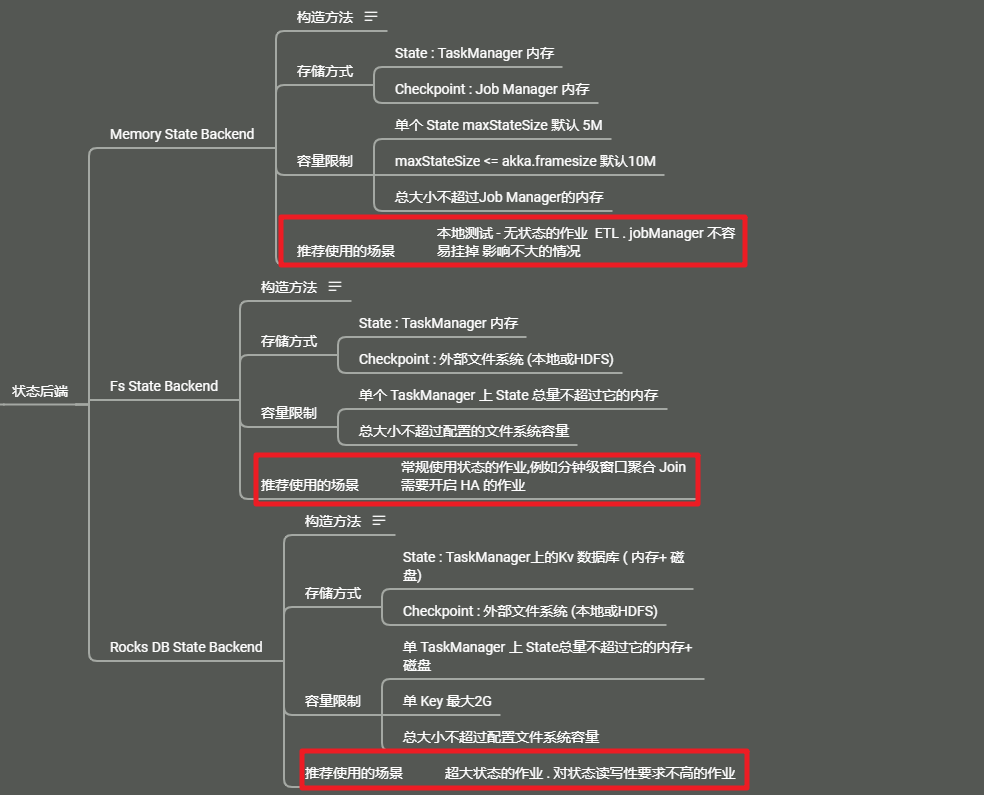
内存型和文件型状态存储
内存型状态存储和文件型状态存储都依赖于内存保存运行时所需的
State,区别在于状态保存的位置内存型 StateBackend
运行时所需要的
State数据保存在TaskManagerJVM 堆上内存中,KV 类型的 State,窗口算子的 State 使用 HashTable 来保存数据,触发器等
在执行检查点的时候,会把 State 的快照数据 保存到 JobManager 的进程的内存中
MemoryStateBackend 可以使用异步的方式进行快照,(也可以使用同步的方式)推荐使用异步的方式,可以避免阻塞算子处理数据
文件型 FsStateBackend
运行时所需的 State 数据保存在 TaskManager 的内存中,在执行检查点的时候,会把 State 的快照数据保存到配置的系统中,可以使用分布式文件系统或本地文件系统
- 使用 HDFS “hdfs://path:port/xxx/xxx”
- 使用 本地 “file:///path/xxx/xxx”
内存型 和 文件型 StateBackend
内存和文件型 StateBackend 依赖于 HeapKeyedStateBackend,内部使用 StateTable 存储数据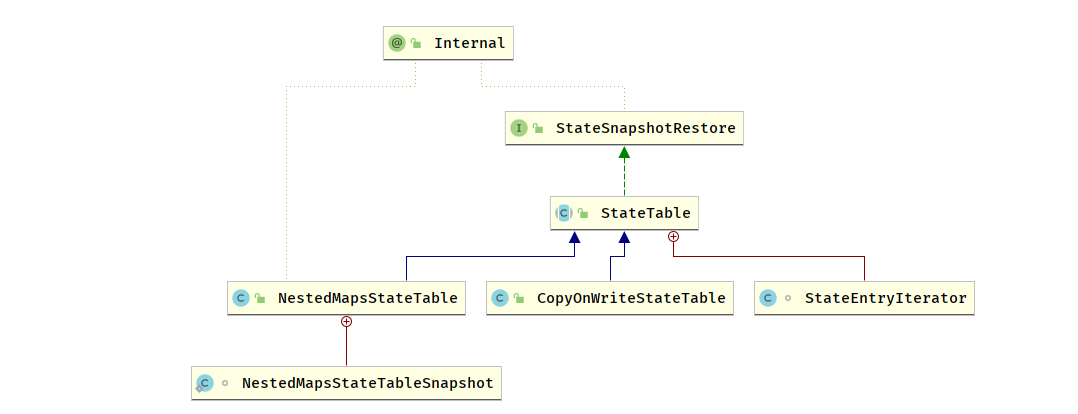
NestedMapsStateTable 使用两层嵌套的 HashMap 来保存状态数据,支持同步快照
@Overrideprotected NestedStateMap<K, N, S> createStateMap() {return new NestedStateMap<>();}
CopyOnWriteStateTable 使用 CopyOnWriteStateMap 来保存状态数据,支持异步快照,可以避免在保存快照的过程中持续写入导致的状态不一致问题
@Overrideprotected CopyOnWriteStateMap<K, N, S> createStateMap() {return new CopyOnWriteStateMap<>(getStateSerializer());}
基于 RocksDB 的 StateBackend
