1、结构
| JDK版本 | 实现方式 | 节点数>=8 | 节点数<=6 |
|---|---|---|---|
| 1.8以前 | 数组+单向链表 | 数组+单向链表 | 数组+单向链表 |
| 1.8以后 | 数组+单向链表+红黑树 | 数组+红黑树 | 数组+单向链表 |
1.1、1.8以前
将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可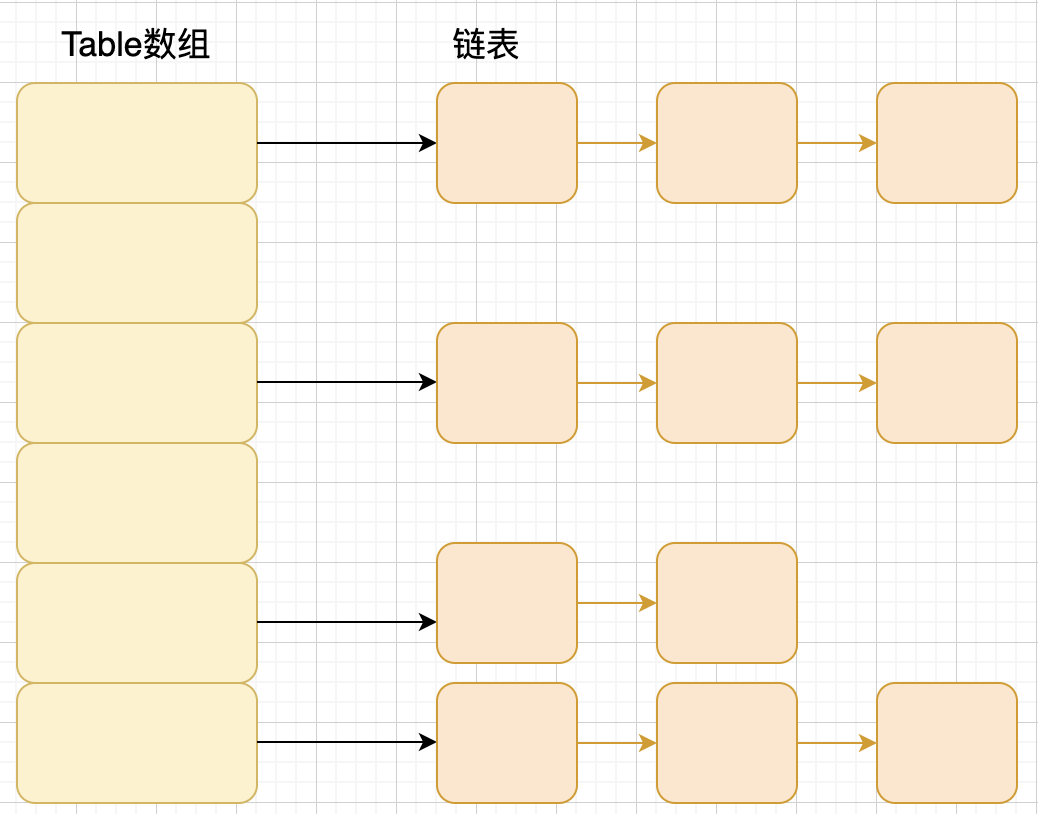
1.2、1.8以后
JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。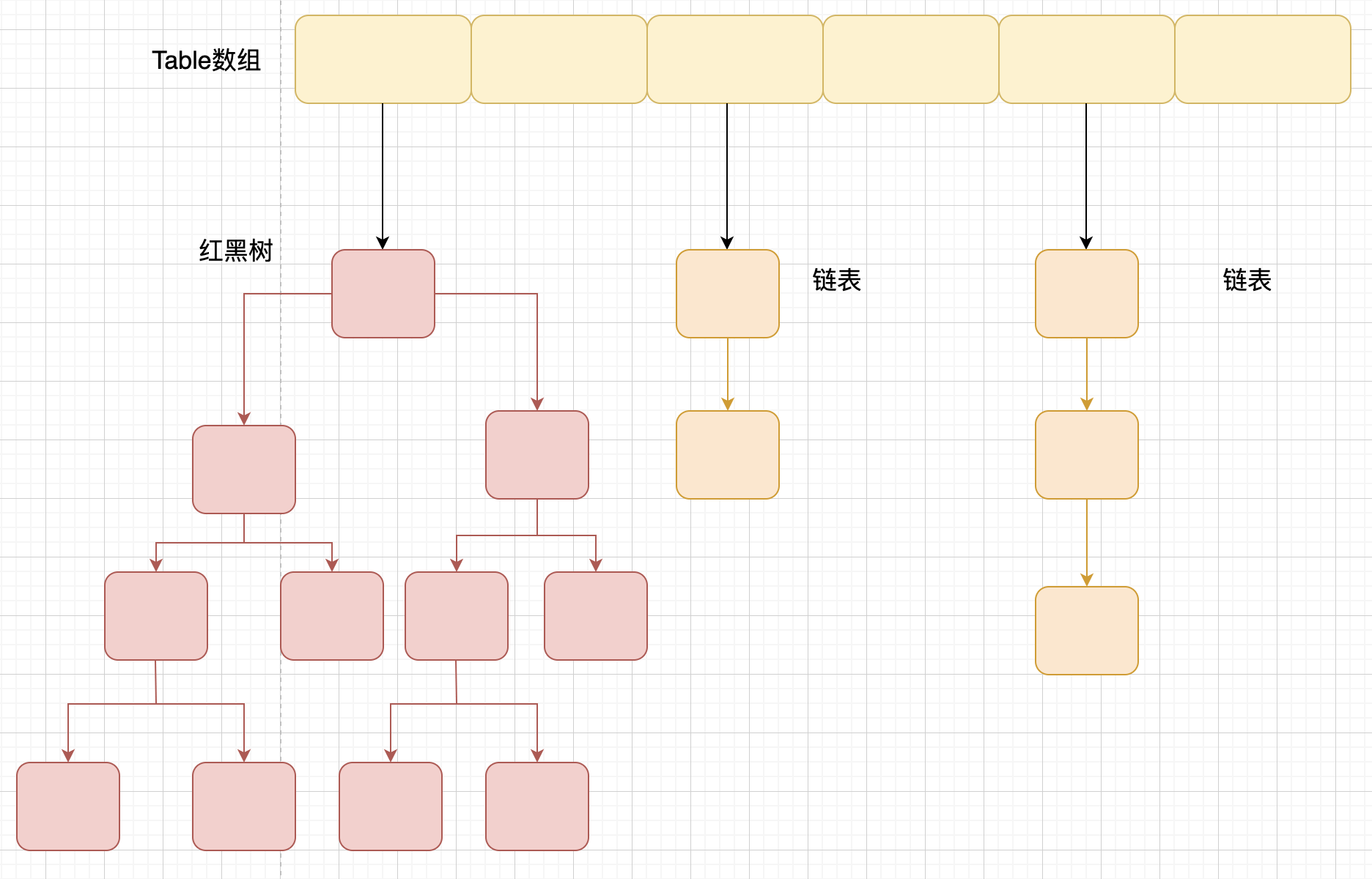
1.3、hashcode
产生hash碰撞,hash码相同,则通过key的equals()方法比较值是否相同.
key值不相等:则会在该节点的链表结构上新增一个节点(如果链表长度>=8且 数组节点数>=64 链表结构就会转换成红黑树)
key值相等:则用新的value替换旧的value
什么时候会产生hash碰撞? 如何解决hash碰撞?
答:只要两个元素产生的hash值相同就会产生hash碰撞。
jdk8前采用链表解决hash碰撞、jdk8以后采用链表 + 红黑树解决hash碰撞。
2、源码
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {/** 下面是成员属性的定义*/private static final long serialVersionUID = 362498820763181265L; // 实现序列化接口的序列化默认版本号static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认初始容量等于16static final int MAXIMUM_CAPACITY = 1 << 30; // 2的30次方也等于 Integer.MAXVALUEstatic final float DEFAULT_LOAD_FACTOR = 0.75f;// 默认的扩容因子static final int TREEIFY_THRESHOLD = 8; // 红黑数的阈值,hash碰撞达到了8链表才会转换成红黑数static final int UNTREEIFY_THRESHOLD = 6;// hash碰撞小于6才解开红黑树结构转换成链表结构static final int MIN_TREEIFY_CAPACITY = 64; // 树型容量的最小值,这个值不能小于 4*TREEIFY_THRESHOLD = 32transient Node<K,V>[] table;// 真正存储数据的数组结构transient Set<Map.Entry<K,V>> entrySet;// 所有节点Entry的集合transient int size;// hashMap的大小transient int modCount;// 并发修改计数,用于检测并发修改异常的值int threshold;// 扩容的条件,threshold=0.75*容量final float loadFactor;// 加载因子,默认值为0.75.可以通过构造方法重新设定/**** 下面的是静态内部类,可以粗略的过一眼,不用细究代码。**/// 这个结构很重要,是真正存储数据的数据结构static class Node<K,V> implements Map.Entry<K,V> {final int hash; // 存储的 hash值final K key; // 存储的 key值V value; // 存储的 value值Node<K,V> next; // 链表结构,下一个节点的数据。结合前面定义的 transient Node<K,V>[] table;因此说HashMap的存储结构是数组+链表。Node(int hash, K key, V value, Node<K,V> next) {} // 构造方法public final K getKey() {} // 获取当前节点的keypublic final V getValue() {} // 获取当前节点的valuepublic final String toString() {} // 返回{key:value}的字符串public final int hashCode() {} // hash当前节点的key,value并返回hash值public final V setValue(V newValue) {} // 给节点设置value值public final boolean equals(Object o) {}// 实现equals方法用于比较o与当前节点是否相等}/** 树节点数据结构,重要部分*/static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父节点TreeNode<K,V> left; // 左节点TreeNode<K,V> right; // 右节点TreeNode<K,V> prev; // 删除后需要取消链接boolean red; // 用来判断当前节点是红还是黑节点/* 构造方法,创建对象的时候数据也存进来了 */TreeNode(int hash, K key, V val, Node<K,V> next) {}// 查找节点final TreeNode<K,V> find(int h, Object k, Class<?