一、基础学习
1、原由
在变量、数组、对象和集合中存储的数据是暂时存在的,一旦程序结束它们就会丢失。为了能够永久地保存程序创建的数据,需要将其保存到磁盘文件中,这样就可以在其他程序中使用它们。
例如,我们平时用的 Office 软件,对于 Word、Excel 和 PPT 文件,我们需要打开文件并读取这些文本,和编辑输入一些文本,这都需要利用输入和输出的功能。
2、输入流与输出流
输入输出的方向是针对程序而言,向程序中读入数据,就是输入流;从程序中向外写出数据,就是输出流。
简单来讲:
你编写了一个java程序,
你用这个java程序从你的电脑上读取文件,就是输入流;
你把你所写的java程序的数据传递给某个文件,就是输出流;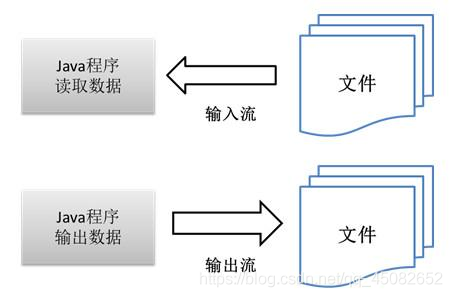
3、输入流
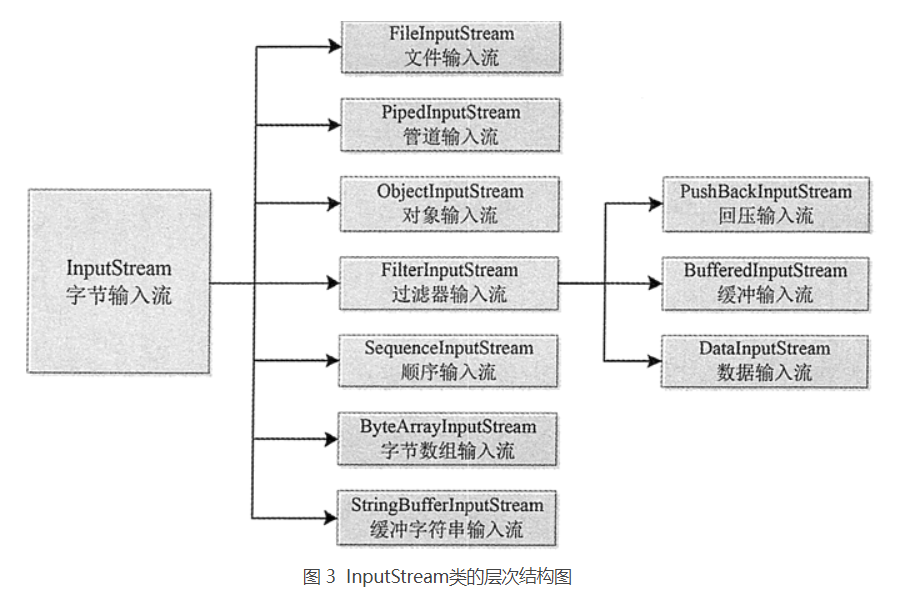
Java 流相关的类都封装在 java.io 包中,而且每个数据流都是一个对象。所有输入流类都是 InputStream 抽象类(字节输入流)和 Reader 抽象类(字符输入流)的子类。其中 InputStream 类是字节输入流的抽象类,是所有字节输入流的父类,其层次结构如图 3 所示。
InputStream 类中所有方法遇到错误时都会引发 IOException 异常。如下是该类中包含的常用方法。
| 名称 | 作用 |
|---|---|
| int read() | 从输入流读入一个 8 字节的数据,将它转换成一个 0~ 255 的整数,返回一个整数,如果遇到输入流的结尾返回 -1 |
| int read(byte[] b) | 从输入流读取若干字节的数据保存到参数 b 指定的字节数组中,返回的字节数表示读取的字节数,如果遇到输入流的结尾返回 -1 |
| int read(byte[] b,int off,int len) | 从输入流读取若干字节的数据保存到参数 b 指定的字节数组中,其中 off 是指在数组中开始保存数据位置的起始下标,len 是指读取字节的位数。返回的是实际读取的字节数,如果遇到输入流的结尾则返回 -1 |
| void close() | 关闭数据流,当完成对数据流的操作之后需要关闭数据流 |
| int available() | 返回可以从数据源读取的数据流的位数。 |
| skip(long n) | 从输入流跳过参数 n 指定的字节数目 |
| boolean markSupported() | 判断输入流是否可以重复读取,如果可以就返回 true |
| void mark(int readLimit) | 如果输入流可以被重复读取,从流的当前位置开始设置标记,readLimit 指定可以设置标记的字节数 |
| void reset() | 使输入流重新定位到刚才被标记的位置,这样可以重新读取标记过的数据 |
4、输出流
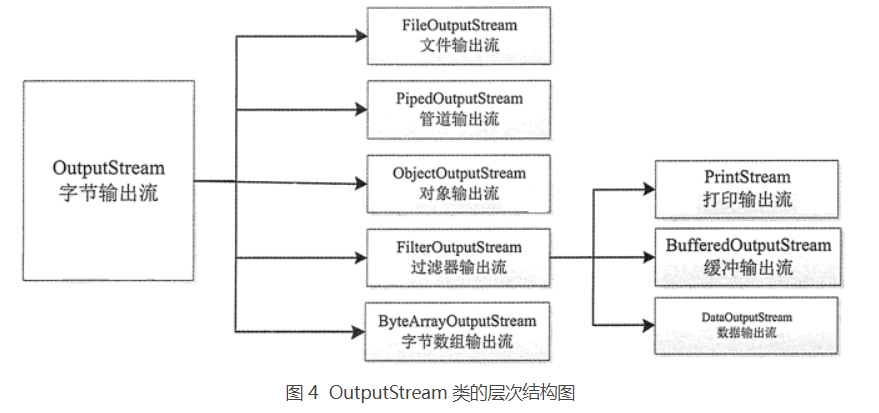
在 Java 中所有输出流类都是 OutputStream 抽象类(字节输出流)和 Writer 抽象类(字符输出流)的子类。其中 OutputStream 类是字节输出流的抽象类,是所有字节输出流的父类,其层次结构如图 4 所示。
OutputStream 类是所有字节输出流的超类,用于以二进制的形式将数据写入目标设备,该类是抽象类,不能被实例化。OutputStream 类提供了一系列跟数据输出有关的方法,如下所示。
| 名称 | 作用 |
|---|---|
| int write(b) | 将指定字节的数据写入到输出流 |
| int write (byte[] b) | 将指定字节数组的内容写入输出流 |
| int write (byte[] b,int off,int len) | 将指定字节数组从 off 位置开始的 len 字节的内容写入输出流 |
| close() | 关闭数据流,当完成对数据流的操作之后需要关闭数据流 |
| flush() | 刷新输出流,强行将缓冲区的内容写入输出流 |
5、java系统流
每个 Java 程序运行时都带有一个系统流,系统流对应的类为 java.lang.System。Sytem 类封装了 Java 程序运行时的 3 个系统流,分别通过 in、out 和 err 变量来引用。这 3 个系统流如下所示:
- System.in:标准输入流,默认设备是键盘。
- System.out:标准输出流,默认设备是控制台。
- System.err:标准错误流,默认设备是控制台。
以上变量的作用域为 public 和 static,因此在程序的任何部分都不需引用 System 对象就可以使用它们。
例 1
下面的程序演示了如何使用 System.in 读取字节数组,使用 System.out 输出字节数组。
public class Test01 {public static void main(String[] args) {byte[] byteData = new byte[100]; // 声明一个字节数组System.out.println("请输入英文:");try {System.in.read(byteData);} catch (IOException e) {e.printStackTrace();}System.out.println("您输入的内容如下:");for (int i = 0; i < byteData.length; i++) {System.out.print((char) byteData[i]);}}}
该程序的运行结果如下所示:
System.in 是 InputStream 类的一个对象,因此上述代码的 System.in.read() 方法实际是访问 InputStream 类定义的 read() 方法。该方法可以从键盘读取一个或多个字符。对于 System.out 输出流主要用于将指定内容输出到控制台。
System.out 和 System.error 是 PrintStream 类的对象。因为 PrintStream 是一个从 OutputStream 派生的输出流,所以它还执行低级别的 write() 方法。因此,除了 print() 和 println() 方法可以完成控制台输出以外,System.out 还可以调用 write() 方法实现控制台输出。
write() 方法的简单形式如下:
void write(int byteval) throws IOException
该方法通过 byteval 参数向文件写入指定的字节。在实际操作中,print() 方法和 println() 方法比 write() 方法更常用。
6、java字符编码
计算机中,任何的文字都是以指定的编码方式存在的,在 Java 程序的开发中最常见的是 ISO8859-1、GBK/GB2312、Unicode、 UTF 编码。
Java 中常见编码说明如下:
- ISO8859-1:属于单字节编码,最多只能表示 0~255 的字符范围。
- GBK/GB2312:中文的国标编码,用来表示汉字,属于双字节编码。GBK 可以表示简体中文和繁体中文,而 GB2312 只能表示简体中文。GBK 兼容 GB2312。
- Unicode:是一种编码规范,是为解决全球字符通用编码而设计的。UTF-8 和 UTF-16 是这种规范的一种实现,此编码不兼容 ISO8859-1 编码。Java 内部采用此编码。
- UTF:UTF 编码兼容了 ISO8859-1 编码,同时也可以用来表示所有的语言字符,不过 UTF 编码是不定长编码,每一个字符的长度为 1~6 个字节不等。一般在中文网页中使用此编码,可以节省空间。
在程序中如果处理不好字符编码,就有可能出现乱码问题。例如现在本机的默认编码是 GBK,但在程序中使用了 ISO8859-1 编码,则就会出现字符的乱码问题。就像两个人交谈,一个人说中文,另外一个人说英语,语言不同就无法沟通。为了避免产生乱码,程序编码应与本地的默认编码保持一致。
本地的默认编码可以使用 System 类查看。Java 中 System 类可以取得与系统有关的信息,所以直接使用此类可以找到系统的默认编码。方法如下所示:
public static Properties getProperty()
使用上述方法可以查看 JVM 的默认编码,代码如下:
public static void main(String[] args) {// 获取当前系统编码System.out.println("系统默认编码:" + System.getProperty("file.encoding"));}
运行结果如下:
可以看出,现在操作系统的默认编码是 GBK。