RocksDBStateBackend 跟内存型和文件型 StateBackend不同,其使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中,不会受限于 TaskManager 的内存大小,在执行检查点的时候,再将整个 RocksDB 中保存的 State 数据 全量或者增量 持久化到配置的文件系统中,在 JobManager 内存中会存储少量的检查点元数据,RocksDB 克服了 State 受内存限制的问题, 同时又能持久化到远端文件系统中,比较适合在生产中使用
但是 RocksDBStateBackend 相比于基于内存的 StateBackend,访问 State 的成本高很多,可能导致数据流的吞吐剧烈下降 (访问内存 跟 访问磁盘 两者效率差很多)
RocksDBStateBackend是目前唯一支持增量检查点的后端RocksDB的 JNI API 基于byte 数组,单 Key 和 单 Value 的大小不能超过 2*31次方 细节
状态持久化

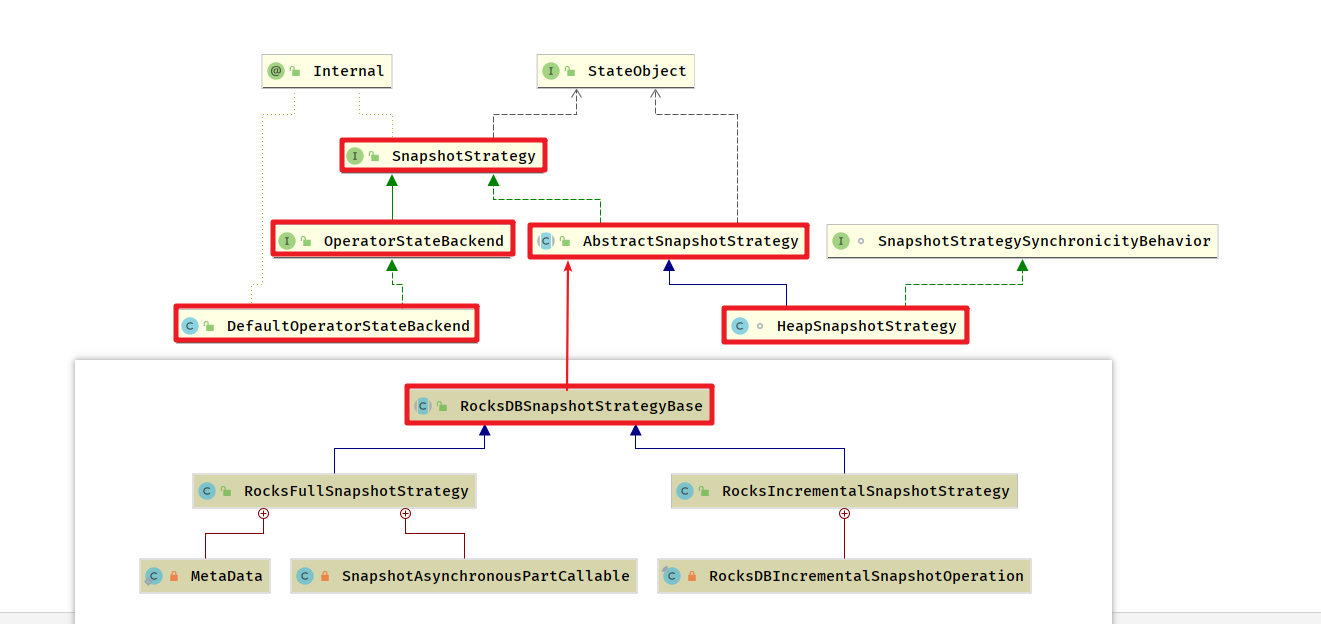
HeapSnapshotStrategy 策略对应于 HeapKeyedStateBackend
RocksBDStateBackend的持久化策略有两种:
在执行持久化策略的时候:
- 使用异步机制,每个算子启动一个独立的线程,将自身的状态写入分布式存储可靠存储中
- 在做持久化的过程中,状态可能会被持续修改
- 基于内存的状态后端使用
CopyOnWriteStateTable来保证线程安全 RocksDBStateBackend则使用RocksDB的快照机制,使用快照来保证线程安
- 基于内存的状态后端使用
2) : 增量持久化策略
增量持久化就是每次持久化增量的 State,只有 RocksBDStateBackend 支持增量持久化
第一阶段: Flush 操作
Flink 增量式的检查点以 RocksDB 为基础,RocksDB 是一个基于 LSM-Tree 的 KV 存储,新的数据保存在内存中,称为 memtable, 如果 Key 相同
- 后到的数据将覆盖之前的数据
- 一旦
memtable写满了RocksDB就会将数据压缩并写入到磁盘, memtable的数据持久化到磁盘后,就变成了不可变的sstable
在启用RocksDB状态后端后,Flink的每个checkpoint周期都会记录RocksDB库的快照,并持久化到文件系统中。所以RocksDB的预写日志(WAL)机制可以安全地关闭,没有重放数据的必要性了。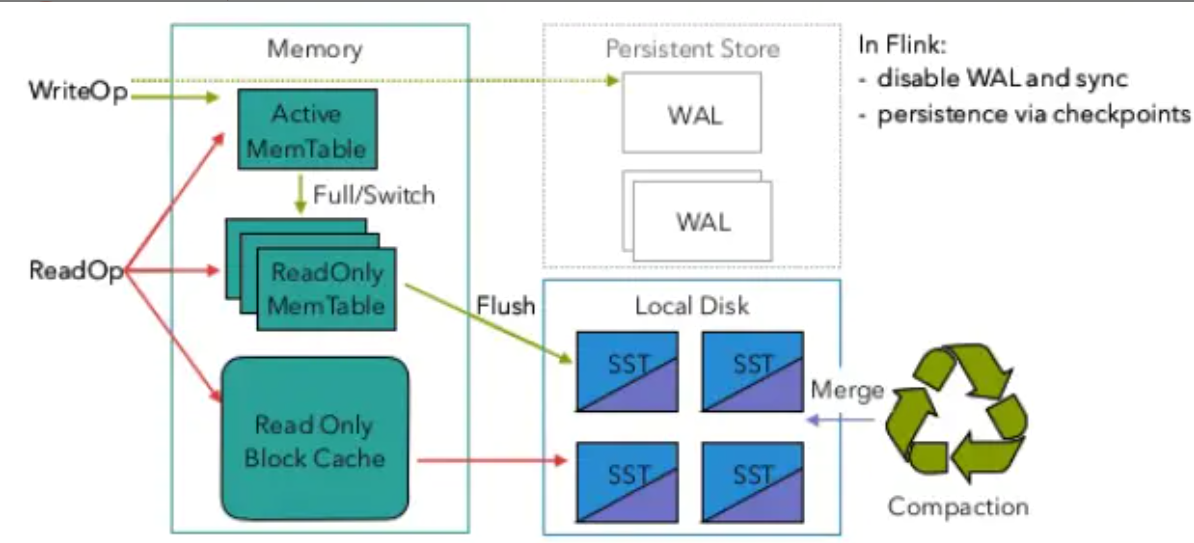
第二阶段: 创建合并以及计数引用
