NoSQL数据库简介
NoSQL:关系型数据库每次操作都是I/O操作,I/O操作是主要影响程序性能的原因之一。现在网站特点:高并发读写、高容量存储和高效存储、高扩展性和高可用性,由此关系型数据库频繁的I/O操作是性能有较大的影响的。
NoSQL数据库的优势:
易扩展
NoSQL数据库种类繁多,但都是去掉关系数据库的关系型特性,数据之间没有关系,这样就非常容易进行扩展,无形之间在架构层面带来了可扩展的能力。
大量数据高性能
NoSQL数据库具有非常高的读写能力,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据
库的结构简单。一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对
web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以
NoSQL在这个层面上来说就要性能高很多了。
灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段
是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。这点在大数据量的web2.0时代
尤其明显
高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制
模型也能实现高可用。
常见NoSQL类型
| 分类 | 相关产品 | 应用常场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值数据库 | Redis、memcached、Riak | 内容缓存:如会话、配置文件、参数等; 频繁读写、拥有简单数据模型的应用 |
扩展性好,灵活性好,大量操作时性能高 | 数据无结构,通常被当做字符串或者二进制数据,只能通过键来查询值 | |
| 列族数据库 | Bigtable、HBase、Cassandra | 分布式数据存储与管理 | 以列族式存储,将一列数据存储在一起 | 可扩展性强,查找速度快,复杂性低 | 功能局限,不支持事物的强一致性 |
| 文档数据库 | MongoDB、CouchDB | Web应用,存储面向文档类型或类似半结构化数据 | 数据结构灵活,可以根据value构建索引 | 缺乏统一查询语法 | |
| 图形数据库 | Neo4j、InfoGrid | 社交网络、推荐系统、专注构建关系图谱 | 图结构 | 支持复杂的图形算法 | 复杂性高,只能支持一定的数据规模 |
Redis简介
Redis(Remote Dictionary Server 远程字典服务器),是C编写开源,遵守BCD协议的高性能的键值(
Redis具有特点
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
Redis支持数据的备份,即master-slave(主从)模式的数据备份
Redis优势
性能极高:Redis能读的速度是110000次/s,写的速度是81000次/s。
- 丰富的数据类型:Redis支持二进制案例的Strings, Lists, Hashes, Sets及Ordered Sets数据类型操作。
- 原子性:Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性: Redis还支持publish/subscribe,通知, key过期等等特性
- 采用单线程:避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
-
Redis使用场景
缓存(数据查询,短连接,新闻内容,商品内容等),使用最多
- 聊天室在线好友列表
- 任务队列(秒杀,抢购,12306等)
- 应用排行榜
- 网站访问统计
- 数据过期处理(可以精确到毫秒)
- 分布式集群架构中的session问题
Redis数据类型
| 数据类型 | 数据类型存储的值 | 说明 |
|---|---|---|
| String(字符串) | string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。 | 可以对字符串进行操作,b比如增加字符串或者求子串;如果是整数或浮点数,可以实现计算,比如自增等 |
| List(列表) | 是一个链表,每一个节点都包含一个字符串 | 支出从两端插入或弹出节点,或者通过偏移量进行裁剪; 还可以读取一个或者多个节点,根据条件删除或者查找节点 |
| Set(无序集合) | 是一个收集器,但是是无序的,里面的每一个元素都是一个字符串,而且是独一无二不重复的 | 可以新增、读取、删除单个元素;可以检查一个元素是否在集合中;可以计算和其他集合的交集、并集和差集;随机从集合中读取元素 |
| ZSet(有序集合) | 是一个有序集合,可以包含字符串、整数、浮点数、分值(Score),元素的排序根据分值(Score)的大小来决定的 | 可以增、删、改、查元素,根据分值(Score)或者成员来获取对应的元素 |
| Hash(哈希散列表) | 类似java的Map,是一个键值对应的无序列表 | 可以增删改查单个键值对,也可获取所有的键值对 |
| HyperLogLog(基数) | 计算重复的值,以确定存储的数量 | 只提供基数的运算,不提供返回的功能 |
Redis命令
命令学习网站1:https://www.redis.net.cn/order/
命令学习网站2:http://doc.redisfans.com/
Redis 键(Key)
Redis Type 命令 返回key存储数据的数据类型
- none(表示key不存在)
- string(字符串)
- list(列表)
- set(集合)
- zset(有序表)
- hash(哈希表)
TYPE KEY_NAME
Redis PEXPIREAT 命令 用于设置 key 的过期时间,以毫秒记。key 过期后将不再可用。设置成功返回1,当 key 不存在或者不能为 key 设置过期时间时返回 0 。
PEXPIREAT KEY_NAME TIME_IN_MILLISECONDS_IN_UNIX_TIMESTAMPRedis Rename 命令 命令用于修改 key 的名称,改名成功时提示 OK ,失败时候返回一个错误。OLD_KEY_NAME 和 NEW_KEY_NAME 相同,或者 OLD_KEY_NAME 不存在时,返回一个错误。 当 NEW_KEY_NAME 已经存在时, RENAME 命令将覆盖旧值。
RENAME OLD_KEY_NAME NEW_KEY_NAMERedis PERSIST 命令 用于移除给定 key 的过期时间,使得 key 永不过期。当过期时间移除成功时,返回 1 。 如果 key 不存在或 key 没有设置过期时间,返回 0 。
PERSIST KEY_NAMERedis Move 命令 用于将当前数据库的 key 移动到给定的数据库 db 当中。移动成功返回 1 ,失败则返回 0 。
MOVE KEY_NAME DESTINATION_DATABASE //DESTINATION_DATABASE redis数据库编号Redis RANDOMKEY 命令 从当前数据库中随机返回一个 key 。当数据库不为空时,返回一个 key 。 当数据库为空时,返回 nil 。
RANDOMKEYRedis Dump 命令 用于序列化给定 key ,并返回被序列化的值。如果 key 不存在,那么返回 nil 。 否则,返回序列化之后的值。
DUMP KEY_NAMERedis TTL 命令 以秒为单位返回 key 的剩余过期时间。当 key 不存在时,返回 -2 。 当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以毫秒为单位,返回 key 的剩余生存时间。
TTL KEY_NAMERedis Expire 命令 用于设置 key 的过期时间。key 过期后将不再可用。设置成功返回 1 。 当 key 不存在或者不能为 key 设置过期时间时返回 0 。
Expire KEY_NAME TIME_IN_SECONDSRedis DEL 命令 命令用于删除已存在的键。不存在的 key 会被忽略。返回被删除 key 的数量。
DEL KEY_NAMERedis Pttl 命令 以毫秒为单位返回 key 的剩余过期时间。当 key 不存在时,返回 -2 。 当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以毫秒为单位,返回 key 的剩余生存时间。
注意:在 Redis 2.8 以前,当 key 不存在,或者 key 没有设置剩余生存时间时,命令都返回 -1 。
PTTL KEY_NAME
Redis Renamenx 命令 用于在新的 key 不存在时修改 key 的名称 。修改成功时,返回 1 。 如果 NEW_KEY_NAME 已经存在,返回 0 。
RENAMENX OLD_KEY_NAME NEW_KEY_NAMERedis EXISTS 命令 用于检查给定 key 是否存在。若 key 存在返回 1 ,否则返回 0 。
EXISTS KEY_NAMERedis Expireat 命令 用于以 UNIX 时间戳(unix timestamp)格式设置 key 的过期时间。key 过期后将不再可用。设置成功返回 1 。 当 key 不存在或者不能为 key 设置过期时间时返回 0 。
Expireat KEY_NAME TIME_IN_UNIX_TIMESTAMPRedis Keys 命令 用于查找所有符合给定模式 pattern 的 key 。符合给定模式的 key 列表 (Array)。获取 redis 中所有的 key 可用使用 *。
KEYS PATTERNString
Redis Setnx 命令 在指定的 key 不存在时,为 key 设置指定的值。设置成功,返回 1 。 设置失败,返回 0 。
SETNX KEY_NAME VALUERedis Getrange 命令 用于获取存储在指定 key 中字符串的子字符串。字符串的截取范围由 start 和 end 两个偏移量决定(包括 start 和 end 在内)。截取得到的子字符串。end为-1 表示末尾。
GETRANGE KEY_NAME start endRedis Mset 命令 用于同时设置一个或多个 key-value 对。总是返回 OK 。
MSET key1 value1 key2 value2 .. keyN valueNRedis Setex 命令 为指定的 key 设置值及其过期时间。如果 key 已经存在, SETEX 命令将会替换旧的值。设置成功时返回 OK 。
SETEX KEY_NAME TIMEOUT VALUERedis SET 命令 用于设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,且无视类型。在 Redis 2.6.12 以前版本, SET 命令总是返回 OK 。从 Redis 2.6.12 版本开始, SET 在设置操作成功完成时,才返回 OK 。
SET KEY_NAME VALUERedis Get 命令 用于获取指定 key 的值。如果 key 不存在,返回 nil 。如果key 储存的值不是字符串类型,返回一个错误。
GET KEY_NAMERedis Getbit 命令 用于对 key 所储存的字符串值,获取指定偏移量上的位(bit)。字符串值指定偏移量上的位(bit)。当偏移量 OFFSET 比字符串值的长度大,或者 key 不存在时,返回 0 。
GETBIT KEY_NAME OFFSETRedis Setbit 命令 用于对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。指定偏移量原来储存的位。
Setbit KEY_NAME OFFSETRedis Decr 命令 将 key 中储存的数字值减一。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 DECR 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。返回执行命令之后 key 的值。
DECR KEY_NAMERedis Decrby 命令 将 key 所储存的值减去指定的减量值。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 DECRBY 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。返回执行命令之后 key 的值。
DECRBY KEY_NAME DECREMENT_AMOUNTRedis Strlen 命令 用于获取指定 key 所储存的字符串值的长度。当 key 储存的不是字符串值时,返回一个错误。字符串值的长度。 当 key 不存在时,返回 0。
STRLEN KEY_NAMERedis Msetnx 命令 用于所有给定 key 都不存在时,同时设置一个或多个 key-value 对。当所有 key 都成功设置,返回 1 。 如果所有给定 key 都设置失败(至少有一个 key 已经存在),那么返回 0 。
