- 1、Centos 安装 Mysql
- 2、Centos 卸载Mysql
- 3、索引">3、索引
- 4、视图">4、视图
- 5、存储过程和函数
- 6、触发器
- 7、mysql体系结构
- 8、存储引擎
- 9、SQL优化
- 10、应用优化
- 11、Mysql锁
- 12、mysql执行流程
- 设置server_id,同一局域网中需要唯一
- 指定不需要同步的数据库名称
- 开启二进制日志功能
- 设置二进制日志使用内存大小(事务)
- 设置使用的二进制日志格式(mixed,statement,row)
- 二进制日志过期清理时间。默认值为0,表示不自动清理。
- 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
- 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
- 18、实战示例
Mysql高级-day01.pdf
Mysql高级-day02.pdf
Mysql高级-day03.pdf
Mysql高级-day04.pdf
1、Centos 安装 Mysql
1.1、wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm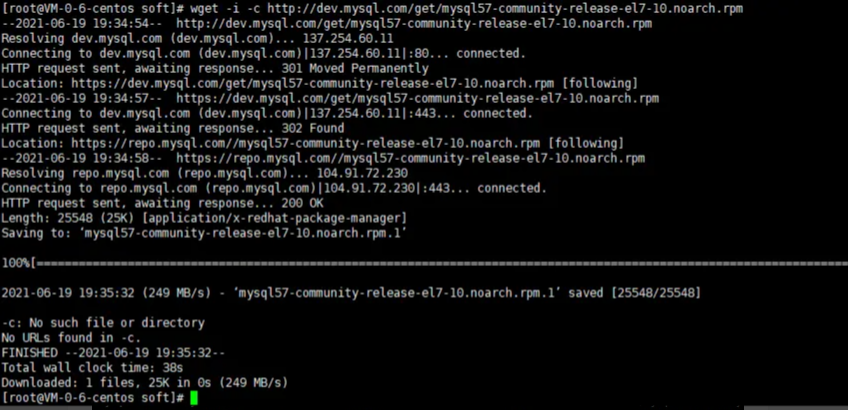
1.2、yum -y install mysql57-community-release-el7-10.noarch.rpm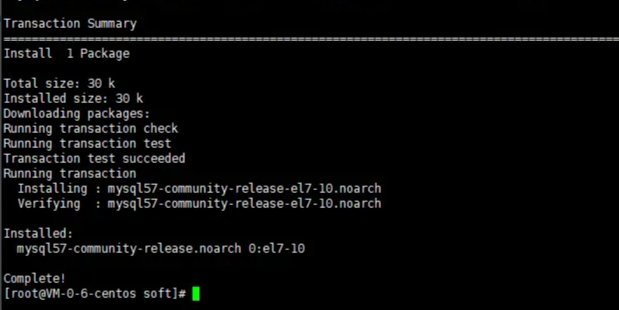
1.3、yum -y install mysql-community-server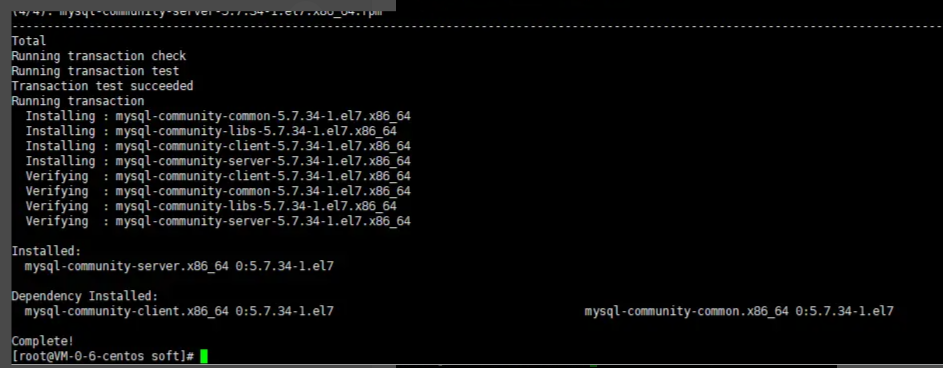
1.4、systemctl start mysqld.service
1.5、grep “password” /var/log/mysqld.log (备注:查看默认的密码)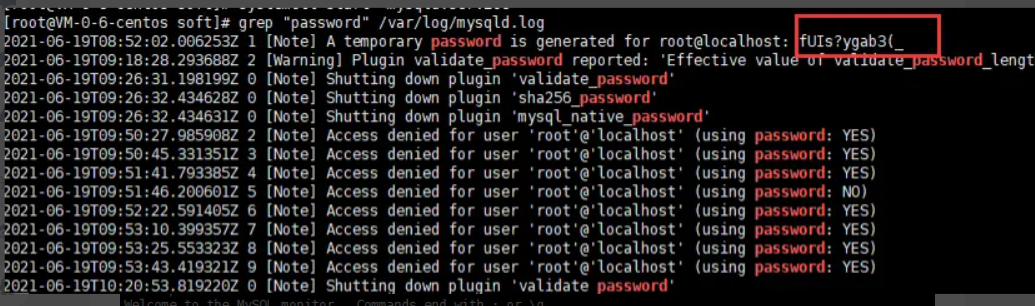
1.6、mysql -uroot -p (备注:输入刚刚默认的密码)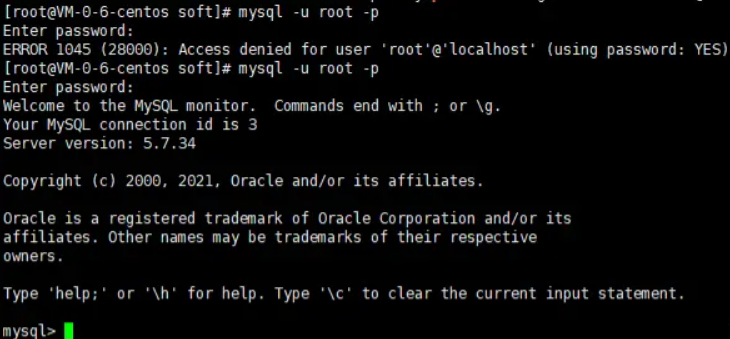
1.7、set global validate_password_policy=0;
1.8、set global validate_password_length=1;
1.9、ALTER USER ‘root’@’localhost’ IDENTIFIED BY ‘你的新密码’; (备注:这里修改你的新密码)
1.10、show databases;
我们修改完密码后才有操作数据库的权限,这时我们来验证一下是否可以查看数据库了。
2、Centos 卸载Mysql
2.1、rpm -qa|grep -i mysql
首先查看mysql有哪些文件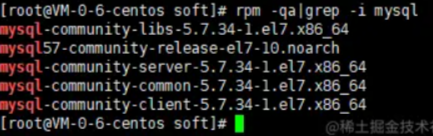
2.2、yum remove 文件名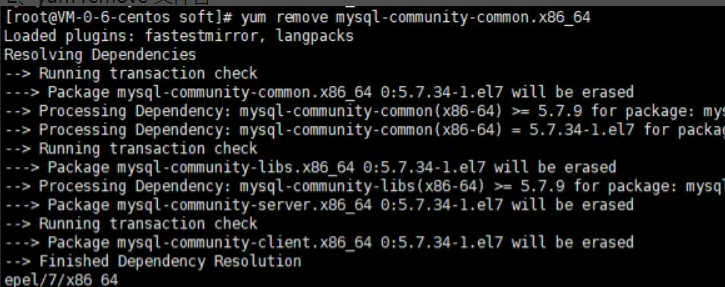
2.3、find / -name mysql
查找mysql的配置文件和数据库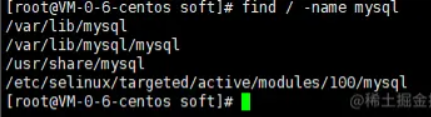
2.4、rm -rf /var/lib/mysql
2.5、rm -rf /usr/share/mysql
2.6、rm -rf /etc/selinux/targeted/active/modules/100/mysql
这些是一些配置文件和数据库,如果不需要删库的请不要执行。
