Flink Checkpoint 是一种容错恢复机制。这种机制保证了实时程序运行时,即使突然遇到异常或者机器问题时也能够进行自我恢复。
出现的原因:
由于程序一直在运行,运行过程中可能存在 机器故障、网络问题、外界存储问题等,要想实时任务一直能稳定运行,实时任务需要有自动容错恢复的功能。(批处理可以选择重新计算一次,而实时任务会因为一直运行的特性,从头开始计算成本高) —-> 需要有一个机制能够减少 容错恢复的时间
因为每次都是从最新的 Chekpoint 点位开始状态恢复,而不是从程序启动的状态开始恢复。举个列子,如果你有一个运行一年的实时任务,如果容错恢复是从一年前启动时的状态恢复,实时任务可能需要运行很久才能恢复到现在状态,这一般是业务方所不允许的。
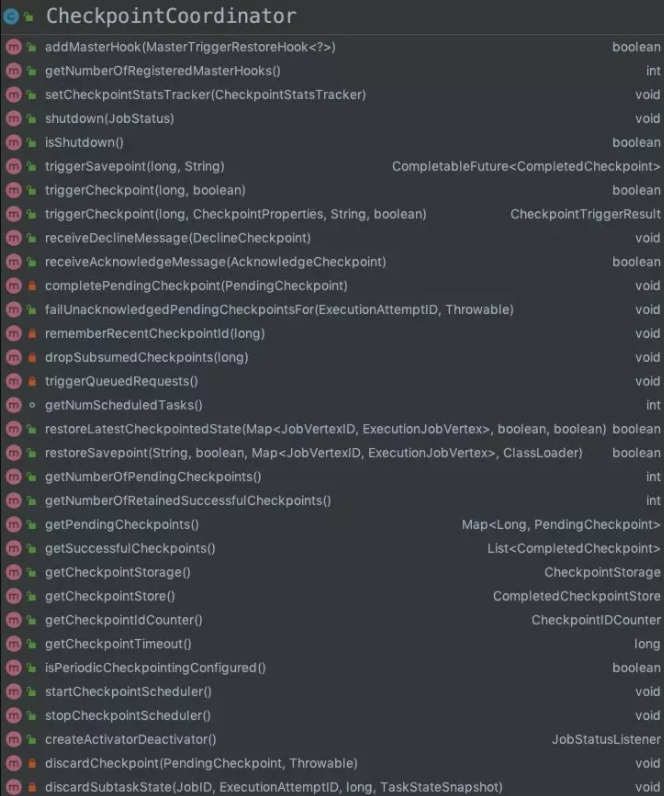
Flink CheckpointCoordinator 中有几个比较重要的方法:
- triggerCheckpoint,触发 Flink 任务进行 Checkpoint 的方法
- triggerSavepoint,触发 Flink 任务 Savepoint 的方法
- restoreSavepoint,Flink 任务从 Savepoint 状态恢复
- restoreLatestCheckpointedState,从最新一次 Checkpoint 点位状态恢复
- receiveAcknowledgeMessage,接受 Operator SubTask Checkpoint 完成的消息并处理
Flink CheckpointCoordinator 类是在 ExecutionGraph 形成时进行初始化的,具体则是在 ExecutionGraph 创建之后,调用 enableCheckpointing 方法,然后在该方法中,CheckpointCoordinator 进行创建。以下是 Flink Checkpoint 触发的时序图: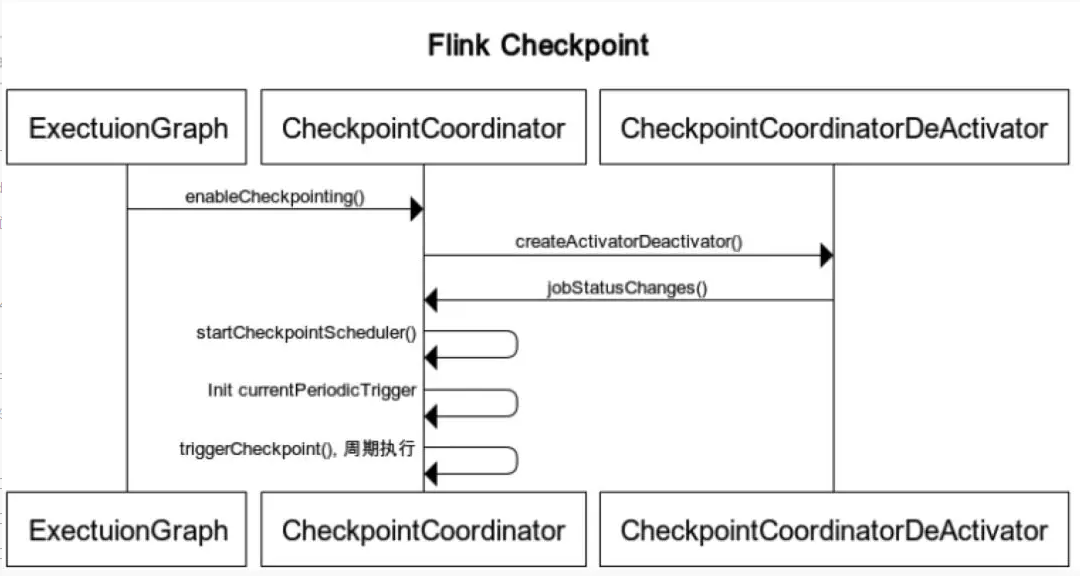
当 Flink 作业状态由创建到运行时,CheckpointCoordinator 中的 ScheduledThreadPoolExecutor 会定时执行 ScheduledTrigger 中的逻辑。ScheduledTrigger 本质就是一个 Runnable,run 方法中执行 triggerCheckpoint 方法。
