- volatile底层
- 重排序
- 又细又多又繁琐
- 解决内容:
- 在高并发情况下,java内存模型是怎样提供支持的
- 一个对象new出来之后,在内存中到底是怎样布局的
硬件层的并发优化基础知识(硬件—->jmm在硬件基础上是如何实现的)
- 指令重排
- happens-before原则
- as-if-series
- 八大原子指令
- 上述都要靠到硬件上去,所以先讲硬件
- jmm是在硬件上进行架构的

超线程—->两个线程在同一个cpu里面跑
disrupter和listtransferqueue中都用了缓存行对齐的方式来提高效率
伪共享问题:使用缓存行对齐能够解决伪共享问题产生的效率下降,但是同时也会浪费空间
合并写技术(读可以乱序,写可以进行合并)
- 硬件层面上还有一个WCBuffer的缓存,这是最快的缓存,比L1缓存还要快,但是他所有的空间也是最小的,只有4byte的空间,只要4byte一满,他就会讲缓存中的内容写到L2缓存中去或者内存里去
- 在一条指令往L2中写的时候,因为太慢了,所以会将之后的对同一个变量的写命令一起执行(假如后续指令也改变了这个值),会合并到一起,扔到一个合并缓存中去,最后将最终的结果扔到L2中去
乱序的证明
- 美团的Disorder程序:(x,y)只能出现(1,0)、(0,1)(1,1),不可能出现(0,0),若真实运行的时候出现了(0,0)说明在程序的执行中可能发生了重排序
- 乱序会产生问题—->volatile保证不能乱序执行,有些情况不能乱序执行(有些情况不能往里面写必须先读,有些情况不能先读必须先写才行)
cpu级别的内存屏障和jvm层面的内存屏障
- 硬件级别如何保证
- JVM级别如何规定,只有规范,具体的实现还得通过c语言操作硬件的那个级别
cpu级别的内存屏障(这里指x86的)
- 不同cpu的内存屏障是不一样的,指令也是有区别的
- intel的cpu的内存屏障:sfence、lfence、mfence
有序性保障 CPU内存屏障 sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。 Ifence:在Ifence指令前的读操作当必须在Ifence指令后的读操作前完成。 mfence:在mfence指 令前的读写操作当必须在mfence指令后的读写操作前完成。
jvm层面的内存屏障
- load是jvm层面的内存屏障???
- 不是说只有硬件层面上的内存屏障才可以实现jvm层面的内存屏障(硬件上也可以用lock指令来实现)
- jvm级别的东西和硬件层面的东西有的不是一回事
- 线程工作内存是对cpu告诉缓存的抽象吗?——>不能说的这么粗狂,严格来讲,线程工作内存就是jvm规范的东西,而jvm要把什么装到内存中去是虚拟机自己的事;线程工作内存现在可以认为是包括cpu告诉缓存的,他是jvm规范实现上的一个对应关系

- 上图不是实际中的物理层,而是JVM虚拟机规定的一个模型,是实际物理实现的一部分,这个模型是怎么实现的要看虚拟机各自的实现,
- 工作内存完全可以是物理内存(告诉缓存和主内存)的一部分(前面的说法是完全可以的)**,主要看JVM虚拟机是怎么实现的**
- storeload屏障是“全能屏障”,硬件层级mfence屏障是全能屏障
- 编程趋势:volatile不用了,都用synchronized(全用synchronized),因为synchronized经过优化后的效率其实也非常高并不比volatile差多少,只有在那种非常追求效率的情况下要用volatile,假如不是在那种非常追求效率的情况下没必要用volatile
volatile的实现细节
- 硬件
- 软件
- jvm
- 字节码混着讲
- 有好几层,不同的层级有不同的实现(字节码bytecode实现—->jvm实现—->os/hd实现)
字节码层面
- ACC_VOLATILE
JVM层面
- 对于所有的写操作前面加了StoreStoreBarrier,后面加了个StoreLoadBarrier
- 对于所有的读操作前面加了LoadLoadBarrier,后面加了个LoadStoreBarrier
- volatile内存区的读写都加屏障
硬件层面
- JVM层面的volatile在硬件层面是如何实现的
- hsdis—-HotSpot Dis Assembler虚拟机的反汇编,把虚拟机编译好的字节码再进行反汇编,观察jvm编译好的字节码在cpu级别是用什么汇编指令完成的(下面文章讲的是在windows上的实现,在Linux上可能是另一个实现)

- 在Windows上是用lock实现的,没有用lfence、sfence或者mfence;在Linux上据说是上面一个屏障、下面一个屏障、最后再加一个lock;每个上面不太一样
volatile的实现是分不同层级的
synchronized的实现细节
字节码层面
- synchronized修饰方法的时候,只会加一个synchronized的修饰符ACC_SYNCHRONIZED
- 而synchronized修饰代码块的时候会有monitorenter和monitorexit这两条指令
- 中间的monitorexit表示发现异常之后会自动退出

