- 消息订阅
- 事务
- 管道技术
- Modules
- Redis 内存管理和缓存
- Set a memory usage limit to the specified amount of bytes.
- When the memory limit is reached Redis will try to remove keys
- according to the eviction policy selected (see maxmemory-policy).
- If Redis can’t remove keys according to the policy, or if the policy is
- set to ‘noeviction’, Redis will start to reply with errors to commands
- that would use more memory, like SET, LPUSH, and so on, and will continue
- to reply to read-only commands like GET.
- This option is usually useful when using Redis as an LRU or LFU cache, or to
- set a hard memory limit for an instance (using the ‘noeviction’ policy).
- WARNING: If you have replicas attached to an instance with maxmemory on,
- the size of the output buffers needed to feed the replicas are subtracted
- from the used memory count, so that network problems / resyncs will
- not trigger a loop where keys are evicted, and in turn the output
- buffer of replicas is full with DELs of keys evicted triggering the deletion
- of more keys, and so forth until the database is completely emptied.
- In short… if you have replicas attached it is suggested that you set a lower
- limit for maxmemory so that there is some free RAM on the system for replica
- output buffers (but this is not needed if the policy is ‘noeviction’).
- maxmemory
配置最大可使用内存 - MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
- is reached. You can select among five behaviors:
- volatile-lru -> Evict using approximated LRU among the keys with an expire set.
- allkeys-lru -> Evict any key using approximated LRU.
- volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
- allkeys-lfu -> Evict any key using approximated LFU.
- volatile-random -> Remove a random key among the ones with an expire set.
- allkeys-random -> Remove a random key, any key.
- volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
- noeviction -> Don’t evict anything, just return an error on write operations.
- LRU means Least Recently Used
- LFU means Least Frequently Used
- Both LRU, LFU and volatile-ttl are implemented using approximated
- randomized algorithms.
- Note: with any of the above policies, Redis will return an error on write
- operations, when there are no suitable keys for eviction.
- At the date of writing these commands are: set setnx setex append
- incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
- sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
- zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
- getset mset msetnx exec sort
- The default is:
- maxmemory-policy noeviction
- LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated
- algorithms (in order to save memory), so you can tune it for speed or
- accuracy. For default Redis will check five keys and pick the one that was
- used less recently, you can change the sample size using the following
- configuration directive.
- The default of 5 produces good enough results. 10 Approximates very closely
- true LRU but costs more CPU. 3 is faster but not very accurate.
- maxmemory-samples 5
- Starting from Redis 5, by default a replica will ignore its maxmemory setting
- (unless it is promoted to master after a failover or manually). It means
- that the eviction of keys will be just handled by the master, sending the
- DEL commands to the replica as keys evict in the master side.
- This behavior ensures that masters and replicas stay consistent, and is usually
- what you want, however if your replica is writable, or you want the replica to have
- a different memory setting, and you are sure all the writes performed to the
- replica are idempotent, then you may change this default (but be sure to understand
- what you are doing).
- Note that since the replica by default does not evict, it may end using more
- memory than the one set via maxmemory (there are certain buffers that may
- be larger on the replica, or data structures may sometimes take more memory and so
- forth). So make sure you monitor your replicas and make sure they have enough
- memory to never hit a real out-of-memory condition before the master hits
- the configured maxmemory setting.
