几个接口
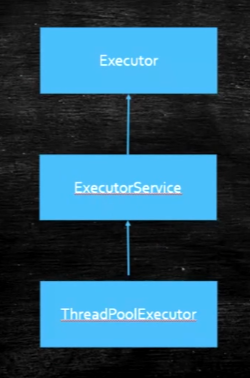

Executor接口
- Executor接口中有一个execute方法,参数为Runnable类型
- 有了Executor接口之后任务的定义和运行就可以分开了,不需要new Thread了
- 本质上还是new Thread,只不过有了很多方式,不用亲自指定每一个Thread,运行的方式可以自己去定义(如何定义?—->如何实现Executor接口)
- 定义和运行分开,可以直接传Runnable或者new Thread再传
- execute是异步的吗?
ExecutorService接口
- 从Executor继承
- 除了可以执行Executor可以执行的任务之外,还完善了整个任务执行器的生命周期
- 如何结束?—->shutdown、……
- 拓展了Executor,实现了线程池声明周期的一些部分
- 真正的线程池就是在ExecutorService接口上实现的
- 有execute,也有submit—->execute是立即执行,而submit是扔给线程池,由线程池决定什么时候运行,是异步的(往里一扔,我就不管了)
- 不管了,那怎么拿到结果(什么时候有结果,怎样拿到结果)—->Future、CompletableFuture、RunnableFuture、FutureTask、……
- submit是异步的—->主线程提交完任务之后,该干嘛就干嘛,主线程不会等待submit执行完返回结果之后才能继续运行
- 什么时候得到结果?—->看Future这个对象中有没有结果,调用get方法,**get方法是阻塞的,直到有结果才会返回**
- 用完线程池之后要调用shutdown关闭线程池,防止资源占用
- execute是异步的吗?—->可以说是异步的,即在线程池中找一个线程去运行他,这时主线程还是可以继续运行的;而submit提交了有结果集返回,execute相当于扔在那就不管了,异步不异步就不管了
- 一般给其他线程发出一个命令不能说是异步,异步一般要求有返回值,是等着还是先去执行其他任务,这个决定了是不是异步!!!
- 发出命令,让别人干一件事,不能叫异步。execute没有什么异步,没有异步的概念
- invokeAll产生一堆的线程,让他产生一堆的结果;invokeAny拿到其中的任何一个,让他产生结果????
- 13用得不多
线程的基础概念
Callable(类似于Runnable,但是可以有返回值)
- 之前只能实现Runnable接口
- jdk1.5之后添加了Callable接口(与Runnable类似,也可以用线程来运行)
- Callable接口中的call方法可以有返回值,而Runnable没有
- 线程将计算结果存起来,什么时候运行结束了,通知一下就行了,不需要像之前调用run之后就在那等着
- 基本上Callable就是为了线程池而设计的,不用线程池的接口,而去写Callable的一些测试程序还是比较麻烦的—->线程池的直接用法
- Callable
代表这个Callable的返回值类型是String类型 - get什么时候有了,什么时候就继续向下运行
Future接口(Callable执行结束之后拿到执行结果的方式)
- 会将Callable的结果封装到一个Future中去
- 与Callable对应,搭配使用
- 未来执行完之后的结果放到Future中去了
- 经常用的是FutureTask
- ExecutorService接口中的submit方法的返回值是Future
FutureTask类(既是一个Future又是一个Task)
- 可以作为一个任务来用
- 并且结果也存在这个对象中了
- FutureTask类实现了RunnableFuture接口,RunnableFuture接口既实现了Runnable,又实现了Future
- 既是一个任务又是一个Future,最终的执行结果存在自己那里
- 可以用Thread也可以用线程池,用起来非常灵活!!!
- 后面还会用—->ForkJoinPool、WorkStealingPool
- Future和Runnable的结合
CompletableFuture(各种任务的管理类)
- 底层很复杂,主要作用是管理多个Future的结果,还可以产生各种各样的异步任务,对各种各样的结果进行组合处理
- 用法非常多,用起来很灵活(会用!!!)