MSETNX key1 value1 key2 value2 .. keyN valueNRedis Incr 命令 将 key 中储存的数字值增一。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。
INCR KEY_NAMERedis Incrby 命令 将 key 中储存的数字加上指定的增量值。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCRBY 命令。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。返回执行命令之后 key 的值。
INCRBY KEY_NAME INCR_AMOUNTRedis Incrbyfloat 命令 key 中所储存的值加上指定的浮点数增量值。如果 key 不存在,那么 INCRBYFLOAT 会先将 key 的值设为 0 ,再执行加法操作。返回执行命令之后 key 的值。
Redis Setrange 命令 用指定的字符串覆盖给定 key 所储存的字符串值,覆盖的位置从偏移量 offset 开始。返回被修改后的字符串长度。
SETRANGE KEY_NAME OFFSET VALUERedis Psetex 命令 以毫秒为单位设置 key 的生存时间。设置成功时返回 OK 。
PSETEX key1 EXPIRY_IN_MILLISECONDS value1Redis Append 命令 用于为指定的 key 追加值。如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
APPEND KEY_NAME NEW_VALUERedis Getset 命令 用于设置指定 key 的值,并返回 key 旧的值。返回给定 key 的旧值。 当 key 没有旧值时,即 key 不存在时,返回 nil 。当 key 存在但不是字符串类型时,返回一个错误。
GETSET KEY_NAME VALUERedis Mget 命令 返回所有(一个或多个)给定 key 的值。 如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。返回一个包含所有给定 key 的值的列表。
MGET KEY1 KEY2 .. KEYNHash
Redis Hset 命令 命令用于为哈希表中的字段赋值 。如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。如果字段已经存在于哈希表中,旧值将被覆盖。
HSET KEY_NAME FIELD VALUERedis Hmset 命令 用于同时将多个 field-value (字段-值)对设置到哈希表中。此命令会覆盖哈希表中已存在的字段。如果哈希表不存在,会创建一个空哈希表,并执行 HMSET 操作。如果命令执行成功,返回 OK 。
HMSET KEY_NAME FIELD1 VALUE1 ...FIELDN VALUENRedis Hget 命令 命令用于返回哈希表中指定字段的值。返回给定字段的值。如果给定的字段或 key 不存在时,返回 nil 。
HGET KEY_NAME FIELD_NAMERedis Hmget 命令 用于返回哈希表中,一个或多个给定字段的值。如果指定的字段不存在于哈希表,那么返回一个 nil 值。
HMGET KEY_NAME FIELD1...FIELDNRedis Hgetall 命令 用于返回哈希表中,所有的字段和值。在返回值里,紧跟每个字段名(field name)之后是字段的值(value),所以返回值的长度是哈希表大小的两倍。以列表形式返回哈希表的字段及字段值。 若 key 不存在,返回空列表。
HGETALL KEY_NAMERedis Hexists 命令 用于查看哈希表的指定字段是否存在。如果哈希表含有给定字段,返回 1 。 如果哈希表不含有给定字段,或 key 不存在,返回 0 。
HEXISTS KEY_NAME FIELD_NAMERedis Hincrby 命令 用于为哈希表中的字段值加上指定增量值。增量也可以为负数,相当于对指定字段进行减法操作。如果哈希表的 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。对一个储存字符串值的字段执行 HINCRBY 命令将造成一个错误。本操作的值被限制在 64 位(bit)有符号数字表示之内。返回执行 HINCRBY 命令之后,哈希表中字段的值。
HINCRBY KEY_NAME FIELD_NAME INCR_BY_NUMBERRedis Hlen 命令 用于获取哈希表中字段的数量。返回哈希表中字段的数量。 当 key 不存在时,返回 0
HLEN KEY_NAMERedis Hdel 命令 用于删除哈希表 key 中的一个或多个指定字段,不存在的字段将被忽略。返回被成功删除字段的数量,不包括被忽略的字段。
HDEL KEY_NAME FIELD1.. FIELDNRedis Hvals 命令 回哈希表所有字段的值。返回一个包含哈希表中所有值的表。 当 key 不存在时,返回一个空表。
HVALS KEY_NAME FIELD VALUERedis Hincrbyfloat 命令 用于为哈希表中的字段值加上指定浮点数增量值。如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。返回执行 Hincrbyfloat 命令之后,哈希表中字段的值。
HINCRBYFLOAT KEY_NAME FIELD_NAME INCR_BY_NUMBERRedis Hkeys 命令 用于获取哈希表中的所有字段名。返回包含哈希表中所有字段的列表。 当 key 不存在时,返回一个空列表。
HKEYS KEY_NAME FIELD_NAME INCR_BY_NUMBERRedis Hsetnx 命令 用于为哈希表中不存在的的字段赋值 。如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。如果字段已经存在于哈希表中,操作无效。如果 key 不存在,一个新哈希表被创建并执行 HSETNX 命令
HSETNX KEY_NAME FIELD VALUEList
Redis Lindex 命令 用于通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
LINDEX KEY_NAME INDEX_POSITIONRedis Rpush 命令 用于将一个或多个值插入到列表的尾部(最右边)。如果列表不存在,一个空列表会被创建并执行 RPUSH 操作。 当列表存在但不是列表类型时,返回一个错误。注意:在 Redis 2.4 版本以前的 RPUSH 命令,都只接受单个 value 值。
RPUSH KEY_NAME VALUE1..VALUENRedis Lrange 命令 列表中指定区间内的元素,区间以偏移量 START 和 END 指定。 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。返回一个列表,包含指定区间内的元素。
LRANGE KEY_NAME START ENDRedis Rpoplpush 命令 用于移除列表的最后一个元素,并将该元素添加到另一个列表并返回。返回被弹出的元素。
RPOPLPUSH SOURCE_KEY_NAME DESTINATION_KEY_NAMERedis Blpop 命令 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。如果列表为空,返回一个 nil 。 否则,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被弹出元素的值。
BLPOP LIST1 LIST2 .. LISTN TIMEOUTRedis Brpop 命令 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。如在指定时间内没有任何元素被弹出,则返回一个 nil 和等待时长。 反之,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被弹出元素的值。
BRPOP list1 100Redis Brpoplpush 命令 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。假如在指定时间内没有任何元素被弹出,则返回一个 nil 和等待时长。 反之,返回一个含有两个元素的列表,第一个元素是被弹出元素的值,第二个元素是等待时长。
BRPOPLPUSH LIST1 ANOTHER_LIST TIMEOUTRedis Lrem 命令 据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。COUNT 的值可以是以下几种:
- count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
- count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
- count = 0 : 移除表中所有与 VALUE 相等的值。
LREM KEY_NAME COUNT VALUE
Redis Llen 命令 用于返回列表的长度。 如果列表 key 不存在,则 key 被解释为一个空列表,返回 0 。 如果 key 不是列表类型,返回一个错误。
LLEN KEY_NAMERedis Ltrim 命令 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。下标 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。命令执行成功时,返回 ok 。
LTRIM KEY_NAME START STOPRedis Lpop 命令 用于移除并返回列表的第一个元素。列表的第一个元素。 当列表 key 不存在时,返回 nil 。
Redis Lpushx 命令 将一个或多个值插入到已存在的列表头部,列表不存在时操作无效。LPUSHX 命令执行之后,列表的长度。
LPUSHX KEY_NAME VALUE1.. VALUENRedis Linsert 命令 用于在列表的元素前或者后插入元素。 当指定元素不存在于列表中时,不执行任何操作。 当列表不存在时,被视为空列表,不执行任何操作。 如果 key 不是列表类型,返回一个错误。如果命令执行成功,返回插入操作完成之后,列表的长度。 如果没有找到指定元素 ,返回 -1 。 如果 key 不存在或为空列表,返回 0 。
LINSERT KEY_NAME BEFORE EXISTING_VALUE NEW_VALUERedis Rpop 命令 用于移除并返回列表的最后一个元素。列表的最后一个元素。 当列表不存在时,返回 nil 。
RPOP KEY_NAMERedis Lset 命令 通过索引来设置元素的值。当索引参数超出范围,或对一个空列表进行 LSET 时,返回一个错误。
关于列表下标的更多信息,请参考 LINDEX 命令。操作成功返回 ok ,否则返回错误信息。
LSET KEY_NAME INDEX VALUE
Redis Lpush 命令 将一个或多个值插入到列表头部。 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。 当 key 存在但不是列表类型时,返回一个错误。注意:在Redis 2.4版本以前的 LPUSH 命令,都只接受单个 value 值。
LPUSH KEY_NAME VALUE1.. VALUENRedis Rpushx 命令 用于将一个或多个值插入到已存在的列表尾部(最右边)。如果列表不存在,操作无效。执行 Rpushx 操作后,列表的长度。
RPUSHX KEY_NAME VALUE1..VALUENSet
Redis Sunion 命令 返回给定集合的并集。不存在的集合 key 被视为空集。并集成员的列表。
SUNION KEY KEY1..KEYNRedis Scard 命令 命令返回集合中元素的数量。返回集合的数量。 当集合 key 不存在时,返回 0 。
SCARD KEY_NAMERedis Srandmember 命令 用于返回集合中的一个随机元素。从 Redis 2.6 版本开始, Srandmember 命令接受可选的 count 参数:
- 如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合。
- 如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值。
该操作和 SPOP 相似,但 SPOP 将随机元素从集合中移除并返回,而 Srandmember 则仅仅返回随机元素,而不对集合进行任何改动。
SRANDMEMBER KEY [count]
Redis Smembers 命令 返回集合中的所有的成员。 不存在的集合 key 被视为空集合。返回集合中的所有成员。
