
今天为大家带来一篇pinterest 公司发表于KDD2020的 PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest 。文章主要情景是在Item Embedding已知的情况下,对User Embedding生成方式进行了探索。
注:Pinterest是一家国外月活3.5亿的内容发现平台,采用瀑布流形式展现图片内容。类似于instagram。
本文提出了一个名为PinnerSage的端到端系统,该系统部署在Pinterest的生产环境中,是一个高度可扩展、灵活和可扩展的推荐系统,在内部用多个PinSage(利用卷积生成item 的Emb)来代表每个用户。通过用户的分层聚类推断出多个Embedding,并通过MEDOID方法得到最终的User Embedding。并通过离线和在线实验广泛评估以及大规模A/B测试表明基于PinnerSage的推荐可以的有效性。
1.背景介绍
从数十亿的候选Item Embedding中构建一个有效的User Embedding,是十分有挑战性的。最为关键的是:如何表达用户多个方面的兴趣。一个用户可以拥有多个兴趣,且兴趣之间没有明显的联系,并且随着时间流逝,用户的兴趣也在不停的演化,有些可能是长期演化的结果,有些则是会在短时间内变化。
在推荐领域,将用户表示为一个高维度embedding,以此来捕捉用户行为和兴趣的丰富性。这个idea是非常work的,但是需要注意的是,一个有效的embedding是要包含用户的多兴趣信息的。但是用户每个交互的item却只能表达用户兴趣的一部分,如何从item Embeding中得到有效的User Embedding。所以引入了Attention Layer或者其他可以track用户兴趣的方法。
其中一个方法[1]是生成多个Embedding(一下用Emb代替)表示一个user,每个Emb表示user一个特定兴趣。该方法在youtube上测试可以提升25%。但是这引发了几个问题:
- 每个用户需要多少个Emb?
- 如何为大规模user进行推理并更新?
- 如何选择Emb来生成个性化?
- 生产环境中的多Emb是否在计算增加的同时带来显著收益?
以前的大多数多Emb工作都是通过只运行在小规模实验而不在生产中部署这些技术,或者通过将用户限制数量较少的Emb,所以在实用性上效果存疑。
2.方案归纳
现阶段有几种成熟设计,文章中进行总结,并针对这些设计进行优化。
2.1 设计1: 商品Emb固定(Pin Embeddings are Fixed)
同时训练itemEmb和userEmb。这种方案的是比较常用的。但是也会出现固有问题。例如:使模型复杂化,减慢推计算,给实时性带来挑战。除此之外,这种方案会导致完全不同类的itemEmb距离很近。为了避免这种问题,文章中说明可以采用pinterest 公司的PinSAGE模型来生成itemEmb。
2.2 设计2: 高维度Emb表示User (No Restriction on Number of Embeddings)
上一节[1]文献中提到可以用固定维度的Emb来代表user,[1]中将Emb维度固定为一个小数字,对其设置为上限。这种限制对全面理解user也会一种限制。导致推介结果效果并不好。
本文作者认为可能会出现多个商品Emb混合mean pooling结果会有问题。如下图所示,user三个想去分别是绘画、鞋子、科技感。但是经过pooling后得到的UserEmb却与商品 能量早餐的Emb特别接近。这实际上是有明显问题的。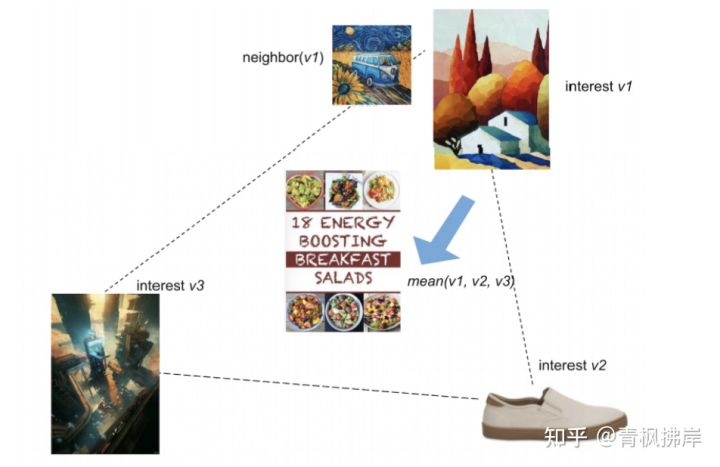
文章针对于这个问题,提出允许用户通过其底层数据支持的尽可能多数量的Embedding来表示。使用层次聚集聚类算法(Ward)对用户行为进行聚类。轻用户可能由3-5个簇表示,而重用户可能由75-100个簇表示。
2.3 设计3: 基于medoid簇的表示(Medoids based Representation of Clusters)
