 创新点:
创新点:
1、线上服务-线下算法模型联合设计优化
2、基于NTM的MIMN算法模型设计
一、论文背景
在搜索、广告以及推荐系统中,CTR预估是一个十分核心的模块,CTR预估的好坏直接影响最终排序的结果,从而影响用户的用户体验。在CTR预估任务中,无论是采用传统的LR、FM模型还是近几年发展迅速的深度模型,特征工程都是十分重要的一步,如何有效的构建特征会直接影响CTR预估的结果。通常用户的历史行为特征是十分重要的一类特征,随着我们引入更长时间的历史行为特征之后,线上系统的性能压力会越来越大,由于在部署线上系统时,采用更长时间的用户历史行为特征意味着需要存储更长时间的用户行为数据,这给线上的内存占用以及计算耗时都得来了巨大的压力;同时随着我们不断的增加越来越多的特征,其带来的收益也越来越微弱, 所以在增加特征的同时需要更复杂更先进的模型与之相匹配,才能最大程度挖掘出两者的潜力。随着模型的进一步发展与演化,模型的复杂度也越来越高,在线上部署复杂模型带来的开销也越来越大,所以如何联合设计复杂模型与线上系统成为亟待解决的问题。
通常我们在对用户历史行为特征建模的时候会采用两种方式,一种是基于pooling的建模,另外一种是序列化建模,前者认为用户的历史行为之间是相互独立的,然后在此基础上sum-pooling、max-pooling以及attention等机制;后者认为用户的一系列历史行为具备某种序列化信息,通常采用RNN、LSTM等循环神经网络来建模。无论采用哪种方式,随着用户历史行为特征序列长度越来越长,将其应用于线上系统变得越来越困难,因为线上系统(CTR预估)通常对耗时要求比较高(需要在一定时间内返回结果),系统的线上延迟和存储开销会随着用户历史行为序列的长度增加而线性增加,当然随着用户行为特征序列长度的增加,当然也会给系统预测指标带来提升,下图是文中给出的分析结果 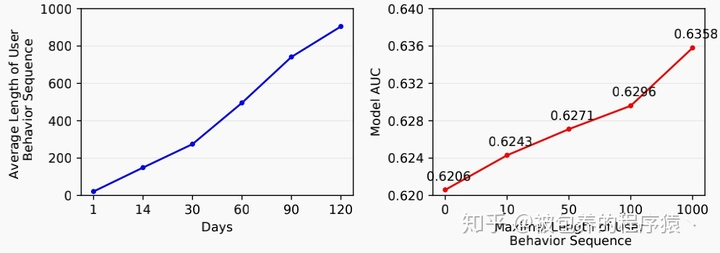
行为序列长度对AUC的影响
从上图中可以发现,当用户行为序列长度增加到1000时,AUC会有1.5%的提升,这种幅度的提升在CTR预估任务当中是非常显著的提升了,所以为了能够给CTR预估模块带来进一步的提升,文章从线下算法到线上系统进行了联合优化设计。
本文的创新点主要包括两个方面:一是工程方面(主要是线上系统的设计优化),二是算法方面(考虑线上系统性能方面的压力,对算法的结构进行改进与优化),前者主要体现在将用户兴趣建模的功能单独解构出来,设计成一个单独的模块UIC,后者主要体现在基于memory network的MIMN算法模型。两者是相辅相成的,缺一不可,正是两者的联合设计与优化,才能使得线上采用长期用户行为特征序列成为了可能