下面通过一个示例讲解乱码的产生。现在本地的默认编码是 GBK,下面通过 ISO8859-1 编码对文字进行编码转换。如果要实现编码的转换可以使用 String 类中的 getBytes(String charset) 方法,此方法可以设置指定的编码,该方法的格式如下:
public byte[] getBytes(String charset);
示例代码如下:
public class Test {public static void main(String[] args) throws Exception {File f = new File("D:" + File.separator + "test.txt");// 实例化输出流OutputStream out = new FileOutputStream(f);// 指定ISO8859-1编码byte b[] = "C语言中文网,你好!".getBytes("ISO8859-1");// 保存转码之后的数据out.write(b);// 关闭输出流out.close();}}
运行结果如下: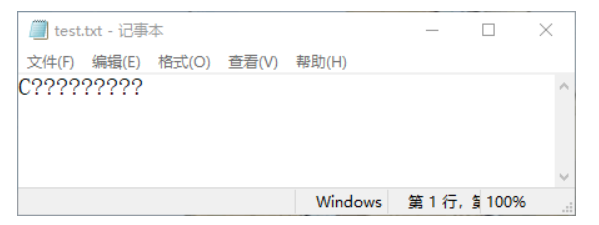
可以发现,因为编码不一致,所以在保存时出现了乱码。在 Java 的开发中,乱码是一个比较常见的问题,乱码的产生就有一个原因,即输出内容的编码与接收内容的编码不一致。
7、File类
在 Java 中,File 类是 java.io 包中唯一代表磁盘文件本身的对象,也就是说,如果希望在程序中操作文件和目录,则都可以通过 File 类来完成。File 类定义了一些方法来操作文件,如新建、删除、重命名文件和目录等。
File 类不能访问文件内容本身,如果需要访问文件内容本身,则需要使用输入/输出流。
File 类提供了如下三种形式构造方法。
- File(String path):如果 path 是实际存在的路径,则该 File 对象表示的是目录;如果 path 是文件名,则该 File 对象表示的是文件。
- File(String path, String name):path 是路径名,name 是文件名。
- File(File dir, String name):dir 是路径对象,name 是文件名。
使用任意一个构造方法都可以创建一个 File 对象,然后调用其提供的方法对文件进行操作。在表 1 中列出了 File 类的常用方法及说明。
| 方法名称 | 说明 |
|---|---|
| boolean canRead() | 测试应用程序是否能从指定的文件中进行读取 |
| boolean canWrite() | 测试应用程序是否能写当前文件 |
| boolean delete() | 删除当前对象指定的文件 |
| boolean exists() | 测试当前 File 是否存在 |
| String getAbsolutePath() | 返回由该对象表示的文件的绝对路径名 |
| String getName() | 返回表示当前对象的文件名或路径名(如果是路径,则返回最后一级子路径名) |
| String getParent() | 返回当前 File 对象所对应目录(最后一级子目录)的父目录名 |
| boolean isAbsolute() | 测试当前 File 对象表示的文件是否为一个绝对路径名。该方法消除了不同平台的差异,可以直接判断 file 对象是否为绝对路径。在 UNIX/Linux/BSD 等系统上,如果路径名开头是一条斜线/,则表明该 File 对象对应一个绝对路径;在 Windows 等系统上,如果路径开头是盘符,则说明它是一个绝对路径。 |
| boolean isDirectory() | 测试当前 File 对象表示的文件是否为一个路径 |
| boolean isFile() | 测试当前 File 对象表示的文件是否为一个“普通”文件 |
| long lastModified() | 返回当前 File 对象表示的文件最后修改的时间 |
| long length() | 返回当前 File 对象表示的文件长度 |
| String[] list() | 返回当前 File 对象指定的路径文件列表 |
| String[] list(FilenameFilter) | 返回当前 File 对象指定的目录中满足指定过滤器的文件列表 |
| boolean mkdir() | 创建一个目录,它的路径名由当前 File 对象指定 |
| boolean mkdirs() | 创建一个目录,它的路径名由当前 File 对象指定 |
| boolean renameTo(File) | 将当前 File 对象指定的文件更名为给定参数 File 指定的路径名 |
File 类中有以下两个常用常量:
- public static final String pathSeparator:指的是分隔连续多个路径字符串的分隔符,Windows 下指;。例如 java -cp test.jar;abc.jar HelloWorld。
- public static final String separator:用来分隔同一个路径字符串中的目录的,Windows 下指/。例如 C:/Program Files/Common Files。
注意:可以看到 File 类的常量定义的命名规则不符合标准命名规则,常量名没有全部大写,这是因为 Java 的发展经过了一段相当长的时间,而命名规范也是逐步形成的,File 类出现较早,所以当时并没有对命名规范有严格的要求,这些都属于 Java 的历史遗留问题。
Windows 的路径分隔符使用反斜线“\”,而 Java 程序中的反斜线表示转义字符,所以如果需要在 Windows 的路径下包括反斜线,则应该使用两条反斜线或直接使用斜线“/”也可以。Java 程序支持将斜线当成平台无关的路径分隔符。
假设在 Windows 操作系统中有一文件 D:\javaspace\hello.java,在 Java 中使用的时候,其路径的写法应该为 D:/javaspace/hello.java 或者 D:\javaspace\hello.java。
1、获取文件属性
在 Java 中获取文件属性信息的第一步是先创建一个 File 类对象并指向一个已存在的文件, 然后调用表 1 中的方法进行操作。
例 1
假设有一个文件位于 C:\windows\notepad.exe。编写 Java 程序获取并显示该文件的长度、是否可写、最后修改日期以及文件路径等属性信息。实现代码如下:
public class Test02 {public static void main(String[] args) {String path = "C:/windows/"; // 指定文件所在的目录File f = new File(path, "notepad.exe"); // 建立File变量,并设定由f变量引用System.out.println("C:\\windows\\notepad.exe文件信息如下:");System.out.println("============================================");System.out.println("文件长度:" + f.length() + "字节");System.out.println("文件或者目录:" + (f.isFile() ? "是文件" : "不是文件"));System.out.println("文件或者目录:" + (f.isDirectory() ? "是目录" : "不是目录"));System.out.println("是否可读:" + (f.canRead() ? "可读取" : "不可读取"));System.out.println("是否可写:" + (f.canWrite() ? "可写入" : "不可写入"));System.out.println("是否隐藏:" + (f.isHidden() ? "是隐藏文件" : "不是隐藏文件"));System.out.println("最后修改日期:" + new Date(f.lastModified()));System.out.println("文件名称:" + f.getName());System.out.println("文件路径:" + f.getPath());System.out.println("绝对路径:" + f.getAbsolutePath());}}
File 类构造方法的第一个参数指定文件所在位置,这里使用C:/作为文件的实际路径;