什么是Medoids?和kmeans一样是一种聚类方法,只不过Kmeans是计算每个簇的平均值,导致平均值会受到异常值的影响较大。kMedoids则不是取平均值,质心必须是簇内的点,计算距离也从平均值变为质心到簇内所有点的距离。kMedoids对噪声的鲁棒性较好,可以将异常样本单独成类。medoid是表示集群的一种简洁方式,因为它只需要存储i每个簇质心 Emb,还可以实现跨用户甚至跨应用程序的缓存共享。
参考:
机器学习:K-means和K-medoid聚类算法_iotflh的博客-CSDN博客
blog.csdn.net/iotflh/article/details/112133565
2.4 设计4: Medoid抽样候选检索(Medoid Sampling for Candidate Retrieval)
一个user肯定拥有多种属性类别,Medoid是比较费时的,出于成本考虑,无法使用Medoid提取到所有的簇。文中的解决方法是根据重要性分数取前3个Medoid,其中重要性分数每天更新,来适应用户不断变化的兴趣。(详细过程将在下节讲解)
2.5 设计5: 实时处理和更新(Two-pronged Approach for Handling RealTime Updates)
推荐系统要适配用户当下的需求,与此同时,也要能表示用户过去60-90天内的行为。数据的绝对大小和增长速度让我们很难同时兼顾两者。对于此,本篇论文通过结合两种方法来解决这个问题:
- 每日批处理推理操作,根据每个用户的长期交互历史推断出多个Medoid
- 同一模型的Online版本,根据用户当天的交互推断Medoid
随着新行为的加入,只更新Online版本。在一天结束后,批处理将使用当天的用户行为以解决Medoid不一致问题。这种方法确保系统能够快速适应用户当前的需求,同时不会损害用户的长期兴趣。
2.5 设计6: ANN系统(Approximate Nearest Neighbor System)
为了生成基于Emb的推荐,我们采用了近似最近邻(ANN)系统。给定一个query(medoid),ANN系统在Emb空间中获取与查询最接近的k个项。我们展示了如何对ANN系统进行一些改进,例如过滤低质量的项目,仔细选择不同的索引技术,缓存MEDOID:最终生产版本的速度是原始原型的1/10。
3.PinnerSage方法详解
集合 ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图3](/uploads/projects/lianghan@zengzhang/4682cb677708c7412ed87b399972a5c7.svg) 代表所有的item(文中叫做pin)。候选item大概有十亿量级。
代表所有的item(文中叫做pin)。候选item大概有十亿量级。 ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图4](/uploads/projects/lianghan@zengzhang/473cf5412d4d9c20a16a5a42e77886e3.svg) 代表了item Emb共d维,中的第i个维度值。
代表了item Emb共d维,中的第i个维度值。![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图5](/uploads/projects/lianghan@zengzhang/53ea2c7bb610854adef02a60ab230a91.svg) 代表用户u点击item 行为序列(按时间顺序排列),且
代表用户u点击item 行为序列(按时间顺序排列),且 ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图6](/uploads/projects/lianghan@zengzhang/7a9b44d71741fa892594038d05a8bf58.svg) 中a不重复。
中a不重复。![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图7](/uploads/projects/lianghan@zengzhang/b248180903a2ab59b74973f42e8b4845.svg) 代表用户u与