- 字节码层面没有太复杂,比较简单,没有牵扯到具体cpu的实现
JVM层面
- C/C++写的,调用了操作系统的同步机制
- C/C++与具体系统相关,在不同的OS内核上有不同的实现(linux、windows上都会提供同步机制—->互斥区、同步区),通过同步区互斥区来提供不同的互斥机制
- 看操作系统内核提供的函数就行了
硬件层面
- 硬件层面基本上用lock指令来实现!!!
- lock指令:lock comxchg ××××(x86)
- comxchg指令是CAS指令(compareAndExchange)
- cpu级别实现同步—->lock一条指令
- 比如将i从0变成1(可能好几条指令,不能同步)
- lock comxchg(0, 0, 1),在执行这条指令的过程中这块内存是被lock住的—->这就进行了同步,内部就完成了synchronized
- synchronized(this){ }有一堆需要同步咋办?
- 很简单,一条lock指令,comxchg(this),change this的时候只有lock住了这个东西之后,后面的才能继续执行,如果执行不了(要想执行只能lock他),如果lock没成功又跳回来JNE,原来从0到1,现在从1到2;这样就保证了不同的线程之间是不可能乱入的
- 保证了一个线程执行到中间,另一个线程也来执行了(有个lock comxchg在那!!!)
- 因为lock comxchg二话不说上来首先干lock aomxchg这件事,你上来把0变成1,我上来就要把1变成2;如果你把1变成不了2,那么后面的就执行不了(这样就将那一块代码给锁住了)
- 上面就是硬件层面上的实现
java的8大原子操作(原来的虚拟机规范)
- 现在的JSR-133已经放弃了这样的描述,但JMM没有变化

- JMM没有变化,只不过描述方式发生了变化,不再拿这种方式去描述JMM规定的一些指令、规范了
happens-before原则(顺序、排序)
- 是java语言的要求,由具体的java虚拟机去实现,本质上实现也是用了前后不能错顺序的方式(上面讲的内容)
- 这是java语言的规范,jvm实现java语言的时候必须遵守这个规范
- 说的是有些指令不能重排的问题,由具体的jvm去实现的
- 本质上还是有些指令不能进行重排的问题
- 可以去读jvm的规范JVMS和实现以及java语言的规范JLS(优先级低)—->oracle网站上下载—->17节的17.4Memory Model下的17.4.5有happens before order

as if serial
- 不管如何重排序,**单线程执行结果不会改变**
- 最后的结果不变
- 重排序不会影响最终的结果,要和没有重排序的结果一样!!!
对象的创建过程
对象的内存布局
观察虚拟机配置:
java -XX:+PrintCommandLineFlags -version普通对象
在hotspot虚拟机中对象头叫做markword,占8个字节
- ClassPointer指针,class的指针,对象属于哪个class,对象中有一个指针指向那个class的类对象(T.class)
- 实例数据:成员变量,int m=9; String是引用指向另外一个
- 引用类型:-XX:+UseCompressedClassPointers为4字节,不开启为8字节(默认是开启的?)
- Oops Ordinary Object Pointer
Padding对齐,8的倍数,真正按块来读,不是真正按多少个字节来读,一下子读16个效率反而会更高,所以要通过填充来进行对齐
数组对象(多了一项)
对象头:markword 8
- ClassPointer指针同上(数组中装的是什么类型的东西)
- 数组长度:4字节
- 数组数据(真正的数据)
- 对齐 8的倍数
对象的大小
- java中没有sizeof这之类的获取大小的方法(一般动态语言也有这个方法)
- java的agent机制:在字节码文件被load到内存的过程中可以使用agent代理截获这些class文件(0101101011101……),并且可以任意进行修改,截获到就可以任意修改,就可以读出来object的大小
- 一般用不上,跟抓包一样,做这个实验要用他
- 这个代理必须得自己去实现(可以任意修改class文件)
- 类似asm
- 将代理装到jvm上去,写一个类,然后打一个包,需要配置一下premain-class(MAINIFEST.MF文件),指定好提前在main方法之前运行的class是哪一个

