CopyOnWriteArrayList
并发包中的并发List资源CopyOnWriteArrayList,CopyOnWriteArrayList是一个线程安全的ArrayList,对其进行修改操作都是在底层的一个复制的数组(快照)上进行的,也就是使用了写时复制策略。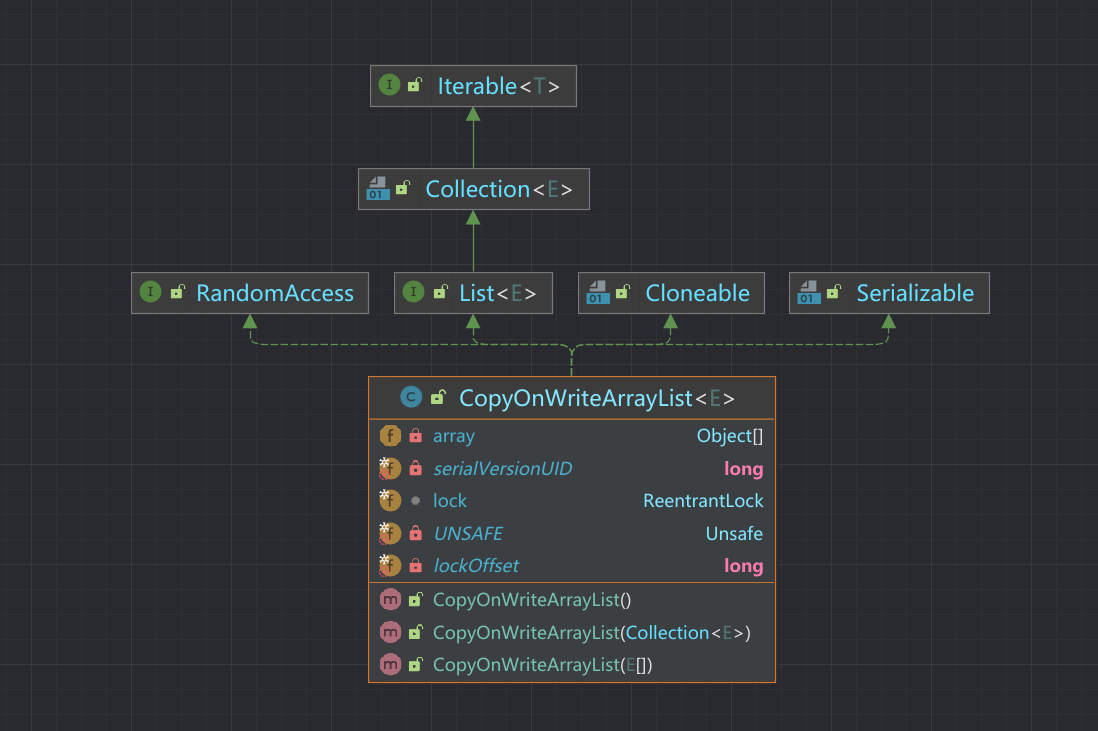
CopyOnWriteArrayList底层是有一个array的对象数组用来存放具体的对象ReentrantLock独占锁用来保证只有一个线程对array进行修改。
初始化-构造方法
public CopyOnWriteArrayList() {setArray(new Object[0]); // return array = new Object[0] 默认长度为0的数组}public CopyOnWriteArrayList(Collection<? extends E> c) {Object[] elements;if (c.getClass() == CopyOnWriteArrayList.class)elements = ((CopyOnWriteArrayList<?>)c).getArray(); // c.getArrayelse {elements = c.toArray();// 再次进行类型检查if (c.getClass() != ArrayList.class)elements = Arrays.copyOf(elements, elements.length, Object[].class);}setArray(elements); // // return array = elements 长度为c.size的数组}public CopyOnWriteArrayList(E[] toCopyIn) {setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));}
final void setArray(Object[] a) {array = a;}
final Object[] getArray() {return array;}
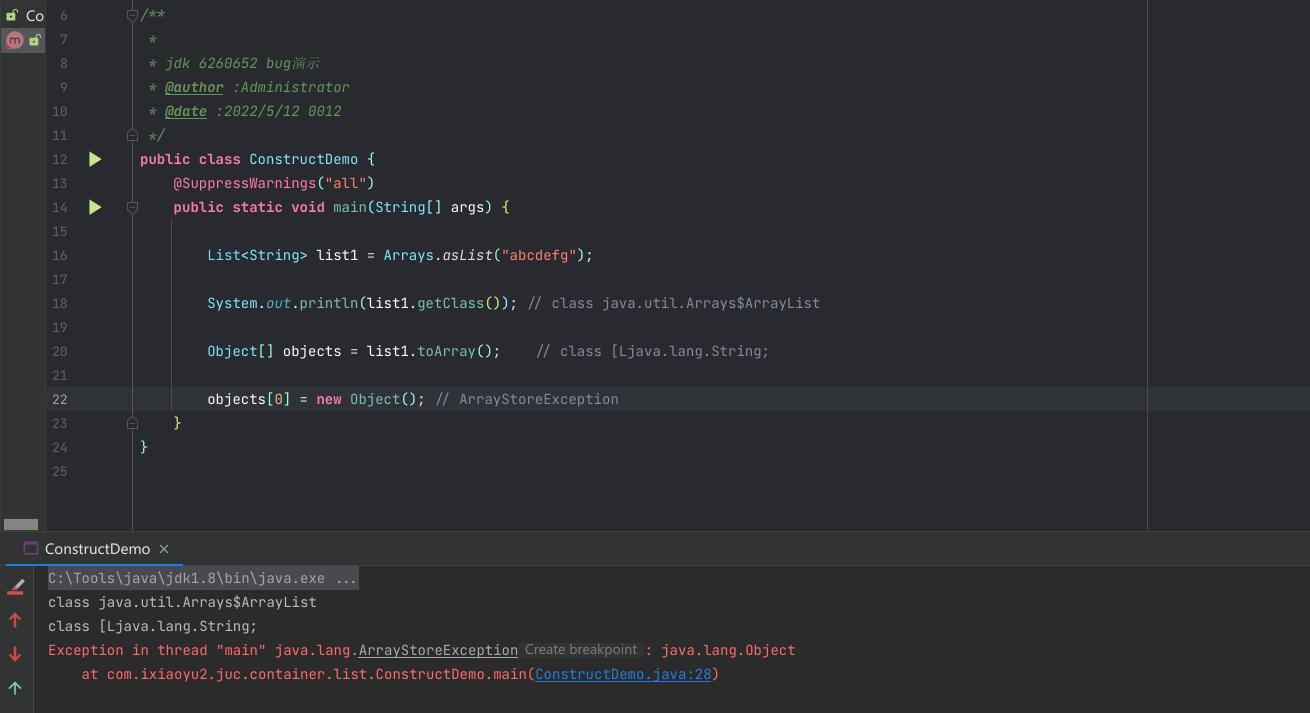
添加元素
CopyOnWriteArrayList中添加元素的方法:
add(E e) add(int index, E element) addIfAbsent(E e) addIfAbsent(E e, Object[] snapshot) addAll(Collection<? extends E> c) addAll(int index, Collection<? extends E> c) addAllAbsent(Collection<? extends E> c)
public boolean add(E e) {final ReentrantLock lock = this.lock;// 获取独占锁lock.lock();try {// 获取array数组Object[] elements = getArray();int len = elements.length;// 复制数组,添加元素到新数组Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;// 使用新数组替换旧数组setArray(newElements);return true;} finally {// 释放锁lock.unlock();}}
获取指定位置元素
使用get(int index)获取指定下标的元素
public E get(int index) {return get(getArray(), index);}private E get(Object[] a, int index) {return (E) a[index];}
修改指定元素
set(int index,E element) 修改list中指定元素的值
public E set(int index, E element) {final ReentrantLock lock = this.lock;// 获取独占锁lock.lock();try {Object[] elements = getArray();// 获取旧元素E oldValue = get(elements, index);if (oldValue != element) {int len = elements.length;// 复制数组Object[] newElements = Arrays.copyOf(elements, len);// 指定下标设置为新值newElements[index] = element;setArray(newElements);} else {// Not quite a no-op; ensures volatile write semanticssetArray(elements);}return oldValue;} finally {lock.unlock();}}
删除元素
remove(int index) remove(Object o) removeAll(Collection<?> c) removeIf(Predicate<? super E> filter)
public E remove(int index) {final ReentrantLock lock = this.lock;// 获取锁lock.lock();try {// 获取数组Object[] elements = getArray();// 数组的长度int len = elements.length;// 获取要删除的值E oldValue = get(elements, index);// 删除值后,要移动的元素数量int numMoved = len - index - 1;// 如果删除的是最后一个元素,不进行移动if (numMoved == 0)setArray(Arrays.copyOf(elements, len - 1));else {// 分两次将原数组的元素复制到新数组中Object[] newElements = new Object[len - 1];System.arraycopy(elements, 0, newElements, 0, index);System.arraycopy(elements, index + 1, newElements, index,numMoved);setArray(newElements);}// 返回删除的元素return oldValue;} finally {// 释放锁lock.unlock();}}
弱一致性迭代器
CopyOnWriteArrayList迭代器是弱一致性,snapshot总是指向旧的数组。
public ListIterator<E> listIterator() {return new COWIterator<E>(getArray(), 0);}
static final class COWIterator<E> implements ListIterator<E> {// array快照private final Object[] snapshot;// 数组下标private int cursor;private COWIterator(Object[] elements, int initialCursor) {cursor = initialCursor;snapshot = elements;}// 是否有下一个元素public boolean hasNext() {return cursor < snapshot.length;}// 是否有前一个元素public boolean hasPrevious() {return cursor > 0;}@SuppressWarnings("unchecked")// 获取元素public E next() {if (! hasNext())throw new NoSuchElementException();return (E) snapshot[cursor++];}@SuppressWarnings("unchecked")// 获取前一个元素public E previous() {if (! hasPrevious())throw new NoSuchElementException();return (E) snapshot[--cursor];}public int nextIndex() {return cursor;}public int previousIndex() {return cursor-1;}@Override// 剩下元素forEach操作public void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);Object[] elements = snapshot;final int size = elements.length;for (int i = cursor; i < size; i++) {@SuppressWarnings("unchecked") E e = (E) elements[i];action.accept(e);}cursor = size;}}
ConcurrentLinkedQueue
ConcurrentLinkedQueue是线程安全的误解非阻塞队列,底层是单向量表实现,入队和出队操作使用CAS实现线程安全。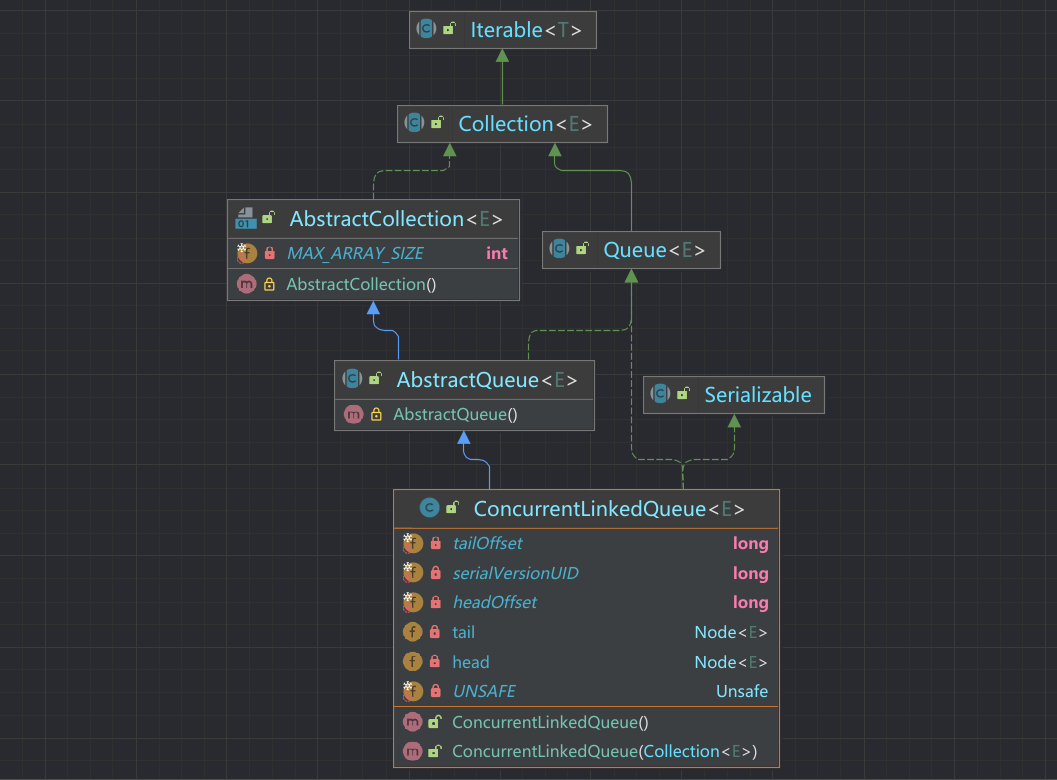
Node 单链表实现
private static class Node<E> {
volatile E item;
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
offer操作
offer操作是在队列末尾添加一个元素,使用CAS操作
public boolean offer(E e) {
checkNotNull(e); // 非空检查
// 将元素封装为Node