因为 sstable 是不可变的,Flink 对比前一个检查点的创建和删除的 RocksDB sstable 文件就可以计算出状态有哪些改变
- 为了确保
sstable是不可变的 - Flink 会在
RocksDB上触发新操作,强制将sstable刷新到磁盘上 - 在Flink 执行检查点时,会将新的
sstable持久化到存储中,同时保留引用 在这个过程中 Flink 并不会持久化本地所有
sstable- 因为本地的一部分历史
sstable在之前的检查点中已经持久化到存储中了 - 只需要增加对
sstable文件的引用次数就可以了
- 因为本地的一部分历史
RocksDB会在后台合并sstable并删除其中重复的数据- 然后
RocksDB删除原来的sstable,替换成新合成的sstable- 新的
sstable包含了被删除的sstable中的信息
- 新的
- 通过合并 历史的
sstable会合并成一个新的sstable,并删除这些历史sstable- 可以减少检查点的历史文件,避免大量小文件的产生
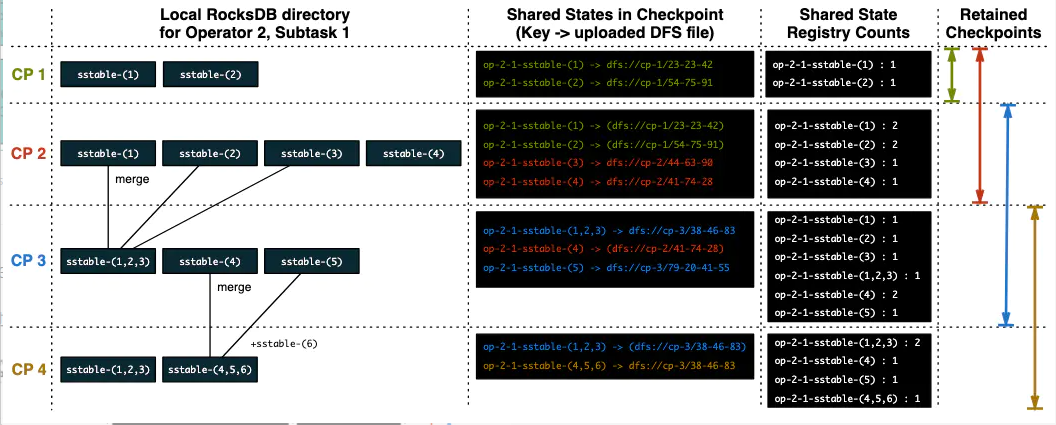
上图示出一个有状态的算子的4个检查点,其ID为2,并且
state.checkpoints.num-retained参数设为2,表示保留2个检查点。表格中的4列分别表示RocksDB中的sstable文件,sstable文件与存储系统中文件路径的映射,sstable文件的引用计数,以及保留的检查点的范围。 下面按部就班地解释一下:
- 检查点CP 1完成后,产生了两个sstable文件,即sstable-(1)与sstable-(2)。这两个文件会写到持久化存储(如HDFS),并将它们的引用计数记为1。
- 检查点CP 2完成后,新增了两个sstable文件,即sstable-(3)与sstable-(4),这两个文件的引用计数记为1。并且由于我们要保留2个检查点,所以上一步CP 1产生的两个文件也要算在CP 2内,故sstable-(1)与sstable-(2)的引用计数会加1,变成2。
- 检查点CP 3完成后,RocksDB的compaction线程将sstable-(1)、sstable-(2)、sstable-(3)三个文件合并成了一个文件sstable-(1,2,3)。CP 2产生的sstable-(4)得以保留,引用计数变为2,并且又产生了新的sstable-(5)文件。注意此时CP 1已经过期,所以sstable-(1)、sstable-(2)两个文件不会再被引用,引用计数减1。
