- A-1.从协同过滤CF到因子分解机模型FM
- A-2.FFM模型的原理与Python实现
- A-3.GBDT+LR模型原理解析
- A-4.阿里LS-PLM模型原理解析
- A-5.推荐模型演化路径梳理
- B-1.Embedding技术理解及在推荐场景的应用举例(附Item2Vec PySpark实现)
- B-2.Graph Embedding技术学习 | 从DeepWalk到Node2vec、EGES | 附DeepWalk PySpark实现
- B-3.主流深度推荐模型演化(上)|从Deep Crossing到Wide&Deep、DeepFM | 附模型TensorFlow代码实现
- B-4.主流深度推荐模型演化(下)|从DIN、DIEN到 MIMN、SIM | 附DIN、DIEN TensorFlow代码实现
- B-5.Youtube DNN serving目标解析 | 从odds到Logit 、Logistic Regression
- B-6.推荐系统架构浅谈
https://www.zhihu.com/people/qiu-yu-xi-xi-l/posts
A-1.从协同过滤CF到因子分解机模型FM
(附FM模型python实习)
因子分解机(FM, Factorization Machines)模型是前深度学习时代推荐领域应用最为广泛的模型之一,其凭借着较好的特征组合(表达)能力一度取代了协同过滤(CF, Collaborative Filtering)、逻辑回归(LR,Logistic Regression )的主流模型地位。在深度学习牢牢占据着主流的今天,FM模型仍旧可以为深度模型提供优化思路。
在介绍FM之前,先简要回顾一下曾经的推荐主流模型协同过滤和逻辑回归。
协同过滤
虽然现在不属于协同过滤推荐的天下,但是如果论资排辈、论影响力和应用范围,协同过滤类算法恐怕会被排为首位。可作为解释的原因有一下几点:
- 应用早;
- 可解释性强;
- 实现简便;
- 曾经是许多大型互联网公司的主推荐模型;
- 推荐思想仍不过时;
- 在某些场景下使用效果仍旧良好;
在商业应用上,协同顾过滤的使用可以追溯到1992年,Xerox公司基于其开发了一个邮件推送服务Tapestry,所以在资历上协同过滤绝对算绝对的老资格了,要知道1992年的互联网还处于萌芽期,博纳斯-李的万维网发布才一年。而在2003年,现在的电子商务巨头、彼时的电子商务先锋Amazon 便以论文Amazon.com recommendations item-to-item collaborative这一论文展示其主推荐系统基于协同过滤类算法构建。而后有着Amazon等大厂的“背书”,协同过滤在很长的一段时间中是业界的研究热点和主流。
协同过滤算法的原理
协同过滤算法基于物以类聚、人以群分的常识理念,其假设相似人群拥有相似的兴趣爱好(物品)、相似的物品可以推荐给同一类人的思想展开推荐。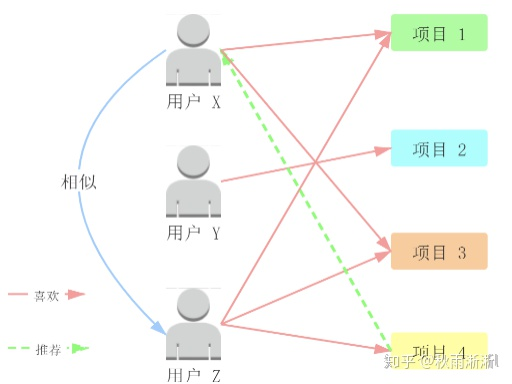
1 基于用户协同过滤推荐基本原理图
在实现步骤上也很简单直观其主要包括(以UserCF为例,ItemCF类似):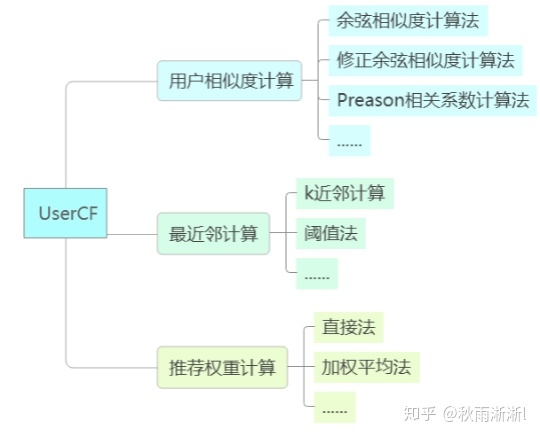
2 基于用户协同过滤推荐计算流程图
在计算上,能称得上复杂的可能只有用户相似度计算这一部分了。它需要做一个将用户评价矩阵转为了用户相似度矩阵的这样一个操作,在相似度计算上,一般也是采用这种很基础的余弦相似度类计算法。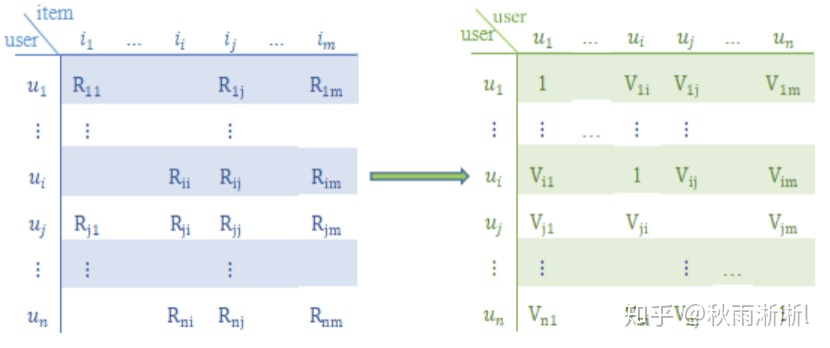
用户评分矩阵转化为用户相似度矩阵
大概给两个公式意思一下: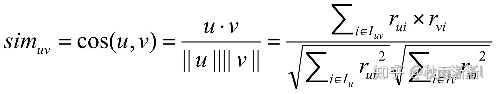
用户相似度计算-余弦定理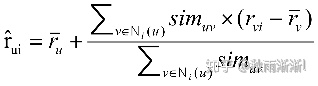
用户偏好计算
从上文的描述可以看出,协同过滤类算法的原理和实现可谓十分简便,它不需要设损失函数、梯度下降求最优解这些现在模型训练常规操作,所要求的数据也非常简约(只需要用户的对商品的评分数据),但也正是因为这些问题,协同过滤类算法存在着以下缺点:
- 表达能力不强;
只用了用户的评分数据这一特征,且不能在模型中加入其它特征(如用户年龄、性别、商品属性等)进行训练来增加模型的表达能力,这极大了限制了模型的上限。 - 较难准确的找到相似用户;
由于互联网应用的场景下,用户的历史数据相对于总商品数而言总数极度的稀疏,导致协同类算法不适用应用于获取用户评分数据较为困难的场景。 - 存在冷启动问题;
对于新用户、新商品,由于极度缺乏,很难保证推荐质量。 - 需要维护一张巨大的用户相似度矩阵/商品相似度矩阵。
逻辑回归模型
逻辑回归本质上是个分类模型,相较于协同过滤类算法利用用户和物品的相似度进行推荐,逻辑回归是将推荐问题转化为一个分类问题来解决或者说是一个点击率预估(Click Through Rate , CTR)问题。
在特征的使用上,逻辑回归可以综合用户、物品、时间上下文等多种维度的信息进行模型训练,不再局限于单一维度的评分信息,从而来增强模型的表达和泛化能力,这是其优于协同过滤类算法最显著的特点。
逻辑回归模型的其它优点如下:
- 数学上符合CTR预估物理含义;
逻辑回归与CTR预估模型的因变量都符合伯努利分布(0-1分布)。 - 强悍的可解释性;
模型训练后可直观的看出特征的推荐权重,从而解释其重要性上极为方便。 - 工程代价小;
模型简单、训练开销小、可并行化。逻辑回归的数学表达
(1)将特征向量化为 形式输入模型。
形式输入模型。
(2)赋予各特征初试权重 ,将各特征进行特征求和得到
,将各特征进行特征求和得到  。(各特征的差异性可由特征权重体现)
。(各特征的差异性可由特征权重体现)
(3)将 输入sigmoid函数得到假设函数
输入sigmoid函数得到假设函数  。
。
(4)使用梯度下降、牛顿法等方法训练模型 ,得到模型最终的特征权重即预测模型。
,得到模型最终的特征权重即预测模型。
sigmoid函数的表达式和函数走势如下图所示:
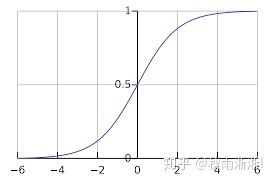
sigmoid函数曲线图逻辑回归的模型训练方法
以常用的梯度下降为例。
当逻辑回归的假设函数为 ,那么逻辑回归的模板函数的求解有一下几个步骤。
,那么逻辑回归的模板函数的求解有一下几个步骤。
- ,对于一个预测样本,其预测为正样本(类别1,点击)和负样本(类别-1,不点击)的概率如下公式所示:


- 将上式子综合起来:

- 基于极大似然估计原理,可得出逻辑回归的目标函数如下:

- 由于上式的连乘形式不利于梯度求导,一般会在给上式取log。同时一般会给目标函数乘以一个
 ,进而也将原本的求极大值为问题转化为求极小值问题,这样逻辑回归的目标函数的求解会转变为一个凸优化问题,在求解上也带来了便利。
,进而也将原本的求极大值为问题转化为求极小值问题,这样逻辑回归的目标函数的求解会转变为一个凸优化问题,在求解上也带来了便利。
- 最后对上式求偏导,进行权重参数进行更新后变可得到逻辑回归的训练模型,也即推荐预测模型。 (注:这个求导的推导过程挺长,此处不做展开,推导过程也很简单,套用下链式法则就行,这里直接给出推导结果)

逻辑函数的梯度算法看起来很舒适,同时它在计算上也很方便,这或许就是它损失函数如此设计的原因。
但是值得注意的是,它的表达上虽然和线性回归一致,但其假设函数 不同,不可一概而论。
不同,不可一概而论。
逻辑回归的局限性
逻辑回归在推荐领域的应用,解决了部分协同过滤类算法表达能力不足问题,但是站在今年的角度来看,逻辑回归被淘汰的理由如下:
- 模型表达能力仍旧不够强;无法进行特征交叉、无法直接利用特征之间的组合信息提升推荐准确性,存在信息损失问题。
- 可能会得出错误的推荐结论。由于仅用单一特征进行建模而非多维交叉特征,很容易陷入”辛普森悖论“困境。
- 无法进行良好的特征筛选;不支持在今天看来较为常规的特征选择等”高级“操作。
逻辑回归的这些局限带来的性能瓶颈,倒逼这推动着业界人士对更”高阶“算法模型的探索,因而本文最想回顾的FM推荐模型得以诞世。
POLY2模型—FM模型与逻辑规则的”中间者“
FM模型的诞生源于业界人员的这样一种尝试:在逻辑回归的基础上直接增加一个高阶特征组合项目,进而挖掘组合信息。
但一开始,这个高阶项目并不像现在使用的形式,它由单一特征之间两两组合得出,其二阶表达式如下所示:
这种特征组合的方式被称为POLY2模型。
POLY2模型的不足之处很容易看出:
- 模型训练复杂度高、训练开销大;
参数量从 上升到
上升到  ,模型复杂度与训练压力剧增。
,模型复杂度与训练压力剧增。 模型容易无法收敛;
互联网中的数据常常极度稀疏,在进行one by one 的特征组合后,数据的稀疏性会极度上升。在缺乏足够的有效数据时,模型的训练无法收敛。因子分解机FM
FM模型通过对二阶组合特征的巧妙设计,较为完美的解决了POLY2模型在增加模型表达能力的基础上带来的新问题,同时在泛化能力等方面有着增强。FM的模型下式所示:

对比FM与POLY2的二阶部分,可以看出两者的主要区别为FM用两个向量的内积 代替了单一的权重系数
代替了单一的权重系数  。这种操作的高明之处在于:
。这种操作的高明之处在于:为每个特征学习了一个隐向量权重(latent vector),而这种隐向量的计算方式可以更好地解决数据的稀疏问题,从而提高模型的泛化能力。(隐向量可以认为是embedding,这样会好理解些)
- 隐向量计算特征权重的方式,可将权重参数从POLY2的
 级别下降到
级别下降到  级别(k为隐向量的维度,n>>k)。
级别(k为隐向量的维度,n>>k)。
问题来了:
- 为什么可以解决稀疏性,提高泛化能力?
假设样本具备两个特征 与
与  ,由于数据稀疏
,由于数据稀疏 并未同时在训练实例里出现过,即
并未同时在训练实例里出现过,即 一起出现的次数为0,按POLY2的计算方式无法学到这特征组合的权重。
一起出现的次数为0,按POLY2的计算方式无法学到这特征组合的权重。
但FM为每个特征都学习了一个embedding,这意味着特征 和其它任意特征组合出现过,就可以学习到每个特征对应的embedding向量。即
和其它任意特征组合出现过,就可以学习到每个特征对应的embedding向量。即 这个特征组合形式没有出现过,但是在预测的时候,如果看到这个新的特征组合,因为
这个特征组合形式没有出现过,但是在预测的时候,如果看到这个新的特征组合,因为 和
和 都能学会自己对应的embedding,从而可以通过内积算出这个新特征组合的权重。这是为何说FM模型泛化能力强的根本原因。
都能学会自己对应的embedding,从而可以通过内积算出这个新特征组合的权重。这是为何说FM模型泛化能力强的根本原因。 - 为什么可以降低大幅度降低参数量?
直接上公式

FM 二阶部分降低参数的手写推导过程
从上述公式可以看到,虽然FM的二阶部分的原始表达方式为  级别的参数量级,但是经过一系列的恒等变化,可以将FM的二阶参数成功的降为了
级别的参数量级,但是经过一系列的恒等变化,可以将FM的二阶参数成功的降为了  级,同时在数值计算上也仍旧优雅。
级,同时在数值计算上也仍旧优雅。
FM的模型训练
FM模型的低阶逻辑回归的训练在前文已经有很详细的推导过程,这里主要推导一下二阶部分的训练。
首选需要定义一个损失函数
从sigmoid的函数谈起:
sigmoid函数  有一个优良的特性:
有一个优良的特性: 
推理如下:

那么若样本标签值用+1与-1表示正负值时,存在:
- 当y=1时,

- 当y=-1时,

那么对于预测数据存在:
采用Logistic loss则可得到FM的损失函数如下:
其损失函数  的求导如下所示:
的求导如下所示:
FM的假设函数  的表达式如下:
的表达式如下:
 的低阶导数较容易求出,二阶部分的求导如下:
的低阶导数较容易求出,二阶部分的求导如下:

结合低阶项目导数,最终得到FM的损失函数导数为:
所以FM模型中参数求解过程如下:
其中 ,参数项由  表示,一阶项参数由
表示,一阶项参数由  表示,二介参数由
表示,二介参数由  表示。
表示。
至此,FM的模型训练推导结束。
FM的代码编写与实际应用
FM在二分类问题上的应用
数据地址
代码如下:
# FM分类预估from __future__ import divisionfrom math import expfrom numpy import *from random import normalvariate # 正态分布import timeimport pandas as pdimport numpy as npimport randomfrom sklearn.model_selection import train_test_splitdef data_preprocessing(input_data):"""预处理数据:param input_data: 输入的数据:return 数据的特征feature, 数据的标签label"""feature = np.array(input_data.iloc[:, :-1]) # 取特征(8个特征)label = input_data.iloc[:, -1].map(lambda x: 1 if x == 1 else -1) # 取Outcome标签并转化为 +1,-1# 将数组按行进行归一化zmax, zmin = feature.max(axis=0), feature.min(axis=0) # 特征的最大值,特征的最小值feature = (feature - zmin) / (zmax - zmin)label = np.array(label)return feature, labeldef sigmoid(inx):return 1.0 / (1 + exp(-inx))def FM(dataMatrix, classLabels, k, iter):''':param dataMatrix: 特征矩阵:param classLabels: 类别矩阵:param k: 隐向量特征维度:param iter: 迭代次数:return: 常数项w_0, 一阶特征系数w, 二阶交叉特征系数v'''# dataMatrix用的是matrix, classLabels是列表m, n = shape(dataMatrix) # 矩阵的行列数,即样本数m和特征数nalpha = 0.01# 初始化参数w_0 = 0 # 常数项初始系数w_1 = zeros((n, 1)) # 一阶特征的初始系数v = normalvariate(0, 0.2) * ones((n, k)) # 二阶交叉特征的系数初始系数for it in range(iter):for x in range(m): # 随机优化,每次只使用一个样本# 二阶项的计算inter_1 = dataMatrix[x] * v # 每个样本(1*n)x(n*k),得到k维向量inter_2 = multiply(dataMatrix[x], dataMatrix[x]) * multiply(v, v) # 二阶交叉项计算,得到k维向量interaction = sum(multiply(inter_1, inter_1) - inter_2) / 2. # 二阶交叉项计算完成p = w_0 + dataMatrix[x] * w_1 + interaction # 计算预测的输出,即FM的全部项之和loss = sigmoid(classLabels[x] * p[0, 0]) -1 # 损失函数公共项目w_0 = w_0 - alpha * loss * classLabels[x] #更新参数项参数for i in range(n):if dataMatrix[x, i] != 0:w_1[i, 0] = w_1[i, 0] - alpha * loss * classLabels[x] * dataMatrix[x, i] #更新一阶项参数for j in range(k):v[i, j] = v[i, j] - alpha * loss * classLabels[x] * (dataMatrix[x, i] * inter_1[0, j] - v[i, j] * dataMatrix[x, i] * dataMatrix[x, i]) #更新而二阶项目参数#print("第{}次迭代后的损失为{}".format(it, loss))print("\t------- iter: ", it, " , cost: ", \getCost(getPrediction(np.mat(dataTrain), w_0, w_1, v), classLabels))# 常数项w_0, 一阶特征系数w_1(n维向量——n个特征), 二阶交叉特征系数v(n个k维向量)return w_0, w_1, vdef getCost(predict, classLabels):'''计算预测准确性input: predict(list)预测值classLabels(list)标签output: error(float)计算损失函数的值'''m = len(predict)error = 0.0for i in range(m):error -= np.log(sigmoid(predict[i] * classLabels[i]))return errordef getPrediction(dataMatrix, w_0, w_1, v):'''得到预测值input: dataMatrix(mat)特征w(int)常数项权重w0(int)一次项权重v(float)交叉项权重output: result(list)预测的结果'''m = np.shape(dataMatrix)[0]result = []for x in range(m):inter_1 = dataMatrix[x] * vinter_2 = np.multiply(dataMatrix[x], dataMatrix[x]) * \np.multiply(v, v) # multiply对应元素相乘# 完成交叉项interaction = np.sum(np.multiply(inter_1, inter_1) - inter_2) / 2.p = w_0 + dataMatrix[x] * w_1 + interaction # 计算预测的输出pre = sigmoid(p[0, 0])result.append(pre)return resultdef getAccuracy(predict, classLabels):'''计算预测准确性input: predict(list)预测值classLabels(list)标签output: float(error) / allItem(float)错误率'''m = len(predict)allItem = 0error = 0for i in range(m):allItem += 1if float(predict[i]) < 0.5 and classLabels[i] == 1.0:error += 1elif float(predict[i]) >= 0.5 and classLabels[i] == -1.0:error += 1else:continuereturn float(error) / allItemif __name__ == '__main__':diabetes_file = './data/diabetes.csv'input_data = pd.read_csv(diabetes_file)train, test = train_test_split(input_data, random_state=1)dataTrain, labelTrain = data_preprocessing(train)dataTest, labelTest = data_preprocessing(test)date_startTrain = time.time()print("开始训练")w_0, w_1, v = FM(mat(dataTrain), labelTrain, 20, 100)predict_train_result = getPrediction(np.mat(dataTrain), w_0, w_1, v)print("训练准确性为:%f" % (1 - getAccuracy(predict_train_result, labelTrain)))date_endTrain = time.time()print("训练用时为:%.2f" % (date_endTrain - date_startTrain), "s")print("开始测试")predict_test_result = getPrediction(np.mat(dataTest), w_0, w_1, v)print("测试准确性为:%f" % (1 - getAccuracy(predict_test_result , labelTest)))
参考资料:
- 《深度学习推荐系统》,王喆,2020.03
- 《Python 机器学习算法》赵志勇,2017.01
- 推荐系统召回四模型之:全能的FM模型
- FM算法推导及python实例分析
- 深度学习:Sigmoid函数与损失函数求导
- FM因子分解机模型的原理、推导、代码和应用
发布于 2020-08-03 22:47
A-2.FFM模型的原理与Python实现
基于上一篇分析中协同过滤、逻辑回归及FM的比较,可以得出这样一个结论:
主流模型迭代的关键在于增强模型表达能力,而增强方式的主要脉络为:
- 引入其它可用特征信息(CF->LR)。
- 将现有特征进行组合(LR->POLY2->FM)。
更通俗的表达:
- 模型迭代在于找到更多的有效信息。
本文想要回顾的FFM(Field-aware Factorization Macheines)模型可以看作是FM模型的增强版,其正是沿用在FM模型的特征组合思想,并将其发扬光大,曾在多项CTR预估赛中夺魁,并且被Criteo、美团等公司深度应用在推荐系统与CTR预估等领域。
相较于FM模型,FFM模型在FM隐向量特征交叉组合的基础上,进一步引入了特征感知(field-aware)这一概念,使得模型表达能力在理论上有了一个较大的提升。
FM模型表达式:
FFM的表达式如下所示:
从表达式中可以看出,FFM与FM的不同之处在于二阶特征组合部分的隐向量由 变成了
变成了  。而这便意味着FFM模型中每一维特征对应的不是唯一一个隐向量,而是一组特征隐向量,这也具体的引出了FFM与FM特征组合不同之处与FFM模型的提升之处。
。而这便意味着FFM模型中每一维特征对应的不是唯一一个隐向量,而是一组特征隐向量,这也具体的引出了FFM与FM特征组合不同之处与FFM模型的提升之处。
FFM这么做的原因是什么?
FM模型中每一特征共用同一个特征隐向量,意味着每一特征与不同域特征进行组合时使用的是同一隐特征向量来学习隐向量参数,这样不够细致,存在明显的信息浪费。
什么是特征域Fileds,FFM怎么去做特征域级的特征组合?
参考论文原文 ,“features” can be grouped into “fields” 。把这句话的主语和宾语置换一下就可以得到Fileds的定义: “fields” is grouped by “features”,也即特征域由某类特征组成。
借用论文的示例,或许可以更直观的回答这个问题: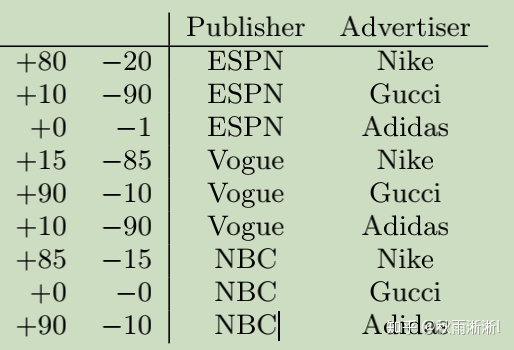
Table 1: An artificial CTR data set, where + (-) representsthe number of clicked (unclicked) impressions.
