Flink 最终执行的时候形成了一个分布式 Dataflow , 子任务 Task 分布在不同的物理机服务器上, Task 之间不可避免地要交换数据
数据传递模式
PULL / PUSH 两种模式
-
Flink Batch模式
Batch 的计算模型采用 PULL 模式,将计算结果分成多份阶段,上游完全计算完毕之后,下游从上游拉取数据开始下一阶段计算,直到最终所有的阶段都计算完毕,输出结果, Batch Job 结束退出
-
Flink Stream模式
Stream 的计算模型采用 PUSH 模式,上游主动向下游推送数据,上下游之间采用生产者-消费者 模式
- 下游收到数据触发计算,没有数据则进入等待状态
PUSH 模式的数据处理过程也叫 Pipeline ,提到 Pipeline 或者流水线的时候,一般是指 PUSH 模式的数据处理过程
| 对比点 | PULL | PUSH |
|---|---|---|
| 延迟 | 延迟高(需要等待上游所有计算完毕) | 延迟低 (上游边计算边向下游输出) |
| 下游状态 | 有状态,需要知道何时拉取 | 无状态 |
| 上游状态 | 无状态 | 有状态,需要了解每个下游的推送点 |
| 连接状态 | 短连接 | 长连接 |
关键组件
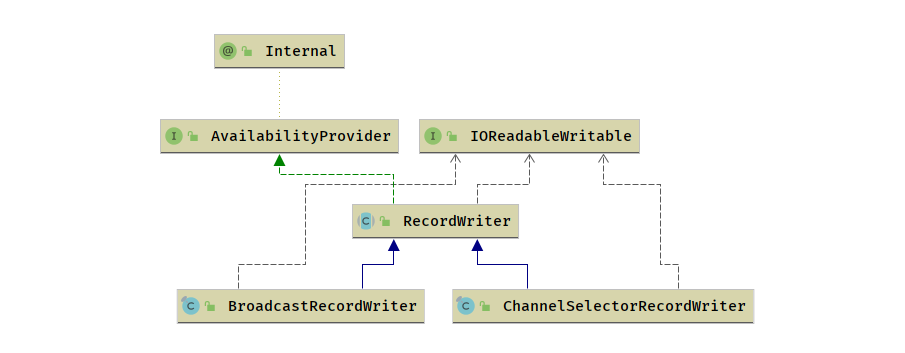
RecordWriter
RecordWriter 负责将 Task 处理的数据输出,然后下游 Task 就可以继续处理了.
RecordWriter面向的是StreamRecord, 直接处理算子的输出结果.ResultPartitionWriter面向的是Buffer,起到承上启下的作用.
RecordWriter 比 ResultPartitionWriter 的层级要高,底层依赖于 ResultPartitionWriter .
数据分区,其中最核心的抽象是 ChannelSelector,在 RecordWriter 中实现了数据分区语义,将开发时对数据分区的 API 调用转换成了实际的物理操作 (DataStream.shuffle())等
最底层内存抽象是 MemorySegment ,用于数据传输的是 Buffer,那么,承上启下对接从 Java 对象转为 Buffer 的中间对象是什么呢? (StreamRecord)
RecordWriter 类负责将 StreamRecord 进行序列化,调用 SpanningRecordSerializer (新版本找不到),
再调用 BufferBuilder 写入 MemorySegment中 (每个 Task 都有自己的 LocalBufferPool ,LocalBufferPool 中包含了多个 MemorySegment)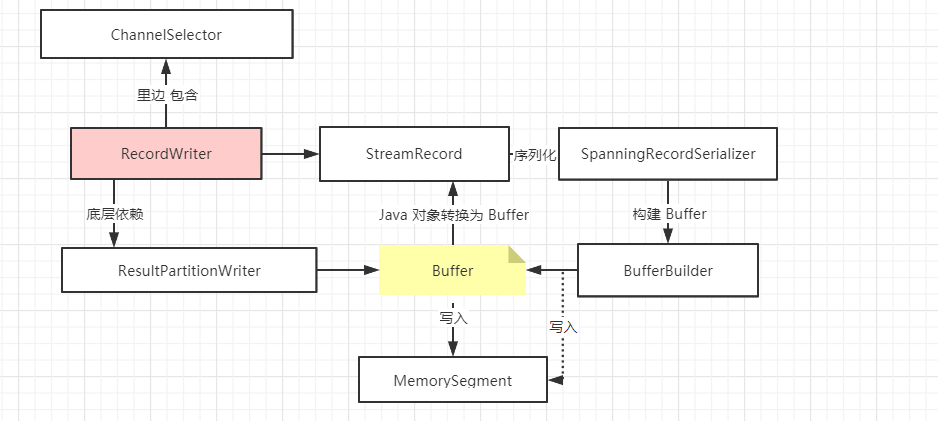
- 哪些数据会被序列化?
- 数据元素
StreamElement
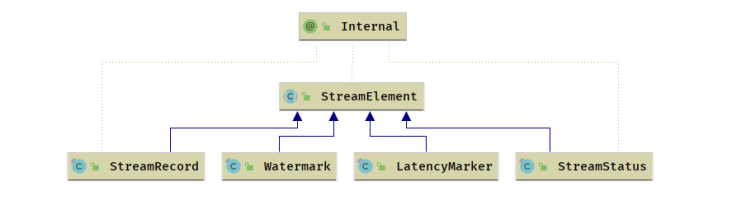
- 事件
Event; Flink 内部的系统事件 (CheckpointBarrier等)
单播
根据 ChannelSelector,对数据流中每一条数据记录都进行选择,有效地写入一个输出通道的 ResultSubPartition 中 , 适用于非 BroadcastPartitioin .