二、实时CTR预测系统
在线上CTR预估系统中,CTR预估模块接收来自召回阶段的输出结果(候选集)之后,会实时的对该候选集中的候选广告进行预测打分,通常这一过程需要在一定时间内完成,通常是10毫秒,具体线上系统的结构如下图所示: 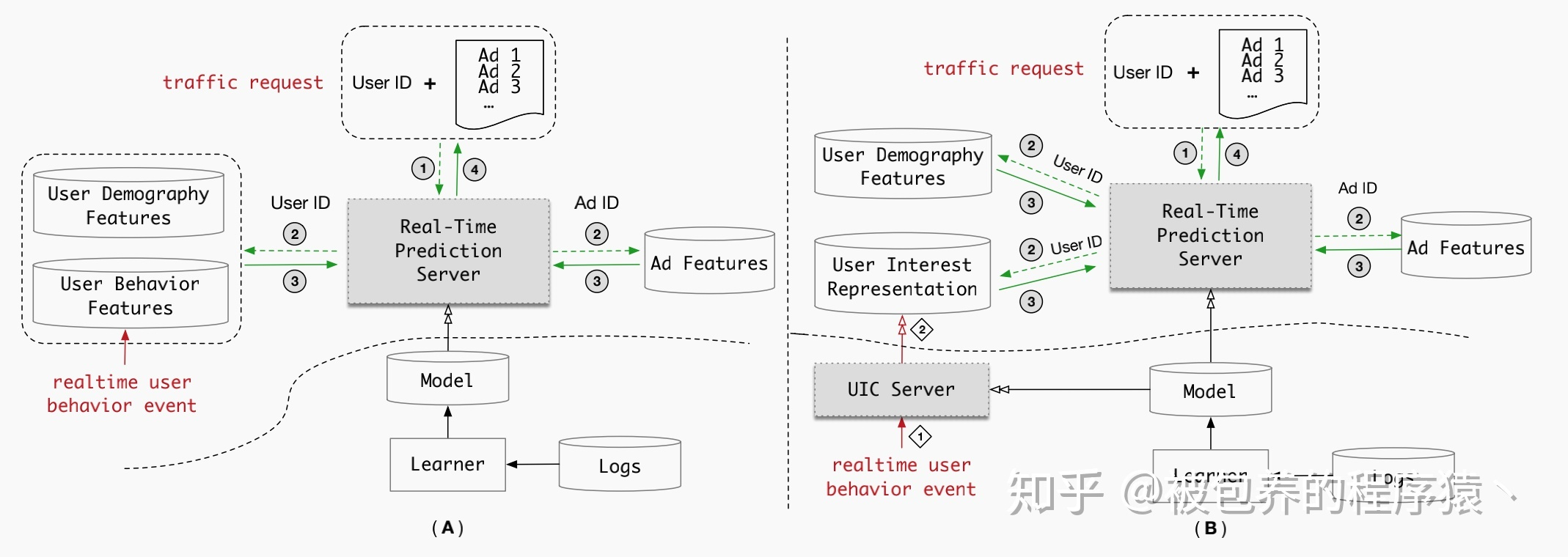
线上系统架构
上图的左侧为传统的线上实时CTR预估模块,右侧为基于UIC的线上实时CTR预估模块,从上图的结构中可以发现,在传统的实时CTR预估模块中,用户行为序列建模是在predict server中完成的,而在基于UIC的预估系统中,单独构建了一个新的模块(即UIC)来完成用户行为序列的建模计算。上文中已经分析了对用户长期历史行为序列建模可以给系统带来巨大的提升,通常对用户短期行为序列建模时,为保证系统的低时延、高吞吐量,用户行为特征通常被存储在分布式内存系统中,当接收到一个请求时,predict server从内存中读取相应的用户行为特征并进行实时的CTR预估。但是对长期用户行为序列建模时主要存在两反面的苦难,具体如下
(1)存储限制
在淘宝这个电商平台上总共存在超过6亿的用户,如果对每个用户构建长度为150的用户行为序列,那将会消耗1TB的存储空间;当用户行为序列的长度增长到1000的时候,存储空间的消耗将会达到6TB,而且消耗的空间会随着用户行为序列长度而线性增长。如前文所述,为保证低时延和高吞吐量采用内存方式进行存储的话,消耗的空间过于巨大,而且如此大的内存占用给用户行为特征的更新和计算也带来了巨大的挑战。
(2)延迟限制
在采用现有的DIEN模型及其对应的线上系统,QPS为500的时候系统延迟在14ms,当用户行为序列长度增加到1000时,QPS为500的时候系统延迟达到了200ms,而实际系统要求QPS为500的时候系统延迟要小于30ms,也就是说采用现有的线上系统架构是无法支撑如此长的用户行为序列的,所以必须对线上系统进行相应的升级优化
为了解决上述的两个主要问题,本文构建了一个单独的模块UIC来完成用户行为序列的建模计算工作。UIC server负责存储每个用户最近的行为兴趣,而且UIC server的核心在于其更新策略,即用户行为序列的更新只依赖于具体的触发事件,而不依赖于请求,因此UIC可以被用于低时延CTR预估系统中,采用UIC这种线上架构有效的降低了系统的延时,当用户行为序列长度为1000时,QPS为500时,线上系统延迟仅为19ms,这可以说UIC为系统耗时的降低带来了巨大的提升。
三、离线MIMN模型