- replica-ignore-maxmemory yes
消息订阅
http://doc.redisfans.com/topic/pubsub.html
list 有BLPOP、BRPOP、BRPOPLPUSH,实现了阻塞单播队列,当多个client操作同一个key时,会按照顺序进行取出操作(先阻塞的客户端先获取数据,获取数据后取消阻塞)。
而消息订阅是实现一份消息被多个订阅者同时获取,即发送者publisher发送消息到频道channel,订阅者subcriber订阅频道获取消息。一个频道可以有多个订阅者,一个redis client可以订阅任意数量的频道。
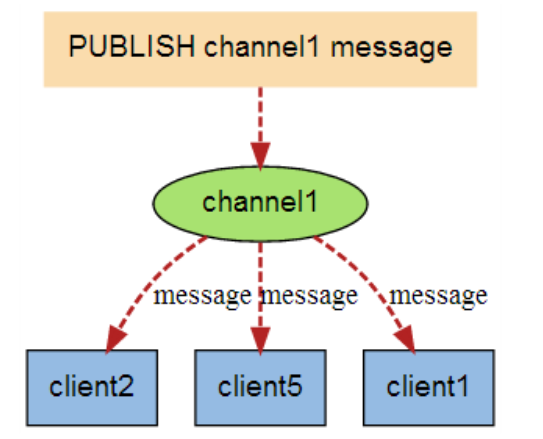
Redis 发布订阅命令
下表列出了 redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | PSUBSCRIBE pattern [pattern …] 订阅一个或多个符合给定模式的频道。 |
| 2 | PUBSUB subcommand [argument [argument …]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | PUNSUBSCRIBE [pattern [pattern …]] 退订所有给定模式的频道。 |
| 5 | SUBSCRIBE channel [channel …] 订阅给定的一个或多个频道的信息。 |
| 6 | UNSUBSCRIBE [channel [channel …]] 指退订给定的频道。 |
事务
http://doc.redisfans.com/topic/transaction.html
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
Redis事务在失败时不进行回滚,而是继续执行剩余的命令——redis命令只会因为语法错误而失败,而语法的错发在开发过程中倍发现处理,而不应该出现在生产环境。因为不需要进行回滚,所以Redis内部可以保持简单快速。
Redis 事务命令
下表列出了 redis 事务的相关命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | DISCARD 取消事务,放弃执行事务块内的所有命令。 |
| 2 | EXEC 执行所有事务块内的命令。 |
| 3 | MULTI 标记一个事务块的开始。 |
| 4 | UNWATCH 取消 WATCH 命令对所有 key 的监视。 |
| 5 | WATCH key [key …] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。 |
EXEC 命令负责触发并执行事务中的所有命令:
- 如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。
- 另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
WATCH 命令可以为 Redis 事务提供 check-and-set (CAS)行为。
- 被 WATCH 的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回空多条批量回复(null multi-bulk reply)来表示事务已经失败。
- 如果使用 WATCH 监视了一个带过期时间的键, 那么即使这个键过期了, 事务仍然可以正常执行
- WATCH 命令可以被调用多次。 对键的监视从 WATCH 执行之后开始生效, 直到调用 EXEC 为止。还可以在单个 WATCH 命令中监视任意多个键。
- 当 EXEC 被调用时, 不管事务是否成功执行, 对所有键的监视都会被取消。 当客户端断开连接时, 该客户端对键的监视也会被取消。使用无参数的 UNWATCH 命令可以手动取消对所有键的监视。
对于一些需要改动多个键的事务, 有时候程序需要同时对多个键进行加锁, 然后检查这些键的当前值是否符合程序的要求。 当值达不到要求时, 就可以使用 UNWATCH 命令来取消目前对键的监视, 中途放弃这个事务, 并等待事务的下次尝试。
管道技术
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。管道技术最显著的优势是提高了 redis 服务的性能。
echo -en "set num1 5 \n incr num1 \n get num1\n" | nc localhost 6379

Modules
https://redis.io/docs/modules/
https://docs.redis.com/latest/modules/
modules-redisbloom.pdf
Redis模块丰富了Redis的核心数据结构,包括搜索能力和现代数据模型,如JSON、图表、时间序列和人工智能(AI)。Redis模块允许开发者在Redis的基础上构建新的应用服务,同时继续享受Redis的亚毫秒速度。此外,在数据库层中包含多个数据模型可以消除不必要的多个数据库开销,保持低延迟,减少开销,并消除应用程序层和多个数据库之间繁琐的通信和连接管理。
| Module Name | discription | github link |
|---|---|---|
| RedisSearch | Redis的查询和索引引擎,提供二级索引、全文搜索和聚合 | https://github.com/RediSearch/RediSearch |