如果在开发的时候没有使用 Partition ,默认会使用 BoundRobinChannelSelector ,使用 RounRobin 算法选择输出通道循环写入本地输出通道对应的 ResultPartition,发送到下游 Task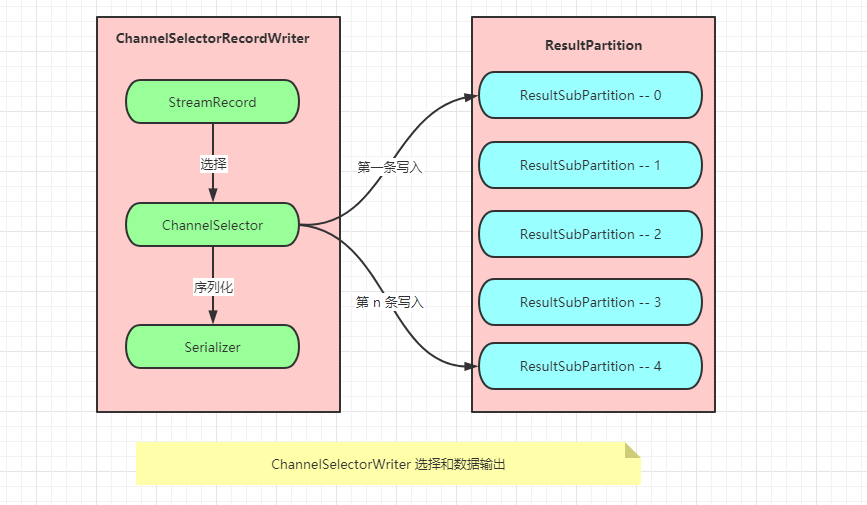
广播
广播就是向下游所有的 Task 发送相同的数据,在所有的 ResultSubPartition 中写入 N 份相同数据.
在实际实现时,同时写入 N 份重复的数据是资源浪费,所以对于广播类型的输出,只会写入编号为 0 的 ResultSubPartition 中,下游 Task 对于广播类型的数据,都会从编号为 0 的 ResultSubPartition 中获取数据.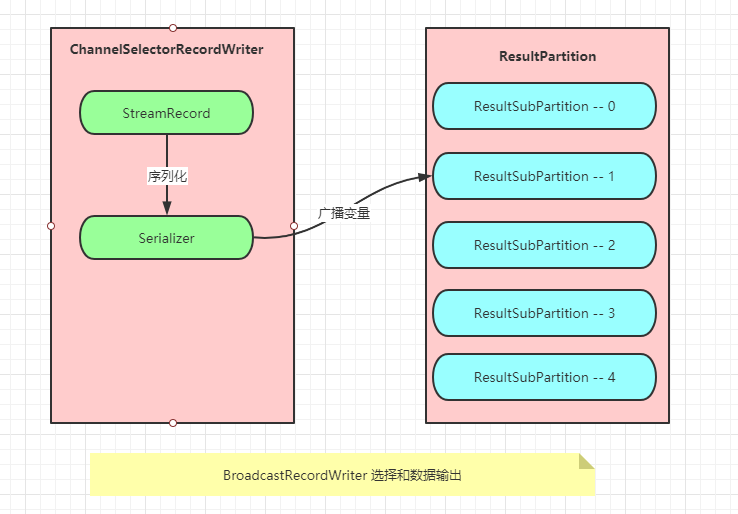
数据记录序列化器 <SpanningRecordSerializer>
数据记录序列化器 RecordSerializer , 负责数据的序列化 (SpanningRecordSerializer 是唯一实现).SpanningRecordSerializer 是一种支持跨内存段的序列化器
- 其实现借助于中间缓存区来缓存序列化后的数据,
- 然后再往真正的目标
Buffer里写,在写的时候会维护两个 “指针”.
