作者:iwtbs
链接:https://www.zhihu.com/question/314773668/answer/2259594886
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. 前言
由于篇幅我只介绍和双塔相关的模型迭代,而诸如图、TDM、业务召回通路、强化学习、nearline等都不在本文讨论范围内,以上可以参考 iwtbs:推荐中的召回算法—总结串讲iwtbs:nearline(近线)召回在阿里妈妈的实践
下文只列出了我看过且比较有代表性的双塔相关工作,大体的优化思路主要有:
- 让user和item更有效地交互
- 让单路召回达到多路的效果
- 面向后链路的一致性建模
-
2. 让user和item更有效地交互
iwtbs:双塔召回模型的前世今生(上篇)阐述了双塔模型牺牲了精读得到了速度,最直观的缺陷是:
特征受限,无法使用交叉特征
- 模型结构受限,user 和 item 分开构建,最后只通过一次内积来交互,不利于 user-item 交互的学习
因此双塔第一个优化的中心思想是:保留更多的信息在单塔输出向量中,从而有机会和让user和item进行充分交叉
2.1 特征重要性筛选-SENet
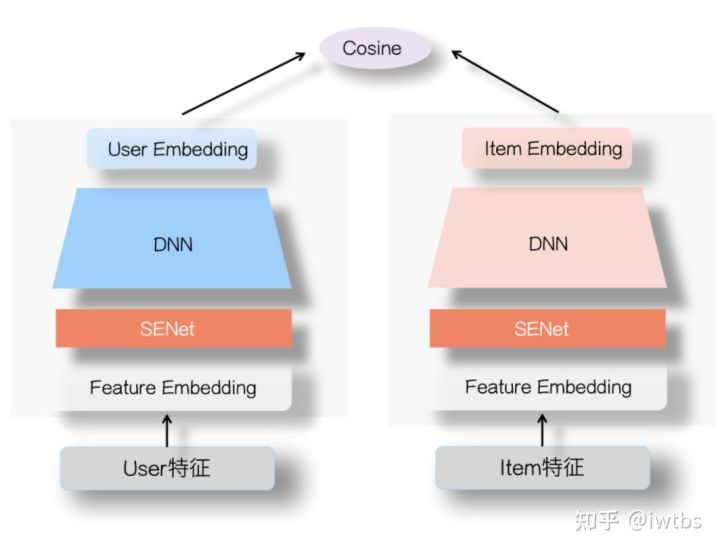
以张俊林大佬的SENet为代表张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它,user塔和Item侧塔的特征Embedding层上,各自加入一个SENet模块,通过SENet网络,动态地学习这些特征的重要性,对于每个特征学会一个特征权重,然后再把学习到的权重乘到对应特征的Embedding里,这样就可以动态学习特征权重,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的。
张俊林老师对于senet有效果的解释是:senet集成了FM和DNN双塔各自的优点,在User侧和Item侧特征之间的交互表达方面增强了DNN双塔的能力。它可以凸显那些对高层User Embedding和Item Embedding的特征交叉起重要作用的特征,更有利于表达两侧的特征交互,避免单侧无效特征经过DNN双塔非线性融合时带来的噪声,同时,它又带有非线性的作用。
我的评价:这种特征重要度学习的思路在阿里COLD和百度的GemNN都有提到,比起强化了最后的u-i交互,某种程度上我觉得和LHUC和PPnet的设计目的更相似,即不同特征组合下就理应有不同的特征重要度,甚至如果觉得senet解释性or效果不够理想,可以基于业务理解直接设计出显式gate+特征组合结构。
