作者:青枫拂岸
链接:https://zhuanlan.zhihu.com/p/450956744
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
今天带来一篇Airbnb 在2020KDD针对于其搜索业务的论文——《Improving Deep Learning For Airbnb Search》。
将深度学习应用于搜索排序是Airbnb最大的提升之一。在应用了深度模型之后,有三个未来可以提升的方向,分别是:architecture、bias和cold start。文章围绕着这三个方向分别给出了探索性的解决方法。堪称一篇工程化论文的范本。
1.背景
Airbnb是全球性的房屋租赁平台,链接房主和房客。Airbnb的搜索排名是针对用户搜索的结果房源进行排序的操作,查询通常包含:位置、人数、入住/退房时间。Airbnb已经在[1]中是运用了深度学习,并起到了不错的效果,接下来如何优化,方向是什么?
2.架构优化
深度学习的最终奥义是什么? 是添加更多层。但是层数与带来的收益并不是正比的。经过一系列的调研实验我们得出结论:增加层对于CNN来讲可能是有效的技术,但是并不一定适合所有DNN。对于FC来讲,2层足以,模型的容量已经满足。
更深的结构没有效果的话,应该探索更专业的结构设计。在搜索模型中,作者试图引入query与lists之间的交叉特征,网络选择wide&deep。交叉特征放入wide部分。接下来是各种基于Attention的网络模型。目的利用Attention聚焦于某些隐藏层输出。但是实验结果并不理想。
可能的解释是一个优秀的架构,结构的性能与其上下文有关。由于深度学习普遍缺乏可解释性,因此很难准确推断新体系结构解决了哪些缺陷以及如何解决这些缺陷。那么如何确定架构的存在哪些缺陷?为了提升成功的可能性,Airbnb抛弃了(下载论文—>复现结构—>A/Btest)的模式,采用了一种非常简单的准则:user lead,model follows 进行分析。
2.1 user lead,model follows
我觉得可以翻译为 用户导向,模型为辅。文中给出的含义是:首先量化用户问题。模型随后进行调整,以此响应用户问题。
沿着这些思路,我们首先观察到,[2]中描述的一系列成功的排名模型发布不仅与预订量的增加有关,还与搜索结果平均市场价格的降低有关。这表明模型迭代正在接近用户的价格偏好,但是该价格低于先前模型的估计值。
作者怀疑即使连续降价,模型选择的价格也会和客户存在差距。为了量化这种差距:研究用户搜索结果的中间价格与用户预订房屋的价格之间的差距。对价格进行log处理,使价格符合正态分布。下图描述了两种价格的差值: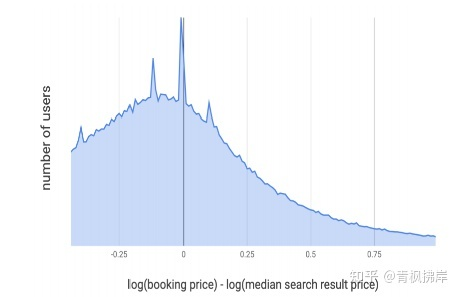
X轴显示预订列表的价格如何与客户搜索结果的中间价格比较,Y轴是对应于价格偏移的用户数。
文章作者预计结果是以0位中心的正态分布,但是结果显而易见,上图是明显向左倾斜的,用户更倾向于预定低价房源。
这带来一个问题:
更接近客人偏好价格的低价房源是否需要排名更靠前?