- 底层用的是ForkJoinPool
- 开发的时候用不太上!
- 内部有好多关于结果的组合,组合各种各样不同的任务,等任务执行完之后产生一个结果?(结果进行组合???)
- 提供了任务异步的运行外,还提供了一堆任务执行的管理
- allOf表示都完成了才可以继续向下,anyOf表示其中有一个完成了就可以继续向下
- 比较三家:都拿到才行
- 论文查重:只拿到一家就行
- CompletableFuture是各种任务的管理类
- 可以有lambda表达式的写法
- 有点大数据的感觉—->写大数据的时候会有这种感觉
- 两种写法其实是有冲突的,应该将前后都注释掉,只留中间的;并且要阻塞住,System.in.read();这样才能拿到结果,不然主线程结束了就拿不到结果了???
- 更高级的类,在很高的层面上帮助管理一些想要的各种任务,可以对任务进行一些组合—->所有任务结束or任何一个任务结束
- 提供了链式处理的方法,lambda表达式的写法—->拿到任务之后,任务的结果进行一些什么样的处理(lambda表达式)
- 里面的api超级多,读一读,理解用法就行了—->用的时候去找

情景:比较不同平台同一产品的价格
- 总体要求:所有的Future结束之后才能展示结果
- 普通的顺序执行—->时间太长
- 多线程执行—->要处理每一个线程,要考虑每一个线程的延迟问题、异常问题、……(每一个都get阻塞,什么时候都阻塞完了,再往下运行)
/*** 假设你能够提供一个服务* 这个服务查询各大电商网站同一类产品的价格并汇总展示* @author 马士兵 http://mashibing.com*/package com.mashibing.juc.c_026_01_ThreadPool;import java.io.IOException;import java.util.Random;import java.util.concurrent.CompletableFuture;import java.util.concurrent.ExecutionException;import java.util.concurrent.TimeUnit;public class T06_01_CompletableFuture {public static void main(String[] args) throws ExecutionException, InterruptedException {long start, end;/*start = System.currentTimeMillis();priceOfTM();priceOfTB();priceOfJD();end = System.currentTimeMillis();System.out.println("use serial method call! " + (end - start));*/start = System.currentTimeMillis();CompletableFuture<Double> futureTM = CompletableFuture.supplyAsync(()->priceOfTM());CompletableFuture<Double> futureTB = CompletableFuture.supplyAsync(()->priceOfTB());CompletableFuture<Double> futureJD = CompletableFuture.supplyAsync(()->priceOfJD());// 里面的所有任务都完成之后,才能继续运行--->joinCompletableFuture.allOf(futureTM, futureTB, futureJD).join();CompletableFuture.supplyAsync(()->priceOfTM()).thenApply(String::valueOf).thenApply(str-> "price " + str).thenAccept(System.out::println);end = System.currentTimeMillis();System.out.println("use completable future! " + (end - start));try {System.in.read();} catch (IOException e) {e.printStackTrace();}}private static double priceOfTM() {delay();return 1.00;}private static double priceOfTB() {delay();return 2.00;}private static double priceOfJD() {delay();return 3.00;}/*private static double priceOfAmazon() {delay();throw new RuntimeException("product not exist!");}*/private static void delay() {int time = new Random().nextInt(500);try {TimeUnit.MILLISECONDS.sleep(time);} catch (InterruptedException e) {e.printStackTrace();}System.out.printf("After %s sleep!\n", time);}}
线程池类型
- 目前jdk提供了两种类型的线程池:ThreadPoolExecutor 和ForkJoinPool
- 是两种不同的线程池,能干的事情不一样
- ForkJoinPool 用于分解汇总的任务 ,用很少的线程可以执行很多的任务(子任务) TPE做不到先执行子任务 ,适合于CPU密集型的任务(forkjoin的概念—->分岔之后再进行汇总)
- fork是分岔的意思,分岔之后再分岔
- join是汇总的意思,将分布的结果进行汇总计算
- nasa的寻找外星人计划,数据不算泄漏,只有一少部分,不可能获取到汇总的数据(算力制约影响更大)
ThreadPoolExecutor
- 继承自AbstractExecutorService抽象类
- 相当于是线程池的执行器,可以向线程池中提交任务,让线程池去运行
- 阿里的手册中要求线程池要自定义!!!