> kc) {}// 获取红黑树中的节点final TreeNode<K,V> getTreeNode(int h, Object k) {}// 链表 转换成 红黑树final void treeify(Node<K,V>[] tab) {}// 红黑树 转换成 链表final Node<K,V> untreeify(HashMap<K,V> map) {}// 添加红黑树节点final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {}// 删除红黑树节点final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,boolean movable) {}// 移除节点final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {} // 拆分// 左旋static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,TreeNode<K,V> p) {}// 右旋static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,TreeNode<K,V> p) {}// 插入元素时保存平衡static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {}// 删除元素时保存平衡static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,TreeNode<K,V> x) {}final TreeNode<K,V> root() {}static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {}static int tieBreakOrder(Object a, Object b) {}static <K,V> boolean checkInvariants(TreeNode<K,V> t) {}}static Class<?> comparableClassFor(Object x) {/*省略*/} ////Entry集合的内部结构,其目的就是实现Set方法,方便获取Set中的Entry(实际存储的数据结构)final class EntrySet extends AbstractSet<Map.Entry<K,V>> {public final int size(){} // Set中元素个数public final void clear(){} // 清空Setpublic final Iterator<Map.Entry<K,V>> iterator() {} // 迭代器,迭代获取Set内容public final boolean contains(Object o) {} // 是否包含某个元素public final boolean remove(Object o) {} // 移除某个元素public final Spliterator<Map.Entry<K,V>> spliterator() {} // 拆分Set集合,暂没有遇到使用场景。跳过public final void forEach(Consumer<? super Map.Entry<K,V>> action) {} // 遍历元素,使用函数式接口Consumer,可以使用lambda表达式进行遍历消费}/** 下面是类迭代器分别代表hash、key、value、Entry*/abstract class HashIterator {Node<K,V> next; // 下一个节点Node<K,V> current; // 当前节点int expectedModCount; // 预期的修改计数int index; // 当前索引值HashIterator() {} //构造方法public final boolean hasNext() {} // 判断是否还有下一个Node节点final Node<K,V> nextNode() {} // 返回下一个节点Nodepublic final void remove() {} // 移除当前节点}final class KeyIterator extends HashIterator implements Iterator<K> {public final K next() { }// 返回下一个节点的 键 key}final class ValueIterator extends HashIterator implements Iterator<V> { public final V next() { }//返回下一个节点的 值 value}final class EntryIterator extends HashIterator implements Iterator<Map.Entry<K,V>> {public