
- 重构后的 TableSource 输出的都是 RowData 结构数据,代表了一行的数据。
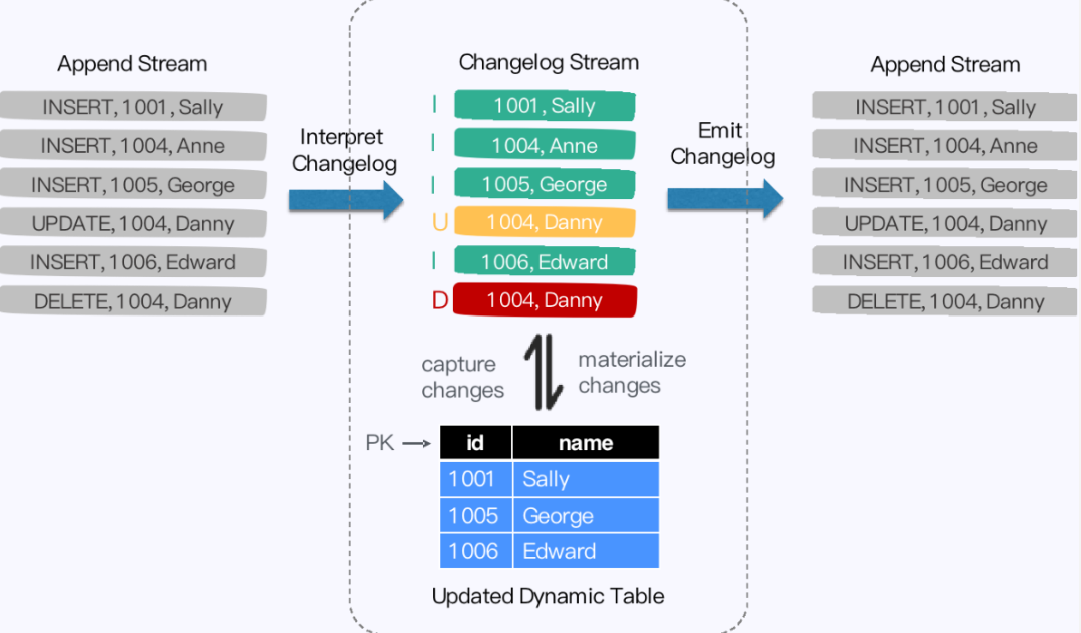
- 在RowData 上面会有一个元数据的信息,我们称为 RowKind 。
- RowKind 里面包括了插入、更新前、更新后、删除,这样和数据库里面的 binlog 概念十分类似。
- 通过 Debezium 采集的 **JSON 格式,包含了旧数据和新数据行以及原数据信息**,
- op 的 u表示是 update 更新操作标识符,ts_ms 表示同步的时间戳。
- 因此,对接 Debezium JSON 的数据,其实就是将这种原始的 JSON 数据转换成 Flink 认识的 RowData。
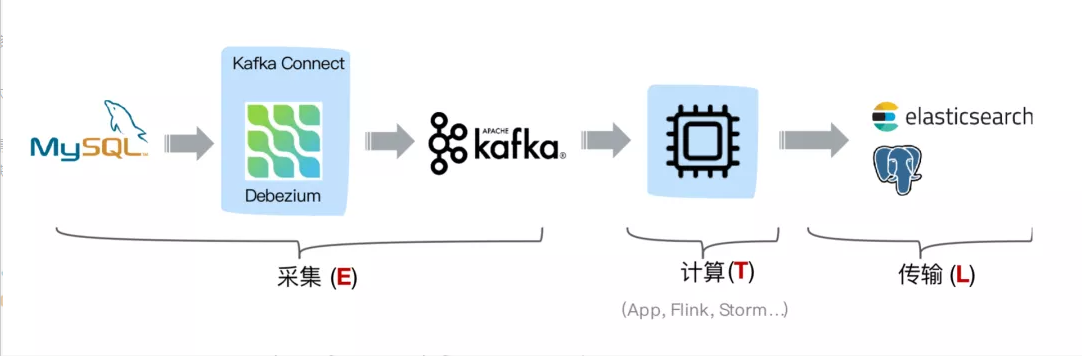
选择 Flink 作为 ETL 工具
当选择 Flink 作为 ETL 工具时,在数据同步场景,如下图同步结构: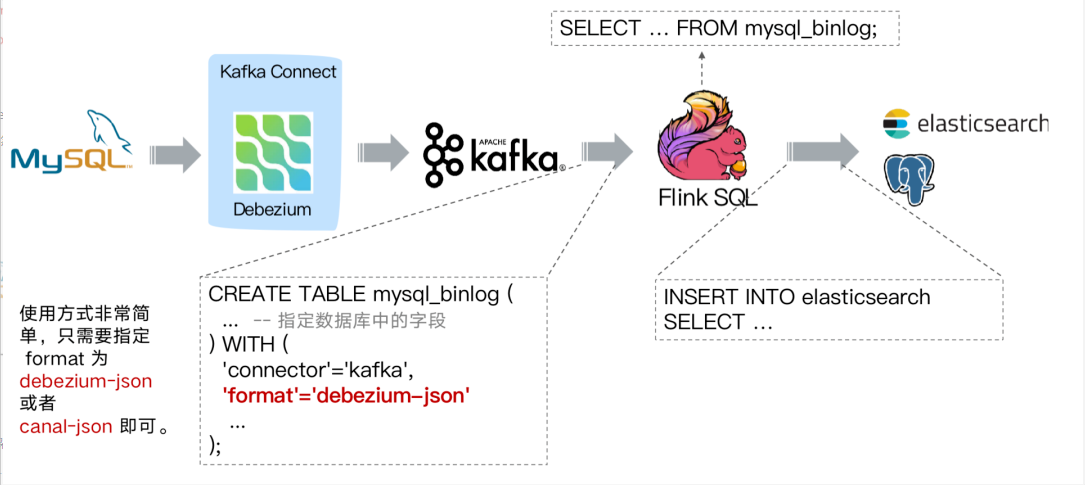
通过 Debezium 订阅业务库 MySQL 的 Binlog 传输至 Kafka ,Flink 通过创建 Kafka 表指定 format 格式为 debezium-json ,然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统,例如图中的 Elasticsearch 和 PostgreSQL。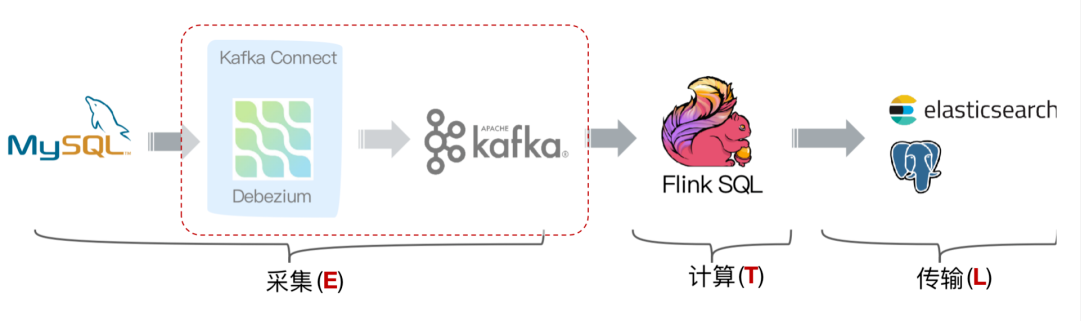
但是这个架构有个缺点,我们可以看到采集端组件过多导致维护繁杂,这时候就会想是否可以用 Flink SQL 直接对接 MySQL 的 binlog 数据呢,有没可以替代的方案呢?