代表用户u与![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图8](/uploads/projects/lianghan@zengzhang/ee201738f8727c0dd84fd4d8bf0e3407.svg) 的互动时间。
的互动时间。
item Emb文章中指出是由Pinterest 公司的另一篇文章中的PinSage模型生成的固定维度的Emb。
文章指出每个user的Emb是不同的,因为不同用户的兴趣多样性是不一致的。但是满足userEmb数量<<交互过itemEmb数量。
通过用户的历史交互item行为,预测下一个交互的item ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图9](/uploads/projects/lianghan@zengzhang/a13f74c5b23c8ac601bd23fe36c75b93.svg) 。即判断userEmb和itemEmb的余弦相似度>0.8。如何得到userEmb,这里进行了4个小实验:
。即判断userEmb和itemEmb的余弦相似度>0.8。如何得到userEmb,这里进行了4个小实验:
- 1.最后一个itemEmb代表userEmb
- 2.衰减平均值:用户表示是其itemEmb的时间衰减平均值。具体来说,衰减平均公式为:
![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图10](/uploads/projects/lianghan@zengzhang/f640d0877b6253ed9030ab6dcbac311b.svg)
- 3.Oracle: Oracle can “look into the future” and pick as the user representation the past action items of the user that is closest to ai+1. This measures the upper bound on accuracy of a method that would predict future engagements based on past engagements. 选择最接近ai+1的用户过去的操作项作为用户表示。这衡量了一种方法的准确性上限。(不太明白如何实现,文中也没有详细解释)
- Kmeans Oracle: User is represented via k-means clustering (k = 3) over their past action pins. Again, the Oracle gets to see item ai+1 and picks as the user representation the cluster centroid closest to it.(同上)
结果展示: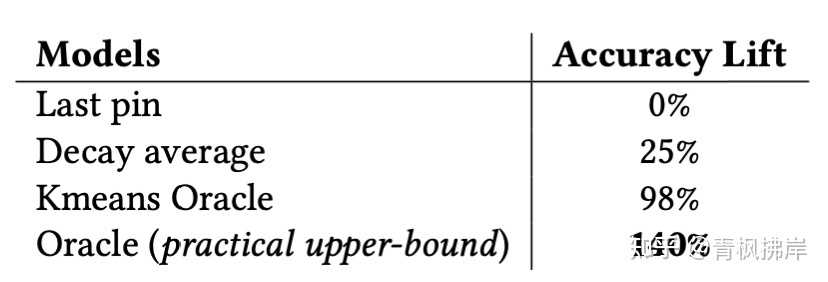
上述实验说明对每个user生成单一Emb的效果的确不好,所以引入PinnerSage。
PinnerSage
由于单Emb的不合理,文中认为基于聚类的方法可以在准确性和存储需求之间进行合理的权衡。从而得得到本文的核心:PinnerSage
共分为三个部分:
1)获取过去90天的用户交互过的item,并将其分为少量集群
2)为每个簇计算基于medoid的表示
3)计算每个集群对用户的重要性得分 Importance score
下面详细算法详细步骤:
3.1 Step 1: 用户交互行为聚类 Cluster User Actions
我们对聚类方法的选择提出了两个主要限制
- 集群应该只包含概念上相似的item(也就是cluster中的item要相似)
- 它应该根据不同用户自动确定集群的数量,以满足用户不同数量的兴趣
Ward[2]满足上述两个约束,这是一种基于最小方差标准(满足约束1)的分层聚集聚类方法。此外,根据距离自动确定簇的数量(满足约束2)。在我们的实验(第5节)中,它的表现优于K-均值和完全链接方法[3]。其他一些基准测试也证明了Ward优于其他聚类方法。
什么是Ward?
