Redis可以用作缓存、数据库,作为缓存时允许数据丢失,且需要保证缓存数据的热度,需要设置内存管理策略,比如LRU、LFU等;作为数据库时,需要保证数据可靠性,就需要对数据库数据做持久化,Redis持久化方案包括允许丢失部分数据的RDB(恢复数据时较快)和不允许丢失数据的AOF(恢复数据相对较慢)。
Redis主从复制
但是Redis作为单机使用时会有几个问题:
- 单点故障问题
- 容量有限问题
- 连接压力问题
AKF扩展立方体(Scalability Cube),是《架构即未来》一书中提出的可扩展模型,这个立方体有三个轴线,每个轴线描述扩展性的一个维度,他们分别是产品、流程和团队:
X轴 —— 代表无差别的克隆服务和数据,工作可以很均匀的分散在不同的服务实例上;
Y轴 —— 关注应用中职责的划分,比如数据类型,交易执行类型的划分;
Z轴 —— 关注服务和数据的优先级划分,如分地域划分。
根据AKF原则对单机Redis存在的问题进行进行处理:
- 针对单点故障,可以考虑做集群,主从\主备复制,但是这时就会带来主从\主备数据一致性的问题。(全量复制)
- 连接压力问题,可以根据业务划分到不同的Redis集群里,这样访问不同的业务时会连接到不同的Redis集群,缓解连接压力,同时也降低容量有限问题。
- 容量有限问题,可以根据数据优先级等规则将数据进行划分,存储到不同的Redis中。
但是存在数据一致性问题——如何解决数据一致性问题?
- 强一致性——采取同步阻塞的方式 ——》弊端:带来服务不可用的问题