在之前的文章中我们提到,到采用RNN的结构对长序列数据进行建模的时候,效果会变得非常差,所以有人提出了Attention机制来解决这个问题,阿里妈妈定向广告团队上一代的算法模型就是基于Attention机制的DIEN模型,但是随着用户行为序列的长度进一步增加,采用这种模型结构由于计算复杂度较高,同样无法满足线上延迟的需求。所以文章借鉴神经图灵机利用额外存储模块来解决长序列数据问题的思路,提出了一种全新的CTR预估模型MIMN(Multi-Channel User Interest Memory Network),整个系统的模型结构如下图所示 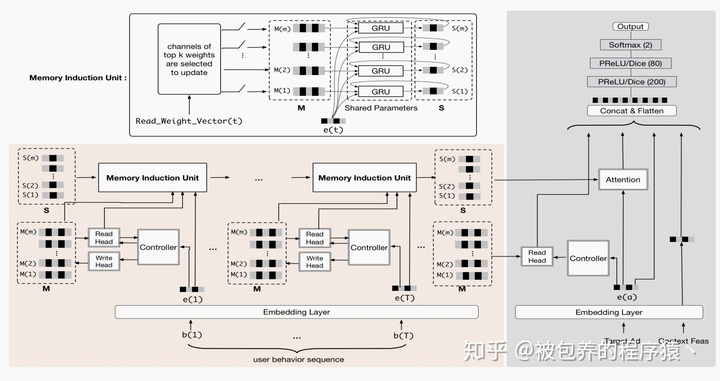
MIMN系统模型
整个网络的左侧主要负责用户兴趣的建模,该部分的核心及创新点主要包括以下两个方面:一方面是NTM中基本的memory read和memory write操作;另一方面是为提取高阶信息而采用多通道GRU的memory induction unit。网络的右侧则为传统的embedding+MLP的经典结构。
(1)神经图灵机
神经图灵机利用一个额外的记忆网络来存储长序列信息,在时间t,记忆网络可以表示为矩阵Mt,其包含m个memory slot,Mt(i){i=1,…,m},NTM通过一个controller模块进行读写操作。
- memory read
当输入第t个用户行为embedding向量,controller会生成一个用于寻址的read key kt,首先遍历全部的memory slot,生成一个权重向量wtr
最后得到一个加权求和的结果rt 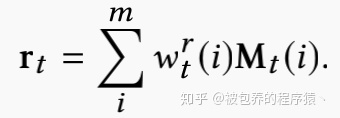
- memory write
类似于memory read中的权重向量的计算,在memory write阶段同样会计算一个权重向量wtw。除此之外,还会生成两个向量,一个是add vector at,另一个是erase vector et,他们都是controller生成的并且他们控制着记忆网络的更新过程。记忆网络的更新过程如下所示: 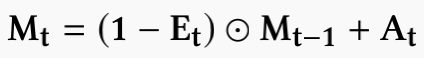
其中 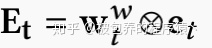
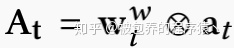
(2)Memory utilization regularization
传统的NTM存在memory利用分配不平衡的问题,这种问题在用户兴趣建模中尤为重要,因为热门的商品很容易出现在用户行为序列中,这部分商品会主要记忆网络的更新,为此文章提出一种名为memory utilization regularization。该策略的核心思想就是对不同的memory slot的写权重向量进行正则,来保证不同memory slot的利用率较为平均,具体如何进行正则化操作可以参考正文,还是比较容易理解的 ,这里只做简要描述。