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) { // p 、t 指向tail尾结点
Node<E> q = p.next;
// q==null 则表示 p 为尾结点
if (q == null) {
// cas操作,设置p的next节点为newNode
if (p.casNext(null, newNode)) {
// cas操作成功,设置当前尾结点
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
// 多线程操作时,由于poll操作移除元素后可能吧head变成自引用,也就是head.nect=head
// 所有需要找新的head
p = (t != (t = tail)) ? t : head;
else
// 寻找尾结点
p = (p != t && t != (t = tail)) ? t : q;
}
}
也就是通过使用无限循环不断进行CAS 尝试方式来替代阻塞算法挂起调用线程。相比阻塞算法,这是使用CPU 资源换取阻塞所带来的开销
add操作
内部调用offer
public boolean add(E e) {
return offer(e);
}
poll
// 返回列表上的第一个活动(未删除)节点,如果没有则为空
public E poll() {
// 标签
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) { // h p 指向head
// 保存当前节点值
E item = p.item;
// 当前值不为null cas操作将当前值设置为null
if (item != null && p.casItem(item, null)) {
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item; // 设置成功返回当前节点值
}
// 当前队列为null 返回null
else if ((q = p.next) == null) {
updateHead(h, p); //
return null;
}
// 如果当前节点被自引用,则重新寻找新的队列节点
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
poll 方法在移除一个元素时,只是简单地使用CAS 操作把当前节点的item 值设置为null ,然后通过重新设置头节点将该元素从队列里面移除,被移除的节点就成了孤立节点,这个节点会在垃圾回收时被回收掉。另外,如果在执行分支中发现头节点被修改了,要跳到外层循环重新获取新的头节点。
peek
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
P ee k 操作的代码结构与poll 操作类似, 不同之处在于)中少了castitem 操作。因为peek 只是获取队列头元素值,并不清空其值。
size
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}
// 返回头节点
Node<E> first() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) { // h ,p 指向head
boolean hasItem = (p.item != null); // p指向节点值不为null
if (hasItem || (q = p.next) == null) { // 或者q==null表示此时没有其他线程offer添加元素
updateHead(h, p); // 将头结点设置为p,h.next = h
return hasItem ? p : null;
}
else if (p == q) // 有其他线程poll元素,导致p.next=p
continue restartFromHead;
else
p = q; // 有其他线程offer添加元素,q!=null
}
}
}
// 返回p的后继节点
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
return (p == next) ? head : next; // //获取当前节点的next元素,如采是自引入节点则返回真正的头节点
}
remove
public boolean remove(Object o) {
if (o != null) {
Node<E> next, pred = null;
for (Node<E> p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
// 当前节点值不为null
if (item != null) {
if (!o.equals(item)) {
// 获取next元素
next = succ(p);
continue;
}
//相等则使用αs设置为null , 同时一个线程操作作成功,
//失败的线程盾环查找队列中是否有匹配的其他元素。
removed = p.casItem(item, null);
}
next = succ(p); // 获取next元素
if (pred != null && next != null) // unlink
pred.casNext(p, next);
if (removed)
return true;
}
}
return false;
}
contains
判断队列里面是否含有指定对象, 由于是遍历整个队列,所以像s ize 操作一样结果也不是那么精确,有可能调用该方法时元素还在队列里面,但是遍历过程中其他线程才把该
元素删除了,那么就会返回false 。
public boolean contains(Object o) {
if (o == null) return false;
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null && o.equals(item))
return true;
}
return false;
}
ConcurrentLinkedQu eue 的底层使用单向链表数据结构来保存队列元素,每个元素被包装成一个Node 节点。队列是靠头、尾节点来维护的,创建队列时头、尾节点指向1个item 为null 的哨兵节点。第一次执行peek 或者自rst 操作时会把head 指向第一个真正的队列元素。由于使用非阻塞CAS 算法,没有加锁,所以在计算size 时有可能进行了offer、poll 或者remove 操作, 导致计算的元素个数不精确,所以在井发情况下size 函数不是很有用。 offer 操作是在tail 后面添加元素,也就是调用tail.casNext 方法,而这个方法使用的是CAS 操作,只有一个线程会成功,然后失败的线程会循环,重新获取tail , 再执行casNext方法。poll 操作也通过类似CAS 的算法保证出队时移除节点操作的原子性。
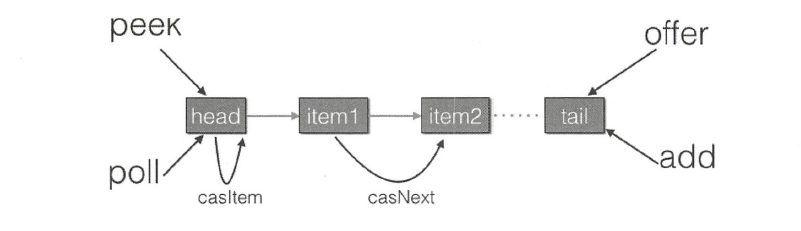
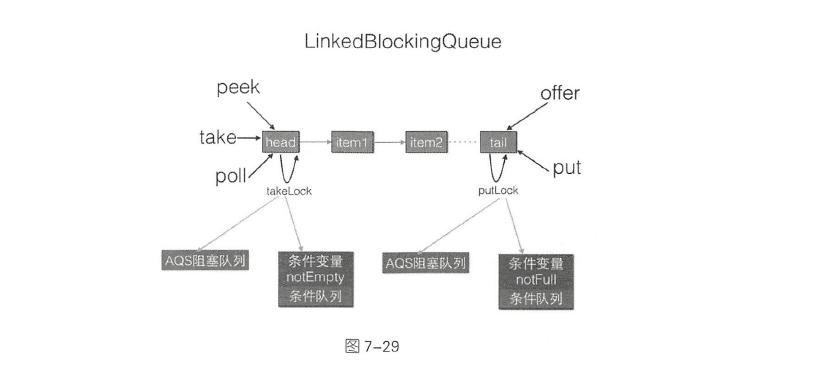
LinkedBlockingQueue
LinkedBlockingQueue是使用独占锁实现的阻塞队列。
LinkedBlockingQueue底层是使用单链表实现,head、last分别储存头结点、尾结点,并且还有一个原子变量count,记录链表元素个数。putLock、takeLock表示进队、出队的锁,保证同时只有一个线程可以向队列尾部添加元素、从头部获取元素。notEmpty、notFull是条件等待队列,存放进队、出队时被阻塞的线程。
static class Node<E> {
// 元素的值
E item;
// 后序节点
Node<E> next;
Node(E x) { item = x; }
}
/** The capacity bound, or Integer.MAX_VALUE if none */
private final int capacity;
/** Current number of elements */
private final AtomicInteger count = new AtomicInteger();
// 头结点,头结点的值 head.item==null(哨兵节点)
transient Node<E> head;
// 尾结点,last.next==null 尾结点的后序为空
private transient Node<E> last;
/** 出队的锁 */
private final ReentrantLock takeLock = new ReentrantLock();
/** 出队阻塞等待的队列 */
private final Condition notEmpty = takeLock.newCondition();
/**入队的锁 */
private final ReentrantLock putLock = new ReentrantLock();
/** 入队的阻塞等队列 */
private final Condition notFull = putLock.newCondition();
初始化——构造方法
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity; // 最多节点数量
last = head = new Node<E>(null); // 初始化,头结点、尾结点指向哨兵节点 item==null
}
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE); // 先初始化构造最大节点数的队列,头结点、尾结点指向哨兵队列
final ReentrantLock putLock = this.putLock; // 获取入队锁
putLock.lock(); // 加锁
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n); // 当前节点数量
} finally {
