一、工作流程分析
全局配置文件 mybatis-Config.xml —> Mapper.xml —> Configuration填充配置类 —> SqlSessionFactory(生成session工厂) —> SqlSession(生成session) —> Executor(执行器) —> StatementHandler —> 数据库
[
](https://blog.csdn.net/qq_40111437/article/details/105274919)
1、Demo示例
/*** 通过 SqlSession.getMapper(XXXMapper.class) 接口方式* @throws IOException*/@Testpublic void testSelect() throws IOException {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);SqlSession session = sqlSessionFactory.openSession(); // ExecutorType.BATCHtry {BlogMapper mapper = session.getMapper(BlogMapper.class);Blog blog = mapper.selectBlogById(1);System.out.println(blog);} finally {session.close();}}
依赖
<!--mysql的JDBC实现--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!--mybatis依赖--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.4.1</version></dependency>
2、解析配置文件并且生成SqlSessionFactory
首先进入构造这个SqlSessionFactory工场的build方法,我们发现它是生成了一个XMLConfigBuilder对象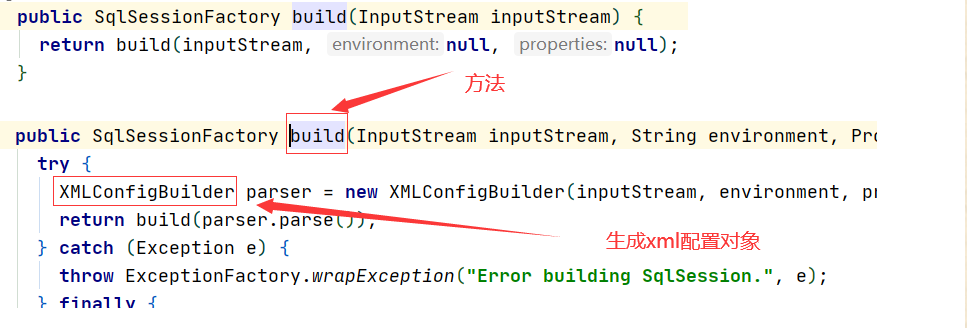
而XMLConfigBuilder对象里面new了一个全局配置对象,也就是我们Mybatis配置文件的Configuration。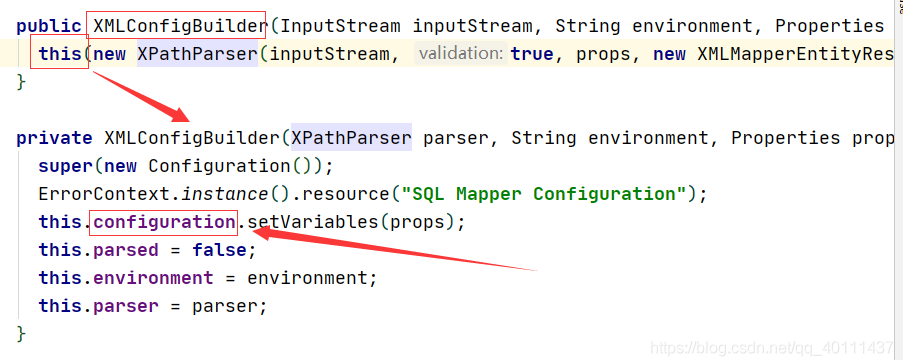
我们再进入这个parser的parse()方法来看看,从if判断我们可以看出这个Mybatis的xml配置文件只能加载一次,否则会丢出异常,然后通过这个XMLConfigBuilder的解析Node方法,把配置文件里面的所有属性以Xnode的形式返回,通过读取根标签configuration开始解析。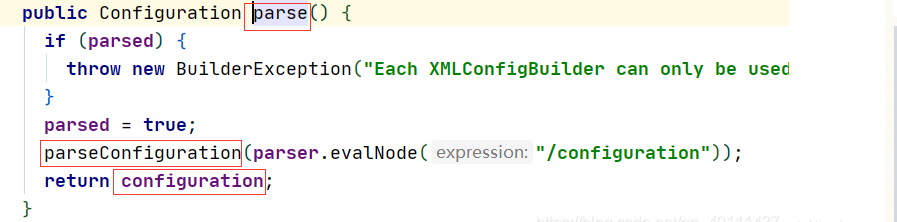
看看parseConfiguration方法,我们发现它是把每个配置文件里的属性解析放在了Configuration的属性中,那下面这些其实也就是把我们的配置文件解析成属性,赋值到Configuration中。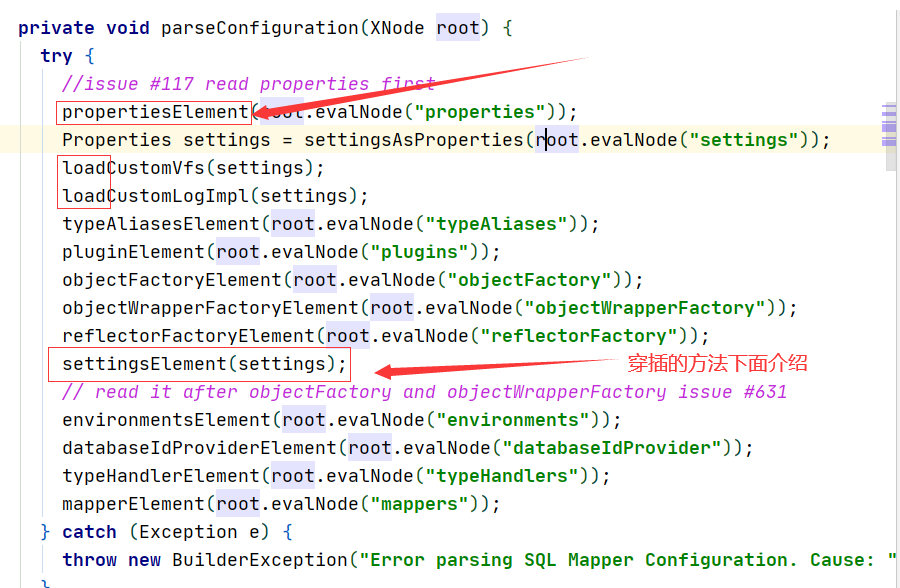
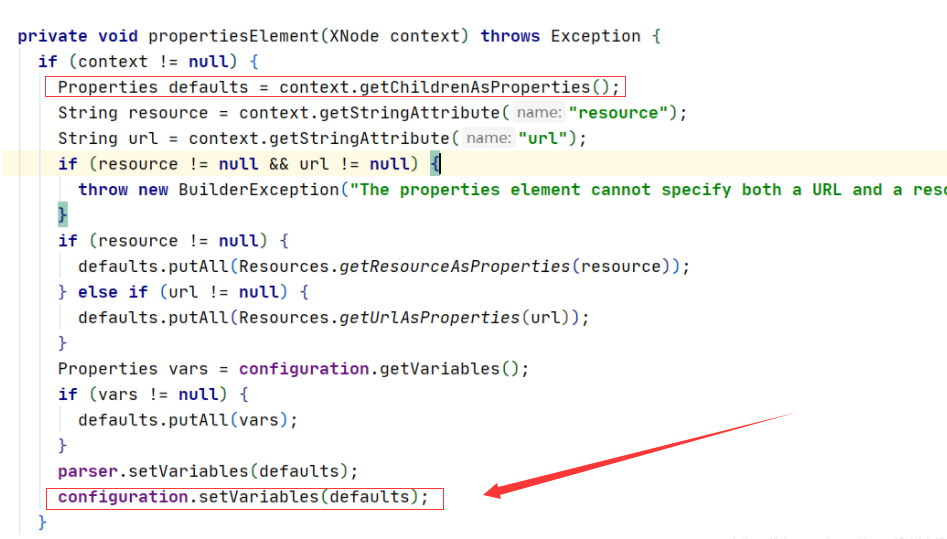
我们发现它设置属性的同时,还有几个load操作,这几个操作是给我们的mybatis开启一些其它功能,比如上面的加载客户端的日志。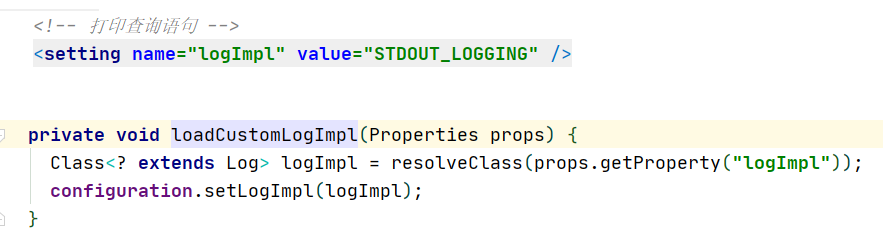
好,解析完这些属性的时候,中间突然插了一个settingElement方法,我们来看看这个方法做了什么。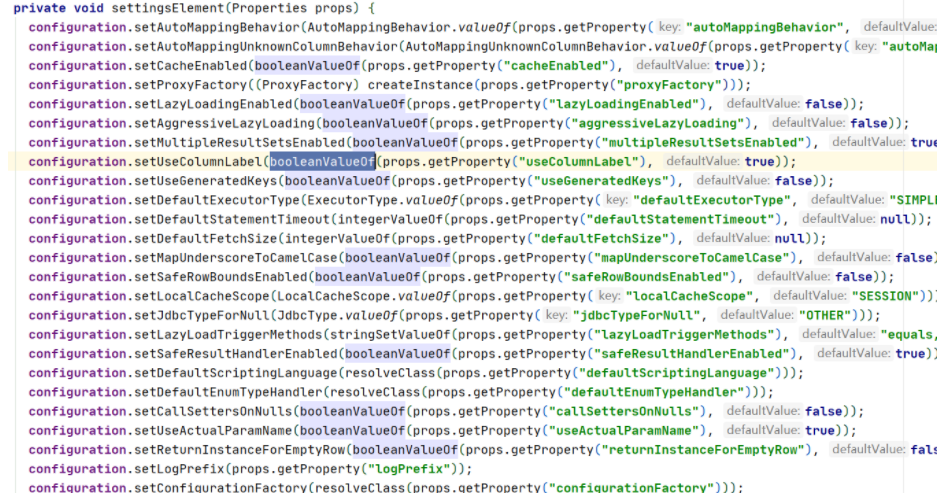
这个方法里面就是设置mybatis给我们开启的功能了,如果你配置文件里面配置了,它就会读取替换,没有开启的就会用它默认的参数,比如延迟加载默认为false,比如缓存开启默认为true等,如果不知道某些值得默认属性得话,我们就可以来这里看看。
打开mybatis中文网也能看到这些配置,看看是不是与上面对应。
再看settingElement方法之后得方法,主要看看mapperElement方法,显然这是解析mapper得方法。