SMEMBERS KEYRedis Sinter 命令 返回给定所有给定集合的交集。 不存在的集合 key 被视为空集。 当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。
SINTER KEY KEY1..KEYNRedis Srem 命令 用于移除集合中的一个或多个成员元素,不存在的成员元素会被忽略。当 key 不是集合类型,返回一个错误。在 Redis 2.4 版本以前, SREM 只接受单个成员值。返回被成功移除的元素的数量,不包括被忽略的元素。
REM KEY MEMBER1..MEMBERNRedis Smove 命令 将指定成员 member 元素从 source 集合移动到 destination 集合。SMOVE 是原子性操作。如果 source 集合不存在或不包含指定的 member 元素,则 SMOVE 命令不执行任何操作,仅返回 0 。否则, member 元素从 source 集合中被移除,并添加到 destination 集合中去。当 destination 集合已经包含 member 元素时, SMOVE 命令只是简单地将 source 集合中的 member 元素删除。当 source 或 destination 不是集合类型时,返回一个错误。如果成员元素被成功移除,返回 1 。 如果成员元素不是 source 集合的成员,并且没有任何操作对 destination 集合执行,那么返回 0 。
SMOVE SOURCE DESTINATION MEMBERRedis Sadd 命令 将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。假如集合 key 不存在,则创建一个只包含添加的元素作成员的集合。当集合 key 不是集合类型时,返回一个错误。注意:在Redis2.4版本以前, SADD 只接受单个成员值
SADD KEY_NAME VALUE1..VALUENRedis Sismember 命令 命令判断成员元素是否是集合的成员。如果成员元素是集合的成员,返回 1 。 如果成员元素不是集合的成员,或 key 不存在,返回 0 。
SISMEMBER KEY VALUERedis Sdiffstore 命令 将给定集合之间的差集存储在指定的集合中。如果指定的集合 key 已存在,则会被覆盖。结果集中的元素数量。返回结果集中的元素数量。
SDIFFSTORE DESTINATION_KEY KEY1..KEYNRedis Sdiff 命令 返回给定集合之间的差集。不存在的集合 key 将视为空集。返回包含差集成员的列表。
SDIFF FIRST_KEY OTHER_KEY1..OTHER_KEYNRedis Sscan 命令 用于迭代集合键中的元素。数组列表。
SSCAN KEY [MATCH pattern] [COUNT count]Redis Sinterstore 命令 将给定集合之间的交集存储在指定的集合中。如果指定的集合已经存在,则将其覆盖。
SINTERSTORE DESTINATION_KEY KEY KEY1..KEYNRedis Sunionstore 命令 将给定集合的并集存储在指定的集合 destination 中。
SUNIONSTORE DESTINATION KEY KEY1..KEYNRedis Spop 命令 用于移除并返回集合中的一个随机元素。被移除的随机元素。 当集合不存在或是空集时,返回 nil 。
SPOP KEYZSet
Redis Zrevrank 命令 返回有序集中成员的排名。其中有序集成员按分数值递减(从大到小)排序。排名以 0 为底,也就是说, 分数值最大的成员排名为 0 。使用 ZRANK 命令可以获得成员按分数值递增(从小到大)排列的排名。
ZREVRANK key memberRedis Zlexcount 命令 在计算有序集合中指定字典区间内成员数量。返回指定区间内的成员数量。
ZLEXCOUNT KEY MIN MAXRedis Zunionstore 命令 计算给定的一个或多个有序集的并集,其中给定 key 的数量必须以 numkeys 参数指定,并将该并集(结果集)储存到 destination 。默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和 。返回保存到 destination 的结果集的成员数量。
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]Redis Zremrangebyrank 命令 用于移除有序集中,指定排名(rank)区间内的所有成员。返回被移除成员的数量。
ZREMRANGEBYRANK key start stopRedis Zcard 命令 用于计算集合中元素的数量。当 key 存在且是有序集类型时,返回有序集的基数。 当 key 不存在时,返回 0 。
ZCARD KEY_NAMERedis Zrem 命令 用于移除有序集中的一个或多个成员,不存在的成员将被忽略。当 key 存在但不是有序集类型时,返回一个错误。注意: 在 Redis 2.4 版本以前, ZREM 每次只能删除一个元素。返回被成功移除的成员的数量,不包括被忽略的成员。
ZRANK key memberRedis Zinterstore 命令 计算给定的一个或多个有序集的交集,其中给定 key 的数量必须以 numkeys 参数指定,并将该交集(结果集)储存到 destination 。默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和。
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]Redis Zrank 命令 返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。
ZRANK key memberRedis Zincrby 命令 对有序集合中指定成员的分数加上增量 increment可以通过传递一个负数值 increment ,让分数减去相应的值,比如 ZINCRBY key -5 member ,就是让 member 的 score 值减去 5 。当 key 不存在,或分数不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。当 key 不是有序集类型时,返回一个错误。分数值可以是整数值或双精度浮点数。
ZINCRBY key increment memberRedis Zrangebyscore 命令 有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。具有相同分数值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]Redis Zrangebylex 命令 通过字典区间返回有序集合的成员。指定区间内的元素列表。
ZRANGEBYLEX key min max [LIMIT offset count]Redis Zscore 命令 返回有序集中,成员的分数值。 如果成员元素不是有序集 key 的成员,或 key 不存在,返回 nil 。返回成员的分数值,以字符串形式表示。
ZSCORE key memberRedis Zremrangebyscore 命令 用于移除有序集中,指定分数(score)区间内的所有成员。返回被移除成员的数量。
ZREMRANGEBYSCORE key min maxRedis Zscan 命令 用于迭代有序集合中的元素(包括元素成员和元素分值)。返回返回的每个元素都是一个有序集合元素,一个有序集合元素由一个成员(member)和一个分值(score)组成。
ZSCAN key cursor [MATCH pattern] [COUNT count]Redis Zrevrangebyscore 命令 返回有序集中指定分数区间内的所有的成员。有序集成员按分数值递减(从大到小)的次序排列。具有相同分数值的成员按字典序的逆序(reverse lexicographical order )排列。除了成员按分数值递减的次序排列这一点外, ZREVRANGEBYSCORE 命令的其他方面和 ZRANGEBYSCORE 命令一样。
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]Redis Zremrangebylex 命令 用于移除有序集合中给定的字典区间的所有成员。返回被成功移除的成员的数量,不包括被忽略的成员。
ZREMRANGEBYLEX key min maxRedis Zrevrange 命令 返回有序集中,指定区间内的成员。其中成员的位置按分数值递减(从大到小)来排列。具有相同分数值的成员按字典序的逆序(reverse lexicographical order)排列。除了成员按分数值递减的次序排列这一点外, ZREVRANGE 命令的其他方面和 ZRANGE 命令一样。
ZREVRANGE key start stop [WITHSCORES]Redis Zrange 命令 返回有序集中,指定区间内的成员。其中成员的位置按分数值递增(从小到大)来排序。具有相同分数值的成员按字典序(lexicographical order )来排列。如果你需要成员按值递减(从大到小)来排列,请使用 ZREVRANGE 命令。下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
ZRANGE key start stop [WITHSCORES]Redis Zcount 命令 用于计算有序集合中指定分数区间的成员数量。返回分数值在 min 和 max 之间的成员的数量。
ZCOUNT key min maxRedis Zadd 命令 用于将一个或多个成员元素及其分数值加入到有序集当中。如果某个成员已经是有序集的成员,那么更新这个成员的分数值,并通过重新插入这个成员元素,来保证该成员在正确的位置上。分数值可以是整数值或双精度浮点数。如果有序集合 key 不存在,则创建一个空的有序集并执行 ZADD 操作。当 key 存在但不是有序集类型时,返回一个错误。注意: 在 Redis 2.4 版本以前, ZADD 每次只能添加一个元素。
ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUENRedis连接
Redis Echo 命令 用于打印给定的字符串。
ECHO messageRedis Select 命令 用于切换到指定的数据库,数据库索引号 index 用数字值指定,以 0 作为起始索引值。
SELECT indexRedis Ping 命令 使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG 。通常用于测试与服务器的连接是否仍然生效,或者用于测量延迟值。
PINGRedis Quit 命令 用于关闭与当前客户端与redis服务的连接。一旦所有等待中的回复(如果有的话)顺利写入到客户端,连接就会被关闭。
QUITRedis Auth 命令 用于检测给定的密码和配置文件中的密码是否相符。
AUTH PASSWORDRedis服务器
Redis Client Pause 命令 用于阻塞客户端命令一段时间(以毫秒计)。
CLIENT PAUSE timeoutRedis Debug Object 命令 是一个调试命令,它不应被客户端所使用。
DEBUG OBJECT keyRedis Flushdb 命令 用于清空当前数据库中的所有 key。
FLUSHDBRedis Save 命令 执行一个同步保存操作,将当前 Redis 实例的所有数据快照(snapshot)以 RDB 文件的形式保存到硬盘。
SAVERedis Showlog 命令 是 Redis 用来记录查询执行时间的日志系统。查询执行时间指的是不包括像客户端响应(talking)、发送回复等 IO 操作,而单单是执行一个查询命令所耗费的时间。另外,slow log 保存在内存里面,读写速度非常快,因此你可以放心地使用它,不必担心因为开启 slow log 而损害 Redis 的速度。
SLOWLOG subcommand [argument]Redis Lastsave 命令 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示。返回字符串,文本行的集合。
LASTSAVERedis Config Get 命令 用于获取 redis 服务的配置参数。在 Redis 2.4 版本中, 有部分参数没有办法用 CONFIG GET 访问,但是在最新的 Redis 2.6 版本中,所有配置参数都已经可以用 CONFIG GET 访问了。
CONFIG GET parameterRedis Command 命令 用于返回所有的Redis命令的详细信息,以数组形式展示。
