非数组对象在内存中的布局:
- markword 8bytes
- class pointer 4bytes(开启压缩后)
- 实例数据
- padding(长度需是8的倍数)
数组对象还多一个数组长度(4bytes)
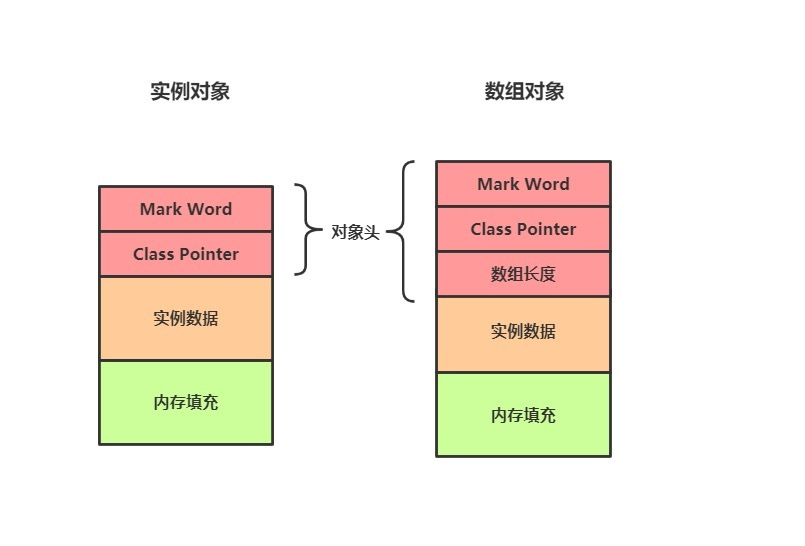
对象头包括markword和classpointer,其中markword记录了synchronized锁的信息。
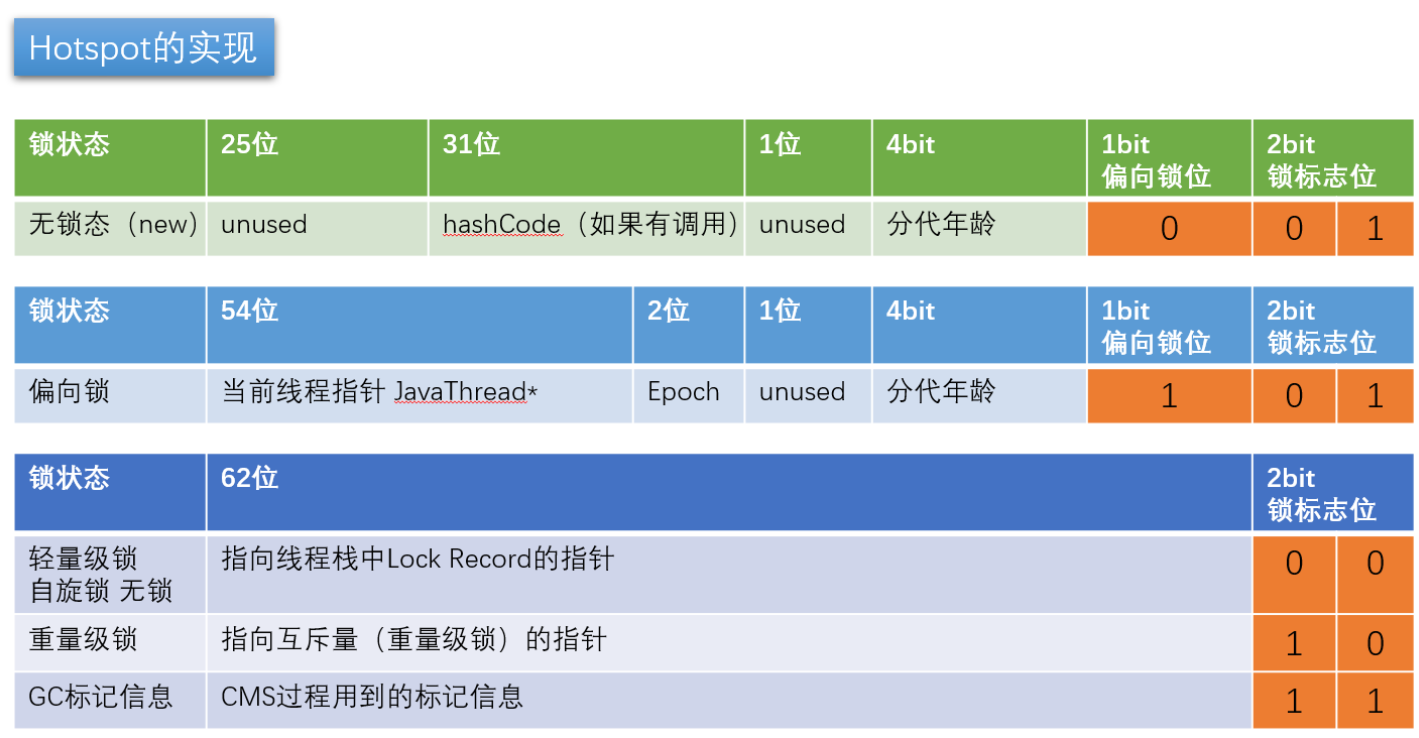
// Bit-format of an object header (most significant first, big endian layout below)://// 32 bits:// --------// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)// size:32 ------------------------------------------>| (CMS free block)// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)//// 64 bits:// --------// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)// size:64 ----------------------------------------------------->| (CMS free block)//// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
Synchronized 的实现
- 源码级别:synchronized(o)
- 字节码级别:monitorenter、moniterexit
- JVM级别(Hotpot)
InterpreterRuntime:: monitorenter方法
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))#ifdef ASSERTthread->last_frame().interpreter_frame_verify_monitor(elem);#endifif (PrintBiasedLockingStatistics) {Atomic::inc(BiasedLocking::slow_path_entry_count_addr());}Handle h_obj(thread, elem->obj());assert(Universe::heap()->is_in_reserved_or_null(h_obj()),"must be NULL or an object");if (UseBiasedLocking) {// Retry