](https://www.jianshu.com/p/5da86afed228)
1、kafka消费模式
1.1、一对一
即点对点的通信,即一个发送一个接收。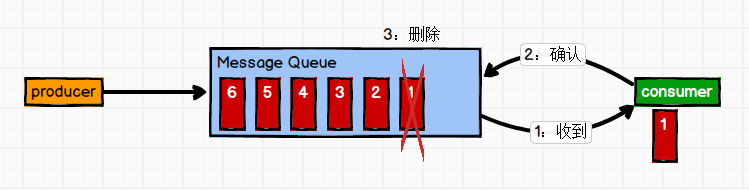
消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费。
1.2、一对多
即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
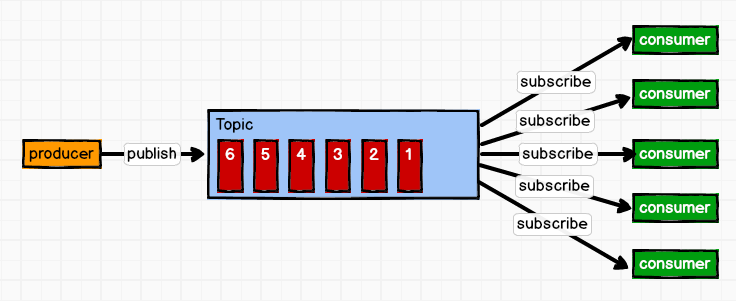
这种模式也称为发布/订阅模式,即利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除。
2、Kafka的基础架构
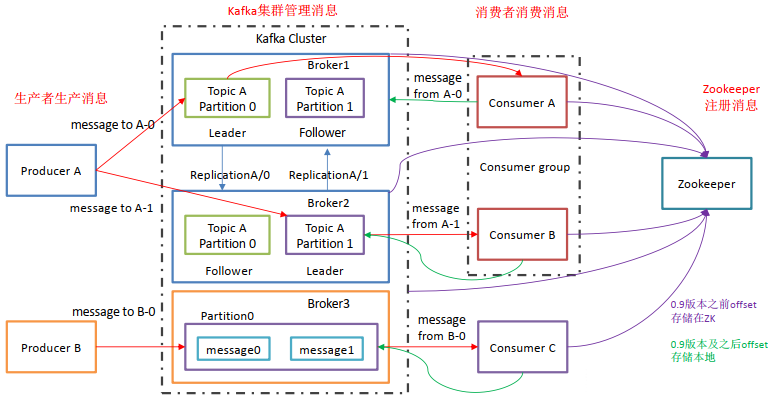
- Producer:消息生产者,向Kafka中发布消息的角色。
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
- Zookeeper:管理broker、consumer ```java 上述一个Topic会产生多个分区Partition,分区中分为Leader和Follower, 消息一般发送到Leader,Follower通过数据的同步与Leader保持同步, 消费的话也是在Leader中发生消费,如果多个消费者,则分别消费Leader和各个Follower中的消息, 当Leader发生故障的时候,某个Follower会成为主节点,此时会对齐消息的偏移量。
<a name="nDPpn"></a>### 3、kafka安装与使用```java# docker直接拉取kafka和zookeeper的镜像docker pull wurstmeister/kafkadocker pull wurstmeister/zookeeper# 首先需要启动zookeeper,如果不先启动,启动kafka没有地方注册消息docker run -it --name zookeeper -p 12181:2181 -d wurstmeister/zookeeper:latest# 启动kafka容器,注意需要启动三台,注意端口的映射,都是映射到9092# 第一台docker run -it --name kafka01 -p 19092:9092 -d -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.233.129:12181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.233.129:19092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka:latest# 第二台docker run -it --name kafka02 -p 19093:9092 -d -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=192.168.233.129:12181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.233.129:19093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka:latest# 第三台docker run -it --name kafka03 -p 19094:9092 -d -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=192.168.233.129:12181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.233.129:19094 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka:latest
上面端口的映射注意都是映射到Kafka的9092端口上!否则将不能够连接!