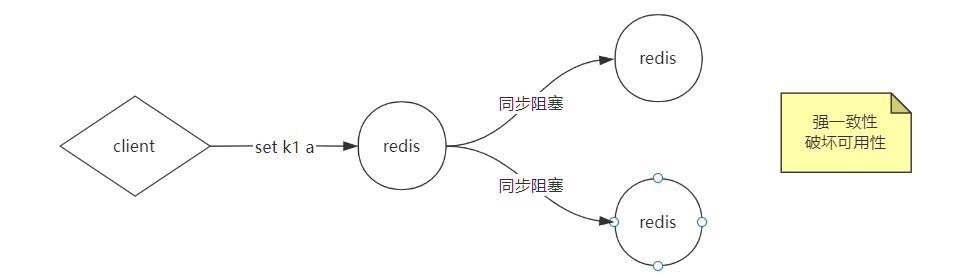
- 弱一致性——异步方式 ——》弊端:数据可能丢失的问题
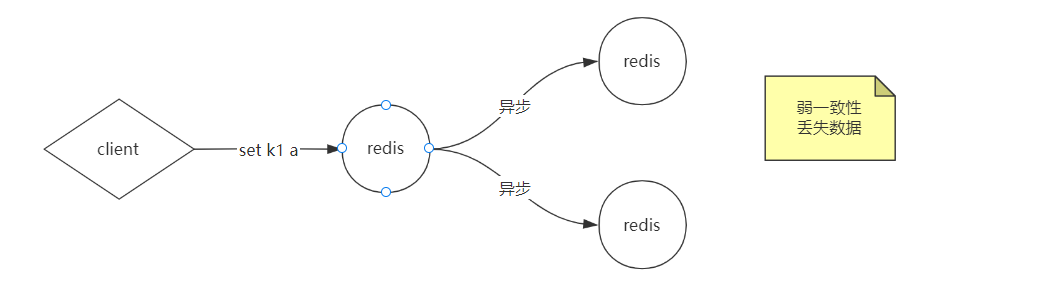
- 最终一致性——异步+消息队列 ——》弊端系统复杂性增加,数据同步期间可能渠道不一致的数据
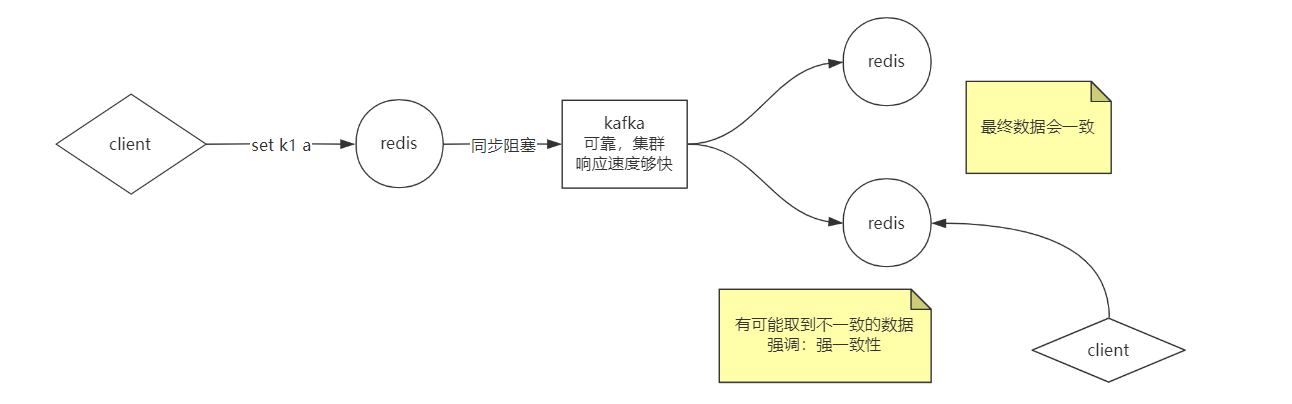
Redis集群采取最终一致性法方式对主从\主备进行数据一致性处理
Redis 一主二从 示例
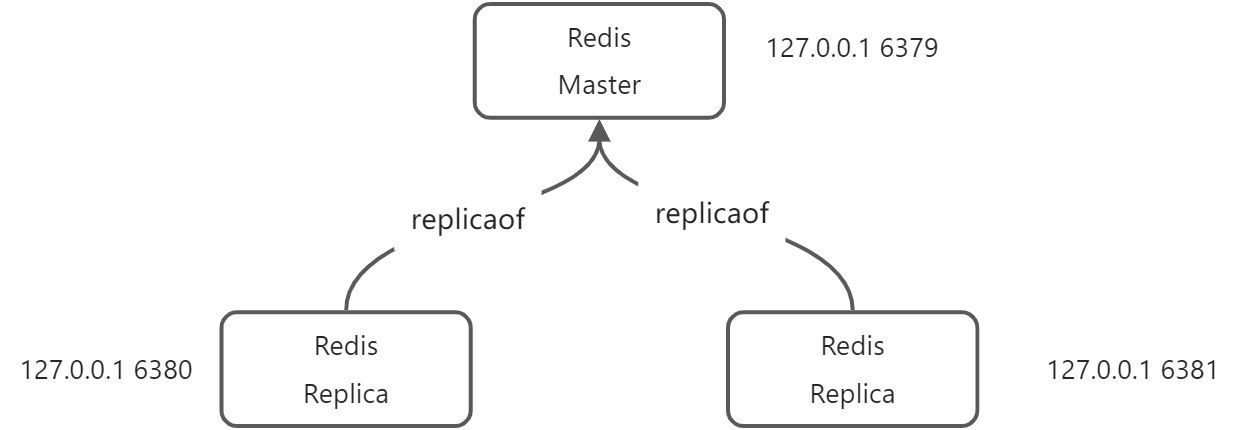
Redis主从集群依赖三个主要的机制:
- 当一个 master 实例和一个 slave 实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给 slave ,包括客户端的写入、key 的过期或被逐出等等。
- 当 master 和 slave 之间的连接断开之后,因为网络问题、或者是主从意识到连接超时, slave 重新连接上 master 并会尝试进行部分重同步,这意味着它会尝试只获取在断开连接期间内丢失的命令流。
- 当无法进行部分重同步时, slave 会请求进行全量重同步。这会涉及到一个更复杂的过程,例如 master 需要创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave。
Redis复制功能如何工作?