fast entry if bias is revoked to avoid unnecessary inflationObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);} else {ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);}assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),"must be NULL or an object");#ifdef ASSERTthread->last_frame().interpreter_frame_verify_monitor(elem);#endifIRT_END
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {if (UseBiasedLocking) {if (!SafepointSynchronize::is_at_safepoint()) {BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {return;}} else {assert(!attempt_rebias, "can not rebias toward VM thread");BiasedLocking::revoke_at_safepoint(obj);}assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");}slow_enter (obj, lock, THREAD) ;}void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {markOop mark = obj->mark();assert(!mark->has_bias_pattern(), "should not see bias pattern here");if (mark->is_neutral()) {// Anticipate successful CAS -- the ST of the displaced mark must// be visible <= the ST performed by the CAS.lock->set_displaced_header(mark);if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {TEVENT (slow_enter: release stacklock) ;return ;}// Fall through to inflate() ...} elseif (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {assert(lock != mark->locker(), "must not re-lock the same lock");assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");lock->set_displaced_header(NULL);return;}#if 0// The following optimization isn't particularly useful.if (mark->has_monitor() && mark->monitor()->is_entered(THREAD)) {lock->set_displaced_header (NULL) ;return ;}#endif// The object header will never be displaced to this lock,// so it does not matter what the value is, except that it// must be non-zero to avoid looking like a re-entrant lock,// and must not look locked either.lock->set_displaced_header(markOopDesc::unused_mark());ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);}
锁升级过程
在jdk早起,synchronized称为重量级锁,因为获取锁需要通过向kernel申请(ox80调用),用户态调用内核态指令。通过升级,synchronized需要经过锁升级过程才会变为重量级锁。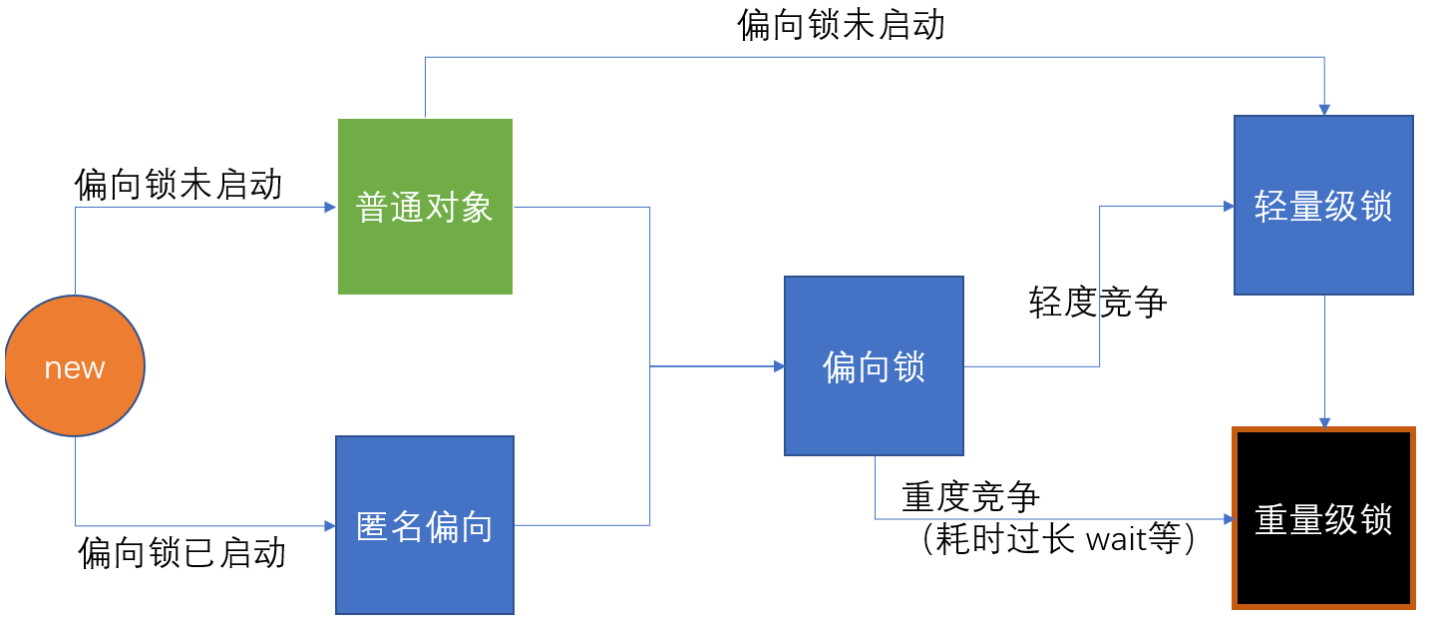
普通对象——>轻量级锁—>重量级锁
public class Code01_Normal {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable(o));
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable(o));
}
}
}
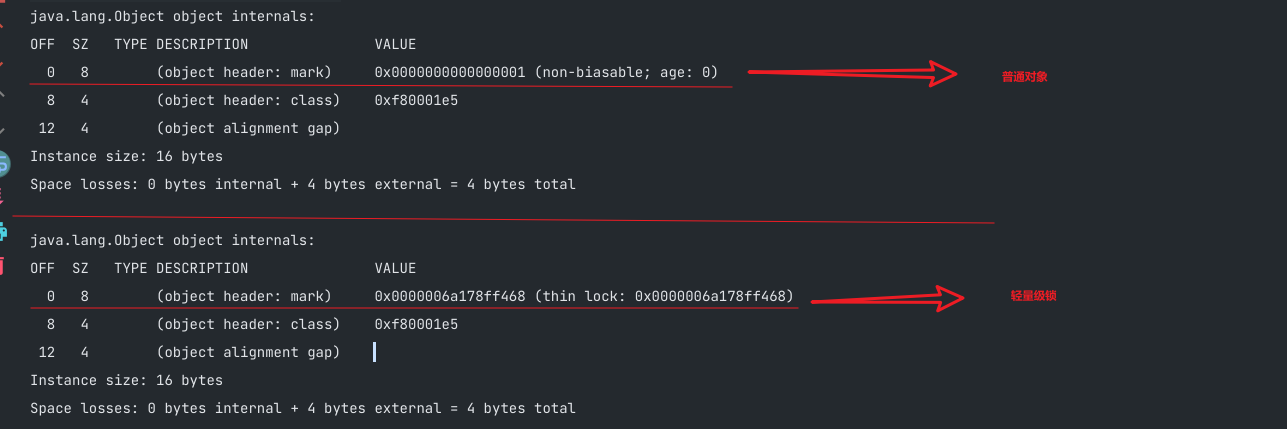
0x0000000000000001
—>0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0001 -》无锁状态
0x0000006a178ff468
—>0000 0000 0000 0000 0000 0000 0110 1010 0001 0111 1000 1111 1111 0100 0110 1000 -》 轻量级锁状态
为什么有自旋锁还需要重量级锁?自旋锁什么时候升级为重量级锁?