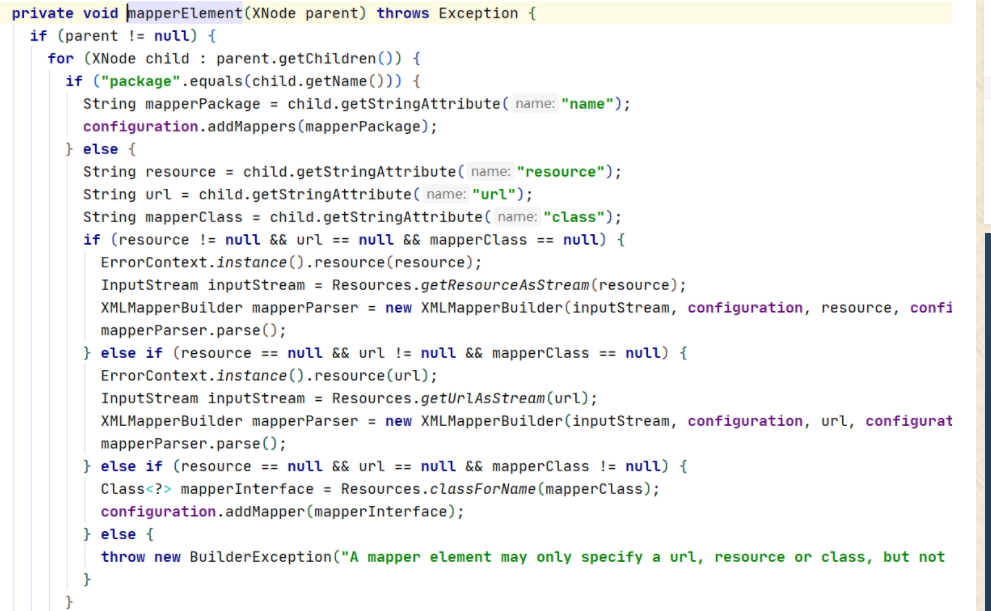
我们常说mybatis查找mapper有几种方式,看到这段代码应该就能记住了,首先代码判断了是否是package标签,这也是我们常用得直接扫描整个包下面得mapper,然后如果不是,就解析下面三种标签,resource(直接指定mapper.xml的相对文件路径),url(直接指定mapper.xml的绝对文件路径),class(直接指定类路径,需要mapper类)。 看看mapper文件的解析方式。
mybatis解析完我们整个sql的标签以后,最终它会产生一个Mappedstatement对象,并把解析出来的,看看里面的属性是不是对应map,sqlsource放的是sql语句,statementType放的是curd标签等,果然,它把我们整个mapper里面的sql变成了一个一个的对象。
再回到mapperParse.parse方法,解析完mapper文件以后,还调用了一个bindMapperForNamespace()方法。
boundType获得那个mapper.xml对应的接口的全路径,然后调用了一个addMapper()方法,把这个mapper接口的全路径传进去。
[
](https://blog.csdn.net/qq_40111437/article/details/105274919)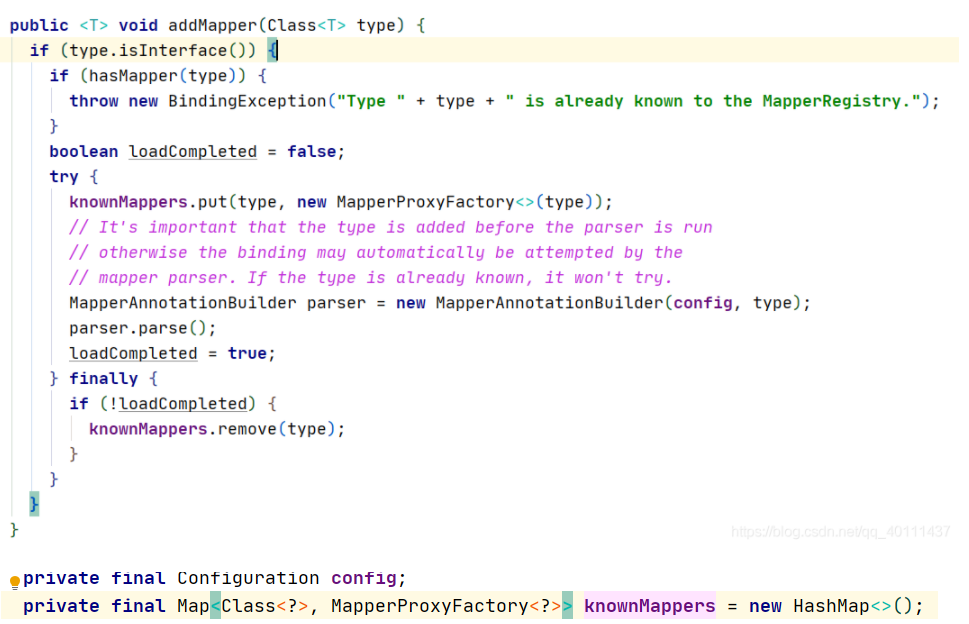
最后,发现它是存了一组这样的键值对,这个mapper的class和这个mapper的代理工厂。
一直走到这里,就发现mybatis已经把我们的配置文件以及mapper.xml都解析完了,并且放在了配置类Configuration里面,最后返回一个DefaultsqlsessionFactory工厂了。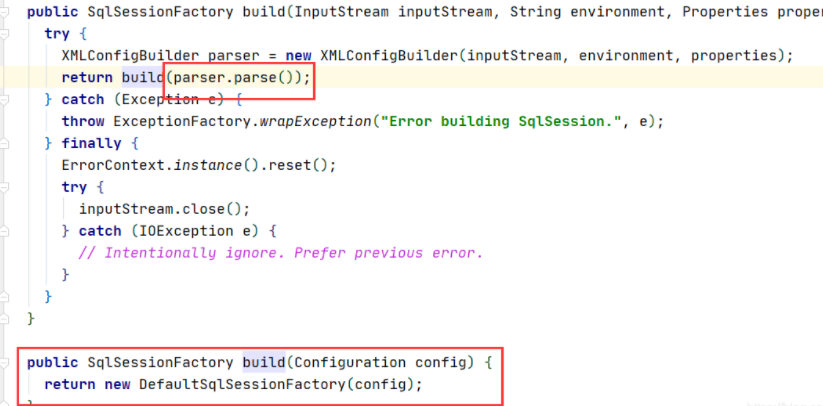
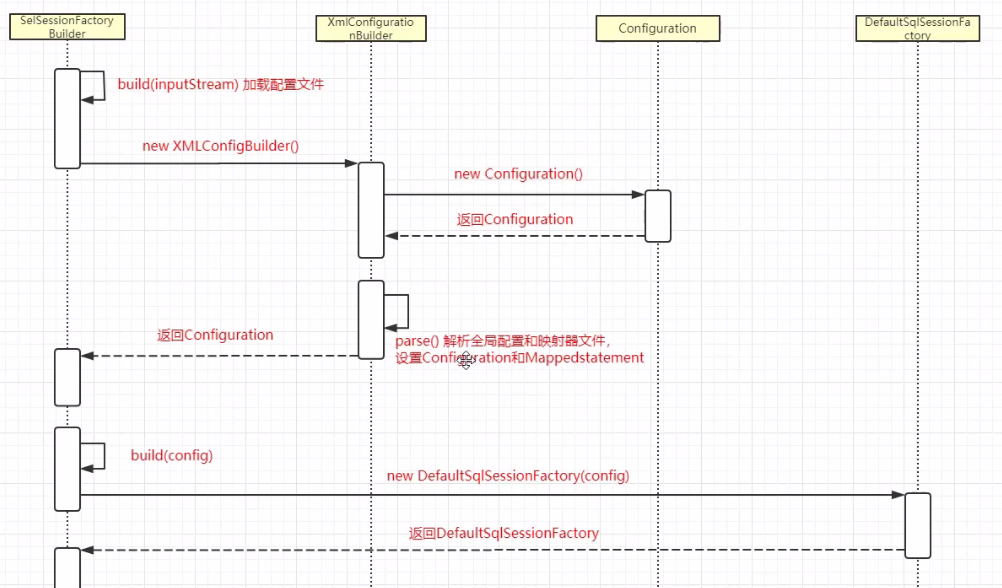
以上总结的 时序图 如下所示:
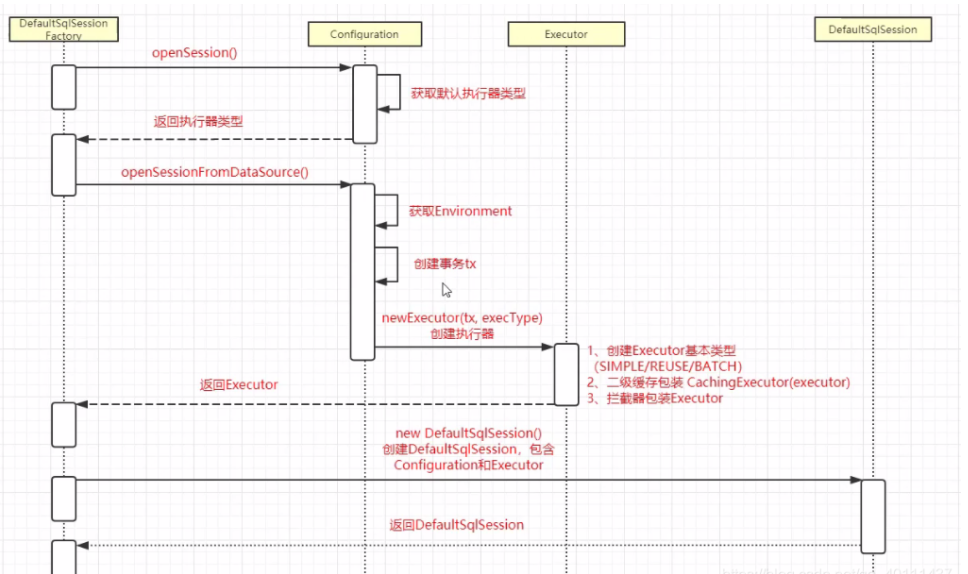
3、SqlSessionFactory生成session会话
通过上一步,我们发现解析完配置文件以后它会返回一个DefaultSqlSessionFactory对象,我们现在看看这个对象是怎么open一个SqlSession的,先跟踪方法。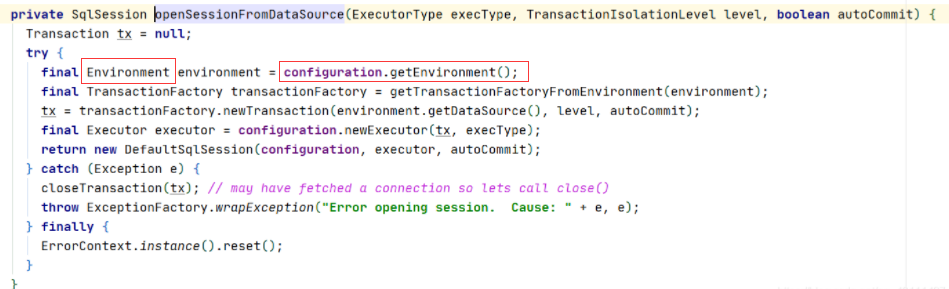
通过这个方法,我们看到,它是从我们之前解析的配置文件里面,拿到了environment对象,同时创建了一个事务,然后又从配置中拿到属性,构造了一个执行器。
所以,mybatis里面的事务和执行器都是在openSession里面创建的,我们重点来看看执行器的构造。
在这里我们可以看到,如果我们没有定义执行器的话,它会默认使用一个simple的执行器,同时为了防止有人手贱,设置一个执行器并且赋值null,所以加了一层null判断。
SimpleExecutor:封装了jdbc的statement,使用完后直接关闭。
ReuseExecutor:封装了jdbc的statement,使用完后不直接关闭,放在一个缓存的map里面等待下次使用。
BatchExecutor:封装了jdbc的statement,有缓存功能,同时支持批量操作。
[
](https://blog.csdn.net/qq_40111437/article/details/105274919)
还记得我们之前说到了mybatis的一级缓存和二级缓存,说过了一级缓存是放在baseExecutor中。
MyBatis系列之Mybatis缓存深入了解
可以看看这个执行器的类图,发现它们都是BaseExcutor的子实现类,里面有几个抽象的增删改查方法,如doUpdate(),doQuery(),留给子类去实现,典型的模板模式。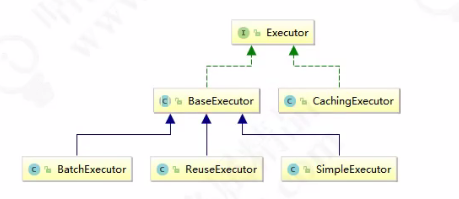
再回到这个方法,添加完执行器以后,它用包装类把这个Executor包装了一下,这里是为了二级缓存的实现,之后还调用了一个插件拦截器链的pluginAll方法,里面是把每个插件都关联一下这个执行器,最后返回这个执行器。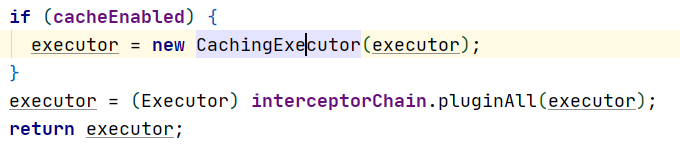
