- Kafka:topic、partition
- RocketMQ:broker、topic、queue
- Kafka:单机或者分布式——>分布式协调zookeeper
- 为了保证有序性,有序的消息一定要放到同一个partition中去
- 两种结构模式:
- 主主:之间互相商量
- 主从:由一台leader或者controller控制
- Kafka决策选主controller的时候会用到zookeeper,所有的broker都会注册到zookeeper中去,谁先抢到锁,谁就称为controller
- 用zookeeper协调选主,选出一个controller,metadata元数据也会放在zookeeper中,各版本有差异,会尽量减少对zookeeper的依赖
- admin-api管理员客户端,admin-api是连接的zookeeper,而生产者和消费者使用的是broker的ip
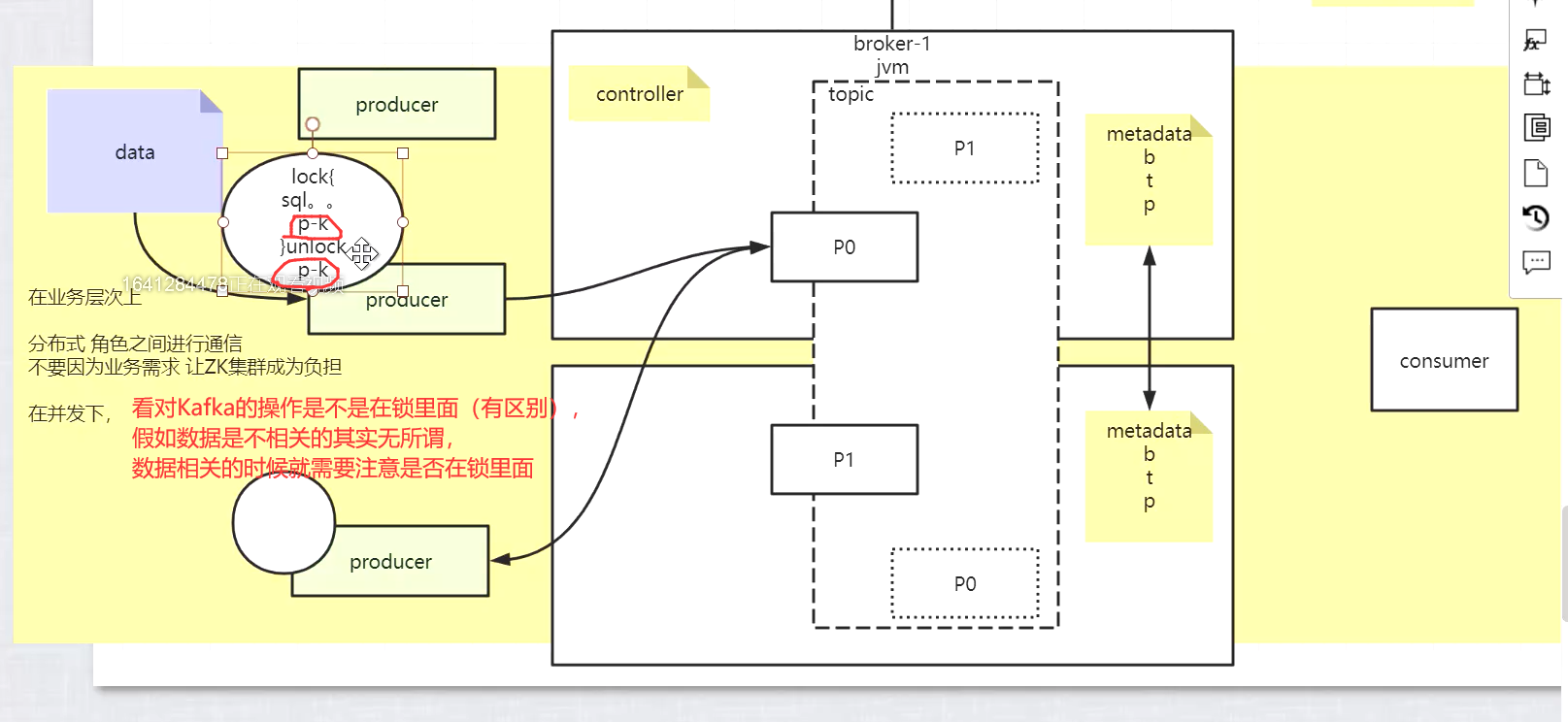
- 亲密性?生产者到broker(亲元性?)