线程自旋等待是需要消耗CPU资源的,如果等待锁的时间长或者自选线程很多,那么CPU会被大量消耗。
重量级锁是有等待队列的,拿不到锁的线程进入等待队列,不需要消耗CPU资源。因此还是需要重量级锁。
等待线程自旋次数超过10次或者等待线程数量大于一半CPU核数,那么轻量级锁会升级为重量级锁。
偏向锁是否一定比自旋锁效率高?
不一定。在明确知道有多线程竞争时,偏向锁可能会涉及锁撤销过程,消耗CPU资源;如果直接使用自旋锁,效率会比使用偏向锁效率高。所以JVM启动过程,会有很多线程竞争(明确),所以默认情况启动时不打开偏向锁,过一段儿时间再打开。(默认延迟4s)
匿名偏向——>偏向锁——>轻量级锁——>重量级锁
可通过设置-XX:BiasedLockingStartupDelay=0,即JVM启动时开始偏向锁,普通对象——》轻量级锁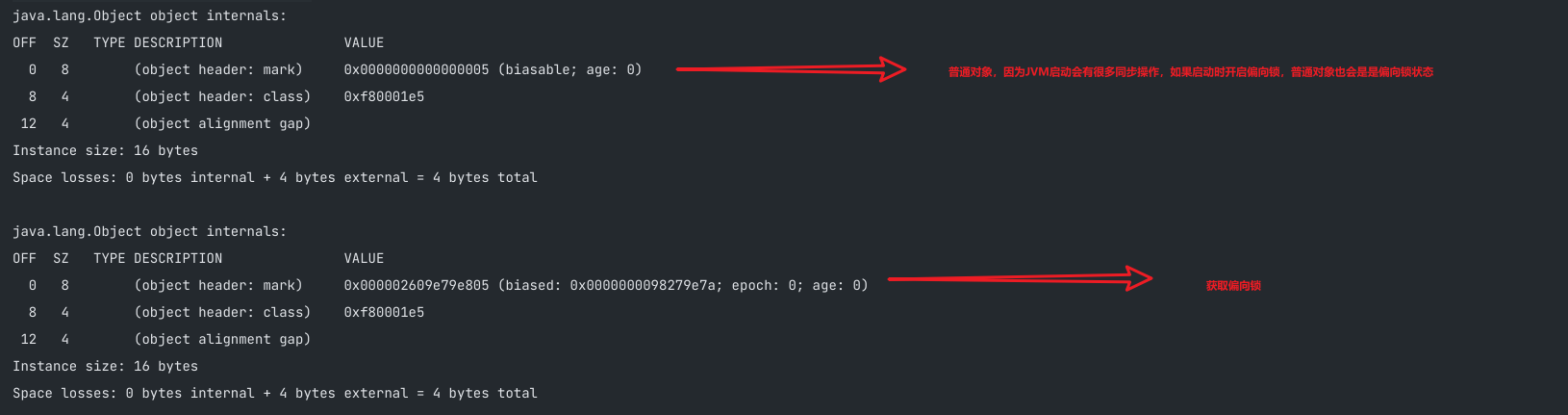
(1)打开偏向锁,new出来的对象,默认就是一个可偏向匿名对象101
0x0000000000000005 -》
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0101
(2)若有线程上锁,把markword的线程ID改为自己线程ID的过程
0x000002609e79e805 ——》
0000 0000 0000 0000 0000 0010 0110 0000 1001 1110 0111 1001 1110 1000 0000 0101
(3)若有线程竞争,撤销偏向锁,升级为自旋锁(轻量级锁)
线程在自己的线程栈生成LockRecord ,用CAS操作将markword设置为指向自己这个线程的LR的指针,设置成功者得到锁。
(4)若竞争加剧,自旋锁升级为重量级锁
竞争加剧:有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制