自定义线程池(7个参数!!!)
- 面试中的7个参数
- 维护了两个集合:线程集合(HashSet实现的)和任务队列
- sdsd
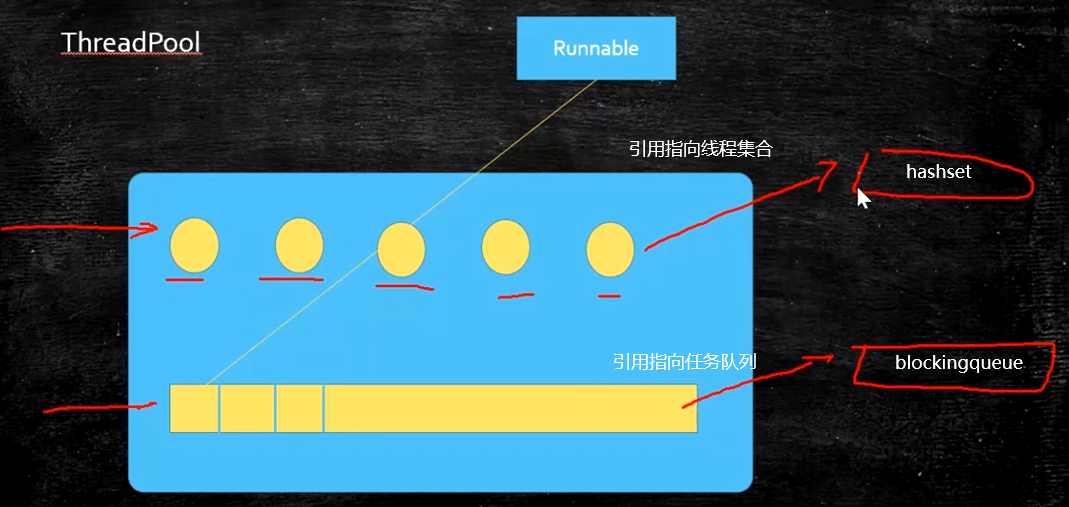
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数
- keepAliveTime:生存时间,没活干将线程归还给操作系统,让os给别人去用这个线程资源(不归还的话消耗也非常大)—->核心线程是不归还的,永远活着,这里面是有参数是可以指定的(核心线程参不参与线程的归还,一般不去指定他)
- 生存时间的单位
- 任务队列:可以用各种各样的BlockingQueue,可以指定等待队列中最大等待的任务数(ArrayBlockingQueue、LinkedBlockingQueue)
- LinkedBlockingQueue不是无界队列,他的最大值是Integer的最大值,说无界队列不精确
- LinkedBlockingQueue不能一直往里面扔直到内存崩了为止,超过最大值也就满了
- 用jdk中默认的阻塞队列
- 用synchronousQueue时队列中一个任务都放不了,必须来一个执行一个,往下执行
- transferQueue也可以用,delayQueue、……
- 线程工厂(产生什么样的线程,线程名叫什么)
- 产生线程的
- 产生线程的方式可以通过自己定义一个工厂来产生自己特定的线程(你想要的线程、业务需求的线程)
- 有默认提供的工厂,如下(设名字,设成非守护线程、设最普通的优先级)

- 在java中不建议对线程优先级进行设置,因为设置了也没有什么用!!!!
- 指定名字很重要,方便出错时回溯!!!—->对阿里来说很重要《阿里开发手册(规范)》
- 如何跟踪线程???—->jvm中可以用命令打印出当前虚拟机中的所有线程,那个线程占用cpu最高、哪个线程产生对象最多这些信息都能知道!!!—->可以使用jstack进行问题排查(阿里吃过亏?🤣)
- 阿里还规定线程资源必须通过线程池提供,不自己new Thread—->有新的接口之后,旧的接口就慢慢不再使用了,只不过旧的用熟了,所以旧接口用得还是比较多的
- 为什么不用Executors去创建而用ThreadPoolExecutor的方式自己定义?
