程序问题引入
/*** volatile 关键字,使一个变量在多个线程间可见* A B线程都用到一个变量,java默认是A线程中保留一份copy,这样如果B线程修改了该变量,则A线程未必知道* 使用volatile关键字,会让所有线程都会读到变量的修改值* <p>* 在下面的代码中,running是存在于堆内存的t对象中* 当线程t1开始运行的时候,会把running值从内存中读到t1线程的工作区,在运行过程中直接使用这个copy,并不会每次都去* 读取堆内存,这样,当主线程修改running的值之后,t1线程感知不到,所以不会停止运行* <p>* 使用volatile,将会强制所有线程都去堆内存中读取running的值* volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized** @author mashibing*/package com.mashibing.juc.c_001_01_Visibility;import com.mashibing.util.SleepHelper;import java.io.IOException;public class T01_HelloVolatile {private static volatile boolean running = true;// 没有volatile的时候主线程中对running的设置不起作用,而加了volatile之后会起作用// 牵扯到线程的可见性问题// private static /*volatile*/ boolean running = true;private static void m() {System.out.println("m start");while (running) {//System.out.println("hello");}System.out.println("m end!");}public static void main(String[] args) throws IOException {new Thread(T01_HelloVolatile::m, "t1").start();SleepHelper.sleepSeconds(1);running = false;System.in.read();}}
图解
- r位于主内存中,两个线程(t1会读、主线程隔一秒后会改)都会用到r
- t1读的是r的拷贝,t1将内存中的r拷贝一份放到线程本地(是线程缓存而不是ThreadLocal),每一次读的r并不是去主内存读,而是读的自己本地的缓存;主要缓存中的值没人改过,或者没有去主内存读,读到的都是之前的值,线程不会主动地去主内存中读(不hi是每次循环都要去主存中读一遍);每次读只是读的本地的
- 主线程1s后会将主线程本地缓存中的r改为false,但是由于t1不会从主内存中重新读,所以改了不会有影响,所以t1停止不了

线程可见性的基本概念(volatile)
- 一个线程改了值之后,另一个线程是不是能见到最新被修改的值
- 默认情况下,一个线程改了,另一个线程看不到
- 想要让他看见,只要让running值用volatile修饰
用volatile保障可见性
- volatile的第一个作用:保证线程的可见性
- 在上图中,volatile修饰的内存r,对于他的任何修改对其他线程立即可见===>线程读r时(每次要用到r时),每次都去主内存中去读一遍;而修改的线程修改之后会立马刷新到主内存中去(读的线程立马可见)
- MESI协议(不同cpu采用不同的缓存一致性协议,MESI只是缓存一致性协议中的一种)===> 只是类似,实际上与volatile没有什么联系(与volatile放一起就有点问题了)===>详见下面缓存行中没有volatile时的缓存一致性???
- 不是一定要volatile类型的数据才会产生问题
- 一个是程序角度上的同步volatile,一个是操作系统CPU角度上的缓存一致性协议???