最后又回到一开始那个方法,返回了一个带有Configruation,executor的defaltSqlSession 。
4、Session获取Mapper
上一步我们已经拿到了一个DefaltSqlSession,现在我们再来看看它是怎么得到一个可以调用curd的mapper的,看看它具体做了哪些操作。
看到这里是不是恍然大悟,我们第一次获得一个defaltSqlSessionFactory的时候,最后一步是不是把接口类和对应的代理工厂绑定在了一起,而这里就是通过这个接口类来获取这个对应的工厂,并且把sqlSession作为参数来new一个实例,最后,它又把这个实例传给了另一个newInstance方法,没错,非常明显的jdk动态代理,接口的类加载器,接口和被代理的对象。<br />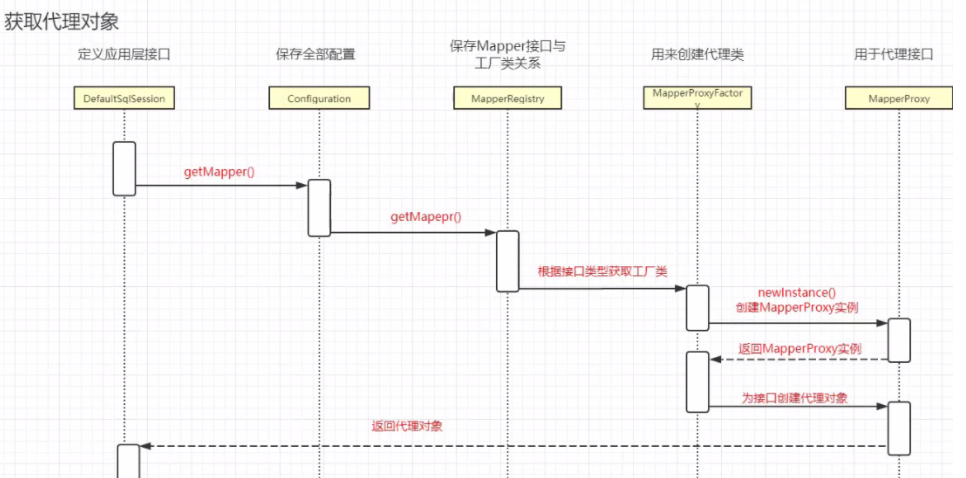
5、代理对象MapperProxy执行具体的sql操作
对最后一行代码进行调试发现,怎么直接去了接口方法,😂😂,当然了!代理对象调用的方法不都在invoke里面吗,此时当然是去看mapperProxy的invoke方法了。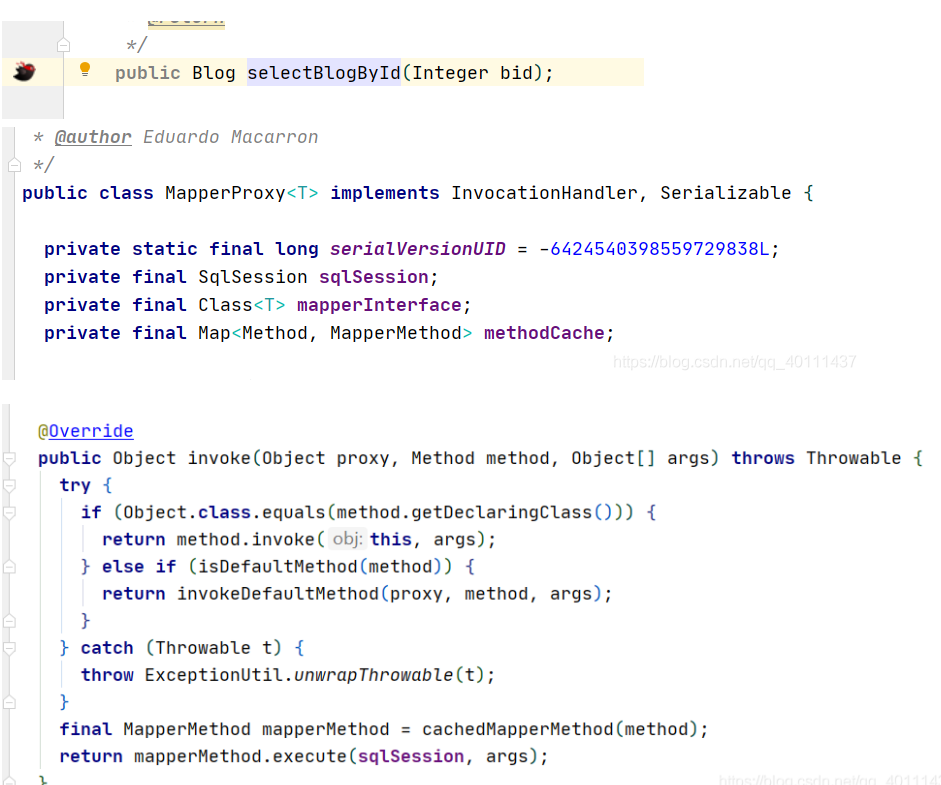
看这个方法,第一步,它首先会去看看它调用的是不是object本身的方法, 如果是就直接调用这个方法;第二步,判断你是不是接口中的defalt方法(jdk1.8中新加了很多接口中得defalut方法),如果是就走下面这个方法,有兴趣的自己可以去看看,否则,它会先拿到一个mapperMethod对象,然后用这个对象调用这个方法,所以重点又来了,这是个啥对象。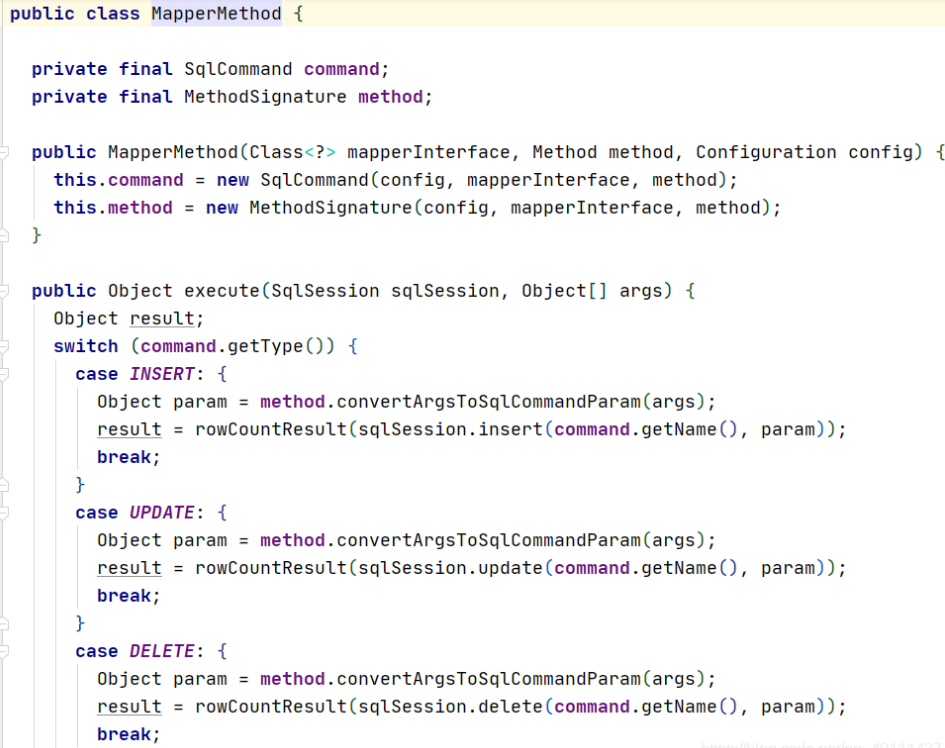
来了来了,就在这里了,判断标签并且调用方法。
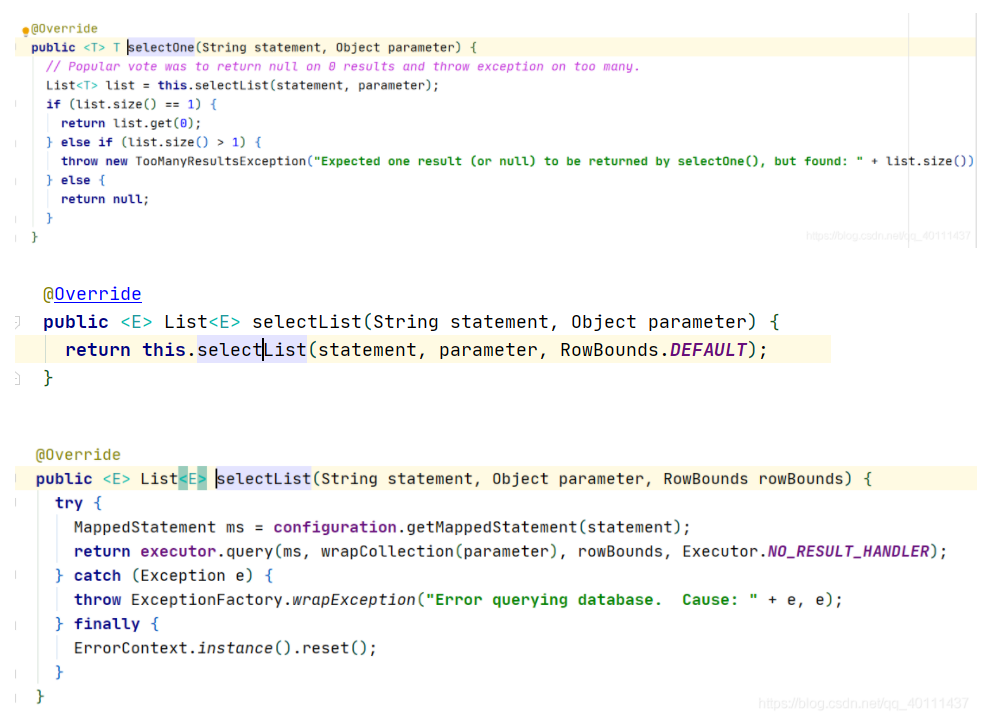
mappedStatement对象,我们第一步封装sql使用的对象,终于在这里拿到了,通过方法的名字拿到了这个方法,也就是这段sql对应的sql对象,然后用执行器执行query方法,因为开启了缓存,我们进入缓存的执行器看看。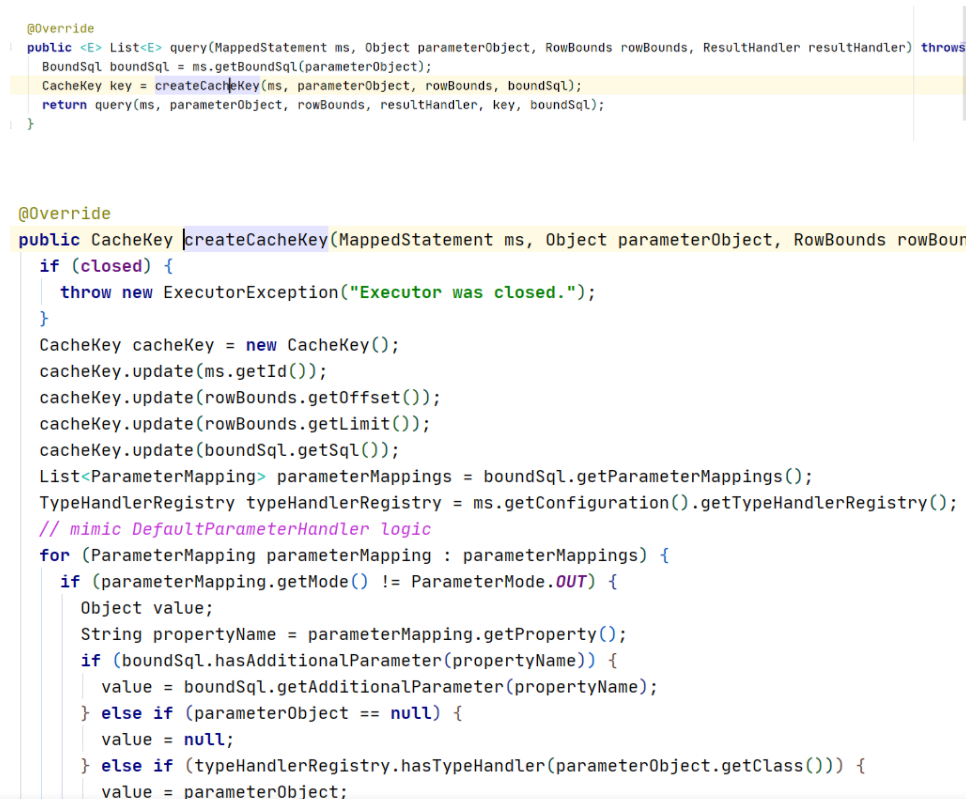
原来,缓存保存一个sql,保存了这个sql的id,分页参数,sql语句以及传参值,这样缓存就能够确保找到这个对应的sql了,好,继续往下走看到这个query方法。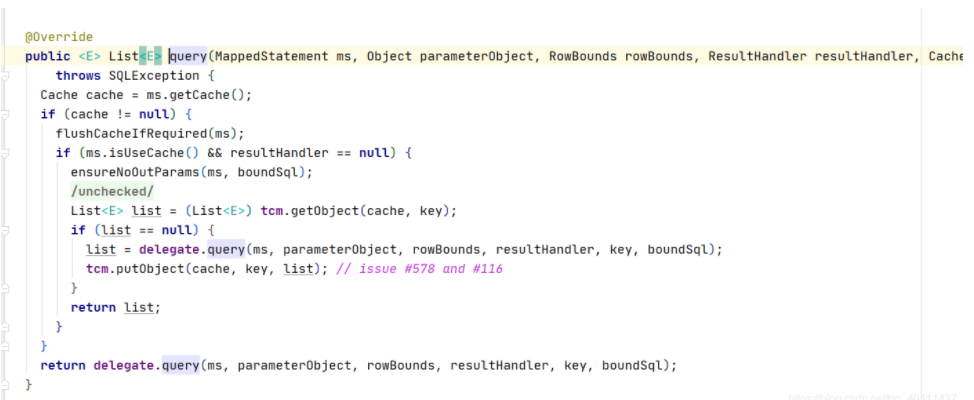
从这一步可以看出,它是先从我们的二级缓存中取这个值,通过我们之前保存的参数,如果取不到,就走下面的方法。 
如果没有二级缓存,它就会走一级缓存中的方法,也就是baseExecutor中的query方法,其中走数据库的方法就是上面那个queryFromDatabase了,终于要揭开他的真面目了。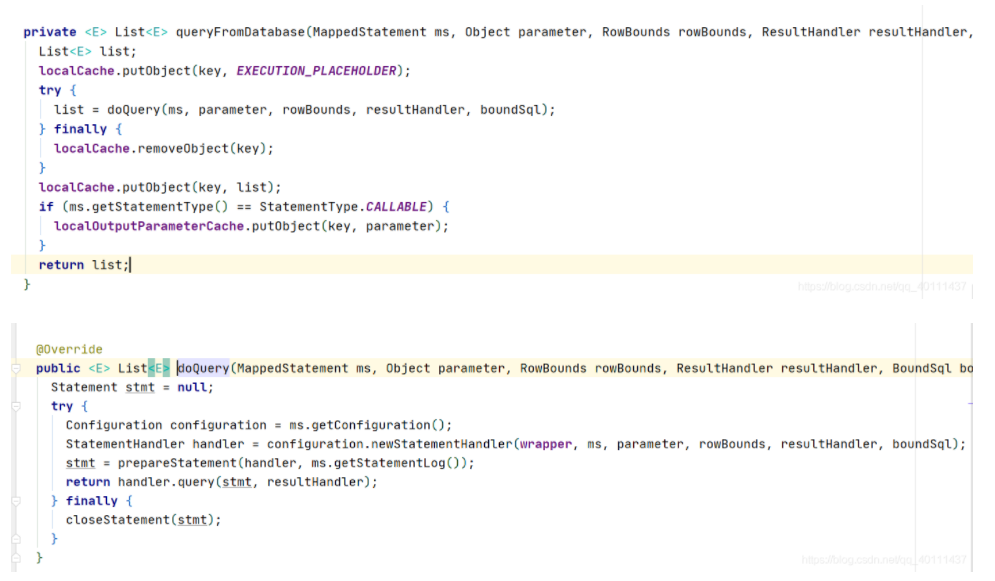
我们看看默认的simpleExecutor执行器是怎么执行的。

发现它创建preparedstatement的时候,先把这些参数赋值,比如配置文件,执行器,sql对象以及分页参数,同时最后还构造了两个handler,一个是参数处理器,一个是结果处理器。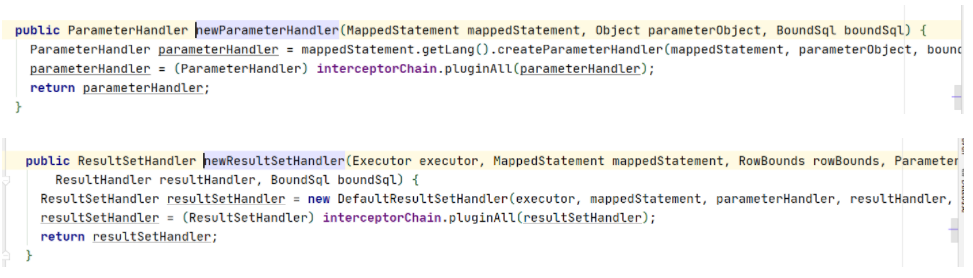
到目前为止,我们已经发现了mybatis里面的四个handler了,分别是executor,执行器的拦截,statement,jdbc的拦截,parameter,参数的拦截以及resultset,返回结果集的拦截。
看到了,下面一个query方法,就是prepareStatement的execute方法了,操作数据库,并且把返回的结果集传给resultSetHandler来处理。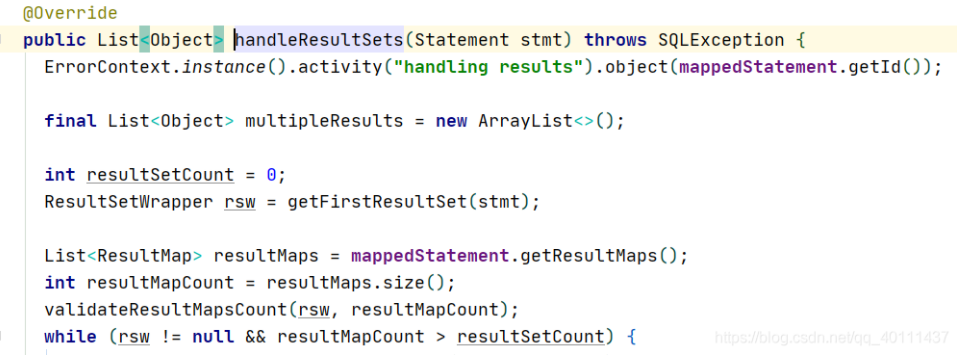
然后就是返回结果集,转换成java对象的操作了。
好,以上的流程就是mybatis怎么通过配置文件和mapper文件执行sql的整体过程了,有兴趣的小伙伴可以继续去看看最后是怎么操作把结果集转换成java对象的,无非就是反射,然后从resultType里面取到类型,然后赋值等一些列操作了。
[