排名模型真的理解了Cheaper Is Better 原则吗?我们不完全确定。
2.2 Enforcing Cheaper Is Better
模型缺乏可解释性的原因是我们采用了DNN的模型,它不像LR或者GBDT可以计算特征权重。为了让价格这个特征更具有解释性,作者进行实验:
- 移除DNN中中相关price的特征。DNN变为
![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图2](/uploads/projects/lianghan@zengzhang/7460a59cb6063dc9b9a561365ee4ea12.svg) ,其中
,其中 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图3](/uploads/projects/lianghan@zengzhang/ad91d6b79b36e6ef1a9f3999285f6792.svg) 是DNN的参数,u是user feature,q是query feature,
是DNN的参数,u是user feature,q是query feature, ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图4](/uploads/projects/lianghan@zengzhang/c863814da12786c3f268564ea09e4037.svg) 是去掉price的listing feature。
是去掉price的listing feature。 - 模型最终的输出为:
![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图5](/uploads/projects/lianghan@zengzhang/8c7803254c546a779aaf12da05638ee4.svg)
其中,![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图6](/uploads/projects/lianghan@zengzhang/679ccaba1cfebeb5e57b4c1a3209e9d7.svg) 为原始价格特征,
为原始价格特征, ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图7](/uploads/projects/lianghan@zengzhang/eca458d8175dda837349d2f46b7cd529.svg) 则是通过计算得到的常量。
则是通过计算得到的常量。![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图8](/uploads/projects/lianghan@zengzhang/1a12df7b08ecd8d6cf807459590e2463.svg) 和
和 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图9](/uploads/projects/lianghan@zengzhang/e4b620d9713bfa55d6ae1ba1bb18018c.svg) 都是需要学习的参数;
都是需要学习的参数; ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图10](/uploads/projects/lianghan@zengzhang/2af195b8617605940da38adb5e094758.svg) 引入了单调性,因为当w>0,模型能够保证Cheaper Is Better的原则。如下图所示:
引入了单调性,因为当w>0,模型能够保证Cheaper Is Better的原则。如下图所示: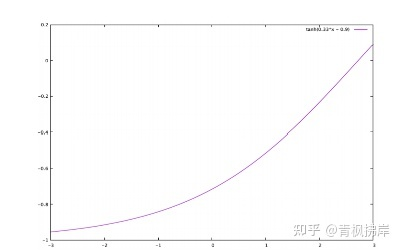
y轴为目标函数,即上面公式,x轴为标准化的价格特征
经过学习,参数得到确定 w=0.33和b=−0.9。这两个参数可以提供解释性。但是采用这种方式的线上A/B test的表现并不好。搜索结果的平均价格下降了5.7%,与线下训练结果一致。下单率下降了1.5%,作为可解释性增强的代价。足以说明:price特征和其他特征有比较强的特征交互,孤立price特征导致了模型的欠拟合。在训练集和测试集上NDCG都下降了,这也印证了这一点。
2.3 Generalized Monotonicity 广义单调性