具体命令学习
# 创建topic名称为first,3个分区,1个副本./kafka-topics.sh --zookeeper 192.168.233.129:12181 --create --topic first --replication-factor 1 --partitions 3# 查看first此topic信息./kafka-topics.sh --zookeeper 192.168.233.129:12181 --describe --topic firstTopic: first PartitionCount: 3 ReplicationFactor: 1 Configs:Topic: first Partition: 0 Leader: 2 Replicas: 2 Isr: 2Topic: first Partition: 1 Leader: 0 Replicas: 0 Isr: 0Topic: first Partition: 2 Leader: 1 Replicas: 1 Isr: 1# 调用生产者生产消息./kafka-console-producer.sh --broker-list 192.168.233.129:19092,192.168.233.129:19093,192.168.233.129:19094 --topic first# 调用消费者消费消息,from-beginning表示读取全部的消息./kafka-console-consumer.sh --bootstrap-server 192.168.233.129:19092,192.168.233.129:19093,192.168.233.129:19094 --topic first --from-beginning# 删除topic

删除topic
具体命令./kafka-topic.sh —zookeeper 192.168.233.129:12181 —delete —topic second
从上图可以看到删除的时候只是被标记为删除marked for deletion并没有真正的删除,如果需要真正的删除,需要再config/server.properties中设置delete.topic.enable=true
修改分区数
./kafka-topics.sh —zookeeper 192.168.233.129:12181 —alter —topic test2 —partitions 3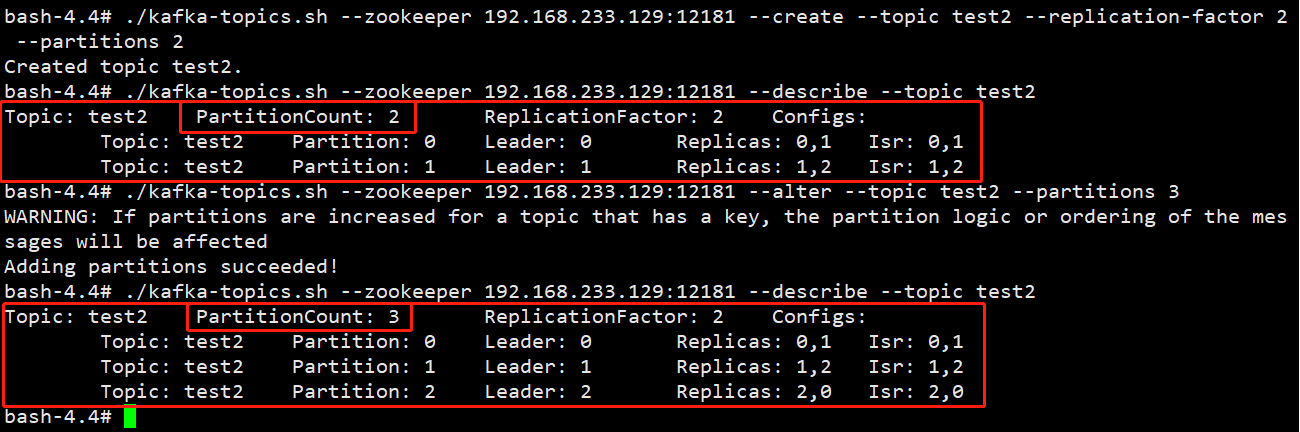
4、SpringBoot+Kafka整合
- 整体架构
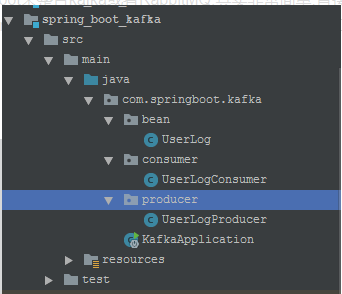
引入依赖
<!--引入kafak和spring整合的jar--><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>1.1.1.RELEASE</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.44</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
首先定义一个bean用来发送消息的载体 ```java package com.springboot.kafka.bean;
import lombok.Data; import lombok.experimental.Accessors;
/**
- @Author
- @Description 定义用户发送的日志数据 */ @Data @Accessors(chain = true) public class UserLog { private String username; private String userid; private String state; } ```
- 定义生产者 ```java package com.springboot.kafka.producer;
import com.alibaba.fastjson.JSON; import com.springboot.kafka.bean.UserLog; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component;
/**
- @Author
@Description 生产者 */ @Component public class UserLogProducer { @Autowired private KafkaTemplate kafkaTemplate;
/**
- 发送数据
- @param userid */ public void sendLog(String userid){ UserLog userLog = new UserLog(); userLog.setUsername(“jhp”).setUserid(userid).setState(“0”); System.err.println(“发送用户日志数据:”+userLog); kafkaTemplate.send(“user-log”, JSON.toJSONString(userLog)); } } ```