比如说CPU,可以让某一个线程亲密到一个CPU上,比如说路由,将相同的品类的东西,打到同样的机器上面去。负载均衡这里也有亲密性,每次都将同性质的打在一起,减少相同的开销。如果在并发的环境中,通过负载均衡,将一个数据打到一个服务器,后面就依然会在这个服务器。此时就不需要分布式锁了,这就是亲密性的意义。即便请求很多,有多线程,是内存里面的,同一商品在一个io离,也不需要分布式的锁。 ———————————————— 版权声明:本文为CSDN博主「weixin_42127238」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_42127238/article/details/108261207
- 牵扯到并发要注意一致性!!!
- 会靠分区的方法,将无关的打在不同的分区中,而将有关的打在同一个分区中,客户端的api—->主要是靠一个key来完成的,感觉类似hash-tag
- Kafka消费者分组又是一个什么样的概念?
- 不同消费者可以通过加锁来实现对同一个分区的访问,但是这样效率反而更低了—->脱裤子放屁,所以不用一个分区被两个consumer消费的模式
- zookeeper支持持久化存储,zookeeper的持久化存储主要是通过日志的形式进行存储的,因为要主从同步,而主从同步大部分都要通过日志来同步
- 假如zookeeper挂了一般要从主节点恢复数据,也是通过日志(MongoDB可以任意两个节点之间同步)同步到内存
- 选择相关版本的时候的考虑:
- 用得最多的版本
- 依赖的其他的版本 ,比如jdk的版本或者其他的一些版本(Scala、zookeeper……)
- 大的版本变化
- 支持到什么版本?是否是长期支持版本
- zookeeper集群客户端连接的时候会在给出的列表中随机地连接一台,并且客户端有一个fail-over的过程,假如失败会自动寻找另外几台
- 多一个topic是多一个进程吗?不是,他完全是由同一个进程去管理的—->就好比MySQL和Oracle的区别一样,MySQL中每一个数据库都可以在一个连接下开启,但是Oracle中每一个数据库都是一个单独的实例
- 一个什么中间件有那个安装指引来着???MySQL?redis?mongodb?zookeeper?es?
- Redis的utils目录下有一个install-server脚本可以交互式的安装redis,并且将redis的启动脚本放到init.d目录下—->开机启动—->通过service redis_6379 start启动
- redis视频的第一个视频
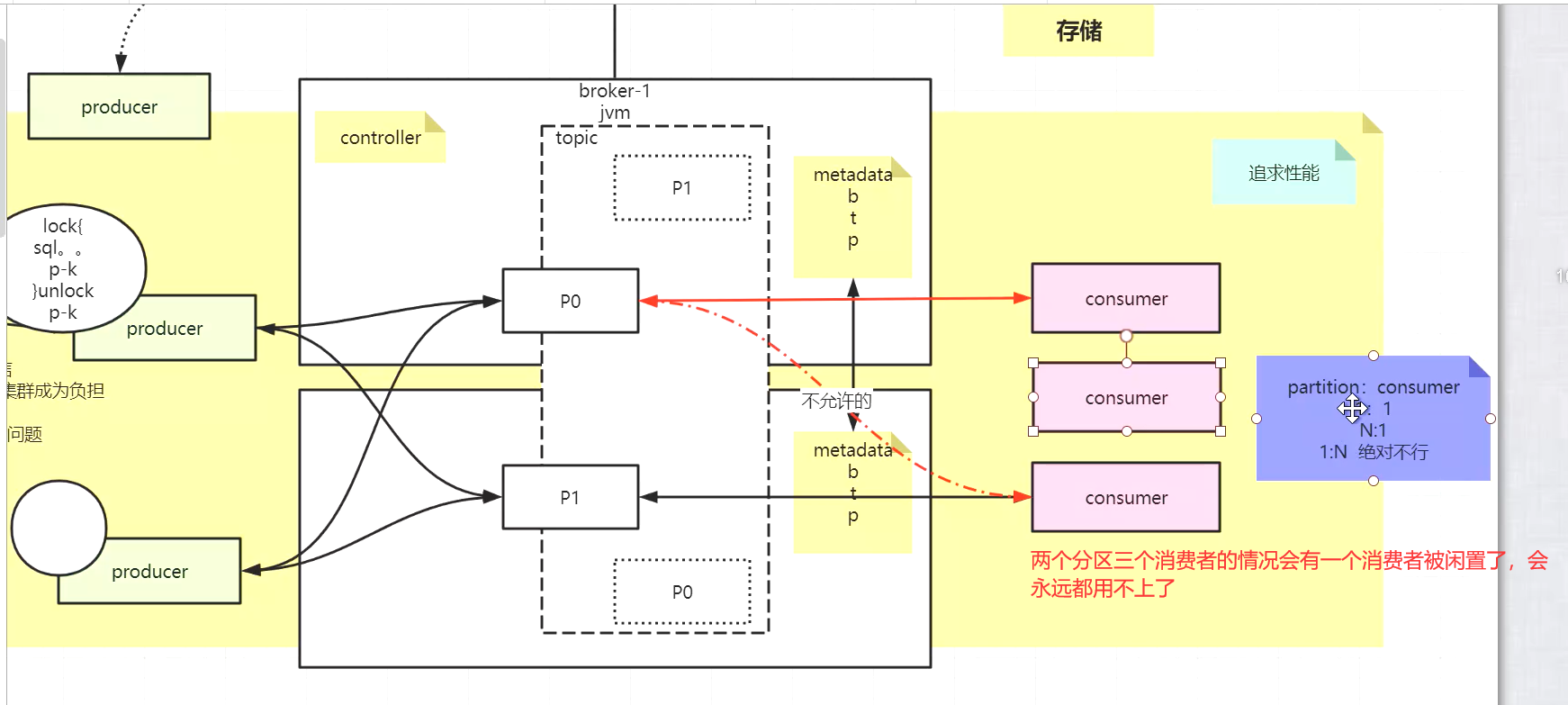
- 消费者有分组的概念,而生产者是没有分组的概念的!—group
