概述
本章节我们对 Kafka 的日志模型进行深入探讨,研究以下问题:
- 日志文件存储为何如何高效?
- 有哪些组件支撑 Kafka 的日志模型?
- 日志文件的读/写/查找等操作?
- 优化后的二分查找算法
- 零拷贝
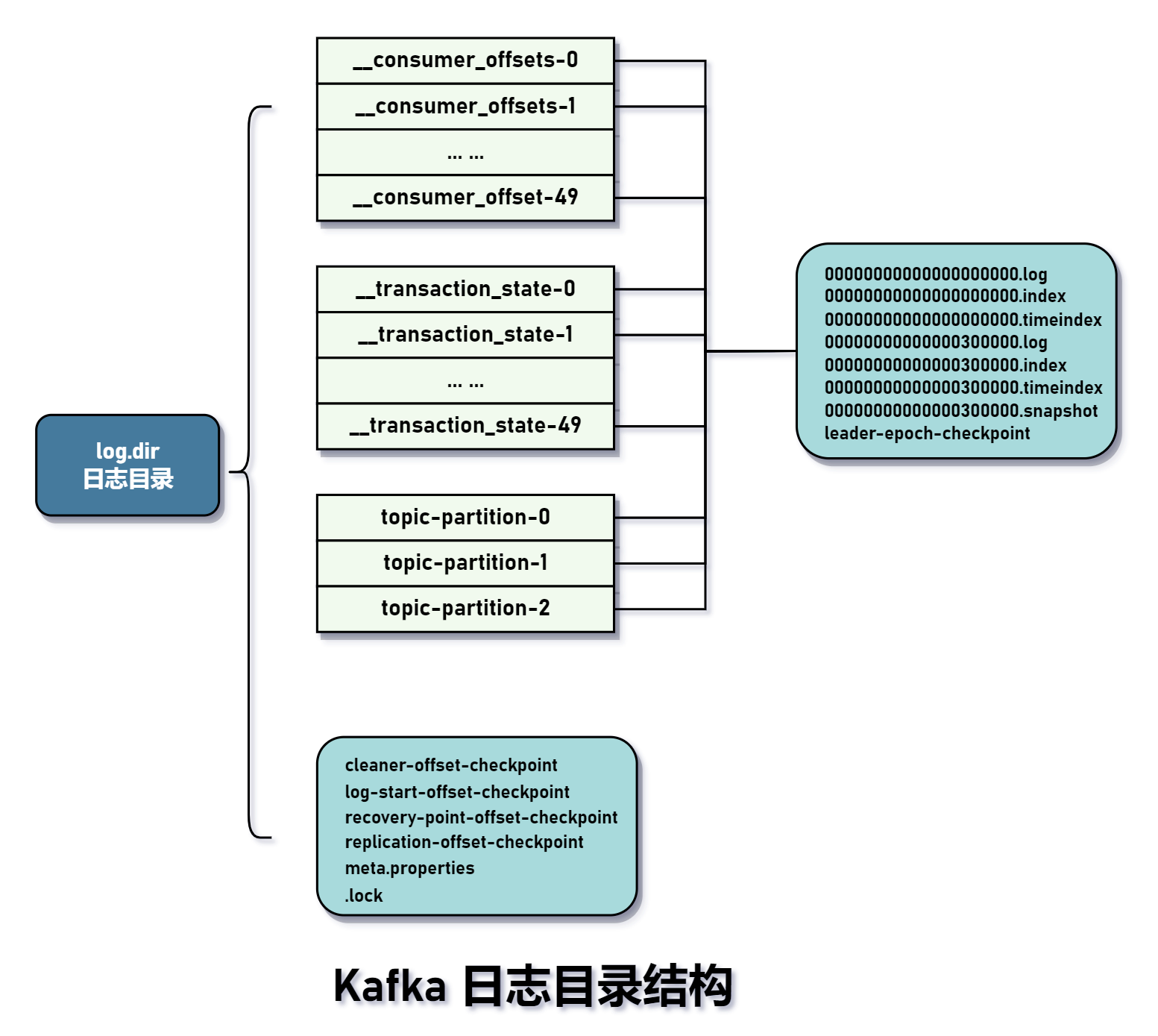
Kafka日志目录结构
这里想借助云原生时代简单谈谈 Kafka 架构设计。没错,就是和 Pulsar 做对比。Kafka 这种存算一体的架构设计在云原生时代并不适合,虽然 Kafka 支持分区扩容,但是这并不是自动的,需要运维人员参与其中。而 Pulsar 是存算分离的云原生设计架构,可以根据需求对计算层或存储层扩缩容。所以,在深入了解一门技术时,我们需要掌握框架的优势与局限,以后当成为 Leader 时根据公司需要选择合适的消息组件。
回到 Kafka,一个分区对应一个日志对象(Log),为防止 Log 无限膨胀,将 Log 切分成多个日志段对象(LogSegment),相当于将一个文件按时间或大小切分成若干个小文件,便于消息的维护和清理。LogSegment 并非和物理文件一一对应,它至少包含一个日志文件(.log结尾)和两个索引文件(.index和.timeindex),如果存在事务,则会包含以.txnindex为后缀的事务索引文件。
向 Log 追加消息时,只有最后一个 LogSegment 才能执行写入操作,在此之前所有的 LogSegment 都不能写入数据,因为它们此刻处于只读状态。只有最后一个 LogSegment 处于活跃(可写)状态。
以.log结尾的文件记录消息,生产者产生的消息都会追加到这个文件中,以.index结尾的文件是消息偏移量的索引文件,保存<消息逻辑偏移量, 消息实际物理位置>映射关系,我们会通过改进的二分查找算法从索引文件中找到上限、下限的物理偏移量,然后再到.log的日志文件中查找给定的消息偏移。.timeindex则是保存<消息时间戳, 消息实际物理位置>,可以通过消息的时间戳快速定位消息在.log的位置。
我们看到,日志目录下还包含两个内部主题,分别是__consumer_offset和__transaction_state,分别保存消费者消费位移值和事务状态。另外,底部还有以checkpoint结尾的文件,它们表示检查点文件。Broker 内部会定期对一些关键数据做持久化操作,这样可以在 Broker 宕机后恢复到宕机前的状态,保证数据的一致性。对 Kafka 相关的文件后缀进行说明
| 文件类型 | 说明 | | —- | —- | | .log | 存储消息的日志文件 | | .index | 存储<相对偏移量, 物理偏移量>索引项 | | .timeindex | 存储<时间戳, 绝对逻辑偏移量>索引项 | | .snapshot | 为幂等型或事务型 Producer 所做的快照文件 | | .txnindex | 存储已终止的事务索引项 | | .deleted | 待删除的日志段文件。删除操作是异步执行。所以这相当于是一个标识符。log cleaner 根据相关日志清理策略清理旧的日志文件。 | | .cleaned | log compact(日志压紧)操作产生的临时文件,在进行log compact时,产生对复制旧的日志段文件,在旧的文件名基础上加上这个后缀作为新的文件名 | | .swap | log compact(日志压紧)操作产生的临时文件,当对.cleaned完成 compact 操作后,会将文件名的后缀修改为.swap,表示可以和旧的日志段文件(.log 结尾)交换,使之成为新的日志段文件,旧的日志段文件会添加 .deleted后缀 | | .kafka_cleanshutdown | 是一标记文件,如果文件存在,表示Broker上次是正常关闭(clean shutdown),重启过程不需要进行恢复操作。如果文件不存在,意味着Broker由于崩溃而导致部分文件错误,需要进行恢复(recovery)操作。 | | -delete | 当删除一个主题时,该主题的所有分区的文件夹会被添加这个后缀 | | -future | 变更主题分区文件夹地址 |val LogFileSuffix = ".log"val IndexFileSuffix = ".index"val TimeIndexFileSuffix = ".timeindex"val ProducerSnapshotFileSuffix = ".snapshot"val TxnIndexFileSuffix = ".txnindex"val DeletedFileSuffix = ".deleted"val CleanedFileSuffix = ".cleaned"val SwapFileSuffix = ".swap"val CleanShutdownFile = ".kafka_cleanshutdown"val DeleteDirSuffix = "-delete"val FutureDirSuffix = "-future"
对日志目录相关文件进行说明
| 文件名 | 说明 |
|---|---|
| cleaner-offset-checkpoint | 保存 cleaner 线程对每个分区的偏移量检查点,方便 Broker 重启后继续从检查点开始进行清理工作 |
| log-start-offset-checkpoint | 保存每个分区对应的Log Start Offset,能够减少Broker启动消耗时间。当调用LogManager#shutdown会对当前Broker的所有分区的 Log Start Offset 进行快照存储。 |
| meta.properties | Broker 元数据信息,包含cluster.id、version 和 broker.id |
| recovery-point-offset-checkpoint | 记录每个分区写入磁盘的偏移量 |
| replication-offset-checkpoint | 每隔一段时间记录所有分区的 High Watermark 的值 |
日志格式的演变
从 0.8.x 版本到 2.0.0 版本,Kafka 的消息格式经历了 3 个版本: v0、v1 和 v2。
v0
在 Kafka 0.11.0 之前都采用这个消息格式。
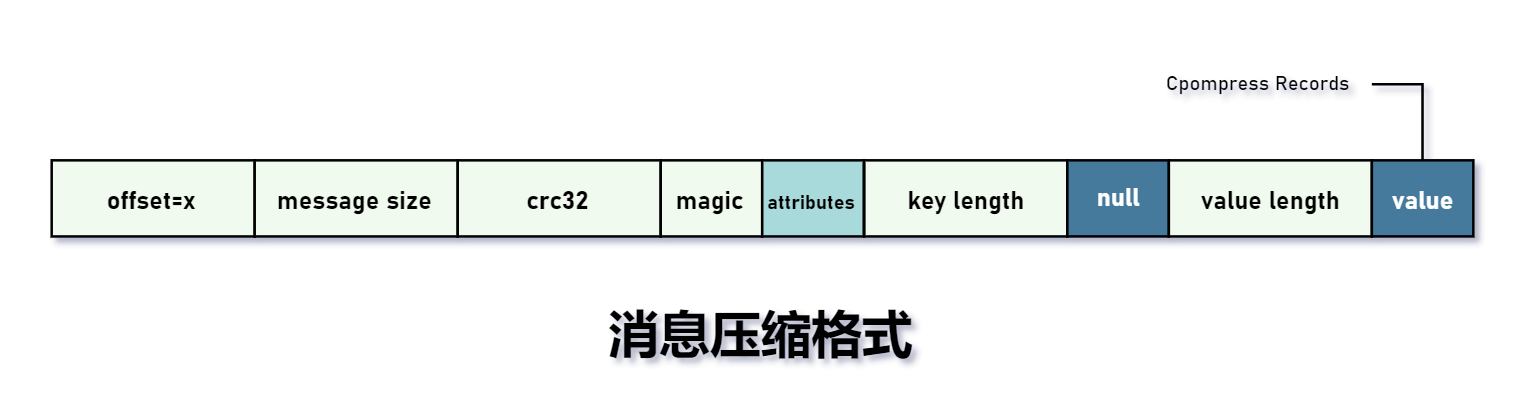
- offset:每条消息都会有一个 offset 用来标记它在分区中的偏移量,它是逻辑值,而非实际物理偏移量。
- message size:消息大小。offset + message size 统称为日志头部(LOG_OVERHEAD),固定为 12B。LOG_OVERHEAD + Record 一起用来描述一条消息。
- crc32:crc32 校验值,从 crc32 开通算起。
- magic:消息格式版本号,此版本的 magic 值为 0。
- attributes:目前使用前 3 位表示消息压缩类型。0:NONE、1:GZIP、2:SNAPPY、3:LZ4。其余位为保留位。
- key length:key 的长度。如果为
-1表示没有设置 key。 - key:可靠。如果 key==null,则没有这个字段。
- value length:value 的长度。如果为
-1表示没有设置 value。 - value:消息体,可以为空,比如墓碑(tombstone)消息。
从上面分析中可以看出,v0 版本每条消息至少占用 12B 大小的空间。其实,这些数据是冗余的。
v1
Kafka 从 0.10.0 版本开始到 0.11.0 版本之前所使用的消息格式版本为 v1,比 v0 版本就多了一个 timestamp 字段,表示消息的时间戳,并且 attributes 的第 4 位表示时间戳类型:0 表示 CreateTime,1 表示 LogAppendTime。
v1 版本的最小长度比 v0 版本要大 8 个字节,即 22B。