- 检查点CP 4完成后,RocksDB的compaction线程将sstable-(4)、sstable-(5)以及新生成的sstable-(6)三个文件合并成了sstable-(4,5,6),并对sstable-(1,2,3)、sstable-(4,5,6)引用加1。由于CP 2也过期了,所以sstable-([1~4])四个文件的引用计数同时减1,这就造成sstable-(1)、sstable-(2)、sstable-(3)的引用计数变为0,Flink就从存储系统中删除掉这三个文件。
状态重分配
作业预先设置的不合理,太多浪费资源,太少则资源不足,可能导致数据积压延迟变大或者处理时间太长,需要在作业运行监控数据调整其并行度
- State 位于算子中,改变了并行度,则意味着算子个数改变了,需要将
State重新分配给算子 - 从 OperatorState 和 KeyedState 两种 State 角度了解 State 是如何重新分配给算子的
OperatorState 重分区
ListState
并行度发生改变的时候,会将并发上的每个List 都取出,然后把这些 List 合并到一个新的 List,根据元素的个数均匀分配给新的 Task
UnionListState
比 ListState 更加灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来的 List 拼接起来,然后不做划分,直接交给用户
BroadcastState
操作 BroadcastState 的 UDF 需要保证不可变性,所以各个算子的同一个 BroadcastState 完全一样,当并发改变的时候,把这些数据分发到新的 Task 即可,
KeyedState 重分区
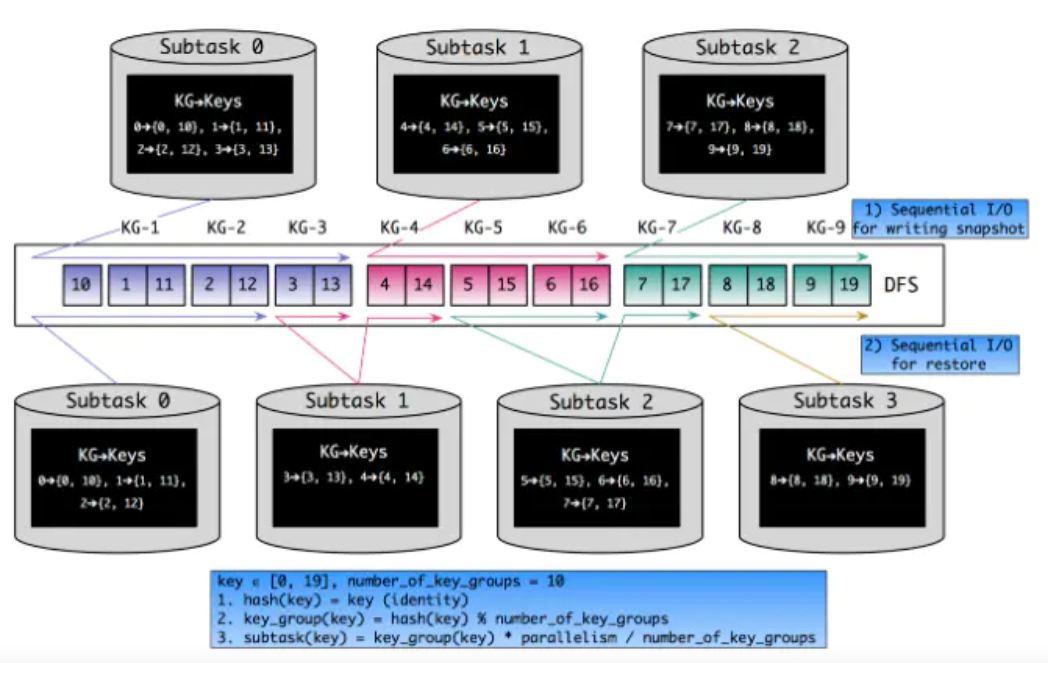
基于 Key-Group, 每个 Key 隶属于唯一的 Key-Group,Key-Group 分配给 Task 实例,每个 Task 至少有1个 Key-GroupKey-Group 的数据取决于最大并行度 (MaxParallism),KeyedStream 并发的上限是 Key-Group 的数量,等于最大并行度
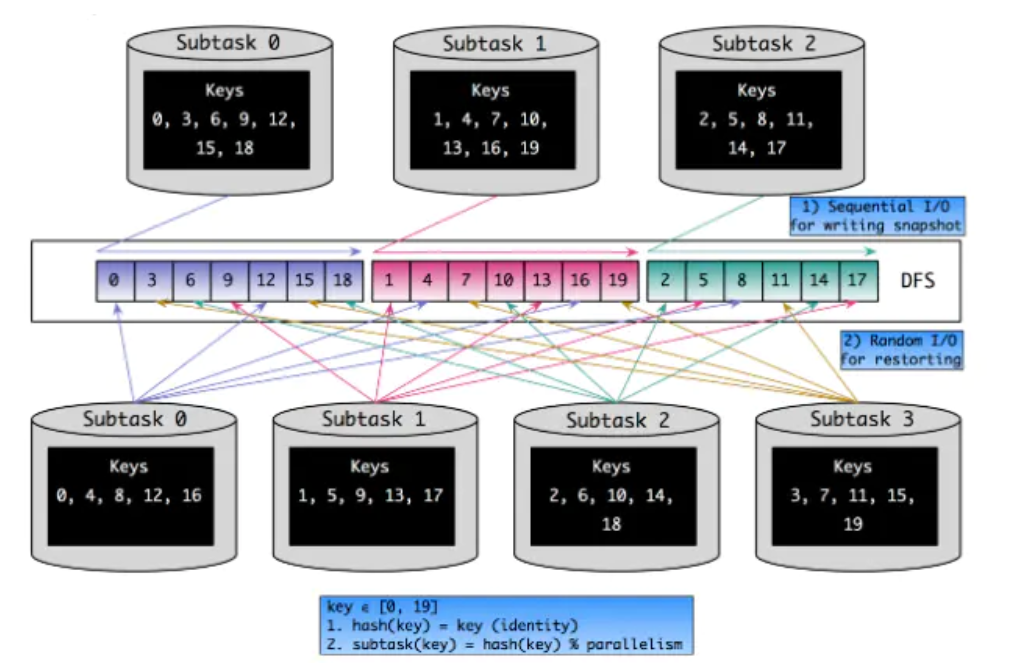
- Flink中的key是按照
hash(key) % parallelism的规则分配到各个Sub-Task上去 - 如何决定一个key该分配到哪个Key Group中
- 对key进行两重哈希(一次取hashCode,一次做MurmurHash)之后,再对最大并行度取余,得到Key Group的索引