- 不是说业务上不能多个consumer消费同一个分区,而是kafka从底层根绝了这种可能会发生的情况,就是说有多个消费者的时候会自动消费不同的分区,否则会空闲下来,就是无法消费该主题下的任何东西;不存在多个消费者消费一个分区时,消费者轮询消费的情况???❓
- 分区是kafka自动分配的
- zookeeper中每一个节点可以是目录,并且还可以在其中放数据
- kafka中有一个存放offset(一个分组对应一个offset)的一个topic,并且这个topic下面有50个分区
- 分区与消费者consumer是自动分配的,不会有两个consumer对应一个分区并且他们是交替轮询消费的情况
- 顺序上没有约束是水平扩展—->加机器只是为了提升并行度
- kafka中的分区key有点类似于mapreduce中的map的分组,只不过map会严格分组,而kafka即便在同一个分区中,也可能有不同key的消息,是交叉的
- 总-分-总的架构模式
- 前面生产者往往都是用一些插件来完成的,类似于redis的推特、predxy等代理,或者mysql-proxy和变形虫……
- 几种类型的consumer:
- 不要使用之前的结果,但是后面接的服务或者数据库要保证数据的有序
- 要使用之前的结果!类似于线程的同步、合作
- 不存在顺序性,只是加个头或者其他的一些东西
- 推送v.s拉取
- 拉取的时候,server不拒绝、不主动、不负责,但是要得知拉取的是哪条数据
- 推送是一个伪命题,当消费者来不及消费的时候,server会暂停推送—->server还要保存消费者的状态
- 拉取的粒度(颗粒度):
- 一条
- 一批
- 类似于TCP滑动窗口的一个思想,发一个窗口,只要收到某一个确认,那么就代表这之前的都收到;否则只能发送一条等待一条的确认(ack)
- 批次处理优过单条处理,与操作系统中的局部性原理(时空)有异曲同工之妙
- 批次处理的实时性稍微低一点
- 批次的粒度!!!
- consumer拿到一个批次之后是单线程处理还是多线程处理!!!应该如何处理批次的数据?offset应该如何维护?
- spring中的事务和数据库中事务有什么区别
- 在一个分区(一个consumer)中,中间完成,两边失败了,怎么去维护这个offset?
- 因为要么会造成数据丢失,要么会造成数据重复消费
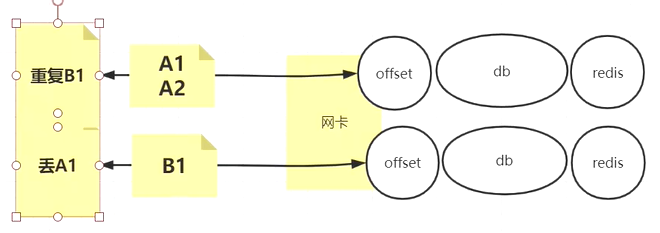
- 多线程按批?单线程按条?
- 单事务是什么?—->使用单事务会把A1、A2线程集又割裂到记录集了,并且最终两个线程还得加锁,最终顺序决定要将offset更新为什么—->这样复杂度太高了
- 单事务就相当于多线程同步成串行执行,没有意义,还不如直接单线程(多线程反而增加了线程间切换的开销)
- 减少事务其实是减少数据库的压力!!!