COMMANDRedis Slaveof 命令 可以将当前服务器转变为指定服务器的从属服务器(slave server)。如果当前服务器已经是某个主服务器(master server)的从属服务器,那么执行 SLAVEOF host port 将使当前服务器停止对旧主服务器的同步,丢弃旧数据集,转而开始对新主服务器进行同步。另外,对一个从属服务器执行命令 SLAVEOF NO ONE 将使得这个从属服务器关闭复制功能,并从从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃。利用『 SLAVEOF NO ONE 不会丢弃同步所得数据集』这个特性,可以在主服务器失败的时候,将从属服务器用作新的主服务器,从而实现无间断运行。
SLAVEOF host portRedis Debug Segfault 命令 执行一个非法的内存访问从而让 Redis 崩溃,仅在开发时用于 BUG 调试。
DEBUG SEGFAULTRedis Flushall 命令 用于清空整个 Redis 服务器的数据(删除所有数据库的所有 key )。
FLUSHALLRedis Dbsize 命令 用于返回当前数据库的 key 的数量。
DBSIZERedis Bgrewriteaof 命令 用于异步执行一个 AOF(AppendOnly File) 文件重写操作。重写会创建一个当前 AOF 文件的体积优化版本。即使 Bgrewriteaof 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 Bgrewriteaof 成功之前不会被修改。注意:从 Redis 2.4 开始, AOF 重写由 Redis 自行触发, BGREWRITEAOF 仅仅用于手动触发重写操作。
BGREWRITEAOFRedis Cluster Slots 命令 用于当前的集群状态,以数组形式展示。
CLUSTER SLOTSRedis Config Set 命令 可以动态地调整 Redis 服务器的配置(configuration)而无须重启。你可以使用它修改配置参数,或者改变 Redis 的持久化(Persistence)方式。当设置成功时返回 OK ,否则返回一个错误。
CONFIG Set parameter valueRedis Command Info 命令 命令用于获取 redis 命令的描述信息。
COMMAND INFO command-name [command-name ...]Redis Shutdown 命令 停止所有客户端。如果有至少一个保存点在等待,执行 SAVE 命令。如果 AOF 选项被打开,更新 AOF 文件。关闭 redis 服务器(server)
SHUTDOWN [NOSAVE] [SAVE]Redis Sync 命令 用于同步主从服务器。
SYNCRedis Client Kill 命令 用于关闭客户端连接。
CLIENT KILL ip:portRedis Role 命令 查看主从实例所属的角色,角色有master, slave, sentinel。
ROLERedis Monitor 命令 用于实时打印出 Redis 服务器接收到的命令,调试用。
MONITORRedis Command Getkeys 命令 用于获取所有 key。
COMMAND GETKEYSRedis Client Getname 命令 用于返回 CLIENT SETNAME 命令为连接设置的名字。 因为新创建的连接默认是没有名字的, 对于没有名字的连接, CLIENT GETNAME 返回空白回复。
CLIENT GETNAMERedis Config Resetstat 命令 用于重置 INFO 命令中的某些统计数据,包括:
- Keyspace hits (键空间命中次数)
- Keyspace misses (键空间不命中次数)
- Number of commands processed (执行命令的次数)
- Number of connections received (连接服务器的次数)
- Number of expired keys (过期key的数量)
- Number of rejected connections (被拒绝的连接数量)
- Latest fork(2) time(最后执行 fork(2) 的时间)
- The aof_delayed_fsync counter(aof_delayed_fsync 计数器的值)
CONFIG RESETSTAT
Redis Command Count 命令 用于统计 redis 命令的个数
COMMAND COUNTRedis Time 命令 用于返回当前服务器时间。
TIMERedis Info 命令 以一种易于理解和阅读的格式,返回关于 Redis 服务器的各种信息和统计数值。
通过给定可选的参数 section ,可以让命令只返回某一部分的信息:
- server : 一般 Redis 服务器信息,包含以下域:
- redis_version : Redis 服务器版本
- redis_git_sha1 : Git SHA1
- redis_git_dirty : Git dirty flag
- os : Redis 服务器的宿主操作系统
- arch_bits : 架构(32 或 64 位)
- multiplexing_api : Redis 所使用的事件处理机制
- gcc_version : 编译 Redis 时所使用的 GCC 版本
- process_id : 服务器进程的 PID
- run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群)
- tcp_port : TCP/IP 监听端口
- uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数
- uptime_in_days : 自 Redis 服务器启动以来,经过的天数
- lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理
- clients : 已连接客户端信息,包含以下域:
- connected_clients : 已连接客户端的数量(不包括通过从属服务器连接的客户端)
- client_longest_output_list : 当前连接的客户端当中,最长的输出列表
- client_longest_input_buf : 当前连接的客户端当中,最大输入缓存
- blocked_clients : 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
- memory : 内存信息,包含以下域:在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致。查看 used_memory_peak 的值可以验证这种情况是否发生。
- used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位
- used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量
- used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
- used_memory_peak : Redis 的内存消耗峰值(以字节为单位)
- used_memory_peak_human : 以人类可读的格式返回 Redis 的内存消耗峰值
- used_memory_lua : Lua 引擎所使用的内存大小(以字节为单位)
- mem_fragmentation_ratio : used_memory_rss 和 used_memory 之间的比率
- mem_allocator : 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
- persistence : RDB 和 AOF 的相关信息
- stats : 一般统计信息
- replication : 主/从复制信息
- cpu : CPU 计算量统计信息
- commandstats : Redis 命令统计信息
- cluster : Redis 集群信息
- keyspace : 数据库相关的统计信息
INFO [section]
Redis Config rewrite 命令 对启动 Redis 服务器时所指定的 redis.conf 配置文件进行改写。CONFIG SET 命令可以对服务器的当前配置进行修改, 而修改后的配置可能和 redis.conf 文件中所描述的配置不一样, CONFIG REWRITE 的作用就是通过尽可能少的修改, 将服务器当前所使用的配置记录到 redis.conf 文件中。返回一个状态值:如果配置重写成功则返回 OK ,失败则返回一个错误。
CONFIG REWRITE parameterRedis Client List 命令 用于返回所有连接到服务器的客户端信息和统计数据。
CLIENT LISTRedis Client Setname 命令 用于指定当前连接的名称。这个名字会显示在 CLIENT LIST 命令的结果中, 用于识别当前正在与服务器进行连接的客户端。
CLIENT SETNAME connection-nameRedis Bgsave 命令 用于在后台异步保存当前数据库的数据到磁盘。BGSAVE 命令执行之后立即返回 OK ,然后 Redis fork 出一个新子进程,原来的 Redis 进程(父进程)继续处理客户端请求,而子进程则负责将数据保存到磁盘,然后退出。
BGSAVERedis脚本
- Redis Script Load 命令
- Redis Eval 命令
- Redis Evalsha 命令
- Redis Script Exists 命令
-
Redis事务
Redis Exec 命令 命令用于执行所有事务块内的命令。
EXECRedis Watch 命令 用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
WATCHRedis Discard 命令 用于取消事务,放弃执行事务块内的所有命令。
DISCARDRedis Unwatch 命令 用于取消 WATCH 命令对所有 key 的监视。
UNWATCHRedis Multi 命令 用于标记一个事务块的开始。事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性(atomic)地执行。
MULTIRedis HyperLogLog
Redis Pgmerge 命令 将多个 HyperLogLog 合并为一个 HyperLogLog ,合并后的 HyperLogLog 的基数估算值是通过对所有 给定 HyperLogLog 进行并集计算得出的。
PFMERGE destkey sourcekey [sourcekey ...]Redis Pfadd 命令 将所有元素参数添加到 HyperLogLog 数据结构中。
PFADD key element [element ...]Redis Pfcount 命令 返回给定 HyperLogLog 的基数估算值。返回整数,返回给定 HyperLogLog 的基数值,如果多个 HyperLogLog 则返回基数估值之和。
PFCOUNT key [key ...]Redis发布订阅
Redis Unsubscribe 命令 用于退订给定的一个或多个频道的信息。
UNSUBSCRIBE channel [channel ...]Redis Subscribe 命令 用于订阅给定的一个或多个频道的信息。返回接收到的信息
SUBSCRIBE channel [channel ...]Redis Pubsub 命令 用于查看订阅与发布系统状态,它由数个不同格式的子命令组成。返回由活跃频道组成的列表
PUBSUB <subcommand> [argument [argument ...]]Redis Punsubscribe 命令 用于退订所有给定模式的频道。
PUNSUBSCRIBE [pattern [pattern ...]]Redis Publish 命令 用于将信息发送到指定的频道。返回接收到信息的订阅者数量。
PUBLISH channel messageRedis Psubscribe 命令 订阅一个或多个符合给定模式的频道。每个模式以 作为匹配符,比如 it 匹配所有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等)。 news.* 匹配所有以 news. 开头的频道( news.it 、 news.global.today 等等),诸如此类。返回接收到的信息。
PSUBSCRIBE pattern [pattern ...]Redis地理位置(geo)
- Redis GEOPOS 命令
- Redis GEODIST 命令
- Redis GEORADIUS 命令
- Redis GEOADD 命令
- Redis GEORADIUSBYMEMBER 命令
Redis事物管理
Redis事务可以一次执行多个命令,并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
一个事务从开始到执行会经历以下三个阶段:开始事务、令入队、执行事务。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set bookname java
QUEUED