| RedisJSON | RedisJSON - Redis的JSON数据类型 | https://github.com/RedisJSON/RedisJSON |
| RedisGraph | 一个图形数据库作为Redis模块 | https://github.com/RedisGraph/RedisGraph |
| RedisBloom | Redis的概率数据类型模块 | https://github.com/RedisBloom/RedisBloom |
| RedisTimeSeries | 时间序列数据结构的Redis | https://github.com/RedisTimeSeries/RedisTimeSeries |
| RedisAI | 一个用于服务张量和执行深度学习图的Redis模块 | https://github.com/RedisAI/RedisAI |
RedisBloom 过滤器
https://docs.redis.com/latest/modules/redisbloom/
Bloom filter是一种概率数据结构,它提供了一种有效的方法来验证一个条目是否确实不在一个集合中。这使得它在访问昂贵资源(如通过网络或磁盘)上搜索项时尤其理想:
如果我有一个大的磁盘数据库,我想知道是否存在的某个key,可以首先查询Bloom过滤器,如果存在那么查询数据库,如果不存在,放弃查询数据库,而直接返回一个否定答复。——》可以减少缓存穿透问题。
Bloom过滤器原理
Bloom过滤器是以个比特位数组 arr[n]
- 当添加一个元素foo到Bloom过滤器,先对这个元素进行hash散列hash(foo)
- 然后求下标 i = hash(foo) % n (n是bits数组的长度)
- 根据下标,将位数组对于下标位设置为1,,即arr[i] = 1
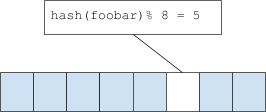
- 如果需要去数据库查询某个元素bar时,为避免缓存穿透,先对bar进行bloom过滤,如果bloom过滤器存在,那么去查询数据库,如果不存在,直接返回不存在。
对于哈希碰撞导致不存在的元素缺查询出来存在的问题,可以通过设置多个hash值那降低概率。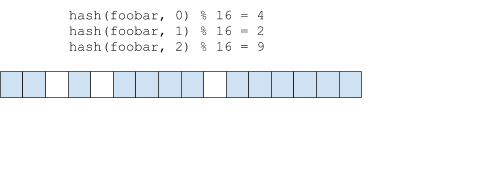
可伸缩Bloom过滤器
通常,创建Bloom过滤器时必须预先知道它们包含多少条目。bpe(bits_prt_element)数需要是固定的,同样,位数组的宽度也是固定的。与哈希表不同,Bloom过滤器不能被重新平衡,因为没有办法知道哪些条目是过滤器的一部分(过滤器只能确定给定的条目是否不存在,但实际上不存储存在的条目)。
为了允许Bloom过滤器缩放,并能够容纳比他们设计的更多的元素,他们可能被堆叠。
一旦一个Bloom过滤器达到容量,就会在其上创建一个新的过滤器。通常,新过滤器比前一个过滤器有更大的容量,以减少需要堆叠另一个过滤器的可能性。在一个可堆叠(可伸缩)的Bloom过滤器,检查成员现在包括检查每一层的存在。现在添加新项需要检查它是否事先不存在,并将其添加到当前筛选器中。然而,散列仍然只需要计算一次。当创建一个Bloom过滤器时——即使是一个可伸缩的过滤器,重要的是要有一个很好的想法,它将包含多少项。如果过滤器的初始层只包含少量元素,则会显著降低性能,因为需要更多层才能达到更大的容量。
Bloom过滤器的使用
- Github clone
- git submodule update —init —recursive 更新初始化子模块
- make 编译 (注意,如果需要使用c99,使用 make CFLAGS=-std=c99),生成redisbloom.so
- 启动redis-server 指定redisbloom.so
redis-server —loadmodule /etc/redis/redisbloom.so
- 或者在配置文件进行配置:loadmodule /etc/redis/redisbloom.so
- 启动后进行使用
Bloom命令
BF.ADD key item
https://redis.io/commands/bf.add/
创建一个空的Bloom Filter,带有单个子过滤器,用于初始请求的容量,并带有上限error_rate。默认情况下,当达到容量时,过滤器通过创建额外的子过滤器自动伸缩。新的子过滤器大小是用前一个子过滤器的大小乘以扩展创膨胀系数。BF.MADD key item [item …]
https://redis.io/commands/bf.madd/
向Bloom Filter添加一个或多个项,如果该过滤器还不存在,则创建该过滤器。该命令的操作与BF相同。添加,只是它允许多个输入和返回多个值。BF.EXISTS key item
https://redis.io/commands/bf.exists/
确定项是否可能存在于Bloom Filter中BF.MEXISTS key item [item …]
https://redis.io/commands/bf.mexists/
确定筛选器中是否存在一个或多个项。BF.RESERVE key error_rate capacity [expansion] [NONSCALING]
https://redis.io/commands/bf.reserve/
创建一个空的Bloom Filter,带有单个子过滤器,用于初始请求的容量,并带有上限error_rate。默认情况下,当达到容量时,过滤器通过创建额外的子过滤器自动伸缩。新的子过滤器大小是用前一个子过滤器的大小乘以扩展创膨胀系数。
创建一个空的Bloom Filter,带有单个子过滤器,用于初始请求的容量,并带有上限error_rate。默认情况下,当达到容量时,过滤器通过创建额外的子过滤器自动伸缩。新的子过滤器大小是用前一个子过滤器的大小乘以扩展创膨胀系数。