Ward是一种层次聚类算法[2],聚类的距离衡量指标为error sum of squares(ESS),公式为: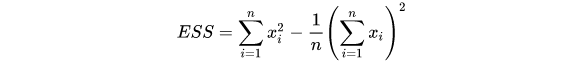
这个看起来是不是比较眼熟,我们再看一下方差公式: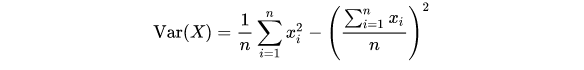
ESS其实就是方差乘以n,也可以理解成最小方差准则(based on a minimum variance criteria)。
Ward聚类过程为:
- 每个点初始化为一个类簇。此时,每个群集中的ESS为0
- 计算每个cluster的ESS
- 计算总的ESS
- 枚举所有二项cluster【N个cluster是N*(N-1)/2个二项集】,计算合并这两个cluster后的总ESS值
- 选择总ESS值增长最小的那两个cluster合并
- 重复以上过程直到N减少到1

图片来源:[4]https://zhuanlan.zhihu.com/p/402068965
- ESS(合并前) = ESS(红) + ESS(蓝) +ESS(其他)
- ESS(合并后) = ESS(红&蓝) +ESS(其他)
但是Ward聚类的常规方法是非常耗时的,每一次合并两个类簇,就要计算任意两个类簇间的ESS。一次的复杂度 ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图15](/uploads/projects/lianghan@zengzhang/e51c93a2250cd4191c8b4544aa549387.svg) ,如果数据过多,这种方法是完全不适用。
,如果数据过多,这种方法是完全不适用。
论文中也指出,并非采用常规的计算Ward聚类方法,而是使用一种快速计算方法叫Lance-Williams Algorithm[5]。具体可以参考:
https://www.cnblogs.com/sddai/p/7662780.html
www.cnblogs.com/sddai/p/7662780.html
例:
假设共5个点,初始化为5个簇:{A B C D E},计算五个簇互相之间的ESS,这步无法简化。
通过计算发现,A、B两个簇ESS最近,则被合并为AB,现在存在4个簇:{AB、C、D、E}。
正常情况下:分别计算:4个簇相互间的ESS。
Lance-Williams Algorithm:![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图16](/uploads/projects/lianghan@zengzhang/82a37170ced61d88a0c722f510911640.svg)
这里 ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图17](/uploads/projects/lianghan@zengzhang/dad6b4c146f9bea2afd2fd5edaac5cac.svg) 代表除AB簇外其他的簇,
代表除AB簇外其他的簇, ![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图18](/uploads/projects/lianghan@zengzhang/7b30a6bd746ee65c9bf2b5a9c7537a14.svg) 代表A、B、K簇中节点数量,由于初始每个节点为1簇,故n=1。
代表A、B、K簇中节点数量,由于初始每个节点为1簇,故n=1。
可以看出,Lance-Williams Algorithm大大的减少了计算量,也是PinnerSage能快速迭代的前提。
总结:PinnerSage将每个用户交互过的item作为节点,进行Ward聚类。
3.2 Step 2: Medoid聚类表示 Medoid based Cluster Representation
典型的方法是考虑聚类质心、时间衰减平均模型或更复杂的序列模型,如LSTM、GRU等。然而,这些方法都有一个问题是,由它们得到的embedding可能位于d维空间(Emb的维度)的不同的区域。假设有一些离群异常点分配给类簇,这些方法可能会出现问题,将导致较大的内部集群方差。这种Emb将导致检索不相关的候选推荐,例如在第2节图中提到的问题。