127.0.0.1:6379> set bookname c++
QUEUED
127.0.0.1:6379> set bookname html
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) OK
Redis发布订阅模式
Redis发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis客户端可以订阅任意数量的频道。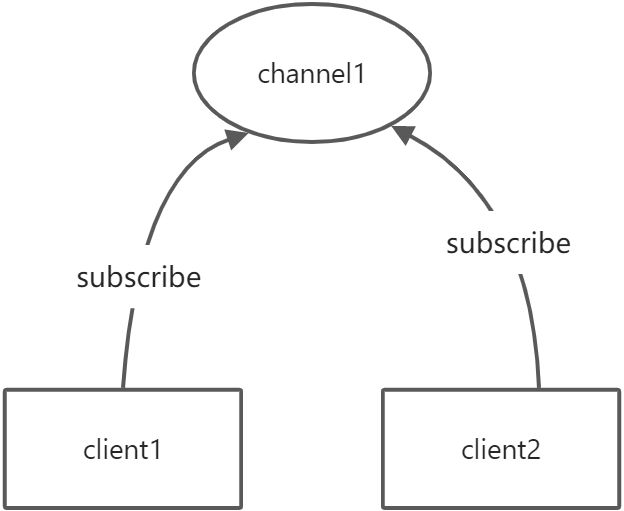
当有新消息通过publish命令发送给频道channel1时,这个消息或被发送给订阅这个频道的客户端: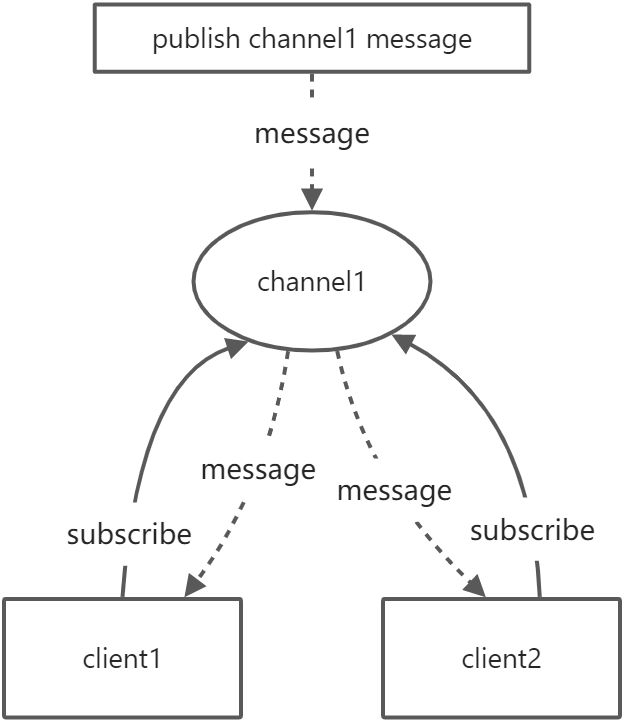
Redis持久模式
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。Redis数据持久化模式有RDB和AOF两种。
RDB持久化
rdb模式是默认模式,可以在指定的时间间隔内生成数据快照(snapshot),默认保存到dump.rdb文件中。当redis重启后会自动加载dump.rdb文件中内容到内存中。用户可以使用SAVE(同步)或BGSAVE(异步)手动保存数据。可以设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令,可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1 # 服务器在900秒之内,对数据库进行了至少1次修改
save 300 10 # 服务器在300秒之内,对数据库进行了至少10次修改
save 60 10000 # 服务器在60秒之内,对数据库进行了至少10000次修改
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
# 当snapshot时出现错误无法继续时,是否阻塞客户端“变更操作”,
# “错误”可能因为磁盘已满/磁盘故障/OS级别异常等
stop-writes-on-bgsave-error yes
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
#是否启用rdb文件压缩,默认为“yes”,压缩往往意味着“额外的cpu消耗”,
#同时也意味这较小的文件尺寸以及较短的网络传输时间
rdbcompression yes
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# The filename where to dump the DB
dbfilename dump.rdb # 持久化数据存储在本地的文件
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
# 持久化数据存储在本地的路径,如果是在/redis/redis-5.0.5/src下启动的redis-cli,
# 则数据会存储在当前src目录下
dir ./
RDB持久化优点:
- 使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能
- rdb文件是一个紧凑文件,直接使用rdb文件就可以还原数据
- 恢复数据的效率要高于aof
RDB持久化缺点:
- RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合
数据要求不严谨的时候 由于每次保存数据都需要fork()子进程,在数据量比较大时可能会比较耗费性能。
AOF持久化
Append Only File,将“操作+数据”以格式化指令的方式追加到操作日志文件的尾部,在append操作返回后(已经写入到文件或者将要写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当server需要数据恢复时,可以直接replay此日志文件,即可还原所有的操作过程。AOF相对可靠,AOF文件内容是字符串,非常容易阅读和解析。
AOF持久化优点:可以保持更高的数据完整性,如果设置追加file的时间是1s,如果redis发生故障,最多会丢失1s的数据;且如果日志写入不完整支持redis-check-aof来进行日志修复;AOF文件没被rewrite之前(文件过大时会对
命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。
AOF持久化缺点:
- AOF文件比RDB文件大,且恢复速度慢。
- 相同数据集AOF要大于RDB。
我们可以简单的认为AOF就是日志文件,此文件只会记录“变更操作”(例如:set/del等),如果server中持续的大
量变更操作,将会导致AOF文件非常的庞大,意味着server失效后,数据恢复的过程将会很长;事实上,一条数
据经过多次变更,将会产生多条AOF记录,其实只要保存当前的状态,历史的操作记录是可以抛弃的;因为AOF
持久化模式还伴生了“AOF rewrite”。
AOF的特性决定了它相对比较安全,如果你期望数据更少的丢失,那么可以采用AOF模式。如果AOF文件正在被
写入时突然server失效,有可能导致文件的最后一次记录是不完整,你可以通过手工或者程序的方式去检测并修
正不完整的记录,以便通过aof文件恢复能够正常;同时需要提醒,如果你的redis持久化手段中有aof,那么在
server故障失效后再次启动前,需要检测aof文件的完整性。
Redis支持AOF和RDB同时生效,如果同时存在,AOF优先级高于RDB(Redis重新启动时会使用AOF进行数据恢复)
AOF默认关闭,开启方法,修改配置文件reds.conf:appendonly yes
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
# AOF 默认关闭,要开启需修改为yes
appendonly no
# The name of the append only file (default: "appendonly.aof")
# AOF 文件名
appendfilename "appendonly.aof"
# The fsync() call tells the Operating System to actually write data on disk
# instead of waiting for more data in the output buffer. Some OS will really flush
# data on disk, some other OS will just try to do it ASAP.
#
# Redis supports three different modes:
#
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
#
# The default is "everysec", as that's usually the right compromise between
# speed and data safety. It's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# More details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# If unsure, use "everysec".
# appendfsync always
# 指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
# always:每一条 aof 记录都立即同步到文件,这是最安全的方式,
#也以为更多的磁盘操作和阻塞延迟,是 IO 开支较大。
# everysec:每秒同步一次,性能和安全都比较中庸的方式,也是 redis 推荐的方式。
#如果遇到物理服务器故障,有可能导致最近一秒内 aof 记录丢失(可能为部分丢失)。
# no:redis 并不直接调用文件同步,而是交给操作系统来处理,
# 操作系统可以根据 buffer 填充情况 / 通道空闲时间 等择机触发同步;
#这是一种普通的文件操作方式。性能较好,在物理服务器故障时,数据丢失量会因 OS 配置有关。
appendfsync everysec
# appendfsync no
# When the AOF fsync policy is set to always or everysec, and a background
# saving process (a background save or AOF log background rewriting) is
# performing a lot of I/O against the disk, in some Linux configurations
# Redis may block too long on the fsync() call. Note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write(2) call.
#
# In order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# BGSAVE or BGREWRITEAOF is in progress.
#
# This means that while another child is saving, the durability of Redis is
# the same as "appendfsync none". In practical terms, this means that it is
# possible to lose up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
# 在aof-rewrite期间,appendfsync是否暂缓文件同步,
# "no"表示“不暂缓”,“yes”表示“暂缓”,默认为“no”
no-appendfsync-on-rewrite no
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
# aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,
# 默认“64mb”,建议“512mb”
auto-aof-rewrite-min-size 64mb
# 相对于“上一次”rewrite,本次rewrite触发时aof文件应该增长的百分比。
# 每一次rewrite之后,redis都会记录下此时“新aof”文件的大小(例如A),
# 那么当aof文件增长到A*(1 + p)之后触发下一次rewrite,
# 每一次aof记录的添加,都会检测当前aof文件的尺寸。
auto-aof-rewrite-percentage 100
# An AOF file may be found to be truncated at the end during the Redis
# startup process, when the AOF data gets loaded back into memory.
# This may happen when the system where Redis is running
# crashes, especially when an ext4 filesystem is mounted without the
# data=ordered option (however this can't happen when Redis itself
# crashes or aborts but the operating system still works correctly).
#
# Redis can either exit with an error when this happens, or load as much
# data as possible (the default now) and start if the AOF file is found
# to be truncated at the end. The following option controls this behavior.
#
# If aof-load-truncated is set to yes, a truncated AOF file is loaded and
# the Redis server starts emitting a log to inform the user of the event.
# Otherwise if the option is set to no, the server aborts with an error
# and refuses to start. When the option is set to no, the user requires
# to fix the AOF file using the "redis-check-aof" utility before to restart
# the server.
#
# Note that if the AOF file will be found to be corrupted in the middle
# the server will still exit with an error. This option only applies when
# Redis will try to read more data from the AOF file but not enough bytes
# will be found.
aof-load-truncated yes