Table 2:a example of click event
在上面两个表中,Publisher(P)、Advertiser(A)和Gander(G)是三个Fileds特征域。其中Publisher特征域的中的feature有ESPN、Vogue和NBC,套用作者定义那么有:fields of Publisher is grouped by features
那么对于Table 2的数据,FFM的二阶特征组合结果为:
而对于FM二阶特征组合结果而言:
可以看到在FFM模型中,Feature ESPN在与NIKE及Male形成特征组合ESPN,NIKE)、(ESPN,Male)时,使用了不同的潜向量 及
及  来学习参数。同理,Feature NIKE在与ESPN及Male特征组合时,也分别使用了两个不同的潜向量
来学习参数。同理,Feature NIKE在与ESPN及Male特征组合时,也分别使用了两个不同的潜向量  及
及  来计算组合权重。
来计算组合权重。
而对于FM而言,Feature ESPN在与NIKE及Male特征组合时,使用的是同一个潜向量 ,同时NIKE与Male特征也只存在唯一一个隐向量。
,同时NIKE与Male特征也只存在唯一一个隐向量。
至此,什么是特征域Fileds,FFM怎么去做特征域级的特征组合得到解释。一个问题
以上解释了FFM模型相较于FM模型的优势在于,每个特征在与不同Field下的Feature进行组合时,会使用与之特征域对应的隐向量来学习组合权重。而这也带来了一个FFM不被大规模应用的问题—参数量暴增,解释如下:
假设一份数据集dataset的维度为(m,n),FM在进行模型训练时将隐向量特征维度设置为k维,那么FM的特征量便为nk。而对于FFM而言,假设dataset的n维特征对应着f个特征域,那么在隐向量维度同维k的情况下,FFM的特征量级为nfk(实际数量为n(f-1)k,由于特征不需要自我交叉,因此为f-1)。
nk与nfk之间的差别虽然只是线性级,但是由于互联网数据特征量n动辄百万级,虽然f的值会比n小若干个数量级,但这也足以使得FFM模型的参数量暴增到一个恐怖的级别。
Table 3:two CTR datasets Criteo and Avazu from Kaggle competitions
以Table3数据集Criteo为例,当维度k取为10时,FM的参数量为 ,而FFM的量级为
,而FFM的量级为  。虽然只增加了一个数量级别,但参数量从千万级变为了亿级别,可谓非常恐怖了。
。虽然只增加了一个数量级别,但参数量从千万级变为了亿级别,可谓非常恐怖了。
python实现
关于FFM的工程代码其实论文作者已经在github上给出C++版本,python版,或者Amazon AI的马超开源的XLearn。
本文引用Python implementation of FFM model (ctr, cvr)一文,来分析一下FFM的代码实现。import numpy as npimport mathimport randomclass ffm(object):def __init__(self, feature_num, fild_num, feature_dim_num, feat_fild_dic, learning_rate, regular_para, stop_threshold):#n features, m domains, each feature dimension kself.n = feature_num #特征数量self.m = fild_num #特征域数self.k = feature_dim_num #隐向量特征长度self.dic = feat_fild_dic #特征对应的域#Set hyperparameter, learning rate eta, regularization coefficient lamdaself.eta = learning_rateself.lamda = regular_paraself.threshold = stop_thresholdself.w = np.random.rand(self.n, self.m , self.k) / math.sqrt(self.k)#权重初试值self.G = np.ones(shape = (feature_num, fild_num, feature_dim_num), dtype = np.float64)def train(self, tr_l, val_l, train_y, val_y, max_echo):#这一部分计算模型的训练损失# tr_l, val_l, train_y, val_y, max_echo are# Training set, validation set, training set label, validation set label, maximum number of iterationsminloss = 0for i in range(max_echo):# Iterative training, max_echo is the maximum number of iterationsL_val = 0Logloss = 0order = range(len(train_y))# mess up the orderrandom.shuffle(order)for each_data_index in order:# Remove a recordtr_each_data = tr_l[each_data_index]# phi() is the model formulaphi = self.phi(tr_each_data)# y_i is the actual tag valuey_i = float(train_y[each_data_index])# Calculate the gradient belowg_phi = -y_i / (1 + math.exp(y_i * phi))# Begin to update the model parameters using the gradient descent methodself.sgd_para(tr_each_data, g_phi)# Next, check on the verification set, the basic process is the same as before.for each_vadata_index, each_va_y in enumerate(val_y):val_each_data = val_l[each_vadata_index]phi_v = self.phi(val_each_data)y_vai = float(each_va_y)Logloss += -(y_vai * math.log(phi_v) + (1 - y_vai) * math.log(1 - phi_v))Logloss = Logloss / len(val_y)# L_val += math.log(1+math.exp(-y_vai * phi_v))print("The %d iteration, LOGLOSS on the validation set: %f" % (i, Logloss))if minloss == 0:# minloss stores the smallest LOGLOSSminloss = Loglossif Logloss <= self.threshold:# It can also be considered that setting the threshold allows the program to jump, and personal needs can be removed.print('Less than the threshold!')breakif minloss < Logloss:# If the next iteration does not reduce LOGLOSS, break out (early stopping)print('early stopping')breakdef phi(self, tmp_dict):#这一部分计算这FFM二阶部分的对应的值#Samples are normalized here to prevent calculation overflowsum_v = sum(tmp_dict.values())#First find the index of the non-zero feature in each piece of data and put it in a listphi_tmp = 0key_list = tmp_dict.keys()for i in range(len(key_list)):#feat_index is the index of the feature, fild_index1 is the index of the domain, and value1 is the value corresponding to the featurefeat_index1 = key_list[i]fild_index1 = self.dic[feat_index1]#The purpose of dividing here by sum_v is to normalize this one (return all feature values to between 0 and 1)#Of course, each feature has been normalized before (0-1)value1 = tmp_dict[feat_index1] / sum_v#Two non-zero features pairwise inner productfor j in range(i+1, len(key_list)):feat_index2 = key_list[j]fild_index2 = self.dic[feat_index2]value2 = tmp_dict[feat_index2] / sum_vw1 = self.w[feat_index1, fild_index2]w2 = self.w[feat_index2, fild_index1]#The final value is obtained by summing up multiple characteristic combinationsphi_tmp += np.dot(w1, w2) * value1 * value2return phi_tmpdef sgd_para(self, tmp_dict, g_phi):#这一部分梯度计算 ,参数的更新#学习率是用的AdaGrad算法sum_v = sum(tmp_dict.values())key_list = tmp_dict.keys()for i in range(len(key_list)):feat_index1 = key_list[i]fild_index1 = self.dic[feat_index1]value1 = tmp_dict[feat_index1] / sum_vfor j in range(i + 1, len(key_list)):feat_index2 = key_list[j]fild_index2 = self.dic[feat_index2]value2 = tmp_dict[feat_index2] / sum_vw1 = self.w[feat_index1, fild_index2]w2 = self.w[feat_index2, fild_index1]# Update g and Gg_feati_fildj = g_phi * value1 * value2 * w2 + self.lamda * w1g_featj_fildi = g_phi * value1 * value2 * w1 + self.lamda * w2self.G[feat_index1, fild_index2] += g_feati_fildj ** 2self.G[feat_index2, fild_index1] += g_featj_fildi ** 2# math.sqrt() can only accept one element, while np.sqrt() can root the entire vectorself.w[feat_index1, fild_index2] -= self.eta / np.sqrt(self.G[feat_index1, fild_index2]) * g_feati_fildjself.w[feat_index2, fild_index1] -= self.eta / np.sqrt(self.G[feat_index2, fild_index1]) * g_featj_fildi
参考资料
A-3.GBDT+LR模型原理解析
0. 背景
GBDT+LR模型由Facebook于2014年发布的一个CTR预估模型,核心思路是基于GBDT做特征筛选和高维特征组合,基于LR做CTR预估。本文回顾此模型的原因是GBDT+LR模型较之于FFM,提供了一种截然不同的特征交叉思路。同时,其论文中指出GBDT+LR模型在Facebook广告预测上比单独的LR或GBDT都有3%以上的提升,模型性能可见一斑。
1. GBDT+LR模型架构
如图1,相比深度模型,GBDT+LR模型在架构而言十分的简洁。GBDT部分通过多颗回归树将输入特征重新筛选组合后为新的特征离散,LR部分则通过读取GBDT的输出特征进行模型训练。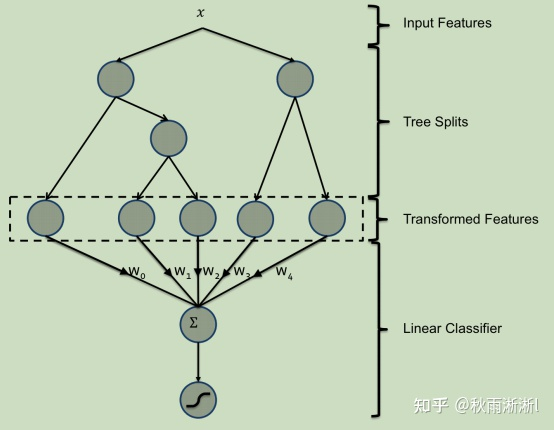
图1 GBDT+LR的模型架构
从架构图直观来看,LR训练和GBDT特征工程部分似乎是耦合在一起的,但其实这两个环节是可以独立训练的。实际上,Facebook原文里也有讲到,相较于轻量的LR训练,GBDT的训练十分费时。因此LR模型可以实时或者daily更新来保证模型学到实时或近实时信息,而GBDT部分则为daily或者weekly级别,尽管后者这种操作会牺牲一部分预测准确率。
较之于前两篇介绍过的CF/LR/FM/FFM模型,LR+GBDT 理论上不需要花费过多的时间做精细化的特征筛选,同时可以引入两个维度以上的特征组合以及通过控制子树数量和深度来避免特征爆炸问题。另外,站在今天的角度来看,LR+GBDT和深度学习时代大行其道的End to End模型训练模型很接近。
2 GBDT特征组合原理
2.1 关于GBDT的几个思考
在分析GBDT原理之前,我们先思考几个有意思的问题。
- GBDT为什么叫做梯度提升树?
- 梯度提升和梯度下降有什么区别和联系?
- GBDT的两个别名GBRT(Gradient Boosted Regression Tree) 、MART(multi Additive Regression Tree)分别说明了什么?
- GBDT的多颗决策树是否可以并行训练?
在思考问题1时,笔者下意识的回答到:GBDT是朝着梯度提升方向进行模型训练的。但是查看了梯度提升和梯度下降算法的更新方式后,如图2,我觉得我错了。实际上,正如GBDT的全称Gradient Boosting Decision Tree 描述的,GBDT是一种基于Gradient Boosting算法框架的决策树模型。其中的GB指的便是用梯度计算拟合损失函数的提升过程,而这也便是其中文名中“梯度提升“的由来。
对于问题2,实际上两者都是利用损失函数相对于模型的负梯度方向的信息,来对当前模型进行更新,这也是两者之间的共性。区别之处在于,在梯度下降中模型是以参数化形式表达,因而模型的更新等价于参数的更新。而在梯度提升中,模型并不需要进行参数化表示,而是直接定义在函数空间中。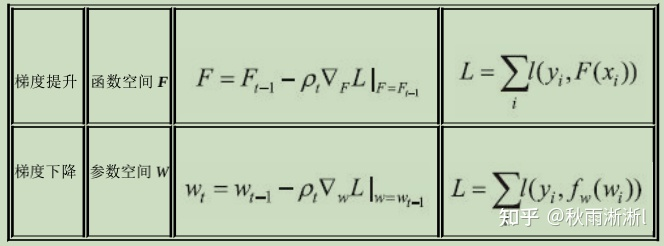
图2 梯度提升算法和梯度下降算法的对比
对于问题3,GBRT中的”Regression Tree“告诉我们GBDT的基学习器是回归树而不会是分类数,MART中”multi additive“则是说明GBDT是一个加法模型。
对于问题4,答案是否定的。GB作为集成学习家族中Boosting一员,其基学习器都采用串行的方式进行运行,学习器之间存在依赖。而Boosting类算法采用串行的原因是,其每一轮训练时想给上一轮训练中出错的样本一个更高的权重
个人认为理解好上面四个问题,尤其是GBDT别名和Boosting的意义,可以让我们简明的了解到GBDT的底层原理和训练方式。
2.2 GBDT模型原理
基于上面四个问题的思考,GBDT中Gradient Boosting 环节的训练逻辑就很好理解了。如图3,简单的来说,Gradient Boosting在每一轮的迭代中,首先会计算出当前模型在所有样本的负梯度<步骤3>,然后以此为目标
图3 Gradient Boosting算法伪代码
如果以上阐述让我们还存在困惑,那大可以再通过一个举例来分析GBDT的优化的过程。
假设当前已经生成了三颗子树<基学习器>,则当前预测值可以定义为:
那么对于第四课子树,GBDT模型期望的则是其预测值  和
和  以及拟合函数
以及拟合函数  存在以下关系:
存在以下关系:
那么第四颗子树的生成过程便是以目标拟合函数与已有树林预测结果的残差  为目标:
为目标:
PS :
- 从
 的定义我们可以看到问题3、4的结论—-加法器 &串行。
的定义我们可以看到问题3、4的结论—-加法器 &串行。 - 从
 的定义我们可以看到问题1的结论—-拟合的是损失函数的提升方向。
的定义我们可以看到问题1的结论—-拟合的是损失函数的提升方向。
最后,如果你也对GBDT拟合的残差也是即负梯度这个问题有一些想法,欢迎在留言区留言。这里在参考文献的第4篇给出了一个不错的观点。
2.3 GBDT特征转化过程
了解了GBDT的训练过程,理解GBDT+LR模块为什么可以做到高维度的特征交叉就变的很容易了。
如图4,假设对于原始特征向量X,我们采用三颗子树来做特征转化,同时每颗子树深度为3,叶子节点数为4。那么对于向量X,则被转化为一个经过两阶特征交叉组合的向量
[0,0,1,0,1,0,0,0,0,0,0,1],其中新特征向量为1的维度是其对应子树落到的对应节点。
同样的道理,如果我们采用四颗深度为3,叶子节点为4的子树进行特征转化,那么特征向量X则是一个经过量三阶特征交叉组合、维度为4*4的向量。
通过增加子树数目和深度,GBDT理论上具备生成任意多阶的交叉组合特征,使得其具备很强的特征组合能力,且不容易出现FM特征组合思路的参数爆炸问题。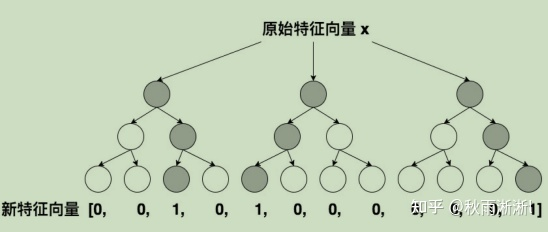
图4 GBDT生成特征离散特征向量过程
3 GBDT+LR的局限性
每一种模型都存在自己的局限性,那么GBDT+LR的局限性是哪些呢?容易想到的有以下几点:
- Boosting 结构带来的无法并行训练问题,导致需要较长的时间进行模型更新。
- 容易过拟合,特别是高维稀疏场景。
- 丢失了大量的数值型特征信息。
结束语
关于LR环节的训练,可以参考前文前深度学习时代—从协同过滤CF到因子分解机模型FM的逻辑回归部分,本文不做展开。
关于GBDT+LR的实现本文也不做举例,主要是目前有很多开源的框架可以让我们快速的完成GBDT的训练和LR的预估过程,而如果要代码实现GBDT的实现过程又会是一个比较复杂的过程,但其复用性却不强,感兴趣的同学可以点击参考文献3的代码示例部分进行学习。
最后,希望本文对你有所帮忙,如果存在描述不清或者错误的地方欢迎在留言区留言指正。
参考文献
- Practical Lessons from Predicting Clicks on Ads at Facebook
- 《深度学习推荐系统》—王喆
- [白话解析] 通俗解析集成学习之GBDT
- GBDT理解难点———拟合负梯度
- 集成学习-Boosting,Bagging与Stacking
A-4.阿里LS-PLM模型原理解析
0. 背景
今天要学习的模型是阿里曾经的主流模型LS-PLM(Large Scale Piece-wise Linear Model 大规模分段线性模型),如果你对这个模型感到陌生,不妨了解一下它的别称—MLR(Mixed Logistic Regression,混合逻辑回归)。
虽然LS-PLM2012年就大规模应用于阿里妈妈定向广告等场景,但在很长的一段时间内业界并不知道它的细节。好在2017年,江湖人称“阿里算法天才”的盖坤携其团队朱小强等大佬将此模型以论文的形式公布,才让LS-PLM的诸多细节公之于众。
一个题外话,大家可以多关注一下这两位大佬在阿里妈妈团队期间的工作,个人感到很惊艳。当然,后期专栏也会对他们提出并成功应用的DIN/DIEN等模型进行学习。
基于论文和盖坤、朱小强的一些公开演讲可以知道,LS-PLM的在设计之初是为了改进大规模广义线性模型的如下问题:
- 广义线性模型性能有限,高度依赖人工特征工程,很难对非线性模式挖掘充分;
- 人工特征工程依赖领域经验,跨领域推广代价高;
LS-PLM最终可以达到的效果:
- Nonlinearity. 具备任意强非线性拟合能力;
- Sparsity.具备特征选择能力,使得模型具备稀疏性。
- Scalability. 具备从大规模稀疏数据中挖掘出具有推广性的非线性模式;
1. LS-PLM模型结构
首先让我们先从名称上来理解LS-PLM(Large Scale Piece-wise Linear Model)结构,我们大概可以解读出以下信息:
- 具备应用于大数据场景能力 Large Scale;
- 有分而治之的思想 Piece-wise;
- 本质上是一个线性模型 Linear Model+ Logistic Regression;
那如果不看LS-PLM的架构,我们可以对上述LS-PLM模型做和想象呢?它这么有效,会不会很复杂呢?信息3不用说,是通用的LR结构。那信息1和2呢?
对于信息1,直观上没有很多可想象的空间。对于信息2,我想到的是一种类似attention的结构,它的作用是去捕捉用户的兴趣。可2012年attenion还不是一种通用有效的结构啊,那LS-PLM是怎么做到“Piece-wise”这件事情呢?好了,不猜了,上模型。
1.1 模型表达


如上述公式所示,LS-PLM在表达上非常朴实,拆开来看就是常见的softmax和LR 。其中的softmax也即  负责将特征切分到m个不同的空间,LR部分
负责将特征切分到m个不同的空间,LR部分  则负责对m个空间的特征分片的进行预测,
则负责对m个空间的特征分片的进行预测,  则的作用则是使得模型符合概率函数定义。
则的作用则是使得模型符合概率函数定义。
1.2 Nonlinearity理解
讲到这里,我们大概可以知道LS-PLM的Nonlinearity和Piece-wise能力是怎么来的了。即通过控制分片数m,使得LS-PLM便具备拟合任意强度高维空间的非线性分类面能力。
为了直观的看到LS-PLM的Nonlinearity,这里再不妨把论文中一个很直观的例子拿出来展示一下。如图1,假设训练数据是一个菱形分类面,基于LR的模型能做到的效果如图1.B),LS-PLM则可以做到用4个分片完美的拟合训练集合,如图1.C)。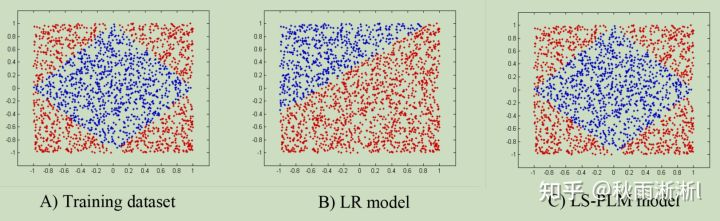
图1 A demo illustration of LS-PLM model
不过需要说明的是,模型的参数会随着m线性增长,相应所需的训练样本也会随之增长。论文中作者指出在阿里的应用场景一般选择m=12。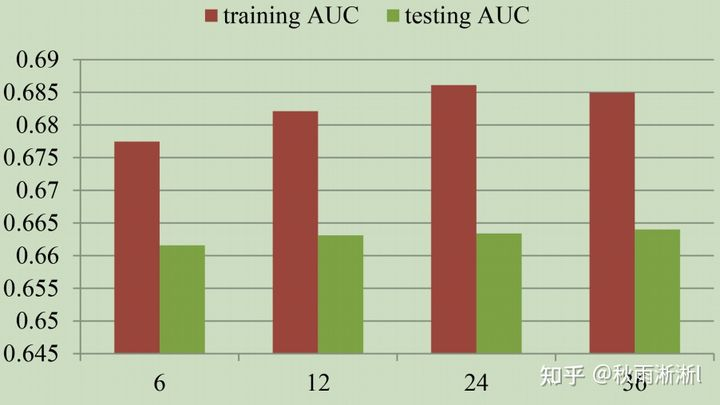
图2 分片数与模型AUC表现
1.3 Sparsity+Scalability理解
基于以上论述,对于LS-PLM的Nonlinearity我们应该很清楚了,那么所谓的LS-PLM 的Sparsity 是怎么体现的呢?实际上,LS-PLM主要是通过  和
和  正则化来做到这件事情。其中
正则化来做到这件事情。其中  用于实现特征筛选,
用于实现特征筛选,  则用于得到尽可能多的稀疏解。同时,
则用于得到尽可能多的稀疏解。同时,  和
和  在提高模型泛化能力的同时,也使得模型的部署更加轻量,很大程度上也能缓解线上推断压力,而这也是为什么LS-PLM可以应用于大规模数据场景了。
在提高模型泛化能力的同时,也使得模型的部署更加轻量,很大程度上也能缓解线上推断压力,而这也是为什么LS-PLM可以应用于大规模数据场景了。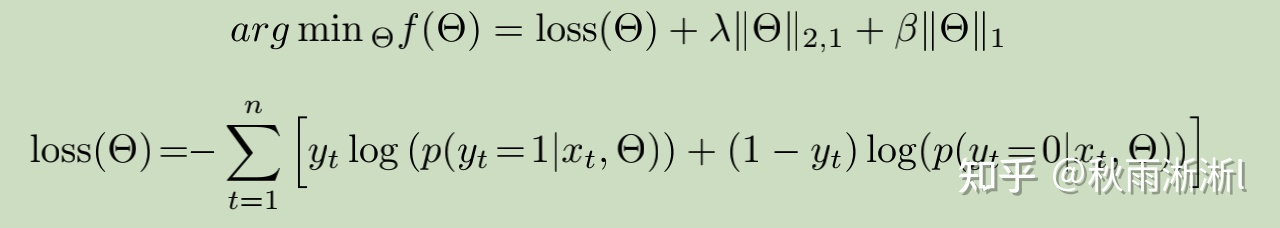
图3 LS-PLM目标函数
1.4 非凸非平滑问题解决方案
不过由于 和
和  都是非平滑(non-smooth)函数,正则化的加入会使得LS-PLM的目标函数变成了一个非凸非平滑(non-convex and non-smooth)函数,而这是一个很大的问题。
都是非平滑(non-smooth)函数,正则化的加入会使得LS-PLM的目标函数变成了一个非凸非平滑(non-convex and non-smooth)函数,而这是一个很大的问题。
为什么说是一个很大的问题呢?因为非凸非平滑意味不能使用传统的梯度下降和EM等方法进行优化求解。在了解盖坤的解决方法之前,让我们先来理解什么是非凸和非平滑函数,以及为什么传统方案为什么无法优化求解。
非凸函数理解
首页什么是非凸函数?抛开数学定义,让我们先从集合的角度来直观理解一下。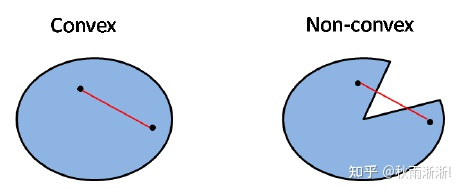
图4 凸集合和非凸集合
简单来说,如果一个集合中的任意两点之间的连线都在集合范围内,则集合为凸集,如图4左图,否则为非凸集合,如图4右图。
如果从函数的角度来看,凸函数的任意局部最优解便是其全局最优解,基于贪婪算法和梯度下降容易找到最优解。而非凸函数则不同,因为它的可行域中可能存在无数个局部最优解,因此全局最优解的求解难度是NP-hard,是公认的难求解问题。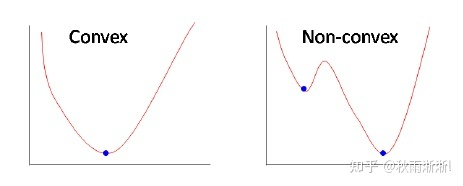
图5 非凸函数与凸函数二维空间举例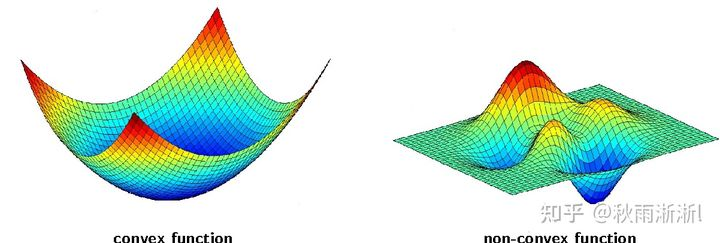
图6 非凸函数与凸函数三维空间举例
非平滑函数理解
非平滑函数比较容易理解,其函数特性是并非处处可导,意味着不是任意点都可计算梯度,无法用梯度下降优化求解。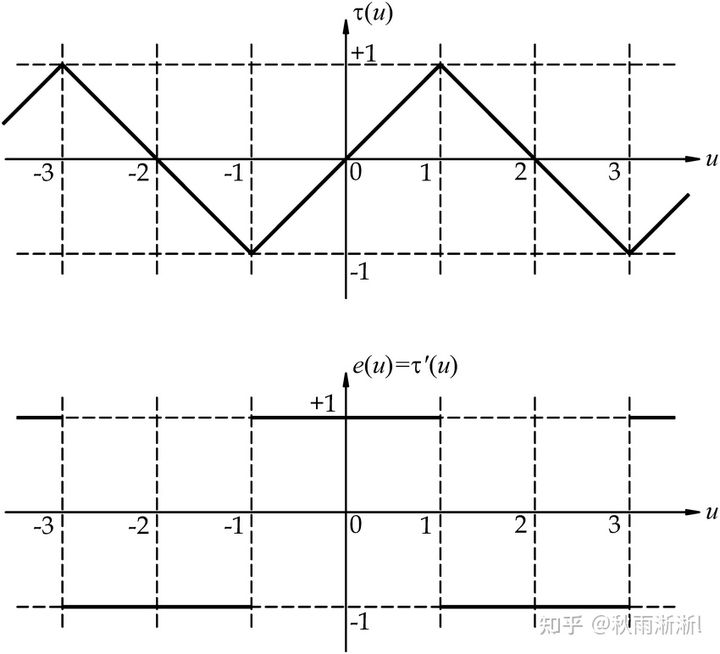
图7 非平滑函数举例
好了,理解好什么是非凸非平滑函数后,我们来看看盖坤他们是怎么解决这两个问题的。
非平滑函数解决方案
首先是非平滑问题,不解决平滑问题意味则模型无法训练,为此LS-PLM在证明函数处处存在方向导数后,对于不存在梯度的点上采用其方向导数来指导模型训练。而为什么损失函数方导数处处存在,此处简单论述如下,如果对推倒过程感兴趣的可以移步原文附录。 范数在数学上会形成一个圆锥点,但那个圆锥点是没有切面的,所以它不可导,这也是其非平滑的原因。不过从它出发沿任何一个方向都有切线,所以其方向可导,而所有部分都方向可导,叠加起来就是处处方向可导。
范数在数学上会形成一个圆锥点,但那个圆锥点是没有切面的,所以它不可导,这也是其非平滑的原因。不过从它出发沿任何一个方向都有切线,所以其方向可导,而所有部分都方向可导,叠加起来就是处处方向可导。
在证明非平滑问题可解后,论文进一步给出了用LBFGS做二阶加速和Line Search补偿搜索来加速算法收敛。
而对于非凸问题,论文中实际上并没有给出详细的求解方案,而且在阿里妈妈算法团队2017年技术分享中也表示,虽然MLR比LR好但并不知道和全局最优相比还有多远,想来这个问题并不是那么好解决。同时,对于笔者而言,非凸优化问题也是一个比较生疏的领域,无法给到一些猜测,不过这个问题我们后续倒是可以专门写一篇文章来进行讨论。
2. LS-PLM模型的工程加速
以上我们从模型设计和优化求解上做了详细的讨论,接下来我们再对论文给出的两个从工程角度加速模型训练的方法做简单介绍。
2.1 并行化模型训练
首先是模型的并行化训练和推断。如图8,LS-PLM的每一个Node中同时部署了Worker和Server两种角色,而这么做的好处是最大化内存和CPU的利用率,进而提高模型推断速度。
具体体现是在每一个Worker Node存储的一部分数据和本地模型,而每个Server Node则存储全局模型参数。在每次模型迭代时,Worker Node并行的计算好各自的损失和梯度并上报给Server Node,Server Node则并行的聚合所有的损失和梯度从而进行全局模型的参数更新。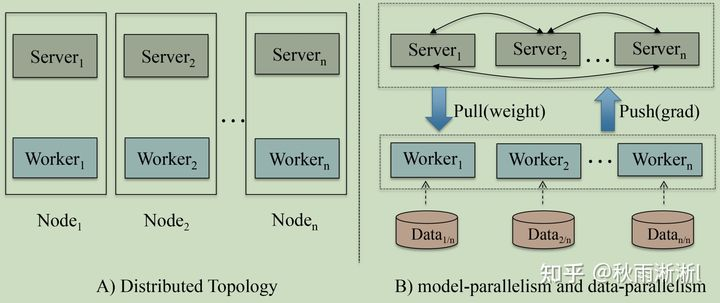
图8 The architecture of parallel implementation
2.2 Common Feature Trick
Common Feature Trick 很好理解,其可达到的目标是大幅度压缩样本存储进而加速模型训练。具体实现是,通过分级缓存用户静态特征(如年龄、性别、昨天以前的历史行为)。因为尽管用户一天会访问广告多次,但实际上只需要存储一次用户的静态数据,其余样本便可通过索引与其关联,因此在训练的过程中对应的这部分特征也只需要计算一次。
值得一提的是,阿里实践中应用common feature trick可以做到同等数据训练,仅花费1/3的资源消耗就获得了12倍的加速。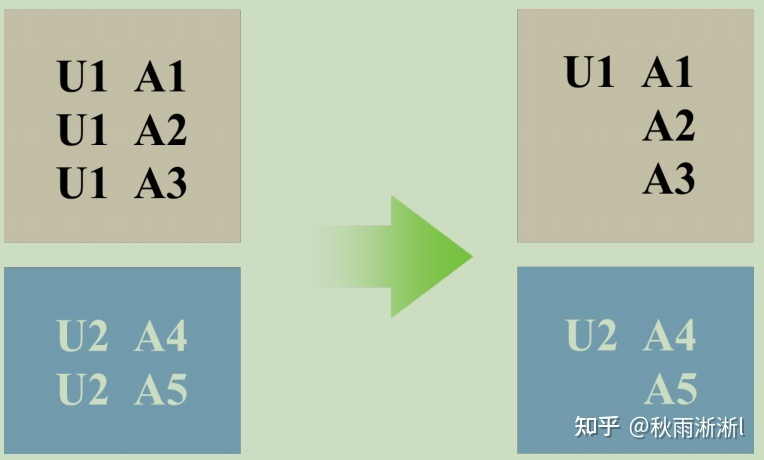
图9 Common feature pattern in display advertising
3. 结束语
从深度学习模型的角度思考LS-PLM
作为前深度时代成功大规模应用的浅层模型,LS-PLM在用自己的方法打破线性LR模型的局限性,向非线性方向推进的同时,也在接近着深度学习的大门。
如图10,LS-PLM实际上可以看成一个三层的神经网络模型,  是大规模的稀疏输入数据,LS-PLM模型第一步是做了一个Embedding操作,分为两个部分,一种叫聚类Embedding(绿色),另一种是分类Embedding(红色)。两个投影都投到低维的空间,纬度为M,对应的是模型中的分片数。完成投影之后,通过很简单的内积(Inner Product)操作便可以进行预测,得到输出Y。
是大规模的稀疏输入数据,LS-PLM模型第一步是做了一个Embedding操作,分为两个部分,一种叫聚类Embedding(绿色),另一种是分类Embedding(红色)。两个投影都投到低维的空间,纬度为M,对应的是模型中的分片数。完成投影之后,通过很简单的内积(Inner Product)操作便可以进行预测,得到输出Y。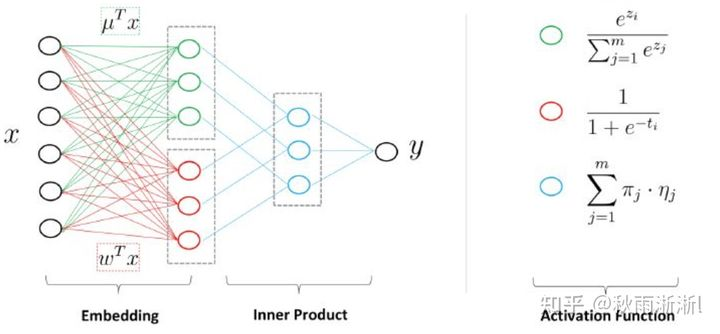
图10 LS-PLM的网络化表示
当然LS-PLM作为浅层机器学习模型,还有是有着其时代的局限性,比如无法端到端的训练。
最后,希望本文对你有所帮忙,如果存在描述不清或者错误的地方欢迎在留言区留言指正。
参考文献
1.论文下载地址Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
2.【阿里算法天才盖坤】解读阿里深度学习实践,CTR 预估、MLR 模型、兴趣分布网络等
3.重磅!阿里妈妈首次公开自研CTR预估核心算法MLR
4. 独家 | 阿里盖坤演讲:从人工特征到深度学习,我们为了更准确地预估点击率都做了多少努力
5.基于深度学习的广告CTR预估算法
6.在数学中一个非凸的最优化问题是什么意思?