所以文章使用Medoid方法,找到每个类簇中所有item中的一个来代表本类簇。该item满足与同簇内其他成员的平方距离之和最小。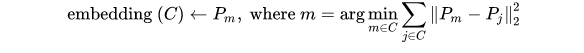
利用itemEmb代表类簇,则可以通过键值对来进行存储。
总结: 对每个类簇,使用簇内item Emb 代表该类簇。
3.3 Step 3: 聚类重要性 Cluster Importance
即使用户的类簇数量很小,仍达到几十到几百。考虑效率和成本,不能使用所有的簇Emb来ANN查询。因此,必须确定类簇对用户的相对重要性,以便我们可以根据其重要性得分对类簇进行采样。考虑到时间衰减平均模式: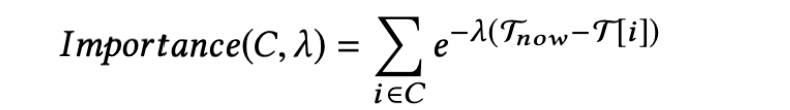
其中![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图21](/uploads/projects/lianghan@zengzhang/48aef140c42211c43e4ed0cdc36ccdcd.svg) 是user与item i互动的时间,C是其中的一个类簇。当user与这个类簇互动越频繁(frequently)以及互动时间越近(recently),类簇重要性就会越高。
是user与item i互动的时间,C是其中的一个类簇。当user与这个类簇互动越频繁(frequently)以及互动时间越近(recently),类簇重要性就会越高。![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图22](/uploads/projects/lianghan@zengzhang/52367f641e33200585537f3ee633a411.svg) 为超参数:
为超参数:
- 当
![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图23](/uploads/projects/lianghan@zengzhang/05c0d1c1127d7ce0081035d3c8b34a31.svg) 的时候,更注重user与这个cluster的互动频率(分数变成类簇内数量item加和)
的时候,更注重user与这个cluster的互动频率(分数变成类簇内数量item加和) - 当
![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图24](/uploads/projects/lianghan@zengzhang/3630a5e27afd0d3f7f453aff8cde8d77.svg) 的时候,更注重用户最近的兴趣(recent interests)影响
的时候,更注重用户最近的兴趣(recent interests)影响
作者通过实验发现,![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图25](/uploads/projects/lianghan@zengzhang/8736c5a5b0a761b7e162e30a2162be20.svg) 可以平衡两者,效果最好。
可以平衡两者,效果最好。
根据第二节设计4提出的,采样重要性前3的类簇Emb。Importance每天进行计算,以此来更新用户兴趣。
总结:利用重要性分数最终生成userEmb。
PinnerSage模型为每个用户独立运行,因此可以在基于MapReduce的框架上高效地并行实现。并且也维护了PinnerSage的在线版本,该版本在用户的最新活动上运行。批处理版本和在线版本的输出组合在一起,用于生成建议。
4.模型应用
得到了3类簇Emb组成的UserEmb后,再拿每类的embedding去检索Faiss,即ANN检索。再融合结果返回。避免了pooling后”只用单一向量表示用户兴趣”而带来的信息损失。
在线服务
PinnerSage的主要目标是根据用户过去历史行为向用户推荐相关内容。同时,我们希望提供与用户实时行为相关的建议。实现这一点的一种方法是将所有用户数据提供给PinnerSage,并在用户有交互行为后立即运行它。然而,由于成本和时延,这实际上是不可行的,所以我们考虑双管齐下的方法:
- 每日batch处理推断:每天在MapReduce集群上运行PinnerSage对用户的最后90天行为建模。将输出(medoid列表及其重要性)以键值存储以供在线服务获取