- 一个是表示目标
Buffer内存段长度的limit - 一个是表示其当前写入位置的
position
- 因为一个
Buffer对应着一个内存块,当将数据序列化并存入内存段时,其空间可能有剩余也可能不够. 因此
RecordSerializer定义了一个表示序列化结果的SerializationResult[x] 在序列化数据写入内存段的过程中,存在 3 种可能的结果:
- PARTIAL_RECORD_MEMORY_SEGMENT_FULL
- 内存段已满但记录的数据只写入了一部分,没有完全写完,需要申请新的内存段继续写入
**
FULL_RECORD_MEMORY_SEGMENT_FULL
- 内存段写满,记录的数据已全部写入
FULL_RECORD
- 记录的数据全部写入,但内存段并没有满
数据记录反序列化器
数据记录反序列化器 RecordDeserializer , 负责数据的反序列化, SpillingAdaptiveSpanningRecordDeserializer 是唯一的实现
跟 RecordSerializer 类似,考虑到数据的数据大小以及 Buffer 对应的内存段的容量大小
- 在反序列化时也存在不同的反序列化结果,以枚举
DeserializationResult表示 PARTIAL_RECORD- 记录并未完全被读取,但缓存中的数据已被消费完成 (3)
INTERMEDIATE_RECORD_FROM_BUFFER- 记录的数据已被完全读取,但缓存中的数据并未完全消费 (1)
LAST_RECORD_FROM_BUFFER- 记录被完全读取,且缓存中的数据也正好被完全消费 (2)
SpillingAdaptiveSpanningRecordDeserializer 适用于数据相对较大且跨多个内存段的数据元素的反序列化,支持将溢出的数据写入临时文件中.序列化与反序列化的过程相反
结果子分区视图
结果子分区视图 ResultSubPartitionView ,其定义了从 ResultSubPartition 中读取数据、释放资源等抽象行为,其中 getNextBuffer 是最重要的方法,用来获取 Buffer
Flink 中设计了两种不同类型的结果子分区,其存储机制不同,对应于结果子分区的不同类型,定义了两个结果子分区视图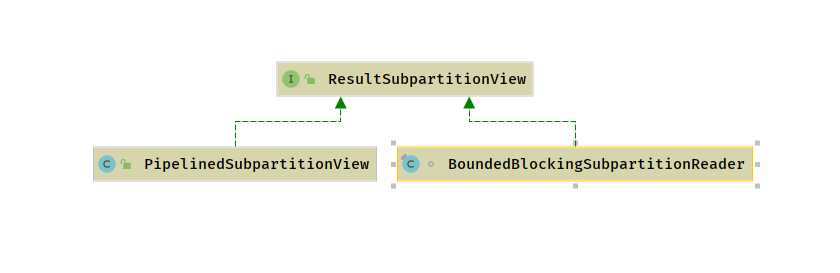
-
BoundedBlockingSubpartitionReader: 用来读取BoundedBlockingSubpartition中的数据 -
PipelinedSubpartitionView: 用来读取PipelinedSubpartition中的数据
数据输出
数据输出 (Output) 是算子向下游传递的数据抽象,定义了向下游发送 StreamRecord 、Watermark 、LetencyMark 的行为,对于 StreamRecord 多了一个 SideOutPut 的行为定义.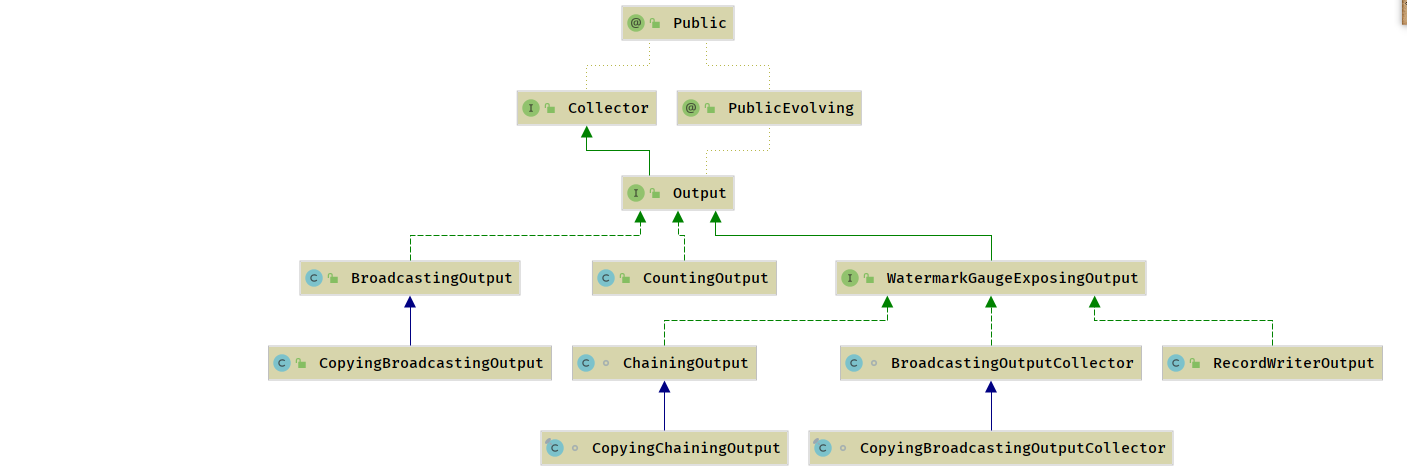
-
WatermarkGaugeExposingOutput - 统计
Watermark监控指标计算行为,将最后一次发送到下游的Watermark作为其指标值. 其实现类负责计算指标值,在Fink
WebUI中,通过可视化StreamGraph看到的Watermark监控信息即来自于此[x]
RecordWriterOutput- 包装了
RecordWriter,使用RecordWriter把数据交给数据交换层. RecordWriter主要用来在线程间、网络间实现数据序列化、写入[x]
ChainingOutput&CopyingChainingOutput- 这两个类是在
OperatorChain内部的算子之间传递数据用的,并不会有序列化的过程,直接在Output中调用下游算子的processElement()方法. 在同一个线程内的算子直接传递数据,跟普通的 Java 方法调用一样,这样就直接省略了线程间的数据传送和网络间的数据传送的开销