http://www.redis.cn/topics/replication.html
每一个 Redis master 都有一个 replication ID :这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新 slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增,所以基本上每一对给定的 Replication ID, offset 都会标识一个 master 数据集的确切版本。
当 slave 连接到 master 时,它们使用 PSYNC 命令来发送它们记录的旧的 master replication ID 和它们至今为止处理的偏移量。通过这种方式, master 能够仅发送 slave 所需的增量部分。但是如果 master 的缓冲区中没有足够的命令积压缓冲记录,或者如果 slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量重同步:在这种情况下, slave 会得到一个完整的数据集副本,从头开始。
全量数据同步
- master 开启一个后台保存进程,以便于生产一个 RDB 文件。
- 同时它开始缓冲所有从客户端接收到的新的写入命令。当后台保存完成时, master 将数据集文件传输给 slave, slave将之保存在磁盘上,然后加载文件到内存。
- 再然后 master 会发送所有缓冲的命令发给 slave。这个过程以指令流的形式完成并且和 Redis 协议本身的格式相同。
- 当主从之间的连接因为一些原因崩溃之后, slave 能够自动重连。如果 master 收到了多个 slave 要求同步的请求,它会执行一个单独的后台保存,以便于为多个 slave 服务。
无需磁盘参与的复制
正常情况下,一个全量重同步要求在磁盘上创建一个 RDB 文件,然后将它从磁盘加载进内存,然后 slave以此进行数据同步。
如果磁盘性能很低的话,这对 master 是一个压力很大的操作。Redis 2.8.18 是第一个支持无磁盘复制的版本。在此设置中,子进程直接发送 RDB 文件给 slave,无需使用磁盘作为中间储存介质。
Redis 复制如何处理 key 的过期
- slave 不会让 key 过期,而是等待 master 让 key 过期。当一个 master 让一个 key 到期(或由于 LRU 算法将之驱逐)时,它会合成一个 DEL 命令并传输到所有的 slave。
- 但是,由于这是 master 驱动的 key 过期行为,master 无法及时提供 DEL 命令,所以有时候 slave 的内存中仍然可能存在在逻辑上已经过期的 key 。为了处理这个问题,slave 使用它的逻辑时钟以报告只有在不违反数据集的一致性的读取操作(从主机的新命令到达)中才存在 key。用这种方法,slave 避免报告逻辑过期的 key 仍然存在。在实际应用中,使用 slave 程序进行缩放的 HTML 碎片缓存,将避免返回已经比期望的时间更早的数据项。
当Master关闭持久化时复制的安全性
在使用 Redis 复制功能时的设置中,强烈建议在 master 和在 slave 中启用持久化。当不可能启用时,例如由于非常慢的磁盘性能而导致的延迟问题,应该配置实例来避免重置后自动重启。
例:
- 我们设置节点 A 为 master 并关闭它的持久化设置,节点 B 和 C 从 节点 A 复制数据。
- 节点 A 崩溃,但是他有一些自动重启的系统可以重启进程。但是由于持久化被关闭了,节点重启后其数据集合为空。
- 节点 B 和 节点 C 会从节点 A 复制数据,但是节点 A 的数据集是空的,因此复制的结果是它们会销毁自身之前的数据副本。
当 Redis Sentinel 被用于高可用并且 master 关闭持久化,这时如果允许自动重启进程也是很危险的。例如, master 可以重启的足够快以致于 Sentinel 没有探测到故障,因此上述的故障模式也会发生。
任何时候数据安全性都是很重要的,所以如果 master 使用复制功能的同时未配置持久化,那么自动重启进程这项应该被禁用。
Redis高可用
http://www.redis.cn/topics/sentinel.html
Redis进行主从\主备复制,但是对于主机而言依然是单点,主机宕机故障,整个集群就依然不可用,因此在主机宕机后需要新的主机出现——》实现Redis集群的高可用。
- 主机宕机后,手动切换一个从机为主机
Sentinel 哨兵模式
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance),该系统执行以下三个任务:
监控(Monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
启动Sentinel redis-server /path/to/sentinel.conf —sentinel 启动 Sentinel 实例必须指定相应的配置文件, 系统会使用配置文件来保存 Sentinel 的当前状态, 并在 Sentinel 重启时通过载入配置文件来进行状态还原。如果启动 Sentinel 时没有指定相应的配置文件, 或者指定的配置文件不可写(not writable), 那么 Sentinel 会拒绝启动。
#指示 Sentinel 去监视一个名为 mymaster 的主服务器,#这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6379#而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意#(只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)sentinel monitor mymaster 127.0.0.1 6379 2#指定了 Sentinel 认为服务器已经断线所需的毫秒数#如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误,#那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。sentinel down-after-milliseconds mymaster 60000# 故障转移超时sentinel failover-timeout mymaster 180000#选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步sentinel parallel-syncs mymaster 1
# *** IMPORTANT ***## By default Sentinel will not be reachable from interfaces different than# localhost, either use the 'bind' directive to bind to a list of network# interfaces, or disable protected mode with "protected-mode no" by# adding it to this configuration file.## Before doing that MAKE SURE the instance is protected from the outside# world via firewalling or other means.## For example you may use one of the following:## bind 127.0.0.1 192.168.1.1## protected-mode no# port <sentinel-port># The port that this sentinel instance will run onport 26379 # sentinel端口号# By default Redis Sentinel does not run as a daemon. Use 'yes' if you need it.# Note that Redis will write a pid file in /var/run/redis-sentinel.pid when# daemonized.daemonize no # 是否后台运行# When running daemonized, Redis Sentinel writes a pid file in# /var/run/redis-sentinel.pid by default. You can specify a custom pid file# location here.pidfile /var/run/redis-sentinel.pid# Specify the log file name. Also the empty string can be used to force# Sentinel to log on the standard output. Note that if you use standard# output for logging but daemonize, logs will be sent to /dev/nulllogfile ""# sentinel announce-ip <ip># sentinel announce-port <port>## The above two configuration directives are useful in environments where,# because of NAT, Sentinel is reachable from outside via a non-local address.## When announce-ip is provided, the Sentinel will claim the specified IP address# in HELLO messages used to gossip its presence, instead of auto-detecting the# local address as it usually does.