消息压缩
常见的压缩算法通常是数据量越,压缩效果越好。但一条消息通常不会太大,这就导致压缩效果不理想。而 Kafka 是以批次为单位进行压缩,这样可以保证较好的压缩效果。在一般情况下,生产者发送的压缩消息在 Broker 端也是保持压缩状态存储的,消费者从 Broker 端获取的也是压缩消息,消费者在处理消息时才会对消息进行解压缩。
Kafka 日志中使用哪种压缩方式通过参数 compression.type 指定,默认为 producer 表示保留生产者使用的压缩方式,此外还可以配置为 gzip、snappy、lz4 等常用压缩算法。如果参数为 uncompressed 表示不压缩。
当消息压缩时是将整个消息集合(Record Set)进行压缩,然后将压缩后的数据写入 value 字段。
V2
Kafka 0.11.0 版本开始使用 V2 版本的消息格式,相较之前改动很大。同时参考了 Protocol Buffer 引入了变速整型(Varints)和 ZigZag 编码。
Varints 是使用一个或多个字节序列化整数的算法。数值越小,占用的字节数就越小。最高位是天体战士标志位,表示后面的字节是否和自己组合表示一个整数。Varints 使用的是小端字节序的布局方式,计算时需要翻转。Varints 可以用来表示 int32、int64、uint32、uint64、sint32、sint64、bool、enum 等类型。 但是使用 Varints 对负数编码存在较大的区别,变了使编码更加高效,Varints 使用 ZigZag 的编码方式。 ZigZag 编码以一种锯齿形的方式来回穿梭正负事业,将带符号整数映射为无符号整数,这样可以使绝对值较小的负数仍然享有较小的 Varints 编码值。
RecordBatch =>BaseOffset => Int64Length => Int32PartitionLeaderEpoch => Int32Magic => Int8CRC => Uint32Attributes => Int16LastOffsetDelta => Int32 // also serves as LastSequenceDeltaFirstTimestamp => Int64MaxTimestamp => Int64ProducerId => Int64ProducerEpoch => Int16BaseSequence => Int32Records => [Record]
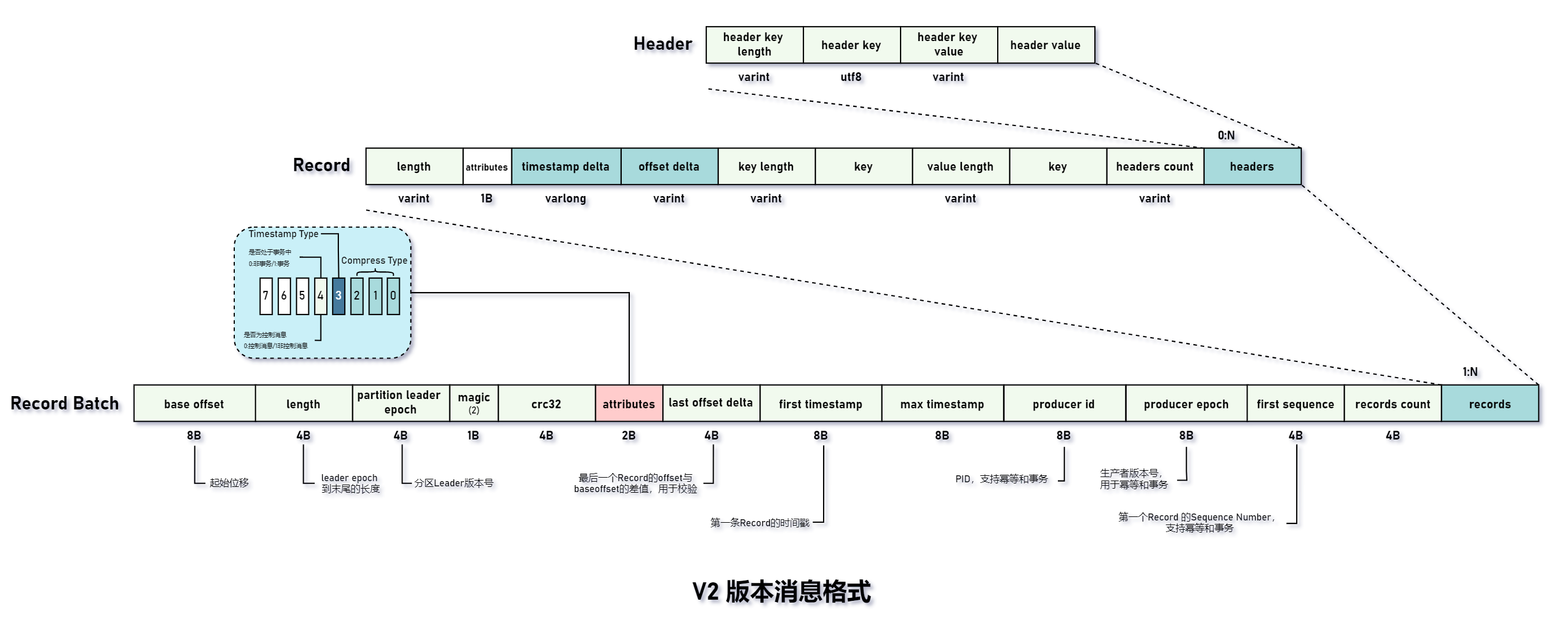
首先对 Record 字段进行解析:
- length:消息总长度。
- attributes:v2 协议弃用,以备未来扩展。
- timestamp delta:时间戳增量。由于时间戳需要 8 个字节来存在,如果保存与 RecordBatch 的起始时间戳的差值,就可以节省大量空间(积少成多)。
- offset delta:位移增量。保存与 RecordBatch 起始位移差值。节点空间。
- headers:支持应用级别扩展,如果应用需要自定义请求头就可以添加到这个字段中。
对 Record Batch 字段进行解析:
- base offset:当前 RecordBatch 的起始位移。
- length:从 partition leader epoch 字段开始到末尾的长度。
- partition leader epoch:分区 Leader 版本号,用来屏蔽 Zombie Leader。
- magic:消息格式的版本号。目前的版本号对应的 magic 值为2。
- attributes:消息属性。这里增加了和事务相关的标志位。第 5 位表示这个 RecordBatch 是否处于事务中,0 表示非事务,1 表示事务。第 6 位表示是否是控制消息(ControlBatch),0 表示非控制消息,1 表示控制消息。控制消息用来支持事务功能。
