- 对于数组中的工具类是Arrays
- 对于集合中的工具类是Collections
- 对于线程池中的工具类是Executors—->线程池的工厂
- Executors可以看成是线程池的一个工厂,用来产生各种各样的线程池
- 线程池默认的拒绝策略:在任务不能再提交的时候,抛出异常,及时反馈程序运行状态—->AbortPolicy
SingleThreadPool
- 继承自AbstractExecutorService类
- SingleThreadPool中只有一个线程,可以保证扔进去的线程是顺序执行的
- 可以保证线程执行的顺序
- 为什么要有单线程的线程池(自己new一个Thread不就行了吗?)
- 线程池有任务队列,假如自己new Thread,还要自己构造一个任务队列,自己去维护,加大了工作量
- 单线程的线程池有完整的生命周期管理,自己new还得自己慢慢new
- 线程池将Thread进行了封装,用起来更方便
- 源码是如何new该线程池的?
- 在new的过程中,先new了一个线程池对象,然后给这个线程池对象加了一层包装
- 包装的作用见下:帮助进行垃圾回收的;为了将第一个线程的线程池的生命周期定义死
- 最终都是ThreadPoolExecutor来实现
- 这个谈不上keepAliveTime,因为他永远不会消失,核心线程默认的情况下不会被回收掉,所以这个参数和下面那个参数没有实际意义
- ❓这个线程池,可以用单线程向里面放任务????
- 阿里手册是不建议用jdk**自带的实现**来定义线程池的
- 可以自定义线程的名称
- 因为阻塞会太多(阻塞队列以Integer.MaxValue为上界),阻塞的任务越积越多,很有可能会OOM
- 因为执行中的线程会太多
- 假如到了上界后,可能会使用jdk默认的拒绝策略,但是**那些默认的拒绝策略一般不会在生产环境中使用**,一般要自定义拒绝策略
- 像阿里、京东这种体量的公司,任务量极有可能会达到这个最大值(不能说一定,是非常有可能的,秒杀来的时候一堆的对象拥过来,一个线程处理不过来,就会堆过来,越堆越多,会达到Integer的最大值,是会满的)
- cs

package com.mashibing.juc.c_026_01_ThreadPool;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class T07_SingleThreadPool {public static void main(String[] args) {ExecutorService service = Executors.newSingleThreadExecutor();for(int i=0; i<5; i++) {final int j = i;service.execute(()->{System.out.println(j + " " + Thread.currentThread().getName());});}}}
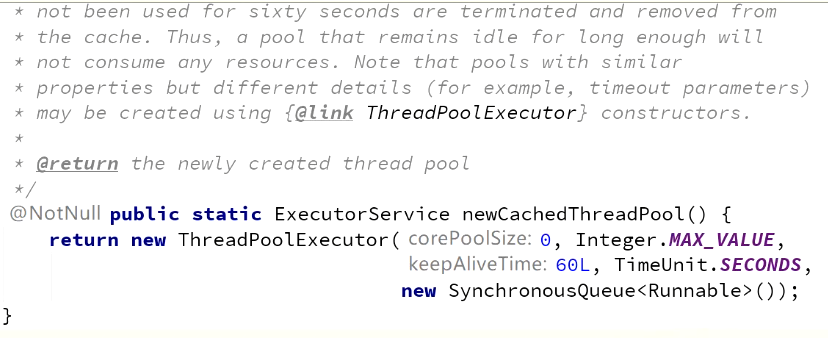
CachedPool
- 特点:来一个任务,就给他起一个线程;当线程池中有线程存在的时候,还有没有到达60s的回收时间的线程存在,即有线程存在的时候,就利用现有的线程;但是当新任务来的时候,所有线程都正在忙着,就起一个新的,不等待。直到上界!
- 因为阻塞队列是SynchronousQueue
() ; - 来一个新的任务必须马上执行,没有线程空着,就new一个新的线程
- 阿里不建议使用该线程池,因为线程数可能起的会非常非常多,线程数基本接近于没有上界
- 一旦线程达到这个级别,cpu会浪费大量时间在线程之间的切换上面,会造成效率非常低
- cpu基本都花在线程之间的切换上,不干别的了(cpu、内存飙升—->jstack查看jvm内部运行信息)
- 一般不会用这样的线程池,当你可以肯定线程不会堆积,不会起太多线程的时候可以用这个线程池(出问题—->领导谈话)
- dd
package com.mashibing.juc.c_026_01_ThreadPool;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.TimeUnit;public class T08_CachedPool {public static void main(String[] args) throws InterruptedException {ExecutorService service = Executors.newCachedThreadPool();System.out.println(service);for (int i = 0; i < 2; i++) {service.execute(() -> {try {TimeUnit.MILLISECONDS.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName());});}System.out.println(service);TimeUnit.SECONDS.sleep(80);System.out.println(service);}}
FixedThreadPool
- 指定一个参数,表示到底有多少个线程
- 核心线程和最大线程都是固定的,那么线程就全都是核心线程,故也没有回收之说
- 在阿里工作,看到LinkedBlockingQueue要小心,这是他不建议用的,因为会堆积太多,造成OOM的异常,或者超过阻塞队列的最大容量会使用你不希望使用的拒绝策略