2.2 底层表征走捷径-ResNet
原来双塔DNN部分改成了一个类似Resnet那样skip connection的结构,也就是信号分成两路,一路还是经过两个relu层,另一路直接接到第二层relu,形成类似残差网络的结构。这样做的好处是,可以把低层级的特征送到最上层进行u-i交叉。类似的结构在精排可以参考:机器如何“猜你喜欢”?深度学习模型在1688的应用实践
我的评价:该模型有一个根本的问题是带来了参数膨胀。最终我们要将最上层emd进行存储和离线构图,存储和内存压力会增大很多;同时该模型又多了很多要调整的超参数。
2.3 显式根据特征调整深度
在《Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook》中,作者不再是一股脑把所有特征concat过MLP,而是部分特征先过A结构,再在显式高维emd基础上进行融合。
如下图所示query侧的输入特征有多个通道,包括query本身的3-gram,国家和原始文本。doc侧的输入特征包括了title,description,title的3-gram,description的3-gram和图像的向量。二者通过attention做融合后分别得到query向量和doc向量,再进行点乘得到预测值。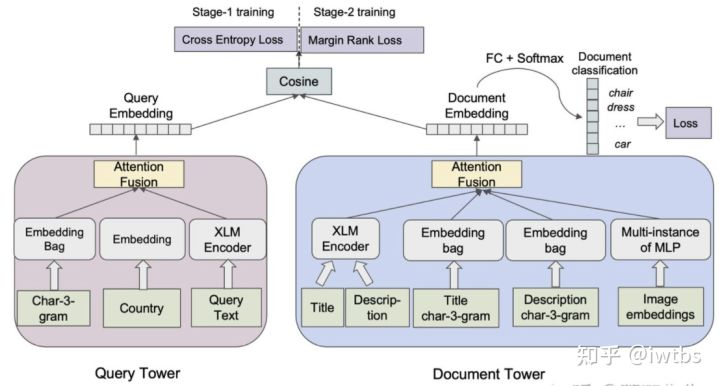
我的评价:优势在于让某些内聚特征一起学,显式调整了不同特征的学习难度,加强了不同filed特征在最后u-i交叉的重要性。除了交互外,facebook这篇文章也介绍了两阶段训练框架+多任务学习,建议阅读原文。
2.4 美团对偶增强双塔
今年美团的一篇文章《A Dual Augmented Two-tower Model for Online Large-scale Recommendation》,设计了Adaptive-Mimic Mechanism,其中最主要的是设计了mimic loss,该loss的主要作用是让增强向量来拟合相应query或着item在另一个塔中所有正样本的输出向量表示,增强向量代表了来自另一个塔的有用信息,在训练增强向量的过程中需要使用stop gradient策略来冻结梯度。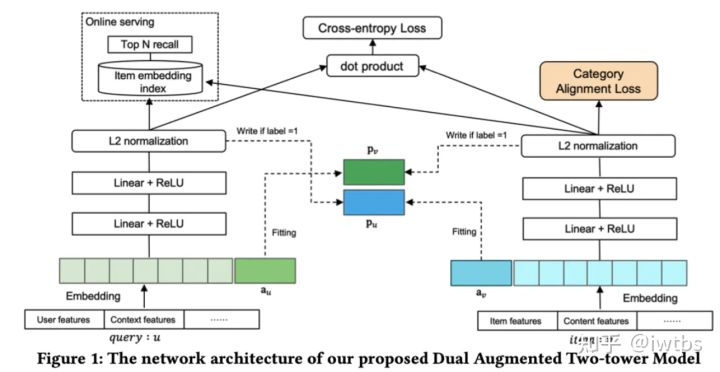
我的评价:从论文介绍来看增强向量更多地是表征用户的历史点击序列/物品的历史点击用户,那么是否可以将这两个序列特征进行简单池化or聚类就有不错的效果,即结构的收益也许可以通过特征来近似拿到。且论文一共有4个loss,直观感觉训练难度会比较大,但是不妨碍这篇论文结构上是比较创新的。