- last offset delta:RecordBatch 最后一个 Record 的 offset 与 base offset 的差值。
- first timestampt:RecordBatch 第一个 Record 的时间戳。
- max timestamp:RecordBatch 中最大的时间戳,一般是最后一个 Record 的时间戳。用来确保消息组装的正确性。
- producer id:PID,用来支持幂等和事务。
- producer epoch:生产者版本号。用来支持幂等和事务。
- first sequence:处于事务的第一条消息对应的 Sequence Number。用于支持幂等和事务。
- records count:RecordBatch 中 Record 的个数。
虽然 v2 看上去单条日志需要更大的空间,但是 Kafka 将多个消息组装成批次,并使用 Varint 编码、相对时间偏移量、相对位移偏移量等优化又节省了很多空间。除此之外,v2 版本的消息提供了更强大的功能:幂等和事务。总体来说,性能提升是十分明显的。
索引文件
索引文件分为两大类,一是根据偏移量获取对应的物理偏移量,二是根据时间戳获取对应的物理偏移量。Kafka 中的索引文件是以稀疏索引(sparse index)的方式构造消息索引,换句话说,并非每条消息都能在索引文件中找到对应的物理偏移量。每当写入一定量(由 log.interval.bytes 指定,默认值:4KB)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项。
由于偏移量和时间戳在各自的索引文件都是单调递增的,所以可以通过十分查找算法在  时间范围内找到一个范围区间(如果偏移量刚好存在,上限和下值相等)。这里会对二分查找算法进行优化。TODO
时间范围内找到一个范围区间(如果偏移量刚好存在,上限和下值相等)。这里会对二分查找算法进行优化。TODO
MappedByteBuffer
Kafka 使用 Java NIO 的 MappedByteBuffer 操作大文件,以加快索引的查询速度。
索引文件格式
偏移量索引文件格式

索引文件并没有使用绝对偏移量,而使用相对偏移量。偏移量索引文件名称是基础偏移量,基础偏移量+相对偏移量=绝对偏移量。这样做也是节省磁盘空间。
时间戳索引文件格式

每个索引项占用 12 个字节,时间戳索引文件还是以偏移量命名,所以不存在相对时间戳偏移量。每个追加的时间戳都必须大于之前追加的索引项 timestamp,否则不会追加。
日志文件(包含索引文件)切分规则
- 当前日志文件的大小超过 Broker 端参数
log.segment.bytes的值。默认值:1GB。 - 日志段中消息的最大时间戳与当前系统的时间戳的差值大于
log.roll.ms或log.roll.hours的值(如果同时配置,选择log.roll.ms),默认情况只配置log.roll.hours参数,其值为 168,即 7 天。 - 对偏移量和时间戳索引文件而言,它文件大小达到 Broker 端参数
log.index.size.max.bytes(10MB)。 追加的消息的偏移量与当前日志分段的偏移量之间的差值大于
Integer.MAX_VALUE,即要追加的消息偏移量无法转换为相对偏移量(溢出了)。如何根据索引确定消息在物理文件中的位置
根据偏移量索引文件查找消息
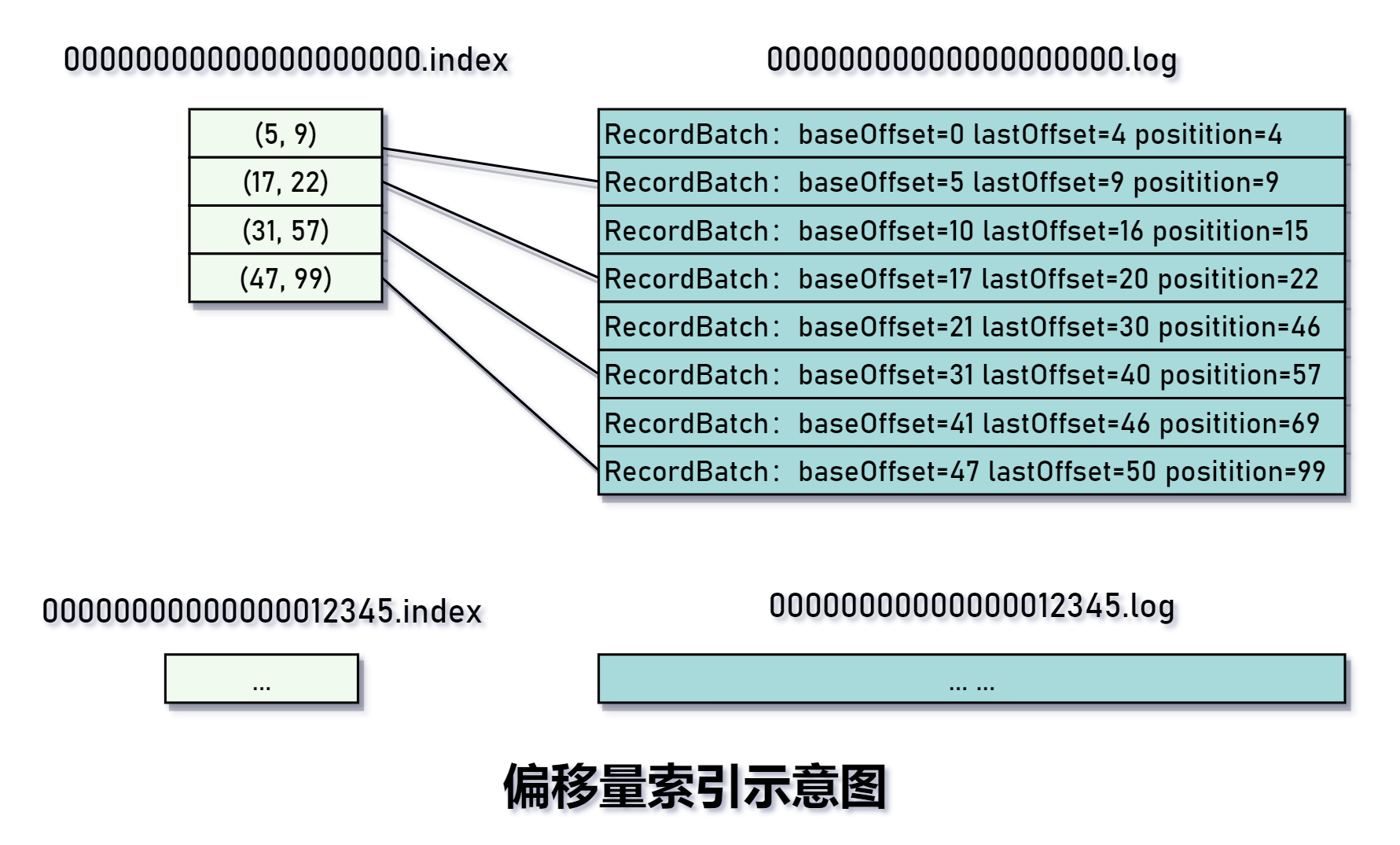
上图是一个简单的偏移量索引示意图,分别有两个日志文件和两个索引文件,因为为了方便管理,所以将日志段切分成多个文件。文件名是基础偏移量,文件内的内容使用相对偏移量,基础偏移量 + 相对偏移量 = 绝对偏移量,这个公式很好理解。
我们来思考如何定位绝对偏移量为 23 的消息?首先根据绝对偏移量定位索引文件。Kafka 使用 ConcurrentSkipListMap 存储日志段对象, key 为文件名,即该日志段的基础偏移量,value则为日志段对象。找到不大于 23 的最大偏移量,这里是 00..000.log。
