- Zookeeper简介
- Zookeeper集群准备
- ZooKeeper使用的基本时间单位(毫秒)。它用于做心跳,并且最小会话超时将是tickTime的两倍。
- The number of ticks that the initial
- synchronization phase can take
- 是超时ZooKeeper用于限制仲裁中的ZooKeeper服务器必须连接到领导者的时间长度
- zookeeper集群中的包含多台server, 其中一台为leader,
- 集群中其余的server为follower. initLimit参数配置初始化连接时,
- follower和leader之间的最长心跳时间.
- 此时该参数设置为10, 说明时间限制为10倍tickTime, 即10*2000ms=10000ms=20s.
- The number of ticks that can pass between
- sending a request and getting an acknowledgement
- 限制了服务器与领导者之间的过时距离。
- 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度.
- 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000ms=10s.
- the directory where the snapshot is stored.
- do not use /tmp for storage, /tmp here is just
- example sakes.
- 存储内存数据库快照的位置,除非另有说明,否则存储数据库更新的事务日志。
- the port at which the clients will connect
- 用于侦听客户端连接的端口
- the maximum number of client connections.
- increase this if you need to handle more clients
- 最大客户端连接数
- maxClientCnxns=600
- Be sure to read the maintenance section of the
- administrator guide before turning on autopurge.
- http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance">http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
- The number of snapshots to retain in dataDir
- autopurge.snapRetainCount=3
- Purge task interval in hours
- Set to “0” to disable auto purge feature
- autopurge.purgeInterval=1
- https://prometheus.io Metrics Exporter">https://prometheus.io Metrics Exporter
- metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
- metricsProvider.httpHost=0.0.0.0
- metricsProvider.httpPort=7000
- metricsProvider.exportJvmInfo=true
- 集群配置,2888端口是用于与Leader通信端口,3888是选Leader时通信端口
Zookeeper简介
ZooKeeper是一种分布式应用程序的分布式协调服务,其特点:
- Zookeeper允许个分布式进程通过共享分层命名空间—znodes(类似文件目录)进行相互协调,可以存储1M数据。
- Zookeeper数据存储在内存当中,使zookeeper具备低延迟和高吞吐量的特点。
- Zookeeper具备高性能、高可用性(zookeeper可构建集群,Leader故障时能快速选出新的Leader)和有序法访问。
- Zookeeper集群中的节点互相通信,内存中维持状态信息,并持久存储事务日志和快照,只要一半以上的节点可用,那么集群服务就可用。
- ZooKeeper用一个数字标记每个更新,这个数字反映了所有ZooKeeper事务的顺序。后续操作可以使用此顺序来实现更高层次的抽象,例如同步原语。即顺序一致性——来自客户端的更新将按照它们被发送的顺序应用
- Zookeeper操作是原子性的——更新要么成功要么失败。没有部分结果。
- Zookeeper集群数据保持一致,一个客户端连接任意节点可看的相同的视图,如果因为节点故障而转移到其他节点,会话(Session)不变。
- 可靠性——一旦应用了更新,它将一直持续到客户端覆盖更新。(最终一致性)
- 及时性——保证系统的客户端视图在特定的时间范围内是最新的。
Zookeeper数据模型和层次名称空间
ooKeeper提供的命名空间很像标准的文件系统。名称是由一个斜杠(/)分隔的路径元素序列。ZooKeeper命名空间中的每个节点都由路径标识。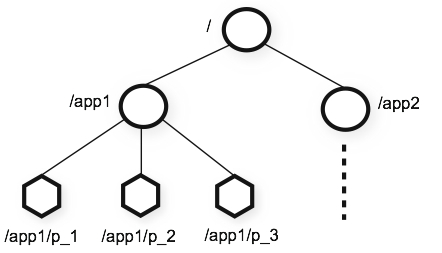