3. 让单路召回达到多路的效果
如果说第2章是让双塔更“深”,那么第3节则是让双塔更“宽”,甚至一个模型能够达到多路召回的效果。
3.1 按兴趣域拆分-多兴趣
召回阶段有时候容易碰到头部问题,就比如通过用户兴趣embedding拉回来的物料,可能集中在头部优势领域中,造成弱势兴趣不太能体现出来的问题。而如果把用户兴趣进行拆分,每个兴趣embedding各自拉回部分相关的物料,则可以很大程度缓解召回的头部问题,同时用单路达到多路的效果。
其中最知名的一篇多兴趣召回模型是《Multi-Interest Network with Dynamic Routing》,MIND通过引入 capsule network 的思想来解决输出多个向量 embedding 的问题,Multi-Interest 抽取层负责建模用户多个兴趣向量 embedding,然后通过 Label-aware Attention 结构对多个兴趣向量加权,这是因为多个兴趣embedding 和待推荐的 item 的相关性肯有差异。线上 serving时,用户的每个兴趣向量embedding依次通过 KNN 检索得到最相似的 Top-N 候选商品集合。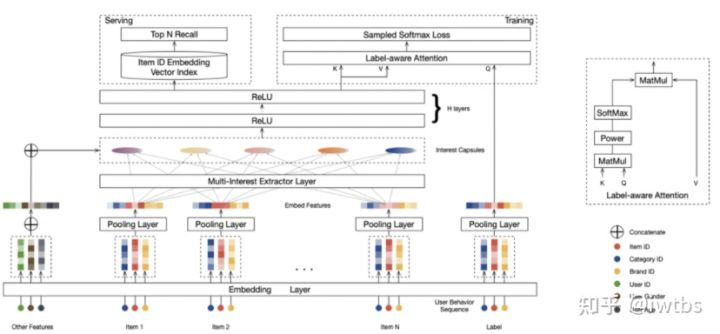
我的评价:多兴趣确实是一个能拿收益的方向,据说MIND已经成为了手淘召回占比最高的触发通路,除了MIND外,还有一些论文也是多兴趣建模:
- 《Controllable Multi-Interest Framework for Recommendation》- ComiRec模型 2020 KDD 阿里
- 《Octopus: Comprehensive and Elastic User Representation for the Generation of Recommendation Candidates》- Octopus模型 2020 SIGIR MSRA
- 《Sparse-Interest Network for Sequential Recommendation》- SINE模型 2021 WSDM 阿里
3.2 按时间跨度拆分-长短期兴趣
历史行为序列通常可以反映用户短期的兴趣,而长期兴趣则可能随着模型的学习逐渐忘却。在精排阶段我们可以通过超长行为序列建模如SIM建模用户的长期兴趣,而对于时延敏感的召回而言超长行为序列是无法使用的。通过同时建模用户短、长期兴趣,用单路召回达到多路的效果。