某些其他语句触发内存缓存同步刷新(能做到与volatile相同的效果)
- 在上面代码中m方法的while循环中添加一个打印语句===>running变得可见了
- System.out.println(“hello”);触发了可见性机制
- System.out.println();方法中有一个synchronized,synchronized也是可以保证可见性的===>在某些语句执行的情况下,可以触发线程本地缓存与主内存之间的数据刷新和同步的
- 每个里面加sout?不要这样做,每加一个sout就相当于上了一把锁,效率会变低
- 不能用sout这种笨拙的方法保证可见性,该用volatile还是用volatile
private static void m() {System.out.println("m start");while (running) {System.out.println("hello");}System.out.println("m end!");}
volatile修饰引用类型(包括数组)
- 只能保证引用本身的可见性,不能保证内部字段的可见性
- volatile修饰引用类型时,内部字段在线程的本地缓存中仍然是不可见的,修改内部字段不会同步刷新
- volatile修饰引用类型时,只有在该引用指向了另外一个对象时,线程本地中的引用也会同步刷新===>就是说这个引用变量是可见的,但是引用所指向的对象的内部字段仍然是不可见的;内部字段r仍然处在线程本地缓存中
- 想让内部字段在线程本地内存中可见,在内部字段前面加volatile,而不是在引用变量前面加volatile
- volatile修饰引用类型相对较少,一般只存在于面试题中(了解即可)
- 尽量避免使用volatile关键字修饰引用变量。
- ”双缓冲+引用赋值“的方法
- 加锁
/*** volatile 引用类型(包括数组)只能保证引用本身的可见性,不能保证内部字段的可见性*/package com.mashibing.juc.c_001_01_Visibility;import com.mashibing.util.SleepHelper;public class T02_VolatileReference {private static class A {boolean running = true;void m() {System.out.println("m start");while (running) {}System.out.println("m end!");}}private volatile static A a = new A();public static void main(String[] args) {new Thread(a::m, "t1").start();SleepHelper.sleepSeconds(1);a.running = false;}}
CPU的三级缓存
cpu三级缓存存取周期对比

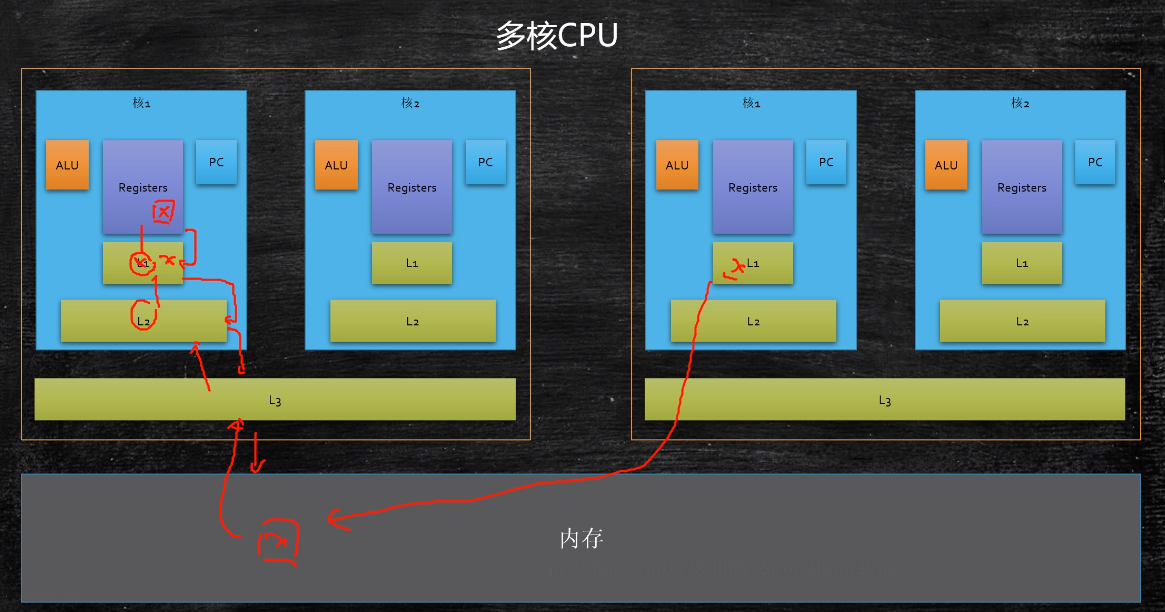
多核cpu中(三级)缓存的位置
- 机箱中有好几颗cpu,核中有好几个核(下图中有两颗cpu,每颗cpu中有两个核)
- L1缓存和L2缓存都位于核的内部,L3缓存在这颗cpu的内部
- 寄存器需要变量x,首先会去L1中找,如果L1没有回去L2找,如果L3没有会去L3找,如果L3没有会去主存中找;读数据时,首先往L3中存一份,再往L2中存一份,然后往L1中存一份,最后读到寄存器中去
- 上面说的线程的缓存的可见性主要是L1和L2中的x和其他核甚至其他cpu中读的同一个x的可见性(可以有好几层的可见性)===>而不是ThreadLocal
缓存行
- 不是每一个数据需要多长就将多长的数据放到各级缓存中,为了让内存(io)效率更高,读取的时候往往是按照一块一块来读的(一读就是一整块,时空局部性原理)
- 按块读取===>一整块的读取到缓存中,这一块数据有多大===>一次性读取的数据叫做缓存行
- 程序局部性原理,可以提高效率
- 程序读数据的时候,相邻的数据很快就能读到(读一个值的时候,与他相邻的值也会很快就用到)===>空间局部性原理(读数据)
- 程序读指令的时候,很快相邻的指令也会用到(读指令的时候一次性将很多相邻的指令也读到缓存或者内存中)===>时间局部性原理(读指令)