# When rewriting the AOF file, Redis is able to use an RDB preamble in the
# AOF file for faster rewrites and recoveries. When this option is turned
# on the rewritten AOF file is composed of two different stanzas:
#
# [RDB file][AOF tail]
#
# When loading Redis recognizes that the AOF file starts with the "REDIS"
# string and loads the prefixed RDB file, and continues loading the AOF
# tail.
aof-use-rdb-preamble yes
Redis主从复制
Redis支持集群功能。为了保证单一节点可用性,redis支持主从复制功能。每个节点有N个复制品(replica),其中一个复制品是主(master),另外N-1个复制品是从(Slave),也就是说Redis支持一主多从。一个主可有多个从,而一个从又可以看成主,它还可以有多个从。
主-从模式优点:
- 加单一节点的健壮性,从而提升整个集群的稳定性。(Redis中当超过1/2节点不可用时,整个集群不可用)
- 从节点可以对主节点数据备份,提升容灾能力。
读写分离。在redis主从中,主节点一般用作写(具备读的能力),从节点只能读,利用这个特性实现读写分离,写用主,读用从。
搭建一主二从
关闭运行的Redis单机版
./redis-cli shutdown创建replica目录,复制三份redis单机版中的bin目录到replica目录中,分别叫做master、slave1、slave2
mkdir /myprogram/replica copy -r /myprogram/redis/bin /myprogram/replica/master copy -r /myprogram/redis/bin /myprogram/replica/slave1 copy -r /myprogram/redis/bin /myprogram/replica/slave2修改从机配置文件,修改自身端口,指定 replicaof 192.168.126.128 6379
- 编写启动批处理文件,启动主从机 ```perl vim /myprogram/replica/starup.sh
进入vim 编辑模式 输入内容
cd /myprogram/replica/master/ ./redis-server redis.conf
cd /myprogram/replica/slave1 ./redis-server redis.conf cd /myprogram/replica/slave2 ./redis-server redis.conf
编辑完成后保存退出vim编辑模式
赋予权限
chmod a+x startup.sh
运行批处理启动文件,启动主从机
./startup.sh
查看redis主从机启动状态
ps aux | grep redis
主机和2台从机都启动起来<br />
5. 进入主机客户端查看信息、进入从机客户端查看信息
主机客户端查看 角色为master,有2个从机,端口分别是6380、6381<br />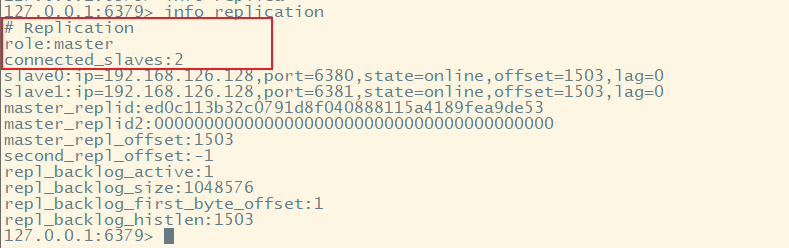<br />进入从机客户端,需要指明端口号;查看角色为slave,从机只能读数据。<br />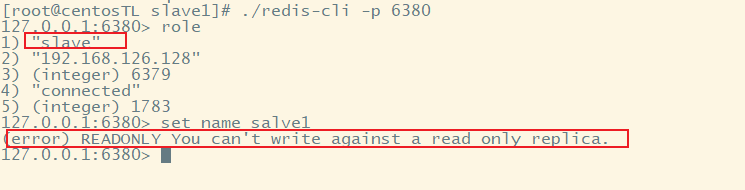
<a name="fDtby"></a>
### 主从复制过程
1. 当从库和主库建立MS(master slaver)关系后,会向主数据库发送SYNC命令;
1. 主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来;
1. 快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis;
1. 从Redis接收到后,会载入快照文件并且执行收到的缓存命令;
1. 主Redis每当接收到写命令时就会将命令发送从Redis,保证数据的一致;(Redis内部完成,所以不支持客户端在从机人为写数据。)
---
<a name="AeJo3"></a>
## Redis哨兵模式
在redis主从默认是只有主节点具备写的能力,而从节点只能读。如果主宕机,整个节点不具备写能力。但是如果这是让一个从变成主,整个节点就可以继续工作。即使之前的主恢复过来也当做这个节点的从节点即可。<br />Redis的哨兵就是帮助监控整个节点的,当主机节点宕机等情况下,帮助重新选取主机。<br />**Redis中哨兵支持单哨兵和多哨兵**
> - 单哨兵是只要这个哨兵发现master宕机了,就直接选取另一个master。
> - 而多哨兵是根据我们设定,达到一定数量哨兵认为master宕机后才会进行重新选取主。我们以多哨兵演示。
哨兵模式架构图<br />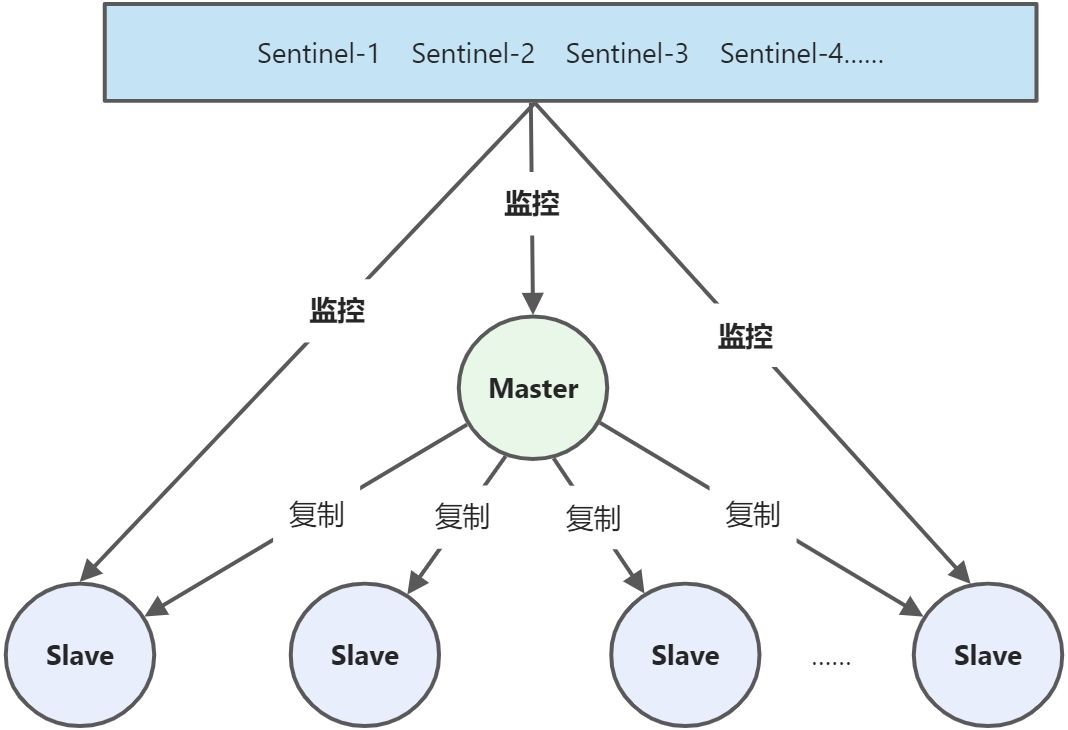
<a name="EUn8z"></a>
### 搭建多哨兵模式
1. 关闭运行中的redis主机和从机
```perl
ps aux|grep redis
kill 9 线程号
复制Redis
cp -r /myprogram/redis/bin/* /myprogram/sentinel
从redis解压目录中复制sentinel配置文件
cp /myprogram/redis-5.0.5/sentinel.conf /myprogram/sentinel
3. 复制多份配置文件,并修改其中内容
```perl
#复制多份sentinel.conf配置文件
cp /myprogram/sentinel/sentinel.conf /myprogram/sentinel/sentinel-26380.conf
cp /myprogram/sentinel/sentinel.conf /myprogram/sentinel/sentinel-26381.conf
#修改配置文件
cd /myprogram/sentinel
vim sentinel.conf
#修改内容为
port 26379
daemonize yes
logfile "/myprogram/sentinel/log/26379.log"
sentinel monitor mymaster 192.168.126.128 6379 2
vim sentinel-26380.conf
#修改内容为
port 26380
daemonize yes
logfile "/myprogram/sentinel/log/26380.log"
sentinel monitor mymaster 192.168.126.128 6379 2
vim sentinel-26381.conf
#修改内容为
port 26381
daemonize yes
logfile "/myprogram/sentinel/log/26381.log"
sentinel monitor mymaster 192.168.126.128 6379 2
# Example sentinel.conf
# *** IMPORTANT ***
#
# By default Sentinel will not be reachable from interfaces different than
# localhost, either use the 'bind' directive to bind to a list of network
# interfaces, or disable protected mode with "protected-mode no" by
# adding it to this configuration file.
#
# Before doing that MAKE SURE the instance is protected from the outside
# world via firewalling or other means.
#
# For example you may use one of the following:
#
# bind 127.0.0.1 192.168.1.1
#
# protected-mode no
# port <sentinel-port>
# The port that this sentinel instance will run on
port 26379
# By default Redis Sentinel does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis-sentinel.pid when
# daemonized.
daemonize yes
# When running daemonized, Redis Sentinel writes a pid file in
# /var/run/redis-sentinel.pid by default. You can specify a custom pid file
# location here.
pidfile "/var/run/redis-sentinel.pid"
# Specify the log file name. Also the empty string can be used to force
# Sentinel to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile "/myprogram/sentinel/log/26379.log"
# sentinel announce-ip <ip>
# sentinel announce-port <port>
#
# The above two configuration directives are useful in environments where,
# because of NAT, Sentinel is reachable from outside via a non-local address.
#
# When announce-ip is provided, the Sentinel will claim the specified IP address
# in HELLO messages used to gossip its presence, instead of auto-detecting the
# local address as it usually does.
#
# Similarly when announce-port is provided and is valid and non-zero, Sentinel
# will announce the specified TCP port.
#
# The two options don't need to be used together, if only announce-ip is
# provided, the Sentinel will announce the specified IP and the server port
# as specified by the "port" option. If only announce-port is provided, the
# Sentinel will announce the auto-detected local IP and the specified port.
#
# Example:
#
# sentinel announce-ip 1.2.3.4
# dir <working-directory>
# Every long running process should have a well-defined working directory.
# For Redis Sentinel to chdir to /tmp at startup is the simplest thing
# for the process to don't interfere with administrative tasks such as
# unmounting filesystems.
dir "/tmp"
