1、结构
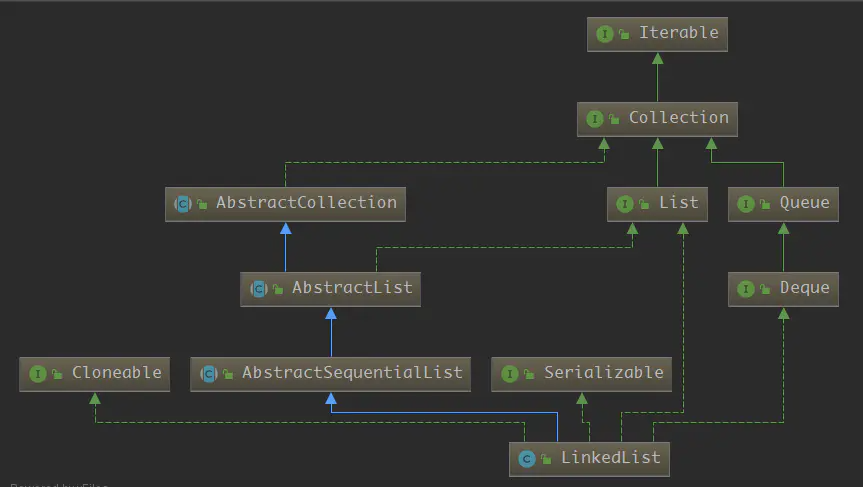
2、源码要点
2.1、接口Deque
相比于ArrayList,它额外实现了双端队列接口Deque,这个接口主要是声明了队头,队尾的一系列方法。
2.2、类成员
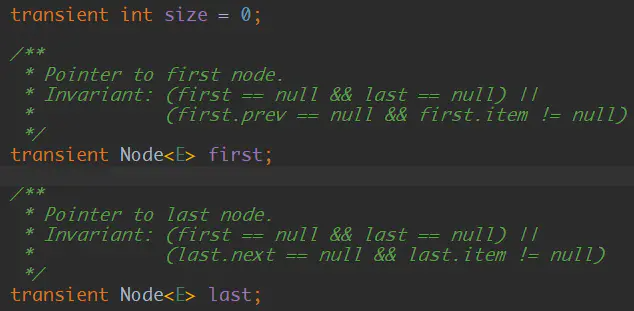
LinkedList内部有两个引用,一个first,一个last,分别用于指向链表的头和尾,另外有一个size,用于标识这个链表的长度,
而它的接的引用类型是Node,这是他的一个内部类: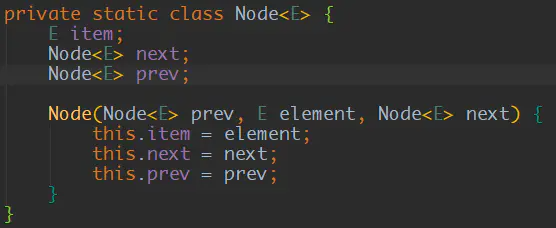
item用于保存数据,而prve用于指向当前节点的前一个节点,next用于指向当前节点的下一个节点。
2.3、add(E e)方法
这个方法直接调用linkLast:
执行过程,一开始,first和last都为null,此时链表什么都没有,当第一次调用该方法后,first和last均指向了第一个新加的节点E1: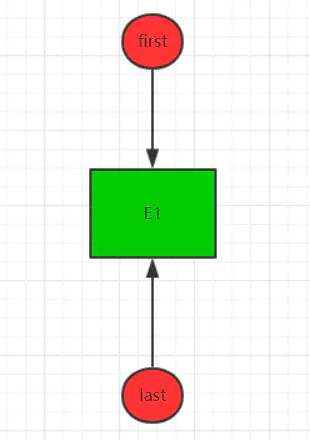
接着,第二次调用该方法,加入新节点E2。首先,将last引用赋值给l,接着new了一个新节点E2,并且E2的prve指向l,接着将新节点E2赋值为last。现在结构如下: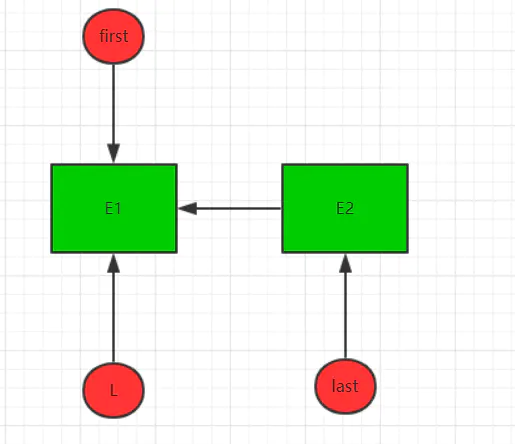
接着判断l==null? 所以走的else语句,将l的next引用指向新节点E2,现在数据结构如下: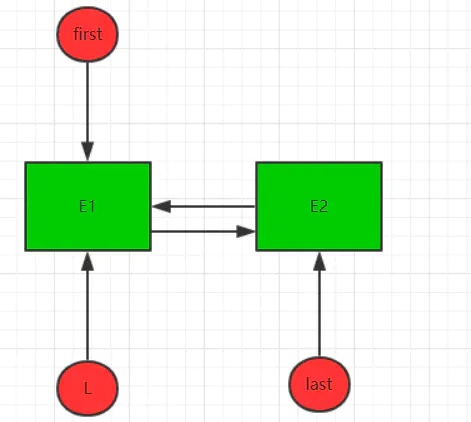
接着size+1,modCount+1,退出该方法,局部变量l销毁,所以现在数据结构如下: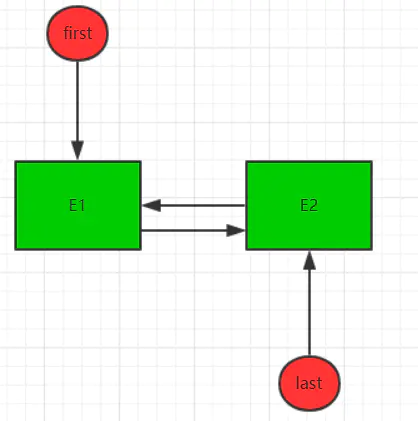