](https://blog.csdn.net/qq_40111437/article/details/105274919)
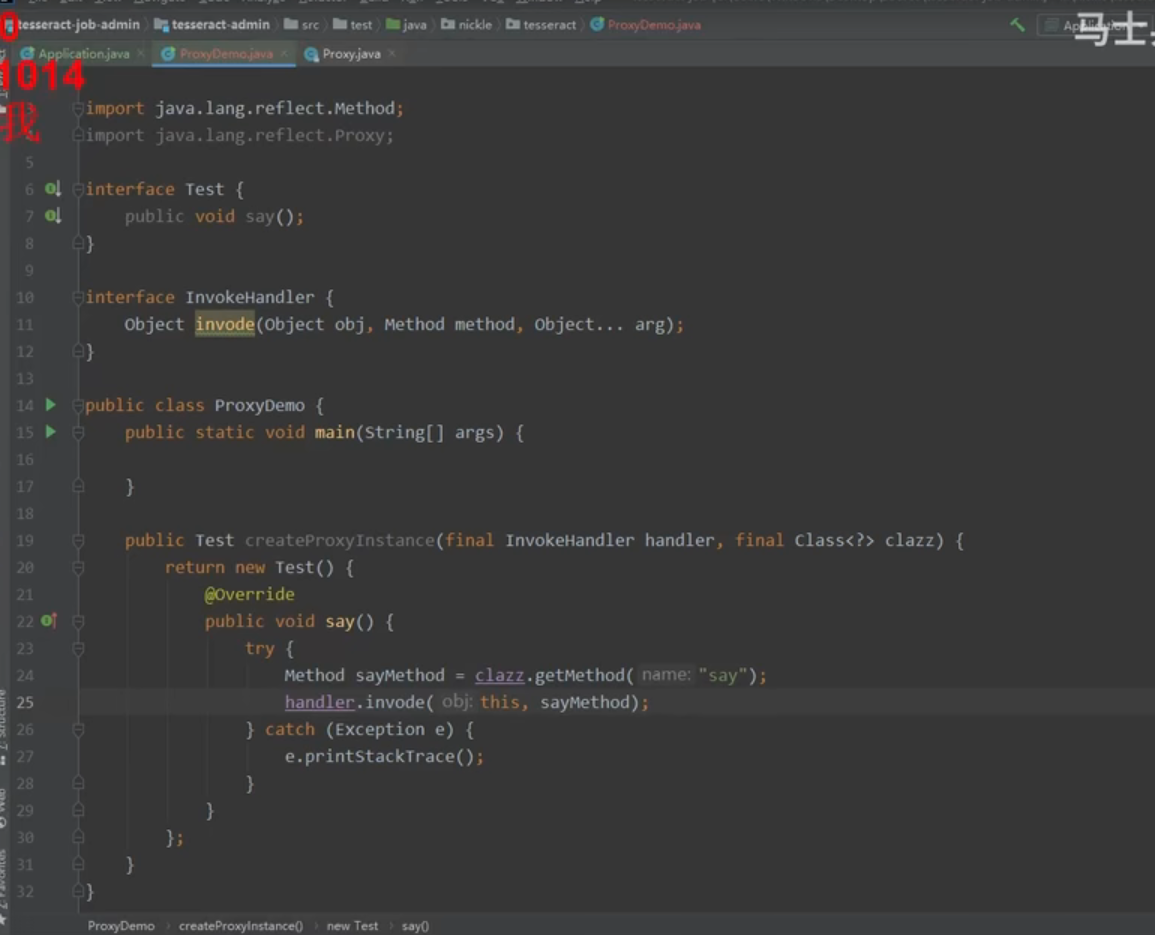
二、JDK动态代理
接口无法实例化 所以采用jdk动态代理 实例化接口
Proxy.newProxyInstance 方法生成动态代理类 invoke() 可以调用类的方法
程序执行时使用java.lang.reflect包中Proxy类与InvocationHandler接口动态地生成一个实现代理接口的匿名代理类及其对象,无论调用代理对象哪个方法,最终都会执行invoke方法。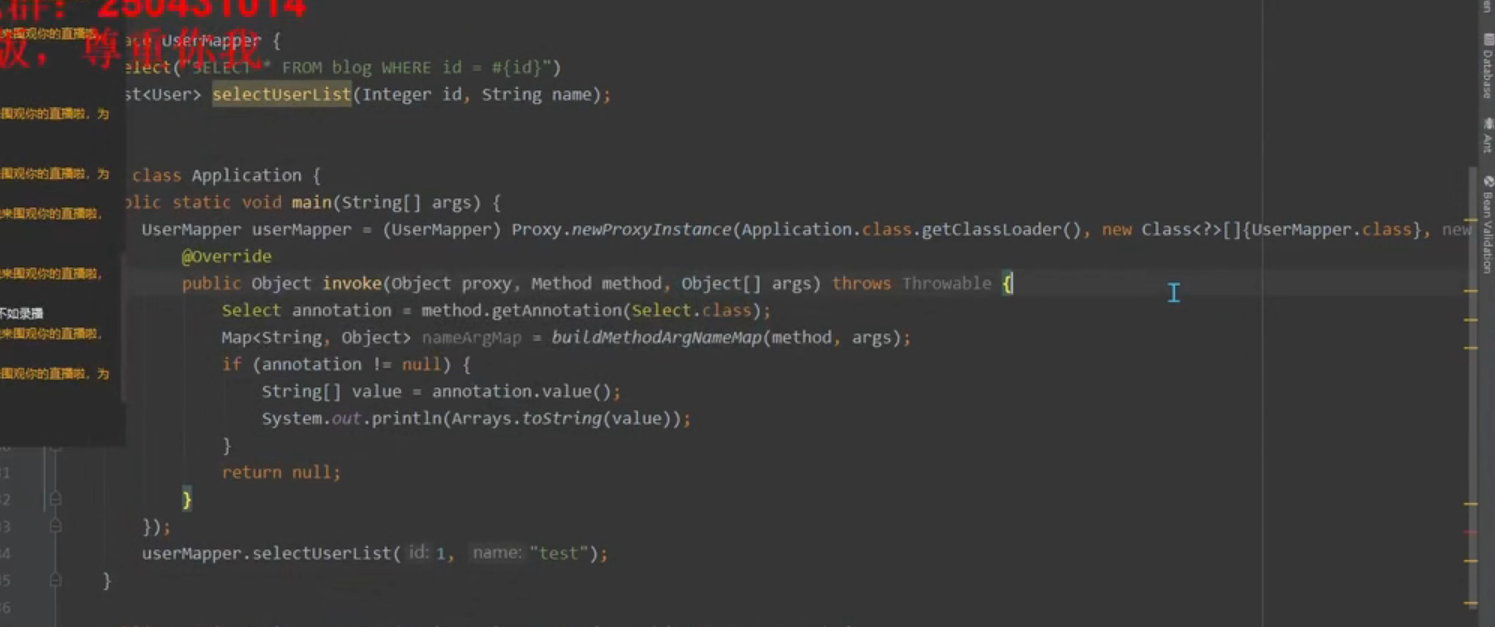
JDBC ,mybatis, Hibernate, SpringJDBC区别
三、要点
1、容器Configuration
Configuration 像是Mybatis的总管,Mybatis的所有配置信息都存放在这里,此外,它还提供了设置这些配置信息的方法。Configuration可以从配置文件里获取属性值,也可以通过程序直接设置。
用一句话概述Configuration,他类似Spring中的容器概念,而且是中央容器级别,存储的Mybatis运行所需要的大部分东西。
2、动态SQL模板
使用mybatis,我们大部分时间都在干嘛?在XML写SQL模板,或者在接口里写SQL模板
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!-- mapper:根标签,namespace:命名空间,命名空间唯一 --><mapper namespace="UserMapper"><select id="selectUser" resultType="com.wqd.model.User">select * from user where id= #{id}</select></mapper>
或者注解
@Mapperpublic interface UserMapper {@Insert("insert into user( name, age) " + "values(#{user.name}, #{user.age})")void save(@Param("user") User user);@Select("select * from user where id=#{id}")User getById(@Param("id")String id);}
2.1、MappedStatement (映射器)
- 就像使用Spring,我们写的Controller类对于Spring 框架来说是在定义BeanDefinition一样。
- 当我们在XML配置,在接口里配置SQL模板,都是在定义Mybatis的域值MappedStatement
一个SQL模板对应MappedStatement
mybatis 在启动时,就是把你定义的SQL模板,解析为统一的MappedStatement对象,放入到容器Configuration中。每个MappedStatement对象有一个ID属性。这个id同我们平时mysql库里的id差不多意思,都是唯一定位一条SQL模板,这个id 的命名规则:命名空间+方法名
Spring的BeanDefinition,Mybatis的MappedStatement
2.2、两种解析方式
同Spring一样,我们可以在xml定义Bean,也可以java类里配置。涉及到两种加载方式。
xml方式的解析:
提供了XMLConfigBuilder组件,解析XML文件,这个过程既是Configuration容器创建的过程,也是MappedStatement解析过程。
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);Configuration config = parser.parse()
与Spring使用时:
会注册一个MapperFactoryBean,在MapperFactoryBean在实例化,执行到afterPropertiesSet()时,触发MappedStatement的解析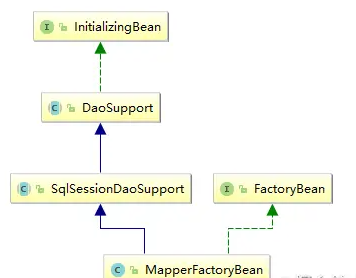