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
#
# Tells Sentinel to monitor this master, and to consider it in O_DOWN
# (Objectively Down) state only if at least <quorum> sentinels agree.
#
# Note that whatever is the ODOWN quorum, a Sentinel will require to
# be elected by the majority of the known Sentinels in order to
# start a failover, so no failover can be performed in minority.
#
# Replicas are auto-discovered, so you don't need to specify replicas in
# any way. Sentinel itself will rewrite this configuration file adding
# the replicas using additional configuration options.
# Also note that the configuration file is rewritten when a
# replica is promoted to master.
#
# Note: master name should not include special characters or spaces.
# The valid charset is A-z 0-9 and the three characters ".-_".
sentinel myid d57ea4276101cab4000b9667c0114407485c561a
# sentinel auth-pass <master-name> <password>
#
# Set the password to use to authenticate with the master and replicas.
# Useful if there is a password set in the Redis instances to monitor.
#
# Note that the master password is also used for replicas, so it is not
# possible to set a different password in masters and replicas instances
# if you want to be able to monitor these instances with Sentinel.
#
# However you can have Redis instances without the authentication enabled
# mixed with Redis instances requiring the authentication (as long as the
# password set is the same for all the instances requiring the password) as
# the AUTH command will have no effect in Redis instances with authentication
# switched off.
#
# Example:
#
# sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# sentinel down-after-milliseconds <master-name> <milliseconds>
#
# Number of milliseconds the master (or any attached replica or sentinel) should
# be unreachable (as in, not acceptable reply to PING, continuously, for the
# specified period) in order to consider it in S_DOWN state (Subjectively
# Down).
#
# Default is 30 seconds.
sentinel deny-scripts-reconfig yes
# sentinel parallel-syncs <master-name> <numreplicas>
#
# How many replicas we can reconfigure to point to the new replica simultaneously
# during the failover. Use a low number if you use the replicas to serve query
# to avoid that all the replicas will be unreachable at about the same
# time while performing the synchronization with the master.
sentinel monitor mymaster 192.168.126.128 6381 2
# sentinel failover-timeout <master-name> <milliseconds>
#
# Specifies the failover timeout in milliseconds. It is used in many ways:
#
# - The time needed to re-start a failover after a previous failover was
# already tried against the same master by a given Sentinel, is two
# times the failover timeout.
#
# - The time needed for a replica replicating to a wrong master according
# to a Sentinel current configuration, to be forced to replicate
# with the right master, is exactly the failover timeout (counting since
# the moment a Sentinel detected the misconfiguration).
#
# - The time needed to cancel a failover that is already in progress but
# did not produced any configuration change (SLAVEOF NO ONE yet not
# acknowledged by the promoted replica).
#
# - The maximum time a failover in progress waits for all the replicas to be
# reconfigured as replicas of the new master. However even after this time
# the replicas will be reconfigured by the Sentinels anyway, but not with
# the exact parallel-syncs progression as specified.
#
# Default is 3 minutes.
sentinel config-epoch mymaster 1
# SCRIPTS EXECUTION
#
# sentinel notification-script and sentinel reconfig-script are used in order
# to configure scripts that are called to notify the system administrator
# or to reconfigure clients after a failover. The scripts are executed
# with the following rules for error handling:
#
# If script exits with "1" the execution is retried later (up to a maximum
# number of times currently set to 10).
#
# If script exits with "2" (or an higher value) the script execution is
# not retried.
#
# If script terminates because it receives a signal the behavior is the same
# as exit code 1.
#
# A script has a maximum running time of 60 seconds. After this limit is
# reached the script is terminated with a SIGKILL and the execution retried.
# NOTIFICATION SCRIPT
#
# sentinel notification-script <master-name> <script-path>
#
# Call the specified notification script for any sentinel event that is
# generated in the WARNING level (for instance -sdown, -odown, and so forth).
# This script should notify the system administrator via email, SMS, or any
# other messaging system, that there is something wrong with the monitored
# Redis systems.
#
# The script is called with just two arguments: the first is the event type
# and the second the event description.
#
# The script must exist and be executable in order for sentinel to start if
# this option is provided.
#
# Example:
#
# sentinel notification-script mymaster /var/redis/notify.sh
# CLIENTS RECONFIGURATION SCRIPT
#
# sentinel client-reconfig-script <master-name> <script-path>
#
# When the master changed because of a failover a script can be called in
# order to perform application-specific tasks to notify the clients that the
# configuration has changed and the master is at a different address.
#
# The following arguments are passed to the script:
#
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
#
# <state> is currently always "failover"
# <role> is either "leader" or "observer"
#
# The arguments from-ip, from-port, to-ip, to-port are used to communicate
# the old address of the master and the new address of the elected replica
# (now a master).
#
# This script should be resistant to multiple invocations.
#
# Example:
#
# sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
# SECURITY
#
# By default SENTINEL SET will not be able to change the notification-script
# and client-reconfig-script at runtime. This avoids a trivial security issue
# where clients can set the script to anything and trigger a failover in order
# to get the program executed.
sentinel leader-epoch mymaster 1
# REDIS COMMANDS RENAMING
#
# Sometimes the Redis server has certain commands, that are needed for Sentinel
# to work correctly, renamed to unguessable strings. This is often the case
# of CONFIG and SLAVEOF in the context of providers that provide Redis as
# a service, and don't want the customers to reconfigure the instances outside
# of the administration console.
#
# In such case it is possible to tell Sentinel to use different command names
# instead of the normal ones. For example if the master "mymaster", and the
# associated replicas, have "CONFIG" all renamed to "GUESSME", I could use:
#
# SENTINEL rename-command mymaster CONFIG GUESSME
#
# After such configuration is set, every time Sentinel would use CONFIG it will
# use GUESSME instead. Note that there is no actual need to respect the command
# case, so writing "config guessme" is the same in the example above.
#
# SENTINEL SET can also be used in order to perform this configuration at runtime.
#
# In order to set a command back to its original name (undo the renaming), it
# is possible to just rename a command to itsef:
#
# SENTINEL rename-command mymaster CONFIG CONFIG
# Generated by CONFIG REWRITE
protected-mode no
sentinel known-replica mymaster 192.168.126.128 6380
sentinel known-replica mymaster 192.168.126.128 6379
sentinel known-sentinel mymaster 192.168.126.128 26381 e92689fea49b62d2d73d3a4104453de61ed85970
sentinel known-sentinel mymaster 192.168.126.128 26380 ec5f593b59af8a6cb05ae0adf000c12c93fe255e
sentinel current-epoch 1
当主机由于意外(断电、硬件故障等原因)宕机,多哨兵监听到宕机状态,会自动修改配置文集指向新主机,再次启动原有主机,原有主机变成从机。
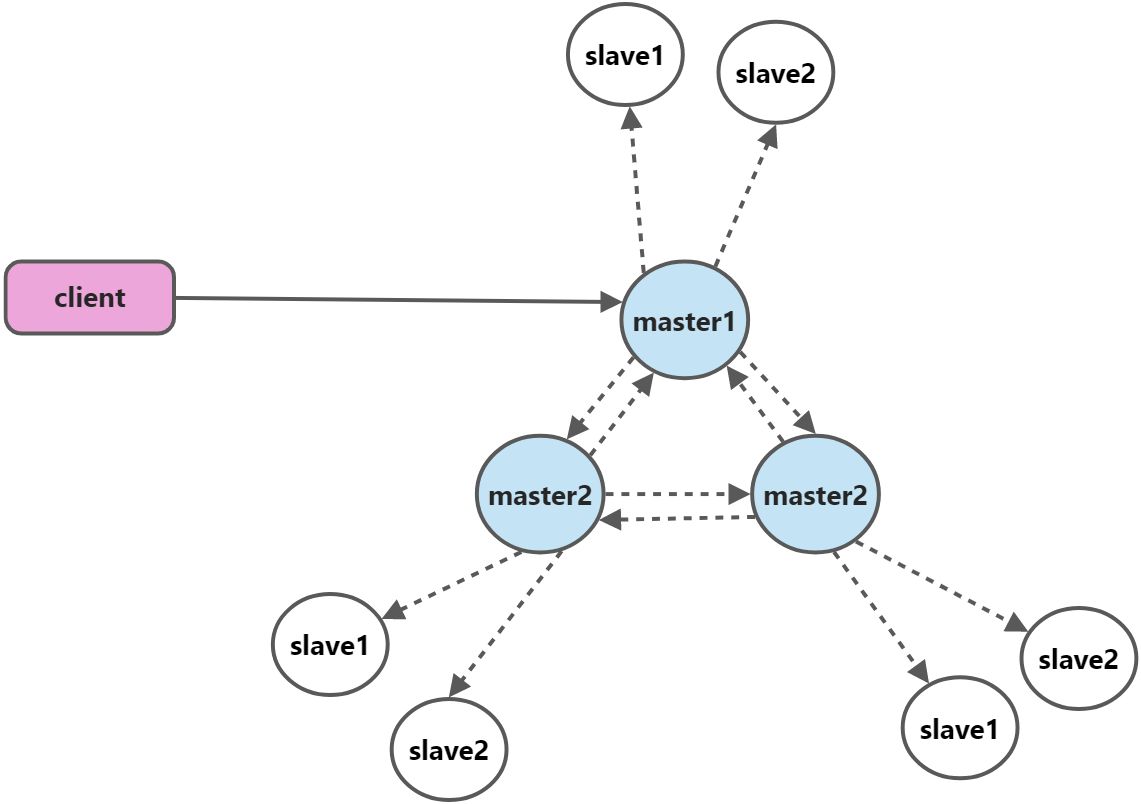
Redis集群(Redis Cluster)
Redis cluster架构图
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的fail是通过集群中超过半数的节点检测有效时整个集群才生效。当集群中超过或等于1/2节点不可用时,整个集群不可用。为了搭建稳定集群,都采用奇数节点。
- 客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,只需连接集群中任何一个可用节点即可
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster负责维护node<->slot<->value
Redis集群中内置了16384个哈希槽,当需要在Redis集群中放置一个key-value时,redis先对key使用crc16算法算出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点

Redis cluster容错机制

- 集群中所有master参与投票,如果半数以上master节点与其中一个master节点通信超过超时时间(cluster-node-timeout),则认为该master节点宕掉了
- 什么时候整个集群不可用(cluster_state:fail)?
- 如果集群任意master挂掉,且当前master没有slave,则mater进入fail状态。也可以理解成集群的[0-16383]slot映射不完全时进入fail状态。
- 如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。
搭建集群
- 创建redis-cluster目录,复制redis单机版中的bin目录到redis-cluster目录中,进入redis-cluster/bin中,将redis.conf 复制9份,分别叫做redis-7001.conf、redis-7002.conf、redis-7003.conf、redis-7004.conf、redis-7005.conf、redis-7006.conf、redis-7007.conf、redis-7008.conf、redis-7009.conf
```perl
cd /myprogram
创建redis-cluster目录
mkdir redis-cluster
复制redis bin目录到redis-cluster目录
cp redis/bin redis-cluster/
cd redis-cluster/bin
复制9份redis.conf
cp redis.conf redis-7001.conf cp redis.conf redis-7002.conf cp redis.conf redis-7003.conf cp redis.conf redis-7004.conf cp redis.conf redis-7005.conf cp redis.conf redis-7006.conf cp redis.conf redis-7007.conf cp redis.conf redis-7008.conf cp redis.conf redis-7009.conf
2. 依次修改9份redis-700x.conf配置文件
```perl
vim redis-7001.conf
#修改内容
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
# appendonly yes 如果开启aof默认,需要修改为yes。如果使用rdb,此处不需要修改
daemonize yes
protected-mode no
pidfile /var/run/redis_7001.pid
- 启动9个redis,使用批处理文件
```perl
进入vim编辑模式
vim startup.sh输入内容