Checkpoint 流程
一次 Flink Checkpoint 的流程是从 CheckpointCoordinator 的 triggerCheckpoint 方法开始,下面来看看一次 Flink Checkpoint 涉及到的主要内容:
Checkpoint 开始之前先进行预检查,比如检查最大并发的 Checkpoint 数,最小的 Checkpoint 之间的时间间隔。默认情况下,最大并发的 Checkpoint 数为 1,最小的 Checkpoint 之间的时间间隔为 0.
Checkpoint 开始之前先进行预检查,比如检查最大并发的 Checkpoint 数,最小的 Checkpoint 之间的时间间隔。默认情况下,最大并发的 Checkpoint 数为 1,最小的 Checkpoint 之间的时间间隔为 0.
判断所有 Source 算子的 Subtask (Execution) 是否都处于运行状态,有则直接报错。同时检查所有待确认的算子的 SubTask(Execution)是否是运行状态,有则直接报错。
创建 PendingCheckpoint,同时为该次 Checkpoint 创建一个 Runnable,即超时取消线程,默认 Checkpoint 十分钟超时。
循环遍历所有 Source 算子的 Subtask(Execution),最底层调用 Task 的triggerCheckpointBarrier, 广播 CheckBarrier 到下游 ,同时 Checkpoint 其状态。
Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier ,
- 下游接收 barrier ( 需要 barrier 都到齐才会开始做 checkpoint)
- Task 开始同步阶段 snapshot
- Task 开始异步阶段 snapshot
下游的输入中有 CheckpointBarrierHandler 类来处理 CheckpoinBarrier,然后会调用 notifyCheckpoint 方法,通知 Operator SubTask 进行 Checkpoint。
每当Operator SubTask 完成 Checkpoint 时,都会向 CheckpointCoordoritor 发送确认消息。CheckpointCoordinator 的 receiveAcknowledgeMessage 方法会进行处理。