第二个参数指定文件名称。创建的 File 类对象为 f,然后通过 f 调用方法获取相应的属性,最终运行效果如下所示。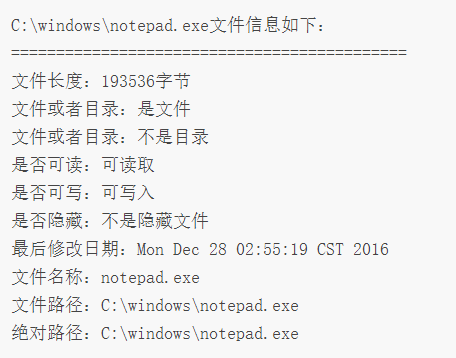
2、创建和删除文件
创建文件需要调用 createNewFile() 方法,删除文件需要调用 delete() 方法。无论是创建还是删除文件通常都先调用 exists() 方法判断文件是否存在。
例 2
假设要在 C 盘上创建一个 test.txt 文件,程序启动时会检测该文件是否存在,如果不存在则创建;如果存在则删除它再创建。
实现代码如下:
public class Test03 {public static void main(String[] args) throws IOException {File f = new File("C:\\test.txt"); // 创建指向文件的File对象if (f.exists()) // 判断文件是否存在{f.delete(); // 存在则先删除}f.createNewFile(); // 再创建}}
运行程序之后可以发现,在 C 盘中已经创建好了 test.txt 文件。但是如果在不同的操作系统中,路径的分隔符是不一样的,例如:
- Windows 中使用反斜杠\表示目录的分隔符。
- Linux 中使用正斜杠/表示目录的分隔符。
那么既然 Java 程序本身具有可移植性的特点,则在编写路径时最好可以根据程序所在的操作系统自动使用符合本地操作系统要求的分隔符,这样才能达到可移植性的目的。要实现这样的功能,则就需要使用 File 类中提供的两个常量。
代码修改如下:
public static void main(String[] args) throws IOException {String path = "C:" + File.separator + "test.txt"; // 拼凑出可以适应操作系统的路径File f = new File(path);if (f.exists()) // 判断文件是否存在{f.delete(); // 存在则先删除}f.createNewFile(); // 再创建}
程序的运行结果和前面程序一样,但是此时的程序可以在任意的操作系统中使用。
注意:在操作文件时一定要使用 File.separator 表示分隔符。在程序的开发中,往往会使用 Windows 开发环境,因为在 Windows 操作系统中支持的开发工具较多,使用方便,而在程序发布时往往是直接在 Linux 或其它操作系统上部署,所以这时如果不使用 File.separator,则程序运行就有可能存在问题。关于这一点我们在以后的开发中一定要有所警惕。
3、创建和删除目录
创建目录需要调用 mkdir() 方法,删除目录需要调用 delete() 方法。无论是创建还是删除目录都可以调用 exists() 方法判断目录是否存在。
例 3
编写一个程序判断 C 盘根目录下是否存在 config 目录,如果存在则先删除再创建。实现代码如下:
public class Test04 {public static void main(String[] args) {String path = "C:/config/"; // 指定目录位置File f = new File(path); // 创建File对象if (f.exists()) {f.delete();}f.mkdir(); // 创建目录}}
4、遍历目录
通过遍历目录可以在指定的目录中查找文件,或者显示所有的文件列表。File 类的 list() 方法提供了遍历目录功能,该方法有如下两种重载形式。
- String[] list()
该方法表示返回由 File 对象表示目录中所有文件和子目录名称组成的字符串数组,如果调用的 File 对象不是目录,则返回 null。
提示:list() 方法返回的数组中仅包含文件名称,而不包含路径。但不保证所得数组中的相同字符串将以特定顺序出现,特别是不保证它们按字母顺序出现。
2. String[] list(FilenameFilter filter)
该方法的作用与 list() 方法相同,不同的是返回数组中仅包含符合 filter 过滤器的文件和目录,如果 filter 为 null,则接受所有名称。
例 4
假设要遍历 C 盘根目录下的所有文件和目录,并显示文件或目录名称、类型及大小。使用 list() 方法的实现代码如下:
public class Test05 {public static void main(String[] args) {File f = new File("C:/"); // 建立File变量,并设定由f变量变数引用System.out.println("文件名称\t\t文件类型\t\t文件大小");System.out.println("===================================================");String fileList[] = f.list(); // 调用不带参数的list()方法for (int i = 0; i < fileList.length; i++) { // 遍历返回的字符数组System.out.print(fileList[i] + "\t\t");System.out.print((new File("C:/", fileList[i])).isFile() ? "文件" + "\t\t" : "文件夹" + "\t\t");System.out.println((new File("C:/", fileList[i])).length() + "字节");}}}
由于 list() 方法返回的字符数组中仅包含文件名称,因此为了获取文件类型和大小,必须先转换为 File 对象再调用其方法。如下所示的是实例的运行效果:
例 5
假设希望只列出目录下的某些文件,这就需要调用带过滤器参数的 list() 方法。首先需要创建文件过滤器,该过滤器必须实现 java.io.FilenameFilter 接口,并在 accept() 方法中指定允许的文件类型。
如下所示为允许 SYS、TXT 和 BAK 格式文件的过滤器实现代码:
public class ImageFilter implements FilenameFilter {// 实现 FilenameFilter 接口@Overridepublic boolean accept(File dir, String name) {// 指定允许的文件类型return name.endsWith(".sys") || name.endsWith(".txt") || name.endsWith(".bak");}}
上述代码创建的过滤器名称为 ImageFilter,接下来只需要将该名称传递给 list() 方法即可实现筛选文件。如下所示为修改后的 list() 方法,其他代码与例 4 相同,这里不再重复。
String fileList[] = f.list(new ImageFilter());
再次运行程序,遍历结果如下所示:
8、字节流
1、字节输入流
InputStream 类及其子类的对象表示字节输入流,InputStream 类的常用子类如下。
- ByteArrayInputStream 类:将字节数组转换为字节输入流,从中读取字节。
- FileInputStream 类:从文件中读取数据。
- PipedInputStream 类:连接到一个 PipedOutputStream(管道输出流)。
- SequenceInputStream 类:将多个字节输入流串联成一个字节输入流。
- ObjectInputStream 类:将对象反序列化。
使用 InputStream 类的方法可以从流中读取一个或一批字节。表 1 列出了 InputStream 类的常用方法。
| 方法名及返回值类型 | 说明 |
|---|---|
| int read() | 从输入流中读取一个 8 位的字节,并把它转换为 0~255 的整数,最后返回整数。 如果返回 -1,则表示已经到了输入流的末尾。为了提高 I/O 操作的效率,建议尽量 使用 read() 方法的另外两种形式 |
| int read(byte[] b) | 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。 该方法返回 读取的字节数。如果返回 -1,则表示已经到了输入流的末尾 |
| int read(byte[] b, int off, int len) | 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。其中,off 指 定在字节数组中开始保存数据的起始下标;len 指定读取的字节数。该方法返回实际 读取的字节数。如果返回 -1,则表示已经到了输入流的末尾 |