- 定义消费者
消费机制是通过监听器实现的,直接使用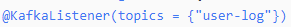 这个注解接口,它可以根据指定的条件进行消息的监听:
这个注解接口,它可以根据指定的条件进行消息的监听:
package com.springboot.kafka.consumer;import lombok.extern.slf4j.Slf4j;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.stereotype.Component;import java.util.Optional;/*** @Author* @Description 消费者*/@Component@Slf4jpublic class UserLogConsumer {@KafkaListener(topics = {"user-log"})public void consumer(ConsumerRecord<?,?> consumerRecord){//判断是否为nullOptional<?> kafkaMessage = Optional.ofNullable(consumerRecord.value());log.info(">>>>>>>>>> record =" + kafkaMessage);if(kafkaMessage.isPresent()){//得到Optional实例中的值Object message = kafkaMessage.get();System.err.println("消费消息:"+message);}}}
- 启动应用类
package com.springboot.kafka;import com.springboot.kafka.producer.UserLogProducer;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import javax.annotation.PostConstruct;/*** @Author* @Description 测试启动类*/@SpringBootApplicationpublic class KafkaApplication {@Autowiredprivate UserLogProducer kafkaSender;@PostConstructpublic void init(){for (int i = 0; i < 10; i++) {//调用消息发送类中的消息发送方法kafkaSender.sendLog(String.valueOf(i));}}public static void main(String[] args) {SpringApplication.run(KafkaApplication.class,args);}}
- 配置文件:
```java
spring.application.name=kafka-user
server.port=8080
============== kafka ===================
指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=localhost:9092
=============== provider =======================
spring.kafka.producer.retries=0
每次批量发送消息的数量
spring.kafka.producer.batch-size=16384 spring.kafka.producer.buffer-memory=33554432
指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
=============== consumer =======================
指定默认消费者group id
spring.kafka.consumer.group-id=user-log-group
spring.kafka.consumer.auto-offset-reset=earliest spring.kafka.consumer.enable-auto-commit=true spring.kafka.consumer.auto-commit-interval=100
指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer ```
这个时候观察控制台打印的消息:
和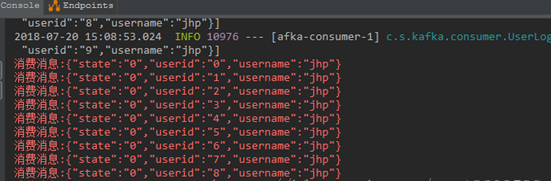
说明springboot和kafka成功的整合了,好简单..不过这里要注意一下就是Kafka版本的问题,具体的版本可以查看jar引入之后的kafka,生产的kakfa集群最好和它的版本一致.
(上面的效果是假设已经在本地装好了zookeeper的集群和kafka的集群)
5、windows安装kafka及案例

若有收获,就点个赞吧
0 人点赞