- 充分发挥总线cpu针脚等一次性读取更多数据的能力
- cache line:在内存中任何数据的组织都是按照一行一行来组织(或者一块一块来组织),读的时候都是一整块一整块的读进来
- 缓存行的大小:64byte
- 64byte的原因:
- 缓存行越大,局部性空间效率越高(命中率高),但读取时间慢
- 缓存行越小,局部性空间效率越低(命中率低),但读取时间快
- 取一个折中值,目前多用:64字节
- 工业实践中得出的最佳实践
- 图解

缓存一致性协议(缓存行的应用)(骨灰级别的程序调优的写法)
package com.mashibing.juc.c_001_02_FalseSharing;import java.util.concurrent.CountDownLatch;public class T01_CacheLinePadding {// 循环10亿次public static long COUNT = 10_0000_0000L;private static class T {//private long p1, p2, p3, p4, p5, p6, p7;// 一个long类型8byte===>一个缓存行64byte===>8个long填满一个缓存行=public long x = 0L; //8bytes//private long p9, p10, p11, p12, p13, p14, p15;}public static T[] arr = new T[2];static {arr[0] = new T();arr[1] = new T();}public static void main(String[] args) throws Exception {CountDownLatch latch = new CountDownLatch(2);Thread t1 = new Thread(() -> {for (long i = 0; i < COUNT; i++) {arr[0].x = i;}latch.countDown();});Thread t2 = new Thread(() -> {for (long i = 0; i < COUNT; i++) {arr[1].x = i;}latch.countDown();});final long start = System.nanoTime();t1.start();t2.start();latch.await();System.out.println((System.nanoTime() - start) / 100_0000);}}
- 将第10行与第13行的注释打开(即在T中x的前后各多定义7个long类型的变量)
- 发现用的时间提升了,变快了,效率变高了(700+ns—->200+ns)
- 上述代码与volatile无关,加不加volatile都会有效率上的区别
- 出现这种现象的原因:
- 当前后没有填充的时候,x和y大概率地是位于同一行(同一缓存行)
- 在上图中,因为x和y位于同一行,虽然左边的计算单元与寄存器单元只访问x,但是x和y会被全部缓存过来;右边的计算单元与寄存器只访问y,但是x和y也会全部缓存过来
- 既然一行数据同时在cpu1和cpu2中,必须采用某种机制保存两者的数据一致性===>数据一致性协议(一边的缓存行失效了或者被更改了,和另外一边的缓存行之间就要保持一致)
- 机制:一边修改了,就要通知另一边:我这边修改了或者失效了,你要重新从内存中刷新一遍新的数据过来
- 因此,有缓存一致性协议的存在就导致花了额外的时间,造成效率低
- 而加了前后各7个填充之后,两个数据x和y必然不处于同一行,每个cpu只需要读自己需要的那一行即可(这次读的包含x的行中不含有y,包含y的行中不含有x),这样就不需要做通知和同步,省了通知和同步的时间,提高了效率
- 缓存行(缓存一致性协议)与volatile没有什么特殊的联系
- MESR协议(缓存一致性协议)与volatile===> 只是类似,实际上与volatile没有什么联系(与volatile放一起就有点问题了)
- 不是一定要volatile类型的数据才会产生问题
- 一个是程序角度上的同步volatile,一个是操作系统CPU角度上的缓存一致性协议???