在一次 Checkpoint 过程中,当所有从 Source 端到 Sink 端的算子 SubTask 都完成之后,CheckpointCoordoritor 会通知算子进行 notifyCheckpointCompleted 方法,前提是算子的函数实现 CheckpointListener 接口。
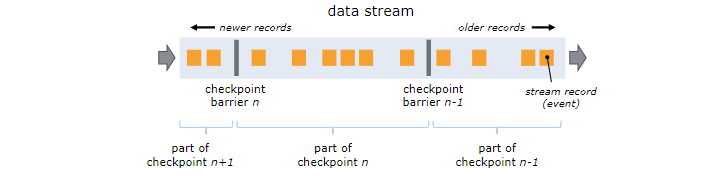
Flink 会定时在任务的 Source 算子的 SubTask 触发 CheckpointBarrier,CheckpointBarrier 是一种特殊的消息事件,会随着消息通道流入到下游的算子中。只有当最后 Sink 端的算子接收到 CheckpointBarrier 并确认该次 Checkpoint 完成时,该次 Checkpoint 才算完成。所以在某些算子的 Task 有多个输入时,会存在 Barrier 对齐时间,我们可以在 Flink Web UI上面看到各个 Task 的 CheckpointBarrier 对齐时间。
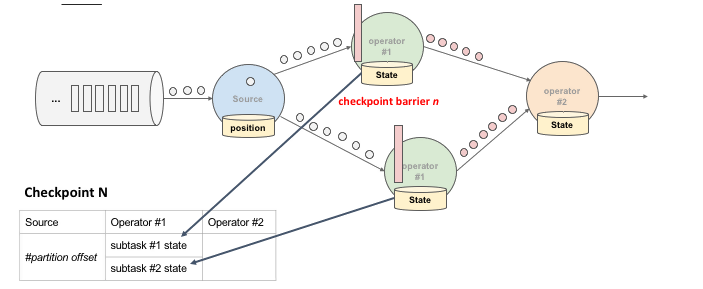
下图是一次 Flink Checkpoint 实例流程示意图: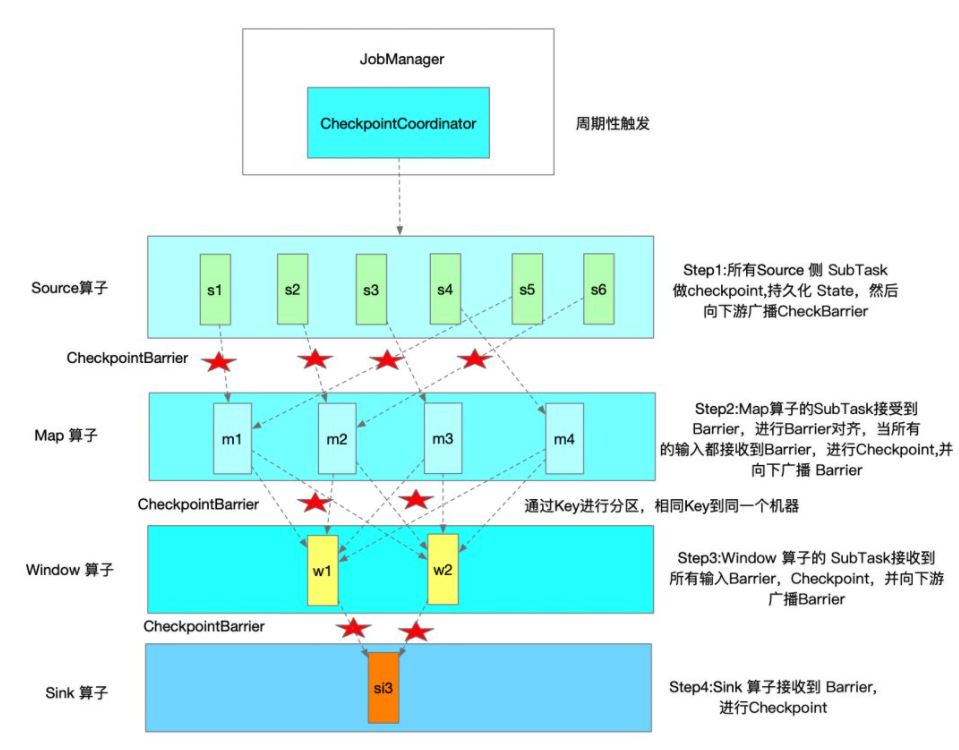
CheckPointing 流程分析
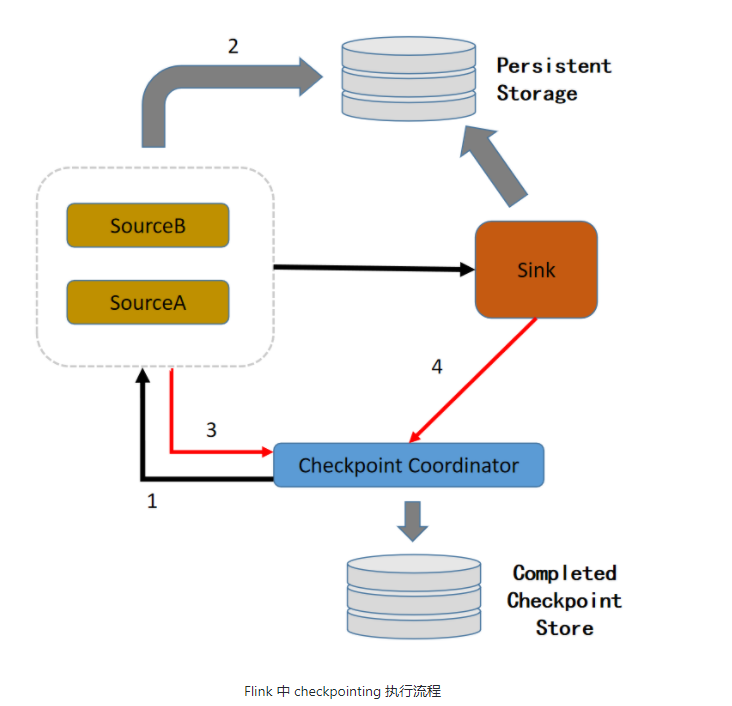
- Coordinator 向所有 Source 节点发出 Barrier。
- Task 从输入中收到所有 Barrier 后,将自己的状态写入持久化存储中,并向自己的下游继续传递 Barrier。
- 当 Task 完成状态持久化之后将存储后的状态地址通知到 Coordinator。
- 当 Coordinator 汇总所有 Task 的状态,并将这些数据的存放路径写入持久化存储中,完成 CheckPointing。
Flin Checkpoint 保存的任务状态在程序取消停止时,默认会进行清除。Checkpoint 状态保留策略主要有两种:
```java
DELETE_ON_CANCELLATION,RETAIN_ON_CANCELLATION