- 轻量级Online推断:收集每个用户最近一天(上次更新键值存储后)的最近20个行为,在线使用PinnerSage构建基于实时事件的流式服务来计算,并从键值存储中更新类簇Emb
5.实验
对PinnerSage进行了评估,并对其性能进行了实证验证。我们首先对PinnerSage进行定性评估,然后进行A/B实验,然后进行广泛的离线评估。离线召回实验
数据集
作者对千万用户进行了抽样调查,并收集了他们过去90天的活动。d日前的所有活动都被标记为训练,从d开始用于测试。
Baseline
LSTM、 GRU 、HierTCN 、PinnerSage(λ =(0, 0.01, 0.1, 0.25))
Loss
L2、hinge、log-loss
Negative Sample
random负采样,popular负采样,hard负采样
评价方法
模型输出userEmb将根据该用户的未来操作进行评估。测试批次按时间顺序进行处理,第一天为d,第二天为d+1,依此类推。一旦完成对测试批次的评估,该批次将用于更新模型;模仿每日批量更新策略。
实验一:候选检索
userEmb 是从一个非常大的候选池(数十亿items)中检索相关候选项以供推荐。候选检索集的生成如下:假设一个模型为一个用户输出e个Emb,然后每个Emb项检索![21.12.18 [论文精读]10—PinnerSage:User Embedding的生成奥义 - 图26](/uploads/projects/lianghan@zengzhang/0a6079b5a293fc4c06d32215a7b4fc8d.svg) 个最近邻项,进行合并(经过去重之后会得到少于400个候选集)。
个最近邻项,进行合并(经过去重之后会得到少于400个候选集)。
根据以下两个指标,使用测试批次中观察到的用户操作对建议集进行评估:
- Relevance (Rel.) 召回的候选集item与用户产生交互的item之间的余弦相似度大于0.8的比例。相关性越高说明召回结果越好。
- recall. 就是用户交互过item在召回候选item集里出现的比例,越大说明效果越好。
结果如下图: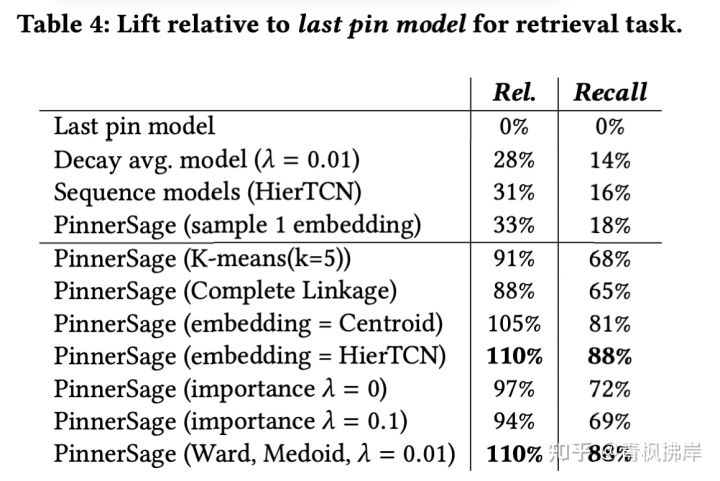
PinnerSage多Emb模型效果远超其它单Emb模型。并且PinnerSage单Emb模型也优于其他单Emb模型。
Ward效果远优于Kmeans和Complete link methods。在类簇Emb生成时,Sequence models 和 Medoid效果相当,但是Medoid易于理解,易于存储。(图中Centorid应该是一大类方法,包含Medoid)
λ=0时,聚类重要性等于聚类中的item数量(看公式很好理解),其性能比λ=0.01差(生产中选择)。
直观地说,这是有意义的,因为较高的λ值包含了簇内item数量和时序兴趣。但是,如果λ太高,那么它会过关注近期兴趣,这会损害长期兴趣,导致模型性能下降(λ=0.1 vs λ=0.01)。
实验二:候选结果排序
userEmb通常被用作模型rank中的一个特征,特别是用于对候选项进行排名。候选集是由多个浏览(impression)和行为(action)items组成的。为了确保每个测试批次的权重相等,我们为每个交互item配备20个浏览items。如果给定测试批次中的items少于20个,我们添加随机样本以保持浏览与行为item比例保证1:20。最后,根据候选items与任何用户嵌入的最大余弦相似度的降序对候选items进行排序。一个更好的嵌入模型应该能够将行为item排在浏览item之上。也可以通过以下两个指标体现:
- R-Precision (R-Prec.) 是top-k中行为item的比例,其中k是根据浏览和行为 行为数量决定。RP是排名前k的item中信噪比的度量。
- Reciprocal Rank (Rec. Rank) 是行为item的平均倒数排名。它衡量行为item在排名中高低。值越说明行为item越排在前面,效果越好。
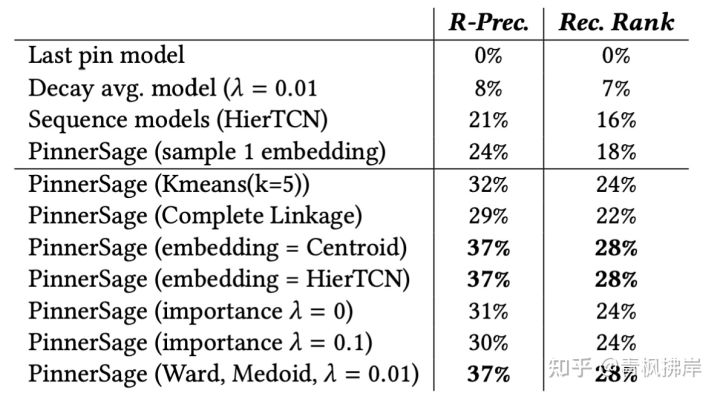