- DB一般是整个系统中最大的瓶颈,整个系统中不只有kafka,还有redis、db等一系列的东西
- 既要追求隔离性,又要追求减少事务!!!
- 减少事务—->🌟追求减少网络IO,优化其他人的网卡IO和其他的算力分摊上—->这种情况下会出现上述的一系列问题
- 线程是隔离的,用线程用的就是隔离性;什么时候多线程的性能才能被发挥出来?
- 什么时候多线程的性能才能被发挥出来?最大化?发挥到极致?
- 具备隔离性
- 彼此独立
- 没有锁、队列这些事的干扰
- 线程级表示线程级别的就是说一个线程中对应一个事务,这个线程要么成功要么失败
- 记录级是线程中的每一条记录都包裹一个事务,这样加的锁就更多了,会降低效率!(A1、A2各有各的事务;A1、A2共用一个事务);多线程的情况下,又要加入记录级的判定顺序,决策更新谁的offset
- 记录级提交的时候,不光要线程之间同步,还要更小的记录级别的同步
- zookeeper分布式协调—->两阶段提交
- 线程之间相互依赖对方的computeFuture(计算结果),多线程之间的computeFuture
- spark是分布式的、多分区的;spark是一个消费者consumer,更新数据库的话也是存在数据重复消费或丢失的问题;分区的概念可能出现的问题,分区的概念比较大(类似对比)
- 响应式编程:
- 更新redis,更新数据库,更新offset这三件事不应该全部并行起来—->先把db和offset这件事拆出去
- 线程级事务的话,线程是并行的,事务是并行的,很难纠正到底是以哪一个东西来决定这个批次—->kafka是按批次来拉取的,也是按批次处理数据的,spark也是按……
- 到底按什么东西来决定批次
- 多线程的方式,把资源统一利用
- 流式计算的时候,有些地方可以是多线程的,有些地方必须是单线程的,在流式计算中就是这样的—->该并行的并行,该收敛的时候收敛,不然维护事务的话太难了,要加锁加什么各种
- 响应式编程—->流式计算!!!
- Trade-off权衡!!!架构师该做的就是这个—->权衡,思路决定出路!(两全相害取其轻者)—->balance
- 双写一致性本来就是一个伪命题
- 最后要看的是集群的吞吐和性能表现
- 将多条sql合并成一句可以降低IO次数,提升整个系统的吞吐量!
- 单线程的情况下记录的精确控制比较好,多线程流式计算的情况下的粒度就比较粗了
- 图中的redis是查数据而不是写数据,暂时不涉及双写一致性的问题
- 更新数据库成功之后才能更新offset,其实他们的事务没有太大的联系
- 数据库没有更新成功,不会更新offset
- 数据库更新成功但是offset更新失败,可以在数据库中做幂等或者一些其他的补偿性的操作(忽略拜占庭问题?不能吧,但是这种情况出现的可能性实在太低了,基本为0),机房炸掉了概率几乎没有但是他们之间出现网络问题的概率可能高一些,假如失败了多请求、重试几次就行了!!!再加上try……catch……,搞个兜底的机制,下次再来的时候直接从兜底的位置开始判定,直接从第三方取offset兜底的位置,绝对能取回正确的位置—->心跳重试
- 说实在,最后肯定是单线程,单线程肯定用得是最多的,只要重启、重试的时候程序能找到、取到offset就行了
- offset要进行持久化才行,这样消费者断开连接之后再去连接才会从上次中断的位置继续向下消费而不是重新消费之前消费过的数据(重复消费)
- 延时提交offset时提交的意思是持久化offset到硬盘上
- 一个运行的consumer,那么自己会维护自己消费进度;一旦你自动提交, 但是是异步的
- 还没到时间,挂了,没提交,重起一个consumer, 参照offset的时候, 会重复消费
- 一个批次的数据还没写数据库成功,但是这个批次的offset被异步提交了,挂了,重起一consumer,参照offset,会丢失消费
- 上面的挂了指消费者挂了或者kafka服务器挂了???
- 假如数据不那么重要,允许丢失或者重复消费,那么就可以使用offset异步的自动提交(也可以设置延时提交);否则还要使用事务进行同步的offset提交持久化
- 运行时的一个配置项:允许并行运行
- 🌟流式计算的方式
- kafka中offset是按什么去更新维护的?
- kafka中的offset是按分区去维护的,分区是offset的最小划分单元,而不是topic

若有收获,就点个赞吧
0 人点赞