3、索引
1)用EXPLAIN 关键字查看sql是否使用索引
EXPLAIN SELECT * FROM 表名 WHERE 字段= ‘内容’;
2)查看表结构
SHOW CREATE TABLE 表名;
3) 查看表的索引
SHOW INDEX FROM 表名;
4) alter命令
ALTER TABLE 表名 ADD[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (索引字段名(长度))
alter table tb_name add primary key(column_list); 该语句添加一个主键索引,这意味着索引值必须是唯一的,且不能为NULL
alter table tb_name add unique index_name(column_list); 这条语句创建索引的值必须是唯一索引的(除了NULL外,NULL可能会出现多次)
alter table tb_name add index index_name(column_list); 添加普通索引, 索引值可以出现多次。
alter table tb_name add fulltext index_name(column_list); 该语句指定了索引为FULLTEXT, 用于全文索引
**5) 删除索引**<br /> ALTER TABLE 表名 DROP INDEX 索引名<br /> DROP INDEX 索引名 ON 表名;
6) create 命令 创建索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] 索引名称 ON 表名(创建索引的字段名[length])
4、视图
- 如果要对一张表或者多张表进行查询,可以通过写复杂的SQL语句来实现
- 如果要这些SQL语句存储为视图,那么查询的时候,就直接查询这个视图就可以了
1)创建视图
CREATE VIEW 视图名 AS SELECT id, name FROM t;
2)修改视图
ALTER VIEW 视图名 AS 语句
3)查看视图
show tables;
5、存储过程和函数
6、触发器
答:通过触发器记录 表的数据变更日志 , 包含增加, 修改 , 删除 ;
7、mysql体系结构
整个MySQL Server由以下组成
- Connection Pool : 连接池组件
- Management Services & Utilities : 管理服务和工具组件
- SQL Interface : SQL接口组件
- Parser : 查询分析器组件
- Optimizer : 优化器组件
- Caches & Buffers : 缓冲池组件
- Pluggable Storage Engines : 存储引擎
- File System : 文件系统
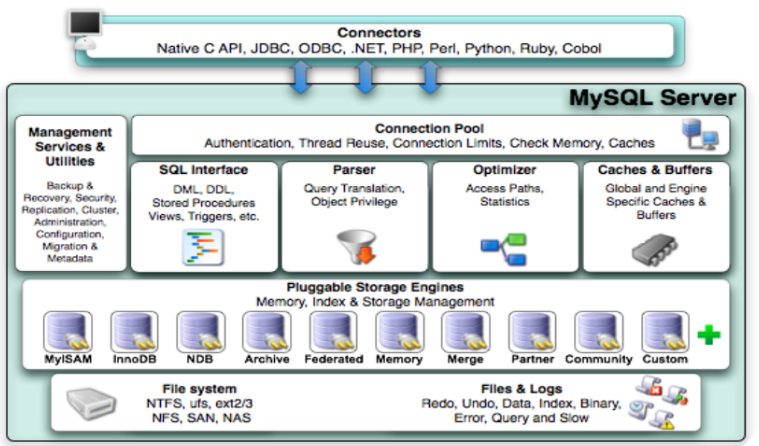
8、存储引擎
- mysql5.5之前的默认存储引擎是 MyISAM ,5.5之后是 InnoDB
- 命令show engines 查看支持的引擎
- InnoDB存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全
9、SQL优化
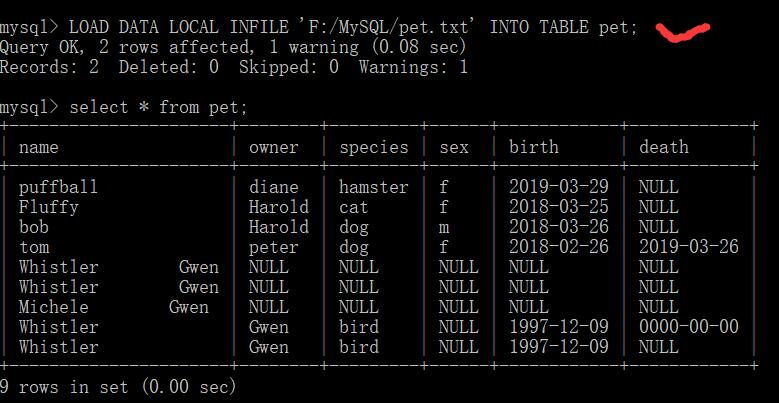
1、大批量插入的 使用load命令
在本地创建一个文件(pet.txt)并且将数据放入这个文件注意数据之间用tab键隔开数据为空的项使用 \N(假设我创建的本地文件路径为:F:\MySQL\pet.txt),文件中的数据如下Whistler Gwen bird \N 1997-12-09 \N使用LOAD命令将其添加到pet表中mysql> LOAD DATA LOCAL INFILE 'F:/MySQL/pet.txt' INTO TABLE pet;注意这里的路径得使用“/”反斜杠
