https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html https://github.com/aladdinpersson/Machine-Learning-Collection/tree/master/ML/Pytorch/GANs
What is a DCGAN
discriminator
输入是想要的图像输入
— is made up of strided convolution layers, batch norm layers, and LeakyReLU activations
generator
输入是一个噪声的分布,输出是我们想要的图像输出
— The input is a latent vector,z, that is drawn from a standard normal distribution
— The output is a 3x64x64 RGB image.
Inputs
nc - number of color channels in the input images.
nz - length of latent vector
lr - learning rate for training
ngf - relates to the depth of features maps carried through the generator
ndf - sets the depth of feature maps propagated through the discriminator
beta1 - beta1 hyperparameter for Adam optimizers. As described in paper, this number should be 0.5
Data
Implementation
Generator
The generator, G , is designed to map the latent space vector(z) to data-space.
Since our data are images, converting z to data-space means ultimately creating a RGB image with the same size as the training images(i.e. 3x64x64). In practice, this is accomplished through a series of strided two dimenional convolutional transpose layers.
The output of the generator is fed through a tanh functions to return it to the input data range of [-1,1].

Discriminator
Loss function and optimizer
We will use the Binary Cross Entropy loss(BCELoss) function which is defined in Pytorch as :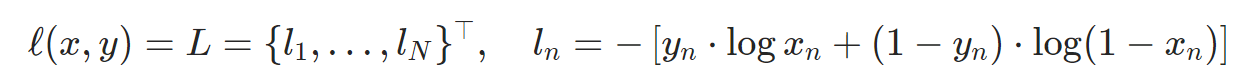
Notice how this function provides the calculation of both log components in the objective function(i.e. log(D(x))) and log(1-D(G(z))). We can specify what part of the BCE equation to use with the y input.
使用BCE loss来计算log成分(通过控制y的值)
Next, we define our real labels as 1 and the fake label as 0. —>用于计算loss
These labels will be used when calculating the losses of D and G, and this is also the convention used in the original GAN paper.
Finally, we set up two separate optimizers, one for D and one for G.
As specified in the DCGAN paper, both are Adam optimizers with learning rate 0.0002 and Beta1 = 0.5.
Training
Be mindful that training GANs is somewhat of an art form, as incorrect hyperparameter settings lead to collapse with little explanation of what went wrong.
part1 — train the discriminator
the goal of training the discriminator is to maximize the probability of correctly classifying a given input as real or fake.
Practically, we want to maximize 
小批次训练的建议
Due to the separate mini-batch suggestion from ganhacks, we will calculate this in two steps.
首先将训练集中的真实样本通过鉴别器,计算log(D(x)), 通过反向传播计算梯度
然后构建一批假样本通过当前的生成器,计算log(1-D(G(z)))
First, we will construct a batch of real samples from the training set, forward pass through D, calculate the loss(D(x)) , then calculate the gradients in a backward pass.
Secondly, we will construct a batch of fake samples with the current generator, forward pass this batch through D, calculate the loss (log(1-D(G(z)))), and accumulate the gradients with a backward pass.
part2 — train the generator
we want to train the generator by minimizing log(1-D(G(z))) in an effort to generate better fakes. — not provide sufficient gradients
As a fix, we instead wish to maximize log(D(G(z)))
in the code we accomplish by: classifying the Generator output from part1 with Discriminator, computing G’s loss using real labels as GT, computing G’s gradients in a backward pass, and finally updating G’s parameters with an optimizer step.
使用鉴别器对第一部分的生成器输出进行分类,使用标签计算G的损失

若有收获,就点个赞吧
0 人点赞