| void close() | 关闭输入流。在读操作完成后,应该关闭输入流,系统将会释放与这个输入流相关 的资源。注意,InputStream 类本身的 close() 方法不执行任何操作,但是它的许多 子类重写了 close() 方法 |
| int available() | 返回可以从输入流中读取的字节数 |
| long skip(long n) | 从输入流中跳过参数 n 指定数目的字节。该方法返回跳过的字节数 |
| void mark(int readLimit) | 在输入流的当前位置开始设置标记,参数 readLimit 则指定了最多被设置标记的字 节数 |
| boolean markSupported() | 判断当前输入流是否允许设置标记,是则返回 true,否则返回 false |
| void reset() | 将输入流的指针返回到设置标记的起始处 |
注意:在使用 mark() 方法和 reset() 方法之前,需要判断该文件系统是否支持这两个方法,以避免对程序造成影响。
2、字节输出流
OutputStream 类及其子类的对象表示一个字节输出流。OutputStream 类的常用子类如下。
- ByteArrayOutputStream 类:向内存缓冲区的字节数组中写数据。
- FileOutputStream 类:向文件中写数据。
- PipedOutputStream 类:连接到一个 PipedlntputStream(管道输入流)。
- ObjectOutputStream 类:将对象序列化。
利用 OutputStream 类的方法可以从流中写入一个或一批字节。表 2 列出了 OutputStream 类的常用方法。
| 方法名及返回值类型 | 说明 |
|---|---|
| void write(int b) | 向输出流写入一个字节。这里的参数是 int 类型,但是它允许使用表达式, 而不用强制转换成 byte 类型。为了提高 I/O 操作的效率,建议尽量使用 write() 方法的另外两种形式 |
| void write(byte[] b) | 把参数 b 指定的字节数组中的所有字节写到输出流中 |
| void write(byte[] b,int off,int len) | 把参数 b 指定的字节数组中的若干字节写到输出流中。其中,off 指定字节 数组中的起始下标,len 表示元素个数 |
| void close() | 关闭输出流。写操作完成后,应该关闭输出流。系统将会释放与这个输出 流相关的资源。注意,OutputStream 类本身的 close() 方法不执行任何操 作,但是它的许多子类重写了 close() 方法 |
| void flush() | 为了提高效率,在向输出流中写入数据时,数据一般会先保存到内存缓冲 区中,只有当缓冲区中的数据达到一定程度时,缓冲区中的数据才会被写 入输出流中。使用 flush() 方法则可以强制将缓冲区中的数据写入输出流, 并清空缓冲区 |
3、字节数组输入流
ByteArrayInputStream 类可以从内存的字节数组中读取数据,该类有如下两种构造方法重载形式。
- ByteArrayInputStream(byte[] buf):创建一个字节数组输入流,字节数组类型的数据源由参数 buf 指定。
- ByteArrayInputStream(byte[] buf,int offse,int length):创建一个字节数组输入流,其中,参数 buf 指定字节数组类型的数据源,offset 指定在数组中开始读取数据的起始下标位置,length 指定读取的元素个数。
例 1
使用 ByteArrayInputStream 类编写一个案例,实现从一个字节数组中读取数据,再转换为 int 型进行输出。代码如下:
public class test08 {public static void main(String[] args) {byte[] b = new byte[] { 1, -1, 25, -22, -5, 23 }; // 创建数组ByteArrayInputStream bais = new ByteArrayInputStream(b, 0, 6); // 创建字节数组输入流int i = bais.read(); // 从输入流中读取下一个字节,并转换成int型数据while (i != -1) { // 如果不返回-1,则表示没有到输入流的末尾System.out.println("原值=" + (byte) i + "\t\t\t转换为int类型=" + i);i = bais.read(); // 读取下一个}}}
该示例中,字节输入流 bais 从字节数组 b 的第一个元素开始读取 4 字节元素,并将这 4 字节转换为 int 类型数据,最后返回。
提示:上述示例中除了打印 i 的值外,还打印出了 (byte)i 的值,由于 i 的值是从 byte 类型的数据转换过来的,所以使用 (byte)i 可以获取原来的 byte 数据。
该程序的运行结果如下: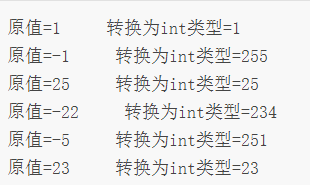
从上述的运行结果可以看出,字节类型的数据 -1 和 -22 转换成 int 类型的数据后变成了 255 和 234,对这种结果的解释如下:
- 字节类型的 1,二进制形式为 00000001,转换为 int 类型后的二进制形式为 00000000 00000000 0000000000000001,对应的十进制数为 1。
- 字节类型的 -1,二进制形式为 11111111,转换为 int 类型后的二进制形式为 00000000 00000000 0000000011111111,对应的十进制数为 255。
可见,从字节类型的数转换成 int 类型的数时,如果是正数,则数值不变;如果是负数,则由于转换后,二进制形式前面直接补了 24 个 0,这样就改变了原来表示负数的二进制补码形式,所以数值发生了变化,即变成了正数。
提示:负数的二进制形式以补码形式存在,例如 -1,其二进制形式是这样得来的:首先获取 1 的原码 00000001,然后进行反码操作,1 变成 0,0 变成 1,这样就得到 11111110,最后进行补码操作,就是在反码的末尾位加 1,这样就变成了 11111111。
4、字节数组输出流
ByteArrayOutputStream 类可以向内存的字节数组中写入数据,该类的构造方法有如下两种重载形式。
- ByteArrayOutputStream():创建一个字节数组输出流,输出流缓冲区的初始容量大小为 32 字节。
- ByteArrayOutputStream(int size):创建一个字节数组输出流,输出流缓冲区的初始容量大小由参数 size 指定。
ByteArrayOutputStream 类中除了有前面介绍的字节输出流中的常用方法以外,还有如下两个方法。
- intsize():返回缓冲区中的当前字节数。
- byte[] toByteArray():以字节数组的形式返回输出流中的当前内容。
例 2
使用 ByteArrayOutputStream 类编写一个案例,实现将字节数组中的数据输出,代码如下所示。
public class Test09 {public static void main(String[] args) {ByteArrayOutputStream baos = new ByteArrayOutputStream();byte[] b = new byte[] { 1, -1, 25, -22, -5, 23 }; // 创建数组baos.write(b, 0, 6); // 将字节数组b中的前4个字节元素写到输出流中System.out.println("数组中一共包含:" + baos.size() + "字节"); // 输出缓冲区中的字节数byte[] newByteArray = baos.toByteArray(); // 将输出流中的当前内容转换成字节数组System.out.println(Arrays.toString(newByteArray)); // 输出数组中的内容}}
该程序的输出结果如下:
5、文件输入流
FileInputStream 是 Java 流中比较常用的一种,它表示从文件系统的某个文件中获取输入字节。通过使用 FileInputStream 可以访问文件中的一个字节、一批字节或整个文件。
在创建 FileInputStream 类的对象时,如果找不到指定的文件将拋出 FileNotFoundException 异常,该异常必须捕获或声明拋出。