答案是有的!经过改进后结构如下图: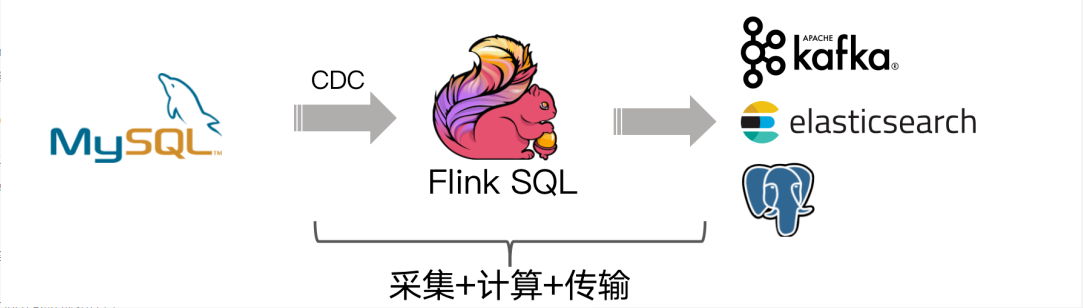
社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。开源地址:
flink-cdc-connectors 可以用来替换 Debezium+Kafka 的数据采集模块,从而实现 Flink SQL 采集+计算+传输(ETL)一体化,这样做的优点有:
- 开箱即用,简单易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯
基于 Flink SQL CDC 的数据同步方案实践
案例 1 : Flink SQL CDC + JDBC Connector
这个案例通过订阅我们订单表(事实表)数据,通过 Debezium 将 MySQL Binlog 发送至 Kafka,通过维表 Join 和 ETL 操作把结果输出至下游的 PG 数据库。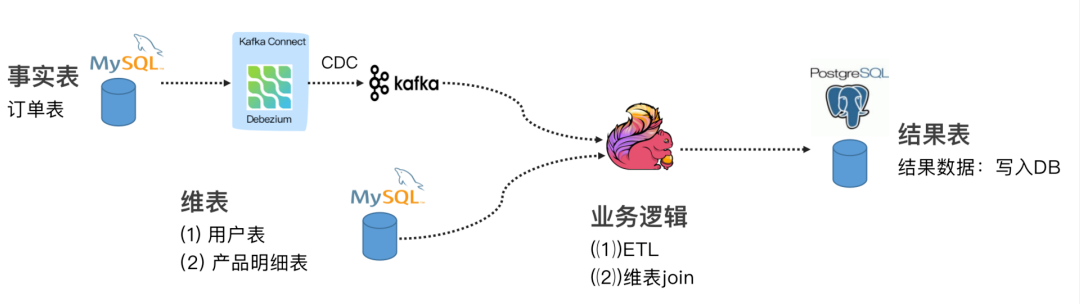
案例 2 : CDC Streaming ETL
模拟电商公司的订单表和物流表,需要对订单数据进行统计分析,对于不同的信息需要进行关联后续形成订单的大宽表后,交给下游的业务方使用 ES 做数据分析,这个案例演示了如何只依赖 Flink 不依赖其他组件,借助 Flink 强大的计算能力实时把 Binlog 的数据流关联一次并同步至 ES 。
例如如下的这段 Flink SQL 代码就能完成实时同步 MySQL 中 orders 表的全量+增量数据的目的。