- DELETE_ON_CANCELLATION 表示当程序取消时,删除 Checkpoint 存储的状态文件- RETAIN_ON_CANCELLATION 表示当程序取消时,保存之前的 Checkpoint 存储的状态文件 用户可以结合业务情况<br />- 设置 Checkpoint 保留模式:```javaStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/** 开启 checkpoint */env.enableCheckpointing(10000);/** 设置 checkpoint 保留策略,取消程序时,保留 checkpoint 状态文件*/env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanu
Flink Checkpoint 语义
Flink Checkpoint 支持两种语义:
- Exactly_Once
- At_least_Once
- 默认的 Checkpoint 语义是 Exactly_Once。具体语义含义如下:
Exactly_Once 含义是:保证每条数据对于 Flink 任务的状态结果只影响一次。打个比方,比如 WordCount 程序,目前实时统计的 “hello” 这个单词数为 5,同时这个结果在这次 Checkpoint 成功后,保存在了 HDFS。在下次 Checkpoint 之前, 又来 2 个 “hello” 单词,突然程序遇到外部异常自动容错恢复,会从最近的 Checkpoint 点开始恢复,那么会从单词数为 5 的这个状态点开始恢复,Kafka 消费的数据点位也是状态为 5 这个点位开始计算,所以即使程序遇到外部异常自动恢复时,也不会影响到 Flink 状态的结果计算。
At_Least_Once 含义是:每条数据对于 Flink 任务的状态计算至少影响一次。比如在 WordCount 程序中,你统计到的某个单词的单词数可能会比真实的单词数要大,因为同一条消息,当 Flink 任务容错恢复后,可能将其计算多次。
Flink 中 Exactly_Once 和 At_Least_Once 具体是针对 Flink 任务状态而言的,并不是 Flink 程序对消息记录只处理一次。举个例子,当前 Flink 任务正在做 Checkpoint,该次 Checkpoint 还没有完成,这次 Checkpoint 时间段的数据其实已经进入 Flink 程序处理,只是程序状态没有最终存储到远程存储。当程序突然遇到异常,进行容错恢复时,那么就会从最新的 Checkpoint 进行状态恢复重启,上一次 Checkpoint 成功到这次 Checkpoint 失败的数据还会进入 Flink 系统重新处理,具体实例如下图: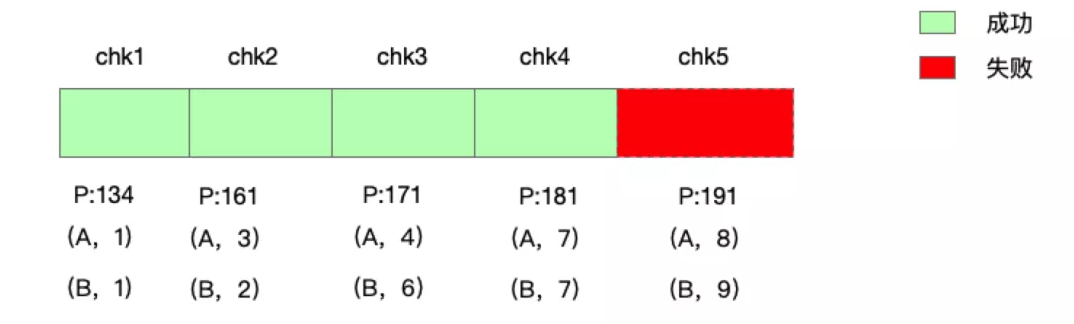