为了保留cheaper is better,同时让价格特征和其它特征进行交互,文章参考[2]的网络架构,Lattice networks是一种解决方案,但是全部改动太复杂,这里提出了一种只改变price特征交互,其他特征不变的结构如下图所示: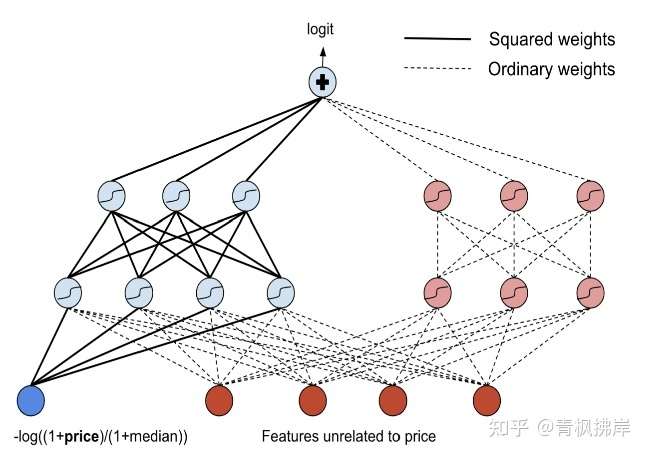
虚线部分就是普通DNN,实现部分则是和price特征进行交互的经过改动的网络。
- 我们将
![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图13](/uploads/projects/lianghan@zengzhang/6f221358479e835537ef87f48d14ba93.svg) 作为特征输入到DNN中(关于价格是单调递减的);
作为特征输入到DNN中(关于价格是单调递减的); - 在输入层,我们不是将
![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图14](/uploads/projects/lianghan@zengzhang/c83456042fc4d3190d44ee84fabbc725.svg) 乘以权重,而是乘以权重的平方。由于
乘以权重,而是乘以权重的平方。由于 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图15](/uploads/projects/lianghan@zengzhang/a915a0a1819186cdb54f2c60af58b80a.svg) 对于w和b的任何实值都是单调递减的,因此第一隐层的输入总是随着price而单调递减;
对于w和b的任何实值都是单调递减的,因此第一隐层的输入总是随着price而单调递减; - 对于给定的隐藏层,我们使用tanh激活函数来保证单调性;
- 给定
![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图16](/uploads/projects/lianghan@zengzhang/1b8967ec207c9fc12913983f6420cae9.svg) 和
和 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图17](/uploads/projects/lianghan@zengzhang/a97e494939a9777f137a4c5824ff4339.svg) ,x的两个单调递减函数,
,x的两个单调递减函数, ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图18](/uploads/projects/lianghan@zengzhang/b3745d2473a80024e90e794d4233e2a7.svg) 也是关于x单调递减的。关于
也是关于x单调递减的。关于 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图19](/uploads/projects/lianghan@zengzhang/b154dc84aedf2308bb9d92e30286c5a4.svg) 和
和 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图20](/uploads/projects/lianghan@zengzhang/38bb590b1a2fd1f0a8f399990efcad93.svg) 可以是任意的权重,我们在第二个隐藏层和输出层中使用这个属性,其中所有的权重都是平方的。在上图中,第二个隐藏层和输出层用粗体实线表示;
可以是任意的权重,我们在第二个隐藏层和输出层中使用这个属性,其中所有的权重都是平方的。在上图中,第二个隐藏层和输出层用粗体实线表示; - 添加一个子网,该子网既没有price作为输入,也没有任何单调性约束,以允许其他功能之间的无约束交互。
尽管比第2.2节中描述的体系结构更灵活,但在线测试的结果非常相似,导致预订量下降了1.6 % . 与其前身一样,该体系结构强制要求模型输出结果都随着price单调递减。这种架构的失败表明,price方面的单调性是一个过于严格的约束。
2.4 Soft Monotonicity 软单调
不强调输出结果一定要和price负相关了,而是改变方向:添加一个soft 提示 来表达 cheaper was better。
一般做搜索模型时,一个query 的结果包含1对list,一个是点击 正例,一个是未点击负例。会根据这两个list的预测结果生成对应的loss,如下图:
为了增加价格的影响,论文引入了第二种label。在训练样本中标注哪个list 是便宜的,哪个是更贵的。对应新增一个损失函数为 priceloss:
loss变为两种损失的和,并利用alpha来平衡相关性和price的占比。
通过调整alpha让loss最小并与baseline model线下的NDCG相等。在线上的A/Btest中,发现搜索结果的价格平均减少了3.3%但是下单率也减少了0.67%。这和文章当初的 **_Cheaper Is Better **自相矛盾。可能的原因就是之前的分析受限于离线日志影响。只分析了re-ranking的结果。
2.5 Putting Some ICE
将price降低的实验给带来了相当大的困惑:搜索模型的结果价格比客户希望得高,但是降低了价格,客户反而不喜欢了。想探索问题到底出在哪里?有必要比较Baseline model是如何利用价格特征的,但这被DNN缺乏可解释性所掩盖。
所以只能去减少DNN的可解释问题。文章没有试图就DNN的价格影响做出一般性陈述,而是着重于解释一次搜索的一次结果。借鉴了[3]individual conditional expectation的想法,从单个搜索结果中获取列表,在保持所有其他功能不变的情况下覆盖所有价格范围,并构建了模型得分图。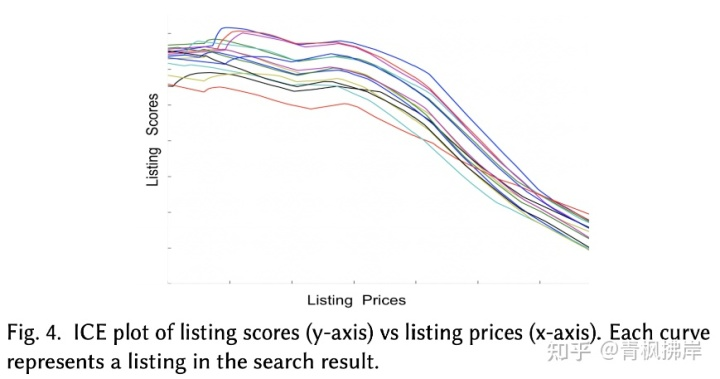
这个图可以看到,两侧的FC已经学到了Cheaper Is Better 。对从日志中随机选择的搜索集合重复进行ICE分析,进一步加强了这一结论。 但是试图进一步压低价格时,这样的方式设计的架构导致了最后失败。
2.6 Two Tower Architecture
回到第一张图: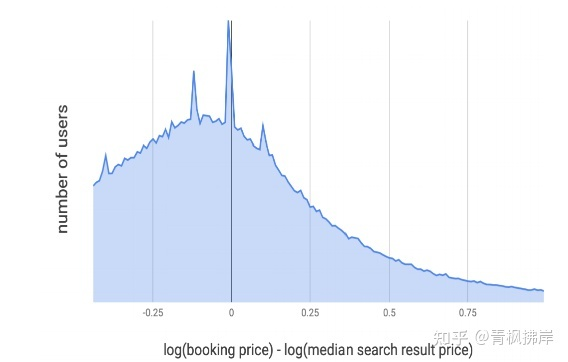
通过重新划分,再次试图去解释图1的现象。
计算客人的搜索结果的中间价格与他们预订的价格之间的差值,并计算了按城市分组的中位数价格的平均值。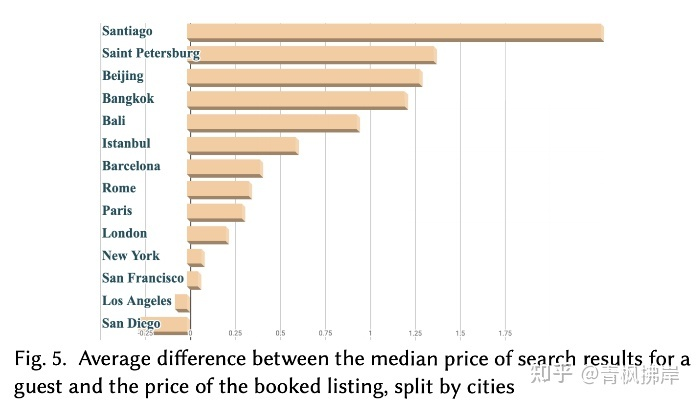
不出所料,城市之间存在差异,对比排名靠前的城市,排名靠后的尾部城市都处于发展中的市场。图5显示了预定不同城市中位数的平均值。
文章就提出了一个假设:模型结果由头部用户所影响,这些用户一般会对价格和质量进行一个权衡,而这个权衡一般取决于那些订单比较多的城市。而这个结果泛化到尾部城市会导致模型的失败。相当于少数服从多数原则。
新的想法是,该模型充分理解了“Cheaper Is Better ”的概念,但它缺少的是旅行的正确价格。掌握这一概念需要更密切地关注查询特征,比如位置,而不是纯粹基于列表特征进行区分。即更关注预订的地点。
这也引出了文章的三塔模型。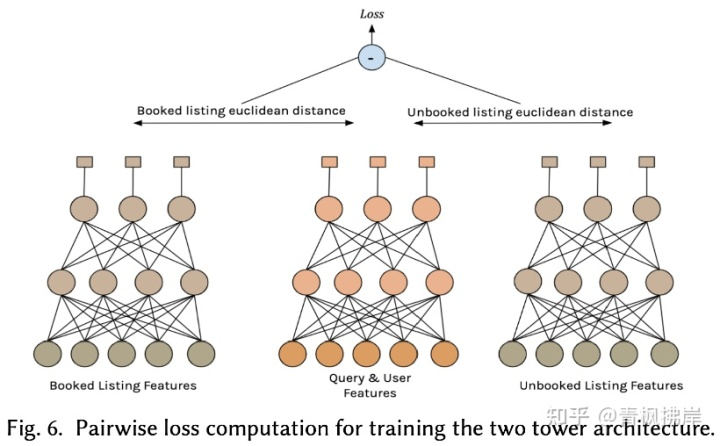
通过上图也很好懂,三个塔分别是query和user特征,预定房屋list特征、未被预定房屋list特征。构成一个三元组的结构,这样就能通过pairwise 的方式去训练模型。三个塔输出的向量分别为100维embedding。计算 user&query特征与book list和unbook list的欧氏距离,希望Booked list塔的输出更接近Query&User塔;让Unbooked List塔的输出更远离Query&User塔。
模型的简要代码:
图片来源:魔法学院的Chilia的知乎专栏
2.7 Test Results 测试结果
线上A/Btest,预订量增加了+0.6%,线计算的NDCG提高了+0.7%,尽管该架构并非直接以降低价格为目标,但我们发现搜索结果的平均价格下降了-2.3%,这是相关性增加的副作用。预订量的增加抵消了价格下跌对收入的影响,仍旧导致整体增长+0.75%。
2.8 Architecture Retrospective 模型回顾
查看ICE图,我们看到了一个显著的变化,曲线不是总是向下倾斜,不符合Cheaper Is Better 的解释,我们看到分数在某些价格附近达到峰值,如图7所示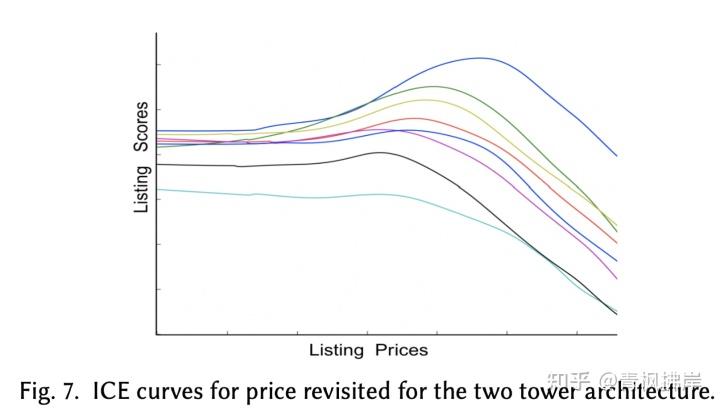
在这种情况下,经常提出的一个问题是,新模式是否可以简单地通过确定价格来提高低质量房源的排名。仔细检查ICE曲线发现,某些价格附近的得分峰值只出现在高质量的房源上,而这些房源一开始通常排在搜索结果的前列附近。对于大多数普通质量房源,相对于价格仍然保持单调递减曲线。