这样就完成了链表新节点的构建。
2.4、add(int index, E element)
这个方法是在指定位置插入新元素
public void add(int index, E element) {checkPositionIndex(index);if (index == size)linkLast(element);elselinkBefore(element, node(index));}
- index位置检查(不能小于0,大于size)
- 如果index==size,直接在链表最后插入,相当于调用add(E e)方法
- 小于size,首先调用node方法将index位置的节点找出,接着调用linkBefore
我们同样作图分析,假设现在链表中有三个节点,调用node方法后找到的第二个节点E2,则进入方法后,结构如下:void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;size++;modCount++;}
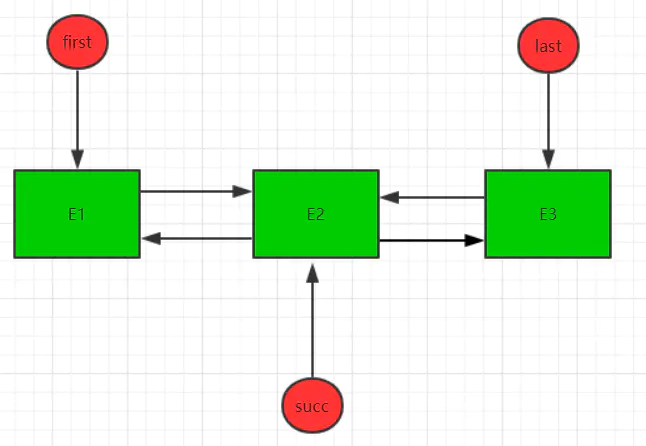
接着,将succ的prev赋值给pred,并且构造新节点E4,E4的prev和next分别为pred和suc,同时将新节点E4赋值为succ的prev引用,则现在结构如下: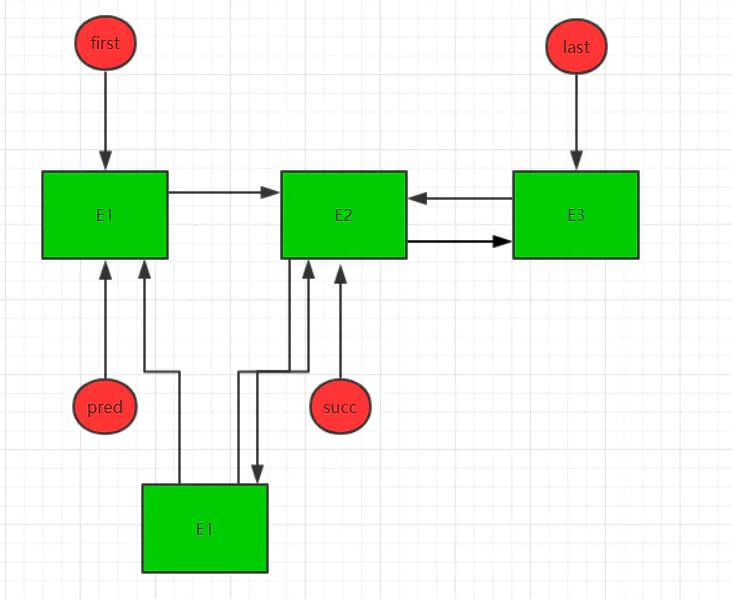
接着,将新节点赋值给pred节点的next引用,结构如下: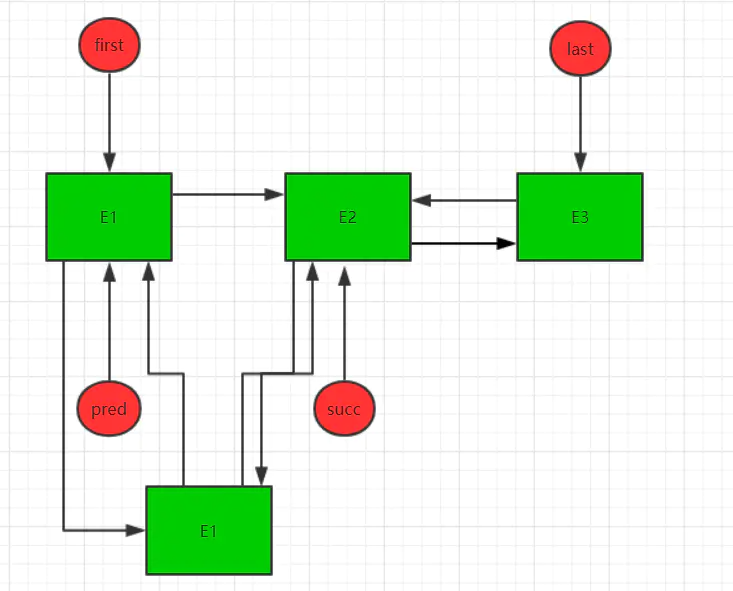
最后,size+1,modCount+1,推出方法,本地变量succ,pred销毁,最后结构如下: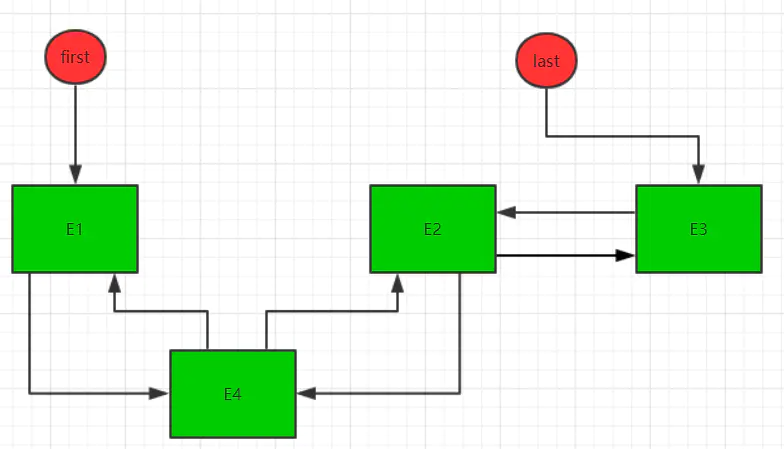
2.5、E get(int index)
获取指定节点数据
public E get(int index) {checkElementIndex(index);return node(index).item;}
直接调用node方法:
Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
- 判断index在链表的哪边。
遍历查找index或者size-index次,找出对应节点。
这里我们知道,相比于数组的直接索引获取,遍历获取节点效率并不高。2.6、E remove(int index)
移除指定节点
public E remove(int index) {checkElementIndex(index);return unlink(node(index));}
检查index位置
调用node方法获取节点,接着调用unlink(E e)
E unlink(Node<E> x) {// assert x != null;final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;if (prev == null) {first = next;} else {prev.next = next;x.prev = null;}if (next == null) {last = prev;} else {next.prev = prev;x.next = null;}x.item = null;size--;modCount++;return element;}
这个方法就不做分析了,其原理就是将当前节点X的前一个节点P的next直接指向X的下一个节点D,这样X就不再关联任何引用,等待垃圾回收即可。
这里我们同样知道,相比于ArrayList的copy数组覆盖原来节点,效率同样更高!