./redis-server redis-7001.conf ./redis-server redis-7002.conf ./redis-server redis-7003.conf ./redis-server redis-7004.conf ./redis-server redis-7005.conf ./redis-server redis-7006.conf ./redis-server redis-7007.conf ./redis-server redis-7008.conf ./redis-server redis-7009.conf
保存退出 赋予启动文件权限
chmod a+x startup.sh
启动9个redis
./startup.sh
4. 建立集群(在redis3的时候需要借助ruby脚本实现集群。在redis5中可以使用自带的redis-cli实现集群功能,比redis3的时候更加方便了。)
```perl
# 建立集群,其中每个节点从节点为2
./redis-cli --cluster 192.168.126.128:7001 192.168.126.128:7002 192.168.126.128:7003 192.168.126.128:7004 192.168.126.128:7005 192.168.126.128:7006 192.168.126.128:7007 192.168.126.128:7008 192.168.126.128:7009 --cluster-replicas 2
集群搭建成功,进行测试
# 进入集群客户端 cd /myprogram/redis-cluster/bin ./redis-cli -p 7001 -c Jedis使用
Jedis使用Jedis连接单机版Redis
@Test public void test01() { // 获取Redis客户端连接 Jedis jedis = new Jedis("192.168.126.128", 6379); // 获取连接后进行操作 jedis.set("name", "章"); System.out.println(jedis.get("name")); jedis.close(); }Jedis 连接池
@Test public void test02() { // 1.获取连接池配置对象,设置配置项 JedisPoolConfig jedisConfig = new JedisPoolConfig(); // 1.1最大的连接数 jedisConfig.setMaxTotal(10); // 1.2最大的空闲 jedisConfig.setMaxIdle(5); // 2.获取连接池 JedisPool jedisPool = new JedisPool(jedisConfig, "192.168.126.128", 6379); // 2.1.获取连接 Jedis jedis = jedisPool.getResource(); jedis.set("age", "18"); System.out.println(jedis.get("age")); jedis.close(); }Jedis连接集群
```java @Test public void testCluster() { Set
set = new HashSet<>(9); set.add(new HostAndPort(“192.168.126.128”,7001)); set.add(new HostAndPort(“192.168.126.128”,7002)); set.add(new HostAndPort(“192.168.126.128”,7003)); set.add(new HostAndPort(“192.168.126.128”,7004)); set.add(new HostAndPort(“192.168.126.128”,7005)); set.add(new HostAndPort(“192.168.126.128”,7006)); set.add(new HostAndPort(“192.168.126.128”,7007)); set.add(new HostAndPort(“192.168.126.128”,7008)); set.add(new HostAndPort(“192.168.126.128”,7009)); JedisCluster jedisCluster = new JedisCluster(set); HashMap
list = jedisCluster.hmget(“student”, “name”, “age”, “gender”); list.forEach(System.out::println);
}
<a name="TUwRn"></a>
## 使用SpringBoot整合SpingDataRedis 操作Redis
Spring Data是Spring公司的顶级项目,里面包含了N多个二级子项目,这些子项目都是相对独立的项目。每个子项目是对不同API的封装。所有Spring Boot整合Spring Data xxxx的启动器都叫做spring-boot-starter-data-xxxx。Spring Data 好处很方便操作对象类型。<br />把Redis不同值得类型放到一个opsForXXX方法中。
- opsForValue : String值
- opsForList : 列表List
- opsForHash: 哈希表Hash
- opsForZSet: 有序集合Sorted Set
- opsForSet : 集合
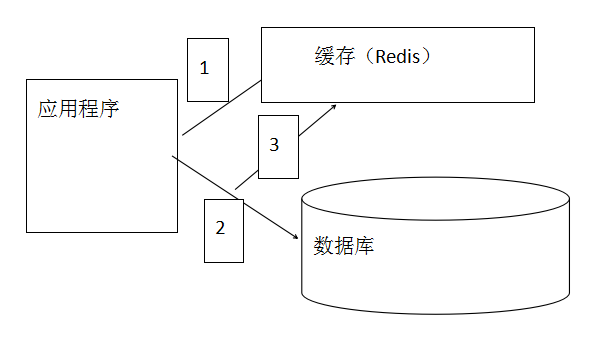
**使用缓存流程:**
1. 先判断缓存中是否存在。如果存在直接从缓存中取出数据。不执行2,3步骤
1. 如果不存在,从mysql中获取数据
1. 获取数据后,把数据缓存到redis中
```java
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<Object>(Object.class));
return redisTemplate;
}
}
@Service
public class PersonServiceImpl implements PersonService {
private final PersonMapper personMapper;
private final RedisTemplate<String, Object> redisTemplate;
@Autowired
public PersonServiceImpl(PersonMapper personMapper, RedisTemplate<String, Object> redisTemplate) {
this.personMapper = personMapper;
this.redisTemplate = redisTemplate;
}
@Override
public Person getPerson(Integer id) {
String key = "person" + id;
if (redisTemplate.hasKey(key)) {
System.out.println("执行缓存");
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<Person>(Person.class));
return (Person) redisTemplate.opsForValue().get(key);
}
System.out.println("执行mysql");
Person person = personMapper.selectById(id);
redisTemplate.opsForValue().set(key, person);
return person;
}
// 操作集合
@Override
public List<Person> getAll() {
String key = "persons";
if (redisTemplate.hasKey(key)) {
System.out.println("执行缓存");
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<List>(List.class));
return (List<Person>) redisTemplate.opsForValue().get(key);
}
System.out.println("执行mysql");
List<Person> list = personMapper.selectById();
redisTemplate.opsForValue().set(key, list);
return list;
}
}
<mapper namespace="com.msb.mapper.PersonMapper">
<select id="selectById" resultType="com.msb.bean.Person">
select id, name, age
from person
<where>
<if test="id !=null">
and id = #{id}
</if>
</where>
</select>
</mapper>
@Controller
@RequestMapping("/person")
public class PersonController {
private final PersonService personService;
@Autowired
public PersonController(PersonService personService) {
this.personService = personService;
}
@RequestMapping("/show/{id}")
@ResponseBody
public String showById(@PathVariable("id") Integer id) {
Person person = personService.getPerson(id);
ObjectMapper objectMapper = new ObjectMapper();
String ans = "";
try {
ans = objectMapper.writeValueAsString(person);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return ans;
}
@RequestMapping("/show")
@ResponseBody
public List<Person> showById() {
List<Person> persons = personService.getAll();
return persons;
}
}
Redis面试相关——缓存穿透,缓存击穿,缓存雪崩
什么是缓存?
- 广义的缓存:就是在第一次加载某些可能会复用数据的时候,在加载数据的同时,将数据放到一个指定的地点做保存。在下一次加载的时候,从这个指定地点去取数据。这里加缓存是有一个前提的,就是从这个地方取数据,比从数据源取数据要快的多。
- java狭义一些的缓存,主要是指三大类:
- 虚拟机缓存(ehcache,JBoss Cache)
- 分布式缓存(redis,memcache)
- 数据库缓存

缓存穿透
缓存穿透:是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决方案:
- 如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
- 把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,既可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
注意:再给对应的ip存放真值的时候,需要先清除对应的之前的空缓存。
public String getPersonById(Long id) {
// 1.先查询redis key为 类全限定名-方法全限定名-id:xxx
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()+ "-id:" + id;
String userName = redisService.getString(key);
if (!StringUtils.isEmpty(userName)) {
return userName;
}
System.out.println("######开始发送数据库DB请求########");
Users user = userMapper.getUser(id);
String value = null;
if (user == null) {
// 标识为null
value = "";
} else {
value = user.getName();
}
redisService.setString(key, value);
return value;
}
缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
热点key:
某个key访问非常频繁,当key失效的时候有大量线程来构建缓存,导致负载增加,系统崩溃。
解决办法:
- 使用锁,单机用synchronized,lock等,分布式用分布式锁。
缓存过期时间不设置,而是设置在key对应的value里。如果检测到存的时间超过过期时间则异步更新缓存。
缓存雪崩
缓存雪崩产生的原因:
缓存雪崩通俗简单的理解就是:由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机,造成系统的崩溃。
缓存失效
解决方案:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。虽然能够在一定的程度上缓解了数据库的压力但是与此同时又降低了系统的吞吐量。
注意:加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着
的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法。
public Users getByUsers(Long id) {
// 1.先查询redis
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()+ "-id:" + id;
String userJson = redisService.getString(key);
// 如果缓存不为空
if (!StringUtils.isEmpty(userJson)) {
Users users = JSONObject.parseObject(userJson, Users.class);
return users;
}
Users user = null;
try {
// 加锁
lock.lock();
// 查询db
user = userMapper.getUser(id);
redisService.setSet(key, JSONObject.toJSONString(user));
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
lock.unlock();
}
return user;
}
- 线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
- 进程锁:为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
- 分布式锁:当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问。
使用分布式锁要满足的几个条件:
- 系统是一个分布式系统(关键是分布式,单机的可以使用ReentrantLock或者synchronized代码块来实现)
- 共享资源(各个系统访问同一个资源,资源的载体可能是传统关系型数据库或者NoSQL)
- 同步访问(即有很多个进程同时访问同一个共享资源。)
应用的场景
线程间并发问题和进程间并发问题都是可以通过分布式锁解决的,但是强烈不建议这样做!因为采用分布式锁解决这些小问题是非常消耗资源的!分布式锁应该用来解决分布式情况下的多进程并发问题才是最合适的。
有这样一个情境,线程A和线程B都共享某个变量X。如果是单机情况下(单JVM),线程之间共享内存,只要使用线程锁就可以解决并发问题。如果是分布式情况下(多JVM),线程A和线程B很可能不是在同一JVM中,这样线程锁就无法起到作用了,这时候就要用到分布式锁来解决。
分布式锁可以基于很多种方式实现,比如zookeeper、redis…。不管哪种方式,他的基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。这里主要讲如何用redis实现分布式锁。
使用redis的setNX命令实现分布式锁
实现的原理
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系。redis的SETNX命令可以方便的实现分布式锁。
基本命令解析
setNX(SET if Not eXists)
- 语法:SETNX key value
- 描述:将key的值设为value,当且仅当key不存在。若给定的key已经存在,则SETNX不做任何动作。SETNX是『SET if Not eXists』(如果不存在,则SET)的简写
- 返回值:设置成功,返回1。设置失败,返回0。
所以我们使用执行下面的命令SETNX可以用作加锁原语(locking primitive)。比如说,要对关键字(key)foo加锁,客户端可以尝试以下方式
SETNX lock.foo <current Unix time + lock timeout + 1>
- 如果SETNX返回1,说明客户端已经获得了锁,SETNX将键lock.foo的值设置为锁的超时时间(当前时间+锁的有效时间)。之后客户端可以通过DEL lock.foo来释放锁。
如果SETNX返回0,说明key已经被其他客户端上锁了。如果锁是非阻塞(non blocking lock)的,我们可以选择返回调用,或者进入一个重试循环,直到成功获得锁或重试超时(timeout)。
getSET
语法:GETSET key value
- 描述::先获取key对应的value值。若不存在则返回nil,然后将旧的value更新为新的value。将给定key的值设为value,并返回key的旧值(old value)。当key存在但不是字符串类型时,返回一个错误。
- 返回值:返回给定key的旧值[之前的值]。当key没有旧值时,也即是,key不存在时,返回nil。
注意的关键点:(回答面试的核心点)
- 同一时刻只能有一个进程获取到锁。setnx
- 释放锁:锁信息必须是会过期超时的,不能让一个线程长期占有一个锁而导致死锁;(最简单的方式就是del,如果在删除之前死锁了。)

public static boolean lock(String lockName) {
// 获取Jedis客户端
Jedis jedis = RedisPool.getJedis();
// lockName可以为共享变量名,也可以为方法名,主要是用于模拟锁信息
System.out.println(Thread.currentThread() + "开始尝试加锁!");
Long result = jedis.setnx(lockName, String.valueOf(System.currentTimeMillis() + 5000));
if (result != null && result.intValue() == 1){
System.out.println(Thread.currentThread() + "加锁成功!");
jedis.expire(lockName, 5);
System.out.println(Thread.currentThread() + "执行业务逻辑!");
jedis.del(lockName);
return true;
} else {
//判断是否死锁
String lockValueA = jedis.get(lockName);
//得到锁的过期时间,判断小于当前时间,说明已超时但是没释放锁,通过下面的操作来尝试获得锁。
//下面逻辑防止死锁 已经过期但是没有释放锁的情况
if (lockValueA != null && Long.parseLong(lockValueA) < System.currentTimeMillis()){
String lockValueB = jedis.getSet(lockName,
String.valueOf(System.currentTimeMillis() + 5000));
//这里返回的值是旧值,如果有的话。之前没有值就返回null,设置的是新超时。
if (lockValueB == null || lockValueB.equals(lockValueA)){
System.out.println(Thread.currentThread() + "加锁成功!");
jedis.expire(lockName, 5);
System.out.println(Thread.currentThread() + "执行业务逻辑!");
jedis.del(lockName);
return true;
} else {
return false;
}
} else {
return false;
}
}
}

若有收获,就点个赞吧
0 人点赞