2、优化insert语句
如果需要同时对一张表插入很多行数据时,应该尽量使用多个值表的insert语句,这种方式将大大的缩减客户端与数据库之间的连接、关闭等消耗。使得效率比分开执行的单个insert语句快。示例, 原始方式为:insert into tb_test values(1,'Tom');insert into tb_test values(2,'Cat');insert into tb_test values(3,'Jerry');优化后方案:insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
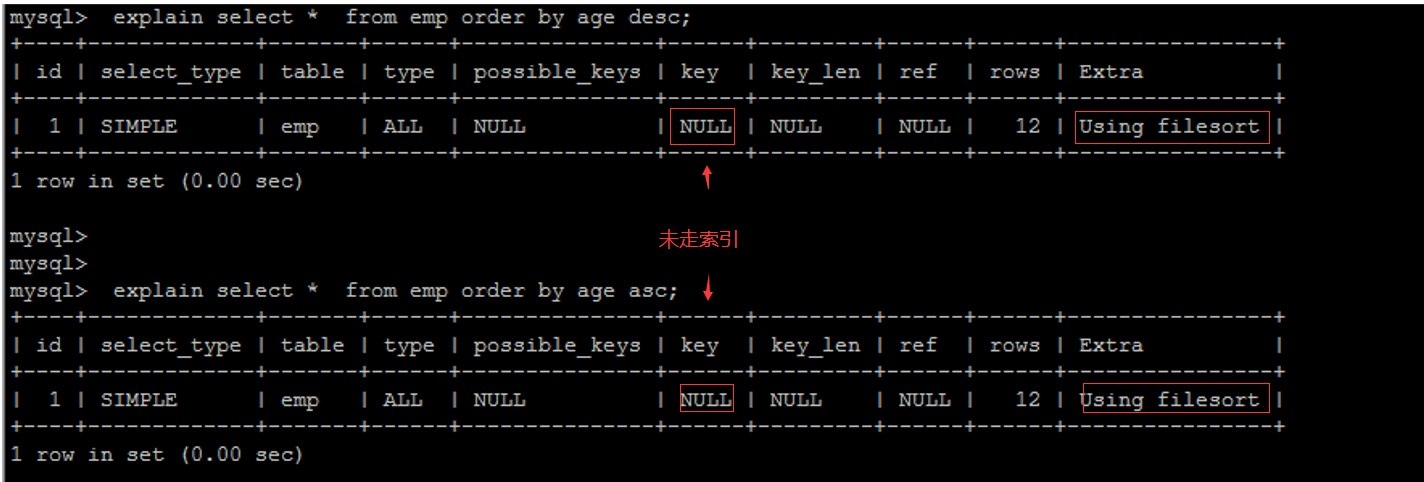
3、优化order by语句
两种排序方式:
- using filesort 排序 :不通过索引 全局扫描 效率低 select * 。。。
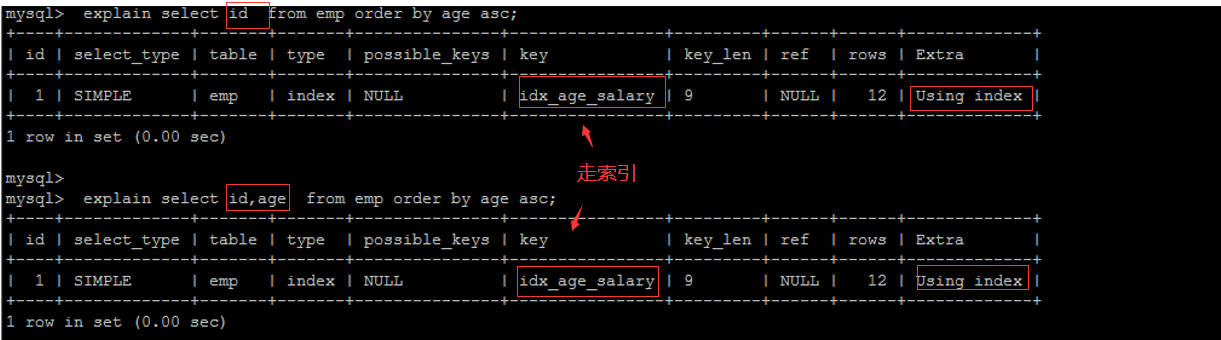
- using index 排序 : 通过指定索引字段排序 效率高 select id 。。。 id 是主键索引
4、优化group by 语句
由于GROUP BY 会进行排序操作,则可以执行order by null 禁止排序
5、优化嵌套查询
子查询是可以被更高效的连接(JOIN)替代。
优化前 子查询explain select * from t_user where id in (select user_id from user_role );优化后 join连表explain select * from t_user u , user_role ur where u.id = ur.user_id;
6、优化OR条件
对于包含OR的查询子句,如果要利用索引,则OR之间的每个条件列都必须用到索引 , 而且不能使用到复合索引; 如果没有索引,则应该考虑增加索引。
7、优化SQL提示
在查询语句中表名的后面,添加 use index 来提供希望MySQL去参考的索引列表,就可以让MySQL不再考虑其他可用的索引。explain select * from tb_seller use index(idx_seller_name) where name = '小米科技';如果用户只是单纯的想让MySQL忽略一个或者多个索引,则可以使用 ignore index 作为 hint 。explain select * from tb_seller ignore index(idx_seller_name) where name = '小米科技';
10、应用优化
1、使用连接池
采用druid 不采用c3p0
对于访问数据库来说,建立连接的代价是比较昂贵的,因为我们频繁的创建关闭连接,是比较耗费资源的,我们有必要建立 数据库连接池,以提高访问的性能。
2、减少对mysql的访问次数
能够一次连接就获取到结果的,就不用两次连接,这样可以大大减少对数据库无用的重复请求。
比如 ,需要获取书籍的id 和name字段 , 则查询如下:select id , name from tb_book;之后,在业务逻辑中有需要获取到书籍状态信息, 则查询如下:select id , status from tb_book;这样,就需要向数据库提交两次请求,数据库就要做两次查询操作。其实完全可以用一条SQL语句得到想要的结果。select id, name , status from tb_book;