升级重量级锁:-> 向操作系统申请资源,linux mutex , CPU从3级-0级系统调用,线程挂起,进入等待队列,等待操作系统的调度,然后再映射回用户空间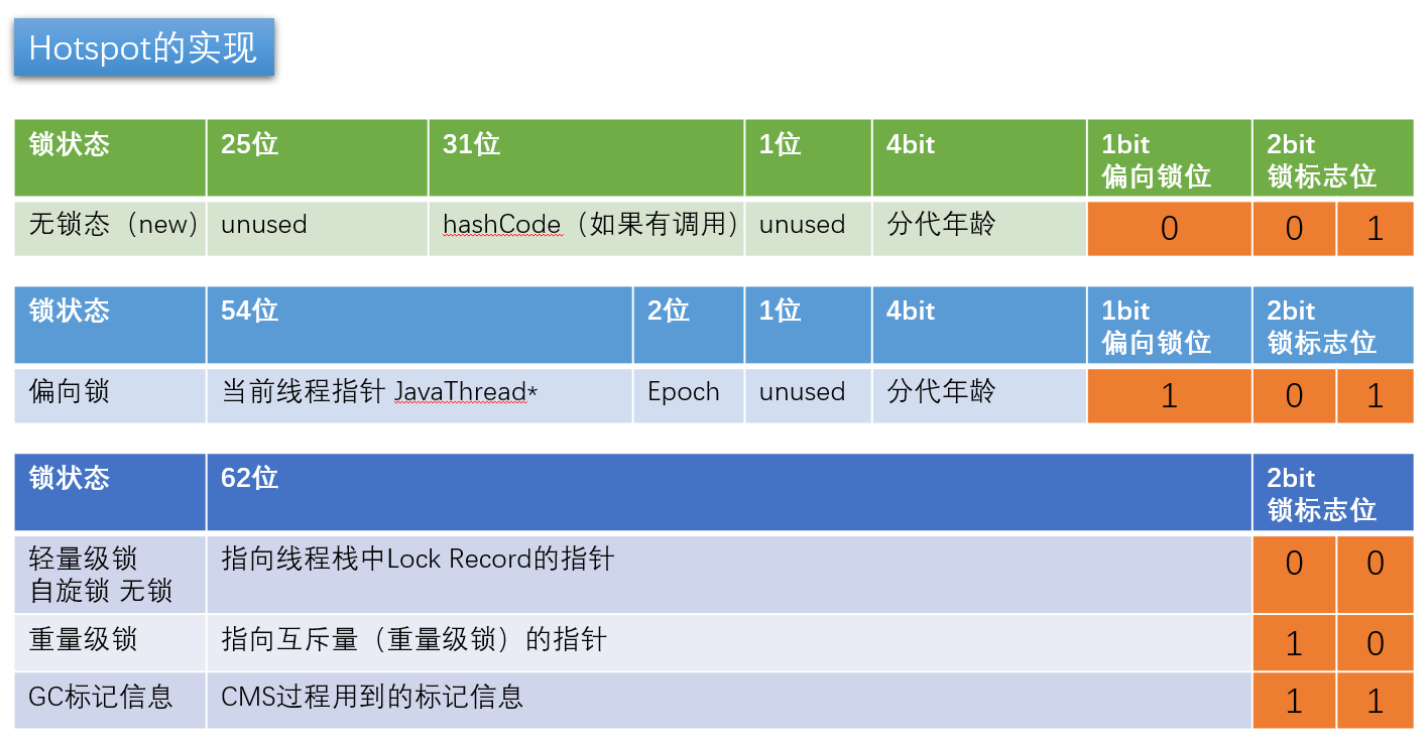
注:(1)如果计算过对象的hashCode,则对象无法进入偏向状态。
(2)轻量级锁重量级锁的hashCode存在线程栈中:轻量级锁的LR(LockRecord )中,或是代表重量级锁的ObjectMonitor的成员中
锁重入
sychronized是可重入锁,重入次数必须记录,因为要解锁几次必须得对应
偏向锁 自旋锁 -> 线程栈 -> LR + 1
重量级锁 -> ? ObjectMonitor字段上
锁消除 lock eliminate
public void add(String str1,String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
我们都知道 StringBuffer 是线程安全的,因为它的关键方法都是被 synchronized 修饰过的,但我们看上面这段代码,我们会发现,sb 这个引用只会在 add 方法中使用,不可能被其它线程引用(因为是局部变量,栈私有),因此 sb 是不可能共享的资源,JVM 会自动消除 StringBuffer 对象内部的锁。
锁粗化 lock coarsening
public String test(String str){
int i = 0;
StringBuffer sb = new StringBuffer():
while(i < 100){
sb.append(str);
i++;
}
return sb.toString():
}
JVM 会检测到这样一连串的操作都对同一个对象加锁(while 循环内 100 次执行 append,没有锁粗化的就要进行 100 次加锁/解锁),此时 JVM 就会将加锁的范围粗化到这一连串的操作的外部(比如 while 虚幻体外),使得这一连串操作只需要加一次锁即可。

若有收获,就点个赞吧
0 人点赞