节点和临时节点
- Zookeeper的每一个节点(znode)都可以同时存储数据(不超过1M)和拥有子节点
- znode维护一个stat结构,其中包括数据更改的版本号、ACL更改和时间戳,以允许缓存验证和协调更新。每次znode的数据更改时,版本号就会增加。
- 名称空间下的znode中的数据,读写操作是原子的。读操作获取znode的所有数据字节,写操作替换所有数据。
- 每个节点都有一个访问控制列表(Access Control List, ACL),用于限制谁可以做什么。
ZooKeeper也有临时节点的概念。创建的临时节点随会话(session)结束而删除。
条件更新和watches
客户端可以在znode上设置watches。当znode变化时,watch将被触发并移除。当一个watch被触发时,客户端会收到一个数据包,告诉znode已经改变(函数回调)。如果客户端和其中一个ZooKeeper服务器的连接中断,客户端会收到本地通知。
3.6.0新增功能:客户端还可以在一个znode上设置永久的、递归的watch,这个watch在被触发时不会被移除,并且递归地触发已注册的znode以及任何子znode的变化。Zookeeper API
create : 创建1个节点
- delete : 删除一个节点
- exists : 判断一个节点是否存在
- get data : 获取节点数据
- set data : 更新一个节点数据
- get children : 获取节点的子节点
-
Zookeeper的一些实现
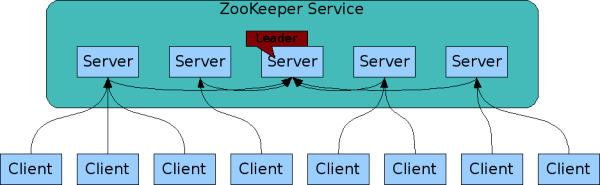
Zookeeper集群的每一个节点都有相同的数据
- Zookeeper集群所有节点都提供读操作,但是节点更新操作都会提交给Leader进行操作。(其中Follower与Leader之间会按照ZAB协议进行通信)
- Zookeeper集群Leader失效时Follower会快速(200ms内)选举出新的Leader,保证集群的高可用。
Zookeeper集群准备
jdk运行环境准备:下载jdk,配置环境变量
export JAVA_HOME=/usr/local/jdk8export PATH=$PATH:$JAVA_HOME/bin
下载zookeeper,配置环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeper3.8.0export PATH=$PATH:$ ZOOKEEPER_HOME/bin
编写配置文件
cd /usr/local/zookeeper3.8.0cd /confcp zoo_sample.cfg zoo.cfgvim zoo.cfg
```bash
ZooKeeper使用的基本时间单位(毫秒)。它用于做心跳,并且最小会话超时将是tickTime的两倍。
tickTime=2000
The number of ticks that the initial
synchronization phase can take
是超时ZooKeeper用于限制仲裁中的ZooKeeper服务器必须连接到领导者的时间长度
zookeeper集群中的包含多台server, 其中一台为leader,
集群中其余的server为follower. initLimit参数配置初始化连接时,
follower和leader之间的最长心跳时间.
此时该参数设置为10, 说明时间限制为10倍tickTime, 即10*2000ms=10000ms=20s.
initLimit=10
The number of ticks that can pass between
sending a request and getting an acknowledgement
限制了服务器与领导者之间的过时距离。
该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度.
此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000ms=10s.
syncLimit=5
the directory where the snapshot is stored.
do not use /tmp for storage, /tmp here is just
example sakes.
存储内存数据库快照的位置,除非另有说明,否则存储数据库更新的事务日志。
dataDir=/var/local/zookeeper
the port at which the clients will connect
用于侦听客户端连接的端口
clientPort=2181
the maximum number of client connections.
increase this if you need to handle more clients
最大客户端连接数
maxClientCnxns=600
#
Be sure to read the maintenance section of the
administrator guide before turning on autopurge.