3、增加cache层
在应用中,我们可以在应用中增加 缓存 层来达到减轻数据库负担的目的。
- 因此可以部分数据从数据库中抽取出来放到应用端以文本方式存储,
- 或者使用框架(Mybatis, Hibernate)提供的一级缓存/二级缓存,或者使用redis数据库来缓存数据 。
4、负载均衡
- 通过MySQL的主从复制,实现读写分离,使增删改操作走主节点,查询操作走从节点,从而可以降低单台服务器的读写压力。
- 分布式数据库架构适合大数据量、负载高的情况,它有良好的拓展性和高可用性。通过在多台服务器之间分布数据,可以实现在多台服务器之间的负载均衡,提高访问效率。
11、Mysql锁
1、从对数据操作的粒度分 :
1) 表锁:操作时,会锁定整个表。
2) 行锁:操作时,会锁定当前操作行。
2、从对数据操作的类型分:
1) 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
2) 写锁(排它锁):当前操作没有完成之前,它会阻断其他写锁和读锁。
3、MyISAM 只支持表锁
给表锁上 读锁或写锁
1) 对MyISAM 表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;
2) 对MyISAM 表的写操作,则会阻塞其他用户对同一表的读和写操作;
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁,则既会阻塞读,又会阻塞写。
此外,MyISAM 的读写锁调度是写优先,这也是MyISAM不适合做写为主的表的存储引擎的原因。因为写锁后,其他线程不能做任何操作,大量的更新会使查询很难得到锁,从而造成永远阻塞。
4、InnoDB 行锁
InnoDB 与 MyISAM 的最大不同有两点:一是支持事务;二是 采用了行级锁。
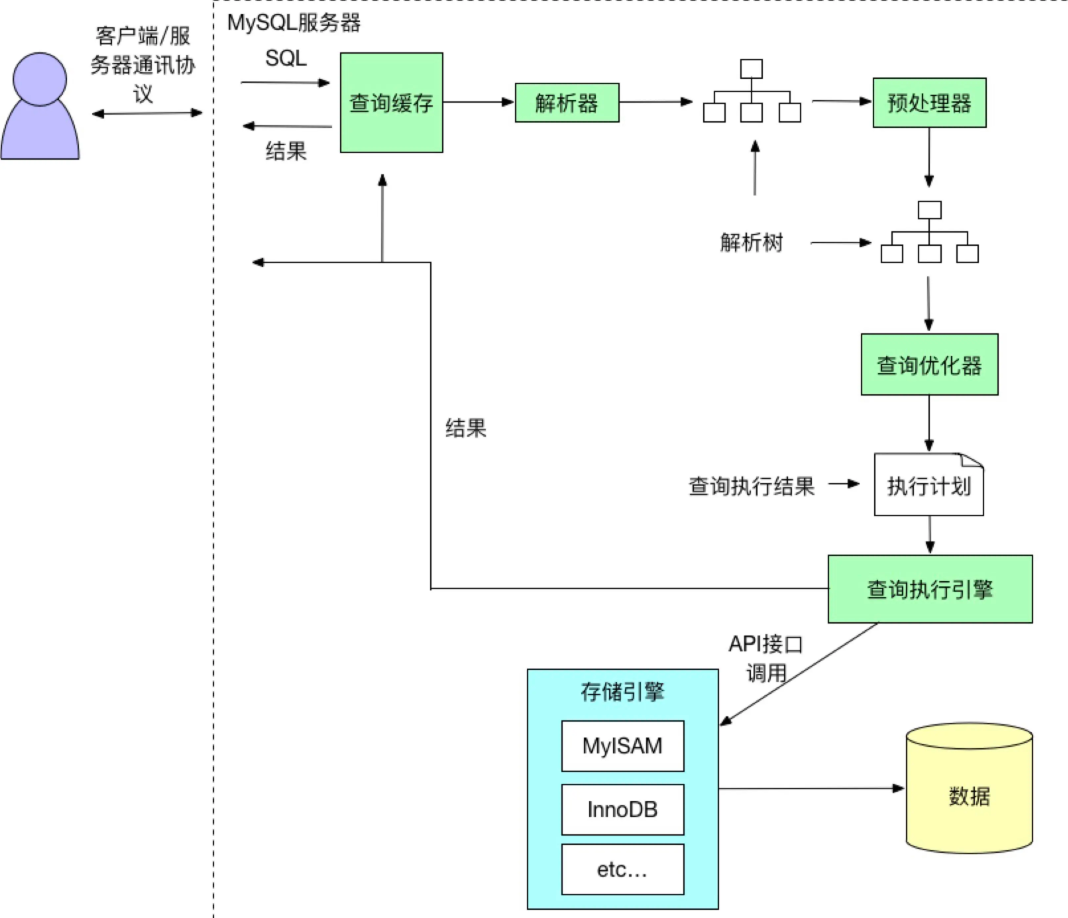
12、mysql执行流程
- MySQL客户端通过协议将SQL语句发送给MySQL服务器。
- 服务器会先检查查询缓存中是否有执行过这条SQL,如果命中缓存,则将结果返回,否则进入下一个环节(查询缓存默认不开启)。
- 服务器端进行SQL解析,预处理,然后由查询优化器生成对应的执行计划。
- 服务器根据查询优化器给出的执行计划,再调用存储引擎的API执行查询。
- 将结果返回给客户端,如果开启查询缓存,则会备份一份到查询缓存中。
13、事务的ACID
| ACID属性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是一个原子操作单元,其对数据的修改,要么全部成功,要么全部失败。 |
| 一致性(Consistent) | 在事务开始和完成时,数据都必须保持一致状态。 |
| 隔离性(Isolation) | 数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的 “独立” 环境下运行。 |
| 持久性(Durable) | 事务完成之后,对于数据的修改是永久的。 |
14、隔离级别
| 隔离级别 | 丢失更新 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read uncommitted(未提交读,) | × | √ | √ | √ |
| Read committed (提交读) | × | × | √ | √ |
| Repeatable read(默认可重复读) | × | × | × | √ |
| Serializable (可串行化) | × | × | × | × |
