Custom DataLoader Example
2) Custom Dataset Class
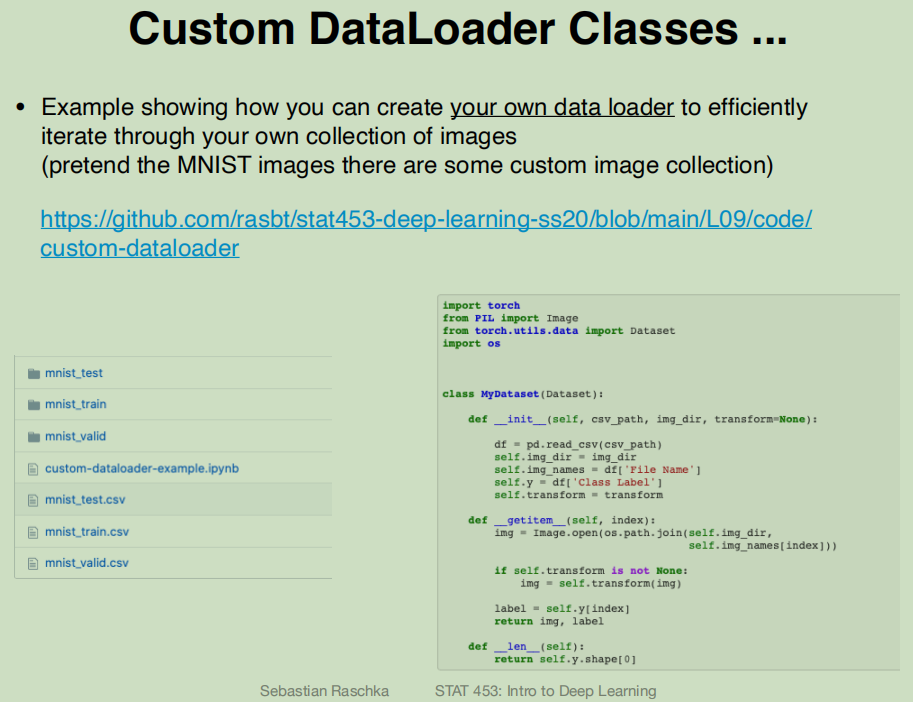
torch.utils.data.Dataset为抽象类
自定义类需要继承这个类,并实现两个函数,一个是__len__(提供数据的大小)另一个是__getitem__(通过给定索引获取数据和标签)
import torchfrom PIL import Imagefrom torch.utils.data import Datasetimport osimport pandas as pdclass MyDataset(Dataset):def __init__(self,csv_path,img_dir,transform=None):df = pd.read_csv(csv_path)self.img_dir = img_dirself.img_names = df['File Name']self.y = df['Class Label']self.transform = transformdef __getitem__(self,index):img = Image.open(os.path.join(self.img_dir,self.img_names[index]))if self.transform is not None:img = self.transform(img)label = self.y[index]return img,labeldef __len__(self):return self.y.shape[0]
通过上面的方式可以定义我们需要的数据类,可以通过迭代的方法来取得每一个数据,但是这样很难实现取batch,shuffle或者多线程去处理数据,所以PyTorch中提供了一个简单的方法来做这个事情
3) Custom Dataloader
__getitem__一次只能获取一个数据,所以通过torch.utils.data.DataLoader来定义一个新的迭代器
from torchvision import transformsfrom torch.utils.data import DataLoadercustom_transform = transform.Compose([transforms.ToTensoir(),transforms.Normalize([0.5],[0.5])])train_dataset = MyDataset(csv_path='mnist_train.csv',img_dir='mnist_train',transform=custom_transform)train_loader = DataLoader(dataset = train_dataset,batch_size = 32,shuffle = True,num_works = 4) # number processes/CPUs to use
- transforms.Compose()可以把一些转换函数组合在一起
- transforms.Normalize([0.5],[0.5])对张量进行归一化,这两个0.5分别表示对张量进行归一化的全局平均值和方差,因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如3个通道,应该是Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
test_loader = data.DataLoader(Test, batch_size=2, shuffle=True, num_workers=2)for i, data in enumerate(test_loader):Data, Label = data
批量读取数据,可以像使用迭代器一样使用它,比如对它进行循环操作
不过它不是迭代器,我们可以通过iter命令将其转化为迭代器
dataiter = iter(test_loader)imgs, labels = next(dataiter)
可视化
def imshow(inp, title=None):"""Imshow for Tensor."""inp = inp.numpy().transpose((1, 2, 0))mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])inp = std * inp + meaninp = np.clip(inp, 0, 1)plt.imshow(inp)if title is not None:plt.title(title)plt.pause(0.001) # pause a bit so that plots are updated# Get a batch of training datainputs, classes = next(iter(dataloaders['train']))# Make a grid from batchout = torchvision.utils.make_grid(inputs)imshow(out, title=[class_names[x] for x in classes])
4) Iterating Through the Dataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")torch.manual_seed(0)num_epochs = 2for epoch in range(num_epochs):for batch_idx, (x,y) in enumerate(train_loader):print("Epoch:",epoch+1,end='')print(" | Batch index:", batch_idx, end='')print(" | Batch size:", y.size()[0])x = x.to(device)y = y.to(device)

若有收获,就点个赞吧
0 人点赞