上图中表示一个 WordCount 实时任务的 Checkpoint,在进行 chk-5 Checkpoint 时,突然遇到程序异常,那么实时任务会从 chk-4 进行恢复,那么之前 chk-5 处理的数据,Flink 系统会再次进行处理。不过这些数据的状态没有 Checkpoint 成功,所以 Flink 任务容错恢复再次运行时,对于状态的影响还是只有一次。
Exactly_Once 和 At_Least_Once 具体在底层实现大致相同,具体差异表现在 CheckpointBarrier 对齐方式的处理:
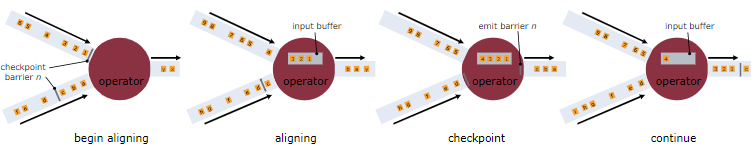
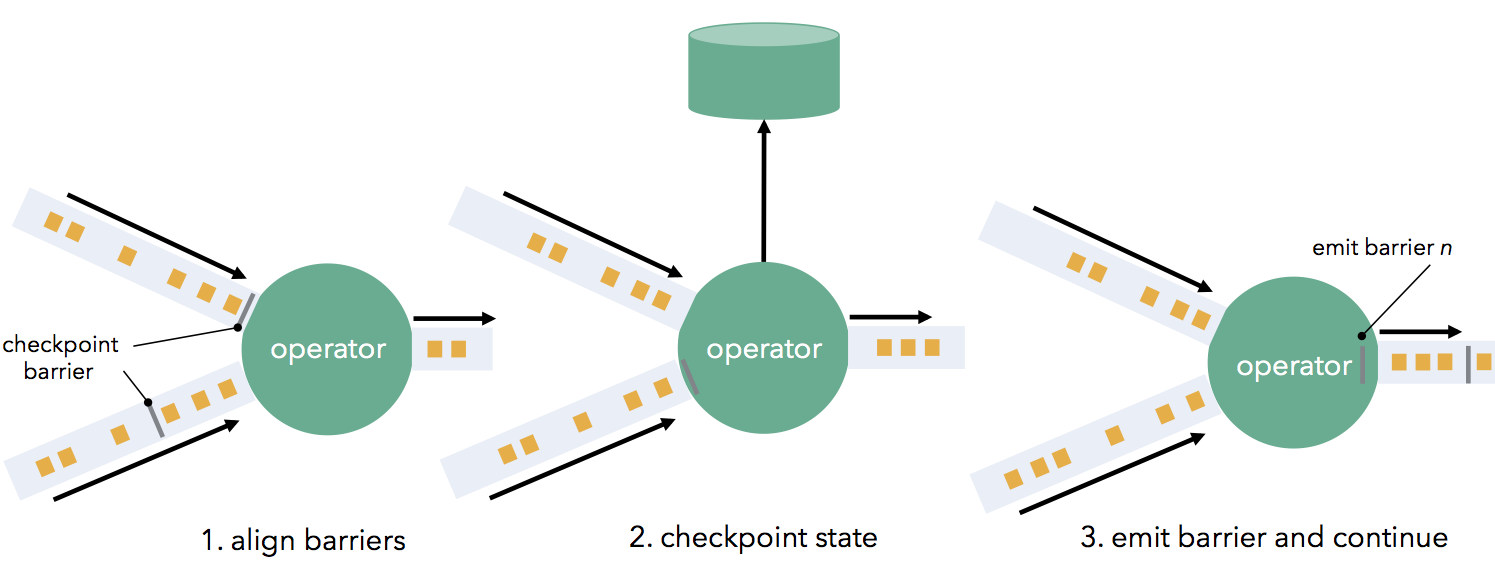
如果是 Exactly_Once 模式,某个算子的 Task 有多个输入通道时,当其中一个输入通道收到 CheckpointBarrier 时,Flink Task 会阻塞该通道,其不会处理该通道后续数据,但是会将这些数据缓存起来,一旦完成了所有输入通道的 CheckpointBarrier 对齐,才会继续对这些数据进行消费处理。
对于 At_least_Once,同样针对某个算子的 Task 有多个输入通道的情况下,当某个输入通道接收到 CheckpointBarrier 时,它不同于 Exactly Once,即使没有完成所有输入通道 CheckpointBarrier 对齐,At Least Once 也会继续处理后续接收到的数据。所以使用 At Least Once 不能保证数据对于状态计算只有一次的计算影响。
实战
Flink Checkpoint 常见失败原因有
- 用户代码逻辑没有对于异常处理,让其直接在运行中抛出。比如解析 Json 异常,没有捕获,导致 Checkpoint失败,或者调用 其他服务 超时异常等等。
- 依赖外部存储系统,在进行数据交互时,出错,异常没有处理。比如输出数据到 Kafka、Redis、HBase等,客户端抛出了超时异常,没有进行捕获,Flink 任务容错机制会再次重启。
- 内存不足,频繁GC,超出了 GC 负载的限制。比如 OOM 异常。
- 网络问题、机器不可用问题等等。
