作者:董鑫
链接:https://www.zhihu.com/question/30643044/answer/1205433761
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我们先来看一个例子。假设我们随机从意大利的大街找一万个人,为他们免费的新冠病毒的检测,我们 姑且假设这里有两位患者。
下面看一下两种情况:
- 某种检测手段,会把所有的人都检测为:没有新冠病毒。这个时候这种检测手段的准确率是 9998/10000 几乎是等于 1 的。但是显然这个检测手段就是个废物。
- 某种检测手段,会把大部分都检测为:有新冠病毒。这个时候这种检测手段大概率能把所有真正有病毒的患者找出来,但是显然这个检测手段也是废物。
那么,上述例子里面,如果携带病毒称为阳性 positive,不携带病毒称为阴性 negative。我们可以把结果画这么一个表: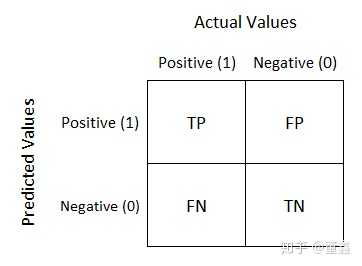
这个表就称为 confusion matrix 。
上面的 TP, FP, FN, TN 分别对应,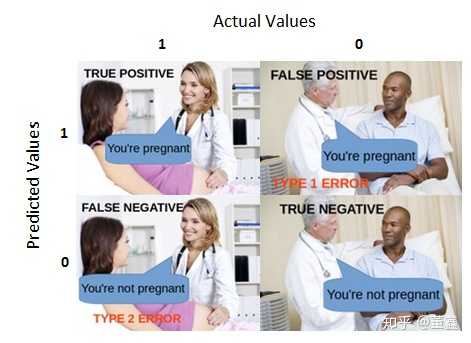
上面新冠病毒的例子中,
- 由于所有的实际携带病毒的人都被检测为了没有携带,这个就称为 假阴性,False Negative (FN)
- 由于大量的实际健康的人都被检测成了携带病毒的人,这个就称为 假阳性,False Positive (FP)
Recall 和 Precision
一般来说,我们 Positive 是我们的检测目标,
如果 FN 太多,我们就说这种方法的recall很低,自然风险控制能力就很差(放走了携带病毒的人)
如果 FP 太多,我们就说这种方法的precision很低,自然这个方法就很浪费(把大量健康人当做携带者处理,成本激增)
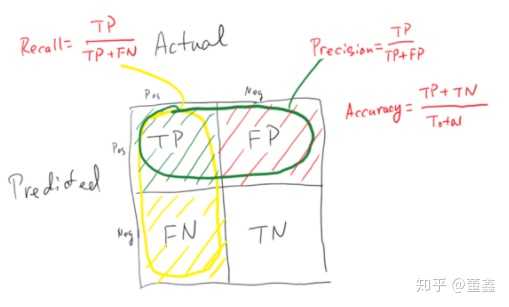
现在再回过头看accuracy的定义,你会发现accuracy相比于上面的recall和precision是一种更加全局化的衡量标准,于此同时,带来的问题是这种衡量标准比较粗糙。
F1 Score
假如我想同时控制风险 (recall) 和成本 (precision)怎么办?那就用F1 Score。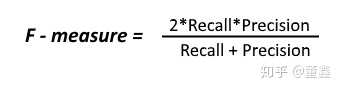
ROC 和 ROC_AUC
这个概念同样和 confusion matrix 有关系。
首先要说的是,confusion matrix 是会受到 threshold 影响的。所谓 threshold,就是假设网络当前的输出值是 0.6 (一般都是经过 sigmoid 之后的值),如果 threshold 是 0.5,那么就会被归到 1 这一类,但是如果 threshold 是 0.7,则会被归到 0 这一类。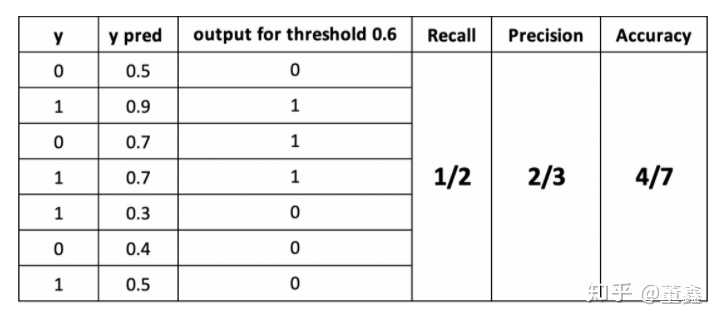