上图说明 PinnerSage效果明显好于Baseline模型。说明了有效性。PinnerSage单Emb效果也优于其他非PinnerSage模型。但是,在PinnerSage变体中,我们注意到Rank目标对Emb如何计算不太敏感,因此centroid , medoid and sequence models 具有类似的性能当Emb仅用于排序item。然而,簇类的重要性分数对结果是d额很敏感,因为λ值决定了userEmb来自哪三个簇Emb。
实验三:多样性和相关性的Tradeoff
推荐系统在相关性和多样性上经常折中。尤其是对于固定维度的单Emb模型。另一方面,多Emb模型具有同时覆盖多兴趣的灵活性。文章定义多样性为候选item集合中两两余弦相似度的均值。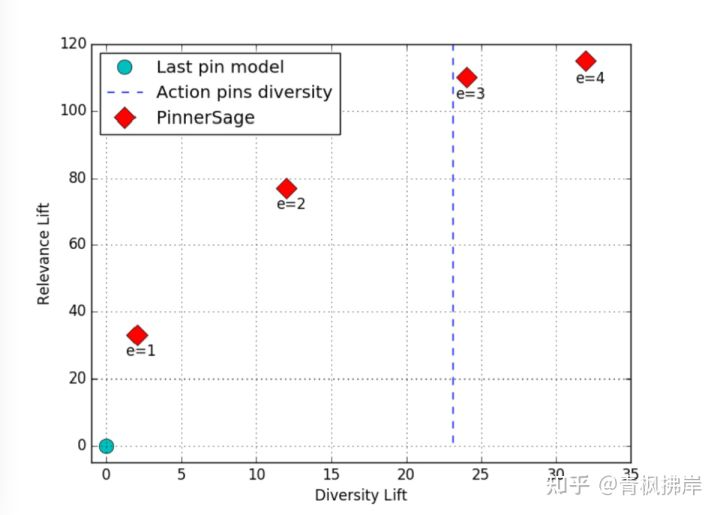
上图表明增大e(user选取类簇Emb的数量),多样性和相似性都会增大。对于e> 3来说,相关性收益逐渐减少,因为用户的活动在给定的一天(平均而言)不会有很大的变化。事实上,对于e = 3, PinnerSage实现的推荐多样性与交互行为item多样性的完美匹配,作者认为这是一个比较好的trade-off。
A/B测试
大规模A/B测试,实验组用户用PinnerSage生成userEmb,控制组用单Emb生成模型。两组数量相同。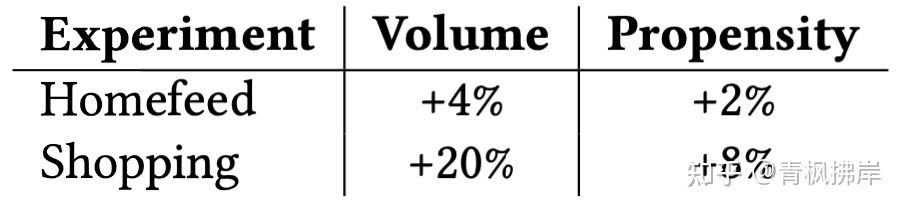
实验发现PinnerSage实验组无论是用户的参与度(全量用户复制和点击数),还是用户倾向性(人均复制和点击数)都得到提升。
6.结论
文章提出了一个名为PinnerSage的基于多Emb生成的端到端模型。利用用户历史行为item序列,利用Ward进行层次聚类。并用Medoid方法在每个类簇中使用itemEmb代表类簇的Emb,利用Importance score提取不同类簇的重要性,并取top3的类簇Emb来代表userEmb。利用ANN进行相似性检索,结果融合后生成user推荐候选item集合。
7.思考
这篇文章和我曾经精读的那篇Facebook的文章都是针对于推荐召回阶段的探索,有兴趣的小伙伴可以点击下方的链接阅读上篇。
青枫拂岸:[论文精读]02—KDD2020:Embedding-based Retrieval in Facebook Search5 赞同 · 0 评论文章
不同的是,Facebook的文章更偏向于从样本构建入手,充分的挖掘正负样本的不同特性,从而使生成Embedding更为准确,在生成方式上并无亮点;而本篇文章,则是从Embedding的生成方式上入手,更关注于用户历史行为中有过交互的item集合,从item中提取user的特征,并且PinnerSage应该看做是PinSage(itemEmb生成模型)的继续延伸。
本文中的PinnerSage模型更加关注用户的多兴趣,这也是近几年推荐领域关注的重点,并且PinnerSage模型无论是用itemEmb代表类簇Emb,还是利用keyValue存储Emb,都是在对线上推理进行优化。并且通过批处理推断和轻量实时推断更保证了模型的准确性。
本文更偏工程风一点,创新型上略显逊色,但整体质量上依旧不俗,并且已经大规模上线,对工程人员来讲值得一读。
参考文献
[1] J. Weston, R. J. Weiss, and H. Yee. Nonlinear latent factorization by embedding multiple user interests. In RecSys, pages 65–68, 2013.
[2] J. J. H. Ward. Hierarchical grouping to optimize an objective function. 1963.
[3] D. Defays. An efficient algorithm for a complete link method. The Computer Journal, 20(4):364–366, 01 1977.
[4] https://zhuanlan.zhihu.com/p/402068965
[5] G. N. Lance and W. T. Williams. A general theory of classificatory sorting strategies 1. Hierarchical systems. Computer Journal, 9(4):373–380, Feb. 1967.

若有收获,就点个赞吧
0 人点赞