截止到时间t的累计更新权重可以表示为 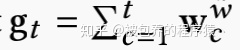
其中wcw表示的是时刻c的re-balanced写权重,计算方式如下: 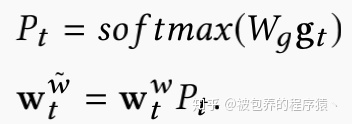
原始写权重与Pt相乘之后得到re-balanced写权重,其中Pt为权重转移矩阵,计算该矩阵需要两个参数:一是gt向量,另外一个是网络参数Wg,该参数是通过正则化loss学习到的。具体的正则化loss可以表示为: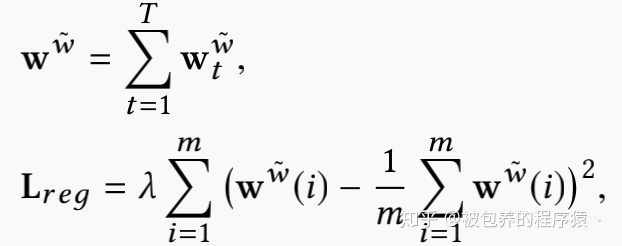
利用上述正则化方式可以有效平衡memory的利用率,具体实验结果参考如下: 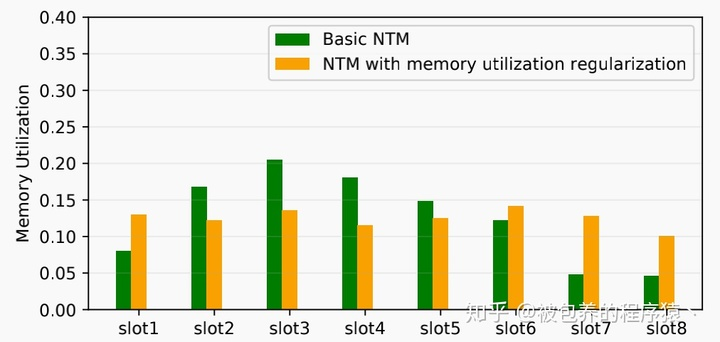 Memory utilization regularization效果
Memory utilization regularization效果
(3)memory induction unit
借鉴NTM的网络结构可以帮助有效构建用户长时应为序列,但是无法进一步提取用户高阶的信息,比如在用户较长的历史浏览行为中,这一系列行为可以被认为是多个channel,具体可以表示为如下: 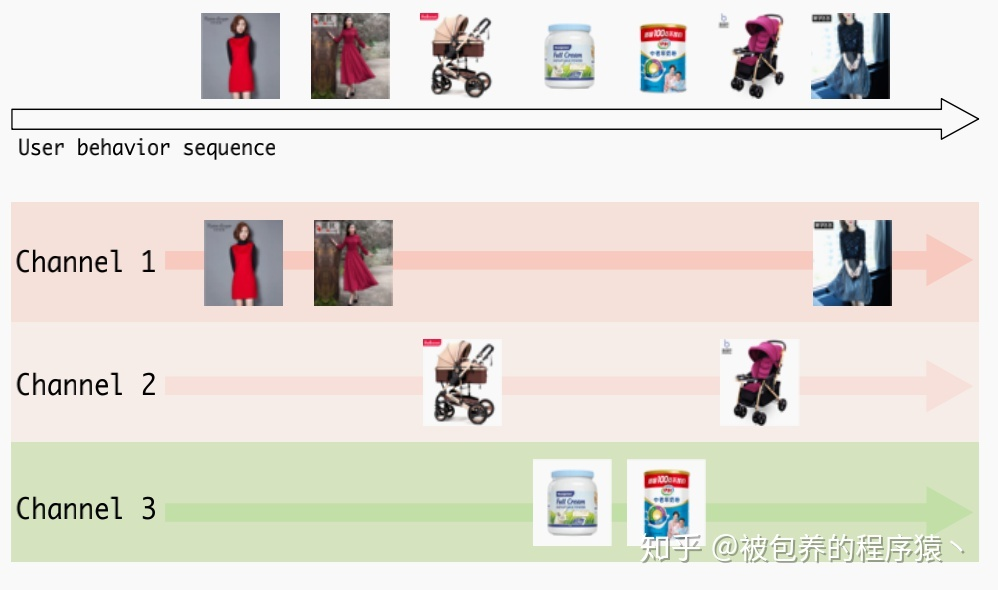 用户interest channel
用户interest channel
也就是说NTM只能帮助我们有效提取并存储尽可能长的用户行为序列,但是其中蕴含的一些兴趣规律可能无法被捕捉到,所以文章提出memory induction unit来对用户高阶兴趣进行建模。在MIU中同样包含一个额外的存储单元S,其包含m个memory slot,这里认为每一个memory slot都是一个用户interest channel。在时刻t,MIU首先选择topK的interest channel,然后针对第i个选中的channel,通过下式更新St(i) 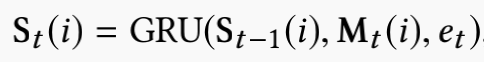
Mt(i)对应的是NTM在时刻t第I个memory slot对应的权重向量,et为用户行为embedding向量。也就是说MIU从用户原始输入行为特征和存储在NTM中的信息中提取高阶兴趣信息。值得一提的是为进一步减少参数量,不同channel的GRU参数是共享的.