## Similarly when announce-port is provided and is valid and non-zero, Sentinel# will announce the specified TCP port.## The two options don't need to be used together, if only announce-ip is# provided, the Sentinel will announce the specified IP and the server port# as specified by the "port" option. If only announce-port is provided, the# Sentinel will announce the auto-detected local IP and the specified port.## Example:## sentinel announce-ip 1.2.3.4# dir <working-directory># Every long running process should have a well-defined working directory.# For Redis Sentinel to chdir to /tmp at startup is the simplest thing# for the process to don't interfere with administrative tasks such as# unmounting filesystems.dir /tmp# sentinel monitor <master-name> <ip> <redis-port> <quorum>## Tells Sentinel to monitor this master, and to consider it in O_DOWN# (Objectively Down) state only if at least <quorum> sentinels agree.## Note that whatever is the ODOWN quorum, a Sentinel will require to# be elected by the majority of the known Sentinels in order to# start a failover, so no failover can be performed in minority.## Replicas are auto-discovered, so you don't need to specify replicas in# any way. Sentinel itself will rewrite this configuration file adding# the replicas using additional configuration options.# Also note that the configuration file is rewritten when a# replica is promoted to master.## Note: master name should not include special characters or spaces.# The valid charset is A-z 0-9 and the three characters ".-_".sentinel monitor mymaster 127.0.0.1 6379 2# sentinel auth-pass <master-name> <password>## Set the password to use to authenticate with the master and replicas.# Useful if there is a password set in the Redis instances to monitor.## Note that the master password is also used for replicas, so it is not# possible to set a different password in masters and replicas instances# if you want to be able to monitor these instances with Sentinel.## However you can have Redis instances without the authentication enabled# mixed with Redis instances requiring the authentication (as long as the# password set is the same for all the instances requiring the password) as# the AUTH command will have no effect in Redis instances with authentication# switched off.## Example:## sentinel auth-pass mymaster MySUPER--secret-0123passw0rd# sentinel down-after-milliseconds <master-name> <milliseconds>## Number of milliseconds the master (or any attached replica or sentinel) should# be unreachable (as in, not acceptable reply to PING, continuously, for the# specified period) in order to consider it in S_DOWN state (Subjectively# Down).## Default is 30 seconds.sentinel down-after-milliseconds mymaster 30000# sentinel parallel-syncs <master-name> <numreplicas>## How many replicas we can reconfigure to point to the new replica simultaneously# during the failover. Use a low number if you use the replicas to serve query# to avoid that all the replicas will be unreachable at about the same# time while performing the synchronization with the master.sentinel parallel-syncs mymaster 1# sentinel failover-timeout <master-name> <milliseconds>## Specifies the failover timeout in milliseconds. It is used in many ways:## - The time needed to re-start a failover after a previous failover was# already tried against the same master by a given Sentinel, is two# times the failover timeout.## - The time needed for a replica replicating to a wrong master according# to a Sentinel current configuration, to be forced to replicate# with the right master, is exactly the failover timeout (counting since# the moment a Sentinel detected the misconfiguration).## - The time needed to cancel a failover that is already in progress but# did not produced any configuration change (SLAVEOF NO ONE yet not# acknowledged by the promoted replica).## - The maximum time a failover in progress waits for all the replicas to be# reconfigured as replicas of the new master. However even after this time# the replicas will be reconfigured by the Sentinels anyway, but not with# the exact parallel-syncs progression as specified.## Default is 3 minutes.sentinel failover-timeout mymaster 180000 ## 故障转转移超时# SCRIPTS EXECUTION## sentinel notification-script and sentinel reconfig-script are used in order# to configure scripts that are called to notify the system administrator# or to reconfigure clients after a failover. The scripts are executed# with the following rules for error handling:## If script exits with "1" the execution is retried later (up to a maximum# number of times currently set to 10).