[x]
CopyingDirectedOutput&DirectedOutput- 包装类,基于一组
OutputSelector选择发送给下游哪些Task DirectedOutput为共享对象模式CopyDirectedOutput为费共享对象模式[x]
BroadcastingOutputCollector&CopyBroadcastingOutputCollector- 包装类,内部包含了一组
Output - 向所有的下游
Task广播数据 Copying和 非Copying区别在于是否重用对象[x]
CountingOutputCountingOutput是Output实现类的包装类,该类没有任何业务逻辑属性,只是用来标记其他Output实现类向下游发送的数据元素个数,并作为监控指标反馈给 Flink 集群
数据传递
数据处理的业务逻辑位于 UDF 的 processElement() 方法中,算子调用 UDF 处理数据完毕之后,需要将数据交给下一个算子, Flink 的算子使用 Collector 接口进行数据传递
- Flink 有 3 种数据传递的方式
- 本地线程内的数据交换
- 本地线程之间的数据传递
- 跨网络的数据交换
本地线程内的数据交换
本地线程内的数据交换是最简单、效率最高的传递形式,其本质是属于同一个 OperatorChain 的算子之间的数据传递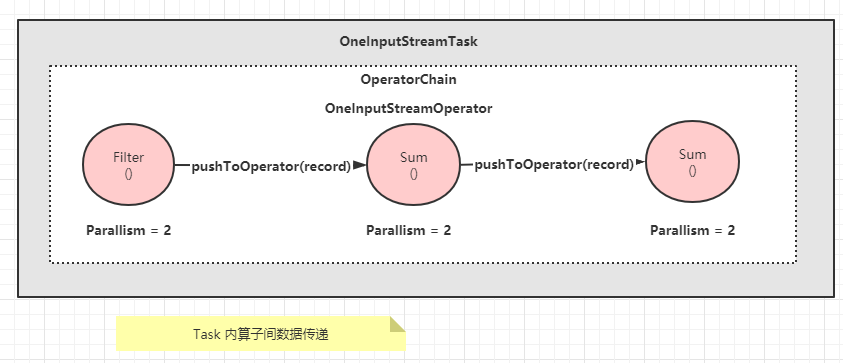
- 3 个算子属于同一个
OperatorChain, 在执行的时候,会被调度到同一个Task. - 上游的算子处理数据,然后通过
Collector接口直接调用下游算子的processElement()方法 - 在同一个线程内执行普通的
Java方法 - 没有将数据序列化写入共享内存、下游读取数据再反序列化的过程
- 线程切换的开销也省掉了.
本地线程之间的数据传递
位于同一个 TaskManager 的不同 Task 的算子之间,不会通过算子间的直接调用方法传输数据,而是通过本地内存进行数据传递.
- 以
Source算子所在线程与下游的FlatMap算子所在线程间的通信为例,这两个Task线程共享同一个BufferPool,通过wait()/notifyAll()来同步. Buffer和Netty中的ByteBuf功能类似,可以看作是一块共享的内存.InputGate负责读取Buffer或Event.
- 本地线程间的数据交换经历 5 个步骤
FlatMap所在线程首先会从InputGate的LocalInputChannel中消费数据,如果没有数据则通过InputGate中的InputChannelWithData.wait()方法阻塞等待数据.Source算子持续地从外部数据源 (如Kafka)写入ResultSubPartition中.ResultSubPartition将数据刷新写入LocalBufferPool中,然后通过InputChannelWithData.notifyAll()方法唤醒FlatMap线程.唤醒
FlatMap所在的线程 (通过InputChannelWithData.notifyAll()方法唤醒) .FlatMap线程首先调用LocalInputChannel从LocalBuffer中读取数据,然后进行数据的反序列化.
FlatMap 将反序列化之后的数据交给算子中的用户代码进行业务处理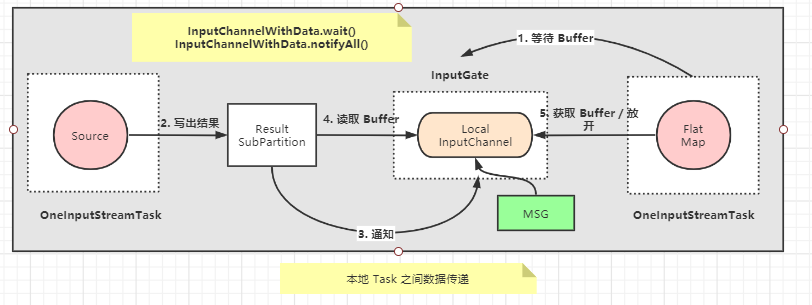
跨网络的数据交换
跨网络数据传递,运行在不同 TaskManager JVM 中的 Task 之间的数据传递,与本地线程间的数据传递类似.
不同点在于,当没有 Buffer 可以消费时,会通过 PartitionRequestClient 向 FlatMap Task 所在的进程发起 RPC 请求,远程的 PartitionRequestServerHandler 接收到请求后,读取 ResultPartition 所管理的 Buffer,并返回给 Client.