final Map.Entry<K,V> next() { }//返回下一个节点}/** 下面是Spliterator和上面迭代器一样作用,* 只不是这些迭代器可以并行处理**/static class HashMapSpliterator<K,V> {final HashMap<K,V> map;Node<K,V> current; // 当前节点int index; // 当前索引int fence; // 上一个节点索引int est; // 预估值int expectedModCount; // 预期的并发修改次数//构造方法HashMapSpliterator(HashMap<K,V> m, int origin,int fence, int est,int expectedModCount) {}final int getFence() {}//返回上一个节点的索引public final long estimateSize() {} // 返回Map的预估个数}// 该类的目的是解决hashMap存储数据过大,不方便处理,对数据进行拆分,提供性能。static final class KeySpliterator<K,V> extends HashMapSpliterator<K,V> implements Spliterator<K> {// 构造方法KeySpliterator(HashMap<K,V> m, int origin, int fence, int est, int expectedModCount) {}public KeySpliterator<K,V> trySplit() {} //public void forEachRemaining(Consumer<? super K> action) {}//遍历剩余元素/*如果有剩余元素,执行Consumer操作,并返回true,否则返回false */public boolean tryAdvance(Consumer<? super K> action) {}public int characteristics() {} //特征值}static final class ValueSpliterator<K,V> extends HashMapSpliterator<K,V> implements Spliterator<V> {//ValueSpliterator(HashMap<K,V> m, int origin, int fence, int est,int expectedModCount) {}public ValueSpliterator<K,V> trySplit() {}public void forEachRemaining(Consumer<? super V> action) {}public boolean tryAdvance(Consumer<? super V> action) {}public int characteristics() {}}static final class EntrySpliterator<K,V> extends HashMapSpliterator<K,V> implements Spliterator<Map.Entry<K,V>> {public EntrySpliterator<K,V> trySplit() {}public void forEachRemaining(Consumer<? super Map.Entry<K,V>> action) {}public boolean tryAdvance(Consumer<? super Map.Entry<K,V>> action) {}public int characteristics() {}}/** 四种构造方法*/public HashMap(int initialCapacity, float loadFactor) {}public HashMap(int initialCapacity) {}public HashMap() {}public HashMap(Map<? extends K, ? extends V> m) {}/** HashMap中定义的方法*/static final int tableSizeFor(int cap) {} // 得到大于cap的最佳容量值final float loadFactor() {} // 返回加载因子final int capacity() {} // 返回容量值public void clear() {} // 清空hashMappublic int size() {} // 返回hashMap存储了多少个元素public boolean isEmpty() {} // 判断hashMap是否没有存储元素static final int hash(Object key) {} // 得到key的hash值/* 添加和修改 */public V put(K key, V value) {} // 存除键值对数据// 实际真正存数据的方法put方法就是调用它才真正的将key,value存入hashMapfinal V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {}public void