putLock.unlock(); // 释放锁
}
}
// 尾结点后添加节点,并将last指向新的尾结点
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
last = last.next = node;
}
offer
向队列尾部插入一个元素,如果队列中有空闲则插入成功后返回true ,如果队列己满
则丢弃当前元素然后返回false 。如果e 元素为null 则抛出NullPointerException 异常。另外,该方法是非阻塞的。
public boolean offer(E e) {
// null判断
if (e == null) throw new NullPointerException();
// 获取当前的节点数量
final AtomicInteger count = this.count;
// 判断队列是否已经满了,满了则无法添加
if (count.get() == capacity)
return false;
int c = -1;
// 添加的值包装为node节点
Node<E> node = new Node<E>(e);
// 获取putLock
final ReentrantLock putLock = this.putLock;
putLock.lock(); // putLock 锁,当前线程获取到该锁后,则其他调用put 和offer 操作的线程将会被阻塞
try {
// 如采队列不满则进队列,并递增元素计数
if (count.get() < capacity) {
enqueue(node); // 添加元素
c = count.getAndIncrement(); // 节点数量加1,c为添加前的节点数量
if (c + 1 < capacity)
notFull.signal(); // 如果此时还可以继续添加节点,则唤醒入队等待队列的一个线程
}
// 如果当前节点数量达到最大,丢弃该元素不进行添加,返回false,释放锁
} finally {
putLock.unlock(); // 释放锁
}
if (c == 0) // 表示队列至少有一个元素
signalNotEmpty(); //唤醒出队等待队列的一个线程,可以取出
return c >= 0;
}
// 唤醒出队等待队列的一个线程,表示队列至少有一个元素,可以取出
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
put
向队列尾部插入一个元素,如果队列中有空闲则插入后直接返回,如果队列己满则阻
塞当前线程,直到队列有空闲插入成功后返回。如果在阻塞时被其他线程设置了中断标志,则被阻塞线程会抛出InterruptedException 异常而返回。另外,如果e 元素为null 则抛出NullPointerException 异常。
public void put(E e) throws InterruptedException {
// null【判断
if (e == null) throw new NullPointerException();
int c = -1;
// 将元素封装为node
Node<E> node = new Node<E>(e);
// putLokc锁
final ReentrantLock putLock = this.putLock;
// 队列节点数量
final AtomicInteger count = this.count;
putLock.lockInterruptibly(); // 可被中断的加锁
try {
// 节点数量达到最大,无法添加,线程进入入队等待队列,释放锁
while (count.get() == capacity) { //while循环防止虚假唤醒
notFull.await();
}
// 没有达到最大,添加节点
enqueue(node);
c = count.getAndIncrement(); // c为添加前的值,节点数量加1
if (c + 1 < capacity)
notFull.signal(); // 还可以继续添加,唤醒一个入队等待队列的线程
} finally {
putLock.unlock(); // 释放锁
}
if (c == 0)
signalNotEmpty();
}
poll
从队列头部获取并移除一个元素, 如果队列为空则返回null , 该方法是不阻塞的。
public E poll() {
// 获取当前节点数量
final AtomicInteger count = this.count;
// 如果为0返回null
if (count.get() == 0)
return null;
E x = null;
int c = -1;
// 获取锁
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
// 如果节点数量>0
if (count.get() > 0) {
x = dequeue(); // 获取第一个元素
c = count.getAndDecrement(); // c=获取前的节点数量,节点数量减1
if (c > 1) // 如果之前节点数量大于1个,还可以继续取数
notEmpty.signal(); // 唤醒一个出队等待队列的线程
}
// 如果节点数为0 返回null
} finally {
takeLock.unlock(); // 释放锁
}
if (c == capacity) // 如果c为最大节点数,取出一个后就可以继续添加
signalNotFull(); // 唤醒一个入队等待队列的线程
return x;
}
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item; // head 总是指向item=null的节点
first.item = null;
return x;
}
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
peek
获取队列头部元素但是不从队列里面移除它,如果队列为空则返回null 。该方法是不
阻塞的。
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock(); // 获取出队锁,保证其他线程的poll、remove等操作阻塞
try {
Node<E> first = head.next;
if (first == null)
return null; // 第一个节点为null,队列为空时
else
return first.item;
} finally {
takeLock.unlock();
}
}
take
获取当前队列头部元素并从队列里面移除它。如果队列为空则阻塞当前线程直到队列
不为空然后返回元素,如果在阻塞时被其他线程设置了中断标志, 则被阻塞线程会抛出InterruptedException 异常而返回。
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly(); // 加锁,线程可被中断
try {
while (count.get() == 0) { // while循环防止虚假唤醒
notEmpty.await(); // 队列为空,线程进入入队等待队列等待
}
x = dequeue(); // 取出第一个元素
c = count.getAndDecrement(); // c为取出前的节点数量,节点数量减1
if (c > 1) // 还可以继续取出
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity) //取出一个节点后队列不满,可以添加节点
signalNotFull(); // 添加节点
return x;
}
remove
删除队列里面指定的元素,有则删除并返回true ,没有则返回false
public boolean remove(Object o) {
if (o == null) return false; // null 判断
fullyLock(); // putLock、takeLock都加锁
try {
for (Node<E> trail = head, p = trail.next; // trail 指向head,p指向head.next
p != null; // p!=null 表示 队列不为null
trail = p, p = p.next) { // 向后移动trail和p
if (o.equals(p.item)) { // 如果p.item ==o
unlink(p, trail); // 断开trai指向p的引用,p会被垃圾回收
return true;
}
}
return false; // 遍历完没有没有该元素,返回false
} finally {
fullyUnlock(); // 释放锁
}
}
void fullyLock() {
putLock.lock();
takeLock.lock();
}
// 断开链接前 trail————>P trai指向p
void unlink(Node<E> p, Node<E> trail) {
// p.item设置为null 表示删除值
p.item = null;
// trai.next = p.next 表示断开trai ——X——> p 的引用
trail.next = p.next;
if (last == p)
last = trail; // 如果p只最后一个节点,断开后trail是最后一个节点
if (count.getAndDecrement() == capacity) // 断开前队列是满的,断开后节点数量减1
notFull.signal(); // 唤醒1个入队等待队列的线程,表示可以添加元素
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
由于remove 方法在删除指定元素前加了两把锁,所以在遍历队列查找指定元素的过程中是线程安全的,并且此时其他调用入队、出队操作的线程全部会被阻塞。另外,获取多个资源锁的顺序与释放的顺序是相反的。
