哈希函数
- 输入参数data,假设是in类型,特征:可能性无穷大,比如str类型的参数
- 输出参数类型out,特征:可能性可以很大,但一定是有穷尽的
- 哈希函数没有任何随机的机制,固定的输入一定是固定的输出
- 输入无穷多但输出值有限,所以不同输入也可能输出相同(哈希碰撞)
再相似的不同输入,得到的输出值,会几乎均匀的分布在out域上(重点:第5条!)
布隆过滤器
Bloom过滤器原理
Bloom过滤器是以个比特位数组 arr[n]
当添加一个元素foo到Bloom过滤器,先对这个元素进行hash散列hash(foo)
- 然后求下标 i = hash(foo) % n (n是bits数组的长度)
- 根据下标,将位数组对于下标位设置为1,,即arr[i] = 1
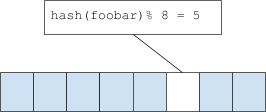
- 如果需要去数据库查询某个元素bar时,为避免缓存穿透,先对bar进行bloom过滤,如果bloom过滤器存在,那么去查询数据库,如果不存在,直接返回不存在。
- Bloom过滤器一定存在失误率(bloom过滤器中存在的一定能查到,不存在的可能会查到)。对于哈希碰撞导致不存在的元素缺查询出来存在的问题,可以通过设置多个hash函数那降低失误概率。
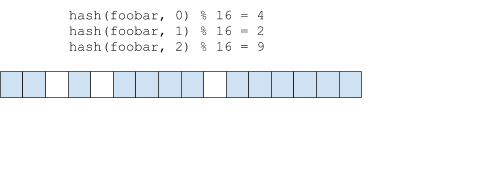
举个例子
过滤url,1000亿个url(黑名单),黑名单中的url无法访问,对url进行过滤,可能不在黑名单中的url会被过滤掉无法访问,这就是bloom的失误率。
影响失误率的因素有总体数据量大小n,bitmap的大小m,哈希函数的个数n,可以进行估算失误率。
布隆过滤器的三个重要公式(记住)
- 假设数据量为n,预期的失误率为p(布隆过滤器大小和每个样本的大小无关)
- 根据n和p,算出Bloom Filter一共需要多少个bit位,向上取整,记为m
- 根据m和n,算出Bloom Filter需要多少个哈希函数,向上取整,记为k
- 根据修正公式,算出真实的失误率p_true



举个例子:数据量100亿,失误率0.0001
100亿数据,通过哈希函数都会变成1位信息,因此—》100亿bit,1.25G
100亿位——》1.17GB
——》 使用约23G空间 14个哈希哈数,失误率大约在0.000007
(1) m 向上取整23G
(2) k 向上取整 14
(3) p_true = 0.0001%
一致哈希设计
例:Redis集群,一致性哈希:https://www.yuque.com/ixiaoyu/uimvv2/gtuzzb#yqBJQ
- 哈希域变成环的设计
- 虚拟节点技术
资源限制类题目技巧
- 布隆过滤器用于集合的建立与查询,并可以节省大量空间
- 一致性哈希解决数据服务器的负载管理问题
- 利用并查集结构做岛问题的并行计算
- 哈希函数可以把数据按照种类均匀分流
- 位图解决某一范围上数字的出现情况,并可以节省大量空间
- 利用分段统计思想、并进一步节省大量空间
- 利用堆、外排序来做多个处理单元的结果合并
题目1
32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,可以使用最多1GB的内存,怎么找到出现次数最多的数?(技巧:哈希函数可以把数据按照种类均匀分流)
1个无符号整数是4字节 ,40亿就是160亿字节 约 16G,采用排序不可行
hash表 map
如果1G内存都做hash表能装多少记录?-》 约125 000 000条,考虑索引的内存,1000万条记录()是一定能放下的,40亿/1000万 = 400
准备400个小文件,将40亿个无符号整数%400分配到400个小文件中,同一种数只会进入同一份文件
然后依次找到每个小文件的最大次数的整数,在对400个小文件的次数最大的整数求最大值
题目2
32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,所以在整个范围中必然存在没出现过的数。可以使用最多1GB的内存,怎么找到所有未出现过的数?【进阶】内存限制为 3KB,但是只用找到一个没出现过的数即可(位图解决某一范围上数字的出现情况,并可以节省大量空间)
(1)1G内存
2^32 bit/ 2^3 = 2^29 = 500M
40亿bit/8 ≈480M
准备0~2^32位的大位图,遍历40亿无符号整数,出现的数字位图对应位置标1,遍历完后为0的位置的下标为 没有出现过的数
(2)3KB,只用找出1个没出现过的数
3KB/4 = 750,最接近750的二次幂 512,生成数组int[512]
将0~2^32 整个范围分成512份,必能均分,每份8388608(2^23)
然而只有40亿个数,不够2^32次方,必然有一份不够8388608,这份必然有没有出现的数字,对这个范围继续分成512份,依次分下去,直到某一个范围可以用3kb内存做bit位统计,找到1个没有出现的数
题目3
有一个包含100亿个URL的大文件,假设每个URL占用64B,请找出其中所有重复的URL【补充】某搜索公司一天的用户搜索词汇是海量的(百亿数据量),请设计一种求出每天热门Top100词汇的可行办法(技巧:堆排序、外排序)
分成多份,每份的前100在进行比较出前100,注意内存范围内
题目4
32位无符号整数的范围是0~4294967295,现在有40亿个无符号整数,可以使用最多1GB的内存,找出所有出现了两次的数。位图
2位表示1个数 00 出现0次 01 出现1次 10 出现2次 11出现3次及以上,统计出现次数 10 的数
题目5
32位无符号整数的范围是0~4294967295,现在有40亿个无符号整数可以使用最多3K的内存,怎么找到这40亿个整数的中位数?(技巧:分段统计思想)
求第20亿小的数
3KB/4 = 750,最接近750的二次幂 512,生成数组int[512]
将0~2^32 整个范围分成512份,必能均分,每份8388608(2^23)
然而只有40亿个数,不够2^32次方,必然有一份不够8388608,这份必然有没有出现的数字,对这个范围继续分成512份,依次分下去,直到某一个范围可以用3kb内存做bit位统计,依次对数做词频统计
依次累加词频,看那一份刚好超过20亿或等于20亿,中位数就在那一份上
题目6
32位无符号整数的范围是0~4294967295,有一个10G大小的文件,每一行都装着这种类型的数字,整个文件是无序的,给你5G的内存空间,请你输出一个10G大小的文件,就是原文件所有数字排序的结果(技巧:堆排序)

若有收获,就点个赞吧
0 人点赞