FileInputStream 常用的构造方法主要有如下两种重载形式。
- FileInputStream(File file):通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。
- FileInputStream(String name):通过打开一个到实际文件的链接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。
下面的示例演示了 FileInputStream() 两个构造方法的使用。
try {// 以File对象作为参数创建FileInputStream对象FileInputStream fis1 = new FileInputStream(new File("F:/mxl.txt"));// 以字符串值作为参数创建FilelnputStream对象FileInputStream fis2 = new FileInputStream("F:/mxl.txt");} catch(FileNotFoundException e) {System.out.println("指定的文件找不到!");}
例 3
假设有一个 D:\myJava\HelloJava.java 文件,下面使用 FileInputStream 类读取并输出该文件的内容。具体代码如下:
public class Test10 {public static void main(String[] args) {File f = new File("D:/myJava/HelloJava.java");FileInputStream fis = null;try {// 因为File没有读写的能力,所以需要有个InputStreamfis = new FileInputStream(f);// 定义一个字节数组byte[] bytes = new byte[1024];int n = 0; // 得到实际读取到的字节数System.out.println("D:\\myJava\\HelloJava.java文件内容如下:");// 循环读取while ((n = fis.read(bytes)) != -1) {String s = new String(bytes, 0, n); // 将数组中从下标0到n的内容给sSystem.out.println(s);}} catch (Exception e) {e.printStackTrace();} finally {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
如上述代码,在 FileInputDemo 类的 main() 方法中首先创建了一个 File 对象 f,该对象指向 D:\myJava\HelloJava.java 文件。接着使用 FileInputStream 类的构造方法创建了一个 FileInputStream 对象 fis,并声明一个长度为 1024 的 byte 类型的数组,然后使用 FileInputStream 类中的 read() 方法将 HelloJava.java 文件中的数据读取到字节数组 bytes 中,并输出该数据。最后在 finally 语句中关闭 FileInputStream 输入流。
图 1 所示为 HelloJava.java 文件的原始内容,如下所示的是运行程序后的输出内容。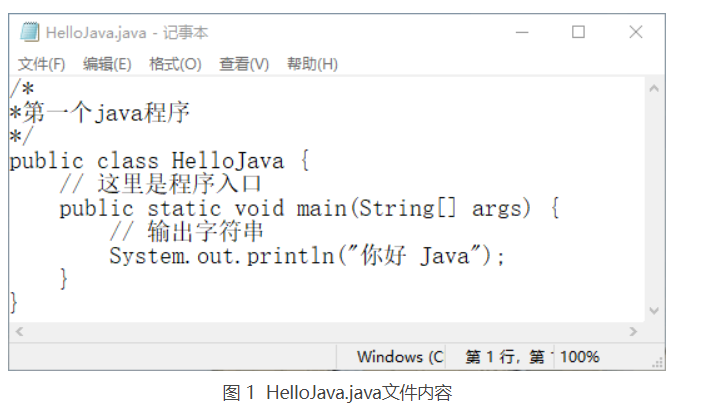
注意:FileInputStream 类重写了父类 InputStream 中的 read() 方法、skip() 方法、available() 方法和 close() 方法,不支持 mark() 方法和 reset() 方法。
6、文件输出流
FileOutputStream 类继承自 OutputStream 类,重写和实现了父类中的所有方法。FileOutputStream 类的对象表示一个文件字节输出流,可以向流中写入一个字节或一批字节。在创建 FileOutputStream 类的对象时,如果指定的文件不存在,则创建一个新文件;如果文件已存在,则清除原文件的内容重新写入。
FileOutputStream 类的构造方法主要有如下 4 种重载形式。
- FileOutputStream(File file):创建一个文件输出流,参数 file 指定目标文件。
- FileOutputStream(File file,boolean append):创建一个文件输出流,参数 file 指定目标文件,append 指定是否将数据添加到目标文件的内容末尾,如果为 true,则在末尾添加;如果为 false,则覆盖原有内容;其默认值为 false。
- FileOutputStream(String name):创建一个文件输出流,参数 name 指定目标文件的文件路径信息。
- FileOutputStream(String name,boolean append):创建一个文件输出流,参数 name 和 append 的含义同上。
注意:使用构造方法 FileOutputStream(String name,boolean append) 创建一个文件输出流对象,它将数据附加在现有文件的末尾。该字符串 name 指明了原文件,如果只是为了附加数据而不是重写任何已有的数据,布尔类型参数 append 的值应为 true。
对文件输出流有如下四点说明:
- 在 FileOutputStream 类的构造方法中指定目标文件时,目标文件可以不存在。
- 目标文件的名称可以是任意的,例如 D:\abc、D:\abc.de 和 D:\abc.de.fg 等都可以,可以使用记事本等工具打开并浏览这些文件中的内容。
- 目标文件所在目录必须存在,否则会拋出 java.io.FileNotFoundException 异常。
- 目标文件的名称不能是已存在的目录。例如 D 盘下已存在 Java 文件夹,那么就不能使用 Java 作为文件名,即不能使用 D:\Java,否则抛出 java.io.FileNotFoundException 异常。
例 4
同样是读取 D:\myJava\HelloJava.java 文件的内容,在这里使用 FileInputStream 类实现,然后再将内容写入新的文件 D:\myJava\HelloJava.txt 中。具体的代码如下:
public class Test11 {public static void main(String[] args) {FileInputStream fis = null; // 声明FileInputStream对象fisFileOutputStream fos = null; // 声明FileOutputStream对象fostry {File srcFile = new File("D:/myJava/HelloJava.java");fis = new FileInputStream(srcFile); // 实例化FileInputStream对象File targetFile = new File("D:/myJava/HelloJava.txt"); // 创建目标文件对象,该文件不存在fos = new FileOutputStream(targetFile); // 实例化FileOutputStream对象byte[] bytes = new byte[1024]; // 每次读取1024字节int i = fis.read(bytes);while (i != -1) {fos.write(bytes, 0, i); // 向D:\HelloJava.txt文件中写入内容i = fis.read(bytes);}System.out.println("写入结束!");} catch (Exception e) {e.printStackTrace();} finally {try {fis.close(); // 关闭FileInputStream对象fos.close(); // 关闭FileOutputStream对象} catch (IOException e) {e.printStackTrace();}}}}
如上述代码,将 D:\myJava\HelloJava.java 文件中的内容通过文件输入/输出流写入到了 D:\myJava\HelloJava.txt 文件中。由于 HelloJava.txt 文件并不存在,所以在执行程序时将新建此文件,并写入相应内容。
运行程序,成功后会在控制台输出“写入结束!”。此时,打开 D:\myJava\HelloJava.txt 文件会发现,其内容与 HelloJava.java 文件的内容相同,如图 2 所示。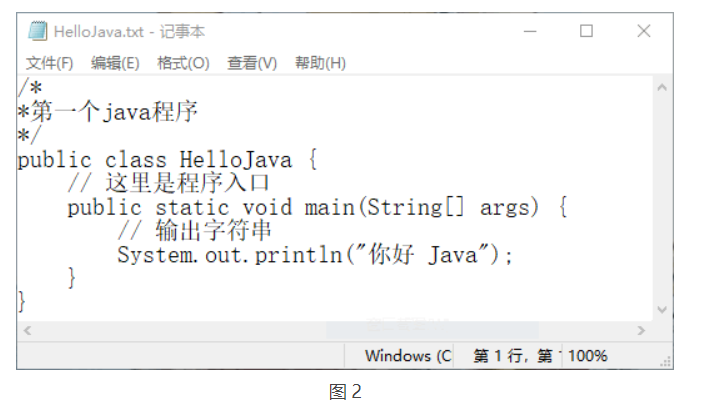