query和user特征塔输出的是正确价格和理想list的embedding,用其与候选list的embedding去做计算,以此来判断候选list的适配性。但是由于embedding 的维度为100,是无法解释的。文中作者使用了T-SNE算法将query和user特征塔输出embedding简化为2维向量,进行画图,如图8所示。并在图中对应标注了与图5中相关的城市和一些筛选条件。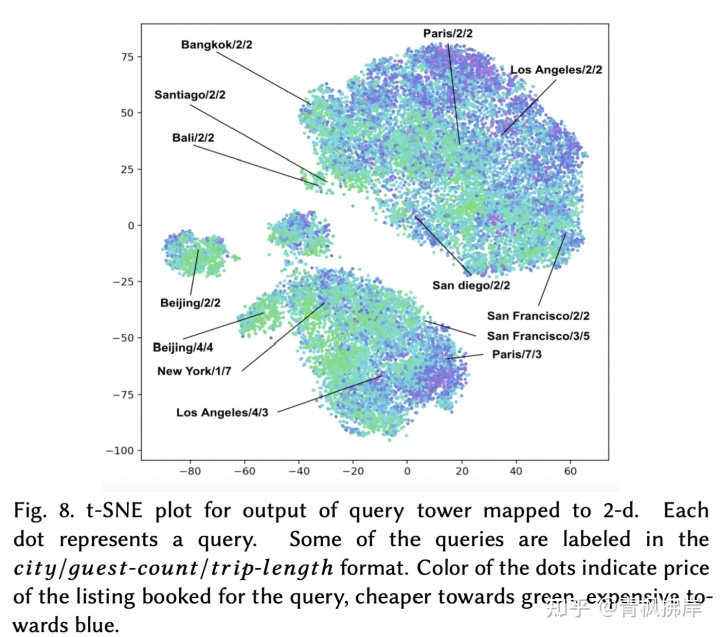
每一个点代表一次query搜索。图中标注 城市/游客数量/行程距离。颜色cheaper为绿色,expensive为蓝色。
图8说明:围绕着类似的参数值(如游客数量和行程距离)形成的大型类簇中,直觉上相似的城市彼此相对靠近。例如在游客数量/行程距离=2/2,可以看到 巴厘岛和曼谷embedding距离相近,巴黎和洛杉矶embedding距离相近。
值得强调的是,类簇不仅仅是按价格聚集的。可以看到每个簇都是蓝绿色相间的,这证明模型输出的结果并不一味地偏向更便宜的。虽然莫斯科通常比巴黎便宜,但莫斯科的订票价格很容易超过巴黎的订票价格(图8中并未体现),这取决于客人数量、停留时间、与旅游距离、周末与工作日以及许多其他因素。
价格与所有其他维度都有着千丝万缕的联系,掌握正确的旅行价格意味着同时掌握所有其他因素。我们所做的任何分析都不能作为确凿的证据,证明三塔式架构确实契合这种理解。但ICE图与价格、查询塔输出的t-SNE可视化以及对城市间价格变动的额外分析的结合,让我们充分相信的确如作者所想。
当架构修正后,开始着手更有挑战性的工作——冷启动问题。
3.冷启动问题
冷启动问题是所有推荐系统都需要面对的问题,分user的冷启动和item的冷启动。对于大多数公司而言,item冷启动问题更为主要,这篇文章也是从item冷启动来探索的。
与前文优化架构相似,作者探索的出发点依旧不是文献调查,而是对用户问题的观察。对搜索问题来说,使用NDCG量化预订列表搜索结果的位置是衡量模型性能最可靠的方法。
经过实验发现新上的房源list和以前存在的房源list会有一个6%的NDCG差距。继续做实验,就是舍弃掉item所有和user的历史交互相关的特征(e.g. the number of past bookings),模型的NDCG下降了4.5%。这说明DNN很依赖item和user的交互历史信息。而可惜的是,由于新的list没有这部分信息,所以DNN只能根据其他特征来进行判断。
Approaching Cold Start As Explore-Exploit EE探索
解决冷启动问题的一个方式是考虑explore-exploit trade-off:(E&E问题)
- exploit:利用已知的比较确定的用户的兴趣,然后推荐与之相关的内容
- explore: 除了推荐已知的用户感兴趣的内容,还需要不断探索用户其他兴趣
文中作者认为exploit可以短期内优化展示,获取收益上升,但是为了长期成功,需要成本进行explore。即对新的房源item进行曝光(提升排名),从而使得新房源item可以用较少的代价收集到user的反馈。这在电商领域很流行。并且可以通过印象计数(impression counts)或引入时间衰减进一步优化加权。进行线上A/B测试,将新房源排名提升,并为新房源分配了 8.5% 的额外首页展示次数。
E&E探索的结果也存在一些挑战:
1)搜索结果相关性降低导致短期内用户体验下降(可以实验量化)
2)长远来看虽然提升了订单率,但是这种方案缺乏一种明确的目标定义(这种影响很难量化)。这样会导致有的人觉得结果好,有的人觉得结果差,不会令所有人满意。
3)Explore问题:什么时候需要大量使用,什么时候不使用? airbnb 中Explore 策略取决了 特定位置的供求关系。有的地方需求高,那么他对Explore的容忍度也是高的。但是需求低的地方对Explore也是很低的。当房源供应充足时,Explore是必须的,但是当大量房源空置期,Explore的代价就很大了。供应和需求反过来又受位置、季节性和用户容量等参数的影响。因此,为了优化使用全局探索预算,需要数千个定位参数,这是一项无法手动处理的任务。计算量很大。
3.2 Estimating Future User Engagement 估算未来用户参与度
为了让系统更加可控,文章回到最开始的问题,是什么导致了冷启动问题,也就是说新list,与老list到底有何异同?
答案显而易见:缺少用户和item 的交互信息,如预订数量、点击次数、评论次数等。而其它基础属性是一致的,如价格、位置、便利设施等。从理论上讲,如果我们有一个组件可以100%准确地预测新item房源的参与特征,它就可以最佳地解决冷启动问题。