- 如何决定一个Sub-Task该处理哪些Key Group(即对应的KeyGroupRange)
- 由并行度、最大并行度和算子实例(即Sub-Task)的ID共同决定
状态过期
流上的数据处理 所维护的状态如果不自动清理的话,会随着作业运行的时间的长度积累越来越多的状态
- 会影响流的性能
- 状态太大可能导致整个作业的崩溃
另一方面,数据是有时效性的,一般情况下 历史数据在业务上的价值会随着时间流逝而不断下降,在 State 持有大量低价值的数据 是没有必要的
DataStream 中 状态过期 Time-To-Live
在 DataStream 作业中,对于复杂的逻辑而言,有时需要精细的控制
为了使用状态TTL,必须首先构建一个 StateTtlConfig 配置对象. 然后可以通过传递配置在任何状态描述符中启用TTL功能:
import org.apache.flink.api.common.state.StateTtlConfig;import org.apache.flink.api.common.state.ValueStateDescriptor;import org.apache.flink.api.common.time.Time;StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);stateDescriptor.enableTimeToLive(ttlConfig);
对于每一个 State 可以设置清理的策略 StateTtlConfig 可以设置的内容:
- 过期时间:
newBuilder超过多长时间未访问,则视为State过期,类似于缓存
更新类型配置何时刷新状态TTL (默认情况下为OnCreateAndWrite):
StateTtlConfig.UpdateType.OnCreateAndWrite- 仅在创建和写入访问时更新StateTtlConfig.UpdateType.OnReadAndWrite- 读取和写入时更新
状态可见性配置如果尚未清除过期值,则是否在读取访问时返回该过期值(默认情况下, NeverReturnExpired
StateTtlConfig.StateVisibility.NeverReturnExpired- 未清理可用StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp- 超期则不可用- 在