- 计算相对偏移量 = 23 - 0 = 23。
- 通过二分法在偏移量索引文件中找到不大于 23 的最大索引项,即 (17, 22)
从日志段(.log)的物理位置 22 开始顺序查找偏移量为 23 的消息。
根据时间戳索引文件查找消息
时间戳索引文件查找步骤相对复杂,但原理基本相同:
由于无法使用 ConcurrentSkipListMap 确定日志段对象,只能将目标时间戳和日志段中的最大时间戳
largestTimeStamp逐一比对,直到找到不小于目标时间戳的largestTimeStamp所对应的日志段。- 在日志段的时间戳索引文件中使用二分法查找不大于目标时间戳最大的索引项。得到一个相对偏移量。
- 在偏移量索引文件中使用二分法查找不大于该相对偏移量的最大索引项,得到物理偏移量。
根据物理偏移量在目标日志文件中(.log)按顺序查找目标时间戳的消息。
二分查找算法
正常二分查找算法局限性
Kafka 使用 MappedByteBuffer 将文件直接遇到到内存中,在大多数情况下,这可以避免磁盘 I/O 阻塞。据我们所知,所有现代操作系统都使用 LRU 策略或其变体来管理页缓存。
Kafka总是将新的消息追加到文件末尾,而且几乎所有的索引查找操作(通常来自Follower同步或消费者消费消息)都接近于索引文件的尾部,所以尾部这段数据成了热点数据。那么,这么看来,LRU 淘汰策略有不错的效果,至少没有起明显冲突。然而,在查找目标索引项时,标准的二分法对缓存并不友好,因为会导致不必要的缺页异常。这是因为二分查找算法需要比较头和尾两个节点,而头结点所在的页可能被淘汰了,触发缺页异常,内核再从磁盘加载相应数据,这一步是非常慢的。但是我们前面说过。几乎所有的索引查找操作都是集中在文件末尾,因此出现了明显的冲突。比如,索引文件有13个页缓存,目的查找第12页,那么标准的二分法会读取0, 6, 9, 11和12这5个页,因为数据不断追加,所以这会导致越靠前的页淘汰概率越大,出现不必要的缺页异常也增加。缓存友好型的二分查找算法
算法思想比较简单:确定一个位置 N,在 N 的左边称为冷区(Code Area),这些数据存在页缓存的概率较低,需要通过缺页异常重新从磁盘将数据加载到内存中。 而在 N 的右边称为热区(Warn Area),处于热区的数据大概率会存在系统的页缓存中。因此,我们先对目标值做一个冷热判断,而不是一股脑直接使用二分法查找。
那如何定义位置 N 呢? Kafka 是直接写死为8192/entrySize,原因有以下两点:这个数字足够小,可以保证每次在热区中查找时不会引发缺页异常,即这些页都存在于页缓存中。当我们在热区进行查找时,indexEntry(end),、indexEntry(end-N)、indexEntry((end*2 -N)/2) 得到的这三个对象总能在页缓存中命中。
- 这个数字也足够大,可以保证大部分同步二分搜索都在热区。Kafka默认配置:8KB 的索引对应约 4MB 的偏移量索引或 2.7MB 的时间戳索引的日志消息。
下面看看实际的源码:
// kafka.log.AbstractIndex#indexSlotRangeForprotected def _warmEntries: Int = 8192 / entrySize/*** 改进后的缓存友好型二分查找算法** @param idx mmap缓存映射对象* @param target 目标值。