#
http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
Purge task interval in hours
Set to “0” to disable auto purge feature
autopurge.purgeInterval=1
Metrics Providers
#
https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
集群配置,2888端口是用于与Leader通信端口,3888是选Leader时通信端口
server.1=192.168.126.6:2888:3888 #myid 1 server.2=192.168.126.11:2888:3888 #myid 2 server.3=192.168.126.12:2888:3888 #myid 3 server.4=192.168.126.13:2888:3888 #myid 4
4. 在配置的dataDir指定目录下创建myid文件,内容分别是1、2、3、44. 依次前台启动zookeeper zkServer.sh start-fore-ground4. netstat -an | grep 2888 、netstat -an | grep 3888 查看端口使用情况** (tcp连接是双向的,所有能够保证集群所有节点都能够进行互相通信)**<br /><br />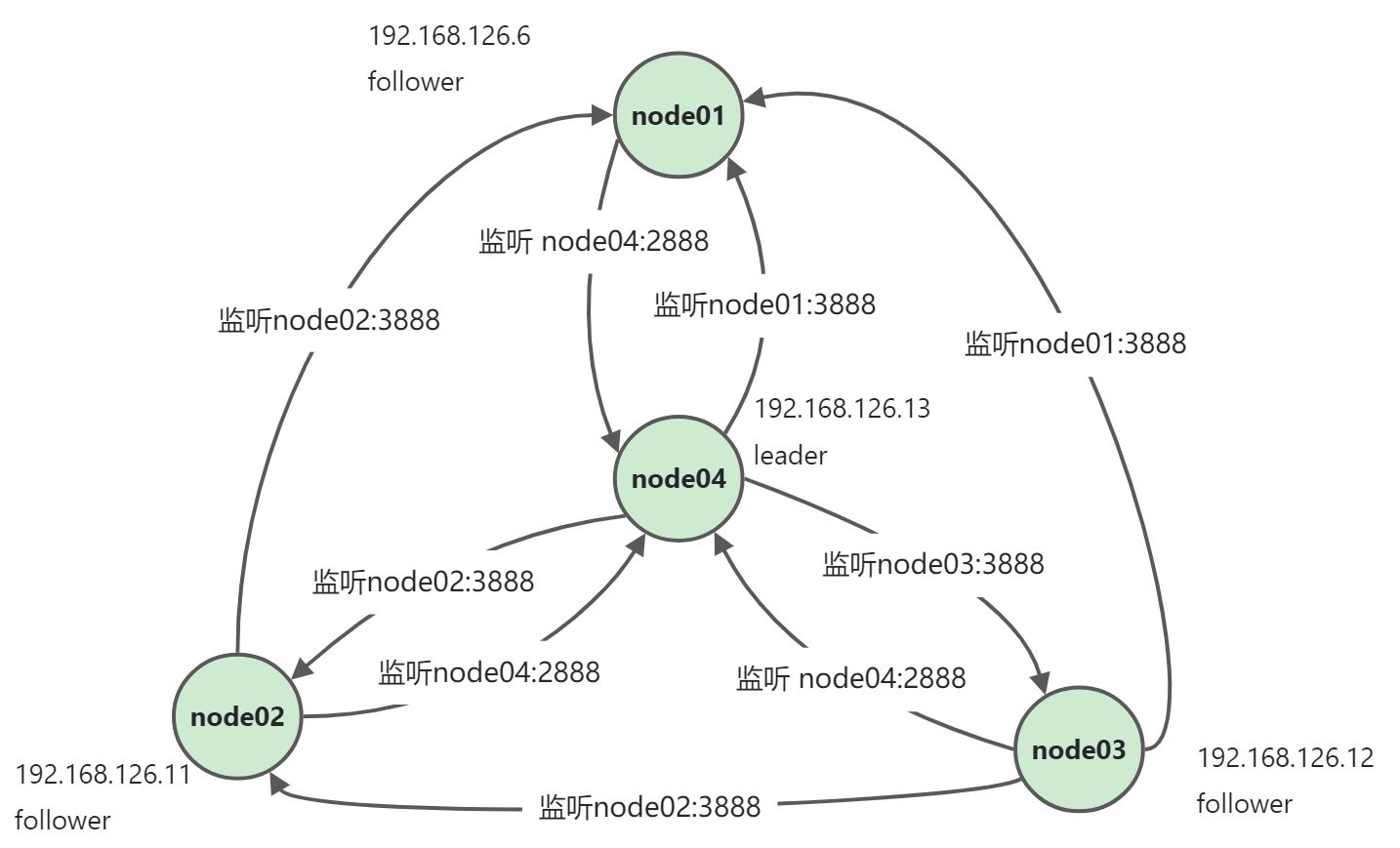<a name="aCmI1"></a>## Zookeeper stat信息```bash[zk: localhost:2181(CONNECTED) 