分析过后,作者将E&E问题转化为一个预估新房源item的用户参与度问题。从而引入了一个新的组件,为DNN提供支持,该组件在训练和测试时能够预测新列表的用户参与功能。
为了计算估计组件的准确性,我们采用了以下步骤:
1.从搜索日志中采样100M个结果。从每个结果的top-100中随机采样一个有用户行为的list,证明用户有参与度。
2. ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图30](/uploads/projects/lianghan@zengzhang/23b37d08537b8b335a32ad28014f5ca2.svg) 表示从日志中获得的item list的排名,作为真实标签。并计算discounted rank DR
表示从日志中获得的item list的排名,作为真实标签。并计算discounted rank DR![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图31](/uploads/projects/lianghan@zengzhang/b1c81d228267d5ca2b57d7051f0b1f37.svg)
3.对于list中的每个item,删除掉user engagement feature,然后用estimator预估的feature代替原本的feature。然后用新的特征预测在list的最新排名 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图32](/uploads/projects/lianghan@zengzhang/87b1afa5e871aa448fdbdb0318375547.svg) 。
。
4.最后计算 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图33](/uploads/projects/lianghan@zengzhang/408307a4c49961ebbf3fb6970e6773ef.svg) 和
和 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图34](/uploads/projects/lianghan@zengzhang/d815f4ea81c2b093ebb0dd2f6e5227a5.svg) 之间的误差平方和
之间的误差平方和![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图35](/uploads/projects/lianghan@zengzhang/47a2e2a1c605bcbef0ce68a13273de20.svg)
5.反复迭代,最终得到一个engagement feature的预估器。
为了验证特征预估器的有效性,进行了一组实验。baseline是生产系统中对engagement feature中缺失进行默认值填充,另一个是采用上文的预估器生成的特征值。预估器通过对冷启动房源item的地理位置附近的房源item的参与特征取平均值来预测参与特征。为了提高准确性,它仅考虑与新列表的访客容量匹配的相邻列表,并计算滑动时间窗口内的平均值以解决季节性问题。
例如,要估计两人入住的新房源的预订数量,需要计算两人入住的新房源小距离半径内所有房源的平均预订数量。这在概念上类似于[11]中的朴素贝叶斯迭代,它使用生成方法来估计缺失的信息。
3.3 Test Results
采用这种冷启动策略,对新item预定量14%的提升,首页item搜索结果分享率提升了14%。对于总下单率有0.38%的提升。,表明用户体验的全面改善。
接下来,进行对偏差问题的探索。
4.消除位置偏差
位置偏差和冷启动一样,是一个老生常谈的问题。有些位置点击率很高,有些位置点击率就是很低。
文章作者发现市场的精品酒店和传统带早餐床位效果不如如期。观察后,认为出现的问题是:位置偏差导致。但是作者也不是百分百确信,因为影响因素还有可能很多。为了探索,作者延续关注用户背身数据而非查阅文献,并且可以发现模型结果和观察显现之间的差距。
4.1 Related Work
给定一个用户 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图36](/uploads/projects/lianghan@zengzhang/e8a04cfa11b2c49d106bdd5904c3294a.svg) ,以及一个query