对于偏移量索引则是相对偏移量,对于时间戳索引则是目标时间戳* @param searchEntity 按key搜索还是按value搜索* @return*/private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchType): (Int, Int) = {// #1 如果索引文件为空,立即返回-1if (_entries == 0)return (-1, -1)// 定义二分查找算法def binarySearch(begin: Int, end: Int): (Int, Int) = {// binary search for the entryvar lo = beginvar hi = endwhile (lo < hi) {val mid = (lo + hi + 1) >>> 1val found = parseEntry(idx, mid)val compareResult = compareIndexEntry(found, target, searchEntity)if (compareResult > 0)hi = mid - 1else if (compareResult < 0)lo = midelsereturn (mid, mid)}(lo, if (lo == _entries - 1) -1 else lo + 1)}// #2 获取热区第一个实体val firstHotEntry = Math.max(0, _entries - 1 - _warmEntries)// #3 比较确定目标对象在热区还是冷区if (compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {// #3-1 在热区进行二分查找return binarySearch(firstHotEntry, _entries - 1)}// #3-2 检查目标偏移量是否比最小的还小if (compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0) {// 比最小的还小,说明怎么找也找不到,直接返回return (-1, 0)}// #3-3 对冷区进行二分查找binarySearch(0, firstHotEntry)}
使用命令查看日志文件
Kafka 提供 kafka-dump-log 工具方便我们查看特定类型的 Kafka 文件,包括 .log 、.index、.index 、.snapshot 等。--help 输出的内容如下:
--deep-iteration if set, uses deep instead of shallowiteration. Automatically set if print-data-log is enabled.--files <String: file1, file2, ...> REQUIRED: The comma separated list of dataand index log files to be dumped.--help Print usage information.--index-sanity-check if set, just checks the index sanitywithout printing its content. This isthe same check that is executed onbroker startup to determine if an indexneeds rebuilding or not.--key-decoder-class [String] if set, used to deserialize the keys. Thisclass should implement kafka.serializer.Decoder trait. Custom jar should beavailable in kafka/libs directory.(default: kafka.serializer.StringDecoder)--max-message-size <Integer: size> Size of largest message. (default: 5242880)--offsets-decoder if set, log data will be parsed as offsetdata from the __consumer_offsets topic.