(4)线上服务
上文已经给出了线上服务的整体架构,对于整个算法结构来说,在部署到线上的时候,主要的计算量都在网络的左侧部分(即用户行为兴趣建模),而右侧的Embedding+MLP的计算量则小很多。所以在线上部署的时候将左侧的网络部署到UIC server中,将右侧的网络部署到RTP server中。在对左侧用户状态进行更新的时候,最新的memory state代表着用户的兴趣,并且可以存储到TAIR中用户实时CTR预估。当有一个用户行为事件发生的时候,UIC会重新计算用户兴趣的表征(而不会将原始的用户行为进行存储)并更新到TAIR中,所以长时间行为序列占用的系统空间从6T减少到了2.7T。同时文章指出MIMN+UIC这种系统结构不是适用任何场景下的,具体需要符合如下的要求:1、可以得到丰富的用户行为数据;2、用户实时行为的数量不能超过CTR预估的请求数量
四、离线实验
文章对系统的一些超参数以及性能进行了详细的分析,同时也对线上部署给出了一些工程化的建议(UIC server和RTP server的同步问题、大数据的影响、Warm-up策略、回滚策略),具体的实验结果和相关分析可以参考原文。MIMN模型在公开数据集上的表现如下: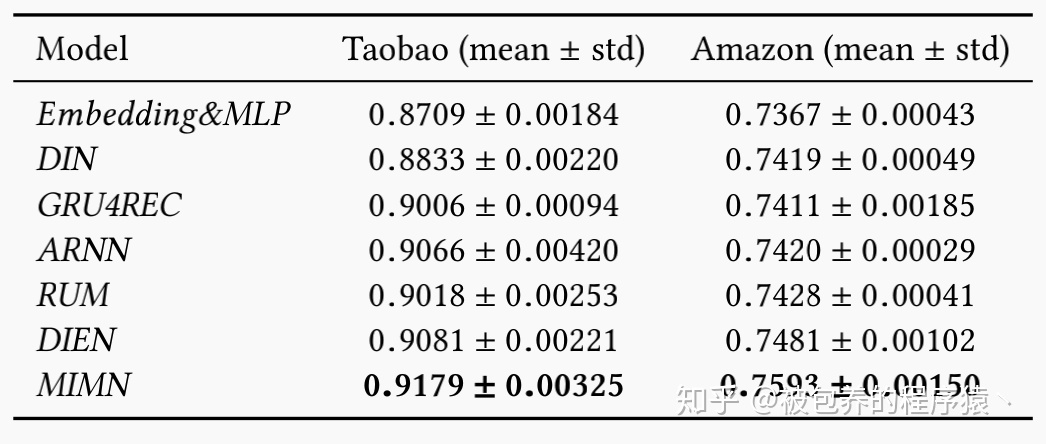 公开数据集表现
公开数据集表现
MIMN在工业数据上的表现如下:  工业数据集表现
工业数据集表现
同时文章还给出线上AB实验的效果,相较于DIEN模型,采用MIMN模型后收入增长6%,CTR提升7.5%,这可以说是非常巨大的提升,也说明UIC+MIMN这种联合设计优化方案的可行性。
五、总结
1、本文针对长时间序列的用户行为建模给出了一种联合线上-线下的设计优化方案,我觉得这是本文最大的创新点,以往当采用复杂模型导致线上耗时增加的时候,会想方法单独去优化线上的服务,本文提出的联合设计的方法给我们提供了一种全新的解决思路
2、本文提出的MIMN算法模型为了更好的适配于线上服务,借鉴了NTM的核心思想,同时也针对NTM存在的利用率不均衡的问题给出了相应的解决方案(memory utilization regularization),同时为更好的挖掘用户高阶兴趣信息,文章提出了memory induction unit来解决这一问题
总的来说,本篇文章是一篇工程性很强的算法模型论文,非常适合广告、搜索、推荐领域的从业人员来阅读,因为该篇文章不只局限于算法领域,同时也给出了线上服务的一些工程化的思考与建议,是非常优秀的一篇论文。
论文地址:
https://arxiv.org/abs/1905.09248
arxiv.org/abs/1905.09248

若有收获,就点个赞吧
0 人点赞