- volatile与缓存行的概念没有半毛钱的关系
上述缓存行对齐运用的实际程序
- jdk1.7的源码道格李的linked blocking queue类中运用了这种写法===>填充
- Disruptor框架===>闪电(速度快)(交易所的开源框架,得过计算机界杜克奖)
- 目前为止,效率最高的mq(单机版的)消息队列
- 消息缓存===>一般指字节数组(头尾指针、位置指针……)
- mq的缓存时环形的缓冲区(ring buffer),只有一个指针(在那转)
- 通过CAS和cache line padding(缓存行对齐)提高了效率
- 具体的内容之后会有

Contended注解
- 手动添加变量不方便,而且可能面临缓存行大小的变化(目前为64byte,一行可以存放8个long类型的变量(每个8byte))
- 缓存行变化,填充的大小不用变===>oracle在jdk1.8时提供了一个注解,保证被他标注的数据不会和其他的数据为同一行
- 添加注解后,效率大幅度上升(700+ns—->200+ns)
- 要想让注解生效起作用,要在jvm运行行参数中添加参数:-XX:-RestrictContended(默认情况下,该注解是被限制住的,不会起作用,要用参数将其打开)上面的参数第二个横线为减号,表示去掉Contended限制(设为false的意思)
- 这个注解用的很少,写jdk内部类时会用(会的人也少);1.9之后就不起作用了,只有1.8起作用
- 尽量别这样用===>追求效率还没有达到这种骨灰级的程度(属于走火入魔了)===>以后哪一天写自己的SDK可能会用的上!
package com.mashibing.juc.c_001_02_FalseSharing;import sun.misc.Contended;//注意:运行这个小程序的时候,需要加参数:-XX:-RestrictContendedimport java.util.concurrent.CountDownLatch;public class T05_Contended {public static long COUNT = 10_0000_0000L;// 要想让注解生效起作用,要在jvm运行行参数中添加参数:-XX:-RestrictContended@Contended //只有1.8起作用 , 保证x位于单独一行中private static class T {public long x = 0L;}public static T[] arr = new T[2];static {arr[0] = new T();arr[1] = new T();}public static void main(String[] args) throws Exception {CountDownLatch latch = new CountDownLatch(2);Thread t1 = new Thread(() -> {for (long i = 0; i < COUNT; i++) {arr[0].x = i;}latch.countDown();});Thread t2 = new Thread(() -> {for (long i = 0; i < COUNT; i++) {arr[1].x = i;}latch.countDown();});final long start = System.nanoTime();t1.start();t2.start();latch.await();System.out.println((System.nanoTime() - start) / 100_0000);}}
硬件层面上的缓存一致性
- 缓存一致性协议不要和MESI这个概念混淆,不同的cpu可能有不同的缓存一致性协议(MSI、MOSI、……),MESI是intel CPU设计的,所以更有名
- 主动性的更新数据,会主动监听,只要一边改了,另一边就会得到通知说那边改了,下次取的时候就会重新从内存中读一遍
- 这东西跟volatile没关系,任何一种类型的数据都会启动MESI协议
- 网上博客一般将volatile和MESI放一起讲,但是volatile底层不是由MESI实现的
- 这就是硬件层级的原理===>因为有这个协议的存在,才会有上面那种**通过缓存行对齐进行效率提升的方法**(因为要保证缓存一致性就会消耗时间,降低效率)

总线锁是一种重量级的锁,会进一步降低效率
总结
- volatile保障线程可见性(是线程本地缓存,不是ThreadLocal)
- 互相之间保持数据一致性而采取的一种机制
- 和内存中的某些数据保持同步
- volatile可以保障的线程的可见性
- 缓存行
- 缓存的概念(L1、L2、L3缓存)
- 读取时一行一行地读缓存行的内容===>诡异的编程技巧
- 缓存一致性协议
- 多数cpu底层支持缓存一致性协议
- 与加不加volatile没有关系
- volatile(保证可见性和有序性)底层实现的原理:详见有序性之后的volatile原理
附录
SleepHelper帮助类(只是简答地将try……catch……扔到帮助类中)
在演示式的代码中写很多try……catch……,看起来费劲
package com.mashibing.util;import java.util.concurrent.TimeUnit;public class SleepHelper {public static void sleepSeconds(int seconds) {try {TimeUnit.SECONDS.sleep(seconds) ;} catch (InterruptedException e) {e.printStackTrace();}}}

若有收获,就点个赞吧
0 人点赞