size
获取当前队列元素个数。
public int size() {
return count.get();
}
由于进行出队、入队操作时的count 是加了锁的, 所以结果相比ConcurrentLinkedQueue 的size 方法比较准确。
 ArrayBlockingQueue
ArrayBlockingQueue
数组方式现实阻塞队列ArrayBlockingQueue
底层实现是一个Object[]数组,用于存放数据。putIndex表示入队元素下标,takeIndex表示出队元素下标,count表示元素个数。这些变量并没有使用volatile 修饰,这是因为访问这些变量都是在锁块内,而加锁己经保证了锁块内变量的内存可见性了。ReentrantLock独占锁,保证入队、出队的原子性。notEmpty、notFull等待阻塞队列。
/** 存放元素的数组 */
final Object[] items;
/** 出队下标 */
int takeIndex;
/** 入队下标 */
int putIndex;
/** 队列元素数量 */
int count;
/**独占锁 */
final ReentrantLock lock;
/** 出队等待队列 */
private final Condition notEmpty;
/** 入队等待队列 */
private final Condition notFull;
/** 当前活动迭代器的共享状态,如果已知不存在,则为null。
允许队列操作更新迭代器状态* iterator state.
*/
transient Itrs itrs = null;
初始化-构造方法
public ArrayBlockingQueue(int capacity) {
this(capacity, false); // 指定初始化容量,指定非公平
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0) // 初始化容量小于0抛出异常
throw new IllegalArgumentException();
this.items = new Object[capacity]; // 构建Object[],大小为指定大小
lock = new ReentrantLock(fair); // 获取ReenTrantLock锁实例(true为公平锁,false为非公平锁)
notEmpty = lock.newCondition(); // 创建出队等待队列
notFull = lock.newCondition(); // 创建出队等待队列
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair); // 构建ArrayBlockingQueue实例
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
int i = 0;
try {
for (E e : c) {
checkNotNull(e); // null检查,为null 抛出NullPointerException
items[i++] = e; // intem[i] = e; i++;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
count = i; // i为当前数组元素个数
putIndex = (i == capacity) ? 0 : i; // 元素满了从0开始
} finally {
lock.unlock(); // 释放锁
}
}
offer
向队列尾部插入一个元素, 如果队列有空闲空间则插入成功后返回true ,如果队列己
满则丢弃当前元素然后返回fals e 。如果e 元素为null 则抛出NullPointerException 异常。另外,该方法是不阻塞的。
public boolean offer(E e) {
checkNotNull(e); // null 检查,为null抛出NPE
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁
try {
// 如果队列已满,返回false 添加失败
if (count == items.length)
return false;
else {
enqueue(e); // 添加元素,并唤醒一个出队等待队列的线程
return true;
}
} finally {
lock.unlock(); // 释放锁
}
}
private void enqueue(E x) {
// 底层对象数组
final Object[] items = this.items;
items[putIndex] = x; // 添加对象
if (++putIndex == items.length) // 如果添加元素后队列满了,putIndex=0
putIndex = 0;
count++; // 元素个数加1
notEmpty.signal(); // 队列不为空,唤醒一个出队等待队列的线程
}
put
向队列尾部插入一个元素,如果队列有空闲则插入后直接返回true ,如果队列己满则
阻塞当前线程直到队列有空闲井插入成功后返回true ,如果在阻塞时被其他线程设置了中断标志, 则被阻塞线程会抛出Inteηupte dE x ception 异常而返回。另外, 如果e 元素为null则抛出NullPointerException 异常。
public void put(E e) throws InterruptedException {
checkNotNull(e); // null检查
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 获取锁,线程可被中断
try {
while (count == items.length) // 如果队列满的,计入入队等待队列,并释放锁
notFull.await();
enqueue(e); // 添加元素,并唤醒出队等待队列一个线程
} finally {
lock.unlock();
}
}
poll
从队列头部获取并移除一个元素,如果队列为空则返回null , 该方法是不阻塞的。
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁
try {
return (count == 0) ? null : dequeue(); // 如果队列为空,返回Null,否则返回队列第一个元素,并唤醒入队等待队列的一个线程
} finally {
lock.unlock();
}
}
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex]; // 获取出队下标的元素
items[takeIndex] = null; // 出队下标元素设置为null
if (++takeIndex == items.length) //出队下标++ 达到数组长度时重置为0
takeIndex = 0;
count--;
if (itrs != null) // 迭代器不为null
itrs.elementDequeued();
notFull.signal(); // 唤醒入队等待队列的一个线程
return x; // 返回取得的元素
}
take
获取当前队列头部元素并从队列里面移除它。如果队列为空则阻塞当前线程直到队列
不为空然后返回元素,如果在阻塞时被其他线程设置了中断标志,则被阻塞线程会抛出
InterruptedException 异常而返回。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 加锁,线程可被中断
try {
while (count == 0)
notEmpty.await(); // 队列为空 进入出队等待队列 并释放锁
return dequeue(); // 返回第一个元素,并唤醒 入队等待队列的一个线程
} finally {
lock.unlock();
}
}
peek
获取队列头部元素但是不从队列里面移除它, 如果队列为空则返回null , 该方法是不
阻塞的。
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock(); //获取锁
try {
return itemAt(takeIndex); // 返回出队下标的元素,如果队列为空返回Null
} finally {
lock.unlock(); // 释放锁
}
}
final E itemAt(int i) {
return (E) items[i]; // 返回i下标的元素
}
size
计算当前队列元素个数。
public int size() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁,因为count没有声明为volatile
try {
return count; // 返回元素个数
} finally {
lock.unlock(); // 释放锁
}
}
ArrayBlockingQueue 通过使用全局独占锁实现了同时只能有一个线程进行入队或者出队操作,这个锁的粒度比较大,有点类似于在方法上添加synchronized。 其中,offer和poll 操作通过简单的加锁进行入队、出队操作,而put 、take 操作则使用条件变量实现了,如果队列满则等待,如果队列空则等待,然后分别在出队和入队操作中发送信号激活等待线程实现同步。 另外,相比LinkedBlockingQueue,Array B lockingQueue 的size 操作的结果是精确的, 因为计算前加了全局锁。
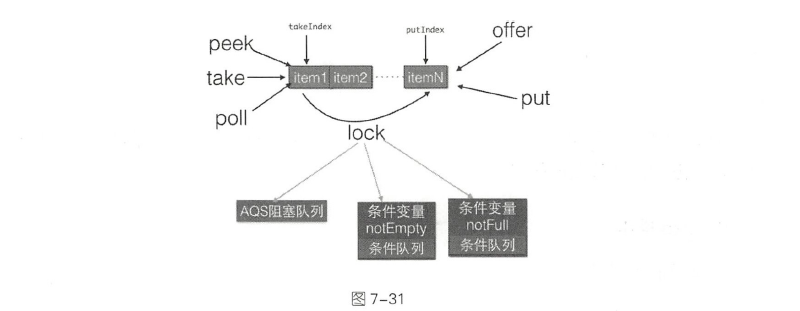 PriorityBlockingQueue
PriorityBlockingQueue
Priority B lockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高或者最低的元素。其内部是使用平衡二叉树堆实现的,所以直接遍历队列元素不保证有序。默认使用对象的c ompareTo 方法提供比较规则,如果你需要自定义比较规则则可以自定义comparators 。