--print-data-log if set, printing the messages content whendumping data logs. Automatically set ifany decoder option is specified.--transaction-log-decoder if set, log data will be parsed astransaction metadata from the__transaction_state topic.--value-decoder-class [String] if set, used to deserialize the messages.This class should implement kafka.serializer.Decoder trait. Custom jarshould be available in kafka/libsdirectory. (default: kafka.serializer.StringDecoder)--verify-index-only if set, just verify the index log withoutprinting its content.--version Display Kafka version.
输出日志数据:
kafka-dump-log.sh --files 00000000000000000000.log --print-data-log
kafka-dump-log.sh --files 00000000000000000000.indexDumping 00000000000000000000.indexoffset: 1009 position: 10887
Kafka日志清理策略(compact、delete)
kafka 的日志清理策略有两种,分别是 delete 和 compact。默认是 delete。
- delete:当不活跃的日志段超过一定时间阈值或大小就会被删除。
- compact:日志压实(翻译成日志压缩可能会产生一定误解,压实更能反映实际的操作场景)能确保 Kafka 始终为分区中的每个消息键保留最后一个已知值。应用场景举例:比如应用崩溃或系统故障后恢复状态,或在运行维护期间应用重启后重新加载缓存。
可以通过 Broker 端的配置项 cleanup.policy 修改 Kafka 日志清理策略。
日志段文件生成策略
日志段文件生成策略有两点:
segment.bytes:空间维度。根据日志段文件大小做分割。超过这个大小就会生成新的日志段。默认值是1GB。segment.ms:时间维度。每隔一定时间生成一个新的日志段文件。默认值是7天。
这两个配置是同时起作用。满足任一一个条件都会生成新的日志段文件。
日志删除(delete)
日志段文件不可以无限创建,否则磁盘空间很快就满载,合适的日志清理可以保证 Kafka 集群可用。日志删除策略是 Kafka 的默认策略,它又基于两个维度对日志文件进行删除操作,分别是基于时间的日志删除和基于空间的日志删除操作。
Kafka 内部会有一个线程周期性对不活跃的日志段文件进行检查,满足以下任意配置就可以执行删除日志段文件操作。
基于时间的日志删除
核心配置参数 log.retention.ms/log.retention.hours,日志保留时间,默认值 168小时(7天)。当消息在集群保留的时间超过所设置的阈值就会被删除。kafka 根据日志段的最大时间戳来判断该日志段(segment)是否满足时间要求,如果不满足,则说明该日志段内的所有消息都已过期,可以删除该日志段。
基于空间的日志删除
核心配置参数 log.retention.bytes ,日志保留大小,默认值 -1,即不采用基于空间的日志删除策略。当总的日志段大小超过阈值时,Kafka 会先删除旧的日志段,直到小于所设定的阈值就停止删除操作。