备注 : √ 代表可能出现 , × 代表不会出现 。
查看系统隔离级别:select @@global.tx_isolation;查看当前会话隔离级别select @@tx_isolation;设置当前会话隔离级别SET session TRANSACTION ISOLATION LEVEL serializable;设置全局系统隔离级别SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
1、READ UNCOMMITTED(未提交读,可脏读)
事务中的修改,即使没有提交,对其他会话也是可见的。
可以读取未提交的数据——脏读。脏读会导致很多问题,一般不适用这个隔离级别。
实例:
-- ------------------------- read-uncommitted实例 -------------------------------- 设置全局系统隔离级别SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;-- Session ASTART TRANSACTION;SELECT * FROM USER;UPDATE USER SET NAME="READ UNCOMMITTED";-- commit;-- Session BSELECT * FROM USER;//SessionB Console 可以看到Session A未提交的事物处理,在另一个Session 中也看到了,这就是所谓的脏读id name2 READ UNCOMMITTED34 READ UNCOMMITTED
2、READ COMMITTED(提交读或不可重复读,幻读)
一般数据库都默认使用这个隔离级别(mysql不是),这个隔离级别保证了一个事务如果没有完全成功(commit执行完),事务中的操作对其他会话是不可见的。
-- ------------------------- read-cmmitted实例 -------------------------------- 设置全局系统隔离级别SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;-- Session ASTART TRANSACTION;SELECT * FROM USER;UPDATE USER SET NAME="READ COMMITTED";-- COMMIT;-- Session BSELECT * FROM USER;//Console OUTPUT:id name2 READ UNCOMMITTED34 READ UNCOMMITTED----------------------------------------------------- 当 Session A执行了commit,Session B得到如下结果:id name2 READ COMMITTED34 READ COMMITTED
也就验证了read committed级别在事物未完成commit操作之前修改的数据对其他Session 不可见,执行了commit之后才会对其他Session 可见。
我们可以看到Session B两次查询得到了不同的数据。
read committed隔离级别解决了脏读的问题,但是会对其他Session 产生两次不一致的读取结果(因为另一个Session 执行了事务,一致性变化)。
3、REPEATABLE READ(可重复读)
一个事务中多次执行统一读SQL,返回结果一样。
这个隔离级别解决了脏读的问题,幻读问题。这里指的是innodb的rr级别,innodb中使用next-key锁对”当前读”进行加锁,锁住行以及可能产生幻读的插入位置,阻止新的数据插入产生幻行。