A-5.推荐模型演化路径梳理
0. 背景
前面花了四篇文章介绍了前深度学习时代的一些主流推荐模型,今天让我们再花一点时间再做一个总结性梳理。
1. 前深度学习时代—推荐模型演化路径梳理
在前面四篇文章中,我们详细的谈论了CF、LR、PLOY2、FM、FFM、GBDT+LR、LS-PLM七个前深度学习时代的经典模型。那这么些模型之间的演化存在什么关系呢?借用王喆老师在《深度学习推荐系统》一书的演化关系图,梳理如下: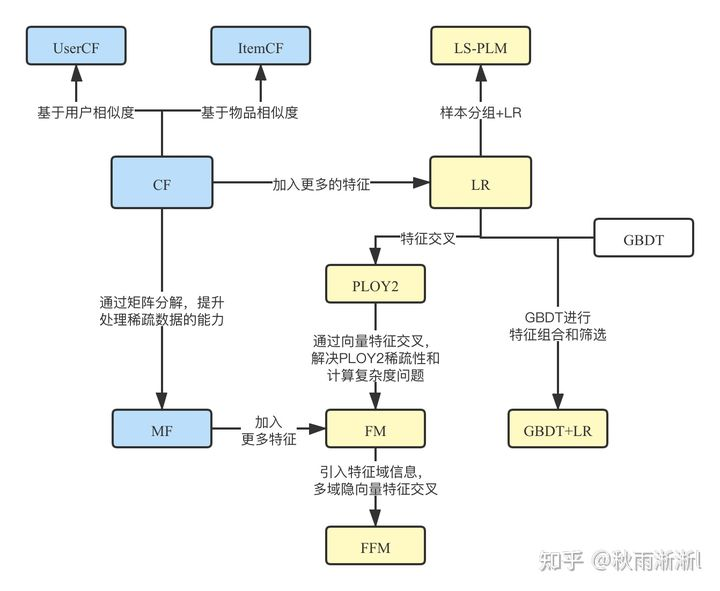
图1 传统推荐模型的演化关系图
1.1 协同过滤算法族。
毫无疑问,之前介绍的UserCF、ItemCF及其本专栏没有介绍过的MF(Matrix Factorization, MF)属于此族。其核心思想可概括为“物以类聚,人以群分”,模型优点有可解释性强,可离线生成计算结果,容易上线,缺点是只利用商品和活动共现关系,具备一定记忆能力,但泛化能力弱,上限明显。
关于MF,其主要是基于CF模型中的共现矩阵做矩阵分解,矩阵分解可以理解为离散特征Embedding化,核心目的是用非常少维度的数据去表达原本的User/Item信息。而这么做的好处也很显然的,MF的空间复杂度会远低于CF,并且泛化能力也好于CF,缺点是逃不出共现矩阵模式的性能上线。
1.2 逻辑回归模型族。
LR是前深度学习时代,CF模型之后最通用的模型,它比CF能学到到更多的信息,如用户、商品动静态属性及上下文信息。优点是可方便并行计算,比较明显的局限性是,需要大量的手动特征工程。而且因此本质上是一个线性模型,学习能力存在时代的“硬伤”,也因此业界发展出来基于LR模型缺陷演化而来的模型框架。
PLOY2是业界为了解决LR模型不具备特征组合能力,而提出的过度性模型,其核心思想是特征之间的暴力组合,缺陷也很明显,比如模型训练复杂度高、训练开销大。
LS-PLM是阿里2012上线并长时间应用的主模型,其通过做分片逻辑回归而具备了可控的非线形能力,配合正则化可以给模型带来很好的稀疏性,是LR一族比较知名有效的变形算法。
1.3 因子分解机模型族。
因子分解机中的FM、FFM,也是从LR模型发展而来,事实上其一阶部分就是LR。FM族的出现主要是为了解决LR模型不具备高阶特征组合能力,而被提出并可有效应用的模型。其中,FFM在FM的基础上,进一步引入了特征感知(field-aware)这一概念,使得模型表达能力在理论上有了一个较大的提升,不过也带了参数线性倍增的问题。
总的来说,FM、FFM的突出点是提出了可行的特征交叉思路,局限性是都只做了二阶特征组合,且更高阶的特征组合存在严重的参数爆炸问题。
不过尽管如此,FM模型的特征交叉的思路仍旧是一个被高频度提及的经典方案,而且在深度学习时代也没有过时,并孕育出DeepFM,xDeepFM等知名模型。
1.4 组合模型族
之前聊过的组合模型只有GBDT+LR,其核心思想是GBDT做特征高阶交叉,LR做CTR预估。
引用王喆老师的观点是:“GBDT+LR组合模型中可以体现出特征工程模块化思想,是深度学习推荐模型的印子和核心思想之一”。
不过阿里妈妈的高级技术总监盖坤在一些场合也讲到:“GBDT这一类非线性模型,存在高维稀疏特征容易过拟合和计算复杂度问题<无法并行计算>”。但无论如何,GBDT+LR提供了一条行之有效的非线性CTR预估模型。
2. 结束语
站着今天的角度看之前的模型,以上介绍的模型相对“低级”和单一。借用阿里妈妈前算法总监朱小强的话,2005-2015这十年间推荐和计算广告领域的主流解决方案,甚至可以用一句话来概括,那就是:“以G/B两家为代表的大规模离散特征+特征工程+分布式线性LR模型解法几乎成为了那个时代的标准解”。
尽管如此,这些模型仍然值得回味和学习,正所谓经典永流传。只不过自2016年后,随着FNN、Deep&Wide、Deep Crossing等一大批优秀推荐模型架构,深度学习模型逐渐席卷和搜广推领域,成为了这个时代当之无愧的主流,而笔者也将追随着这波潮流去探索其中奥秘。
参考文献
B-1.Embedding技术理解及在推荐场景的应用举例(附Item2Vec PySpark实现)
0. 背景
从今天开始,专栏正式进入深度学习时代。在学习具体的深度模型之前,先来聊聊Embedding技术,这么做的理由有以下几点:
- Embedding是深度学习中的核心基础操作,理解Embedding技术便于理解深度模型训练。
- 比之于One-hot方式的向量表达,Embedding向量表达极具区别性。
- 基于物品Embedding做物品的召回/推荐是非常通用有效的做法。
据此,本文将会展开讨论的有:
- Embedding基础知识
- Embedding的经典生成方法理解—Word2vec
- Embedding在推荐系统的应用举例—Item2vec
- Item2vec的PySpark实现
1.Embedding基础知识
首先什么是Embedding?如果你对Embedding不陌生,相信这个问题你会有自己的答案。在这里我给一下对Embedding的理解:
- Embedding是object的低维稠密的向量化表示,通过网络化等训练后可具备大量信息。
这其中的object可以理解为某商品、某用户、或者某个词汇又或者是anything,正如江湖流传“万物皆可Embedding”。
为什么会特意强调低维、稠密、向量化和大量信息这个几个词呢?
主要在Embedding技术之前,object的向量化一般是One-hot实现,但One-hot有一个特点是会有大规模的数据稀疏问题。而Embedding则不然,它一般都是一个低维稠密的表达。
为了更直观的理解这两者的差异,我们不妨用以下例子展开说明:
- 假设某电商平台存在一亿件商品,那么基于One-hot表达商品ID,每个商品便需要一个一亿维度的向量进行表示,一亿件商品便是一亿*一亿维度的参数空间。
- 而基于Embedding是可以控制向量维度的,比如每件商品基于一个10维空间向量进行表达,一亿件商品便是一亿*10维度的参数空间。
通过这个例子,Embedding强调是低维稠密向量原因可见一斑。
而对于Embedding具备大量信息这个问题,是因为随着Graph Embedding的提出,Embedding 几乎可以引入任何信息进行编码,如用户年龄、性别及历史行为,使其本身就包含大量有价值的信息。
讲明了Embedding的这些特性,我们很容易想到直接将其应用在推荐系统。比如计算物品和用户的相似度,进而得到推荐或者召回结果。事实上基于Embedding做进行相似物品推荐,几乎是业界最流行的做法。
接下来就让我们从Embedding最经典的生成方式开始,讲讲其的生成过程和在推荐系统的应用举例。
2.Embedding的经典生成方法—Word2vec
讲Embedding几乎必提Word2vec。Word2vec在提出之时,是为了给“词”一种不同的向量表示。正如原文所说:
“We propose two novel model architectures for computing continuous vector repre-sentations of words from very large data sets.”
这个”word to vector”的过程,后来也被认为是经典的 Embedding方法。自从2013年谷歌提出以来,就被大规模应用于NLP和搜广推等场景,成为深度学习中不可或缺的核心基础技术。
而关于Word2vec 的原理和实现,模型提出者Tomas Mikolov等人给出了两种方案,分别是 CBOW(Continuous Bag-of-Words Model)和Skip-gram。
CBOW和Skip-gram的架构和区别如图1所示: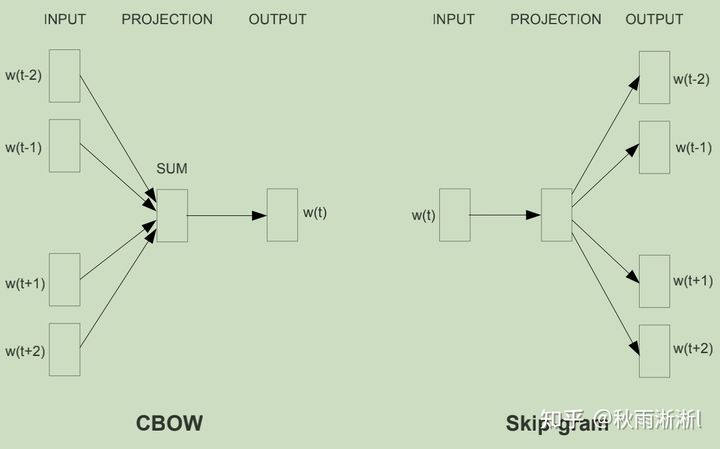
图1 Word2vec模型架构
从图1可以看出,Word2vec的CBOW是基于上下文来预测某个词汇  的输出概率,而Skip-gram则于基于当前词汇
的输出概率,而Skip-gram则于基于当前词汇  预测与之最相近的上下文词汇。
预测与之最相近的上下文词汇。
由于包括原文作者在内,都认为Skip-gram的效果要好于CBOW,因而本文接下来以Skip-gram为例来深入剖析Word2vec的训练过程。
2.1 Word2vec(Skip-gram)的训练过程
不同于之前的CTR预估模型是预测Item的点击概率,Word2vec模型的优化目标是所有样本条件概率的最大化。
在理解Word2vec的优化目标之前,需要先理解一下Word2vec的样本构造。
Word2vec的一组训练样本,由目标词及其上下滑窗c个词汇构成。而对所有的目标词都做此操作,便可得到全部训练集。
而具体到某一组训练样本上,考虑目标词语上下文词之间最为“相似”,那么优化目标可以公式化为:
同理,对于所有样本空间Word2vec的目标函数则可表达如下:
最后套用常用的极大似然估计法,便得出Word2vec的最终目标函数:
而其中的  作者采用的是softmax函数。这个也很好理解,将其看作是多分类任务求解。
作者采用的是softmax函数。这个也很好理解,将其看作是多分类任务求解。
- 其中的
 代表的输出词
代表的输出词  ,
,  代表的是输入词
代表的是输入词  。
。
讲到这里,Word2vec的目标函数说的差不多了。那问题来了,Embedding是怎么生成的呢?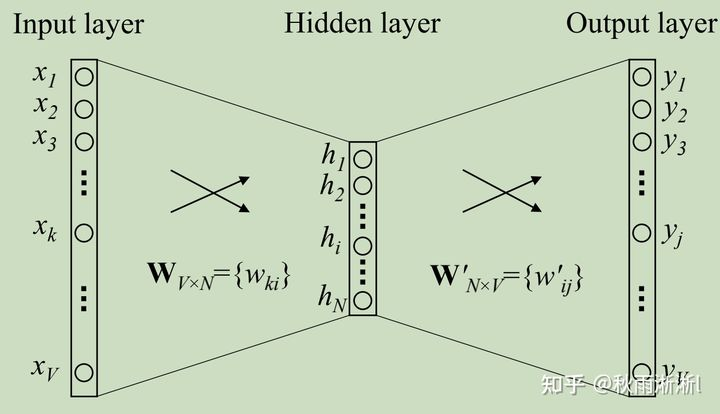
图2 Word2vec的网络化表示(仅考虑一组训练样本)
借用图2可以比较直观的得到答案。
如图2,Word2vec的输入层是训练集单词的One-hot表示,此时Input layer到Hidden layer层的输入向量可以由  表示(其中的V表示词袋长度),Hidden layer到Output layer的输出向量则可以由
表示(其中的V表示词袋长度),Hidden layer到Output layer的输出向量则可以由  表示。
表示。
而这其中的  则正是我们常说的Embedding向量了。实际上,输出向量矩阵实际上也可以看作是每个词汇的Embedding,只不过不是一个通用的做法。
则正是我们常说的Embedding向量了。实际上,输出向量矩阵实际上也可以看作是每个词汇的Embedding,只不过不是一个通用的做法。
最后,可以指出的是模型参数的求解通常用梯度下降。
2.2 Word2vec的负采样训练方法
Word2vec的负采样(Negative Samping)是一种用于加速Word2vec训练的方法,不做负采样直接按2.1介绍的方法训练成本会高到难以接受,原因如下:
考虑待训练的语料库有10000个单词,则Word2vec对应的输出神经元也将有10000个。那么每次计算Hidden layer到Output layer都需要计算字典中所有10000个词汇预测误差,而这个操作计算量是极大的(实际数据中输出神经元数远大于本文举的case)。
那Word2vec的负采样的原理是什么呢?其是通过采样相对原样本中很少的一部分样本来计算预测误差。由于负采样集合非常的小(实际中通常小于10),因此可以大大的加快模型的收敛速度。
除了负采样外,常用的加快Word2vec训练速度的方法还有Hierarchicak softmax(层级softmax),不过其实现较为复杂,同时效果没有明显优于负采样,实际训练中应用较少。
具体到Word2vec的负采样训练细节,参考Yoav Goldberg 和 Omer Levy的 Negative-Sampling Word-Embedding Method一文可推导如下:
首先是正负样本概率计算的定义:
假设有pair(c|w),其中w为中心词为w,c为上下文词。
那么正样本概率可定义为:  ;
;
负样本可定义为:  ;
;
其中, 的计算方法如(2-5)(原文中说是参考softmax函数得出,但这个形式应该是sigmoid):
的计算方法如(2-5)(原文中说是参考softmax函数得出,但这个形式应该是sigmoid):
那么,基于极大似然的思想,负采样情况下的优化目标函数可定义为式(2-6):

其中,(2-6)和(2-7)中的集合D为正样本集,对应的  为负样本集。
为负样本集。
在(2-7)的基础上求对数,进而引入对数极大似然,可得(2-8):
此时,将(2-5)代入(2-8)可得:
在(2-9)的基础上进一步化简可得:
最后,令  ,则(2-10)可以进一步简化为:
,则(2-10)可以进一步简化为:
而(2-11)的结果,则是我们常看的word2vec负采样优化目标函数,非常的简洁。
3. Embedding在推荐系统的应用举例—Item2vec
基于Word2vec可以从词的“序列”学到词的低维稠密向量表达,进而得到词之间的相似度。那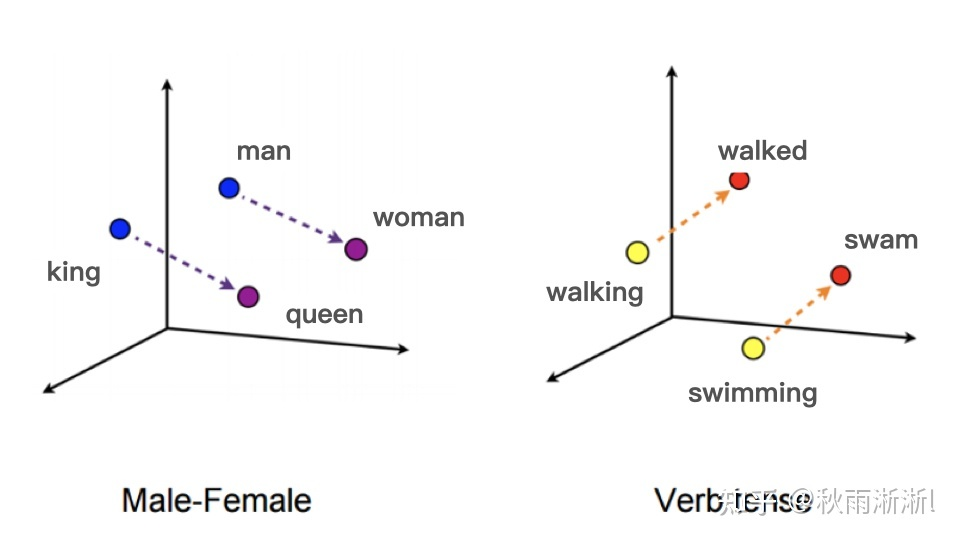
图3 词向量例子(图片源于深度学习推荐系统实战)
么,是否也可以基于用户的点击、加购、下单等“序列”得到商品的Embedding呢?