针对周期性检查日志段文件也有相关配置:
log.retention.check.interval.ms:Broker 端配置参数。表示每隔多久检查一次是否有可删除的日志段,默认是 300S,即 5 分钟。file.delete.delay.ms:在彻底删除文件前所保留时间。默认是 1 分钟。基于日志起始偏移量的日志删除
log start offset是一个很重要的偏移值,它表示消费者可以开始消费的起始偏移量。小于log start offset的消息就可以删除了。日志压实(compact)
delete 是简单的日志保留策略,当超过一定时间或大小后将旧的日志文件删除,这对于时间性的事件数据来说很有效,比如每条记录都是单独存在的日志。然而,一类重要的数据流是对关键的、易变的数据的变化进行日志记录(例如,数据库表的变化)。确保在程序崩溃时可以全量加载所有数据。可以拿数据库进行类型,我们对一个记录进行增、删和改一系列操作,将这些操作记录到日志文件,当我们对日志文件进行压缩后,保留最后一次对该条记录的日志文件。其它的可以被删除。这种做法会导致我们无法对历史数据进行溯源,但可以保留全量数据,这需要根据自己业务进行合理判断。
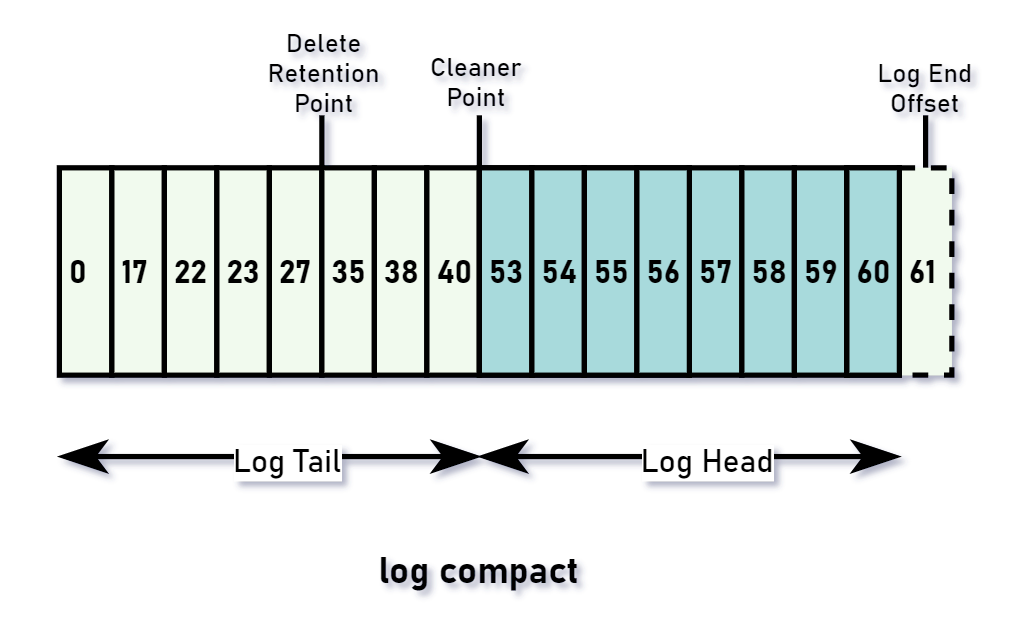
上图是某个日志段文件内的日志压实(log compact)示意图,对相关指针变量进行解释:log end offset:LEO,下一条待写入消息的偏移量。
- cleaner point:日志清理点。该偏移量之前的日志消息都已进行日志压实操作。所以我们一般会看到日志的偏移量是不连续的。
- delete retention point:删除保留点。如果我们想删除某一个 key 时该怎么做呢? 就该 key 的 value 赋值为 null 即可,这样的消息称为墓碑消息(tombstone)。因此,delete retention point 表示在该偏移量之前的墓碑消息都已经被删除了。
- log tail:日志尾部,也称为
cleaned数据,这一段消息已经经过压实(compact)处理。 - log head:日志头部,也称为
Dirty数据,这一段消息等待压实处理。
从上图中我们还应该知道,消息的偏移量是不会改变的,即便它造成的消息序列号不连续。

上图是日志压紧操作示意图,可以很清楚看到,log compact 操作材质就是保留 key 的最新值。
日志压实相关配置项
和日志压实相关的配置有以下这些:
min.compaction.lag.ms:表示某一条消息多长时间不会被 compact。这是为了满足有些想要获取一定时间内的历史快照的业务。默认值是 0,就是不会根据消息投递时间来决定消息是否应该被 compact。min.cleanable.dirty.ratio:可以进行 compact 的脏数据的比例。默认值是 0.5。
log compaction 是由 log cleaner 处理的,这是一个后台线程,它重新复制日志段文件,删除那些键出现在日志头部的 key 以及对应的 value。每个log cleaner 线程的工作方式如下:
- 选择 log head 和 log tail 的比例最高的日志段。
- 对 log head 区间的每个 key 的最后偏移量创建一个摘要。
- 它从头到尾重新复制日志,删除在日志中稍后出现的 key。新的、干净的片段会被立即交换到日志中,所以所需要的额外磁盘空间只是一个额外的日志片段(而不是日志的完整拷贝)。
- 日志头的摘要本质上只是一个空间紧凑的哈希表。它每个条目正好使用 24 个字节。因此,用 8GB 的清洁器缓冲区,一个清洁器的迭代可以清洁大约 366GB 的 log head(假设是1k的消息)。
参考
- 「书籍」深入理解Kafka:核心设计与实践原理
- 极客时间 Kafka 核心源码解读
- 柳年思水
- Kafka Document
- Kafka RPC 协议

若有收获,就点个赞吧
0 人点赞