下文中详细分析。
4、SERIALIZABLE(可串行化)
最强的隔离级别,通过给事务中每次读取的行加锁,写加写锁,保证不产生幻读问题,但是会导致大量超时以及锁争用问题。
5、脏读 vs 幻读 vs 不可重复读
脏读:一事务未提交的中间状态的更新数据 被其他会话读取到。 当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有 提交到数据库中(commit未执行),这时,另外会话也访问这个数据,因为这个数据是还没有提交, 那么另外一个会话读到的这个数据是脏数据,依据脏数据所做的操作也可能是不正确的。
不可重复读:简单来说就是在一个事务中读取的数据可能产生变化,ReadCommitted也称为不可重复读。
在同一事务中,多次读取同一数据返回的结果有所不同。换句话说就是,后续读取可以读到另一会话事务已提交的更新数据。 相反,“可重复读”在同一事务中多次读取数据时,能够保证所读数据一样,也就是,后续读取不能读到另一会话事务已提交的更新数据。
幻读:会话T1事务中执行一次查询,然后会话T2新插入一行记录,这行记录恰好可以满足T1所使用的查询的条件。然后T1又使用相同 的查询再次对表进行检索,但是此时却看到了事务T2刚才插入的新行。这个新行就称为“幻像”,因为对T1来说这一行就像突然 出现的一样。
innoDB的RR级别无法做到完全避免幻读,下文详细分析。
6、幻读和 不可重复读的区别
幻多是读到之前没有出现过的数据(新增或删除),
不可重复读是同一条数据两次读的结果不一样。
15、mysql常用工具
1、mysql
该mysql不是指mysql服务,而是指mysql的客户端工具。
参数 :-u, --user=name 指定用户名-p, --password[=name] 指定密码-h, --host=name 指定服务器IP或域名-P, --port=# 指定连接端口示例 :mysql -h 127.0.0.1 -P 3306 -u root -pmysql -h127.0.0.1 -P3306 -uroot -p2143
执行选项
此选项可以在Mysql客户端执行SQL语句,而不用连接到MySQL数据库再执行,对于一些批处理脚本,这种方式尤其方便。
参数:-e, --execute=name 执行SQL语句并退出示例:mysql -uroot -p2143 db01 -e "select * from tb_book";
2、mysqladmin
3、mysqladmin
4、mysqladmin
5、mysqlimport/source
6、mysqlshow
16、Mysql日志
在 MySQL 中,有 4 种不同的日志,分别是错误日志、二进制日志(BINLOG 日志)、查询日志和慢查询日志
1、错误日志
1.1、错误日志
进入mysql中:
show variables like ‘log_error%’;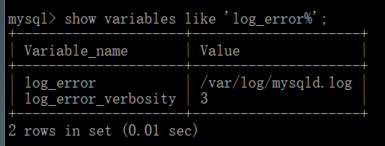
1.2、查看日志
退出mysql 进入目录:
tail -f /var/log/mysql.log
2、二进制日志
3、查询日志
4、慢查询日志
17、Mysql主从复制
1、用处
其实在 MySQL 本身就自带有一个主从复制的功能,可以帮助我们实现负载均衡和读写分离。
对于主服务器(Master)来说,主要负责写,从服务器(Slave)主要负责读,这样的话,就会大大减轻压力,从而提高效率。
2、原理
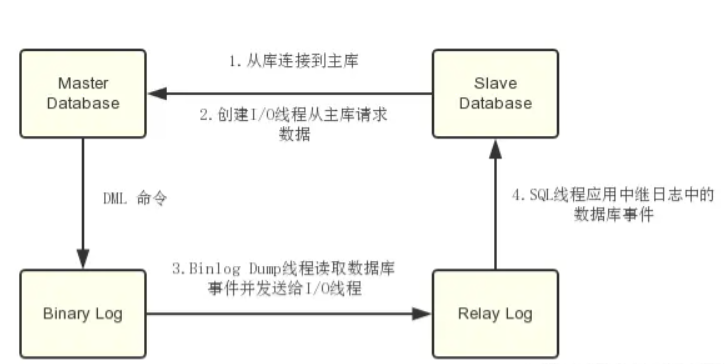