技巧:在创建 FileOutputStream 对象时,如果将 append 参数设置为 true,则可以在目标文件的内容末尾添加数据,此时目标文件仍然可以暂不存在。
9、字符流
1、字符输入流
Reader 类是所有字符流输入类的父类,该类定义了许多方法,这些方法对所有子类都是有效的。
Reader 类的常用子类如下。
- CharArrayReader 类:将字符数组转换为字符输入流,从中读取字符。
- StringReader 类:将字符串转换为字符输入流,从中读取字符。
- BufferedReader 类:为其他字符输入流提供读缓冲区。
- PipedReader 类:连接到一个 PipedWriter。
- InputStreamReader 类:将字节输入流转换为字符输入流,可以指定字符编码。
与 InputStream 类相同,在 Reader 类中也包含 close()、mark()、skip() 和 reset() 等方法,这些方法可以参考 InputStream 类的方法。下面主要介绍 Reader 类中的 read() 方法,如表 1 所示。
| 方法名及返回值类型 | 说明 |
|---|---|
| int read() | 从输入流中读取一个字符,并把它转换为 0~65535 的整数。如果返回 -1, 则表示 已经到了输入流的末尾。为了提高 I/O 操作的效率,建议尽量使用下面两种 read() 方法 |
| int read(char[] cbuf) | 从输入流中读取若干个字符,并把它们保存到参数 cbuf 指定的字符数组中。 该方 法返回读取的字符数,如果返回 -1,则表示已经到了输入流的末尾 |
| int read(char[] cbuf,int off,int len) | 从输入流中读取若干个字符,并把它们保存到参数 cbuf 指定的字符数组中。其中, off 指定在字符数组中开始保存数据的起始下标,len 指定读取的字符数。该方法返 回实际读取的字符数,如果返回 -1,则表示已经到了输入流的末尾 |
2、字符输出流
与 Writer 类是所有字符输出流的父类,该类中有许多方法,这些方法对继承该类的所有子类都是有效的。
Writer 类的常用子类如下。
- CharArrayWriter 类:向内存缓冲区的字符数组写数据。
- StringWriter 类:向内存缓冲区的字符串(StringBuffer)写数据。
- BufferedWriter 类:为其他字符输出流提供写缓冲区。
- PipedWriter 类:连接到一个 PipedReader。
- OutputStreamReader 类:将字节输出流转换为字符输出流,可以指定字符编码。
与 OutputStream 类相同,Writer 类也包含 close()、flush() 等方法,这些方法可以参考 OutputStream 类的方法。下面主要介绍 Writer 类中的 write() 方法和 append() 方法,如表 2 所示。
| 方法名及返回值类型 | 说明 |
|---|---|
| void write(int c) | 向输出流中写入一个字符 |
| void write(char[] cbuf) | 把参数 cbuf 指定的字符数组中的所有字符写到输出流中 |
| void write(char[] cbuf,int off,int len) | 把参数 cbuf 指定的字符数组中的若干字符写到输出流中。其中,off 指定 字符数组中的起始下标,len 表示元素个数 |
| void write(String str) | 向输出流中写入一个字符串 |
| void write(String str, int off,int len) | 向输出流中写入一个字符串中的部分字符。其中,off 指定字符串中的起 始偏移量,len 表示字符个数 |
| append(char c) | 将参数 c 指定的字符添加到输出流中 |
| append(charSequence esq) | 将参数 esq 指定的字符序列添加到输出流中 |
| append(charSequence esq,int start,int end) | 将参数 esq 指定的字符序列的子序列添加到输出流中。其中,start 指定 子序列的第一个字符的索引,end 指定子序列中最后一个字符后面的字符 的索引,也就是说子序列的内容包含 start 索引处的字符,但不包括 end 索引处的字符 |
注意:Writer 类所有的方法在出错的情况下都会引发 IOException 异常。关闭一个流后,再对其进行任何操作都会产生错误。
3、字符文件输入流
为了读取方便,Java 提供了用来读取字符文件的便捷类——FileReader。该类的构造方法有如下两种重载形式。
- FileReader(File file):在给定要读取数据的文件的情况下创建一个新的 FileReader 对象。其中,file 表示要从中读取数据的文件。
- FileReader(String fileName):在给定从中读取数据的文件名的情况下创建一个新 FileReader 对象。其中,fileName 表示要从中读取数据的文件的名称,表示的是一个文件的完整路径。
在用该类的构造方法创建 FileReader 读取对象时,默认的字符编码及字节缓冲区大小都是由系统设定的。要自己指定这些值,可以在 FilelnputStream 上构造一个 InputStreamReader。
注意:在创建 FileReader 对象时可能会引发一个 FileNotFoundException 异常,因此需要使用 try catch 语句捕获该异常。
字符流和字节流的操作步骤相同,都是首先创建输入流或输出流对象,即建立连接管道,建立完成后进行读或写操作,最后关闭输入/输出流通道。
例 1
要将 D:\myJava\HelloJava.java 文件中的内容读取并输出到控制台,使用 FileReader 类的实现代码如下:
public class Test12 {public static void main(String[] args) {FileReader fr = null;try {fr = new FileReader("D:/myJava/HelloJava.java"); // 创建FileReader对象int i = 0;System.out.println("D:\\myJava\\HelloJava.java文件内容如下:");while ((i = fr.read()) != -1) { // 循环读取System.out.print((char) i); // 将读取的内容强制转换为char类型}} catch (Exception e) {System.out.print(e);} finally {try {fr.close(); // 关闭对象} catch (IOException e) {e.printStackTrace();}}}}
如上述代码,首先创建了 FileReader 字符输入流对象 fr,该对象指向 D:\myJava\HelloJava.java 文件,然后定义变量 i 来接收调用 read() 方法的返回值,即读取的字符。在 while 循环中,每次读取一个字符赋给整型变量 i,直到读取到文件末尾时退出循环(当输入流读取到文件末尾时,会返回值 -1)。
4、字符文件输出流
Java 提供了写入字符文件的便捷类——FileWriter,该类的构造方法有如下 4 种重载形式。
- FileWriter(File file):在指定 File 对象的情况下构造一个 FileWriter 对象。其中,file 表示要写入数据的 File 对象。
- FileWriter(File file,boolean append):在指定 File 对象的情况下构造一个 FileWriter 对象,如果 append 的值为 true,则将字节写入文件末尾,而不是写入文件开始处。
- FileWriter(String fileName):在指定文件名的情况下构造一个 FileWriter 对象。其中,fileName 表示要写入字符的文件名,表示的是完整路径。
- FileWriter(String fileName,boolean append):在指定文件名以及要写入文件的位置的情况下构造 FileWriter 对象。其中,append 是一个 boolean 值,如果为 true,则将数据写入文件末尾,而不是文件开始处。