在《SDM: Sequential Deep Matching Model for Online Large-scale Recommender System》中,作者将最近一个session定义为短期行为,利用LSTM+多头自注意力层+用户注意力层捕捉短期兴趣序列;发生在最近一个session前7天内的session定义为长期行为,通过用户注意力层+DNN得到用户长期兴趣。最终利用fusion gate来控制长短期的影响。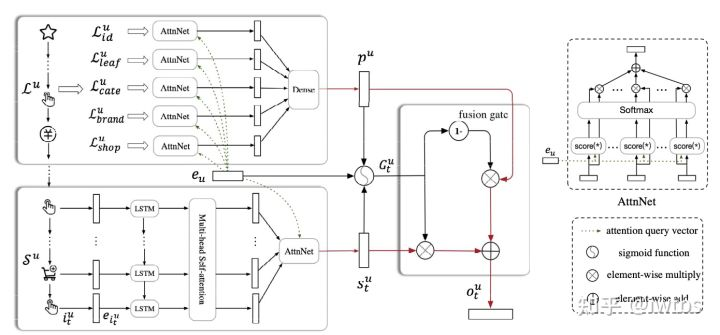
我的评价:实时、短期、长期兴趣建模也是一个被验证能拿收益的方向,具体实操时要结合特征、优化器、模型结构一起迭代,同时也可以结合灾难性遗忘做些优化。除了SDM外,与长短期兴趣相关的召回模型还有《Embedding-based Product Retrieval in Taobao Search》和《Next Item Recommendation with Self-Attention》3.3 PDN
一般来说I2I和U2I分别是两路召回,I2I对共现少的pair难以泛化,缺乏准确和个性化;U2I无法建模用户每一个行为和打分item之间的关系,召回结果缺乏多样性。《Path-based Deep Network for candidate item matching in recommender》做了联合建模,采用一个TriggerNet建模用户对每一个交互过商品的喜爱程度,采用Similarity Net建模交互商品与目标商品的相似度,利用两次相似度关系传播同时近似表征了U2I和I2I的信息。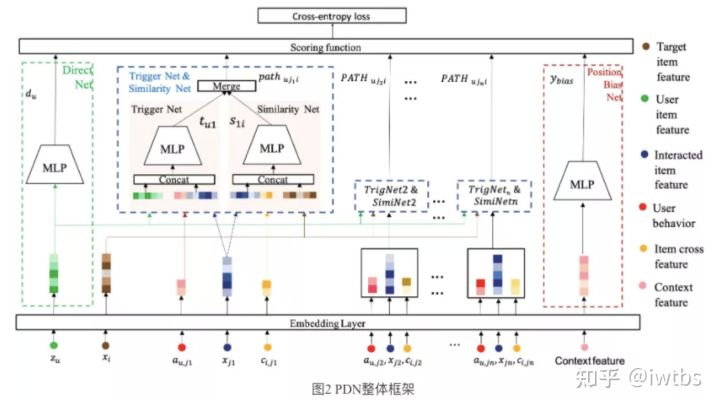
我的评价:严格来说这并不是双塔结构,不过我觉得整体思路嵌入着向量化的思想,同时这种不同触发方式融合建模也是比较有借鉴意义的。不过原文只将PDN对比了纯U2I和I2I证明有收益,其实应该加一组PDN对比U2I+I2I,看联合建模是否能给系统带来增量。3.4 特征组合大乱炖-并联双塔
上面介绍了物理意义的单路拆多路,当然也会有同一目标单模型拆多模型,比如腾讯的“并联”双塔,尝试通过"并联"多个双塔结构(MLP、DCN、FM、FFM、CIN)暴力出奇迹;并引入 LR 进行带权融合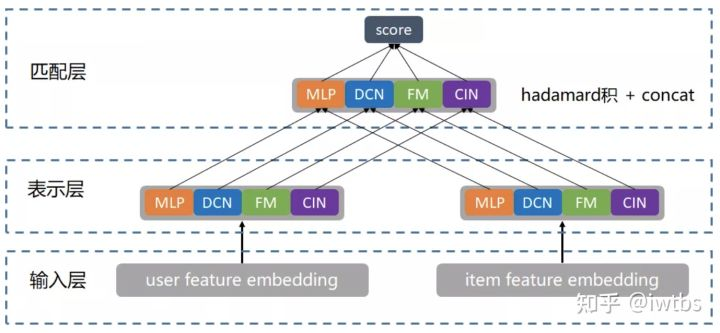
我的评价:整体价值不大。第一,该模型单纯是增加参数换一些精度,能否打平线上serving机器资源的增加也是未知数;2.原文对比效果的时候甚至都没有打平参数量对比,而原有模型可能增加emd维度本身就能带来auc提升;3.既然不共享底层embedding,直接训四个召回效果是不是也差不多,而且这个LR就等价于调召回weight,难调又不好解释收益来源。不过也确实算是单路拆多路,所以放在这个专题下。4. 面向后链路的一致性建模