- 跨网络的
FlatMap算子 和KeyedAgg/Sink算子数据交换 如下
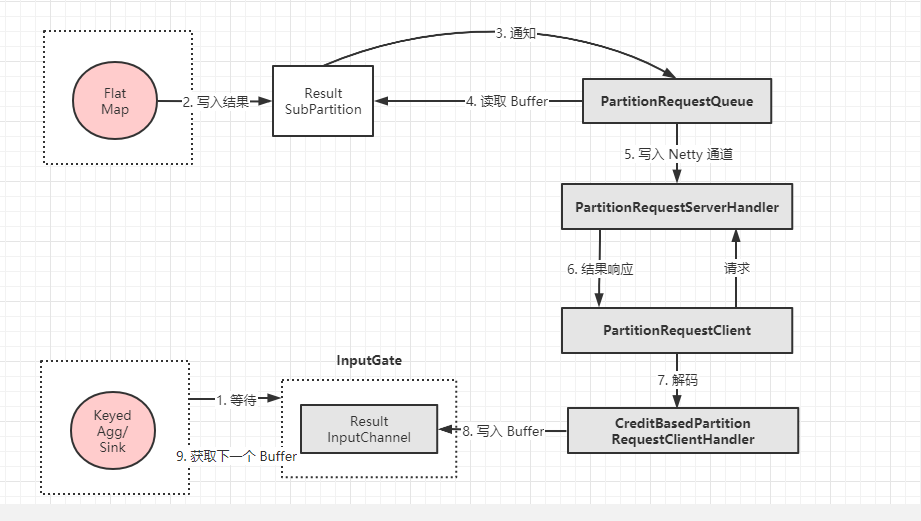
- 跨网络的数据交换比本地线程间的数据传递要复杂一些
Keyed/Agg所在线程从InputGate的RemoteInputChannel中消费数据,如果没有数据则阻塞在RemoteInputChannel中的receviedBuffers上等待数据.FlatMap持续处理数据,并将数据写入ResultSubPartition中.ResultSubPartition通知PartitionRequestQueue有新的数据.PartitionRequestQueue从ResultSubPartition读取数据.ResultSubPartition将数据通过PartitionRequestServerHandler写入Netty Channel,准备写入下游Netty.Netty将数据封装到Response消息中,推送到下游,此处需要下游对上游的request请求,用来建立数据从上游到下游的通道,此请求是对ResultSubPartition的数据请求,创建了PartitionRequestQueue.下游
Netty收到Response消息,进行解码.CreditBasedPartitionRequestClientHandler将解码后的数据写入RemoteInputChannel的Buffer缓冲队列中,然后唤醒Keyed/Agg所在线程消费数据.从
Keyed/Agg所在线程RemoteInputChannel中读取Buffer缓冲队列中的数据,然后进行数据的反序列化,交给算子中的用户代码进行业务处理.
数据传递过程
- 从总体上来说,数据在
Task之间传递分为如下几个大的步骤
数据在本算子处理完后,交给
RecordWriter.每条记录都要选择下游节点,所以要经过ChannelSelector,找到对应的结果子分区.每个结果子分区都有一个独有的序列化器 (避免多线程竞争),把这条记录序列化为二进制数据.
数据被写入结果分区下的各个子分区中,此时该数据已经存入
DirectBuffer(MemorySegment).单独的线程控制数据的
flush速度,一旦触发flush,则通过Netty的nio通道向对端写入.对端的
Netty Client接收到数据,解码出来,把数据复制到Buffer中,然后通知InputChanel.有可用的数据时,下游算子从阻塞醒来,从
InputChannel取出Buffer,再反序列化成数据记录,交给算子执行用户代码 (UDF).
数据读取
ResultSubPartitionView 接收到数据可以通知之后,有两类对象会接收到该通知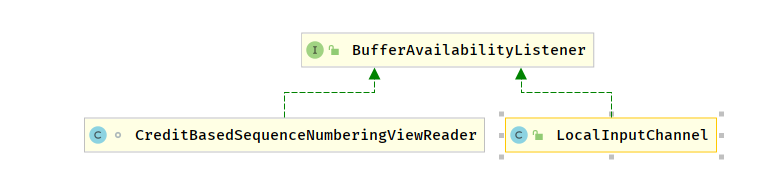
LocalInputChannel其实是本地JVM线程之间的数据传递CreditBasedSequenceNumberingViewReader用来对本机跨 JVM 或者跨网络的数据传递
无论是本地线程间数据交换还是跨网络的数据交换,对于数据消费端而言,其数据消费的线程会一直阻塞在 InputGate 上,等待可用的数据,并将可用的数据转换成 StreamRecord 交给算子进行处理.
其基本过程为 : StreamTask.processInput()StreamOneInputStreamOperator.processInput()StreamTaskNetworkInput.emitNext()SpillingAdaptiveSpanningRecordDeserializer
从 NetworkInput 中读取数据反序列化为 StreamRecord , 然后交给 DataOutput 向下游发送
[x]
StreamTaskNetworkInput@Overridepublic InputStatus emitNext(DataOutput<T> output) throws Exception {while (true) {// get the stream element from the deserializerif (currentRecordDeserializer != null) {DeserializationResult result;try {result = currentRecordDeserializer.getNextRecord(deserializationDelegate);} catch (IOException e) {throw new IOException(String.format("Can't get next record for channel %s", lastChannel), e);}if (result.isBufferConsumed()) {currentRecordDeserializer.getCurrentBuffer().recycleBuffer();currentRecordDeserializer = null;}if (result.isFullRecord()) {processElement(deserializationDelegate.getInstance(), output);return InputStatus.MORE_AVAILABLE;}}// 从 InputGate 中获取 下一个 BufferOptional<BufferOrEvent> bufferOrEvent = checkpointedInputGate.pollNext();// 如果是 Buffer, 则设置 RecordDeserializer 处理下一条记录,否则释放 RecordDeserializerif (bufferOrEvent.isPresent()) {// return to the mailbox after receiving a checkpoint barrier to avoid processing of// data after the barrier before checkpoint is performed for unaligned checkpoint// modeif (bufferOrEvent.get().isBuffer()) {processBuffer(bufferOrEvent.get());} else {processEvent(bufferOrEvent.get());return InputStatus.MORE_AVAILABLE;}} else {if (checkpointedInputGate.isFinished()) {checkState(checkpointedInputGate.getAvailableFuture().isDone(),"Finished BarrierHandler should be available");return InputStatus.END_OF_INPUT;}return InputStatus.NOTHING_AVAILABLE;}}}
数据反序列化时,使用
DataInputView从内存中读取二进制数据,根据数据的类型进行不同的反序列化.