- 为了更加明确线程池的运行规则,规避资源耗尽的风险(OOM)
- 说明: Executors返回的线程池对象的弊端如下(主要是队列的问题):
- 1 ) FixedThreadPool 和SingleThreadPool:允许的**请求队列长度**为Integer.MAXVALUE,可能会堆积大量的请求,从而导致OOM.
- 2) CachedThreadPool:
允许的**创建线程数量**为Integer.MAXVALUE,可能会创建大量的线程.从而导致OOM.(就算不OOM,系统也快崩了)
- 拒绝策略(几种?jdk默认提供了4种,但是我们可以进行自定义)
- 可以自定义,jdk默认提供了四种
- Abort:抛异常,没人处理它,直接抛异常—->new AbortPolicy();
- Discard:扔掉,不抛异常,静悄悄地扔掉,,不执行—->new DiscardPolicy();
- DiscardOldest:扔掉排队时间最久的,扔掉最老的—->new DiscardOldestPolicy();(2被扔出去了,100被加进来了,2最老被扔掉)—->现实中用的很少,也有实际应用—->游戏服务器中游戏物体不断移动,位置不断变化,每移动一下发个位置信息给服务器,服务器会将位置信息的处理任务封装起来扔到一个线程池中去,此时收到新的之后,最老的就没有意义了,这时候可以扔掉最老的任务
- CallerRuns:调用者处理任务,哪个线程调用了线程池的execute方法或提交了任务,哪个线程就去执行这个任务—->new CallerRunsPolicy();
- 上面四种是默认的拒绝策略,实际中基本都不用(用得都很少),只在简单得情形下才用这种策略,一般情况下都是自定义策略—->实现拒绝策略的接口,然后去处理—->处理的方式:消息等要保存下来的时候(比如订单、消息等),保存到kafka,保存到redis,保存到各种mq,或者保存到数据库,并且做好日志,记录下有哪些任务还没有处理,对于实时性要求不高的,什么时候有空闲,再来进行处理
- 当看到日志中有大量任务堆积,还没有处理的话,就说明要加机器了,要加机器性能了,需要大量的消费者将这里面的任务消费光了(因为堆积的太多了) ```java package com.mashibing.juc.c_026_01_ThreadPool;
import java.io.IOException; import java.util.concurrent.*;
public class T05_00_HelloThreadPool {
static class Task implements Runnable {private int i;public Task(int i) {this.i = i;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " Task " + i);try {System.in.read();} catch (IOException e) {e.printStackTrace();}}@Overridepublic String toString() {return "Task{" +"i=" + i +'}';}}public static void main(String[] args) {ThreadPoolExecutor tpe = new ThreadPoolExecutor(2, 4,60, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(4),Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());for (int i = 0; i < 8; i++) {tpe.execute(new Task(i));}// 查看任务队列里的情形System.out.println(tpe.getQueue());tpe.execute(new Task(100));System.out.println(tpe.getQueue());tpe.shutdown();}
}
```
结果:
执行顺序:
- 一开始corePoolSize的大小是2,最开始默认指定的情况下,线程池中一个任务也没有
- 来一个任务起一个线程,假如这个任务执行完了,由于corePoolSize还没到,所以这个线程是不会终止(归还)的,就在线程池中呆着了
- 假如第一个任务没结束就来了第二个任务,那么就会再起一个线程
- 假如第三个任务来的时候,前两个都还没执行完,没空去执行这第三个任务就将其加入任务队列
- 假如任务队列满了,又有新的任务到来,就再起新线程去处理这个任务
- 当任务队列都满了的时候,并且达到maximumPoolSize的时候,所有线程都在执行任务,这时就要执行拒绝策略(线程池忙,任务队列满,这时要执行各种各样的拒绝策略)

若有收获,就点个赞吧
0 人点赞