## If script exits with "2" (or an higher value) the script execution is# not retried.## If script terminates because it receives a signal the behavior is the same# as exit code 1.## A script has a maximum running time of 60 seconds. After this limit is# reached the script is terminated with a SIGKILL and the execution retried.# NOTIFICATION SCRIPT## sentinel notification-script <master-name> <script-path>## Call the specified notification script for any sentinel event that is# generated in the WARNING level (for instance -sdown, -odown, and so forth).# This script should notify the system administrator via email, SMS, or any# other messaging system, that there is something wrong with the monitored# Redis systems.## The script is called with just two arguments: the first is the event type# and the second the event description.## The script must exist and be executable in order for sentinel to start if# this option is provided.## Example:## sentinel notification-script mymaster /var/redis/notify.sh# CLIENTS RECONFIGURATION SCRIPT## sentinel client-reconfig-script <master-name> <script-path>## When the master changed because of a failover a script can be called in# order to perform application-specific tasks to notify the clients that the# configuration has changed and the master is at a different address.## The following arguments are passed to the script:## <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>## <state> is currently always "failover"# <role> is either "leader" or "observer"## The arguments from-ip, from-port, to-ip, to-port are used to communicate# the old address of the master and the new address of the elected replica# (now a master).## This script should be resistant to multiple invocations.## Example:## sentinel client-reconfig-script mymaster /var/redis/reconfig.sh# SECURITY## By default SENTINEL SET will not be able to change the notification-script# and client-reconfig-script at runtime. This avoids a trivial security issue# where clients can set the script to anything and trigger a failover in order# to get the program executed.sentinel deny-scripts-reconfig yes# REDIS COMMANDS RENAMING## Sometimes the Redis server has certain commands, that are needed for Sentinel# to work correctly, renamed to unguessable strings. This is often the case# of CONFIG and SLAVEOF in the context of providers that provide Redis as# a service, and don't want the customers to reconfigure the instances outside# of the administration console.## In such case it is possible to tell Sentinel to use different command names# instead of the normal ones. For example if the master "mymaster", and the# associated replicas, have "CONFIG" all renamed to "GUESSME", I could use:## SENTINEL rename-command mymaster CONFIG GUESSME## After such configuration is set, every time Sentinel would use CONFIG it will# use GUESSME instead. Note that there is no actual need to respect the command# case, so writing "config guessme" is the same in the example above.## SENTINEL SET can also be used in order to perform this configuration at runtime.## In order to set a command back to its original name (undo the renaming), it# is possible to just rename a command to itsef:## SENTINEL rename-command mymaster CONFIG CONFIG
主观下线和客观下线
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复(valid reply), 那么 Sentinel 就会将这个服务器标记为主观下线。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
每个 Sentinel 都需要定期执行的任务
- 每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者 -MASTERDOWN 。
- 如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。 当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主观下线状态就会被移除。
自动发现 Sentinel 和从服务器
一个 Sentinel 可以与其他多个 Sentinel 进行连接, 各个 Sentinel 之间可以互相检查对方的可用性, 并进行信息交换。 Sentinel 可以通过master发布与订阅功能来自动发现正在监视相同主服务器的其他 Sentinel , 这一功能是通过向频道 sentinel:hello 发送信息来实现的。
故障转移
一次故障转移操作由以下步骤组成:
发现主服务器已经进入客观下线状态。
- 对我们的当前纪元(epoch)进行自增(详情请参考 Raft leader election ), 并尝试在这个纪元中当选。
- 如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤。
- 选出一个从服务器,并将它升级为主服务器。
- 向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
- 通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
- 向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
- 当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
Sentinel 使用以下规则来选择新的主服务器:
- 在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。
- 在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。
- 在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。

若有收获,就点个赞吧
0 人点赞