对于数据记录、则使用其类型对应的序列化器,对于其他类型的数据元素 如Watermark、LatencyMarker``、StreamStatus等,直接读取其二进制数据转换为数值类型.[x]
StreamElementSerializer@Override public StreamElement deserialize(DataInputView source) throws IOException { int tag = source.readByte(); if (tag == TAG_REC_WITH_TIMESTAMP) { long timestamp = source.readLong(); return new StreamRecord<T>(typeSerializer.deserialize(source), timestamp); } else if (tag == TAG_REC_WITHOUT_TIMESTAMP) { return new StreamRecord<T>(typeSerializer.deserialize(source)); } else if (tag == TAG_WATERMARK) { return new Watermark(source.readLong()); } else if (tag == TAG_STREAM_STATUS) { return new StreamStatus(source.readInt()); } else if (tag == TAG_LATENCY_MARKER) { return new LatencyMarker( source.readLong(), new OperatorID(source.readLong(), source.readLong()), source.readInt()); } else { throw new IOException("Corrupt stream, found tag: " + tag); } }
数据写出
Task 调用算子执行 UDF 之后,需要将数据交给下游进行处理.RecordWriter 类负责将 StreamRecord 进行序列化,调用 SpaningRecordSerializer ,再调用 BufferBuilder 写入 MemorySegment 中 (每个 Task 都有自己的 LocalBufferPool,LocalBufferPool 中包含了多个 MemorySegment )
[x]
RecordWriter```java private void emit(T record, int targetChannel) throws IOException, InterruptedException {// 把 StreamRecord 序列化为 二进制数组 serializer.serializeRecord(record); // 将数据写入 ResultPartition 的 MemorySegment 中 ??? if (copyFromSerializerToTargetChannel(targetChannel)) { serializer.prune(); }}
在数据序列化之后,通过 `Channel` 编号 选择结果子分区,将数据复制到结果子分区中,在写入过程中,序列化器将数据复制到 `BufferBuilder` 中
- 如果数据太大,则需要写入多个 `Buffer` ,即跨内存段写入数据
- [x] `RecordWriter`
```java
private boolean copyFromSerializerToTargetChannel(int targetChannel) throws IOException, InterruptedException {
// We should reset the initial position of the intermediate serialization buffer before
// copying, so the serialization results can be copied to multiple target buffers.
serializer.reset();
boolean pruneTriggered = false;
// 获取对应 targetChannel 的 BufferBuilder
BufferBuilder bufferBuilder = getBufferBuilder(targetChannel);
// 将序列化器中 StreamRecord 的二进制复制到 Buffer中
SerializationResult result = serializer.copyToBufferBuilder(bufferBuilder);
while (result.isFullBuffer()) {
numBytesOut.inc(bufferBuilder.finish());
numBuffersOut.inc();
// If this was a full record, we are done. Not breaking out of the loop at this point
// will lead to another buffer request before breaking out (that would not be a
// problem per se, but it can lead to stalls in the pipeline).
// 数据完全写入到 Buffer 中,写入完毕
if (result.isFullRecord()) {
pruneTriggered = true;
bufferBuilders[targetChannel] = Optional.empty();
break;
}
// 数据没有完全写入,buffer已满,则申请新的 BufferBuilder 继续写入
bufferBuilder = requestNewBufferBuilder(targetChannel);
result = serializer.copyToBufferBuilder(bufferBuilder);
}
checkState(!serializer.hasSerializedData(), "All data should be written at once");
// 数据写入之后,通过 flushAlways 控制是立即发送还是延迟发送
if (flushAlways) {
targetPartition.flush(targetChannel);
}
return pruneTriggered;
}
数据清理
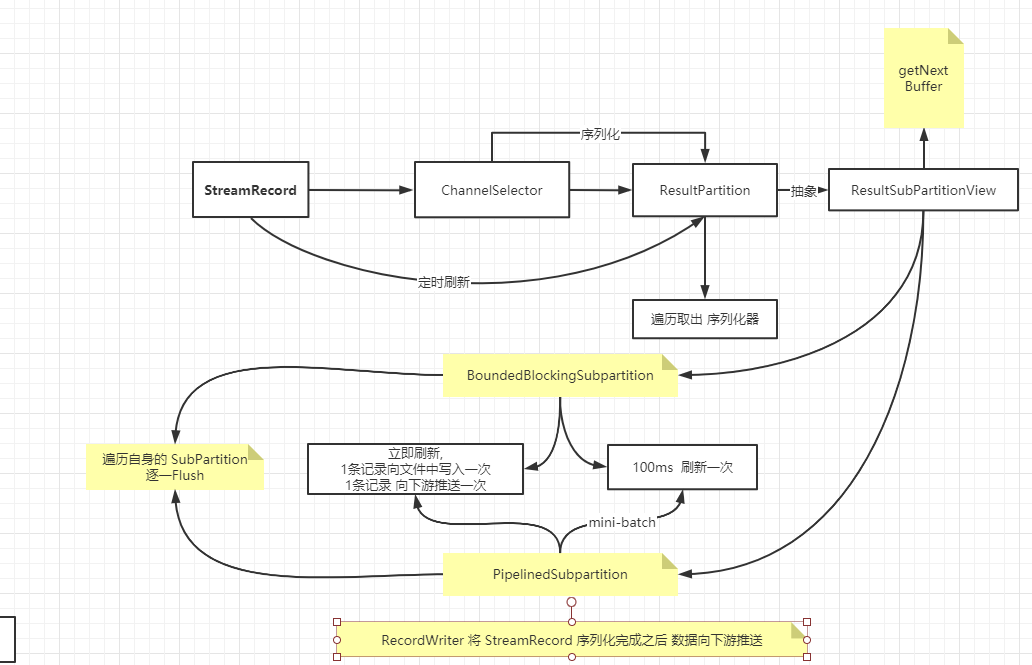
RecordWriter 将 StreamRecord 序列化完成之后,会根据 flushAlways 参数决定是否立即将数据进行推送,相当于每条记录发送一次,这样做延迟最低,但是吞吐量会下降,Flink 默认的做法是单独启动一个线程,每隔一个固定时间刷新 (flush) 一次所有的 Channel ,本质上是一种批量处理 .