以视频推荐场景为例,一般排序模型会综合多种目标进行综合打分,比如a ctr+b staytime + c 点赞 + d 转发 + e * 关注…,如果我们只搞ctr、staytime、点赞等召回,就造成了召回和排序目标不一致(比如只用竞赛选拔人才,那高考状元也进不了清北),显然不利于全链路的优化。4.1 样本变换
可以基于各种目标进行样本加权,比如同样是点击样本,时长较长、点赞较多的给更大的权重,方法简单直观可解释性强,缺点就是又又又一大堆超参数要调。4.2 蒸馏
腾讯《Distillation based Multi-task Learning: A Candidate Generation Model for Improving Reading Duration》论文中也提到了如何在召回中同时将点击和时长融合。模型结构和常规的蒸馏一致(不了解的可以看iwtbs:蒸馏技术在推荐模型中的应用),用一个多任务精排模型学习ctr和staytime,并将ctr*staytime蒸馏到双塔网络中。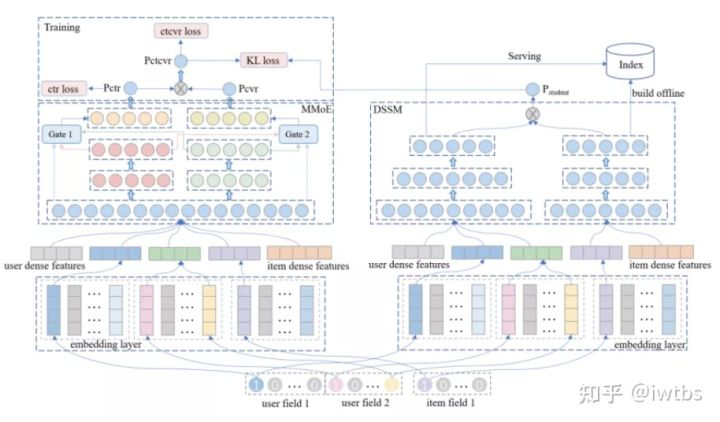
我的评价:蒸馏肯定是一种多目标召回的范式,但是本文很多细节包括实验我个人觉得有待改进。1.精排和召回空间是不一致的,直接真实样本训肯定有问题 2.虽然原文说是想建模时长,但最终卡了时长>50s转换为了二分类,其实损失了很多时长信息,比如50s和500s样本权重理应不一样,时长60s的视频和600s的视频看50s也应不一样,没做消偏 3.实验结果中,拿多目标召回和单目标召回比auc + 和ctr召回比avg staytime不是很公平,而且业界也不会直接拿原始staytime做mse loss的。综上,本文虽然思路是对的也可以借鉴,但是细节自己落地还是要深挖。4.3 人工构造样本
以百度的《MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search》为例。传统多层的漏斗,首先召回时保证一定的相关性,然后通过rank层预估ctr,ctr较高的内容最终得以展现依然是召回排序目标不一致,导致match层召回的很多广告cpm不高,不会被展现,从而影响商业收入。mobius的思路是把召回层和rank层融合,兼顾相关性和商业指标。具体思路是人工构造出低相关性且高ctr的bad case样本,再通过在模型的目标函数中加上bad case率这个目标来进行学习。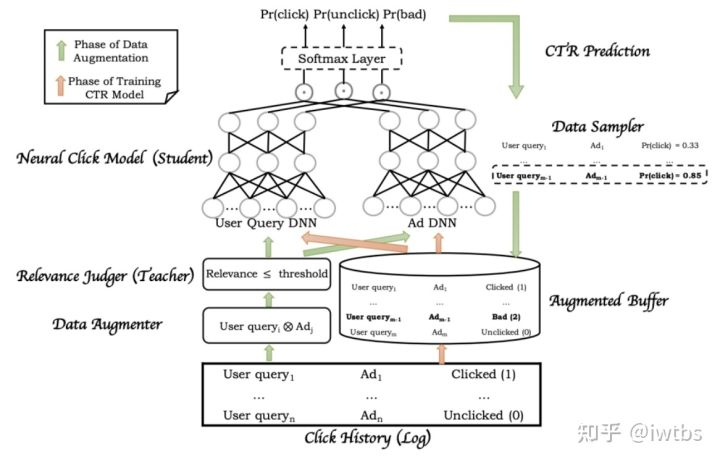
我的评价:只要我们理解“模型的目标是拟合数据的分布”,就能明白fake instance为什么能起到作用。本文的模型工程侧也需要做一些配合,同时因为召回引入了bid信息,后面线上也需要关注生态相关的指标。4.4 学习后链路的序