12] get -s /ooxx/xxoohellocZxid = 0x300000007ctime = Mon May 09 07:59:01 CST 2022mZxid = 0x300000007mtime = Mon May 09 07:59:01 CST 2022pZxid = 0x300000007cversion = 0dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 5numChildren = 0
- hello:存放的数据
- cZxid:创建时zxid(znode每次改变时递增的事务id)
- ctime:创建时间戳
- mZxid:最近一次更新的zxid
- mtime:最近一次更新的时间戳
- pZxid:子节点的zxid
- cversion:子节点更新次数
- dataversion:节点数据更新次数
- aclVersion:节点ACL(授权信息)的更新次数
- ephemeralOwner:如果该节点为ephemeral节点(临时,生命周期与session一样), ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是ephemeral节点, ephemeralOwner值为0.
- dataLength:节点数据字节数
-
Zookeeper节点通信协议
Zookeeper具备扩展性、可靠性,其主要还是基于Leader节点与Follower、Observer节点之间的通信,保证数据一致,保证Leader挂掉之后能够快速选出新的Leader。通信基于Paxos、ZAB协议。
Zookeeper.xmindPaxos协议
paxos-simple.pdf
Paxos Made Simple 论文翻译版:https://www.jianshu.com/p/67dd80555ba2
快速理解Paxos:https://blog.csdn.net/qq_41946557/article/details/102222863 Paxos协议保证多个进程提议的多个值只有1个会被选择,且被选中后所有的进程都会采用被选中的值
- Paxos有三个角色:proposers、acceptors、learners
- 每个代理可能具备多个角色,每个代理之间可以相互通信
- Paxos的前提是没有拜占庭将军问题:
- 代理以任意速度操作,可能因停止而失败,也可能重新启动。由于所有代理都可能在选择一个值然后重新启动后失败,除非某个失败并重新启动的代理能够记住某些信息,否则不可能有解决方案。
- 消息传递的时间可以任意长,可以复制,也可以丢失,但它们没有损坏。
- 每个proposer进行提议每个值,都会有一个数字表示当前版本P
ZAB协议
ZAB协议详解:https://blog.csdn.net/liuchang19950703/article/details/111406622
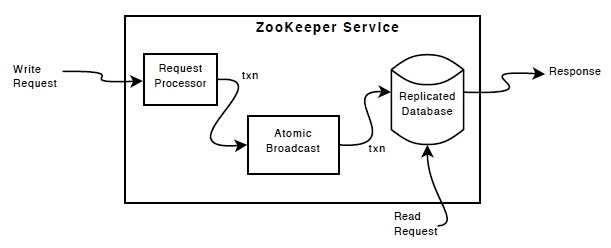
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。
- Zab协议是为分布式协调服务Zookeeper专门设计的一种 支持崩溃恢复 的 原子广播协议 ,是Zookeeper保证数据一致性的核心算法。Zab借鉴了Paxos算法,但又不像Paxos那样,是一种通用的分布式一致性算法。它是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。