PriorityBlockingQueue(堆结构)底层是Object数组存放数据,size存放元素个数,allocationSpinLock是个自旋锁,使用CAS操作保证同时只有一个线程可以扩容队列。状态为0或1,0表示没有进行扩容、1表示正在扩容。
// 底层数组默认长度
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 底层数组最大长度
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 底层数组
private transient Object[] queue;
// 元素个数
private transient int size;
// 比较器
private transient Comparator<? super E> comparator;
// 独占锁
private final ReentrantLock lock;
// 出队等待队列
private final Condition notEmpty;
// 队列扩容自旋锁
private transient volatile int allocationSpinLock;
// PriorityQueue 优先级队列(堆)
private PriorityQueue<E> q;
初始化——构造方法
public PriorityBlockingQueue(int initialCapacity) {
this(initialCapacity, null); // 只指定初始容量
}
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException(); // 容量小于0抛出异常
this.lock = new ReentrantLock(); // ReentrantLock 独占锁实例
this.notEmpty = lock.newCondition(); // 出队等待队列
this.comparator = comparator; // 比较器
this.queue = new Object[initialCapacity]; // 初始化底层数组
}
public PriorityBlockingQueue(Collection<? extends E> c) {
this.lock = new ReentrantLock(); // ReentrantLock 独占锁实例
this.notEmpty = lock.newCondition(); // 出队等待队列
boolean heapify = true; // heapify 向下调整堆结构
boolean screen = true; //
if (c instanceof SortedSet<?>) { // c是排序结构的集合
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator(); // 获取比较器
heapify = false; // 不用向下调整
}
else if (c instanceof PriorityBlockingQueue<?>) { // // c是排序结构的PriorityBlockingQueue
PriorityBlockingQueue<? extends E> pq =
(PriorityBlockingQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator(); // 获取比较器
screen = false;
if (pq.getClass() == PriorityBlockingQueue.class) // 准确匹配
heapify = false;
}
Object[] a = c.toArray();
int n = a.length; // 元素数量
// 再次进行类型检查
if (c.getClass() != java.util.ArrayList.class)
a = Arrays.copyOf(a, n, Object[].class);
if (screen && (n == 1 || this.comparator != null)) {
for (int i = 0; i < n; ++i)
if (a[i] == null) // 非空检查
throw new NullPointerException();
}
this.queue = a;
this.size = n;
if (heapify)
heapify(); // 进行堆结构调整
}
offer
offer 操作的作用是在队列中插入一个元素,由于是无界队列, 所以一直返回true 。如
下是offer 函数的代码。
public boolean offer(E e) {
if (e == null) // null检查
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock(); // 获取独占锁
int n, cap;
Object[] array;
// 若当前元素个数>=队列容量,扩容
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap); // 扩容
try {
Comparator<? super E> cmp = comparator; // 比较器
if (cmp == null) // 默认比较器为null
siftUpComparable(n, e, array);
else
siftUpUsingComparator(n, e, array, cmp); // 使用自定义比较器
size = n + 1; // 队列元素加1
notEmpty.signal(); // 唤醒出队队列的一个线程
} finally {
lock.unlock(); // 释放锁
}
return true; // 返回true
}
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // 释放获得的锁 -> 提供并发性能,让其他线程可以进行入队和出队操作
Object[] newArray = null; // 新数组
if (allocationSpinLock == 0 && // 获取自旋锁 CAS成功 allocationSpinLock == 0表示没有其他线程在进行扩容操作
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) { // 获取锁成功
try {
// oldGap<64 则扩容, 执行oldcap+2 ,否则扩容50% ,并且最大为MAX_ARRAY_SIZE
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
// 如果扩容后的大小超过最大容量
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
// 判断是否溢出
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError(); // 溢出
newCap = MAX_ARRAY_SIZE;
}
// 新的容量>旧容量且没有其他线程更改array, 创建newArray
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
// 第一个线程CAS成功后,第二个线程会进入这段代码,
// 然后第二个线程让出CPU ,尽量让第一个线程获取锁,但是这得不到保证。
if (newArray == null) // back off if another thread is allocating
Thread.yield();//让出cpu, 是让扩容线程扩容后优先调用lock.lock 重新获取锁
lock.lock();
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
poll
poll 操作的作用是获取队列内部堆树的根节点元素,如果队列为空,则返回null
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁
try {
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
int n = size - 1; // 队列为空返回Null
if (n < 0)
return null;
else {
Object[] array = queue; // 获取头元素
E result = (E) array[0];
E x = (E) array[n]; // 队尾元素
array[n] = null;
Comparator<? super E> cmp = comparator;
// 堆结构调整
if (cmp == null)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
put
put 操作内部调用的是offer 操作,由于是无界队列,所以不需要阻塞。
public void put(E e) {
offer(e); // never need to block
}
take
take 操作的作用是获取队列内部堆树的根节点元素, 如果队列为空则阻塞
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 获取锁,可被中断
E result;
try {
while ( (result = dequeue()) == null) // 获取元素第一个元素
notEmpty.await(); //为空表示队列为空,线程进入出队等待队列,地方锁
} finally {
lock.unlock(); // 释放锁
}
return result;
}