在信息流推荐里由于目标众多,很难用上述几个方法把一大堆目标融合在一起,所以往往会采用拟合序的方式。这里以萧瑟:阿里广告技术最新突破:全链路联动-面向最终目标的全链路一致性建模 的LDM模型为例。引入同一次请求内精排阶段的参竞日志,在构造样本pair的时候把展现样本做为正样本,参竞未展现样本作为负样本,让模型学习将展现集合排在最前面,通过交叉熵loss进行学习。为了解决SSB问题,引入了随机负采样loss,以展现作为正样本,batch内随机采的作为负样本,同样额外构建了另外一个双塔网络,和原双塔网络前几层参数共享,新网络以交叉熵loss的方式进行学习。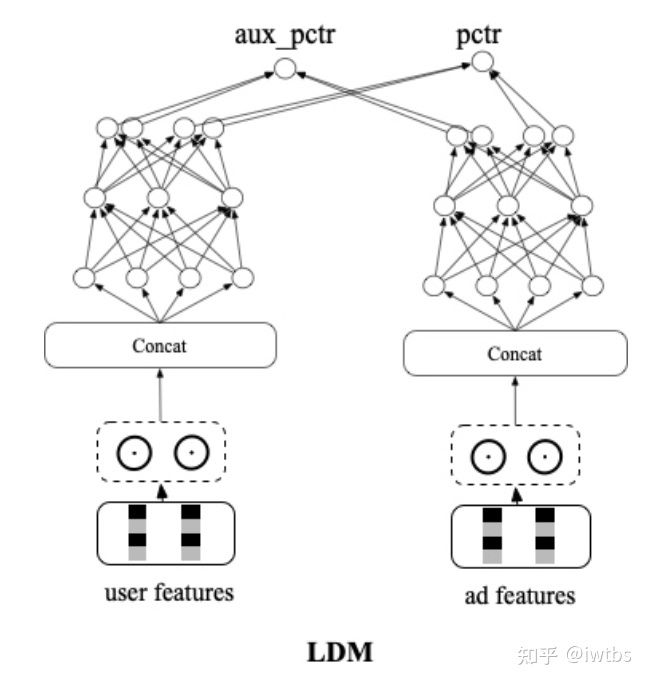
我的评价:原文对于设计思路讲的蛮清楚的,这种学序的方式也已经成为了一种范式,至于SSB问题、pairwise等可以在自己业务尝试看看是否有效。5. 其他
除了以上大框架的优化外,我们要牢记召回是一个非常吃业务+细节的环节,这里介绍三篇我自己比较喜欢的浓浓工业风的论文,其中很多细节都是实践出来的经验,强烈建议通篇阅读5.1 对比学习优化长尾分发
谷歌的这篇《Self-supervised Learning for Large-scale Item Recommendations》很经典地利用对比学习辅助训练双塔召回模型,从而让冷门、小众item也能够学好embedding表征。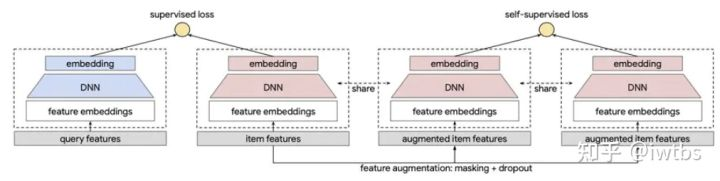
5.2 流式纠偏与softamx
Youtube的《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》使用batch softmax进行双塔的训练,并且针对batch内采样的热度问题提出了频率预估的采样纠偏方案,论文整体又不少细节,可以参考我之前的一篇文章 iwtbs:借Youtube论文,谈谈双塔模型的八大精髓问题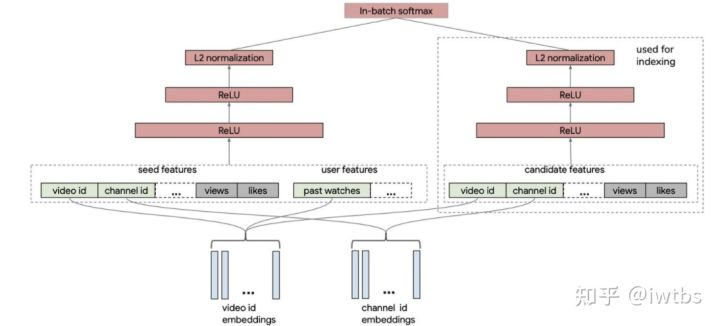
5.3 样本+特征+模型+全链路的实战经验
EBR是很经典的一篇工业界论文,是facebook发表在KDD2020上的一篇关于搜索召回的paper,可贵之处在于全面,包括了特征、样本、模型、全链路等各种细节知识,一些关键但容易忽视的点可以参考我之前的一篇文章 iwtbs:《Embedding-based Retrieval in Facebook Search》论文精读
编辑于 2021-12-07 04:49

若有收获,就点个赞吧
0 人点赞
