参考
https://www.jianshu.com/p/494e479c9037
https://www.cnblogs.com/cloudtj/articles/5512335.html
https://stefvanbuuren.name/mice/
https://stefvanbuuren.name/fimd/
https://cran.r-project.org/web/packages/mice/mice.pdf
前言
分析数据第一步就是清理数据了,包括异常值,缺失值处理等。首先要明白为什么会缺失,然后可以将缺失分为三类。最后是根据缺失的原因分类结果选用不同的方法来处理缺失值。例如缺失是完全随机的,不受其他因素或者变量影响,这个时候就可以直接删除有缺失的样本,只保留完整的样本。这里可以理解为数据完整的样本是随机的重新抽样(大样本中的一部分),可以反应总体。其实我们好好想想,抽样分析其实就是一个填补缺失值的研究,总体的中没有抽到的样本都算缺失。上面的参考中有更详细的阐述,这里主要介绍 mice 包的使用方法和适用条件。文章只用来参考,若有错误请指出,共同学习。
1、均值填充
library("mice")data("airquality")imp <- mice(airquality, method = "mean", m = 1, maxit = 1)##The argument method = mean specifies mean imputation, the argument m = 1 requests a single imputed dataset, and maxit = 1 sets the number of iterations to 1 (no iteration).
均值填补很快捷但是不推荐,因为大多数情况下会改变原始数据的分布,干扰变量之间的关系。
2、回归填补(Regression imputation)
data <- airquality[, c("Ozone", "Solar.R")]imp <- mice(data, method = "norm.predict", seed = 1,m = 1, print = FALSE)xyplot(imp, Ozone ~ Solar.R)
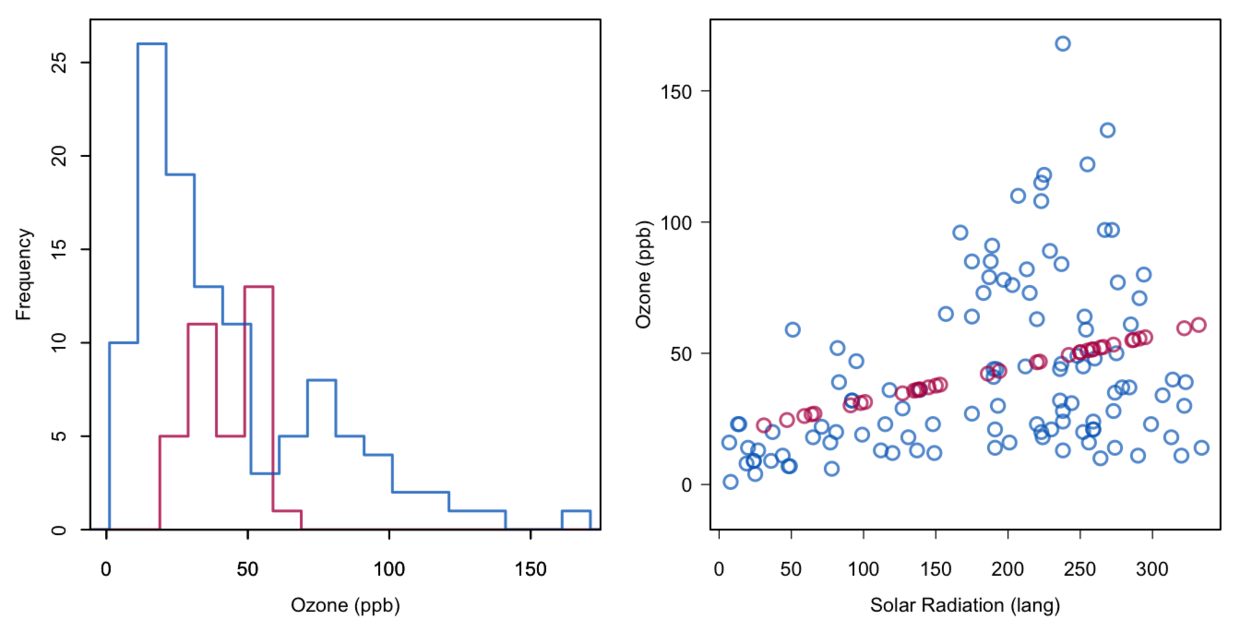
根据变量之间的关系,建立回归模型,然后再预测缺失值。但从上图中可以看出,预测值和真实观测值还是会有区别,观测值是随机分布的,而不是完美的在某一条回归曲线上。预测的缺失值会增加变量之间的相关性。
3、随机回归 (Stochastic regression imputation)