,以及一个query ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图37](/uploads/projects/lianghan@zengzhang/11a0884b12e4e4a31cc6922c746bd691.svg) 和一个list
和一个list ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图38](/uploads/projects/lianghan@zengzhang/af380d9611eac21567faa4d1a6607983.svg) ,以及list中的每个位置
,以及list中的每个位置 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图39](/uploads/projects/lianghan@zengzhang/2bc0f5d798e0befa8d45dbf278483bb9.svg) 。参考文献[4],用户预订的概率是:
。参考文献[4],用户预订的概率是: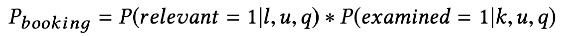
前部分是这个list被用户点击的概率,后半部分是item在位置K被用户点击的概率。两部分相加得到物品被点击概率。
作者希望理想模型下,只关注前半部分,仅根据相关性对列表进行排名。而不希望位置k影响模型结果。
4.2 Position As Control Variable 位置作为控制变量
这里并没有用position构建显示模型,而是作为一个正则项使用。训练时加入位置信息,预测时位置信息置0。
在2.6中的三塔模型中,使用q (query features), u (user features), l (listing features), θ (DNN parameters), 输出结果为: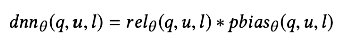
这里 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图42](/uploads/projects/lianghan@zengzhang/feb77988342d4f5b02ab9ffd3327d48e.svg) 为原始输出,表示相关性预测结果。
为原始输出,表示相关性预测结果。 ![22.01.02 [论文精读]12—Airbnb搜索排序:从模型驱动到数据驱动的转变 - 图43](/uploads/projects/lianghan@zengzhang/3496286e965629380e90c43e357f3845.svg) 称之为位置偏差预测。
称之为位置偏差预测。
将位置信息k添加进DNN中,由于后一项之和k有关,与l无关,公式变为: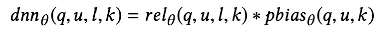
当进行预测时,k置0,输出结果变为: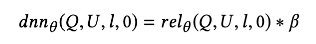
上述这些,读了几遍,并没有理解公式绕来绕去说了什么,后来查阅资料觉得下面的话可以很好地解释上面的一堆公式:来源自 坡哥说 的知乎专栏
位置特征k在模型中往往会起到很大的作用。训练中,这个特征如果过度拟合,那么会导致其他特征没有学习得很充分。在真实的线上预测中,这个特征一旦置0,其他特征学习得不好的情况下,会使得线上真实效果大打折扣,往往体现出来的情景就是:线下的NDCG指标有提升,但是线上的业务效果暴跌。
4.3 Position Dropout
正如上文所说,将position信息引入后,模型的NDCG下降1.3%。原因上文已经解释:训练时相关性的计算依赖位置信息,但在测试的时候,这个位置信息置为0。导致结果下降。
为了减少相关性计算对position feature 的依赖,文章采用了 训练阶段对position feature 进行dropout,即:在样本中以15%的概率把这个特征直接置0,这样至少在这些样本中,其他特征能和以前的模型一样,从未使学习更充分。
15%是怎么得到的呢?文中利用了网格搜索,在相关性预测和位置偏差预测之间,取一个平衡值。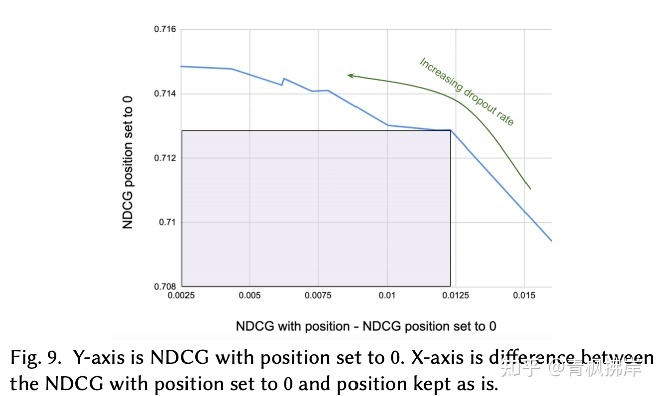
纵坐标是位置信息置0的NDCG,横坐标是 带位置信息的NDCG-位置信息置0的NDCG差值。随着dropout rate的增加,横坐标趋近于0,说明两个模型的NDCG差越来越小。这正是我们更希望的。
4.4 Test Results
dropout rate为0.15时,线上预订率提升0.7%。并且预定收入增加了1.8%。