答案当然是肯定的。2015年微软便提出了基于物品Embedding的向量方法Item2vec。而Item2vec与Word2vec的原理极为相似,唯一不同是Item2vec摒弃了时间窗口这个概念,认为序列中的商品两两相关。
Item2vec的优化目标如下:
式中的  代表的是用户行为序列长度,
代表的是用户行为序列长度,  代表序列中的具体商品。
代表序列中的具体商品。
图4 不同场景下的序列数据(图片源于深度学习推荐系统实战)
另外,值得一提的是,常见的物品Embedding方法除了微软提出的Item2vec外,业界非常知名的双塔模型也可以看作成为Item2vec。不过关于双塔模型的举例我们在这里暂时不做展开。
4. Item2vec的PySpark实现
4.1 数据集介绍
下列代码数据集来源于MovieLens,数据结构如图: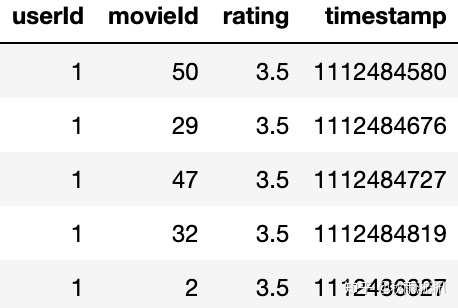
图5 数据结构
基于2、3小结的讨论,我们很容易知道每一组训练样本可以按是由userId按时间排序后的movieId聚合序列。比如对于图5的case,我们可以得到如下序列:[50, 29, 47, 32, 2]。
4.2 Item2vec pySpark代码实现
import osfrom pyspark import SparkConffrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import *from pyspark.sql.types import *from pyspark.ml.feature import BucketedRandomProjectionLSHfrom pyspark.mllib.feature import Word2Vecfrom pyspark.ml.linalg import Vectorsimport randomfrom collections import defaultdictimport numpy as npfrom pyspark.sql import functions as Fclass UdfFunction:@staticmethoddef sortF(movie_list, timestamp_list):"""sort by time and return the corresponding movie sequenceeg:input: movie_list:[1,2,3]timestamp_list:[1112486027,1212546032,1012486033]return [3,1,2]"""pairs = []for m, t in zip(movie_list, timestamp_list):pairs.append((m, t))# sort by timepairs = sorted(pairs, key=lambda x: x[1])return [x[0] for x in pairs]def processItemSequence(spark, rawSampleDataPath):"""describe:生成训练序列结合"""# rating dataratingSamples = spark.read.format("csv").option("header", "true").load(rawSampleDataPath)# ratingSamples.show(5)# ratingSamples.printSchema()sortUdf = udf(UdfFunction.sortF, ArrayType(StringType()))userSeq = ratingSamples \.where(F.col("rating") >= 3.5) \.groupBy("userId") \.agg(sortUdf(F.collect_list("movieId"), F.collect_list("timestamp")).alias('movieIds')) \.withColumn("movieIdStr", array_join(F.col("movieIds"), " "))# userSeq.select("userId", "movieIdStr").show(10, truncate = False)return userSeq.select('movieIdStr').rdd.map(lambda x: x[0].split(' '))def embeddingLSH(spark, movieEmbMap):"""describe:局部敏感哈希实现和case举例计算"""movieEmbSeq = []for key, embedding_list in movieEmbMap.items():embedding_list = [np.float64(embedding) for embedding in embedding_list]movieEmbSeq.append((key, Vectors.dense(embedding_list)))movieEmbDF = spark.createDataFrame(movieEmbSeq).toDF("movieId", "emb")bucketProjectionLSH = BucketedRandomProjectionLSH(inputCol="emb", outputCol="bucketId", bucketLength=0.1,numHashTables=3)bucketModel = bucketProjectionLSH.fit(movieEmbDF)embBucketResult = bucketModel.transform(movieEmbDF)print("movieId, emb, bucketId schema:")embBucketResult.printSchema()print("movieId, emb, bucketId data result:")embBucketResult.show(10, truncate=False)print("Approximately searching for 5 nearest neighbors of the sample embedding:")sampleEmb = Vectors.dense(0.795, 0.583, 1.120, 0.850, 0.174, -0.839, -0.0633, 0.249, 0.673, -0.237)bucketModel.approxNearestNeighbors(movieEmbDF, sampleEmb, 5).show(truncate=False)def trainItem2vec(spark, samples, embLength, embOutputPath):"""describe:Item2vec训练"""word2vec = Word2Vec().setVectorSize(embLength).setWindowSize(5).setNumIterations(10)model = word2vec.fit(samples)synonyms = model.findSynonyms("158", 20)for synonym, cosineSimilarity in synonyms:print(synonym, cosineSimilarity)embOutputDir = '/'.join(embOutputPath.split('/')[:-1])if not os.path.exists(embOutputDir):os.makedirs(embOutputDir)with open(embOutputPath, 'w') as f:for movie_id in model.getVectors():vectors = " ".join([str(emb) for emb in model.getVectors()[movie_id]])f.write(movie_id + ":" + vectors + "\n")embeddingLSH(spark, model.getVectors())return modelif __name__ == '__main__':conf = SparkConf().setAppName('ctrModel').setMaster('local')spark = SparkSession.builder.config(conf=conf).getOrCreate()file_path = 'file:///Users/klook/opt/app/SparrowRecSys/src/main/resources'rawSampleDataPath = file_path + "/webroot/sampledata/ratings.csv"samples = processItemSequence(spark, rawSampleDataPath)embLength = 10model = trainItem2vec(spark, samples, embLength,embOutputPath=file_path[7:] + "hubery/webroot/modeldata2/item2vecEmb.csv")
当然,上文只是提供一个可运行代码和基于局部敏感哈希计算商品最近邻的demo,并没有具体分析最近demo是否有效。这么做的主要原因是MovieLens的数据还是具备一定的理解成本的,计算出case后并不太好说明其有效性。大家感兴趣完成可以尝试使用自己熟悉的业务数据来构造序列,然后再看看计算出的最近邻是否符合数据的业务场景。
注:代码源于深度学习推荐系统实战
5. 结束语
本文首先介绍了embedding的概念和Word2vec实现原理,紧接着介绍了Word2vec在推荐系统中最简单的应用Item2vec及其pySpark实现。
不过Item2vec的局限性还是比较明显的,比如不擅长处理网络化数据。因此,下文将复习一下Graph Embedding,来看看DeepWalk,Node2vec以及阿里的EGES是怎么解决这个问题的。
参考文献
1.Tomas, Mikolov, et al. Efficient Estimation of Word Representations in Vector Space.2013.
2.Mikolov, Tomas, et al. Distributed Representations of Words and Phrases and their Compositionality 2013.
3.Xin, Rong. word2vec Parameter Learning Explained 2014
4.《深度学习推荐系统》—王喆
5.《深度学习推荐系统实战》—王喆
6.Yoav Goldberg and Omer Levy. word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
B-2.Graph Embedding技术学习 | 从DeepWalk到Node2vec、EGES | 附DeepWalk PySpark实现
0. 背景
上篇文章我们学习什么是Embedding,以及其经典生成方法Word2vec与在搜广推中最简单的应用Item2vec。在文章的末尾我们指出,基于Word2vec的Embedding技术本质上是基于文本、用户行为的“序列”建模范式。但在搜广推和互联网领域的实际应用中,“object”与“object”存在大量呈现图结构的数据关系,而Word2vec无法直接学习到这类数据的Embedding。
图1 图结构数据由多节点和多边组成
在这样的背景下,作为图结构数据Embedding技术总称的Graph Embedding成了当时的研究热点。而本文接下来也将对Graph Embedding中展开学习,并对搜广推领域中代表性应用的DeepWalk、Node2vec、EGES展开详细的讨论。
本文接下的安排如下:
- 第一章:DeepWalk原理分析
- 第二章:Node2vec原理与应用举例
- 同质性与结构性怎么理解?
- BFS与DFS谁决定同质性?
- BFS与DFS实现细节
- Node2vec应用举例—微信广告是怎么用好Node2ec同质性的?
- 第三章:EGES原理分析
- 冷启动问题与Side information理解
- EGES怎么做多Embedding 融合?
- EGES效果分析
- 第四章:DeepWalkPySpark实现。
1. DeepWalk原理
DeepWalk是美国石溪大学的Bryan Perozzi等人于2014发布的经典Graph Embedding方法。其核心思想是基于图结构数据做随机游走采样,然后把得到的序列数据集给到Word2vec学习,从而得到“object”的Embedding向量。
借用阿里EGES原文Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba中非常经典的图,如图2,我们可以具体的把DeepWalk的算法流程总结如下: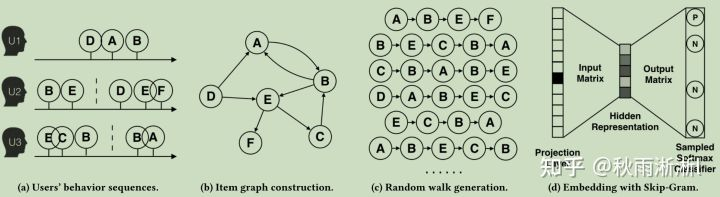
图2 DeepWalk算法流程&lt;图源于阿里EGES论文,假设用户行为是对商品的点击&gt;
(1)图2(a)为用户U1、U2、U3的行为序列,是Word2vec可以直接学习的序列结构。
(2)图2(b)为基于图2(a)得出物品点击关系图。可以看到的是商品为节点,有向边(出边)是指被连接商品在点击上有先后关系。比如基于用户U1,可以得出D—>A—>B的点击序列,而加上用户U2,则可得出一组新有向序列B—>E与D—>E—>F。
(3)图2(c)则是基于图2(b)沿着有向边的方向,随机游走得出的物品点击序列。仔细查看图2(c)可以看到的是,通过随机游走可以生成很多不直接存在于图2(a)的点击序列,比如A—>B—>E—>F序列和B—>E—>C—>B—>A。
(4)图2(d)则是基于图2(c)的商品点击序列和Skip-Gram 方式得到的商品Embedding过程。
通过分析DeepWalk的实现过程,可以发现DeepWalk实际上只做了一个物品点击关系图构建和有向随机采样工作,并没有很大的算法创新。而对于有向随机采样,DeepWalk则是通过定义两个几节点的跳转概率进行调控的,如公式(2-1)。
公式(2-1)中,  分布代表当前节点和下一节点,
分布代表当前节点和下一节点,  代表的则是
代表的则是  作为
作为  出边的频次。
出边的频次。
因此,DeepWalk可以同时设置合适的跳转概率,来保证采样序列的质量。同时在实际使用中,还会设置一个采用长度,用以控制采样序列的最大长度。
2. Node2vec原理与应用举例
Node2vec是斯坦福大学的Aditya Grover于2016年发布的另一个经典的Graph Embedding方法,其核心是思想是基于DeepWalk基础上,提出了一套随机游走权重调节方法,来学习网络结构中的同质性(homophily)与结构性(structure equivalence )。
2.1 同质性与结构性怎么理解?
在探讨Node2vec如何学习同质性与结构性之前,很有必要先对这两个概念进行阐述一下。
借用Node2vec原文图3和是原文Introduction 部分(见Present work前一段落),同质性可以理解为在位置上(Embedding)上更为相近的点,如图3中的  节点与
节点与  。而结构性则体现为在结构组成上更为相近的点,如图3中的
。而结构性则体现为在结构组成上更为相近的点,如图3中的  与
与  。
。
不过这个描述还是比较抽象的,我们不妨再来理解一下腾讯新闻团队给出的例子:
同质性:社会类的内容召回同为社会类或时事类、政治类的内容,因为它们在图结构中更可能同属一个大簇。( 节点与
节点与  )
)
结构性:社会类的热点新闻会召回娱乐类的热点新闻,因为它们在图结构中的角色是相近的,都是一个簇的中心。(  与
与  )
)
而关于同质性与结构性,Node2vec在则是通过控制游走倾向时是以深度优先(Deep-First Search, DFS)还是广度优先(Breadth-First Search, BFS)来实现的。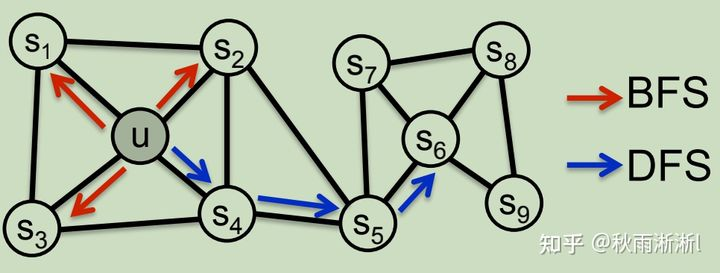
图3 Node2vec BFS与DFS游走示意图
具体的来说,DFS会使得节点游走到离中心点更远的节点上,如U—>  ,从而得到序列
,从而得到序列 ,而BFS生成的序列则是围绕着中心点U的点,如
,而BFS生成的序列则是围绕着中心点U的点,如  。
。
那问题来了,是DFS的游走方式可以学到同质性还是BFS?
2.2 BFS与DFS谁决定同质性?
第一次接触Node2vec的时候,这个问题在一度让我非常的迷惑。当时拍脑袋得出的结论是,DFS学习到的是结构性,BFS学习到的是同质性。一点解释的原因是,同质性的节点位置相近,而BFS的采样序列正是其相近节点。
但实际上并非如此,结论恰恰相反,这让我感到很反直觉。
关于这个问题的答案,Node2vec作者明确在原文3.1小结指出,BFS 由于可以对微观视角(Microscopic View)的结构进行更清楚的探索,所以更能捕捉图的结构信息。相比之下,DFS 则更可以在局部图中探索宏观视角(Marco-view)的信息,所以更能捕捉图在一个大社区下的节点之间的同质性信息。
为此作者也给出了他们的验结果,如图4 左图是作者给出的DFS结果,可以看相同颜色的点在位置上比较集中。右图则是BFS的结果,表现为结构上相同的点颜色(如蓝色节点)相同。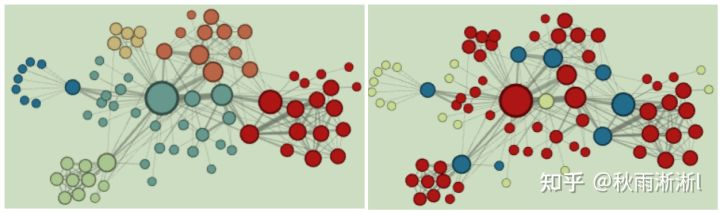
图4 Node2vec实验结果(图片来自Node2vec原文)
但如果不结合实验结果,单纯的来理解作者的解释,我觉得非常的抽象,主要是反直觉。事实上作者的解释似乎让很多同行都感到难以理解,因此网上也一直有很多人在探讨,这里给一篇分析的比较好的文章,感兴趣的同学可以去围观。同时在查阅资料的过程中,我发现DFS学习到同质性,BFS学习到结构性这个结论是有较多数据案例支撑的,比如上文提到的腾讯看点团队、知乎算法团队负责人孙付伟以及下文要讲到的微信广告算法团队都表示在大量的数据和实验后,得到的结论都是DFS学习到同质性,BFS学习到结构性。
不得不出说的是,这个例子让我又一次对实践出真知这个道理有了新的认识。
2.3 BFS与DFS实现细节
如第二章开头所言,Node2vec是调节跳转权重来实现的,可以由式(2-2)来表示:
其中的  是指节点
是指节点  到节点
到节点  的跳转权重,由第一章公式(2-1)可知这个权重是个定值,其中的
的跳转权重,由第一章公式(2-1)可知这个权重是个定值,其中的  则指的是节点
则指的是节点  跳转到 一阶距离点
跳转到 一阶距离点 和二阶距离点的转移参数。
和二阶距离点的转移参数。
可以指出的是  中的
中的  称为返回参数(return parameter)和
称为返回参数(return parameter)和  则称为进出参数(in-out parameter),并且是由它们决定Node2vec是BFS和DFS。同时基于图5,
则称为进出参数(in-out parameter),并且是由它们决定Node2vec是BFS和DFS。同时基于图5,  可以表示为公式(2-3):
可以表示为公式(2-3):
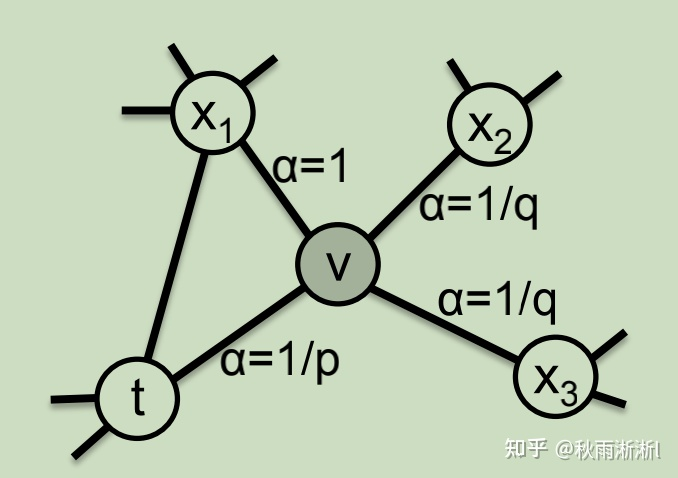
图5 Node2vec节点跳转概率图
于是结合公式(2-2)和公式(2-3)我们可以得出的结论是:只要把  设的越小,
设的越小,  设的越大,
设的越大,  值则越大,
值则越大,  就越大,那么Node2vec则更倾向于在当前节点的附近进行采样,也即BFS和结构性,反之则是DFS和同质性。
就越大,那么Node2vec则更倾向于在当前节点的附近进行采样,也即BFS和结构性,反之则是DFS和同质性。
2.4 Node2vec应用举例—微信广告是怎么用好Node2ec同质性的?
本章前三小结中,我们分析了Node2vec的原理和实现细节,并对其同质性和结构性进行了详细的探讨,在本章末尾我们再以Node2vec在微信朋友圈广告(以下简称微信广告)场景应用为例,来看看它的效果。
微信作为国内最大的社交网络平台,其好友关系及其交互网络天然便是网络化的,而这正好是Node2vec擅长的领域。具体到2017年微信广告建模策略,根据微信社交lookalike负责人易玲玲的公开分享可以知道,其策略方具体如下:
广告主会提供他已有的客户名单作为种子用户,这是机器学习的正样本,然后会从活跃用户里面(非种子用户)或者历史我们已经积累了相似的广告负反馈的用户,作为负样本,训练一个二分类的模型,利用模型结果对这个用户进行打分排序,取出广告主需要的目标数据的用户。
图6 微信广告投放策略图
从上述引文我们可以读出的是,微信广告的核心思想是基于正负样本二分类建模,预测广告主目标数据的相似用户。
那除去数据网络化外,Node2vec适合微信广告更具体的原因是什么呢,Node2vec又是怎么找到相似用户的呢?参考易玲玲的演讲可整理如下:
- 社交关系数据里面有两个核心的价值,分别是社交同质性和社交影响力。
- 其中的社交同质性是指相似性,即我和我的好友可能有相似的兴趣。
- 社交影响力则是:我可能被我的某些好友与朋友圈广告的互动行为所影响。
- 社交同质性这个特征可以基于Node2vec可控(BFS or DFS)。
- 社交同质性、影响力基于Node2vec可量化(embedding Similarity),可以解决亲人,闺蜜,同学,同事,陌生人的相似权重排序问题。
- 对于好友沟通网络,沟通次数多的好友,更容易被随机采样。
- 对于事务沟通网络,因为我跟事务型好友没有形成社交圈,在做embedding的时候, 产生序列的邻居共现次数比小
- 综上,Node2vec 模型比较好地结合了当时微信朋友圈广告推送的业务场景和业务数据。
最后演讲中指出,基于Node2vec的Looklike算法相比直接的二分类模型有2倍-3倍的lift值提升(lift值为其预估指标)。
图7 基于Node2vec的Looklike算法结构图
图8 基于Node2vec的Looklike算法实验效果
3. EGES原理—阿里冷启动解决方案大杀器
EGES( Enhanced Graph Embedding with Side information )是阿里巴巴与2018年发布的一种Graph Embedding算法,当时被大规模应用于手淘推荐召回当中,核心亮点是在DeepWalk的基础上引入side information来解决冷启动问题,同时也可以加强Embedding的表达能力。
3.1 冷启动问题与Side information理解
我们都知道,无论是阿里巴巴还是其它互联网公司,都存在着大规模的数据稀疏问题。以商品Embedding化为例,如果一个商品是新上架活动或者与用户的交互非常少,那么基于Word2vec等方法则无法为其学到一个比较好的Embedding向量。而这种缺乏足够的交互行为导致商品无法Embedding化、不能较好的进行召回或进行推荐等情况被称为冷启动问题。
就Embedding而言,DeepWalk虽然可以通过多次随机游走解决增加训练样本,但架不住商品行为数据的极度稀疏。为了给这些长尾活动“合理”的一个初始Embedding,阿里巴巴团队提出了引入商品补充信息的方法来解决这个问题。而商品的补充信息可以是店铺、品牌、价格、类目等商品画像信息,这些补充信息在论文中被称为Side information,也是 EGES(Enhanced Graph Embedding with Side Information)名字的由来。
3.2 EGES的训练—怎么做多Embedding 融合
关于EGES怎么训练的问题中,首当其冲的是Side Information怎么输入和训练的问题。而关于这个问题,我们可以基于EGES模型图来回答。
如图9所示,作者假设基于商品行为序列生成原生Embedding由输入  表示,而对于的
表示,而对于的  种不同的side information输入则为
种不同的side information输入则为  到
到  。那么在得到商品原生的Embedding和Side Embedding后,剩下的问题便怎么融合商品的多个Embedding了。
。那么在得到商品原生的Embedding和Side Embedding后,剩下的问题便怎么融合商品的多个Embedding了。
最简单的Embedding融合方法当然是平均池化,这也是原文作者最初的做法。其中对商品  ,基于平均池化后的Embedding可以表达如下公式(2-3):
,基于平均池化后的Embedding可以表达如下公式(2-3):
但很显然平均池化不会是一个好的解决方案,因为它对所有的Embedding一视同仁,会损失大量有效信息。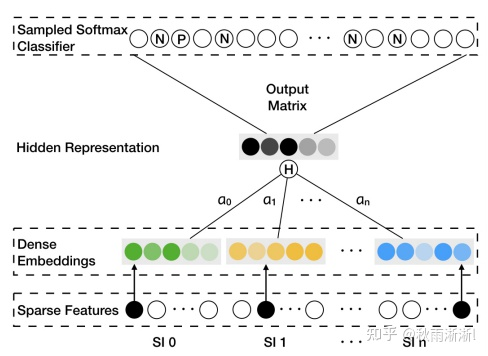
图9 EGES算法架构图(图源于EGES原文)
如原文中举出的例子,对于iphone手机等电子产品,商品的品牌information可能更重要,而在衣帽等商品中,价格可能是用户更为敏感的side information。因此在聚合过程中,对于不同的side information 赋予不同的权重是可能带来效果提升的。
为了证实这个观点,作者也给出了另一种融合方案,论文中这个权重作者用  来进行表示,对应带权重的Embedding聚合公式则如(2-4)所示:
来进行表示,对应带权重的Embedding聚合公式则如(2-4)所示:
其中,对于(2-4)中的权重为什么要用  而不是
而不是  ,作者在原文中也有解释。其一是使得聚合权重大于0;其二是对权重值做了归一化。
,作者在原文中也有解释。其一是使得聚合权重大于0;其二是对权重值做了归一化。
需要指出的是,式(2-4)的融合方式也正是EGES的最终形态。
3.3 EGES效果分析
理解EGES的原理后,可以发现其在算法上没有复杂的创新,仅仅只是引入了更多的Side Information 来指导商品的Embedding化,那么它的效果如何?