当所有数据都写入完成之后需要调用 Flush 方法将可能残留在序列化器 Buffer 中的数据都强制输出.Flush 方法会遍历每个 ResultSubPartition 然后依次取出该 ResultSubPartition 对应的序列化器,如果其中还有残留的数据,则将数据全部输出. (这也是每个 ResultSubPartition 都对应一个序列化器的原因)
数据写入之后,无论是即时 Flush 还是定时 Flush , 根据结果子分区的类型的不同,行为都会有所不同
-
PipelinedSubpartition
如果是立即刷新,则相当于一条记录向下游推送一次,延迟最低,但是吞吐量会下降,Flink 默认的做法是单独启动一个线程,默认 100ms 刷新一次,本质上是一种 mini-batch ,这种 mini-batch 只是为了增大吞吐量
ResultPartition 遍历自身的 PipeliedSubPartition,逐一进行 Flush , Flush 之后 通知 ResultSubPartitionView 有可用数据,可以进行数据的读取了.
private void notifyDataAvailable() {
if (readView != null) {
readView.notifyDataAvailable();
}
}
-
BoundedBlockingSubpartition
如果是立即刷新,则相当于 1 条记录向文件中写入1次,否则认为是延迟刷新,每隔一定时间周期将该事件周期内的数据进行批量处理,默认是 100ms 刷新一次, 数据刷新的时候根据 ResultPartition 中 ResultSubPartition 的类型的不同有不同的刷新行为.
ResultPartition 遍历自身的 BoundedBlockingSubPartition , 逐一进行 Flush , 写入之后回收 Buffer .
该类型的 SubPartition 并不会触发数据可用通知
private void writeAndCloseBufferConsumer(BufferConsumer bufferConsumer) throws IOException {
try {
final Buffer buffer = bufferConsumer.build();
try {
if (parent.canBeCompressed(buffer)) {
final Buffer compressedBuffer =
parent.bufferCompressor.compressToIntermediateBuffer(buffer);
data.writeBuffer(compressedBuffer);
if (compressedBuffer != buffer) {
compressedBuffer.recycleBuffer();
}
} else {
data.writeBuffer(buffer);
}
numBuffersAndEventsWritten++;
if (buffer.isBuffer()) {
numDataBuffersWritten++;
}
} finally {
buffer.recycleBuffer();
}
} finally {
bufferConsumer.close();
}
}
网络通信
一般的流计算系统德消息传递,都是基于推送机制的
- 数据从上游处理节点推送给下游处理节点
在这个过程中如果下游的处理能力无法应对上游的数据发送速度,那么就会导致数据在下游处理节点累积,一旦超过了处理限度,就可能会发生数据丢失、进程错误、内存空间不足、CPU 使用率过高等 各种难以预测的情况,最终导致资源耗尽甚至系统崩溃
- 为了保持整个流计算系统的稳定性,需要对上游节点发送数据的速度进行流量控制,这种控制机制 叫做反压 (
BackPressurs)
很多种情况都会导致反压
- JVM 垃圾回收的停顿导致数据的积压
- 秒杀等高并发情况导致的瞬间流量爆发
Task中业务逻辑复杂导致数据记录处理比较慢- …
网络连接
Flink 的 Task 在物理层上时基于 TCP 连接,且 TaskManager 上所有 Task 共享一个 TCP 连接
- 所以 Flink 1.5 版本之前的流控机制是基于连接的
- 跨网络的数据交换 [上]
- 经过
ResultPartition、NettyBuffer、TCP、InputGate
无流控
当 Task 的发送缓冲池耗尽时,也就是结果子分区的 Buffer 队列中或者更底层的基于 Netty 的网络栈的网络缓冲区满时,生产者 Task 就被阻塞,无法继续处理数据,开始产生背压.
当 Task 的接收缓冲区耗尽时,也是类似的效果,较低层网络栈中传入的 Netty Buffer 需要通过网络缓冲区提供给 Flink.
如果相应 Task 的缓冲池中没有可用的 Buffer,Flink 停止从该 InputChannel 读取,直到在缓冲区中可用 Buffer 时才会开始读取数据并交给算子进行处理.