data <- airquality[, c("Ozone", "Solar.R")]imp <- mice(data, method = "norm.nob", m = 1, maxit = 1,seed = 1, print = FALSE)
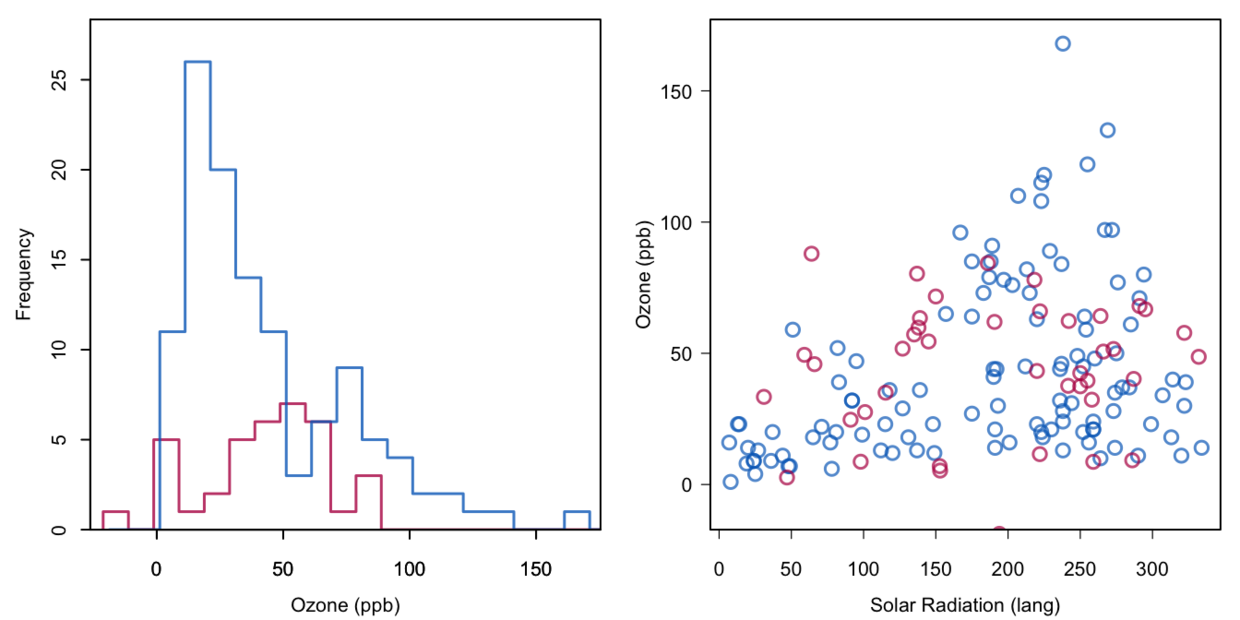
此种方法是上面方法的改进,在回归中加入噪音(随机残差),这样可以减少相关偏差。即保留了回归权重,又不太影响变量之间的相关性。
当然回归分析也有局限性,变量之间有依赖性才行。
4、向填充或者向前填充
airquality2 <- tidyr::fill(airquality, Ozone)
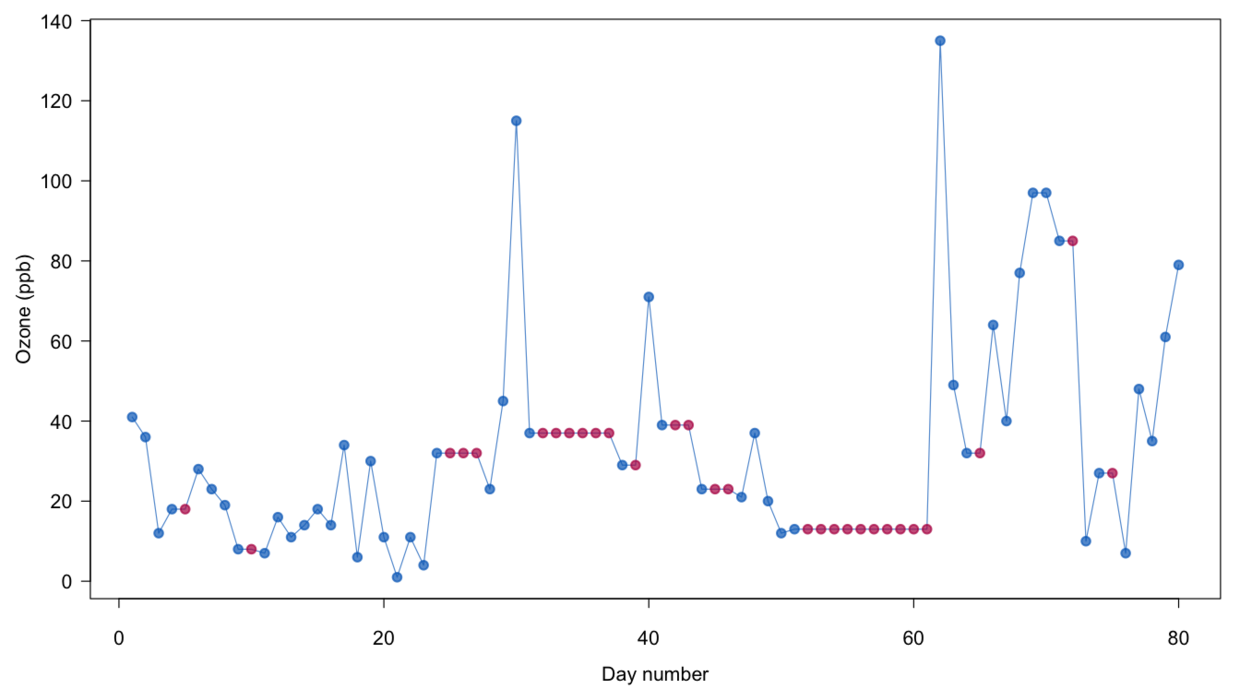
这种方法应该对时间依赖型的数据比较友好,比如每天的室温记录,如果有缺失,这个温度很有可能和前天或者后天的温度保持一致。这种方法多用于临床和药物研究中。
5、多重补插
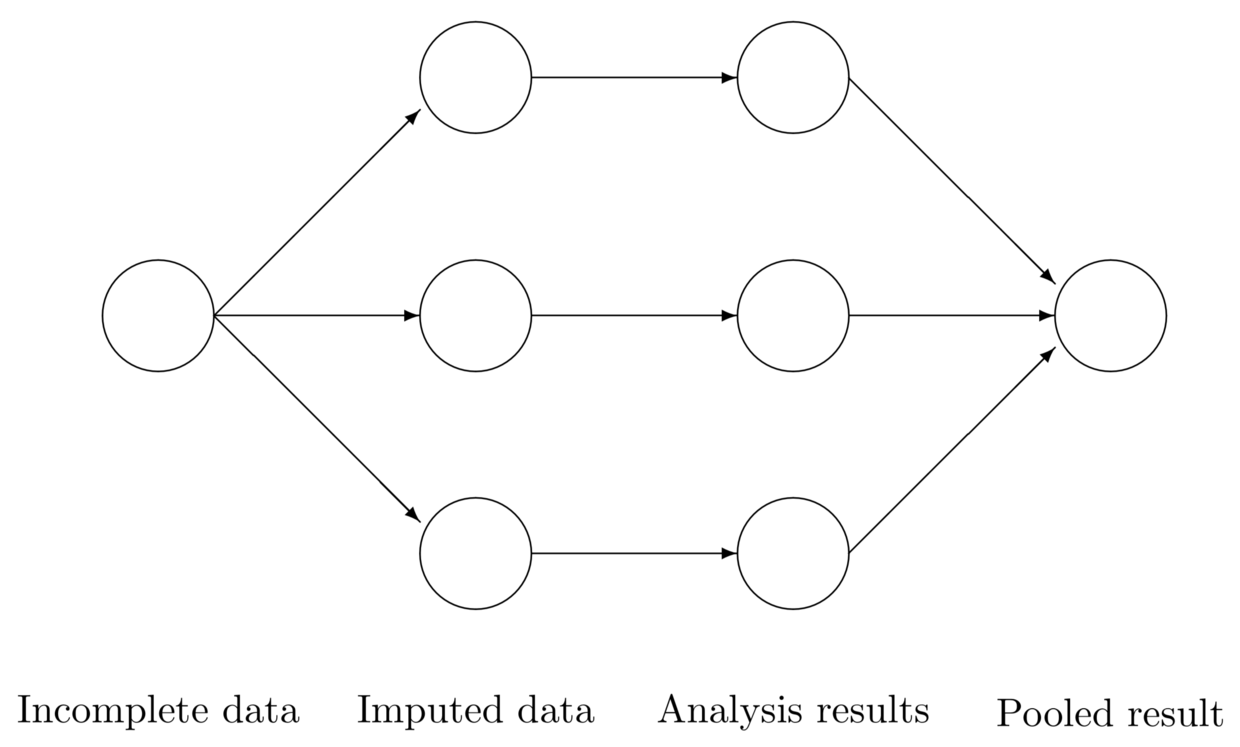
如下图所示,通过可信值替换缺失值,生成多个完整数据集,然后进行我们感兴趣的分析。最终结果之间的差异就完全是因为缺失值造成的。最后进行合并,在适当的条件下,合并的估计是无偏的,并且具有正确的统计特性。

若有收获,就点个赞吧
0 人点赞