最终会调用Mybatis提供的一MapperAnnotationBuilder 组件,从其名字也可以看出,这个是处理注解形式的MappedStatement
3、SqlSession
3.1、基本介绍
有了SQL模板,传入参数,从数据库获取数据,这就是SqlSession干的工作。
SqlSession代表了我们通过Mybatis与数据库进行的一次会话。使用Mybatis,我们就是使用SqlSession与数据库交互的。
我们把SQL模板的id,即MappedStatement 的id 与 参数告诉SqlSession,SqlSession会根据模板id找到对应MappedStatement ,然后与数据交互,返回交互结果
User user = sqlSession.selectOne("com.wqd.dao.UserMapper.selectUser", 1);
3.2、分类
- DefaultSqlSession:最基础的sqlsession实现,所有的执行最终都会落在这个DefaultSqlSession上,线程不安全
- SqlSessionManager : 线程安全的Sqlsession,通过ThreadLocal实现线程安全。
Sqlsession有点像门面模式,SqlSession是一个门面接口,其内部工作是委托Executor 执行器完成的。
3.3、Executor
public class DefaultSqlSession implements SqlSession {private Configuration configuration;private Executor executor;//就是他}
我们调用SqlSession的方法,都是由Executor完成的。
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {try {MappedStatement ms = configuration.getMappedStatement(statement);----交给Executorexecutor.query(ms, wrapCollection(parameter), rowBounds, handler);} catch (Exception e) {throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);} finally {ErrorContext.instance().reset();}}
4、Mapper
4.1、存在的意义
UserMapper userMapper = sqlsession.getMapper(UserMapper.class);User user = userMapper.getById("51");
Mapper的意义在于,让使用者可以像调用方法一样执行SQL。
区别于,需要显示传入SQL模板的id,执行SQL的方式。
User user = sqlSession.selectOne("com.wqd.dao.UserMapper.getById", 1);
4.2、工作原理
Mapper通过代理机制,实现了这个过程。
1、MapperProxyFactory: 为我们的Mapper接口创建代理。
- 单独使用Mybatis时,Mybatis会调用MapperRegistry.addMapper()方法,为UserDao接口,创建new MapperProxyFactory(type)
- 当和Spring一起使用时,MapperScannerRegistrar组件触发ClassPathMapperScanner组件的doScan方法将UserDao的BeanDefinition 的BeanClass设置为MapperProxyFactory, 在走SpringBean实例化时,就从MapperProxyFactory里获取UserDao的实例对象(即代理对象)。
```java
public T newInstance(SqlSession sqlSession) {
final MapperProxymapperProxy = new MapperProxy (sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy); }
