1、MySql的三大范式
1.1、第一范式(1NF)
定义:每个列都不可以再拆分
案例:
这张表就不符合第一范式规定的原子性,不符合关系型数据库的基本要求,在关系型数据库中创建这个表的操作就不能成功。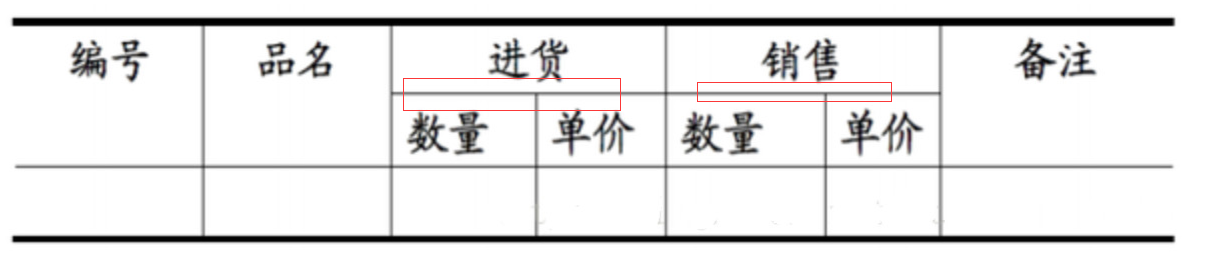
不得不将数据表设计为如下形式。
例如:顾客表(姓名、编号、地址、……)其中”地址”列还可以细分为国家、省、市、区等。
1.2、第二范式(2NF)
定义:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分
案例:下满这张表不符合第二范式的要求。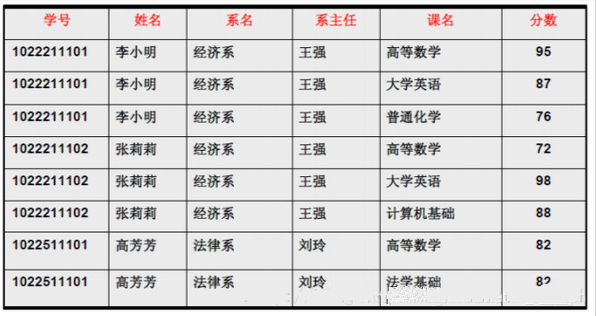
缺点:
- 表中的第一行数据都存储了系名、系主任,数据的冗余太大
- 如果有一个新的系还没有开始找到学生,那么不能讲该系的信息添加到数据表中去,从数据表中看不到该系的存在
- 如果将某个系的学生信息全部删除,那么这个系在数据表里也就不存在了,但这个系还存在。
- 如果某个人要转系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据
做出修改: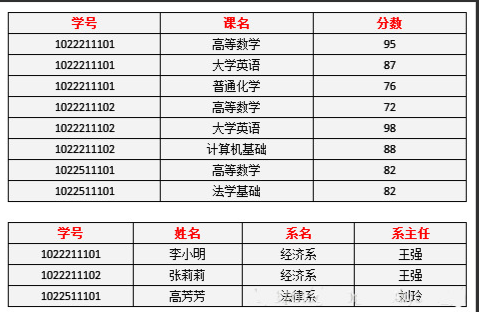
表一中分数完全依赖于学号和课程的属性
表二中姓名、系名、系主任完全依赖于学号的属性
第二范式消除了第一范式的部分依赖
例如:订单表(订单编号、产品编号、定购日期、价格、……),”订单编号”为主键,”产品编号”和主键列没有直接的关系,即”产品编号”列不依赖于主键列,应删除该列。
1.3、第三范式(3NF)
定义:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键
例如:订单表(订单编号,定购日期,顾客编号,顾客姓名,……),初看该表没有问题,满足第二范式,每列都和主键列”订单编号”相关,再细看你会发现”顾客姓名”和”顾客编号”相关,”顾客编号”和”订单编号”又相关,最后经过传递依赖,”顾客姓名”也和”订单编号”相关。为了满足第三范式,应去掉”顾客姓名”列,放入客户表中。
2、一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 MySQL 数据库,又插入了一条数据,此时 id 是几?
- 表类型如果是 MyISAM ,那 id 就是 8。
- 表类型如果是 InnoDB,那 id 就是 6。
InnoDB 表只会把自增主键的最大 id 记录在内存中,所以重启之后会导致最大 id 丢失。
3、查看当前mysql的版本
使用 select version() 获取当前 MySQL 数据库版本。
4、ACID是什么?
- Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
- Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
- Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
5、 char 和 varchar 的区别是什么?
- char(n) :固定长度类型,比如订阅 char(10),当你输入”abc”三个字符的时候,它们占的空间还是 10 个字节,其他 7 个是空字节。
chat 优点:效率高;缺点:占用空间;适用场景:存储密码的 md5 值,固定长度的,使用 char 非常合适。
- varchar(n) :可变长度,存储的值是每个值占用的字节再加上一个用来记录其长度的字节的长度。
所以,从空间上考虑 varcahr 比较合适;从效率上考虑 char 比较合适,二者使用需要权衡。
6、 float 和 double 的区别是什么?
- float 最多可以存储 8 位的十进制数,并在内存中占 4 字节。
- double 最可可以存储 16 位的十进制数,并在内存中占 8 字节。
7、 MySQL 的内连接、左连接、右连接有什么区别?
内连接关键字:inner join;左连接:left join;右连接:right join。
内连接是把匹配的关联数据显示出来;左连接是左边的表全部显示出来,右边的表显示出符合条件的数据;右连接正好相反。
8、MySQL 索引是怎么实现的?
索引是满足某种特定查找算法的数据结构,而这些数据结构会以某种方式指向数据,从而实现高效查找数据。
具体来说 MySQL 中的索引,不同的数据引擎实现有所不同,但目前主流的数据库引擎的索引都是 B+ 树实现的,B+ 树的搜索效率,可以到达二分法的性能,找到数据区域之后就找到了完整的数据结构了,所有索引的性能也是更好的。
9、怎么验证 MySQL 的索引是否满足需求?
使用 explain 查看 SQL 是如何执行查询语句的,从而分析你的索引是否满足需求。
explain 语法:explain select * from table where type=1。
10、数据库的隔离级别

若有收获,就点个赞吧
0 人点赞