这种方案就是想尽最大可能将训练和测试阶段保持一致同时又能减少相对性对position feature的依赖。这种方法简单可实现,效果上也不错。
5.总结与思考
整篇文章Airbnb从现有数据出发,分别从 架构(价格影响)、房源item冷启动、展示位置偏差 三点优化了当前的搜索排序模型。
针对于架构上:发现用户预订item的价格比模型的展现平均价格低,从而构建了3塔模型,将地理位置、价格等特征让模型充分理解。
针对房源冷启动问题,文章用离new item地理位置临近的、且客人数相等的老item的用户交互信息平均值来填充缺失值。如何划分临近程度,则需要迭代进行尝试。
针对item展现位置偏差,文章方法处理的更为简单,将位置信息输入到DNN中,并利用dropout 来使模型在训练和预测中均获得优秀的效果。
总结完文章,说点自己的感想:Airbnb摒弃了传统的模型迭代方式:读paper—>—>复现结构—>A/Btest,而是另辟蹊径直接从 观察数据—> 分析问题—>逻辑推演—>模型改动—>A/Btest 这一点的确令人耳目新,没有各种整活的奇淫技巧,体现了数据驱动生产力,返璞归真的感受。
文章信息密度过高,虽然文笔流畅简洁,但全篇读下来却也花了不少时间,但也给了很多启发:
- 神经网络并不是不可解释,可以通过ICE统计方法和t-SNE降维来侧面辅证模型有效性
- 根据业务来对双塔模型进行适当的改造,来符合自己的场景数据和逻辑假设
- 损失函数的设计上,不能生搬硬套,思考自己的业务下是否适用
- 位置偏差可以通过dropout来优化,不要认为基础方法不work,有时候很可能事半功倍
参考文献
[1] Malay Haldar, Mustafa Abdool, Prashant Ramanathan, Tao Xu, Shulin Yang, Huizhong Duan, Qing Zhang, Nick Barrow-Williams, Bradley C. Turnbull, Brendan M. Collins, and omas Legrand. 2019. Applying Deep Learning to Airbnb Search. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19). ACM, New York, NY, USA, 1927–1935. https://doi.org/10.1145/3292500.3330658
[2] Seungil You, David Ding, Kevin Canini, Jan Pfeifer, and Maya Gupta. 2017. Deep Lattice Networks and Partial Monotonic Functions. In Advances in Neural Information Processing Systems 30, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garne (Eds.). Curran Associates, Inc., 2981–2989. http://papers.nips.cc/paper/ 6891-deep-laice-networks-and-partial-monotonic-functions.pdf
[3] Alex Goldstein, Adam Kapelner, Justin Bleich, and Emil Pitkin. 2015. Peeking Inside the Black Box: Visualizing Statistical Learning With Plots of Individual Conditional Expectation. Journal of Computational and Graphical Statistics 24, 1 (2015), 44–65. https://doi.org/10.1080/10618600.2014.907095
[4] Aleksandr Chuklin, Ilya Markov, and Maarten de Rijke. 2015. Click Models for Web Search. Synthesis Lectures on Information Concepts, Retrieval, and Services 7, 3 (2015), 1–115. https://doi.org/10.2200/S00654ED1V01Y201507ICR043

若有收获,就点个赞吧
0 人点赞