- MySql主库在事务提交时会把数据变更作为事件记录在二进制日志Binlog中;
- 主库推送二进制日志文件Binlog中的事件到从库的中继日志Relay Log中,之后从库根据中继日志重做数据变更操作,通过逻辑复制来达到主库和从库的数据一致性;
- MySql通过三个线程来完成主从库间的数据复制,其中Binlog Dump线程跑在主库上,I/O线程和SQL线程跑着从库上;
- 当在从库上启动复制时,首先创建I/O线程连接主库,主库随后创建Binlog Dump线程读取数据库事件并发送给I/O线程,I/O线程获取到事件数据后更新到从库的中继日志Relay Log中去,之后从库上的SQL线程读取中继日志Relay Log中更新的数据库事件并应用,如下图所示。
3、主实例搭建
运行mysql主实例:
docker run -p 3307:3306 --name mysql-master \-v /mydata/mysql-master/log:/var/log/mysql \-v /mydata/mysql-master/data:/var/lib/mysql \-v /mydata/mysql-master/conf:/etc/mysql \-e MYSQL_ROOT_PASSWORD=root \-d mysql:5.7
在mysql的配置文件夹/mydata/mysql-master/conf中创建一个配置文件my.cnf:
touch my.cnf
修改配置文件my.cnf,配置信息如下: ```javascript [mysqld]
设置server_id,同一局域网中需要唯一
server_id=101
指定不需要同步的数据库名称
binlog-ignore-db=mysql
开启二进制日志功能
log-bin=mall-mysql-bin
设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
- **修改完配置后重启实例:**```javascriptdocker restart mysql-master
进入mysql-master容器中:
docker exec -it mysql-master /bin/bash
在容器中使用mysql的登录命令连接到客户端:
mysql -uroot -proot
创建数据同步用户:
CREATE USER 'slave'@'%' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
4、从实例搭建
运行mysql从实例:
docker run -p 3308:3306 --name mysql-slave \-v /mydata/mysql-slave/log:/var/log/mysql \-v /mydata/mysql-slave/data:/var/lib/mysql \-v /mydata/mysql-slave/conf:/etc/mysql \-e MYSQL_ROOT_PASSWORD=root \-d mysql:5.7
在mysql的配置文件夹/mydata/mysql-slave/conf中创建一个配置文件my.cnf:
touch my.cnf
修改配置文件my.cnf:
[mysqld]## 设置server_id,同一局域网中需要唯一server_id=102## 指定不需要同步的数据库名称binlog-ignore-db=mysql## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用log-bin=mall-mysql-slave1-bin## 设置二进制日志使用内存大小(事务)binlog_cache_size=1M## 设置使用的二进制日志格式(mixed,statement,row)binlog_format=mixed## 二进制日志过期清理时间。默认值为0,表示不自动清理。expire_logs_days=7## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致slave_skip_errors=1062## relay_log配置中继日志relay_log=mall-mysql-relay-bin## log_slave_updates表示slave将复制事件写进自己的二进制日志log_slave_updates=1## slave设置为只读(具有super权限的用户除外)read_only=1
修改完配置后重启实例:
docker restart mysql-slave
5、将主从数据库进行连接
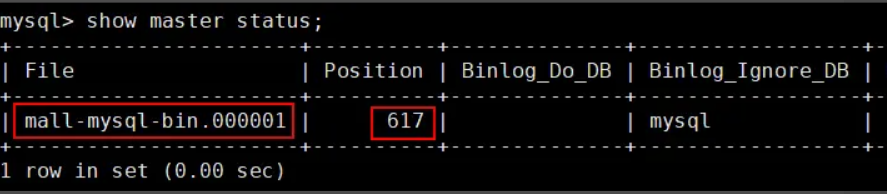
连接到主数据库的mysql客户端,查看主数据库状态:
show master status;
主数据库状态显示如下:
- 进入mysql-slave容器中: ```javascript docker exec -it mysql-slave /bin/bash
- **在容器中使用mysql的登录命令连接到客户端:**```javascriptmysql -uroot -proot
- 在从数据库中配置主从复制: ```javascript change master to master_host=’192.168.6.132’, master_user=’slave’, master_password=’123456’, master_port=3307, master_log_file=’mall-mysql-bin.000001’, master_log_pos=617, master_connect_retry=30;
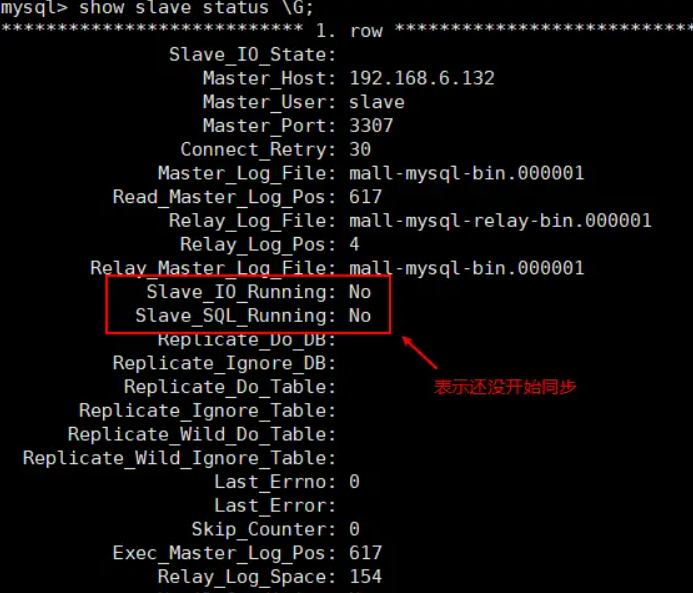
- **主从复制命令参数说明:**- master_host:主数据库的IP地址;- master_port:主数据库的运行端口;- master_user:在主数据库创建的用于同步数据的用户账号;- master_password:在主数据库创建的用于同步数据的用户密码;- master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;- master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;- master_connect_retry:连接失败重试的时间间隔,单位为秒。- **查看主从同步状态:**```javascriptshow slave status \G; 复制代码
- 从数据库状态显示如下:
开启主从同步:
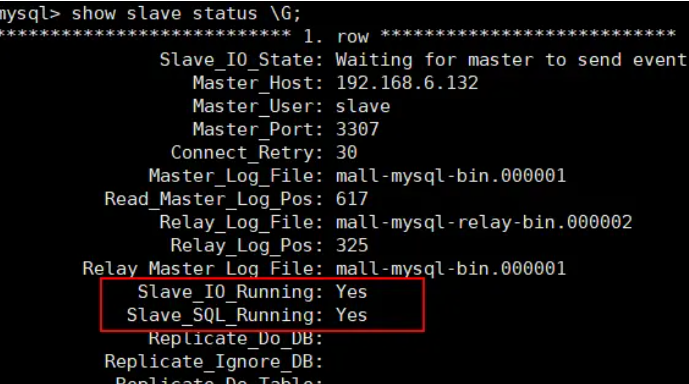
start slave;
查看从数据库状态发现已经同步:
6、主从复制测试
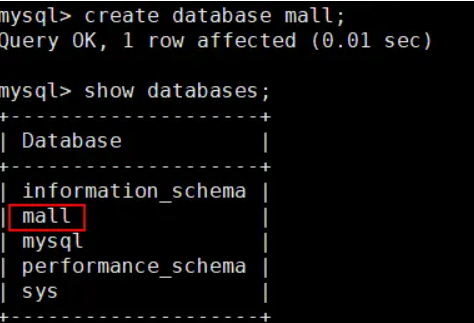
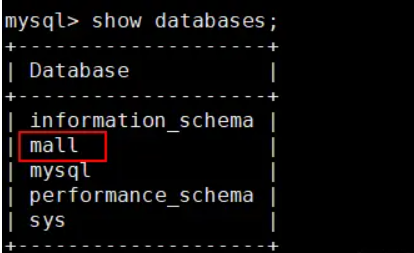
主从复制的测试方法有很多,可以在主实例中创建一个数据库,看看从实例中是否有该数据库,如果有,表示主从复制已经搭建成功。
- 在主实例中创建一个数据库mall;
- 在从实例中查看数据库,发现也有一个mall数据库,可以判断主从复制已经搭建成功。
18、实战示例

若有收获,就点个赞吧
0 人点赞