- key: 在其下找到过滤器的键
- error_rate: T误报的期望概率.。例如,对于期望的假阳性率0.1% (1 / 1000),error_rate应设置为0.001。
- capacity: 要添加到筛选器的条目数。如果您的过滤器允许缩放,那么在添加超过这个数字的项目后,性能将开始下降。实际的退化程度取决于超出极限的程度。性能随子过滤器数量的增加而线性下降。
- NONSCALING: 在达到初始容量时,防止筛选器创建其他子筛选器。非缩放过滤器比缩放过滤器需要更少的内存。当达到容量时,过滤器返回一个错误
EXPANSION: 当达到容量时,将创建一个额外的子过滤器。新子滤波器的大小等于最后一个子滤波器的大小乘以扩展系数。如果在筛选器中存储的元素数量未知,我们建议您使用2个或更多的扩展,以减少子筛选器的数量。否则,我们建议您使用扩展1来减少内存消耗。默认值为2。
BF.INSERT key [capacity] [error] [expansion] [NOCREATE] [NONSCALING] ITEMS item [item …]
https://redis.io/commands/bf.insert/
是BF.ADD和BF.RESERVE的组合形式NOCREATE: (可选)如果筛选器不存在,则不创建该筛选器。如果筛选器还不存在,则返回一个错误,而不是自动创建它。这可能用于需要在创建过滤器和添加过滤器之间进行严格分离的地方。将NOCREATE与CAPACITY或error一起指定是错误的。
- capacity: (可选)创建过滤器的容量。如果过滤器已经存在,则忽略此参数。如果该过滤器是自动创建的,且该参数不存在,则使用模块级容量。见男朋友。保留有关此值影响的更多信息。
- error: (可选)新建过滤器不存在时,指定新建过滤器的错误率。如果过滤器是自动创建的,并且没有指定错误,则使用模块级错误率。见男朋友。保留有关该值格式的更多信息。
- NONSCALING: 在达到初始容量时,防止筛选器创建其他子筛选器。非缩放过滤器比缩放过滤器需要更少的内存。当达到容量时,过滤器返回一个错误。
expansion: 当达到容量时,将创建一个额外的子过滤器。新子滤波器的大小等于最后一个子滤波器的大小乘以扩展。如果在筛选器中存储的元素数量未知,我们建议您使用2个或更多的扩展,以减少子筛选器的数量。否则,我们建议您使用扩展1来减少内存消耗。默认值为2。
BF.INFO key
BF.SCANDUMP key iterator
开始对bloom过滤器进行增量保存。这对于不能适应正常的SAVE和RESTORE模型的大型bloom过滤器很有用。
第一次调用该命令时,iter的值应该为0。这个命令返回连续的(iter, data)对,直到(0,NULL)表示完成key: 过滤器的名称
-
BF.LOADCHUNK key iterator data
使用SCANDUMP恢复以前保存的筛选器。使用方法请参见scanump命令。
此命令覆盖存储在key下的任何bloom过滤器。确保在调用之间不会更改bloom过滤器 key: 要恢复的密钥的名称
- iter: 与数据相关的迭代器值(由SCANDUMP返回)
- data: 当前数据块(由SCANDUMP返回)
Redis 内存管理和缓存
https://redis.io/docs/manual/eviction/
Redis是key-value的内存数据库,可以作为缓存使用。缓存的特点是缓存不是全量数据,缓存是不重要可以丢失的,缓存应该是随着访问变化而变化的热数据。
给缓存数据设置过期时间,即设置key的有效期。key发生重复写时,会删除过期时间。给key设置有效期的的原因:
- 业务逻辑需要
- 内存有限,需要淘汰掉“冷数据”
当内存使用达到最大,Redis会根据配置的规则删除keys,如果配置的是” noeviction “,当使用如SET、LPUSH向redis添加key时,Redis会抛出需要更多内存的错误信息。
在Redis的配置文件中,关于内存管理的设置
maxmemory
配置最大可使用内存,将maxmemory设置为零将导致没有内存限制 MAXMEMORY POLICY 最大内存管理策略(5大策略):
- LRU Least Recently Used 最近最少使用(时间)
- volatile-lru 在具有过期集合的键中使用LRU算法删除1个
- allkeys-lru 所有key范围使用LRU算法删除1个
- LFU Least Frequently Used 最少使用(频率)
- volatile-lfu 在具有过期集合的键中使用LFU算法删除1个
- allkeys-lfu 所有key范围使用LFU算法删除1个
- RANDOM 随机
- volatile-random 在具有过期集合的键中移除一个随机键
- allkeys-random 所有keys中随机删除
- volatile-ttl 删除具有最近过期时间的key(剩余存活时间短TTL)
- noeviction 不要排除任何东西,只是在写操作时返回一个错误。(redis默认策略,作为数据库使用,作为缓存是不能使用)
- LRU Least Recently Used 最近最少使用(时间)
maxmemory-samples 5 检查样本大小,redis默认在5个key中进行选择1个 ```powershell
######################## MEMORY MANAGEMENT
Set a memory usage limit to the specified amount of bytes.