protected T newInstance(MapperProxy
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
MapperProxyFactory通过JDK动态代理技术,在内存中帮我们创建一个代理类出来。(虽然你看不到,但他确实存在)2、MapperProxy:就是上面创建代理时的增强```javapublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {try {if (Object.class.equals(method.getDeclaringClass())) {return method.invoke(this, args);} else if (isDefaultMethod(method)) {return invokeDefaultMethod(proxy, method, args);}} catch (Throwable t) {throw ExceptionUtil.unwrapThrowable(t);}--------------------------final MapperMethod mapperMethod = cachedMapperMethod(method);return mapperMethod.execute(sqlSession, args);}
3、MapperMethod
一个业务方法在执行时,会被封装成MapperMethod, MapperMethod 执行时,又会去调用了Sqlsession
public Object execute(SqlSession sqlSession, Object[] args) {Object result;switch (command.getType()) {case SELECT:...result = sqlSession.selectOne(command.getName(), param);...break;....}
绕了一周,终究回到了最基本的调用方式上。
result = sqlSession.selectOne(command.getName(), param);User user = sqlSession.selectOne("com.wqd.dao.UserMapper.getById", 1);
总结下:
- 最基本用法=sqlsession.selectOne(statement.id,参数)
- Mapper=User代理类getById—-》MapperProxy.invoke方法—-》MapperMethod.execute()—-》sqlsession.selectOne(statement.id,参数)
5、缓存
5.1、一级缓存
原来就是HashMap的封装
public class PerpetualCache implements Cache {private String id;private Map<Object, Object> cache = new HashMap<Object, Object>();public PerpetualCache(String id) {this.id = id;}}
在什么位置?作为BaseExecutor的一个属性存在。
public abstract class BaseExecutor implements Executor {protected BaseExecutor(Configuration configuration, Transaction transaction) {this.localCache = new PerpetualCache("LocalCache");}}
Executor上面说过,Sqlsession的能力其实是委托Executor完成的.Executor作为Sqlsession的一个属性存在。
所以:MyBatis一级缓存的生命周期和SqlSession一致。
5.2、二级缓存
基本信息
二级缓存在设计上相对与一级缓存就比较复杂了。
以xml配置为例,二级缓存需要配置开启,并配置到需要用到的namespace中。
<setting name="cacheEnabled" value="true"/>