putAll(Map<? extends K, ? extends V> m) {} //批量添加// 查询public V get(Object key) {} // 根据key取出hashMap中的内容// 删除public V remove(Object key) {} // 删除key所对于的键值对// hashMap的扩容方法final Node<K,V>[] resize() {}public boolean containsKey(Object key) {} // 判断hashMap中是否包含keypublic boolean containsValue(Object value) {} // 判断hashMap中是否包含valuefinal void treeifyBin(Node<K,V>[] tab, int hash) {}// 转换成红黑树//获取节点final Node<K,V> getNode(int hash, Object key) {}//删除节点final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {}// 批量添加Entryfinal void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {}public Collection<V> values() {} // 获取所有valuepublic Set<K> keySet() {}final class KeySet extends AbstractSet<K> {}final class Values extends AbstractCollection<V> {}public Set<Map.Entry<K,V>> entrySet() {}/** 下面是集合类作者失误导致的结果,* 不用细究,* 原因是HashMap实现了Map接口,继承的AbstractMap也实现了同样的接口* 导致出现下面这么多重写方法。(后作者发现自己的错误,想修改,但被拒绝了,因为jdk组织认为不值得修改)*/@SuppressWarnings({"rawtypes","unchecked"})static int compareComparables(Class<?> kc, Object k, Object x) {}@Overridepublic V getOrDefault(Object key, V defaultValue) {}@Overridepublic V putIfAbsent(K key, V value) {}@Overridepublic boolean remove(Object key, Object value) {}@Overridepublic boolean replace(K key, V oldValue, V newValue) {}@Overridepublic V replace(K key, V value) {}@Overridepublic V computeIfAbsent(K key,Function<? super K, ? extends V> mappingFunction) {}public V computeIfPresent(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {}@Overridepublic V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {}@Overridepublic V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) {}@Overridepublic void forEach(BiConsumer<? super K, ? super V> action) {}@Overridepublic void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {}@SuppressWarnings("unchecked")@Overridepublic Object clone() {}private void writeObject(java.io.ObjectOutputStream s)}private void readObject(java.io.ObjectInputStream s)throws IOException, ClassNotFoundException {}Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {}Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {}TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {}TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {}void reinitialize() {}void afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {}}

若有收获,就点个赞吧
0 人点赞