可见,不断的调整 threshold,就能得到不同的 confusion matrix。
当然,这个 threshold 的调整,不是随便调的,设的越高,灵敏度就越低,设的越低,假阳性就越多。
这里,
灵敏度的定义是: the true positive rate (TP / (TP + FN)) 就是前面说的recall
假阳性的定义是:the false positive rate (FP / (FP + TN)) 就是所有本来是阴性其中有多少被错判成了阳性,可以理解成成本。
一般来说,调整 threshold,会让这两个值反向变化。(TPR 和 FPR 数值上是同向变大的,但是我们希望 TPR 越大越好而 FPR 越小越好,所以这里我们说二者是反向变化的。感谢
@爱你在南苑
指出。) 有同学 > @高首 疑惑,最优的模型(绿线)为什么会通过 (0,0) 和 (1,1) 这两个点?这里实际上不是通过,而是为了表示 “> 不管你怎么调整threshold,一直都是 FPR=0,TPR=1” 这种最优情况。如果如实画图就是一个点了,不容易观察,所以才画一个这种半个正方形的图。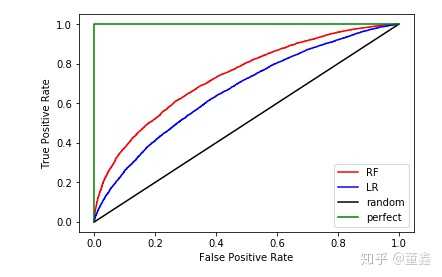
不同颜色代表不同模型。明显,黑色模型是瞎猜模型,绿色模型是最好的,但是也是不可能实现的。剩下的,红色的比蓝色的好。
也就是说,ROC (Receiver Operating Characteristic)曲线下面的面积越大,模型就越好。这个曲线下面积就称为 AUC(Area Under the Curve)。Precision-Recall curve
同样的,改变 threshold 也会反向的改变 precision 和 recall。我们也可以画一下这两个量的关系图,这个图就叫做 precision recall curve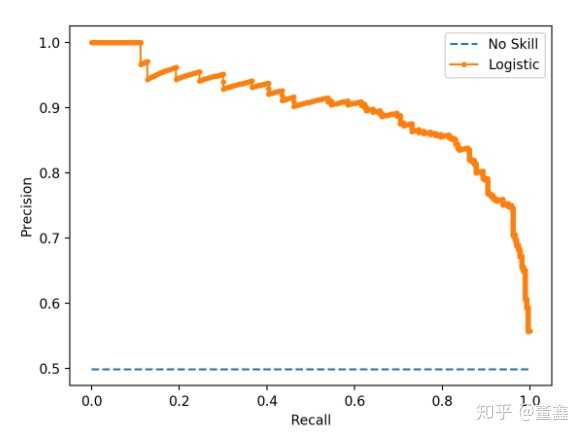
蓝色虚线属于瞎猜模型,橙色曲线下面包的面积越大越好。
什么时候用 ROC,什么时候用 Precision-Recall 呢?
一般来说,像上面新冠病毒的例子,用 Precision-Recall 比较好,属于 data imbalanced 的情况。
如果 positive,negative 的数量基本是平衡的,那 ROC 就更常用一些。完美打印 Confusion Matrix
一个比较好用的,完美打印 confusion matrix 的工具箱是,
wcipriano/pretty-print-confusion-matrix (https://github.com/wcipriano/pretty-print-confusion-matrix)
打印的画风是这样的,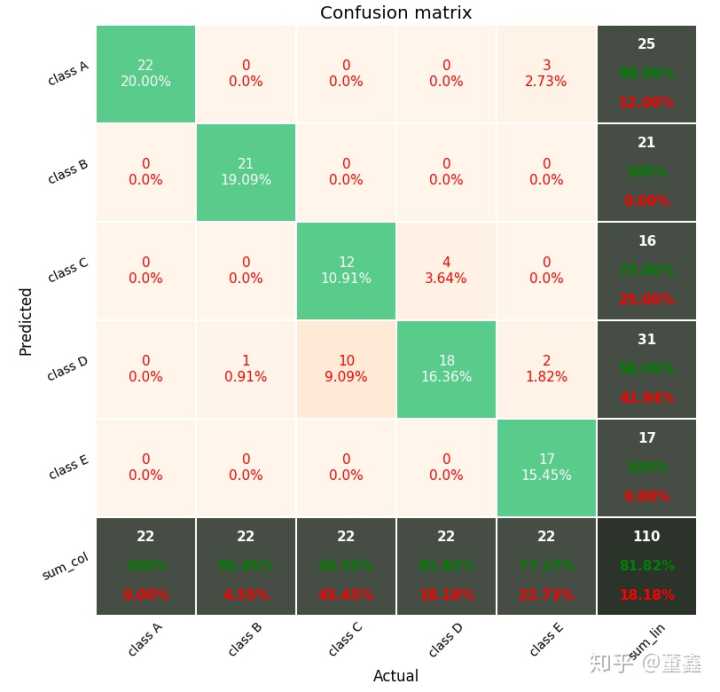
更多相关文章,请关注我的专栏:

若有收获,就点个赞吧
0 人点赞