这将对使用该 TCP 连接的所有 Task 造成背压,影响范围是整个 TaskManager 上运行的 Task.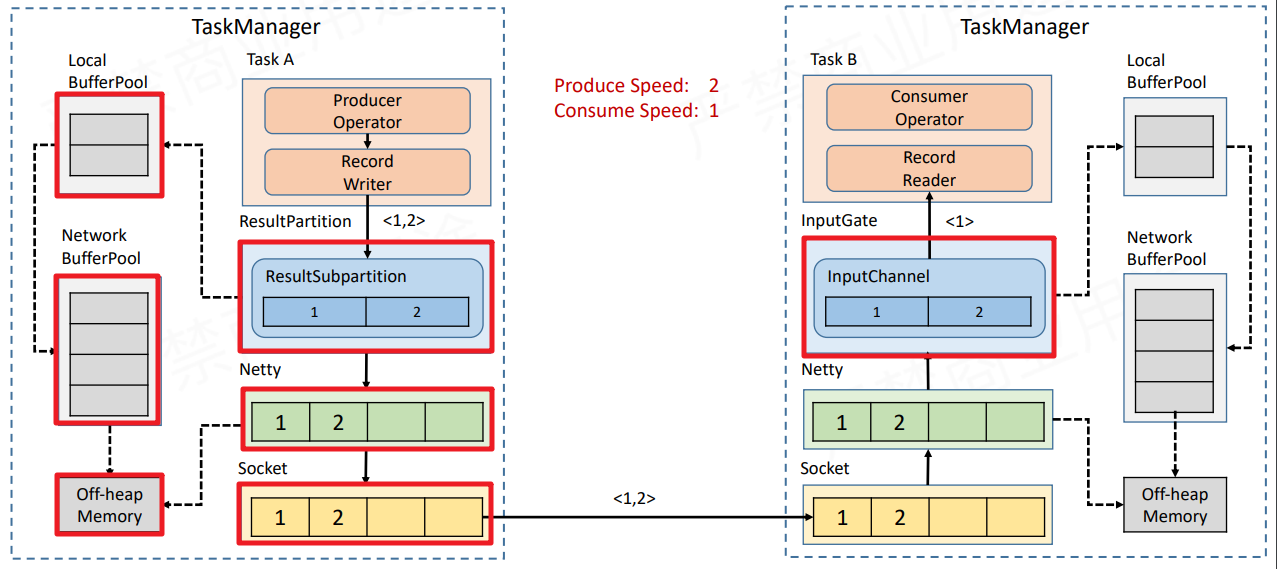
基于信用的流控
Flink 原有流控机智的基础上,拓展出了新的流控机制 — 基于信用的流量控制,用来解决同一个 TaskManager 上 Task 之间相互影响的问题.
基于信用的流控机制可以确保下游总是有足够的内存接受上游的数据,不会出现下游无法接收上游数据的情况,
该流控机制作用于 Flink 的数据传输层,在结果子分区 (ResultSubPartition) 和输入通道 (InputChannel) 引入了信用机制,每个远端的 InputChannel 现在都有自己的一组 独占缓冲区,不再使用共享的本地缓冲池.LocalBufferPool 中的 Buffer 称为 浮动缓存 (Float Buffer),因为 LocalBufferPool 的大小是浮动的,并可以用于所有 InputChannel.
- 下游接收端将可用的
Buffer数量作为信用值 (1Buffer= 1 信用) 通知给上游 - 每个结果子分区 (
ResultSubPartition) 将跟踪其对应的InputChannel的信用值 - 如果信用可用,则缓存仅转发到较低层的网络栈,每发送一个
Buffer都会对InputChannel的信用值 减 1 - 在发送
Buffer的同时,还会发送前结果子分区 (ResultSubPartition) 队列中的积压数据量 (Backlog Size) - 下游的接收端会根据积压数据量从浮动缓冲区申请适当数量的
Buffer, 以便更快的处理上游积压等待发送的数据 - 下游接收端首先会尝试获取与
Backlog大小一样多的Buffer,但浮动缓冲区的可用Buffer数量可能不够,只能尝试一部分甚至获取不到Buffer- 保证每次上游发送的数据都是下游
InputChannel的Buffer可以承受的数据量
- 保证每次上游发送的数据都是下游
- 下游接收端会充分利用获取到的
Buffer,并且会持续等待新的可用Buffer
基于流控的流量控制使用配置参数 buffer-per-channel 参数来设置独占的缓冲池大小,使用配置参数 floating-buffers-per-gate 设置 InputGate 输入网关的缓冲池大小,输入网关的缓冲池由属于该网关的 InputChannel 共享,其缓冲区上限与基于连接的流控机制相同.
一般情况下,使用这两个参数的默认值,理论上可以达到与不采用流控机制的吞吐量一样高.
流量控制的最大吞吐量至少于没有流量控制时一样高,前提是网络的延迟比较低.
相比没有流量控制的接收器的背压机制,信用机制提供了更直接的控制逻辑:
- 如果接收缓存不足,其可用信用值会降到 0 ,发送方会停止发送.
- 这样只在这个
InputChannel上存在背压,而不会影响其他Task, 从而避免一个Task的处理能力不足导致其所在的TaskManager上所有的Task都无法接收数据的问题.

若有收获,就点个赞吧
0 人点赞