<mapper namespace="mapper.StudentMapper"><cache/></mapper>
同一个namespace下的所有MappedStatement共用同一个二级缓存。二级缓存的生命周期跟随整个应用的生命周期,同时二级缓存也实现了同namespace下SqlSession数据的共享。
二级缓存配置开启后,其数据结构默认也是PerpetualCache。这个和一级缓存的一样。
但是在构建二级缓存时,mybatis使用了一个典型的设计模式装饰模式,对PerpetualCache进行了一层层的增强,使得二级缓存成为一个被层层装饰过的PerpetualCache,每装饰一层,就有不同的能力,这样一来,二级缓存就比一级缓存丰富多了。
装饰类有:
- LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志
- LruCache:采用了Lru算法的Cache实现,移除最近最少使用的Key/Value
- ScheduledCache: 使其具有定时清除能力
- BlockingCache: 使其具有阻塞能力
层层装饰private Cache setStandardDecorators(Cache cache) {try {MetaObject metaCache = SystemMetaObject.forObject(cache);if (size != null && metaCache.hasSetter("size")) {metaCache.setValue("size", size);}if (clearInterval != null) {cache = new ScheduledCache(cache);((ScheduledCache) cache).setClearInterval(clearInterval);}if (readWrite) {cache = new SerializedCache(cache);}cache = new LoggingCache(cache);cache = new SynchronizedCache(cache);if (blocking) {cache = new BlockingCache(cache);}return cache;} catch (Exception e) {throw new CacheException("Error building standard cache decorators. Cause: " + e, e);}}
如何工作
二级缓存的工作原理,还是用到装饰模式,不过这次装饰的Executor。使用CachingExecutor去装饰执行SQL的Executor
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {executorType = executorType == null ? defaultExecutorType : executorType;executorType = executorType == null ? ExecutorType.SIMPLE : executorType;Executor executor;if (ExecutorType.BATCH == executorType) {executor = new BatchExecutor(this, transaction);} else if (ExecutorType.REUSE == executorType) {executor = new ReuseExecutor(this, transaction);} else {executor = new SimpleExecutor(this, transaction);}if (cacheEnabled) {executor = new CachingExecutor(executor);//装饰} executor = (Executor) interceptorChain.pluginAll(executor);return executor;}
当执行查询时,先从二级缓存中查询,二级缓存没有时才去走Executor的查询