When the memory limit is reached Redis will try to remove keys
according to the eviction policy selected (see maxmemory-policy).
#
If Redis can’t remove keys according to the policy, or if the policy is
set to ‘noeviction’, Redis will start to reply with errors to commands
that would use more memory, like SET, LPUSH, and so on, and will continue
to reply to read-only commands like GET.
#
This option is usually useful when using Redis as an LRU or LFU cache, or to
set a hard memory limit for an instance (using the ‘noeviction’ policy).
#
WARNING: If you have replicas attached to an instance with maxmemory on,
the size of the output buffers needed to feed the replicas are subtracted
from the used memory count, so that network problems / resyncs will
not trigger a loop where keys are evicted, and in turn the output
buffer of replicas is full with DELs of keys evicted triggering the deletion
of more keys, and so forth until the database is completely emptied.
#
In short… if you have replicas attached it is suggested that you set a lower
limit for maxmemory so that there is some free RAM on the system for replica
output buffers (but this is not needed if the policy is ‘noeviction’).
#
maxmemory 配置最大可使用内存
MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
is reached. You can select among five behaviors:
#
volatile-lru -> Evict using approximated LRU among the keys with an expire set.
allkeys-lru -> Evict any key using approximated LRU.
volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
allkeys-lfu -> Evict any key using approximated LFU.
volatile-random -> Remove a random key among the ones with an expire set.
allkeys-random -> Remove a random key, any key.
volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
noeviction -> Don’t evict anything, just return an error on write operations.
#
LRU means Least Recently Used
LFU means Least Frequently Used
#
Both LRU, LFU and volatile-ttl are implemented using approximated
randomized algorithms.
#
Note: with any of the above policies, Redis will return an error on write
operations, when there are no suitable keys for eviction.
#
At the date of writing these commands are: set setnx setex append
incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
getset mset msetnx exec sort
#
The default is:
#
maxmemory-policy noeviction
LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated
algorithms (in order to save memory), so you can tune it for speed or
accuracy. For default Redis will check five keys and pick the one that was
used less recently, you can change the sample size using the following
configuration directive.
#
The default of 5 produces good enough results. 10 Approximates very closely
true LRU but costs more CPU. 3 is faster but not very accurate.
#
maxmemory-samples 5
Starting from Redis 5, by default a replica will ignore its maxmemory setting
(unless it is promoted to master after a failover or manually). It means
that the eviction of keys will be just handled by the master, sending the
DEL commands to the replica as keys evict in the master side.
#
This behavior ensures that masters and replicas stay consistent, and is usually
what you want, however if your replica is writable, or you want the replica to have
a different memory setting, and you are sure all the writes performed to the
replica are idempotent, then you may change this default (but be sure to understand
what you are doing).
#
Note that since the replica by default does not evict, it may end using more
memory than the one set via maxmemory (there are certain buffers that may
be larger on the replica, or data structures may sometimes take more memory and so
forth). So make sure you monitor your replicas and make sure they have enough
memory to never hit a real out-of-memory condition before the master hits
the configured maxmemory setting.
#
replica-ignore-maxmemory yes
``` Redis的key过期原理:主动式、被动式
- 主动式(周期轮询判定):每10s间接时主动遍历key的过期时间,随机测试20个key,删除其中所有过期的key,比例大于25%重复,没有就等下个周期。
- 被动式(被动访问式判定):过期的key再次被访问时进行删除

若有收获,就点个赞吧
0 人点赞