到现在,我们关于链表的核心方法,增删改都分析完毕,最后介绍下它实现的队列Deque的各个方法: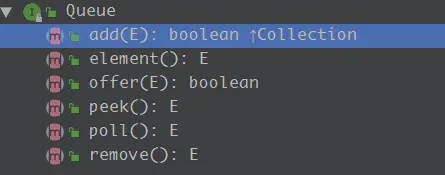
LinkedList
- add(E e):队尾插入新节点,如果队列空间不足,抛出异常;LinkedList没有空间限制,所以可以无限添加。
- offer(E e):队尾插入新节点,空间不足,返回false,在LinkedList中和add方法同样效果。
- remove():移除队头节点,如果队列为空(没有节点,first为null),抛出异常。LinkedList中就是first节点(链表头)
- poll():同remove,不同点:队列为空,返回null
- element():查询队头节点(不移除),如果队列为空,抛出异常。
- peek():同element,不同点:队列为空,返回null。
总结
- LinkedList内部使用链表实现,相比于ArrayList更加耗费空间。
- LinkedList插入,删除节点不用大量copy原来元素,效率更高。
- LinkedList查找元素使用遍历,效率一般。
- LinkedList同时是双向队列的实现。
3、源码
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {@java.io.Serialprivate static final long serialVersionUID = 876323262645176354L; // 序列化版本号transient int size = 0; // 当前元素个数0transient Node<E> first; // 指向第一个节点数据transient Node<E> last; // 指向最后一个节点/*** 存储数据的* Node数据结构*/private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}/*** LinkedList构造方法*/public LinkedList() {} // 构造一个空集合public LinkedList(Collection<? extends E> c) {} // 构造一个带有c集合所有元素的集合/*** 添加元素*/public void addFirst(E e) {} // 将节点e加入作为第一个节点public void addLast(E e) { } // 将节点e加入作为尾节点public boolean add(E e) {} // 添加元素,会加入到链表末尾public boolean offer(E e) {} // 添加元素,调用的是add(e);就是上面一个方法public void add(int index, E element) {}// index位置加入元素elementpublic boolean addAll(Collection<? extends E> c) {} // 添加集合元素public boolean addAll(int index, Collection<? extends E> c) {} // 指定位置后添加元素public boolean offerFirst(E e) {} // 添加e成为首元素public boolean offerLast(E e) {} // 添加e成为尾元素元素public void push(E e) {} // 添加e并成为首元素/*** 移除元素*/public E removeFirst() {} // 移除首元素public E removeLast() {} // 移除最后一个节点public E pollFirst() {} // 返回并移除首元素public E pollLast() {} // 返回并移除尾元素public E remove() {} // 移除首元素public E pop() {} // 移除首元素并返回首元素public E poll() {} // 返回首元素并从链表中剔除首元素,或者返回nullpublic boolean remove(Object o) {} // 移除元素o,如果成功返回true,失败(说明不存在)返回falsepublic E remove(int index) {} // 移除index位置的元素public boolean removeFirstOccurrence(Object o) {} // 从头开始找元素o,并移除元素opublic boolean removeLastOccurrence(Object o) {} // 从尾往前找元素o,并移除元素/*** 修改元素*/public E set(int index, E element) {} // 替换index索引元素存的内容/*** 查询元素*/public E getFirst() {} // 获取第一个节点public E getLast() {} // 获取最后一个节点public E peek() {} // 返回表头元素或者nullpublic E element() {} // 返回表头元素,如果为null则抛异常,不会返回null元素public E peekLast() {} // 返回尾元素,可以返回nullpublic E get(int index) {} // 获得index索引下的元素public int indexOf(Object o) {} // 从首元素往后找,返回元素o的索引值,如果不存在则返回-1public int lastIndexOf(Object o) {} // 从尾元素往前找,返回元素索引public boolean contains(Object o) {} // 是否包含o/*** 其它对集合操作的方法* 链表转数组* 集合大小、清空集合、克隆集合、迭代器*/public Object[] toArray() {} // 链表转数组,不带泛型public <T> T[] toArray(T[] a) {} // 链表转数组,传入泛型public int size() {} // 返回链表长度public void clear() {} // 清除所有元素private LinkedList<E> superClone() {} // 克隆一个LinkedList对象public Object clone() {} // 将所有元素都克隆一份,并返回public Spliterator<E> spliterator() {} // 迭代器,允许并行处理public ListIterator<E> listIterator(int index) {} // 迭代器/*** 后面的可以不用看,主要需要掌握前面对外提供的方法** 