如图10,从原文给出EGES和DeepWalk(BGE)及平均池化(GES)在阿里7天的线上AB实验上有着显著的提升。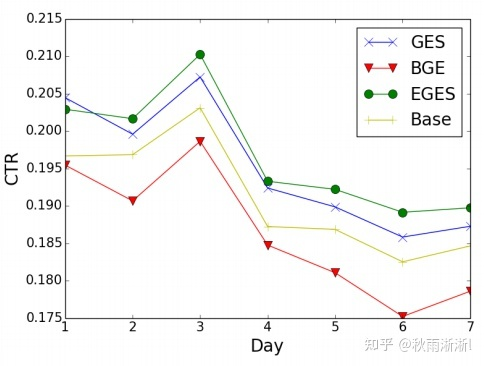
图10 EGES在7天AB实验CTR表现(图源于EGES原文)
另外,论文也给出了冷启动召回的case。如图11,可以看到对于一个新上架的活动,基于EGES学习后,基于Embedding召回的活动在类目(cate)、价格好和品牌上都具备很好的解释性。
图11 冷启动活动召回举例(图源于EGES原文)
最后,在聚合权重上,论文给出了三个我觉得特别有意思结论,它们分别是:
- 不同Side information 的聚合权重不同。
- 原生Embedding的权重最大(非常make sense,商品维度基于行为信息训练,粒度更细)。
- 除了原生Embedding之外,“商铺”的聚合权重最高。(符合淘宝用户购物习惯,因为在同一商家购物会更方便和便宜,考虑同店铺商品对比和凑单)
4. DeepWalk PySpark实现
如2、3、4章分析,Node2vec和EGES在某值意义上都是DeepWalk的变质,了解DeepWalk的实现则基本具备Node2vec和EGES 实现能力,因此本文给出一个可行的DeepWalk PySpark实现如下。4.1 数据集介绍
下列代码数据集来源于MovieLens,数据结构如图: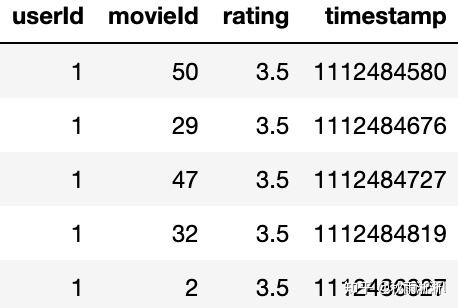
图12 数据结构4.2 DeepWalk pySpark代码实现
```python import os from pyspark import SparkConf from pyspark.sql import SparkSession from pyspark.sql.functions import from pyspark.sql.types import from pyspark.ml.feature import BucketedRandomProjectionLSH from pyspark.mllib.feature import Word2Vec from pyspark.ml.linalg import Vectors import random from collections import defaultdict import numpy as np from pyspark.sql import functions as F
class UdfFunction: @staticmethod def sortF(movie_list, timestamp_list): “”” sort by time and return the corresponding movie sequence eg: input: movie_list:[1,2,3] timestamp_list:[1112486027,1212546032,1012486033] return [3,1,2] “”” pairs = [] for m, t in zip(movie_list, timestamp_list): pairs.append((m, t))
# sort by timepairs = sorted(pairs, key=lambda x: x[1])return [x[0] for x in pairs]
def processItemSequence(spark, rawSampleDataPath): “”” describe:生成训练序列结合 “””
# rating dataratingSamples = spark.read.format("csv").option("header", "true").load(rawSampleDataPath)# ratingSamples.show(5)# ratingSamples.printSchema()sortUdf = udf(UdfFunction.sortF, ArrayType(StringType()))userSeq = ratingSamples \.where(F.col("rating") >= 3.5) \.groupBy("userId") \.agg(sortUdf(F.collect_list("movieId"), F.collect_list("timestamp")).alias('movieIds')) \.withColumn("movieIdStr", array_join(F.col("movieIds"), " "))# userSeq.select("userId", "movieIdStr").show(10, truncate = False)return userSeq.select('movieIdStr').rdd.map(lambda x: x[0].split(' '))
def embeddingLSH(spark, movieEmbMap): “”” describe:局部敏感哈希实现和case举例计算 “”” movieEmbSeq = [] for key, embedding_list in movieEmbMap.items(): embedding_list = [np.float64(embedding) for embedding in embedding_list] movieEmbSeq.append((key, Vectors.dense(embedding_list))) movieEmbDF = spark.createDataFrame(movieEmbSeq).toDF(“movieId”, “emb”) bucketProjectionLSH = BucketedRandomProjectionLSH(inputCol=”emb”, outputCol=”bucketId”, bucketLength=0.1, numHashTables=3) bucketModel = bucketProjectionLSH.fit(movieEmbDF) embBucketResult = bucketModel.transform(movieEmbDF) print(“movieId, emb, bucketId schema:”) embBucketResult.printSchema() print(“movieId, emb, bucketId data result:”) embBucketResult.show(10, truncate=False) print(“Approximately searching for 5 nearest neighbors of the sample embedding:”) sampleEmb = Vectors.dense(0.795, 0.583, 1.120, 0.850, 0.174, -0.839, -0.0633, 0.249, 0.673, -0.237) bucketModel.approxNearestNeighbors(movieEmbDF, sampleEmb, 5).show(truncate=False)
def trainItem2vec(spark, samples, embLength, embOutputPath): “”” describe:Item2vec训练 “”” word2vec = Word2Vec().setVectorSize(embLength).setWindowSize(5).setNumIterations(10) model = word2vec.fit(samples) synonyms = model.findSynonyms(“158”, 20) for synonym, cosineSimilarity in synonyms: print(synonym, cosineSimilarity) embOutputDir = ‘/‘.join(embOutputPath.split(‘/‘)[:-1]) if not os.path.exists(embOutputDir): os.makedirs(embOutputDir) with open(embOutputPath, ‘w’) as f: for movie_id in model.getVectors(): vectors = “ “.join([str(emb) for emb in model.getVectors()[movie_id]]) f.write(movie_id + “:” + vectors + “\n”) embeddingLSH(spark, model.getVectors()) return model
def generate_pair(x):
# eg:# watch sequence:['858', '50', '593', '457']# return:[['858', '50'],['50', '593'],['593', '457']]pairSeq = []previousItem = ''for item in x:if not previousItem:previousItem = itemelse:pairSeq.append((previousItem, item))previousItem = itemreturn pairSeq
def generateTransitionMatrix(samples): “”” describe:生成活动转移矩阵,等价于公式(2-1)计算过程 “”” pairSamples = samples.flatMap(lambda x: generate_pair(x)) pairCountMap = pairSamples.countByValue() pairTotalCount = 0 transitionCountMatrix = defaultdict(dict) itemCountMap = defaultdict(int) for key, cnt in pairCountMap.items(): key1, key2 = key transitionCountMatrix[key1][key2] = cnt itemCountMap[key1] += cnt pairTotalCount += cnt transitionMatrix = defaultdict(dict) itemDistribution = defaultdict(dict) for key1, transitionMap in transitionCountMatrix.items(): for key2, cnt in transitionMap.items(): transitionMatrix[key1][key2] = transitionCountMatrix[key1][key2] / itemCountMap[key1] for itemid, cnt in itemCountMap.items(): itemDistribution[itemid] = cnt / pairTotalCount return transitionMatrix, itemDistribution
def oneRandomWalk(transitionMatrix, itemDistribution, sampleLength): “”” describe:基于随机采样长度和条件概率矩阵,生成采样序列 “”” sample = []
# pick the first elementrandomDouble = random.random()firstItem = ""accumulateProb = 0.0for item, prob in itemDistribution.items():accumulateProb += probif accumulateProb >= randomDouble:firstItem = itembreaksample.append(firstItem)curElement = firstItemi = 1while i < sampleLength:if (curElement not in itemDistribution) or (curElement not in transitionMatrix):breakprobDistribution = transitionMatrix[curElement]randomDouble = random.random()accumulateProb = 0.0for item, prob in probDistribution.items():accumulateProb += probif accumulateProb >= randomDouble:curElement = itembreaksample.append(curElement)i += 1return sample
def randomWalk(transitionMatrix, itemDistribution, sampleCount, sampleLength): “”” describe:基于随机采样长度和条件概率矩阵,生成采样序列 “”” samples = [] for i in range(sampleCount): samples.append(oneRandomWalk(transitionMatrix, itemDistribution, sampleLength)) return samples
def graphEmb(samples, spark, embLength, embOutputFilename): “”” describe:deepwalk训练 “”” transitionMatrix, itemDistribution = generateTransitionMatrix(samples) sampleCount = 20000 sampleLength = 10 newSamples = randomWalk(transitionMatrix, itemDistribution, sampleCount, sampleLength) rddSamples = spark.sparkContext.parallelize(newSamples) trainItem2vec(spark, rddSamples, embLength, embOutputFilename)
if name == ‘main‘: conf = SparkConf().setAppName(‘ctrModel’).setMaster(‘local’) spark = SparkSession.builder.config(conf=conf).getOrCreate() file_path = ‘file:///Users/klook/opt/app/SparrowRecSys/src/main/resources’ rawSampleDataPath = file_path + “/webroot/sampledata/ratings.csv” samples = processItemSequence(spark, rawSampleDataPath) embLength = 10 graphEmb(samples, spark, embLength, embOutputFilename=file_path[7:] + “hubery/webroot/modeldata2/itemGraphEmb.csv”) ``` 注:代码源于深度学习推荐系统实战
5. 结束语
本文回顾了Graph Embedding 中非常经典的DeepWalk、Node2vec以及阿里EGES,在探讨它们各自的原理之外,我们还给出了DeepWalk的PySpark实现与Node2vec的应用举例。
可以看到的是,DeepWalk对比Item2vec、Node2vec对比DeepWalk以及EGES对比DeepWalk有差异性,但不大。比如DeepWalk只是在Item2vec的实现上加了一个随机游走;Node2vec则只是DeepWalk的基础上设置了两个跳转时参数,以控制其游走倾向,从学到同质性或者结构性;EGES则更多的是DeepWalk的工程应用,比起DeepWalk更多的是考虑怎么解决冷启动问题,以及给出了一个有效的多Embedding融合方案。
尽管如此,这些并没有妨碍DeepWalk、Node2vec以及EGES成为有效且经典的Graph Embedding 解决方案。从这里我也有了一结论,那就是只有优化思路对了,看似小的模型改动也能带来巨大的业务提升。当然,这里的思路主要是值基于业务数据场景和业务数据特性的深度理解得出(如微信广告社交化特性,阿里手淘冷启动问题)。
参考文献
- DeepWalk: Online Learning of Social Representations
- node2vec: Scalable Feature Learning for Networks
- EGES | Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
- 当机器学习遇上复杂网络:解析微信朋友圈 Lookalike 算法
- 知乎算法团队负责人孙付伟:Graph Embedding在知乎的应用实践
- 主流图嵌入模型的原理和应用 - 极术社区 - 连接 AIoT 开发者与生态服务
- 《深度学习推荐系统实战》—王喆
B-3.主流深度推荐模型演化(上)|从Deep Crossing到Wide&Deep、DeepFM | 附模型TensorFlow代码实现
0. 背景
经过前面七篇文章的铺垫,是到了谈深度推荐模型的时候了。
在今天这个时间节点上,我们都知道深度学习是推荐算法中的主旋律。但这个主旋律是怎么刮起来的呢?它形成的前提条件是什么?为什么会是始于2016并在2018年开始呈井喷状态?为什么在几年的时间完胜了传统模型?
我相信无论是对于刚接触深度推荐模型的人,还是深度推荐模型的老兵,了解主流推荐模型的演化和理清楚上述问题都是十分必要。正如高更传世名画中说表达的”我们从哪里来?我们是谁?我们向何处去?“,了解推荐模型从哪里来,现在的应用状况,以及未来的发展脉络是极具思考价值的。
图1 高更名作《我们从哪里来?我们是谁?我们向何处去?》
关于深度推荐模型从何处来这个问题,可以对照图2的浅层推荐模型演化关系图。如果对图中所指模型的实现细节有所疑问,也可以翻阅笔者之前的学习笔记—前深度学习时代—推荐模型演化路径梳理。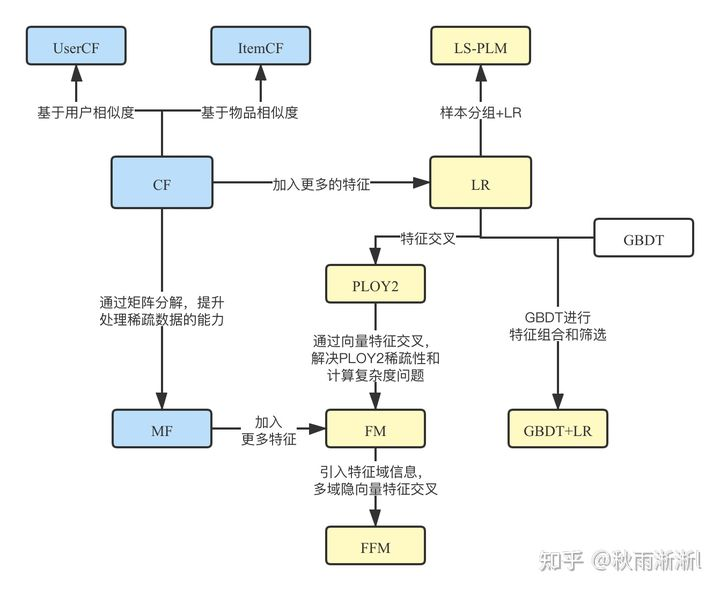
图2 传统推荐模型的演化关系图(图片参考王喆《深度学习推荐系统》一书)
而关于深度推荐模型现在的应用状况可以参考图3。在深度推荐时代你方唱罢我登场的情形下,模型层出不穷,乃至眼花缭乱,如何在众多模型抓住时代发展脉络,显得难得可贵。下图3是近两年网上流程很广的一张深度推荐模型演义图,笔者在原图的基础上加上了阿里的MIMN和SIM。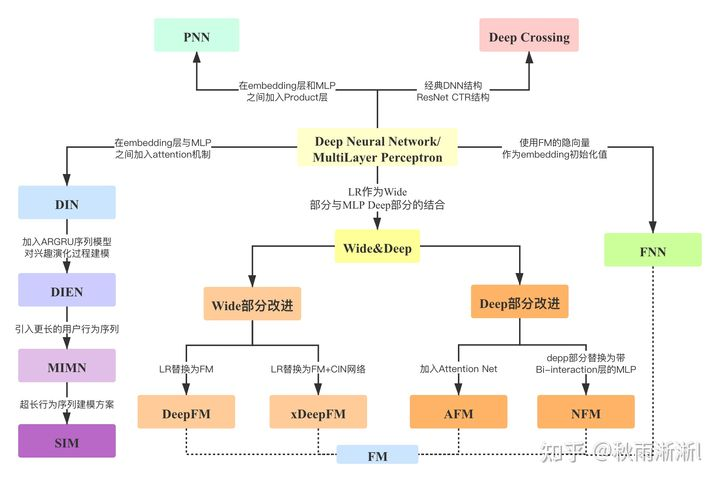
图3 经典深度推荐模型演化图谱(图片参考王喆《深度学习推荐系统》一书)
如图3所示,深度推荐模型以深度学习中的多层感知机(MultiLayer Perceptron)为核心,演化出了Deep Crossing/Wide&Deep/DeepFM/DIN等多个经典模型。看似种类繁多,但实际上可以用两种建模范式来进行概括(以下引文参考阿里妈妈精排前算法总监朱小强,觉得总结不当的欢迎指出)。
其一是”代数式先验建模“;本质是是基于先验认识,通过模型的结构设计捕捉特征之间的”代数关系“,模型代表有Deep Crossing/Wide&Deep/DeepFM,也即上图3中,除去DIN一族的其它模型。
其二是“物理式先验建模”;本质是对“用户兴趣”这个物理概念进行的数学化解析,进而生成不同的模型,模型代表有DIN/DIEN/MIMN/SIM一族。
顺着上述描述,本文接下来将对”代数式先验建模“范式中的Deep Crossing/Wide&Deep
/DeepFM模型展开讨论,“物理式先验建模”则留到下一篇。
选择Deep Crossing/Wide&Deep /DeepFM进行讨论的原因如下:
- 足够经典。
- 模型来源于大厂工业实践。
- 流传和应用足够广泛。
如果你以上三个解释无法直接达成认同,不妨跟着本文的思路往下再看看。
1. Deep Crossing
首先应该聊的是Deep Crossing,这么做的原因如下:
- Deep Crossing于2016年背靠微软搜索引擎Bing发布,在时间上来足够早。
- Deep Crossing提出了从特征工程、稀疏向量稠密化、多层神经网络优化目标拟合的完整深度推荐建模方案,在工程应用上具备可实施性。
- Deep Crossing是一个端到端(End to End)模型,同时其特征交叉能力在2016年的时间节点来看,极具备跨时代的革命意义。
-
1.1 Deep Crossing 模型架构
Deep Crossing模型架构如图4。
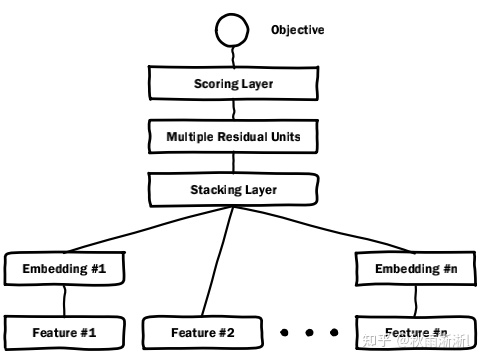
图4 Deep Crossing模型架构图
如上图4所示,很容易可以看出的是Deep Crossing模型架构十分简单,只由四部分组成,分别是: Embedding层;
- Stacking 层;
- 多层残差网络层(Multiple Residual Units);
- 打分层(Scoring Layer);
其中的Embedding层不用多说,主要是将离散特征稠密化,便于神经网络进行处理。而Stacking层则是将多个特征的Embedding向量和连续特征(like Feature #2)concat成为一个向量后,输入到多层残差网络层。多层残差网络层则会将输入的concat向量进行充分的特征交叉,然后再输入到打分层得出预测分值。
容易知道的是,Deep Crossing特征交叉部分是在多层残差网络层完成,是其大大不同于浅层模型之处。这种操作使其可以学到更多的非线性特征和组合特征的信息,进而在表达能力上较传统浅层模型有大幅度的增强。
1.2 为什么需要做Embedding
这个问题是我刚接触神经网络时的一个疑惑点,借此机会再进行一个复习。
需要做Embedding一般都是离散特征。在没有Embedding技术之前,模型为了学习离散特征一般都需要做One-Hot操作,但容易知道的是One-Hot会带来严重的数据稀疏问题,而这个问题对于神经网络来说却会带来两个大问题:
- 一:特征稀疏导致网络收敛速度非常缓慢。如果深入到神经网络的梯度下降学习过程就会发现,特征过于稀疏会使得每一个样本在梯度下降的时候只有极少数的权重会得到更新。另外,在样本数量有限的情况下会导致模型不收敛。
- 二:离线训练和线上开销大。One-Hot 类稀疏特征的维度往往非常地大,在大厂随便就达到千万乃至亿级别,如果直接连接进入深度学习网络,那整个模型的参数数量会非常庞大,
那有人就会说了,数据稀疏我们可以进行降维操作啊,比如PCA/LDA。
是的,确实可以。但PCA/LDA都是基于数学变换的线性降维方法,优化上限并没有Embedding这么的高。抛去PCA/LDA并没有Embedding多样的生成方法不谈,PCA/LDA并不具备类似EGES这种可引用各种适当的Side information来增强特征表达的能力。
1.3 Embedding的一些局限性
这个问题大多数人可以想到的答案会是,Embedding参数量占Deep Crossing模型全部参数的99%以上,使得Embedding层训练占用了网络的绝大部分训练开销,会让人感觉它是一个很低效的操作。
当然,这确实是一个大问题,但并不是我想分享给大家的,我想给大家分享的是在朱小强和周国睿大佬在知乎朱小强大佬文献和周国睿大佬文献 中指出:
我一直对embedding结构耿耿于怀:它太粗暴,lookup table的方式使得集中了CTR模型99%以上参数量的embedding matrix学习很低效。
embedding不太有什么意义,纯粹是data-driven的学习过程收敛出来的结果,且任意两次随机初始化的训练,embedding之间也很难有什么内在的泛化性联系。
相反地,原始的sparse id本身有着确定性意义,或者说输入端蕴含的信息是确定的,只不过embedding这个翻译的codebook有随机性。为此,在推进输入端建模时我非常强烈地坚持了在embedding之前“搞事情”;
他们的看法概括起来可以理解为:
- embedding低效,不一个足够好的解决方案,使用它存粹是为了让神经网络能处理ID特征。
- 原始的sparse id本身有着确定性意义,embedding的使用丧失ID本身的明确意义。
关于上述问题,两位大佬所在阿里妈妈精排团队花了近一年的时间去解决,得出的有效解决方案可以参考周大佬文献,感兴趣的戳上面的文献链接。
1.4 为什么使用深度残差网络
在图4中,我们可以看到Deep Crossing使用了残差网络而不是通用的多层感知机,那它这么做的原因是什么呢?(如果你知道深度残差网络的作用,那这个问题完全可以跳过)
实际上,残差网络的作用主要是为了解决深度神经网络中的梯度消失问题。而梯度消失产生的原因主要是梯度在反向传播时会逐渐衰减,而且当网络层数较深时及激活函数为Sigmoid时则尤为明显。我们都知道的是,神经网络的优化是沿着梯度下降去找全局最优解的过程。如果在某一层梯度(靠近输入层)都已经消失,那网络的训练便失去了方向,优化函数则更容易陷入局部最优解。
深度残差网络结构示意图5如下: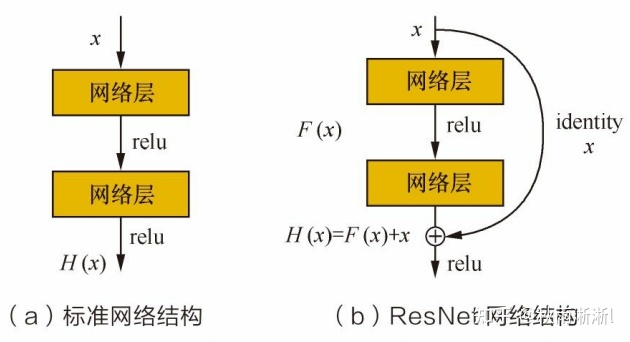
图5 ResNet网络结构图(图片出自《百面机器学习一书》)
结合图5可知,ResNet核心思路是以短接的方式前置输入层到更靠近输出层当中。
如图5(a)所示,假设  经过两层神经网络变换后得到
经过两层神经网络变换后得到  ,ResNet经过变换后得到
,ResNet经过变换后得到  ,但同时也将
,但同时也将  短接到两层之后,这样一来最后这个包含两层的神经网络模块输出则为
短接到两层之后,这样一来最后这个包含两层的神经网络模块输出则为  。因此
。因此  则可以被设计为只需要拟合输入
则可以被设计为只需要拟合输入  与目标输出
与目标输出  的残差
的残差  (残差网络的名称也因此而来)。
(残差网络的名称也因此而来)。
在这种设计下,如果某一层的输出已经较好的拟合了期望结果,那么多加入一层不会使得模型变得更差,因为该层的输出将直接被短接到两层之后,相当于直接学习了一个恒等映射,而跳过的两层只需要拟合上层输出和目标之间的残差即可。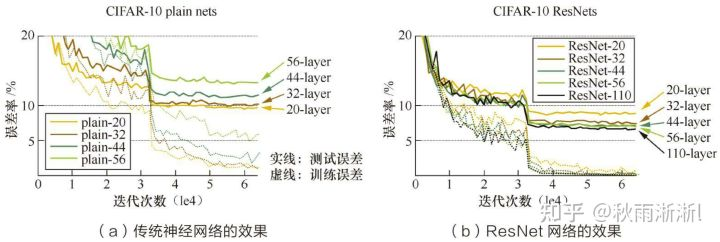
图6 ResNet与传统神经网络效果对比图(图片出自《百面机器学习一书》)
2. Wide&Deep
Wide&Deep是google play团队于2016年发布的一个深度推荐模型,在业界具备巨大的影响力。其模型亮点是具备一定的记忆和泛化能力,模型结构如图7所示。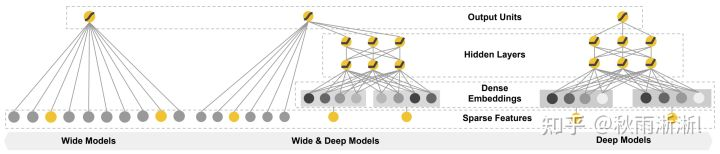
图7 Wide&amp;Deep 模型架构图
如图7,Wide&Deep模型主要由单层的Wide部分和多层Deep Net组成,在架构上十分的简单明了。如果拿它与Deep Crossing对比的话,Wide&Deep实际上只是多了一个Wide Models。
而具体到Wide Models,如图8的Cross Product Transformation部分(左边是Deep部分),则是由谷歌工程师基于行业先验给出的强特组合(这也意味着它存在人工特征工程),Wide&Deep原文给出的是用户已安装App和待曝光App的组合特征。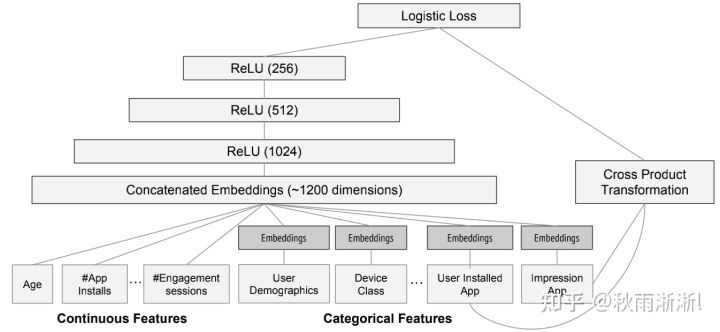
图8 Wide&amp;Deep 模型详细结构图
可以进一步指出的是,Wide&Deep Wide Models的人工组合强特,使得模型具备很强的”记忆能力“。而这也是很好理解,Wide&Deep通过这种强特征组合的方式去告诉模型,各个app被共同安装在同一台设备上的条件概率,本质上可以基于条件概率最大化去理解。
3. DeepFM
DeepFM是华为与哈工大于2017年发布的经典深度推荐模型,其核心亮点是将Wide&Deep的Wide部分改为FM结构,从而使得模型具备更强的自动化特征组合能力。DeepFM的架构图9。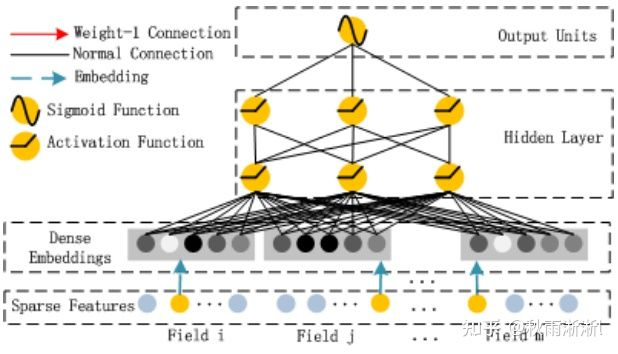
图9 DeepFM模型架构图
如图9,为了使得模型具备一定”记忆“能力的同时,又想摒弃Wide&Deep的手动特征工作,DeepFM选择了FM结构和Deep Net的双模型组合结构。
4. 代码实现
这部分直接贴代码github链接了。
- Deep Crossing(MLP实现版本)
- Wide&Deep
-
5.总结
本文回顾了”代数式先验建模“范式中极具代表性的Deep Crossing、Wide&Deep 以及DeepFM展开讨论,并给出了其TensorFlow的代码实现。可以做补充解释的是,”代数式先验建模“本质是基于先验认识,通过模型的结构设计捕捉特征之间的”代数关系“,如Deep Crossing的baseline版特征交叉、Wide&Deep的先验强特组合以及FM在浅层推荐时代就表现出的二阶特征组合能力。
虽然站在今天的时间节点上来看,这三个模式的架构和原理十分的简洁明了,乃至让人感觉换我也能行的”错觉“。但需要指出的是,这几个模型在深度推荐模型发展路程中走的是0~1的历程,它们的现世无不是经历的大量的实验和探索。我们现在之所以觉得简单,只不过是因为我们今天是站在1~n的里程上高屋建瓴的进行回顾罢了。
最后,预告一下,在下文中笔者将对“物理式先验建模”这一类模型中的典型代表DIN/DIEN/MIMN/SIM进行回顾和学习。参考文献
1.秋雨淅淅l:前深度学习时代—推荐模型演化路径梳理
2.《深度学习推荐系统》—王喆
3.朱小强:屠龙少年与龙:漫谈深度学习驱动的广告推荐技术发展周期
4.Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features
5.Wide & Deep Learning for Recommender Systems
6.DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
7.周国睿:想为特征交互走一条新的路B-4.主流深度推荐模型演化(下)|从DIN、DIEN到 MIMN、SIM | 附DIN、DIEN TensorFlow代码实现
0. 背景
上篇文章我们聊了主流深度推荐模型的演化,并对其中”代数式先验建模“范式一路中的Deep Crossing/Wide&Deep/DeepFM模型展开详细的讨论。本篇文章,笔者将对主流深度推荐模型中“物理式先验建模”一路中的DIN/DIEN/MIMN/SIM进行回顾和学习。
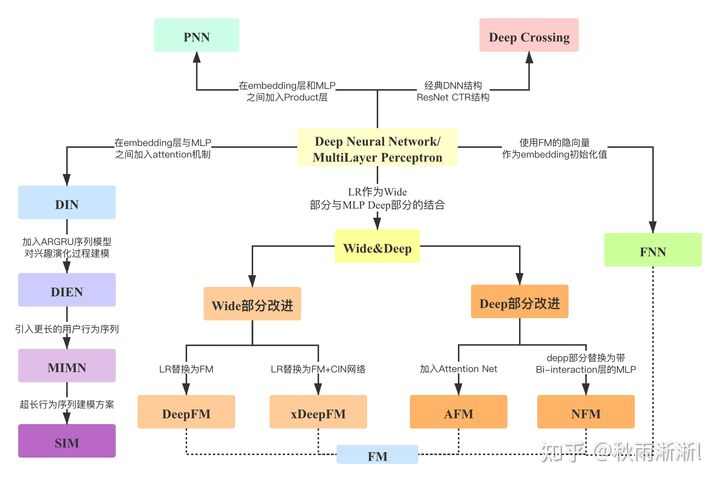
图0-1 经典深度推荐模型演化图谱(图片参考王喆《深度学习推荐系统》一书)
选择DIN/DIEN/MIMN/SIM的原因如下: 在基于用户序列捕捉“用户兴趣”这类模型中,知名度和复用度极高。
- 经历大厂大流量检验,同时工程应用性极强。
- 一脉相承于行业尖兵阿里妈妈精排团队,可以学习阿里妈妈团队近几年的建模思路。
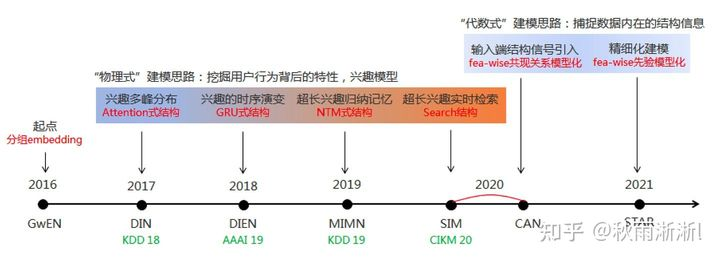
图0-2 阿里展示广告团队CTR主模型的发展轨迹(2016-2021)
接下来,让我们来沿着时间的车轮一一进行分析。
1. DIN模型—阿里兴趣建模开端
DIN(Deep Interest Network )是阿里妈妈团队于2017年发表的一个兴趣模型,是阿里展示广告团队兴趣建模的开端。不同于DeepFM等模型是,DIN在整体上表现为重用户兴趣序列挖掘而弱特征交叉设计。
1.1 DIN模型出发点
作为阿里发布的第一个兴趣建模模型,其出发点是基于阿里妈妈团队在其业务数据中观察到的Diversity和Local activation现象。
Diversity和Local activation 名词理解:
- Diversity指用户历史兴趣呈多峰分布。即用户在过去的一段时间中,会对各种行然不同的商品产生兴趣,并产生浏览、点击、加购、下单、复购等指示性消费信息。
- 考虑我们实际使用淘宝场景。如果我们在短期内想购买多种不同类别的商品,如水果、鞋子、笔记本电脑,并产生了大量相关的访问记录。那么在当前时刻,我们至少存在三个截然不同的兴趣峰。
- Local activation则指的是,尽管用户历史兴趣呈多峰分布,但决定用户当下转化只会是其中的某几个兴趣导致。
- 在最终下单笔记本电脑前,我们产生了很多的水果、鞋子以及笔记本的选货记录。但在购买笔记本这件事情上,只有和笔记本相关的访问中,才可能隐藏我们可能下单的兴趣信息。
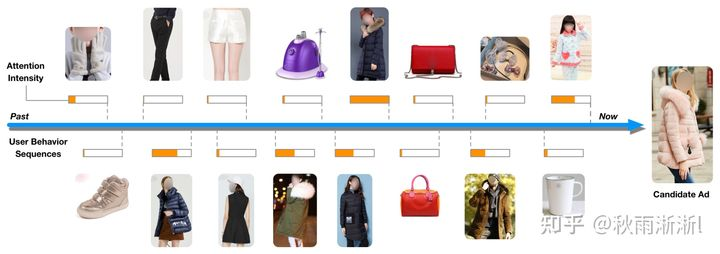
图1-1 用户兴趣呈多峰分布
Diversity和Local activation指明的信息:
- 在基于用户历史行为建模时,将用户访的商品embedding sum-pooling、max-pooling后无差的喂给MLP不是一个很好的方案。
- 用户历史行为中,只有与待推荐的candidate类似的兴趣,才具备更强、更有效性的指导模型训练信息。
基于上述思考,阿里妈妈团队提出了DIN模型。而DIN模型的特点与亮点是通过设计一个attention-like的网络结构,捕捉待推荐candidate商品与用户历史行为序列与之间注意力分。
1.2 DIN模型架构解析
如下图1-2右,DIN由五部分组成,分别是:
- embedding输入层,输入用户行为序列中的商品ID、商铺ID等。
- activation单元。
- concatenate层。
- MLP特征交叉层。
- 输出层。
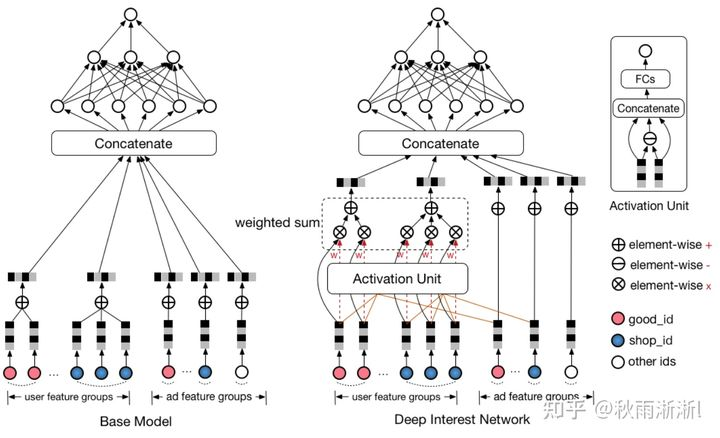
图1-2 DIN模型架构图
上述五个部分中,activation单元是DIN模型的核心要义所在,也是其不同于其它模型之处。
如上图1-2左是阿里2016提出的GwEN,其代表着业界对用户行为序列处理的流行做法,会将用户的历史行为直接pooling后输入MLP部分。而DIN则是通过activation unit计算出candidate与用户历史行为的兴趣度分值,并以此分值加权做sum-pooling,然后再将pooling后的结果与商品candidate的embedding concatenate后输入MLP。
可以进一步补充的是,DIN activation unit为MLP的输入了一个有偏的用户潜在兴趣信息,其告诉了MLP 在当前的candidate下,用户哪些兴趣该被local activate。
在DIN论文中,作者也自信的提到他们是当时业界第一件做这件事情并成功的人。
1.3 DIN attention结构解析
如上文指出,activation单元是DIN要义所在,那它的结构和实现是怎么样的呢?