什么时候用CachedThreadPool?什么时候用FixedThreadPool?
- 线程数量问题,要预估并发量,到底线程池中起多少个线程?

- 很难精准定义一个任务应该用多少线程,一般情况下很多人是用一个经验值设好进行压测,在高并发的场景中,压测是少不了的—->测试专业:性能测试(压力测试)、测试开发(测开)
- 测试团队会模拟各种各样的高并发场景对程序进行压测,如果达不到预期的需求,再调整之前设置的线程数
- 公式很难计算,运用到实际中去是很难的,知道公式也很难去运用!
- 可以用公式预估,然后用预估结果作为初值,**进行压测**!!!
- 根据压测结果进行调整!!!
- 线程是要占用cpu资源的,当某一个线程执行的时候发生了等待,这时候别的线程就可以占用cpu了,线程之间竞争抢占cpu
- 就算用了这个公式,在实战上线之前依然需要进行强力的压力测试,达不到要求还得调!!!
- 有人说实际中好像用的都是cpu核数,cpu用到100%,基本是cpu密集型的,没有io密集型的
Cached vs. Fixed
- 假如任务来的时候忽高忽低,不平稳,但是我要保证来了就要有人做这个事,就可以用Cached
- 保证任务不堆积,用Cached
- 假如任务来的比较平稳,大概都是这个量,不断的量,可以估算出一个值(比如8),完全可以处理,就可以new8个线程扔在这就行了
- 阿里是两个都不用,自己进行估算(多少个线程能够进行处理),估算好了进行精确的定义
ScheduledThreadPoolExecutor
- 里面的任务都是隔多长时间之后可以执行的任务
- DelayedWorkQueue();
- 这个线程池用得不多
- 简单的用jdk里面的Timer
- 复杂的用定时器框架
- 定时任务线程池
- 定时器框架:quartz、cron(涉及到shell脚本,写起来可能会费劲,但很强大)
- 这是一个专门给定时任务用的线程池
- 有个很好用的方法:隔多长时间执行一次任务service.scheduleAtFixedRate(()->{});可以灵活地对时间进行控制
- 因为MaximumPoolSize依然为Integer的最大值,所以在阿里依旧不能用!!!


package com.mashibing.juc.c_026_01_ThreadPool;import java.util.Random;import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.TimeUnit;public class T10_ScheduledPool {public static void main(String[] args) {ScheduledExecutorService service = Executors.newScheduledThreadPool(4);service.scheduleAtFixedRate(()->{try {TimeUnit.MILLISECONDS.sleep(new Random().nextInt(1000));} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName());}, 0, 500, TimeUnit.MILLISECONDS);}}
面试题:假如提供一个闹钟服务,订阅这个服务的人特别多,有10亿人,该怎么优化?
(阿里)
- 开放题,没有标准答案
- 一鸣的亿级流量的前置知识
- cg?nginx
- 思想就是把定时任务分发到边缘的服务器上去(一台不够的话)
- 每一台服务器上每天的定时任务很多,在一台上的优化—->一个队列存着这些任务,一堆的线程去消费,也是要用线程池的
- 大的结构上要用分而治之的思想,主服务器同步到边缘服务器,在每一台服务器上用线程池+任务队列
总结:上面的四种线程池全部用的是ThreadPoolExecutor

若有收获,就点个赞吧
0 人点赞