NeverReturnExpired的情况下,变为不可访问的 ReturnExpiredIfNotCleanedUp允许在清理之前返回过期状态
- 在
清理过期状态
default Read expired delete
默认情况下 只有在明确读出过期值时才会删除过期值
import org.apache.flink.api.common.state.StateTtlConfig;StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).disableCleanupInBackground().build();
Cleanup in full snapshot
做快照时激活清除操作,减小其大小, 但在从上一个快照恢复的情况下,不会包括已删除的过期状态
- 此选项不适用于RocksDB状态后端中的增量检查点。 ```java import org.apache.flink.api.common.state.StateTtlConfig; import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig .newBuilder(Time.seconds(1)) .cleanupFullSnapshot() .build();
<a name="qY1cl"></a>####<a name="Y1Kml"></a>#### Incremental cleanup通过增量触发器逐渐清理 `State`,当进行状态访问或者处理数据时,在回调函数中进行处理,当每次增量清理触发时,遍历 `StateBackend` 中的状态,清理掉过期的- 每次触发增量清理时,迭代器都会前进。检查遍历的状态条目,并清理过期的条目。```javaimport org.apache.flink.api.common.state.StateTtlConfig;StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).cleanupIncrementally(10, true).build();
Cleanup during RocksDB compaction
如果使用RocksDB状态后端,则将调用Flink特定的压缩过滤器进行后台清理。 RocksDB定期运行异步压缩以合并状态更新并减少存储。 Flink压缩过滤器使用TTL检查状态条目的过期时间戳,并排除过期值。
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();
参考

若有收获,就点个赞吧
0 人点赞