如公式1-1所示:
式中, 为用户历史行为
为用户历史行为  的embedding表示,如用户点击过的商品/店铺ID,
的embedding表示,如用户点击过的商品/店铺ID,  为待推荐商品/店铺的ID。
为待推荐商品/店铺的ID。 则是用户所有序列的embedding 加权sum-pooling,而
则是用户所有序列的embedding 加权sum-pooling,而  则是用户序列 中
则是用户序列 中 与待推荐candidate中
与待推荐candidate中  的权重分,由注意力activation网络计算得出。
的权重分,由注意力activation网络计算得出。
具体到注意力计算函数  ,其在网络中体现为将
,其在网络中体现为将  的Embedding做元素级相减(element -wise minus),如图1-2右上角所示。
的Embedding做元素级相减(element -wise minus),如图1-2右上角所示。
另外,值得一提的是,如图1-2中的红线所示,商品ID(good_id)只与用户历史行为中的商品ID发现作用,同理商铺ID(shop_id)也只与用户历史行为中的商铺ID算注意力分。这说明DIN作者认为,注意力的高低应该由同类信息的相关度决定。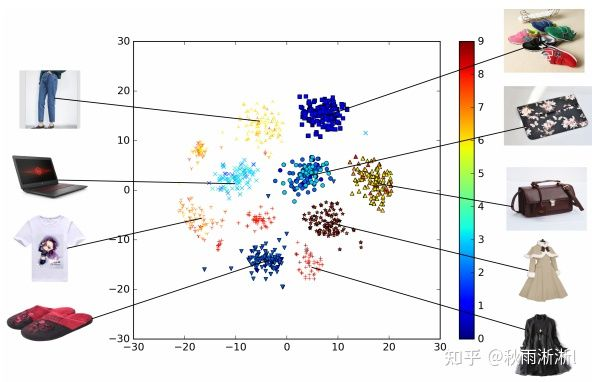
图1-3 基于DIN得出不同类目商品Embedding的可视化图(图源于DIN原文)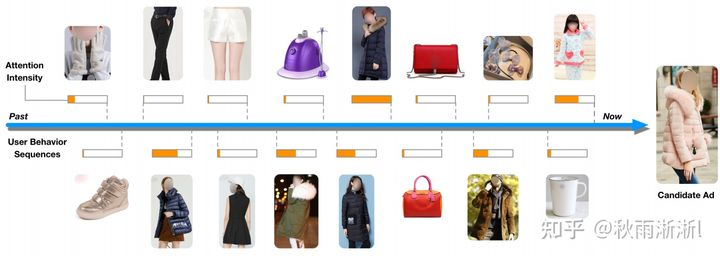
图1-4 与候选商品相似的用户访问序列会得到更高的注意力分(图源于DIN原文)
2. DIEN
在DIN上线后获得正向效益后,阿里继续朝着用户兴趣挖掘这条路上展开深入的研究,2018发布的DIEN(Deep Interest Evolution Network )则是DIN之后的一个产物,在上线后在CTR和eCPM上分别为阿里妈妈带来了20.7%和17.%的恐怖提升。(要知道对于阿里这样一个大体量的公司,每一个点的CTR提升带来的都是千万计的收益)
2.1 DIEN的创新点
DIEN不同于DIN和其它兴趣模型的创新点在于:
- 不把用户访问行为直接当做用户兴趣,而是设计了GRU单元来抽取用户兴趣和模拟兴趣迁移过程。
- 为了避免用户兴趣的迁移(interest drifting )带来的影响,设计了基于带attention 的GRU单元AUGRU,来强化用户相关兴趣与candidate的注意力权重。
DIEN的这两个创新点,体现出了DIEN更加注重对用户序列的深度挖掘,这么说的原因如下:
- 利用了用户行为序列中,极具信息量的用户购物时序信号,模拟了用户兴趣转移。
- 如DIN模型,无序的把用户行为与candidate进行attention计算,忽略了用户访问序列时序和用户兴趣递进演绎信息。而在用户购物时,最近访问的商品恰恰对下一次购买商品的影响较大。
-
2.2 DIEN模型架构解析
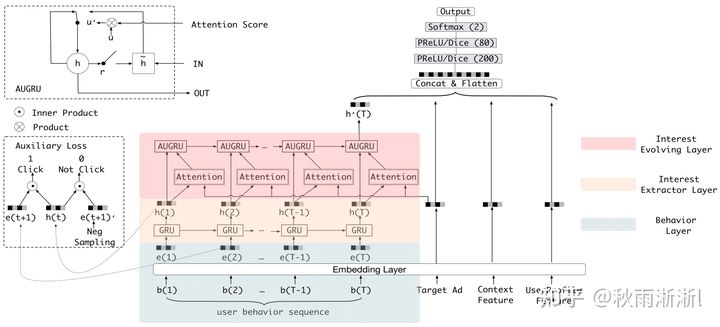
如下图2-1,DIEN在MLP层之前的网络由三部分组成,分别是:
行为序列层(Behavior Layer ,图浅绿色部分):其作用是原始的ID特征转为稠密的embedding特征。
- 兴趣抽取层(Interest Extractor Layer,图淡黄色部分):其作用是基于用户行为序列模拟用户兴趣迁移,从而抽取用户各个转态对应的兴趣。
- 兴趣进化层(Interest Evolving Layer,图粉色部分):其作用是强化用户相关兴趣与candidate的注意力权重。
2.3 兴趣抽取层结构
如上图2-1,兴趣抽取层的基本结构是GRU(Gated Recurrent Unit)。GRU作为循环神经网络中的变种,于2014年由Chung提出,其比之于RNN更不容易出现梯度消失问题(Vanishing Gradients Problem ),比之LSTM在架构上更为简单,在性能上却相仿,线上推断成本会更低很多。因此DIEN是选用GRU作为记忆单元而不是LSTM/RNN(如图2-2,GRU只用同一个门控 就同时可以进行遗忘和选择记忆,LSTM需要使用两个门控
就同时可以进行遗忘和选择记忆,LSTM需要使用两个门控  )。
)。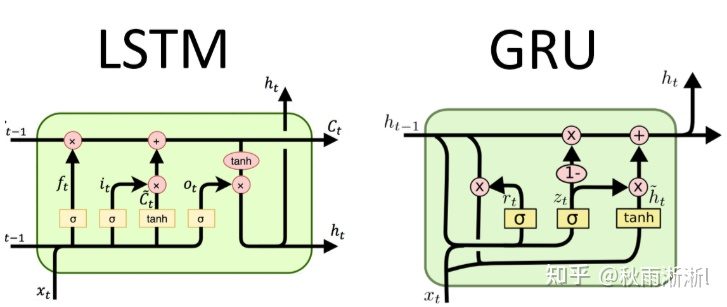
图2-2 LSTM和GRU模型架构图
DIEN中的GRU单元公式如2-1所示:

其中,  是6组GRU需要进行学习的参数矩阵,
是6组GRU需要进行学习的参数矩阵,  则是三组偏置量。
则是三组偏置量。  是当前时刻的用户行为embedding输入
是当前时刻的用户行为embedding输入  ,
,  是上一时刻(序列中的上一个活动)的隐状态向量(hidden state),
是上一时刻(序列中的上一个活动)的隐状态向量(hidden state),  为当前时刻(序列中的当前输入活动)的隐转态向量。同时
为当前时刻(序列中的当前输入活动)的隐转态向量。同时  决定GRU的记忆量,
决定GRU的记忆量,  则可以看作是遗忘门(forget gate)。
则可以看作是遗忘门(forget gate)。
注:公式2-1中的  对应图中的
对应图中的 。
。
2.3.1 DIEN为什么会多一个辅助损失函数?
DIEN认为单纯的GRU模型抽取用户兴趣不够有效,因此其在基础的损失函数  上加上了一个辅助损失函数
上加上了一个辅助损失函数  (Auxiliary loss )。
(Auxiliary loss )。 和
和  的表达式如下:
的表达式如下:

其中,  是常规的二分类交叉熵损失函数,此处不做展开介绍。
是常规的二分类交叉熵损失函数,此处不做展开介绍。
在 中,
中,  为t时刻的隐状态,
为t时刻的隐状态,  为t+1输入活动embedding,
为t+1输入活动embedding,  为t+1时刻负采样所得用户所得活动embedding(类似word2vec负采样,取用户点击序列之外的活动)。
为t+1时刻负采样所得用户所得活动embedding(类似word2vec负采样,取用户点击序列之外的活动)。
加上 的DIEN损失函数最终形式为:
的DIEN损失函数最终形式为:
其中,  是用了平衡兴趣表示和CTR预测值的超参数。
是用了平衡兴趣表示和CTR预测值的超参数。
DIEN加上  的原因(注意 ,这很值得留意):
的原因(注意 ,这很值得留意):
- 作者认为,target item的点击只由用户的最后一次兴趣触发,可
 损失函数只是在是否点击层面进行的监督学习,却没有对GRU中的历史门控输出
损失函数只是在是否点击层面进行的监督学习,却没有对GRU中的历史门控输出  进行监督学习。
进行监督学习。 - 每一个用户兴趣状会产生一系列、连续的用户序列(即正样本),因此对对
 进行监督学习非常必要。
进行监督学习非常必要。
 带来的好处:
带来的好处:
- 在抽取用户兴趣这件事情上更为高效。
- 减少了GRU的梯度消失问题。
学习到了更多语言层面(semantic information )的embedding信息。
2.4 兴趣进化层结构
DIEN设计兴趣进化层的原因如下:
用户兴趣存在迁移。
- 用户兴趣本身存在进化的过程。
具体到兴趣进程层的结构,其比之于兴趣抽取层主要是加入了注意力机制。而注意力引入的方式则与DIN如出一辙,都是在强化target item与相关用户兴趣的注意力,只不过在DIN中的兴趣简单的以用户行为来表达DIEN中的  了而已。另外DIEN还有一点与DIN模型不同的是,DIEN的attention进制主要基于GRU单元来实现,因此DIEN的兴趣进化层单元也被称为了AUGRU(GRU with attentional update gate )。
了而已。另外DIEN还有一点与DIN模型不同的是,DIEN的attention进制主要基于GRU单元来实现,因此DIEN的兴趣进化层单元也被称为了AUGRU(GRU with attentional update gate )。
AUGRU架构:
AUGRU的架构如图2-3和公式表达如公式2-5: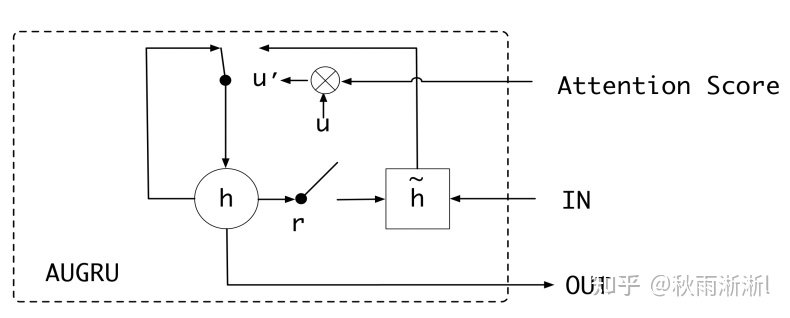
图2-3 AUGRU架构
其中,  计算方式如公式(2-6),表示的是target item的embedding与用户兴趣层的隐状态
计算方式如公式(2-6),表示的是target item的embedding与用户兴趣层的隐状态  的注意力分。
的注意力分。

结合GRU原始表达(2-1)和公式(2-5)、(2-6)我们可以知道,用户的每一个兴趣  与target item的注意力分(相关性)决定着
与target item的注意力分(相关性)决定着  输出状态
输出状态  。
。
因此可以知道的是,attention加入会使得兴趣进化层在进化时,会着重进化与target item相关的用户兴趣,并将这个进化得到的最终兴趣量  作为MLP的重要输入,从而让模型知道用户是否对当前的target item真正的感兴趣。
作为MLP的重要输入,从而让模型知道用户是否对当前的target item真正的感兴趣。
另外在把注意力怎么加到GRU单元这件事情上,DIEN做了其它两种尝试,个人觉得这些思考同样具备学习意义,此处介绍如下:
AIGRU:
AIGRU(GRU with attentional input),它的想法是兴趣进化层GRU的输入上做文章,具体表达如下:
但DIEN作者表示,理想情况下,加入注意力进制后,那些相关性较低的兴趣输入对应的兴趣输出应该接近与0,但是AIGRU却做不到这一点,甚至在输入为0的情况下,仍然会改变当前GRU的输出状态,因此AIGRU最终没有被DIEN采用。
AGRU:
为了解决AIGU在输入为0时,输出不为0问题,DIEN作者还设计了名为AGRU(Attention based GRU)的结构模型,其表达如下:
对比公式(2-1),我们可以发现AGRU在结构上用  代替了之前的更新门
代替了之前的更新门  。在效果上,作者表示AGRU可解决AIGU输入为0问题,但却也因此丧失了原本更新门的信息,因此AGRU最终也没有被DIEN采用
。在效果上,作者表示AGRU可解决AIGU输入为0问题,但却也因此丧失了原本更新门的信息,因此AGRU最终也没有被DIEN采用
兴趣进化层的收益:
- 可以强化相关兴趣在模型中的表达能力。
-
3. MIMN
MIMN是阿里妈妈于2019年发布在KDD 19上的又一兴趣模型,其所解决的问题是超长(1000这个量级)兴趣序列在线推断建模,实现方法是用户兴趣求解解耦+多通道兴趣建模。核心创新点是偏向工程实现(向减少时延妥协),在算法上结构上不比DIEN复杂。
3.1 为什么要引入更长的用户序列?
首先,从先验知识上来说,更长的用户行为训练意味着,模型可以得到更长、更可信的用户兴趣。沿着用户兴趣进化的路径,去学到用户的兴趣偏好,可以让模型更懂用户对什么感兴趣。
另外,从MIMN的作者给出的数据来看,如下图3-1,基于简单的MLP来对不同长度的用户行为序列进行建模,发现离线AUC指标与用户序列长度线性相关。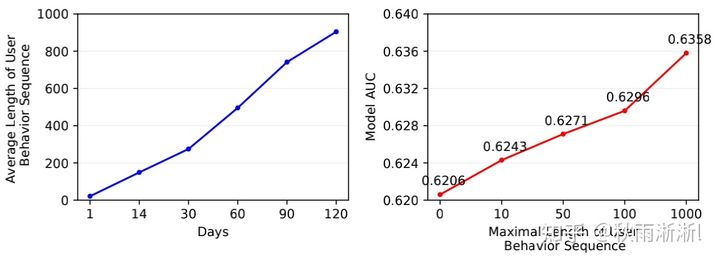
图3-1 用户行为长度与离线AUC成正比
据此,MIMN作者认为增加用户序列长度,有提升模型线上表现的巨大潜力。3.2 为什么DIEN不适用了?