- checkpoint 太大 导致 checkpoint 失败
Flink Checkpoint 优化
- Checkpoint 时间比设置的 Checkpoint 间隔还要长时 (设置最少间隔时间) 避免频繁 做Checkpoint
当 Checkpoint 时间比设置的 Checkpoint 间隔时间要长时,可以设置 Checkpoint 间最小时间间隔。这样在上次 Checkpoint 完成时,不会立马进行下一次 Checkpoint,而是会等待一个最小时间间隔,之后再进行 Checkpoint。否则,每次 Checkpoint 完成时,就会立马开始下一次 Checkpoint,系统会有很多资源消耗 Checkpoint 方面,而真正任务计算的资源就会变少。
- 状态太大 进行恢复时间长(浪费时间在大量的网络传输上), 可以开启状态本地恢复
如果Flink状态很大,在进行恢复时,需要从远程存储上读取状态进行恢复,如果状态文件过大,此时可能导致任务恢复很慢,大量的时间浪费在网络传输方面。此时可以设置 Flink Task 本地状态恢复,任务状态本地恢复默认没有开启,可以设置参数 state.backend.local-recovery 值为 true 进行激活。
- Checkpoint 保存数设置多一些 避免磁盘副本损坏问题
Checkpoint 保存数,Checkpoint 保存数默认是1,也就是只保存最新的 Checkpoint 的状态文件,当进行状态恢复时,如果最新的 Checkpoint 文件不可用时(比如 HDFS 文件所有副本都损坏或者其他原因),那么状态恢复就会失败,如果设置 Checkpoint 保存数 2,即使最新的Checkpoint恢复失败,那么Flink 会回滚到之前那一次 Checkpoint 的状态文件进行恢复。考虑到这种情况,用户可以增加 Checkpoint 保存数。
建议设置的 Checkpoint 的间隔时间最好大于 Checkpoint 的完成时间
选择合适的 Checkpoint 存储方式
CheckPoint 存储方式有 MemoryStateBackend、FsStateBackend 和 RocksDBStateBackend。由官方文档可知,不同 StateBackend 之间的性能以及安全性是有很大差异的。通常情况下,MemoryStateBackend 适合应用于测试环境,线上环境则最好选择 RocksDBStateBackend。