size
计算队列元素个数。如下代码在返回size 前加了锁,以保证在调用size() 方法时不会有其他线程进行入队和出队操作。另外,由于size 变量没有被修饰为volatie 的, 所以这里加锁也保证了在多线程下size 变量的内存可见性。
public int size() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁
try {
return size;
} finally {
lock.unlock();
}
}
PriorityBlockingQueue 队列在内部使用二叉树堆维护元素优先级,使用数组作为元素存储的数据结构,这个数组是可扩容的。 当前元素个数>=最大容量时会通过CAS 算法扩容,出队时始终保证出队的元素是堆树的根节点,而不是在队列里面停留时间最长的元素。 使用元素的compareTo 方法提供默认的元素优先级比较规则,用户可以自定义优先级的比较规则。 PriorityBlockingQueue 类似于ArrayBlockingQueue ,在内部使用一个独占锁来控制同时只有一个线程可以进行入队和出队操作。 另外,PriorityBlockingQueue 只使用了一个notEmpty 条件变量而没有使用notFull ,是因为PriorityBlockingQueue 是无界队列,执行put 操作时永远不会处于await 状态,所以也不需要被唤醒。而take 方法是阻塞方法,并且是可被中断的。当需要存放有优先级的元素时该队列比较有用。
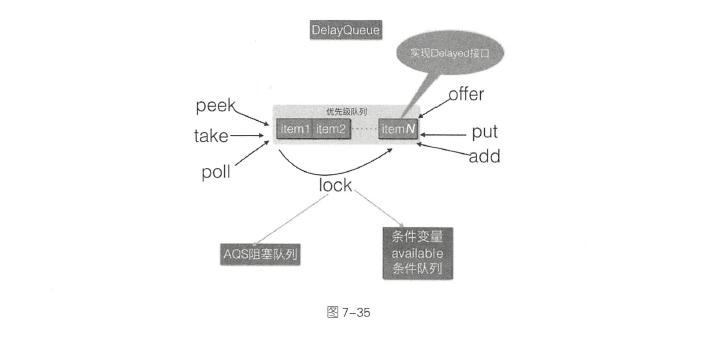
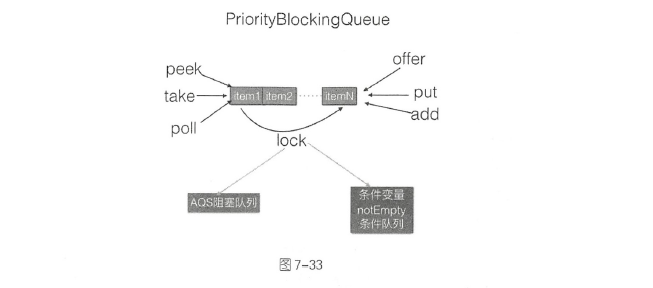 DelayQueue
DelayQueue
DelayQueue 并发队列是一个无界阻塞延迟队列,队列中的每个元素都有个过期时间,当从队列获取元素时,只有过期元素才会出队列。队列头元素是最快要过期的元素。
DelayQueue内部使用PriorityQueue存放数据,使用ReentrantLock实现线程同步。 队列里面的元素要实现Delayed 接口,由于每个元素都有一个过期时间,所以要实现获知当前元素还剩下多少时间就过期了的接口,由于内部使用优先级队列来实现,所以要实现元素之间相互比较的接口。 leader 变量的使用基于Lead er-Follower 模式的变体,用于尽量减少不必要的线程等待。当一个线程调用队列的take 方法变为leader 线程后,它会调用条件变量available .awaitNanos( delay) 等待delay 时间,但是其他线程C follwer 线程) 则会调用available.await()进行无限等待。leader 线程延迟时间过期后,会退出take 方法, 并通过调用available.signal()方法唤醒一个follwer 线程,被唤醒的follwer 线程被选举为新的l eader 线程。
初始化——构造函数
public DelayQueue() {}
public DelayQueue(Collection<? extends E> c) {
this.addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
boolean modified = false;
for (E e : c)
if (add(e)) // 调用add
modified = true;
return modified;
}
public boolean add(E e) {
return offer(e);
}
offer
插入元素到队列,如果插入元素为null 则抛出Null PointerException 异常, 否则由于是无界队列, 所以一直返回true 。插入元素要实现Delayed 接口。
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
q.offer(e); // 加入优先级队列
if (q.peek() == e) { // 为堆的第一个元素,表示最先过期
leader = null; //leader重置为null
available.signal(); // 唤醒出队等待队列的线程
}
return true;
} finally {
lock.unlock(); // 释放锁
}
}
take
获取并移除队列里面延迟时间过期的元素,如果队列里面没有过期元素则等待。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 获取锁 线程可被中断
try {
for (;;) {
E first = q.peek(); // 堆第一个元素 最先过期
if (first == null)
available.await(); // 如果为null 表示堆为空 进入等待队列 释放锁
else {
long delay = first.getDelay(NANOSECONDS); // 获取剩余过期时间
if (delay <= 0) // 已经过期
return q.poll(); // 返回堆第一个元素
first = null; // don't retain ref while waiting
if (leader != null) // 不为空表示其他线程也在执行take,
available.await(); // 进入等待队列
else {
Thread thisThread = Thread.currentThread();
leader = thisThread; // leader为空,当前线程设置为leader
try {
available.awaitNanos(delay); // 等待第一个元素过期,释放锁
} finally {
if (leader == thisThread)
leader = null; // 重新拿到锁之后重置leader=null
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal(); // 唤醒等待队列的一个线程
lock.unlock(); // 释放锁
}
}
poll
获取并移除队头过期元素,如果没有过期元素则返回null 。
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁
try {
E first = q.peek();
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null; // 队列为空或者没有过期的元素 返回Null
else
return q.poll(); // 返回第一个过期的元素
} finally {
lock.unlock(); // 释放锁
}
}
size
计算队列元素个数,包含过期的和没有过期的。
public int size() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取锁
try {
return q.size(); // 返回元素个数
} finally {
lock.unlock(); // 释放锁
}
}
DelayQueue 队列,其内部使用P riorityQueue 存放数据,使用ReentrantLock 实现线程同步。另外队列里面的元素要实现Delayed 接口,其中一个是获取当前元素到过期时间剩余时间的接口,在出队时判断元素是否过期了,一个是元之间比较的接口,因为这是一个有优先级的队列。
SynchronousQueue(待整理)
:::danger
- 待整理 :::
TransferQueue (待整理)
:::danger
- 待整理 :::
ConcurrentHashMap
ConcurrentHashMap是线程安全且高效的HashMap,普通的HashMap在多线程并发的情况下可能出现死循环,而线程安全的HashTable效率有非常低(每个方法添加synchronized保证线程安全),因此在多线程高并发下适合使用ConcunrrentHashMap。
HashMap 多线程不安全分析
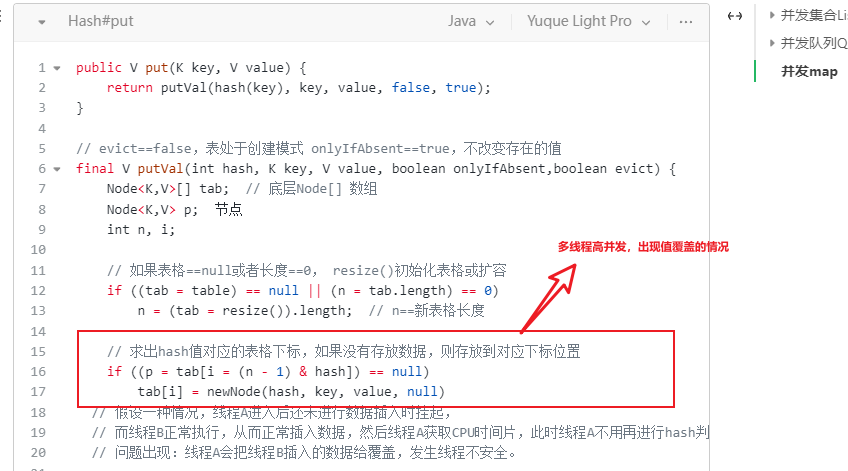
jdk1.7 HashMap在多线程高并发下出现死循环,jdk1.8则会出现值覆盖的情况
HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
JDK1.8 hashMap#put 源码分析
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// evict==false,表处于创建模式 onlyIfAbsent==true,不改变存在的值
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; // 底层Node[] 数组
Node<K,V> p; 节点
int n, i;
// 如果表格==null或者长度==0, resize()初始化表格或扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // n==新表格长度
// 求出hash值对应的表格下标,如果没有存放数据,则存放到对应下标位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null)
// 假设一种情况,线程A进入后还未进行数据插入时挂起,
// 而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,
// 问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。
// 存放过数据,则进行链表或者红黑树处理
else {
Node<K,V> e; //节点
K k; // key
// p = tab[(n-1)&hash]
if (p.hash == hash && // hash值相等 且 (key为同一个或者 key不为null但key值相同