private Executor delegate;private TransactionalCacheManager tcm = new TransactionalCacheManager();public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)throws SQLException {Cache cache = ms.getCache();....List<E> list = (List<E>) tcm.getObject(cache, key);if (list == null) {list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);tcm.putObject(cache, key, list);// issue #578 and #116}return list;}}return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
其中TransactionalCacheManager 属性为二级缓存提供了事务能力。
public void commit(boolean required) throws SQLException {delegate.commit(required);tcm.commit();也就是事务提交时才会将数据放入到二级缓存中去}
总结下二级缓存
- 二级缓存是层层装饰
- 二级缓存工作原理是装饰普通执行器
- 装饰执行器使用TransactionalCacheManager为二级缓存提供事务能力
6、插件
一句话总结mybaits插件:代理,代理,代理,还是代理。
Mybatis的插件原理也是动态代理技术。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {..executor = new SimpleExecutor(this, transaction);....if (cacheEnabled) {executor = new CachingExecutor(executor);}插件的入口executor = (Executor) interceptorChain.pluginAll(executor);return executor;}InterceptorChainpublic Object pluginAll(Object target) {for (Interceptor interceptor : interceptors) {target = interceptor.plugin(target);}return target;}
以分页插件为例,
创建完Executor后,会执行插件的plugn方法,插件的plugn会调用Plugin.wrap方法,在此方法中我们看到了我们属性的JDK动态代理技术。创建Executor的代理类,以Plugin为增强。
QueryInterceptorpublic Object plugin(Object target) {return Plugin.wrap(target, this);}public class Plugin implements InvocationHandler {public static Object wrap(Object target, Interceptor interceptor) {Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);Class<?> type = target.getClass();Class<?>[] interfaces = getAllInterfaces(type, signatureMap);if (interfaces.length > 0) {return Proxy.newProxyInstance(type.getClassLoader(),interfaces,new Plugin(target, interceptor, signatureMap));}return target;}}
最终的执行链:Executor代理类方法—》Plugin.invoke方法—》插件.intercept方法—》Executor类方法

若有收获,就点个赞吧
0 人点赞