在回答这个问题之前,需要先了解的一个数据是:在阿里的应用场景下,DIEN在线推荐时能容纳的最大序列长度在150这个量级,再往上加则会面临时延和数据存储这两个线上推断的大问题。其中前者导致推荐请求时间过长,后者给线上服务器带来高昂的数据存储成本。另外,可以一提的是,时延和数据存储可以说是所有复杂模型上线的最大拦路虎。
而MIMN的作者,在一开始上就打着使用尽可能长的用户序列,因此DIEN这种精致的线上兴趣提取加工算法模型并不适合。另外,DIEN的记忆单元主要是GRU,而GRU对超长序列建模本身便存在一定的性能问题。3.3 MIMN模型结构概览
如下图3-1,MIMN模型结构由两部分组成,分别是左边的UIC单元和右边的Attention+MLP主模型。
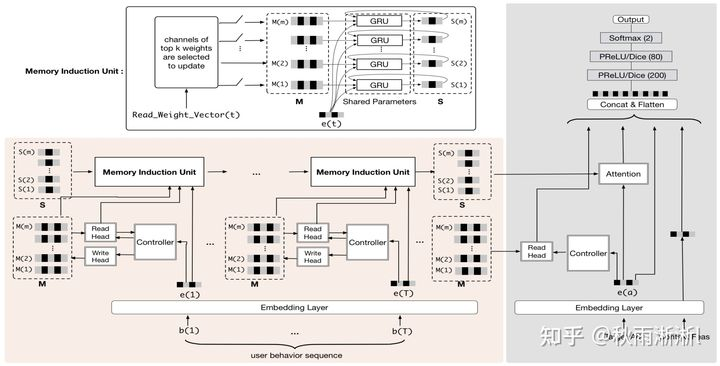
图3-1 MIMN模型结构
可以看到MIMN模型结构基本上是在表达UIC单元,而右边的打分结构则非常的简洁。实际上MIMN的原文也基本是介绍UIC,对MLP部分介绍很少。因此接下来会对MIMN的UIC模块进行介绍,看看它是怎么做到基于超长用户序列生成用户兴趣兴趣同时,又做到克服时延和节省线上存储这件事情的。3.4 UIC-MIMN超长序列存储方案
如图3-2(B),抛开主模型不谈,MIMN的在线预估模型(Real-Time Prediction ,RTP)在获取用户长期兴趣同时克服时延和存储问题这件事情,MIMN的做法是将用户兴趣抽取模块(UIC)和主模型做解耦,使得主模型可以更加轻的上线。
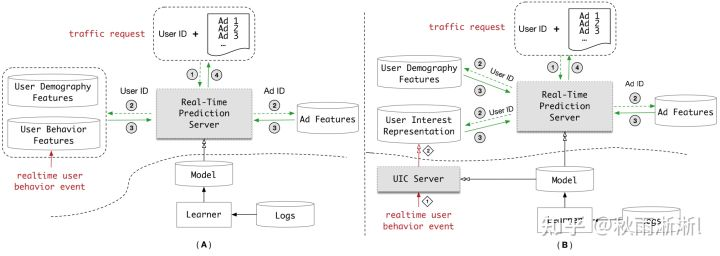
题3-2 图A为常见RTP推荐系统,图B为MIMN RTP架构
另外,UIC由于与主模型解耦,因此相对于主模型来说是个离线模型,但UIC自己本身确又是实时更新的,所以对于在获取用户兴趣这件事情上,主模型实际上是没有时延的。
而具体到UIC的设计,如图3-3,其主要由两部分组成。分别是负责提取和存储原始用户兴信息的NTM(Neural Turing Machine)和负责提炼用户兴趣的MIU(Memory Inducation Unit)模块。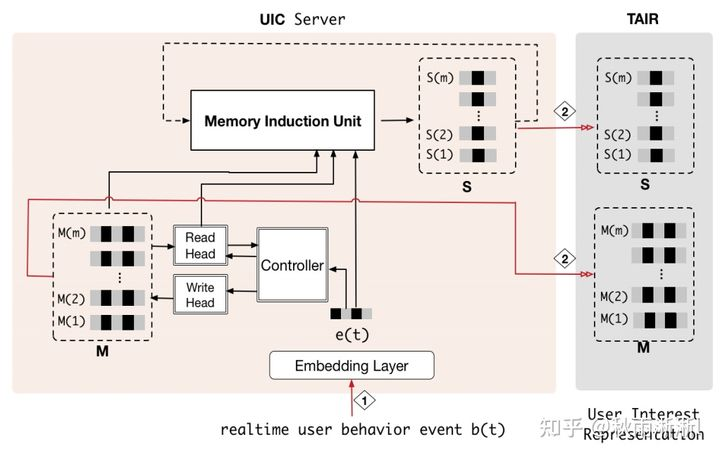
图3-3 UIC单元架构3.5 NTM- UIC兴趣记忆单元
NTM是大名鼎鼎的DeepMind于14年发布的一个神经记忆网络。不同于LSTM范式模型的基于门控方式来进行信息的遗忘与更新,NTM是第一篇提出使用外部memory模块来增强神经网络记忆能力的模型。其核心思想是通过特定寻址的方式,只对特定memory进行修改,再加上可以用外部存储,使得NTM理论上可以记录非常长的序列信息。而关于LSTM或GRU,因其每次迭代都要更新所有隐向量
 而导致无法记录非常长久的信息,同时hidden_size也会限制了模型记忆信息的容量,所以UIC最终采用NTM来存储和处理用户行为序列。
而导致无法记录非常长久的信息,同时hidden_size也会限制了模型记忆信息的容量,所以UIC最终采用NTM来存储和处理用户行为序列。
引用参考文献5中的例子。下图3-4(a)是NTM的结果,3-4(b)图是LSTM的结果,每个子图下面的是预测,上面的是真实值。对比可以发现LSTM在序列长度为30的时候就已经无法正常预测,而NTM在序列长度为50的时候还可以预测的很好。
图3-4(a) NTM记忆效果展示(图片出自参考文献5)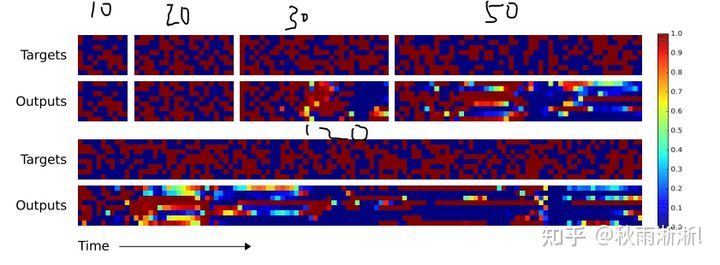
图3-4(a) NTM记忆效果展示(图片出自参考文献5)
而关于NTM的架构,其主要由controller和一个memory矩阵组成。
其中controller主要负责根据输入对memory进行读写操作,从而实现记忆的更新,可以使用简单的前向神经网络或者RNN来作为controller的模型,前向神经网络计算复杂度较低,而且更加透明,但是因为比较简单所以会限制NTM模型在每个time step里的计算类型。而选用RNN作为controller的话,其本身就存在一个内部记忆,如果将其比作计算机的话,LSTM就是CPU,其内部hidden state就是寄存器,负责对内存进行读写,而memory矩阵就是内存。使用RNN的好处是通过内部记忆扩展读写规模,不会受到每个时间步都被单次读写的限制。
NTM架构解析出自参考文献5
NTM结构如图3-5所示: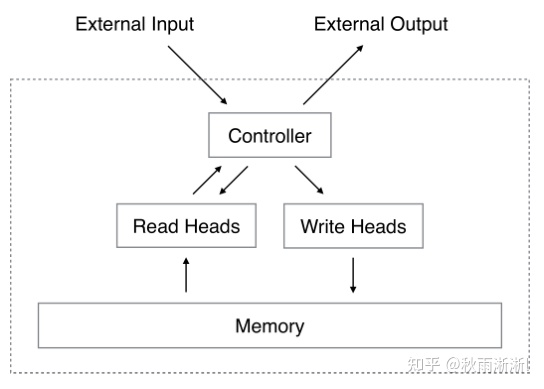
图3-5 NTM架构
具体到UIC的NTM做memory read这件事情上,在时刻t,对于为red key 来读存储矩阵
来读存储矩阵  的时,其读出的状态量表达如下:
的时,其读出的状态量表达如下:
其中 为red key
为red key  与NTM的存储矩阵
与NTM的存储矩阵  的相似权重(从表达上来看,就是一个softmax函数),
的相似权重(从表达上来看,就是一个softmax函数),  则是由m个内存槽(memory slots)
则是由m个内存槽(memory slots)  中的t时刻状态。
中的t时刻状态。 计算方式如下:
计算方式如下:
其中:
是一个余弦相似度的计算过程。
而对于UIC的每一次memory write,其表达如下:
其中, 为擦除矩阵(erase matrix),由擦除向量
为擦除矩阵(erase matrix),由擦除向量  和权重
和权重  叉乘而来,权重
叉乘而来,权重  的计算则基于公式(3-2),具体表达如下。
的计算则基于公式(3-2),具体表达如下。
 则为记忆矩阵(add matrix),由记忆量
则为记忆矩阵(add matrix),由记忆量  和权重
和权重  叉乘。
叉乘。
NTM模型改进-Memory Utilization Regularization
以上,描述了NTM模型做数据读写的常规方案,但MIMN的作者认为直接使用这种方法来做存储用户兴趣,存在内存利用率不高和热门活动在内存中占比高等问题。因此MIMN在基础的NTM上做了归一化,以达UIC最终可以表达更多用户兴趣信息。
NTM的归一化方式如下:
取中的 是(3-2)中提到的方式计算出的写权重,
是(3-2)中提到的方式计算出的写权重,  则是归一化后写权重矩阵,其中的
则是归一化后写权重矩阵,其中的  计算方式如下:
计算方式如下:
而其中的 则是m个卡槽在t时刻的内存利用率,
则是m个卡槽在t时刻的内存利用率,  权重矩阵则基于正则损失函数得出:
权重矩阵则基于正则损失函数得出:
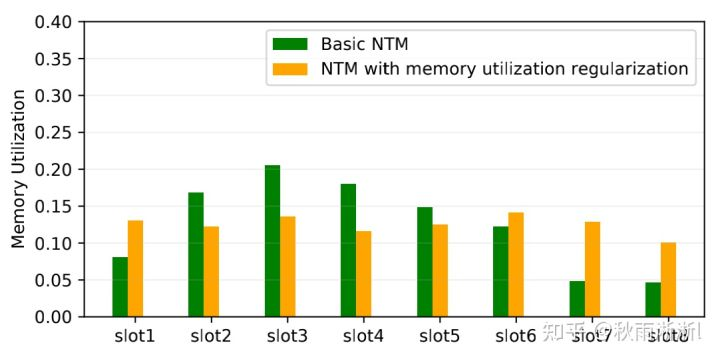
图3-6 NTM归一化内存利用率3.6 MIU-UIC兴趣提取单元
NTM单元对于UIC更多的是做了兴趣的读和写,因此到目前为止UIC并不具备类似DIEN的兴趣表达能力,为此MIMN作者为UIC增加了一个高阶兴趣抽取模块MIU。
如MIU结构图3-3,MIU的存储方式与NTM如出一辙,拥有m卡槽来存储用户高阶兴趣,同时个卡槽表达用户的一个用户兴趣channel。公式表达如下:
在时刻t,从集合 中选择出k个用户兴趣channel,再对选出的K个channel按如下公式更新:
中选择出k个用户兴趣channel,再对选出的K个channel按如下公式更新:
其中, 为t时刻第i个内存槽的记忆信息,
为t时刻第i个内存槽的记忆信息,  则为t时刻的用户行为embedding量。另外,为了节省内存,MIU的multi-channel memory的GRU参数公用一份参数。
则为t时刻的用户行为embedding量。另外,为了节省内存,MIU的multi-channel memory的GRU参数公用一份参数。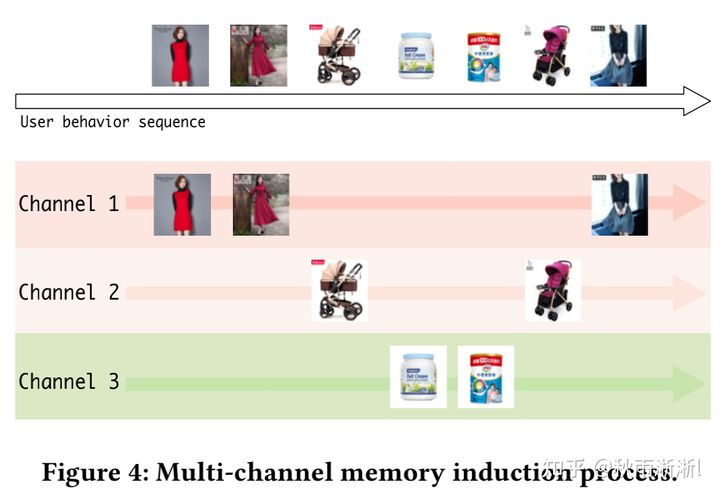
图3-7 MIU多通道处理示意图3.7 MIMN效果展示

图3-9 MIMN不同slot对应的离线表现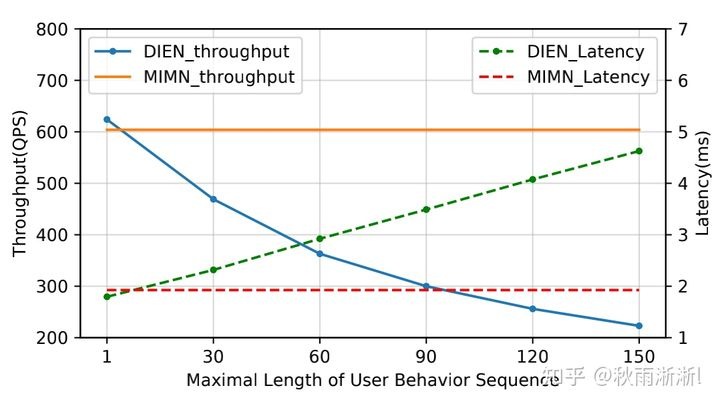
图3-10 MIMN和DIEN的时延和QPS表现(MIMN在150的sequence范围内毫无抖动)
另外,MIMN论文公布,MIMN在2019-03-30~2019-05-10的线上AB实验中,在前一代兴趣模型DIEN的基础上取得了7.5%的CTR预估提升和6%的PRM(Revenue Per Mile)增益,效果可谓非常的惊人。4. SIM
对于阿里妈妈精排团队而言,MIMN的成功又一次印证了DIN和DIEN中对预估目标item信息利用的重要性。同时更有指向性的是:增加用户访问序列长度(从DIEN的150到MIMN的1000),在线上实验可以取得更好的成绩,而2020年被公布的SIM则是在这阿里在这一道路上探索的最新成果。
4.1 SIM核心创新点
SIM的核心创新点如下:
基于GSU(General Search Unit)做用户全生命周期行为快速检索,从而赋予SIM处理54000量级序列的能力。
基于ESU(Exact Search Unit)对GSU seach得出的SBS(Sub User Behavior Sequence )做类似DIN/DIEN的attention操作得到target item和用户兴趣的相关性分。
4.2 SIM 模型架构解析
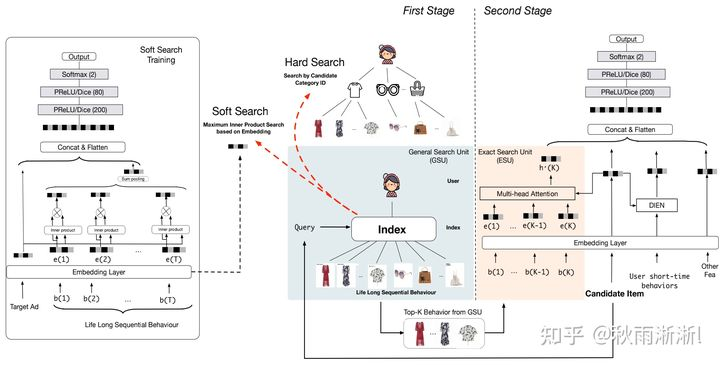
图4-1 SIM架构图
如上图4-1,SIM的模型架构比DIEN、MIMN简单很多。其可以分两部分来看,其一是虚线左边的First Stage部分 GSU,其负责检索用户全生命周期序列,包含的Soft Search和Hard Search两种方案可选(考虑线上实验,线上采用的Harh Seach的方法)。其二是 Second Stage部分,主要由ESU和DIEN组成的MLP打分模型。
具体到SIM最终选用的GSU,其结构非常的简单,就是以用户维度按target item对应的categroy在用户全生命周期做一个索引召回而已。
关于ESU,如4.1小结中指出,其是对GSU seach得出的SBS做类似DIN/DIEN的attention操作得到target item和用户兴趣的相关性分。
在具体实现时,ESU考虑SBS中的用户序列集时间跨度较长,假设SBS 中的top k活动序列为 ,假设其对应的时间区间为
,假设其对应的时间区间为  ,ESU为D对应的时间窗向量表达为为
,ESU为D对应的时间窗向量表达为为  ,于是ESU最终将用户兴趣GSU中的Top k向量表达为
,于是ESU最终将用户兴趣GSU中的Top k向量表达为  。而关于target item和用户兴趣的相关性分,ESU采用其所谓的multi-head attention机制来获取离散的用户兴趣:
。而关于target item和用户兴趣的相关性分,ESU采用其所谓的multi-head attention机制来获取离散的用户兴趣:

对应的,ESU最终输出的multi-head attention向量 。
。
最后SIM和DIEN也为ESU的attention更新设置了一个loss为 来监督attention的更新。
来监督attention的更新。
4.3 SIM效果分析
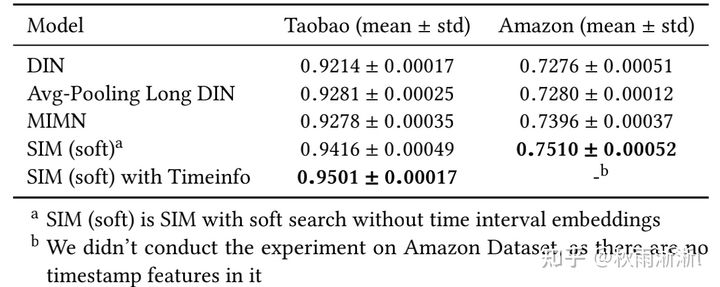
图4-2 SIM在公开数据集上的表现(b)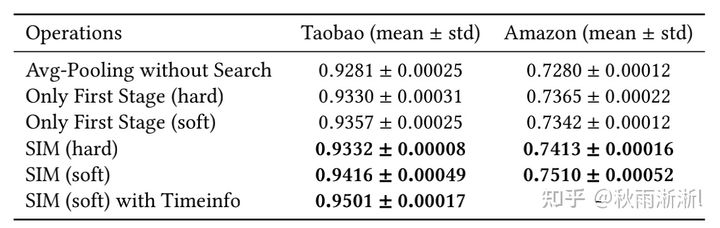
图4-3 SIM在公开数据集上的表现(b-测试SIM不同模块的效果)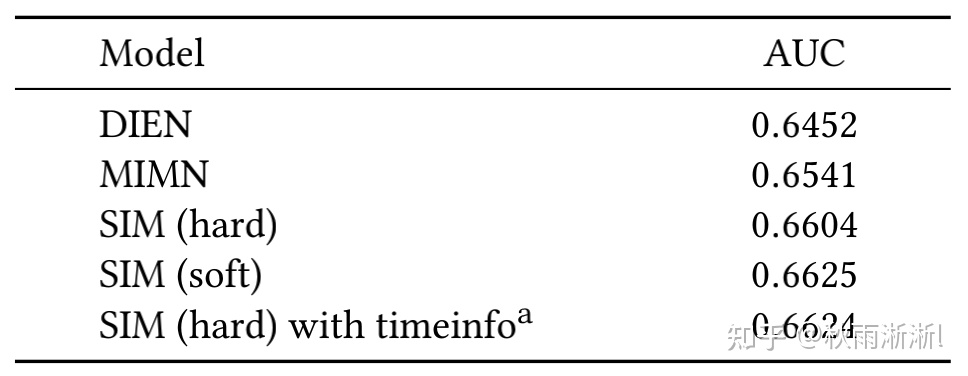
图4-4 SIM上线后的效果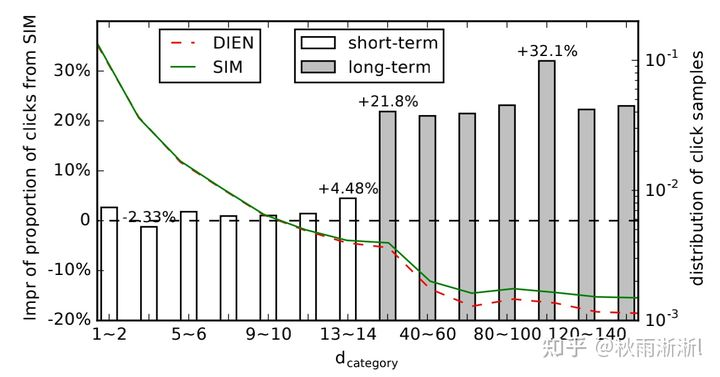
图4-5 在长期部分,SIM预测效果明显好于DIEN
实验效果表明:SIM真正更多的推荐出了用户偏向长期行为相关的结果,且用户进行了点击,侧面说明SIM相对更好的建模了长期兴趣。
注:d_category的定义:与用户点击的item 类目相同的行为最近发生日期离当前的天数。
图4-6 SIM时延显然低于MIMN
另外,SIM论文公布,SIM在2020-01-07~2020-02-07的线上AB实验中,在前一代兴趣模型MIMN的基础上取得了7.1%的CTR预估提升和4.4%的PRM(Revenue Per Mile)增益,效果同样可谓非常的惊人。5. 代码实现
这部分直接贴代码github链接了。
-
6.总结
本文本对主流深度推荐模型中“物理式先验建模”一路中的DIN/DIEN/MIMN/SIM进行回顾和学习。在学习的过程中,我们发现DIN/DIEN/MIMN/SIM也刚好是阿里展示广告团队在2017~2020期间的CTR主模型主模型发展轨迹。在文章结束之前让我们来对阿里的这条轨迹做最后的概括性总结:
以挖掘用户兴趣序列为主线,以强化用户兴趣表达为主旋律。
- 从简单的用户行为表达用户兴趣,到基于GRU、NTM来表达用户兴趣。
- 以挖掘用户兴趣attention机制提高模型性能,以增加用户序列长度拔高模型上限。
- attention机制贯穿终始,同时用户序列长度从DIN、DIEN的100+到MIMN的1000+再到SIM的54000+。CTR预估指标一路提升,线上时延和存储却保持在一个可接受的水平。
-
参考文献
DIN | Deep Interest Network for Click-Through Rate Prediction
- DIEN | Deep Interest Evolution Network for Click-Through Rate Prediction
- MIMN | Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction
- SIM | Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
- Neural Turing Machines-NTM系列(一)简述
- 呜呜哈:记忆网络之Neural Turing Machines
- 被包养的程序猿丶:阿里妈妈长期用户历史行为建模——MIMN模型详解
- 周国睿:Life-long兴趣建模视角CTR预估模型:Search-based Interest Model
- 陈诚:人人都能看懂的GRU
- 卡门:直觉理解LSTM和GRU
B-5.Youtube DNN serving目标解析 | 从odds到Logit 、Logistic Regression
0. 背景
最近主要在学习召回模型,在学到Youtube的经典论文Deep Neural Networks for YouTube Recommendations中的召回时,无意看了一下它的排序部分,然后就对其线上serving部分感到非常困惑(如下图0.2 红圈部分)。
图0.1 Youtube DNN两级推荐架构图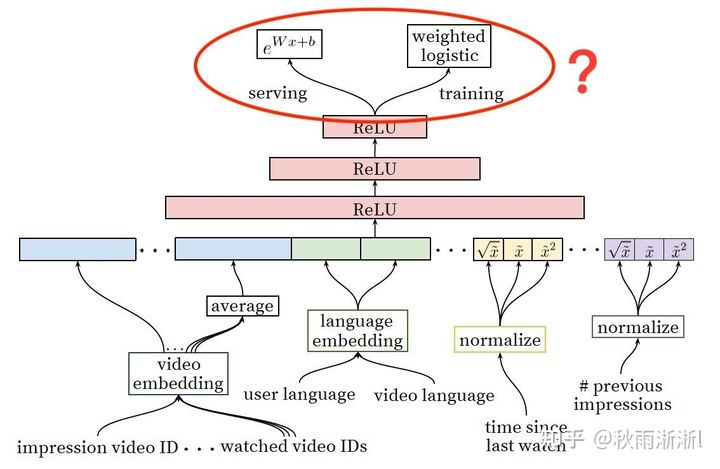
图0.2 Youtube DNN排序部分模型架构
让我感到困惑主要为以下两点:
- 从模型架构上来看,training学习的是weighted logistic,serving的时候为什么预测值变成了
 。
。 - 在查看weighted logistic细节时,不理解
 的转换关系(见论文4.2小结,如图0.3红框部分。
的转换关系(见论文4.2小结,如图0.3红框部分。

图0.3 Youtube 4.2 Modeling Expected Watch Time原文局部
为了解开这两个困惑,花了我不少的时间,好在最终得到了答案。
在解决上述问题时,我重新梳理Odds和Logistic的关系,并对Logistic重新进行了推导,最终得到了不错的答案。事后回想起来觉得这个是一个有趣的过程,遂记录如下。
1. Odds和Logistic的关系
1.1 什么是Odds?
Odds在英语中是指事情发生与不发生的比率。假设事情发生的概率为P,则有  。
。
这么直观的看,Odds似乎难以和Logistic联系在一起,因为我们知道Logistic的分布区间为为(-1,1),同时其分布函数表达如下:
而Odds的分布区间则为 
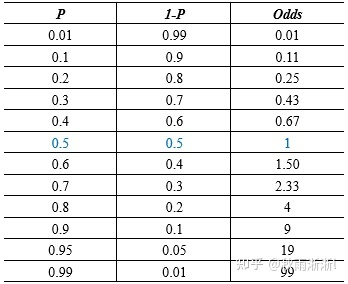
表1.0 Odds和概率P之间的关系(引用参考文献1)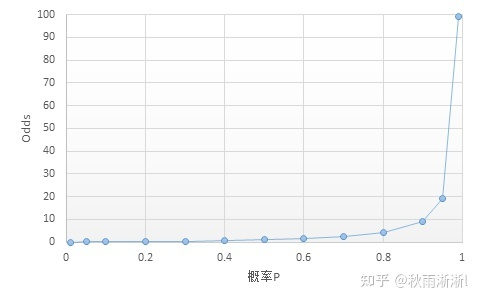
图1.0 概率P和Odds之间的关系 (引用参考文献1)
1.2 Logit=log(Odds)
让Odds和Logistic 联系起来的是Logit。而Logit的函数表达也很直观,它就是将Odds做了一个Log。
图1.1 概率、Odds和Logit的关系(引用参考文献1)
于是有:
(1-2)等式最右边的为Logit的假设函数。
把(1-2)中的Log换成在机器学习更方便求导的Ln可得:
在(1-3)的基础上,我们来考虑求解概率P,于是有:
那么,对(1-4)两边消去Ln,可得(1-5)
而在(1-5)的基础上,我们容易得到如下推导过程:
于是(1-6)系列的推导结果是:
而(1-7)则是我们非常熟悉的sigmoid函数,也是Logistic分布中,当u=0,r=1时候的一种形式。
1.3 结论
于是基于上述推导,我们可以得到的结论如下:
- Logit模型的左侧是Odds的对数(如式1-2),而Logistic模型的左侧是概率(如式1-7)。
- Logit模型的右侧是一个线性结构(如式1-2),而Logistic模型的右侧是非线性的(如式1-7)。
- 二者可以相互转化如(如式1-5与式1-6)。
2. Youtube DNN serving函数解析
有了上述知识的铺垫,我们就可以进入正题了。
如原文所说,Youtube DNN模型要学习的是用户点击的Odds。在原文中,其Odds表达如下:
其中,N为曝光给用户的总样本量,k为用户点击的正样本, 为用户观看视频的总长度。
为用户观看视频的总长度。
但有了第一章的讨论,我们知道Youtube模型的Odds显然做了某种变形。在这个时候,我们就需要再看一下上下文的信息了。
从原文“the positive (clicked) impressions are weighted by the observed watch time on the video. Negative (unclicked) impressions all receive unit weight”这句话中,我们可以知道的是,Youtube给每一个正样本做了加权,而加的权重则是用户观看视频的时长T_i,同时负样本不做加权。
基于这个条件,我们就可以尝试为(2-1)的计算做一个推导,看看是不是因为这加权导致的,毕竟在图0.1模型的training部分我们也可以看到有一个weighted Logistic的过程。
首先,在用户是否点击视频显然符合伯努利分布,于是可得用户点击视频的概率为: 。
。
于是有:
又由于Youtube为正样本按T_i加权,于是有:
其中E(T_i)是用户观看时长的平均值(期望)。
讲到这里,我们得到了Youtube预测函数的前半部分,即理清楚了它的Odds是怎么来的。
同时如原文所说,由于N>>k,所以P的先验值非常的小,以至于可以小到忽略不计,于是可以推导出Odds≈E(Ti)(这解释了问题1,用e^{wx+b}来学习E(T_i))。这样线上预估的时候推测的就是用户观看视频的时长,非常符合Youtube这种视频网站的商业目标。
但让人费解的是,原文紧接着说:由于p接近于零,于是给出了Odds are approximately (1+p)E(T_i)的结论。
而这就让人很迷惑了,因为基于我们的推导,我们得出的结论Odds是(2-3) Odds=E(T_i)/(1-p)这个形式。
由于原文只给出了  的结论,并没有给出推导过程,让我一度以为原文写错了。本来我打算放弃这个深究这个问题,毕竟这个论文的精髓不在这里。但奈何这个问题让我非常的纠结,最后我还是想尝试来理解一下是否有写错之外的可能。于是便在朋友圈的发起了场外求助下,幸运的是我最终得到了一个make sense的答案。
的结论,并没有给出推导过程,让我一度以为原文写错了。本来我打算放弃这个深究这个问题,毕竟这个论文的精髓不在这里。但奈何这个问题让我非常的纠结,最后我还是想尝试来理解一下是否有写错之外的可能。于是便在朋友圈的发起了场外求助下,幸运的是我最终得到了一个make sense的答案。
考虑p是一个接近于0的值,那么我们可以让1/(1-p)在0点做一阶泰勒展开,同时为了方便书写,我们令  ,于是有f(p)的泰勒展开如下:
,于是有f(p)的泰勒展开如下:
而f(p)的在零点的一阶导数等于  ,于是在1/(1-p)在0点做一阶泰勒展开结果如下:
,于是在1/(1-p)在0点做一阶泰勒展开结果如下:
于是,我们得到了从(2-3)的基础上得到了Odds are approximately (1+p)E(T_i)的这个结果。
如果上述推导是正确的,那问题2就真相就大白了。当然如有路过的同学觉得这个解释不对,欢迎在留言区指出。
3. Logistic Regression 损失函数推导
文章写到这里已经和Youtube模型没有什么关系了,如果不关心Logistic Regression(以下简称LR) 损失函数求导精妙之处的可以退场了。
为什么要将Logistic Regression 损失函数推导呢?主要是因为在翻看资料时,一个已经有让我点模糊的表达式的出现:
(3-1)这个式子,懂的都懂,是逻辑回归损失函数(对数似然函数)的导数形式。
我之说它精妙,是因为(3-1)的表达的梯度计算方式,似乎有过分简单的嫌疑了。这一点可以对比LR的损失函数(3-2):
虽然以前推导过(3-2)到(3-1)步骤,但可能是时间久远,又可能是当时学的不扎实,我有点忘了,于是今天又用两种方式推导了一下。
3.1 Logistic Regression损失函数的由来
先简单的给一下Logistic Regression损失函数的由来。
LR的表达式如下:
其中,x为特征空间,w为x对应的参考空间。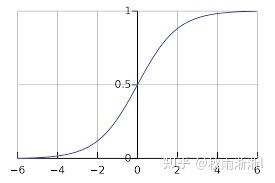
图3.1 Sigmoid 函数图像
于是在求解w时,LR使用了统计学中常用的极大似然估计法来求解。即找到一组参数,使得在这组参数下数据的似然度(概率)最大(但这不是LR损失函数的最终形式)。
于是可设:
所以,LR的似然函数为:
但(3-5)的形式并不适合机器学习中的梯度求导,因此会处理成对数似然的形式:
对(3-6)进行简化得到:
最终为(3-7)乘以一个 ,进而将求对数似然函数的极大值为问题转化为求极小值问题后,就得到了LR最终的损失函数的最终形式(3-2)。
,进而将求对数似然函数的极大值为问题转化为求极小值问题后,就得到了LR最终的损失函数的最终形式(3-2)。
接下来让我们对LR的损失展开推导。
3.2 LR损失函数导数求解过程

我们把等式按➕分割得到左右两部分,同时给出  的求导结果:
的求导结果:
于是(3-8)➕左边部分的求导结果为:
➕右边部分求导结果为:
将左右相加得到如下式子:
最后我们再为(3-12)乘上  就可以得到(3-1)的最终求导形式。
就可以得到(3-1)的最终求导形式。
至此,LR的对数似然函数求导完毕。如果你是一位初学者,不知道是否会能感受到这个过程的精妙。
当然除了上述求导方法之外,我们也可以在(3-7)的基础上,直接把p(xi) = sigmoid(xi)代如方程进行求解,结果都是一样的,在此不做推导展开。
参考文献
- EricG:Logit究竟是个啥?——离散选择模型之三
- 阿泽:【机器学习】逻辑回归(非常详细)
- 如何通俗地解释泰勒公式?