在创建 FileWriter 对象时,默认字符编码和默认字节缓冲区大小都是由系统设定的。要自己指定这些值,可以在 FileOutputStream 上构造一个 OutputStreamWriter 对象。
FileWriter 类的创建不依赖于文件存在与否,如果关联文件不存在,则会自动生成一个新的文件。在创建文件之前,FileWriter 将在创建对象时打开它作为输出。如果试图打开一个只读文件,将引发一个 IOException 异常。
注意:在创建 FileWriter 对象时可能会引发 IOException 或 SecurityException 异常,因此需要使用 try catch 语句捕获该异常。
例 2
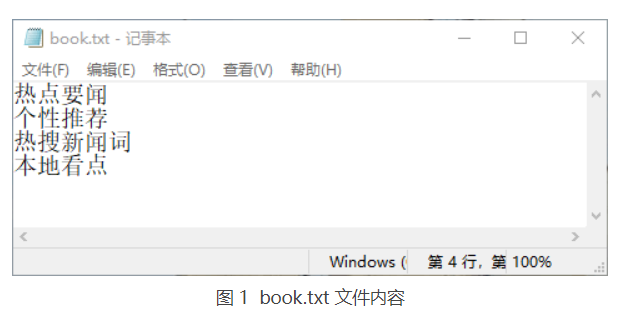
编写一个程序,将用户输入的 4 个字符串保存到 D:\myJava\book.txt 文件中。在这里使用 FileWriter 类中的 write() 方法循环向指定文件中写入数据,实现代码如下:
public class Test13 {public static void main(String[] args) {Scanner input = new Scanner(System.in);FileWriter fw = null;try {fw = new FileWriter("D:\\myJava\\book.txt"); // 创建FileWriter对象for (int i = 0; i < 4; i++) {System.out.println("请输入第" + (i + 1) + "个字符串:");String name = input.next(); // 读取输入的名称fw.write(name + "\r\n"); // 循环写入文件}System.out.println("录入完成!");} catch (Exception e) {System.out.println(e.getMessage());} finally {try {fw.close(); // 关闭对象} catch (IOException e) {e.printStackTrace();}}}}
如上述代码,首先创建了一个指向 D:\myJava\book.txt 文件的字符文件输出流对象 fw,然后使用 for 循环录入 4 个字符串,并调用 write() 方法将字符串写入到指定的文件中。最后在 finally 语句中关闭字符文件输出流。
运行该程序,根据提示输入 4 个字符串,如下所示。接着打开 D:\myJava\book.txt 文件,将看到写入的内容,如图 1 所示。
5、字符缓冲区输入流
BufferedReader 类主要用于辅助其他字符输入流,它带有缓冲区,可以先将一批数据读到内存缓冲区。接下来的读操作就可以直接从缓冲区中获取数据,而不需要每次都从数据源读取数据并进行字符编码转换,这样就可以提高数据的读取效率。
BufferedReader 类的构造方法有如下两种重载形式。
- BufferedReader(Reader in):创建一个 BufferedReader 来修饰参数 in 指定的字符输入流。
- BufferedReader(Reader in,int size):创建一个 BufferedReader 来修饰参数 in 指定的字符输入流,参数 size 则用于指定缓冲区的大小,单位为字符。
除了可以为字符输入流提供缓冲区以外,BufferedReader 还提供了 readLine() 方法,该方法返回包含该行内容的字符串,但该字符串中不包含任何终止符,如果已到达流末尾,则返回 null。readLine() 方法表示每次读取一行文本内容,当遇到换行(\n)、回车(\r)或回车后直接跟着换行标记符即可认为某行已终止。
例 3
使用 BufferedReader 类中的 readLine() 方法逐行读取 D:\myJava\Book.txt 文件中的内容,并将读取的内容在控制台中打印输出,代码如下:
public class Test13 {public static void main(String[] args) {FileReader fr = null;BufferedReader br = null;try {fr = new FileReader("D:\\myJava\\book.txt"); // 创建 FileReader 对象br = new BufferedReader(fr); // 创建 BufferedReader 对象System.out.println("D:\\myJava\\book.txt 文件中的内容如下:");String strLine = "";while ((strLine = br.readLine()) != null) { // 循环读取每行数据System.out.println(strLine);}} catch (FileNotFoundException e1) {e1.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {try {fr.close(); // 关闭 FileReader 对象br.close();} catch (IOException e) {e.printStackTrace();}}}}
如上述代码,首先分别创建了名称为 fr 的 FileReader 对象和名称为 br 的 BufferedReader 对象,然后调用 BufferedReader 对象的 readLine() 方法逐行读取文件中的内容。如果读取的文件内容为 Null,即表明已经读取到文件尾部,此时退出循环不再进行读取操作。最后将字符文件输入流和带缓冲的字符输入流关闭。
运行该程序,输出结果如下所示:
6、字符缓冲区输出流
BufferedWriter 类主要用于辅助其他字符输出流,它同样带有缓冲区,可以先将一批数据写入缓冲区,当缓冲区满了以后,再将缓冲区的数据一次性写到字符输出流,其目的是为了提高数据的写效率。
BufferedWriter 类的构造方法有如下两种重载形式。
- BufferedWriter(Writer out):创建一个 BufferedWriter 来修饰参数 out 指定的字符输出流。
- BufferedWriter(Writer out,int size):创建一个 BufferedWriter 来修饰参数 out 指定的字符输出流,参数 size 则用于指定缓冲区的大小,单位为字符。
该类除了可以给字符输出流提供缓冲区之外,还提供了一个新的方法 newLine(),该方法用于写入一个行分隔符。行分隔符字符串由系统属性 line.separator 定义,并且不一定是单个新行(\n)符。
提示:BufferedWriter 类的使用与 FileWriter 类相同,这里不再重述。
10、字节流与字符流区别
- 每次读写的字节数不同;
- 字符流是块读写,字节流是字节读写;
- 字符流带有缓存,字节流没有。
11、java转换流
正常情况下,字节流可以对所有的数据进行操作,但是有些时候在处理一些文本时我们要用到字符流,比如,查看文本的中文时就是需要采用字符流更为方便。所以 Java IO 流中提供了两种用于将字节流转换为字符流的转换流。
InputStreamReader 用于将字节输入流转换为字符输入流,其中 OutputStreamWriter 用于将字节输出流转换为字符输出流。使用转换流可以在一定程度上避免乱码,还可以指定输入输出所使用的字符集。
例 1
在 java.txt 中输出“C语言中文网”这 6 个字,将 java.txt 保存为“UTF-8”的格式,然后通过字节流的方式读取,代码如下:
public static void main(String[] args) {try {FileInputStream fis = new FileInputStream("D://java.txt");int b = 0;while ((b = fis.read()) != -1) {System.out.print((char) b);}} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
输出结果为 C??????????,我们发现中文都是乱码。下面用字节数组,并通过字符串设定编码格式来显式内容,代码如下:
public static void main(String[] args) {try {FileInputStream fis = new FileInputStream("D://java.txt");byte b[] = new byte[1024];int len = 0;while ((len = fis.read(b)) != -1) {System.out.print(new String(b, 0, len, "UTF-8"));}} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