- 在Zookeeper中主要依赖Zab协议来实现数据一致性,基于该协议,zk实现了一种主备模型(即Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。
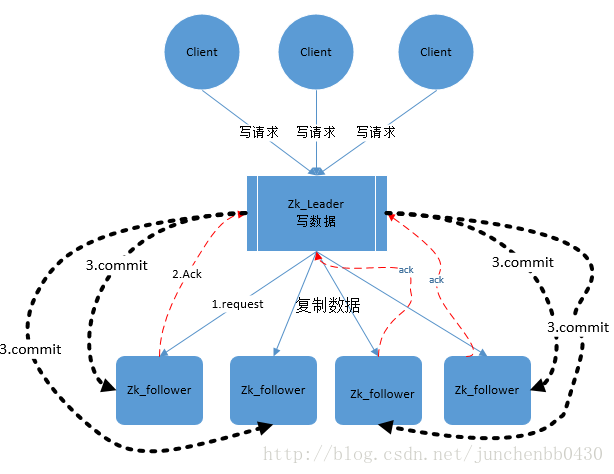
这里的主备系统架构模型,就是指只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。
- Zookeeper 客户端会随机的链接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;
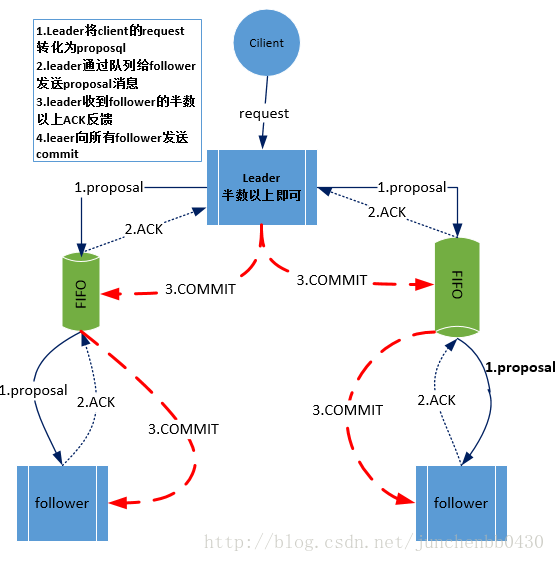
- 如果是写请求,那么节点就会向 Leader 提交事务,Leader 接收到事务提交,会广播该事务,只要超过半数节点写入成功,该事务就会被提交。
ZAB协议的四个阶段
选举阶段(3888端口)—》发现阶段(2888端口)—》同步阶段(2888端口)—》广播阶段(2888端口)
- 选举阶段成为 Leader 的条件:
1)选 epoch 最大的
2)若 epoch 相等,选 zxid 最大的
3)若 epoch 和 zxid 相等,选择 server_id 最大的(zoo.cfg中的myid)
Zookeeper的应用
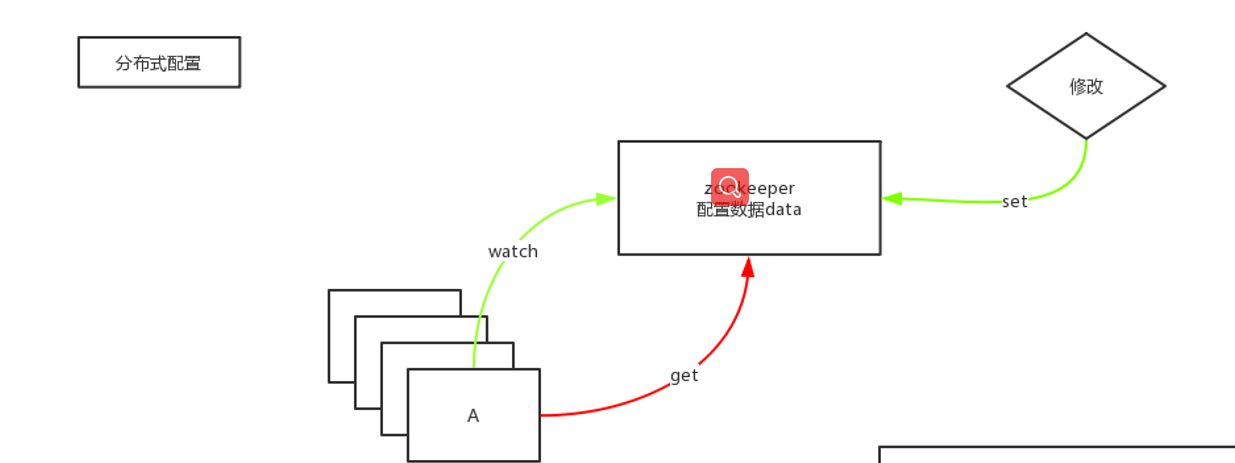
分布式配置管理
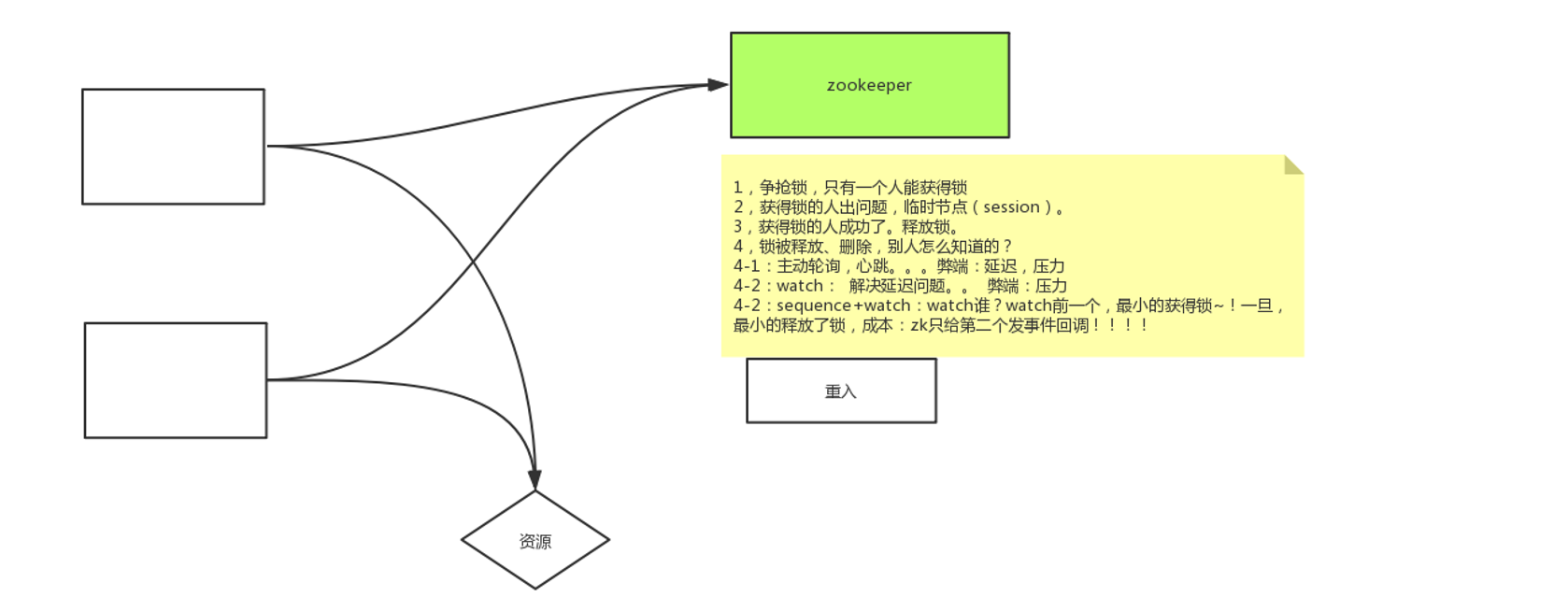
分布式锁

若有收获,就点个赞吧
0 人点赞