-
B-6.推荐系统架构浅谈
0. 背景
近半年来,本专栏分享了不少经典推荐算法,并从算法的架构、原理、发展脉络以及实现细节等多个角度展开了或浅或深的剖析。
在这些算法里,有最为经典传统的CF,也有在浅层模式时代大杀四方的LR,以及在LR基础上发展出的FM、FFM、LS-PLM(MLR)以及GBDT+LR(后几者是浅层推荐算法中非线性模型的经典代表)。
在深度推荐算法中,专栏先是回顾了神经网络中的核心基操Embedding,并对Embedding中最为经典的实现方法word2vec、Item2vec以及Graph Embedding类的DeepWalk、Node2vec、EGES展开了详细的讨论,同时还基于movielens数据集给出了Embedding PySpark实现。
而后,参考知乎大V王喆、阿里妈妈前算法总监朱小强等的文章,专栏对自2016年开始火爆的深度推荐模型发展演绎做出了总结,并挑选出了笔者认为最为经典的近10个深度模型,然后从算法架构、原理、发展脉络以及实现细节等多个角度展开了深度的剖析,旨在深度挖掘其演绎精髓。
这一路的学习和总结出的文章数量虽然不多,但却基本回顾了推荐算法近20年的发展历程。正当笔者兴高采烈地想去学习一起其它知识时,忽然意识到有两个重要的知识点被遗漏了,它们是: 推荐系统的架构
- 推荐系统架构中的召回算法
考虑到这两者在推荐知识领域的重要性,笔者还是按捺住了学习新知识的雀跃之喜,决定花一些时间来对它们进展复习和总结,特别是在算法层面往往被大家忽视的推荐召回(召回这块内容比较多,后面会单独开文章来讨论,本文不涉及具体具体召回方法讨论)。
1. 推荐系统架构
1.1 算法和系统的区别
如果你是一个初学者,不知道你有没有这种困惑:推荐算法和推荐系统是啥关系?
不过这个问题并不难回答,我们几乎可以脱口而出:推荐算法属于推荐系统中的一环。
考虑到推荐算法被广泛的提及与研究、加之算法工程师总给给人一种”高端“感,我们几乎可以很自信的为上面回答中再加一个程度修饰词:推荐算法属于推荐系统中最重要、最核心的一环。
公允的来说,最重要、最核心这个修饰词这么加是没有问题的。
不过问题来了,推荐算法是推荐系统的一环,那其它几环是啥?它们扮演的角色又是什么?
1.2 推荐系统架构图—baseline
在回答上述问题,我们可以不妨先看看图1.1这个极简推荐系统逻辑图。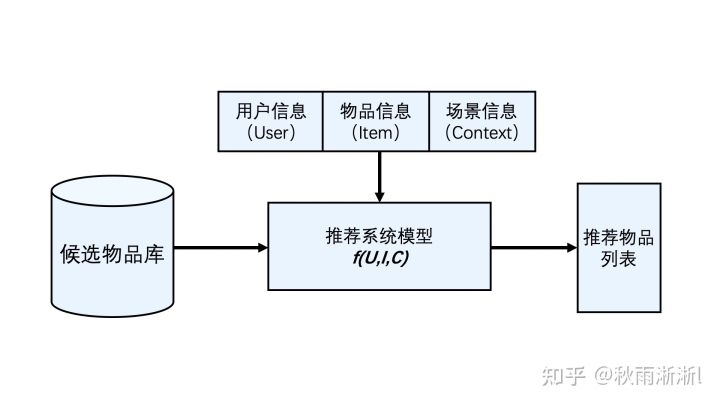
图1.1 推荐系统逻辑架构(图出于王喆《深度学习推荐系统实战》)
如图1.1,推荐系统可以高度概括为  ,这个极简定义源于推荐系统核心要义:基于用户(User)+物品(Item)+场景(Context)信息,从系统中的物品库中,给对应的用户推荐相应的物品,也即实现所谓的”千人千面“。
,这个极简定义源于推荐系统核心要义:基于用户(User)+物品(Item)+场景(Context)信息,从系统中的物品库中,给对应的用户推荐相应的物品,也即实现所谓的”千人千面“。
基于图文1.1,我们可以看到的推荐系统完成一次推断的流程为:
- 读取数据(ETL)
- 读取用户数据
- 读取物品数据
- 读取场景数据(实时上下文数据)
- 读取候选物品库数据(这里有很多召回的知识)
- 算法模型打分
- 有算法模型,意味着存在模型训练的过程
- 推荐结果展示
- 按打分结果排序
不过这个流程还是比较简洁的,只是对整体流程做了简单描述,接下来让我们再换一个稍微复杂一点的图。
1.3 推荐系统经构图—经典的Netflix推荐架构
在上一小节,我们基于推荐系统的最小版本图指出了推荐系统的核心组织部分,本章节就让我们基于Netflix于2013在官方博客中发布的经典推荐架构图,来理解一下推荐系统中各个环节的的具体位置。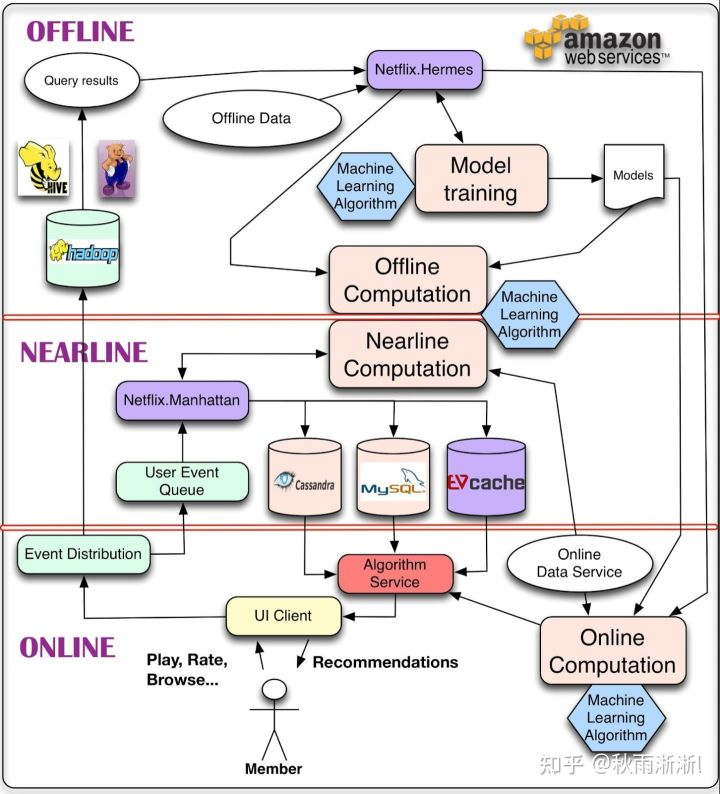
图1.2 Netflix推荐系统架构图(发布于2013年)
如果先不看图1.2中诸如HIVE/MySQL等具体的功能组件,我们发现Netfix在整体上把推荐系统分为了三个部分,分别是:
- offline—离线
- nearline—近线
- online—在线
如果你是一个初学者,你或许不能立马反应过来这么切分的原因,但如果你对推荐系统有基本的研究,Netfix的这个做法你应该觉得是一个基本操作了。
具体的来说,Netfix的这个切分方法是因为推荐这件事情本质是data driven的决定的,而推荐在不同环节所需的处理的data量级和需要的读取速度又是大大不一样的,比如:
- 需要优化某个算法时
- 需要分析海量数据,从而获取算法优化的大方向
- 开始算法模型训练时
- 算法模型需要吞噬海量数据,才能获得一定的预测能力(预测CTR/CVR)
- 算法模型在线推断时
- 需要极短的时间内(100ms级别),读取到模型所需的特征并完成推荐召回 + 推荐精排
于是我们很容易知道,Netfix的三段式架构是也是源自于data driven,即有:
offline—离线
- 基于HIVE、Hadoop等分布式数据存储系统存储海量数据,从而给算法训练(优化)提高丰富原材料,进而完成离线的model training 。
- 在这个阶段对数据读取的响应速度没有很高的要求,只要保证数据可达即可。
nearline—近线
- 把算法模型所需要的特征数据,存储到读取时延更低的Cassandra/MySQL等中,在数据获取上减少推断时延。
- 定期更新(1分钟、半小时)算法模型所需要的特征数据,保证特征的实时性。
- 近线更新算法模型,提高模型实时性。
online—在线
- 基于用户属性+场景信息对召回活动做在线打分,并把结果推荐给用户(整个环节需要在100ms这个量级内完成)。
- 存储、分发用户和推荐系统的在线交互日志,用于推荐系统的下一次迭代。
于是在1.2小结的基础上,我们可以把推荐系统的推断流程丰富为:
- 读取数据(ETL)
- 读取用户数据(离线+近线+在线)
- 读取物品数据(离线+近线+在线)
- 读取场景数据(离线+在线)
- 读取候选物品库数据(在线)
- 算法模型训练
- 离线训练
- 近线迭代
- 算法模型打分
- 在线
- 推荐结果展示
- 在线
- 存储数据
- 记录用户和推荐系统的交互日志(在线+近线+离线)
至此,我们基本得到了一个工业级的推荐系统的推断流程,并对离线、近线、在线做出来了区分,非常好,不过我们还没有给出每个环节的技术栈。
1.4 推荐系统经构图—在今天的视角(2021)
在1.2和1.3两个小结,我们讨论了一个推荐系统架构的基本组成,并以Netflix 2013年发布但流行至今的推荐系统架构图分析做了补充分析,但上述两小节的讨论没有很好的展示出当前的推荐系统技术栈(不过1.2和1.3的讨论仍旧是必要的,由简到繁可以深化我们对知识的认知程度)。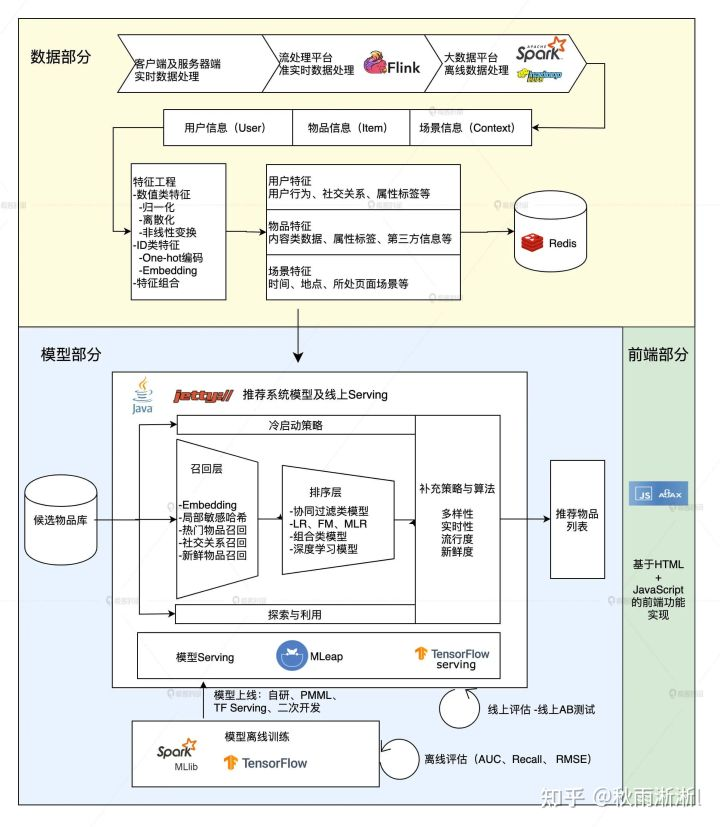
图1.3 推荐系统逻辑架构(图出于王喆《深度学习推荐系统实战》)
简答的来说,图1.3依旧可以套用Netflix的结构图来理解,如数据部分我们可以看到offline和nearline ,模型部分也同样是包括offline、nearline以及online三中形式(此处不具体指出三个部分具体为那个步骤,感兴趣的同学可以自己尝试回答),而其中体现的当前主流技术栈如下:
在数据ETL方面:
- 在数据采集上,可以采用流行的是Flink;
- 在离线批量计上,可以采用流行的是Spark;
- 在底层数据存储上,HDFS仍不过时;
- 在存储(U,I,C)的近线在线特征时,Redis能扛能打;
- 图中还给出了(U,I,C)的常用特征和特征工程细节
在模型推断方面:
- 算法层:
- 召回+排序
- 召回和排序需要分开做,是大数据场景下的基本操作
- 图中给出了经典的召回+排序算法选型,此处不细说。
- 重排层
- 打散,在精排给出的准确性因子上增加多样性、新鲜度、流行度等因子
- 冷启动推荐策略
- 召回+排序
- 算法工具层:
- TensorFlow,算法开发成本直线下降
- Spark MLlib,分布式计算你值得拥有
- 模型性能预估:
- 离线 AUC/Recall/RMSE
- 在线AB Testing
于是在1.3小结的流程上,我们还可以再做补充如下:
- 数据ETL
- 读取用户数据(离线+近线+在线)
- 读取物品数据(离线+近线+在线)
- 读取场景数据(离线+在线)
- 读取候选物品库数据(在线)
- 对上述数据做离线做特征工程,然后导入近线和在线层数据库
- 可用技术栈 HDFS(离线)+Spark(离线)+Flink(在线+近线)+Redis(在线+近线)
- 算法模型训练
- 离线训练
- 评估指标 AUC/Recall/RMSE
- 近线迭代
- 可用技术栈 TensorFlow/Spark MLlib
- 离线训练
- 算法模型打分
- 在线
- 存在召回+排序+重排三个阶段
- 技术栈 CF/LR/FM/MLP
- 推荐结果展示
- 在线
- 线上效果评估
- AB Testing
- 存储数据
- 记录用户和推荐系统的交互日志(在线+近线+离线),用于cycle上述流程。
在上述流程中,有一个之前没有提及的推荐环节。这个环境不直接与用户相关,但却与算法模型优化迭代息息相关,如果没有这个环节,推荐系统于推荐算法工程师而言无异于裸奔。这个重要的部分是:
- AB Testing
AB Testing ,熟悉它的工程师都知道,它是用于衡量某值算法上线后带来的真实收益情况(这里的收益可以是CTR/CVR/ecpm等),从而让我们知道某个算法是否和离线预估表现的一致,是否值得上线替代老版本的算法。
1.5 小结
在1.4小结中,我们给出了一个比较完整的推荐系统架构。至此,我相信你对本章开头的问题:“推荐系统其它几环是啥?它们扮演的角色又是什么?”有了一定的答案。
但是推荐算法与推荐系统中其它环节的革命分工虽然不同,但却环环相扣,每一环出现错误都会使得线上最终的展示结果不理想。因此我们需要知道的是,推荐系统里不只有推荐算法,尽管算法很重要、很核心,但它要发挥作用是有许多依赖项的。另外,在推荐系统中的各个环节都需要大量的工程师,所需要的技术也不一定会比推荐算法复杂多少。
最后再借微博机器学习负责人,张俊林大佬的图简化一下上述流程:
图1.4 工业级推荐系统整体架构(深度学习时代)
2. HDFS+Spark简介
在上述章节,我们由简到繁的剖析了工业级推荐系统架构的整体框架。在本章节,我们将对推荐系统数据ETL部分的HDFS及Spark做概要阐述。
2.1 HDFS
首选是分布式文件系统HDFS。
熟悉大数据平台的同学应该都知道,HDFS是谷歌三论文中的GFS的开源实现,是Hadoop生态中最重要的组件之一。其设计之初就是为了解决海量数据中的存储问题,经过数十年的发展,如今已经具备良好的容错性、易用性及动态扩容能力。同时,其块级别的分布式设计理念,使得其具备良好的负载均衡和并行处理能力,是目前许多大型推荐系统构建存储平台的首选,也是底层基石般的存在。
如下图2.1所示,HDFS采取分布式集群中经典的Master/Slave(主从)架构,Master(主节点)被称为NameNode(名称节点),Slave(从节点)被称为DataNode(数据节点)。其中NameNode由FsImage及EditLog两部分组成,主要负责管理和维护系统中数据的元信息和所有的DataNode,当其发现某个DataNode没有向其发送正常的心跳信息,NameNode会通知其它正常活动的DataNode对数据进行备份。DataNode的角色则是存储Client写入的实际数据,HDFS中存在多个DataNode节点来对写入的数据进行分布式存储。
图2.1 HDFS架构图
另外,HDFS中只存在一个Master节点,当Master节点出现故障不能与Client及Slave节点进行通讯时,HDFS则会启用处于备用状态的Standby NameNode节点来替换原来的Master。
HDFS的主节点备份和分布式存储使得其具备着优秀的动态容错性能,同时其允许分布式文件集群运行在大量廉价的服务器上,使得HDFS被广泛应用成为了可能。
2.2 Spark
Spark是一个基于内存式的高性能DAG(Directed Acyclic Graph)计算引擎,非常擅长于处理大规模数据的迭代式及交互式计算。与另一个常用的计算框架MapReduce相比,Spark不仅拥有着MapReduce的并行计算能力与容错性等能力,还具备着性能高效、编程灵活、通用性强等特点。
在架构上,Spark沿用Hadoop的主从分布式架构,组成成员主要包括集群管理器(Cluster Manager)、工作节点(Worker Node)、Master服务器上的Driver节点以及每个节点上具体执行任务的执行进程(Executer)。在组成结构上,Spark具备批处理组件Spark Core与Spark SQL、流式处理组件Spark Streaming、图计算组件GraphX以及强大的机器学习组件ML,能够一站式地解决应用场景中的大规模数据处理任务。在生态上,Spark与Hadoop生态有着完美的集成,有着能够对HDFS、HBse及Hive等访问的能力。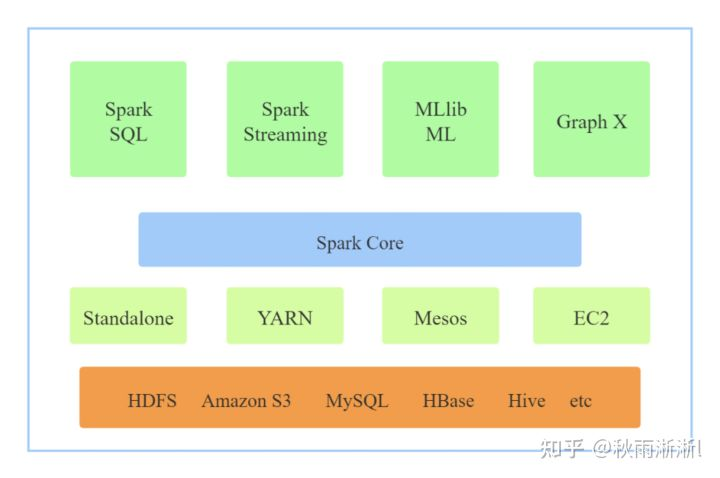
图2.2 Spark计算引擎生态系统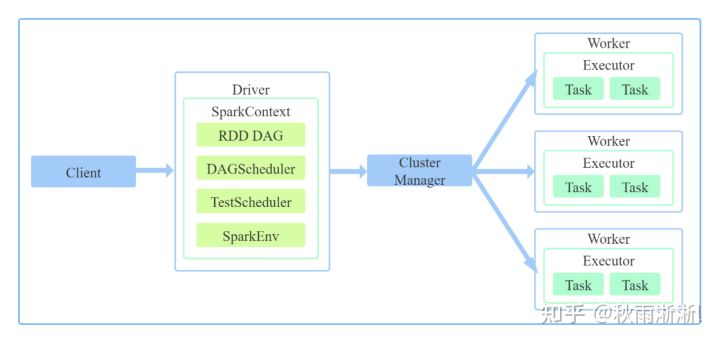
图2.3 Spark系统架构
另外,近两年江湖上时不时的就有传言说Spark要被Flink干掉。但怎么说呢,它们各有所长,至少在在离线数据处理和ML这方面Spark仍然值得拥有。
3. AB Testing
AB Testing,推荐算法的试金石。
如果你是一位没有在工业级实践过的同学,你大抵没有接触过AB Testing,因为有AB Testing意味着有实时服务。但遗憾的是,实时的推荐在学校或者机构一般是难以接触到的,比如笔者在学校期间就一直没有机会接触到实时推荐这块。
3.1 AB Testing的意义
简单的来说,AB Testing的意义在于:
- 离线评估无法完全消除模型过拟合的影响,因此,得出的离线评估结果无法完全替代线上评估结果。
- 离线评估无法完全还原线上的工程环境。
- 一般来讲,离线评估往往不会 考虑线上环境的延迟、数据丢失、标签数据缺失等情况。
- 因此,离线评估的结果 是理想工程环境下的结果。
- 线上系统的某些商业指标在离线评估中无法计算。
- 离线评估一般是针对 模型本身进行评估,而与模型相关的其他指标,特别是商业指标,往往无法直接获得。
- 比如,上线了新的推荐算法,离线评估往往关注的是ROC曲线、P-R曲线等 的改进而线上评估可以全面了解该推荐算法带来的用户点击率、留存时长、PV 访问量等的变化。这些都要由A/B测试来进行全面的评估。
- 注:引用《百面机器学习》2.4章节内容
粗暴点的说法:
-
3.2 AB Testing的流程
AB Testing的流程讲起来也很简单。
假设我们要上线A算法通过了我们的离线预估,准备上线来与线上正在跑的B算法battle一下。
那么通常的AB Testing流程是: 在线上的流量池中,切出一部分流量来给A算法(我们令这么份流量为实验组)
- 同时为了方便对,我们也会切出等量的流量来给B算法(同样我们令这份流量为对照组)
- 让这两个算法分别再各自的流量中运行一段时间,看看最终在线CTR/CVR等商业指标的表现情况如何。
而其中的流量则指的是用户,同时在实验期间:
- 实验组有且仅能看到A算法效果;
- 控制组有且仅能看到B算法效果
因此AB Testing环节的精髓便在于,怎么”公平“的切分流量。即让两个流量组的用户分布均匀,不会存在实验组用户和控制组用户区分性太大,因为区分性太大流量就有偏了,做出来的实验效果自然不可信。比如实验组美国的用户占比为80%,而控制组的用户美国的用户的10%就是一个分流非常差的结果。
而对于怎么做流量划分则相对细节,此处不展开说明,大抵都是一些LSH的做法
4. 结束语
本文由简到繁再到简的方式介绍了推荐系统的架构组织,并对ETL中常用的HDFS和Spark以及在线评估工具AB Testing展开了必要的说明,而其中的推荐召回我们将保留到下一篇文章中来讨论。
最后,希望本文对你有所帮忙,同时也欢迎在留言区指出描述不当指出。
参考文献:
- Netflix推荐系统架构图博文(2013)
- 《深度学习推荐系统》王喆
- 《百面机器学习》

若有收获,就点个赞吧
0 人点赞