- 那个类中要有premain方法,这个方法是固定的,里面的参数也是固定的(与main方法一样格式是固定的),第二个参数是Instrumentation
- 这个方法是虚拟机自动调用的,如何拿到Instrumentation调琴师:通过premain方法拿到jvm传给这个方法的调琴师赋值给自己的成员变量(jvm自动调用,jvm会传过来他的调琴师)
- 调琴师中有一个getObjectSize的方法,这样就能知道对象的大小
- 在idea中打成一个jar包,拿到别的项目中去用,这个东西实际就是一个agent,把这个jar文件当成一个agent给用到另外一个项目中去
- jar文件代表的就是agent(了解)
- 在别的项目中用agent的时候必须加参数
-javaagent:c:\work\……\ObjectSize.jar - javaagent有很多用处,阿里的调试gc的工具arthas就是用javaagent完成的
- 指针压缩打开就会把原来8个字节的类指针压缩成4个字节(在java中原来的指针是64位的,即8字节的???,压缩之后就变成了4字节)
- 最终必须是8的倍数
- 数组的**classpointer**不是oops,这是错的!!!(网上是错的,误导性特别强)
- 在64位的机器上引用类型(ref)的大小是64位的(总线宽度、大小)即8字节
- Oops是ordinary object pointers—->普通的对象指针
- Oops与ClassPointer是不一样的,两者之间的压缩命令也是不一样的(两个是不同的压缩选项!!!),Oops是
**-XX:+UseCompressedOops**,而ClassPointer是**-XX :+UseCompressedClassPointers** - Oops与ClassPointer是分开的,一个是普通对象指针,一个是类对象指针;并且这两者的压缩也是分开的
- String类型是引用类型
- 网上有n多文章将Oops安到ClassPointer上去了❌
- 这个实验自己做,做不出来就背过
- HotSpot开启压缩是有一些原则,这些原则了解一下(内存不是越大越好)

对象头中具体包括了什么
- 非常复杂
- 各个版本的实现也不一样(此处以1.8为例)
- 需要看虚拟机的源码了—->markword的结构定义在markOop.hpp文件中(c++)
- 32位怎么实现的,64位是怎么实现的,其中有多少位是不用的,里面哪两位代表的是什么内容(特别复杂)
- 下图中的那个表是用32位的情况在说明64位的情况,所以表格中hashcode25位,而下面的文字说明有31位!!!(不要眼花,要认真看!要仔细看!小心谨慎!!!)

