- MySQL模糊查询like可以解决检索、搜索的问题(全文索引)
- ES可以进行PB级的数据的近实时搜索—->秒级!!!IT男的梦想
- 搜索引擎
- 分析引擎
- 存储引擎
- kibana可以对未来可能发生的情况进行预测——>机器学习的应用
- ElasticSearch在索引创建之后,你可以在任何时候动态地改变**复制数量,但是不能改变**分片的数量。
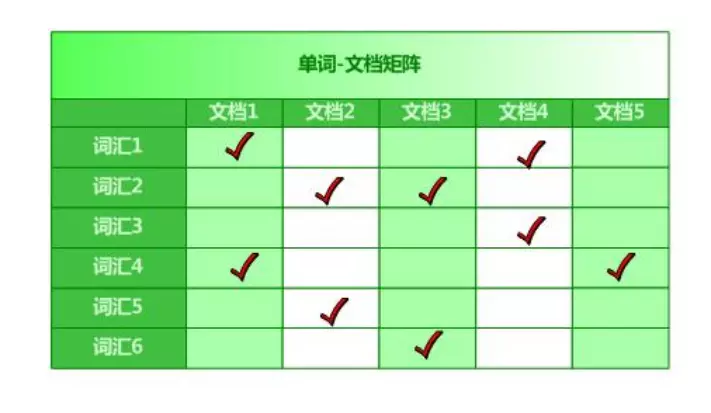
什么是倒排索引?
经过Lucene分词之后,维护一个类似于“词条—文档ID”的对应关系,当我们进行搜索某个词条的时候,就会得到相应的文档ID。不同于传统的顺排索引根据一个词,知道有哪几篇文章有这个词。
elasticsearch中文档自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串,这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。
- elasticsearch中整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。 批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。 但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
- 幸运的是,很容易找到这个 最佳点 :通过批量索引典型文档,并不断增加批量大小进行尝试。 当性能开始下降,那么你的批量大小就太大了。一个好的办法是开始时将 1,000 到 5,000 个文档作为一个批次, 如果你的文档非常大,那么就减少批量的文档个数。密切关注你的批量请求的物理大小往往非常有用,一千个 1KB 的文档是完全不同于一千个 1MB 文档所占的物理大小。 一个好的批量大小在开始处理后所占用的物理大小约为 5-15 MB。
- 个性化分词
- cianel阿里的主从同步
- es操作单独抽出来做一个服务,使用类似主从同步的原理不将更新es的操作嵌入到业务代码中去,而是拉取mysql数据库的binlog来同步数据
- minIO集群—->文件系统
- 处理消息,消息中间件
- docker笔记
- docker的windows操作台
- 地图前端页面,前端页面—->地图组件
- Windows Subsystem for Linux(简称WSL)
- 剖析mapping:一个mapping由一个或多个analyzer组成, 一个analyzer又由一个或多个filter组成的。当ES索引文档的时候,它把字段中的内容传递给相应的analyzer,analyzer再传递给各自的filters。
- 装专业版的docker,不装企业版的,社区版也不行
- es中聚合搜索的开关打开
- IK分词器(设置head)—->个性化分词

若有收获,就点个赞吧
0 人点赞