不对外使用的方法*/E unlink(Node<E> x) {} // 移除节点xNode<E> node(int index) {} // 返回index下的节点void linkLast(E e) {} // 链接到最后一个节点上void linkBefore(E e, Node<E> succ) {} // 链接到succ节点的上一个节点private void linkFirst(E e) {} // 链接到第一个节点上private E unlinkFirst(Node<E> f) {} // 移除第一个节点private E unlinkLast(Node<E> l) {} // 移除最后一个节点private boolean isElementIndex(int index) {} // 判断index是否在链表长度内private boolean isPositionIndex(int index) {} // 判断index是否是正向索引private String outOfBoundsMsg(int index) {} // 返回超出索引范围的提示字符串:"Index: "+index+", Size: "+size;private void checkElementIndex(int index) {} // 检查元素索引index是否在链表长度以内,不是则抛异常private void checkPositionIndex(int index) {} // 检查正向索引/*** 序列化*/@java.io.Serialprivate void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {}/*** 反序列化*/@SuppressWarnings("unchecked")@java.io.Serialprivate void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {}public Iterator<E> descendingIterator() {return new DescendingIterator();}private class DescendingIterator implements Iterator<E> {private final ListItr itr = new ListItr(size());public boolean hasNext() {} // 是否有下一个元素public E next() {} // 返回下一个元素public void remove() {} // 移除当前迭代器返回的元素}private class ListItr implements ListIterator<E> {private Node<E> lastReturned; // 上一个元素节点private Node<E> next; // 下一个节点元素private int nextIndex; // 上一个元素索引值private int expectedModCount = modCount;// 并发修改异常计数ListItr(int index) {} // 构造器public void add(E e) {} // 添加public void remove() {} // 删除public void set(E e) {} // 修改public boolean hasNext() {} // 判断是否有下一个元素public E next() {} // 返回下一个元素public boolean hasPrevious() {} // 是否有上一个值public E previous() {} // 返回上一个元素public int nextIndex() {} // 下一个元素的索引值public int previousIndex() {} // 上一个元素的索引值public void forEachRemaining(Consumer<? super E> action) {} // 遍历迭代器剩余元素final void checkForComodification() {} // 检查并发修改异常}static final class LLSpliterator<E> implements Spliterator<E> {static final int BATCH_UNIT = 1 << 10; // batch array size incrementstatic final int MAX_BATCH = 1 << 25; // max batch array size;final LinkedList<E> list; // null OK unless traversedNode<E> current; // current node; null until initializedint est; // size estimate; -1 until first neededint expectedModCount; // initialized when est setint batch; // batch size for splitsLLSpliterator(LinkedList<E> list, int est, int expectedModCount) {} // 构造方法public void forEachRemaining(Consumer<? super E> action) {} // 遍历剩余元素public boolean tryAdvance(Consumer<? super E> action) {} // 尝试获取剩余元素,如果没有剩余元素返回falsefinal int getEst() {}public long estimateSize() {}public Spliterator<E> trySplit() {}public int characteristics() {}}}
4、双向链表
另外推荐一篇把双向链表讲清楚的文章:https://juejin.cn/post/6844903648154271757
双向链表: 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。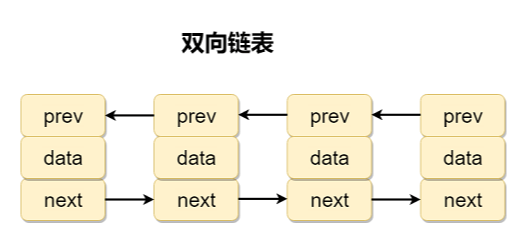
双向循环链表: 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。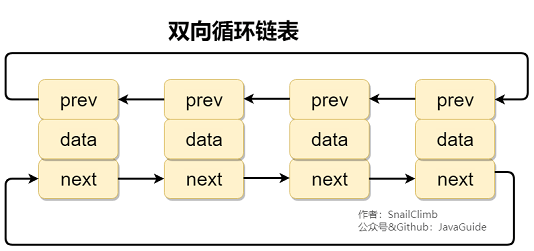

若有收获,就点个赞吧
0 人点赞