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // p是否是treeNode 红黑树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 链表结构 -> 链表末尾插入节点
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // p是否是最后一个节点
p.next = newNode(hash, key, value, null); // 插入节点
if (binCount >= TREEIFY_THRESHOLD - 1) // TREEIFY_THRESHOLD = 8
treeifyBin(tab, hash); // 链表转换为红黑树
break;
}
// e = p.next
if (e.hash == hash && // hash值相等 且 (key为同一个或者 key不为null但key值相同
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)//onlyIfAbsent==true 值相同是不改变,false要改变
e.value = value; //替换为薪资
afterNodeAccess(e);
return oldValue; // 返回旧值
}
}
++modCount; // modCount加1
if (++size > threshold) // 如果size加1 大于threshold
resize(); // resize()
afterNodeInsertion(evict);
return null; // 返回Null
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // oldtable
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 长度
int oldThr = threshold; //oldThrehold
int newCap, newThr = 0;
if (oldCap > 0) { // 旧表长度大于0
if (oldCap >= MAXIMUM_CAPACITY) { // 旧表长度达到最大长度限制 >= MAXIMUM_CAPACITY = 2^30
threshold = Integer.MAX_VALUE; // threshold设为Integer最大值
return oldTab; // 返回旧表
}
// 旧表长度没有达到最大长度限制
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && // 旧表长度*2 也在最大长度范围内
oldCap >= DEFAULT_INITIAL_CAPACITY) // 旧表长度大于默认长度 16
newThr = oldThr << 1; // threshold*2
}
else if (oldThr > 0) // oldThr > 0
newCap = oldThr; // 新表长度 = oldThr
else {
// 初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
jdk1.7 HashMap#put源码分析
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold); // 为空进行初始化
}
if (key == null) // keyNull ,进行null 插入
return putForNullKey(value);
int hash = hash(key); // key的hash值
int i = indexFor(hash, table.length); // hash & (table.length-1) 求到hash值对应的下标
// 遍历链表 table[i] != null,这个位置有节点
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// hash值相等 同时 (是同一个key 或者 key相等) -》表示更新操作
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 上面for 循环走完 e == null ,进行插入节点操作
modCount++;
addEntry(hash, key, value, i);
return null;
}
// 插入节点操作
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果 table[i] 不为空 同时 表格大小超过thrshold,进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // 2倍扩容
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// table[i] == null 或者没超过thread 直接添加
createEntry(hash, key, value, bucketIndex); // 插入节点
}
// 直接插入节点
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; // 当链表的头结点
table[bucketIndex] = new Entry<>(hash, key, value, e); // 新插入的节点作为链表的头结点
size++;
}
// 扩容操作
void resize(int newCapacity) {
Entry[] oldTable = table; // 旧表
int oldCapacity = oldTable.length; // 旧表长度
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE; // 旧表长度达到最大 增大thread 为Integer.MAX_VALUE
return;
}
Entry[] newTable = new Entry[newCapacity]; // 新表长度为2倍
transfer(newTable, initHashSeedAsNeeded(newCapacity)); // 数据复制
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**将旧表数组重新复制到新表*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length; // 新表长度
for (Entry<K,V> e : table) { // table还指向旧表 ,遍历旧表
while(null != e) { // 链表头结点 != null
Entry<K,V> next = e.next; // 下一个节点
if (rehash) { // 是否需要重新计算hash
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); // 新表中的位置
e.next = newTable[i]; // e.next 指向 newTable[i]
newTable[i] = e; // newTable[i] = e // 会产生多线程不安全,循环链表
e = next; // 下一个节点
}
}
}

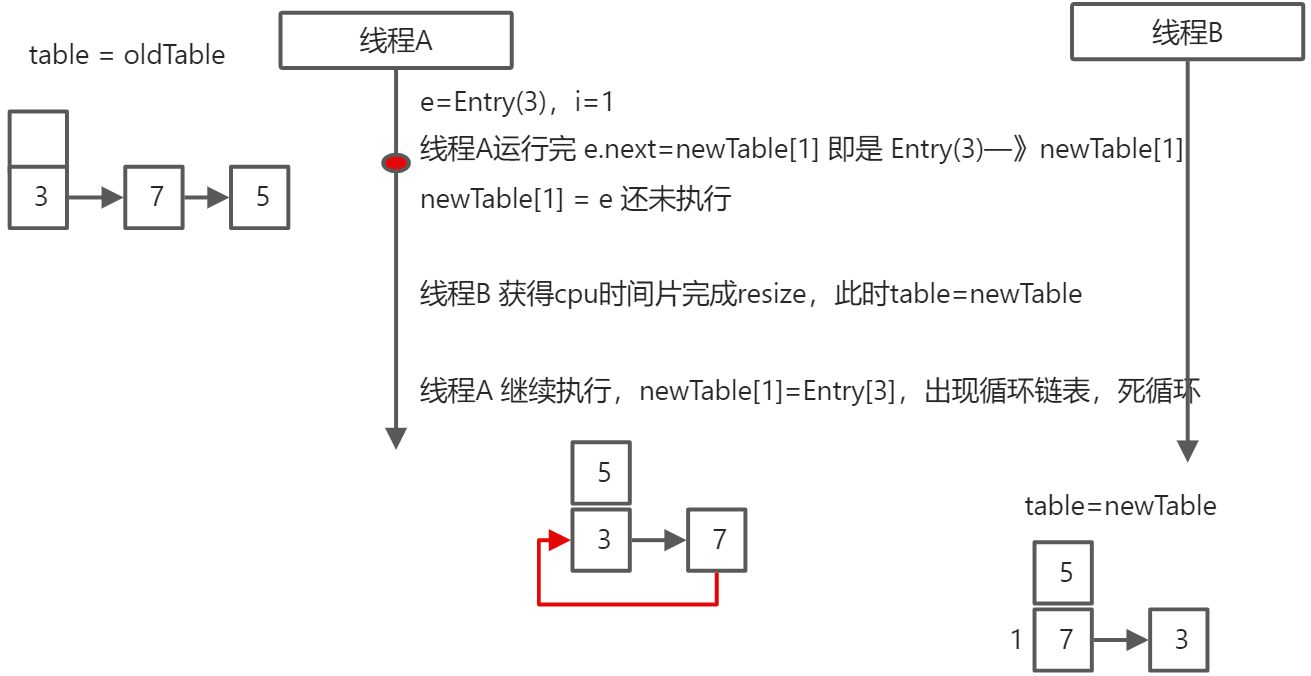
CurrentHashMap分析
https://www.jianshu.com/p/865c813f2726
jdk1.7 CurrentHashMap
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。 Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色; HashEntry则用于存储键值对数据。 一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
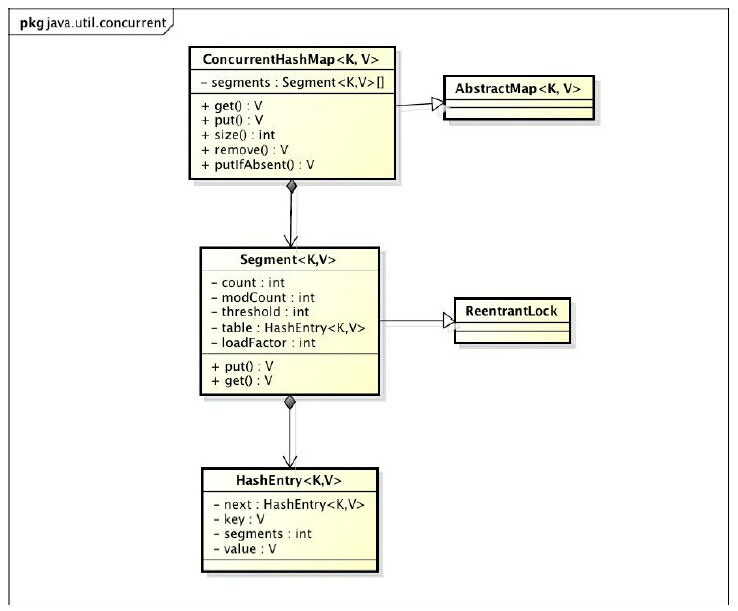
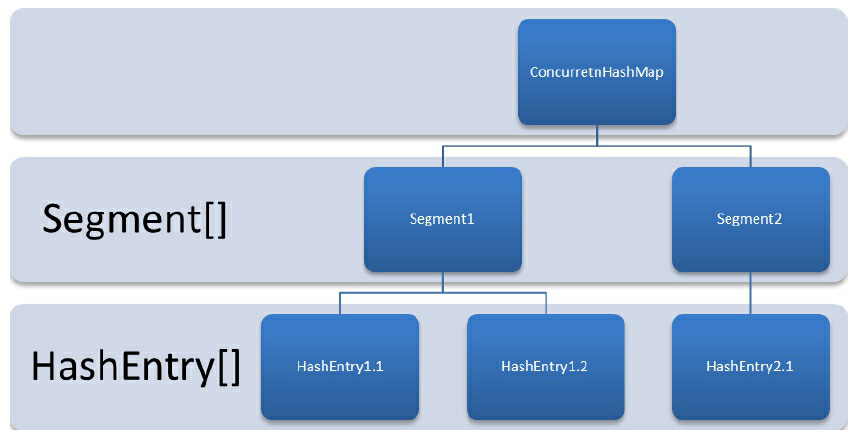
初始化—构造方法
// DEFAULT_INITIAL_CAPACITY=16 , DEFAULT_LOAD_FACTOR=0.75f ,DEFAULT_CONCURRENCY_LEVEL=16
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// 参数检查
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// MAX_SEGMENTS = 1 << 16 2^16 = 65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS; // 并发等级为25536
// Find power-of-two sizes best matching arguments
int sshift = 0; // 移位次数
int ssize = 1; // sigmentSize 是2的幂次方
while (ssize < concurrencyLevel) { // 默认DEFAULT_CONCURRENCY_LEVEL = 16 = 2^4
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift; // 默认情况 sshift=4
this.segmentMask = ssize - 1; // 默认情况 ssize=16 用来求segment[]数组索引
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
//c 为 segment的数量
// MIN_SEGMENT_TABLE_CAPACITY=2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