- 不同对象状态下,记录的内容是不一样的
- 面试题:markword里面装的是什么呀?
- 锁定信息:两位代表该对象有没有被锁定,锁定的意思是synchronized(这个对象—->this、o、p),当锁定了这个对象的时候,用这两位来标记这个锁的标志位
- gc的标记:表示对象被回收了多少次了,他的年龄是多少,指分代年龄!
- 64的头中有8个字节,其实是看对象的状态来真正分配这64位,在普通状态下是什么样的,在锁定状态下是什么样的,在不同的状态下这64位的情况是不一样的
- 严格来讲是里面的三位表示锁的状态,而不是两位(实际中是三位)
- 在无锁状态的时候,那个hashcode也并不是显式显示在markword中的,不是记录在这里的,只有调用了这个对象的hashcode的时候,他才会被记录在markword中
- 这里存的是按原始内容计算的hashcode(这个hashcode是identityHashCode),重写过的hashcode方法计算的结果不会存在这里???❓
- hashcode比较特殊,分两种情况
- hashCode被重写过:根据重写的逻辑决定hashcode的值,❓此时不存放到markword的hashcode位置上去???❓
- hashCode没有被重写过,hashCode是根据对象后面的这些内存的具体情况算出来的值,❓一旦生成了这个hashcode,就会将这个hashcode放到markword头中去—->什么时候生成hashcode呢?—->调用未重写的hashcode方法或者调用了System.identityHashCode方法的时候❓
- 一共占25位(cpu系统是32位的情况)
- 32位与64位差不了太多
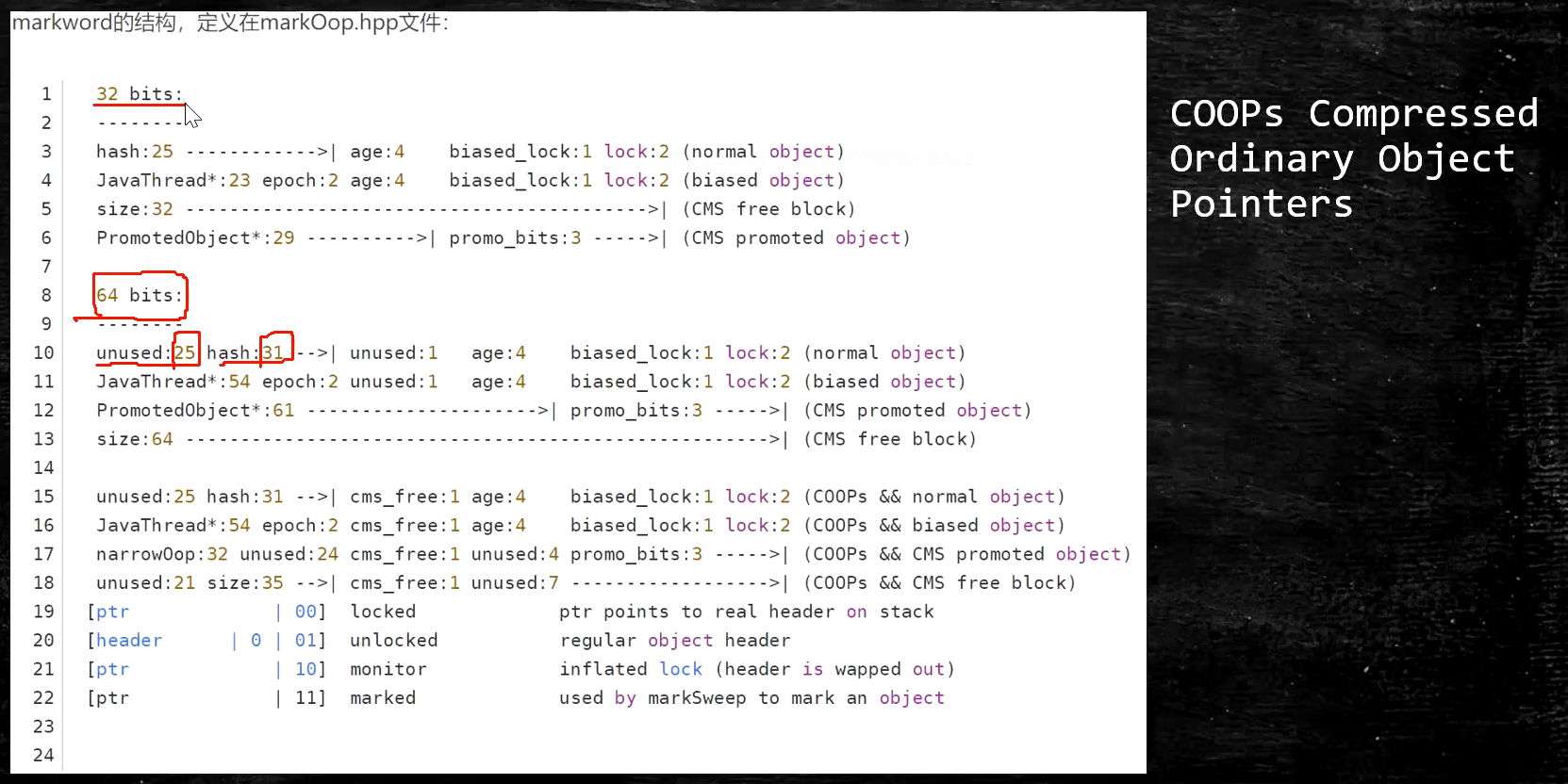
- gc的回收状态与gc的垃圾回收相关,CMS是gc的其中一个过程:CMS promoted
- 总之,不同的状态,前面的markword表示的是不同的内容—->复杂
- 锁标志位分别代表无锁、偏向锁、轻量级、重量级、gc标记(gc也会用到锁(stop-the-world))
- 如何出面试题,搞那些自己关心的面试题(实际中用到的那些自己比较关心的新技术之类的、或者是自己想解决的问题)做成面试题,让面试的人现场打开机器来解决就可以了
- IdentityHashCode的问题:当一个对象计算过identityHashCode之后,不能进入偏向锁状态,可能会直接进入重量级锁状态,因为hashcode可以存在重量级锁的monitor中,而在偏向锁或者轻量级锁中无法存放

- 上图是正确的,如果已经计算过hashcode,就相当于那一块被偏向锁给占了,这时候偏向锁就进不来了

-
对象定位(面试官卖弄的过程)
- T t = new T();
- t是如何找到new出来的那个对象的?(两种方式)
- 句柄池(间接指针):t指向两个指针,一个指向对象,一个指向T.class(相当于中间隔了一下,中间单独拿出来了—->实际对象和类对象)
- 直接指针:平时常话的,t直接指到实际对象,在实际对象中有一个class指针指向T.class

句柄池和直接指针没有优劣之分,有的虚拟机实现用第一种,有的用第二种(Hotspot用的第二种)
- 第二种效率比较高,直接就找到对象了
- 第一种效率相对比较低一些,因为他需要找两次指针(需要找一个指针再找一个指针),但是句柄池的方法在GC垃圾回收的时候效率比较高
- GC的时候牵扯到一些算法,后面会说(比如说三色标记算法CMS回收器)
- 使用三色标记算法进行回收的时候假如用句柄池效率会相对比较高,使用第二种效率会比较低
对象怎么分配
- 与GC相关的,讲到GC时再讲
- 公开课
- 非常复杂
- 尝试往栈上分配,栈一弹出,这个对象就没了
- 如果栈上那个分配不下,特别大的对象,直接分配到堆内存的老年代
- 如果对象不大,首先进行线程本地分配,能分配下就分配,分配不下找eden区
- 然后进行GC,年龄到了就进入老年代;年龄不到就GC来GC去

若有收获,就点个赞吧
0 人点赞