CREATE TABLE orders (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN) WITH ('connector' = 'mysql-cdc','hostname' = 'localhost','port' = '3306','username' = 'root','password' = '123456','database-name' = 'mydb','table-name' = 'orders');SELECT * FROM orders
案例 3 : Streaming Changes to Kafka
下面案例就是对 GMV 进行天级别的全站统计。包含插入/更新/删除,只有付款的订单才能计算进入 GMV ,观察 GMV 值的变化。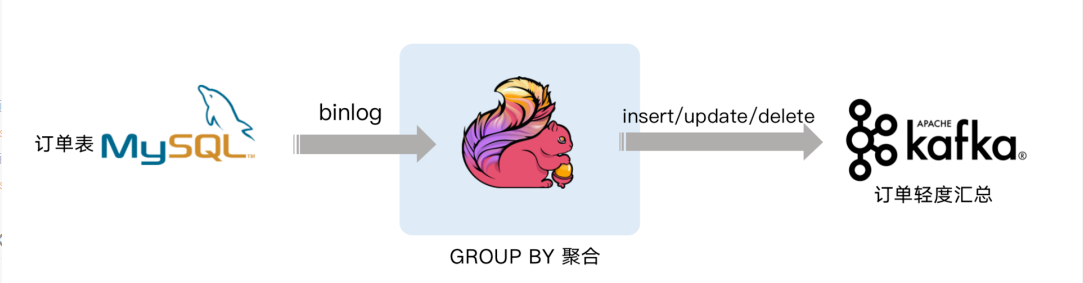
其他
Flink 在数据同步场景中的灵活定位
- 如果你已经有 Debezium/Canal + Kafka 的采集层 (E),可以使用 Flink 作为计算层 (T) 和传输层 (L)
- 也可以用 Flink 替代 Debezium/Canal ,由 Flink 直接同步变更数据到 Kafka,Flink 统一 ETL 流程
如果不需要 Kafka 数据缓存,可以由 Flink 直接同步变更数据到目的地,Flink 统一 ETL 流程
Flink SQL CDC : 打通更多场景
实时数据同步,数据备份,数据迁移,数仓构建
- 优势:丰富的上下游(E & L),强大的计算(T),易用的 API(SQL),流式计算低延迟
- 数据库之上的实时物化视图、流式数据分析
- 索引构建和实时维护
- 业务 cache 刷新
- 审计跟踪
- 微服务的解耦,读写分离
- 基于 CDC 的维表关联
- 优势:丰富的上下游(E & L),强大的计算(T),易用的 API(SQL),流式计算低延迟
Temporal Table DDL(基于 CDC 的维表关联)
- FLIP-132
参考视频
参考文档

若有收获,就点个赞吧
0 人点赞