RocksDB 妙处
- RocksDBStateBackend 是外部存储,其他两种 Checkpoint 存储方式都是 JVM 堆存储。受限于 JVM 堆内存的大小,Checkpoint 状态大小以及安全性可能会受到一定的制约;
- 其次 RocksDBStateBackend 支持增量检查点。
- 增量检查点机制(Incremental Checkpoints)仅仅记录对先前完成的检查点的更改,而不是生成完整的状态。
- 与完整检查点相比,增量检查点可以显著缩短 checkpointing 时间,但代价是需要更长的恢复时间。
6.合理增加算子(Task)并行度
Checkpointing 需要对每个 Task 进行数据状态采集。单个 Task 状态数据越多则 Checkpointing 越慢。所以我们可以通过增加 Task 并行度,减少单个 Task 状态数据的数量来达到缩短 CheckPointing 时间的效果。
7.缩短算子链(Operator Chains)长度
Flink 算子链(Operator Chains)越长,Task 也会越多,相应的状态数据也就更多,Checkpointing 也会越慢。通过缩短算子链长度,可以减少 Task 数量,从而减少系统中的状态数据总量,间接的达到优化
解决端到端的一致性方法
做幂等以及事务写,幂等的话,可以使用 KV 存储系统来做幂等,因为 KV 存储系统的多次操作结果都是相同的。Flink 内部目前支持二阶段事务提交,Kafka 0.11 以上版本支持事务写,所以支持 Flink 端到 Kafka 端的 EXACTLY_ONCE。
并不是任意两个 operator 就能 chain 一起的。其条件还是很苛刻的:
- 上下游的并行度一致
- 下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
- 上下游节点都在同一个 Slot Group 中
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 两个节点间数据分区方式是 forward
- 用户没有禁用 chain
- 在同一个TaskManager 上
基于以上这些规则,我们在代码层面上合并了相关度较大的一些 Task,使得平均的操作算子链长度至少缩短了 60%~70%。
Checkpoint 失败的排查思路
Checkpoint 慢

若有收获,就点个赞吧
0 人点赞