get
get方法没有加锁,使用的是UNSAFE.getObjectVolatile,volatile语言保证了内存可见性。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
// 定位到哪一个segement
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 找到对应的segment,在segment 的 HashEntry[] 继续寻找
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); // 定位到哪一个HashEntry e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value; // 找到返回
}
}
return null;
}
put
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必
须加锁。put方法首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个
步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位
置,然后将其放在HashEntry数组里。
(1)是否需要扩容
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阈
值,则对数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap
是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容
之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
(2)如何扩容
在扩容的时候,首先会创建一个容量是原来容量两倍的数组,然后将原数组里的元素进
行再散列后插入到新的数组里。为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只
对某个segment进行扩容。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask; // 定位到哪一个segment
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 加锁 保证多线程安全
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
size
如果要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小
后求和。
ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如
果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
jdk1.8 CurrentHashMap
静态常量
// node数组最大容量 2^30
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 初始容量 16
private static final int DEFAULT_CAPACITY = 16;
// 数组可能最大值
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 并发级别
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 默认加载因子
private static final float LOAD_FACTOR = 0.75f;
// 链表转换为红黑树阈值
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转换链表阈值
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
private static final int MIN_TRANSFER_STRIDE = 16;
private static int RESIZE_STAMP_BITS = 16;
// help resize的最大线程数 2^15-1
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// sizeCtl 中记录size大小的偏移量
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// CPU的数量
static final int NCPU = Runtime.getRuntime().availableProcessors();
/** For serialization compatibility. */
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
Node结构
Node是一个单向链表结构,允许查询数据,不允许修改
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
// 不允许更新value
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
TreeNode
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 标志红黑树的红节点
TreeNode(int hash, K key, V val, Node<K,V> next,TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
// 根据给定的key,从根节点找出相应的TreeNode
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
}
put
:::info
- 如果没有初始化就先调用initTable()方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
- 最后一个如果Hash冲突时会形成Node链表,在链表长度超过8,Node数组超过64时会将链表结构转换为红黑树的结构,break再一次进入循环
如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容 ::: ```java public V put(K key, V value) {
return putVal(key, value, false );
}
/* Implementation for put and putIfAbsent /
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null ) throw new NullPointerException();
int hash = spread(key.hashCode()); //两次hash,减少hash冲突,可以均匀分布
int binCount = 0 ;
for (Node<K,V>[] tab = table;;) { //对这个table进行迭代
Node<K,V> f; int n, i, fh;
//这里就是上面构造方法没有进行初始化,在这里进行判断,为null就调用initTable进行初始化,属于懒汉模式初始化
if (tab == null || (n = tab.length) == 0 )
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { //如果i位置没有数据,就直接无锁插入
if (casTabAt(tab, i, null ,
new Node<K,V>(hash, key, value, null )))
break ; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) //如果在进行扩容,则先进行扩容操作
tab = helpTransfer(tab, f);
else {
V oldVal = null ;
//如果以上条件都不满足,那就要进行加锁操作,也就是存在hash冲突,锁住链表或者红黑树的头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0 ) { //表示该节点是链表结构
binCount = 1 ;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//这里涉及到相同的key进行put就会覆盖原先的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break ;
}
Node<K,V> pred = e;
if ((e = e.next) == null ) { //插入链表尾部
pred.next = new Node<K,V>(hash, key,
value, null );
break ;
}
}
}
else if (f instanceof TreeBin) { //红黑树结构
Node<K,V> p;
binCount = 2 ;
//红黑树结构旋转插入
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null ) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0 ) { //如果链表的长度大于8时就会进行红黑树的转换
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null )
return oldVal;
break ;
}
}
}
addCount(1L, binCount); //统计size,并且检查是否需要扩容
return null ;
}

若有收获,就点个赞吧
0 人点赞