这时输出结果为 C语言中文网,但是当存储的文字较多时,会出现解码不正确的问题,且字节长度无法根据解码内容自动设定,此时就需要转换流来完成。代码如下:
public static void main(String[] args) {try {FileInputStream fis = new FileInputStream("D://java.txt");InputStreamReader isr = new InputStreamReader(fis, "UTF-8");int b = 0;while ((b = isr.read()) != -1) {System.out.print((char) b); // 输出结果为“C语言中文网”}} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
例 2
下面以获取键盘输入为例来介绍转换流的用法。Java 使用 System.in 代表标准输出,即键盘输入,但这个标准输入流是 InputStream 类的实例,使用不太方便,而且键盘输入内容都是文本内容,所以可以使用 InputStreamReader 将其转换成字符输入流,普通的 Reader 读取输入内容时依然不太方便,可以将普通的 Reader 再次包装成 BufferedReader,利用 BufferedReader 的 readLine() 方法可以一次读取一行内容。程序如下所示。
public static void main(String[] args) {try {// 将 System.in 对象转换成 Reader 对象InputStreamReader reader = new InputStreamReader(System.in);// 将普通的Reader 包装成 BufferedReaderBufferedReader br = new BufferedReader(reader);String line = null;// 利用循环方式来逐行的读取while ((line = br.readLine()) != null) {// 如果读取的字符串为“exit”,则程序退出if (line.equals("exit")) {System.exit(1);}// 打印读取的内容System.out.println("输入内容为:" + line);}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
上面代码第 4 行和第 6 行将 System.in 包装成 BufferedReader,BufferReader 流具有缓冲功能,它可以一次读取一行文本,以换行符为标志,如果它没有读到换行符,则程序堵塞,等到读到换行符为止。运行上面程序可以发现这个特征,在控制台执行输入时,只有按下回车键,程序才会打印出刚刚输入的内容。
由于 BufferedReader 具有一个 readLine() 方法,可以非常方便地进行一次读入一行内容,所以经常把读入文本内容地输入流包装成 BufferedReader,用来方便地读取输入流的文本内容。
学到这里,大家可能有一个疑问:既然有字节流转字符流的转换流,那么为什么没有字符流转字节流的转换流呢?
这个问题一语指出了 Java 设计的遗漏之处,想一想字符流和字节流的差别。字节流比字符流的使用范围要更广,但字符流比字节流操作方便。如果有一个流已经是字符流了,也就是说,是一个用起来更方便的流,为什么要转换成字节流呢?反之,如果现在有一个字节流,但可以确定这个字节流的内容都是文本内容,那么把它转换成字符流来处理就会更方便一些,所以 Java 只提供了将字节流转换成字符流的转换流,没有提供将字符流转换成字节流的转换流。
12、java保存图片信息
每到学校开学季都会新进一批图书教材,需要将这些图书信息保存到文件,再将它们打印出来方便老师查看。下面编写程序,使用文件输入/输出流完成图书信息的存储和读取功能,具体的实现步骤如下。
1)创建 Book 类,在该类中包含 no、name 和 price 3 个属性,分别表示图书编号、图书名称和图书单价。同时还包含两个方法 write() 和 read(),分别用于将图书信息写入到磁盘文件中和从磁盘文件中读取图书信息并打印到控制台。
此外,在 Product 类中包含有该类的 toString() 方法和带有 3 个参数的构造方法,具体的内容如下:
public class Book {private int no; // 编号private String name; // 名称private double price; // 单价public Book(int no, String name, double price) {this.no = no;this.name = name;this.price = price;}public String toString() {return "图书编号:" + this.no + ",图书名称:" + this.name + ",图书单价:" + this.price + "\n";}public static void write(List books) {FileWriter fw = null;try {fw = new FileWriter("E:\\myJava\\books.txt"); // 创建FileWriter对象for (int i = 0; i < books.size(); i++) {fw.write(books.get(i).toString()); // 循环写入}} catch (Exception e) {System.out.println(e.getMessage());} finally {try {fw.close();} catch (IOException e) {e.printStackTrace();}}}public static void read() {FileReader fr = null;BufferedReader br = null;try {fr = new FileReader("E:\\myJava\\books.txt");br = new BufferedReader(fr); // 创建BufferedReader对象String str = "";while ((str = br.readLine()) != null) { // 循环读取每行数据System.out.println(str); // 输出读取的内容}} catch (Exception e) {System.out.println(e.getMessage());} finally {try {br.close();fr.close();} catch (IOException e) {e.printStackTrace();}}}}
如上述代码,分别使用字符文件输出流 FileWriter 和字符缓冲区输入流 BufferedReader 完成对图书信息的存储和读取功能。
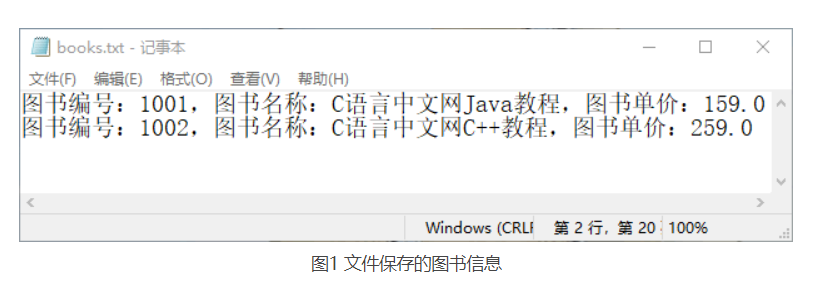
2)编写测试类 Test14,创建两个 Book 对象,并将这两个对象保存到 List 集合中,再将 List 集合对象传递给 Book 类中的 write() 方法,向 F:\product.txt 文件中写入图书信息。最后调用 Product 类中的 read() 方法读取该文件内容,代码如下:
public class Test14 {public static void main(String[] args) {Book book1 = new Book(1001, "C语言中文网Java教程", 159);Book book2 = new Book(1002, "C语言中文网C++教程", 259);List books = new ArrayList();books.add(book1);books.add(book2);Book.write(books);System.out.println("********************图书信息******************");Book.read();}}
3)运行程序,输出的图书信息,如下所示。打开 E:\myJava\books.txt 文件,该文件的内容如图 1 所示。

若有收获,就点个赞吧
0 人点赞
