概述
当集群没有可用的 Controller 时,每个 Broker 都可以参与 Controller 竞选,但只能有一个 Broker 竞选成功。
实现逻辑
谁能创建 /controller 临时节点成功,谁就成当选成为集群的 Controller。其它 Broker 会监听 /controller 节点,一旦发现该节节点创建、删除和数据变更等情况,就会注册相关 Controller 事件。
/*** 这个处理器监听Zookeeper节点「/controller」的变化:创建、删除、修改都会被监听到,* 并配合具体的变化向 {@link ControllerEventManager} 事件管理器中放入对应的Controller事件。* 事件驱动模型** @param eventManager*/class ControllerChangeHandler(eventManager: ControllerEventManager) extends ZNodeChangeHandler {/*** Controller所关闭的Zookeeper节点:/controller*/override val path: String = ControllerZNode.path/*** 当节点创建时,将 {@link ControllerChange} 事件提交给* 事件管理器 {@link ControllerEventManager} 处理*/override def handleCreation(): Unit = eventManager.put(ControllerChange)/*** 当节点被删除时,将 {@link Reelect} 事件提交给事件管理器处理。* 节点被删除意味着接下来需要进行Controller选举*/override def handleDeletion(): Unit = eventManager.put(Reelect)/*** 当节点被修改时,将 {@link ControllerChange} 事件交给事件管理器处理*/override def handleDataChange(): Unit = eventManager.put(ControllerChange)}
Controller 选举
Controller 选举流程图如下所示: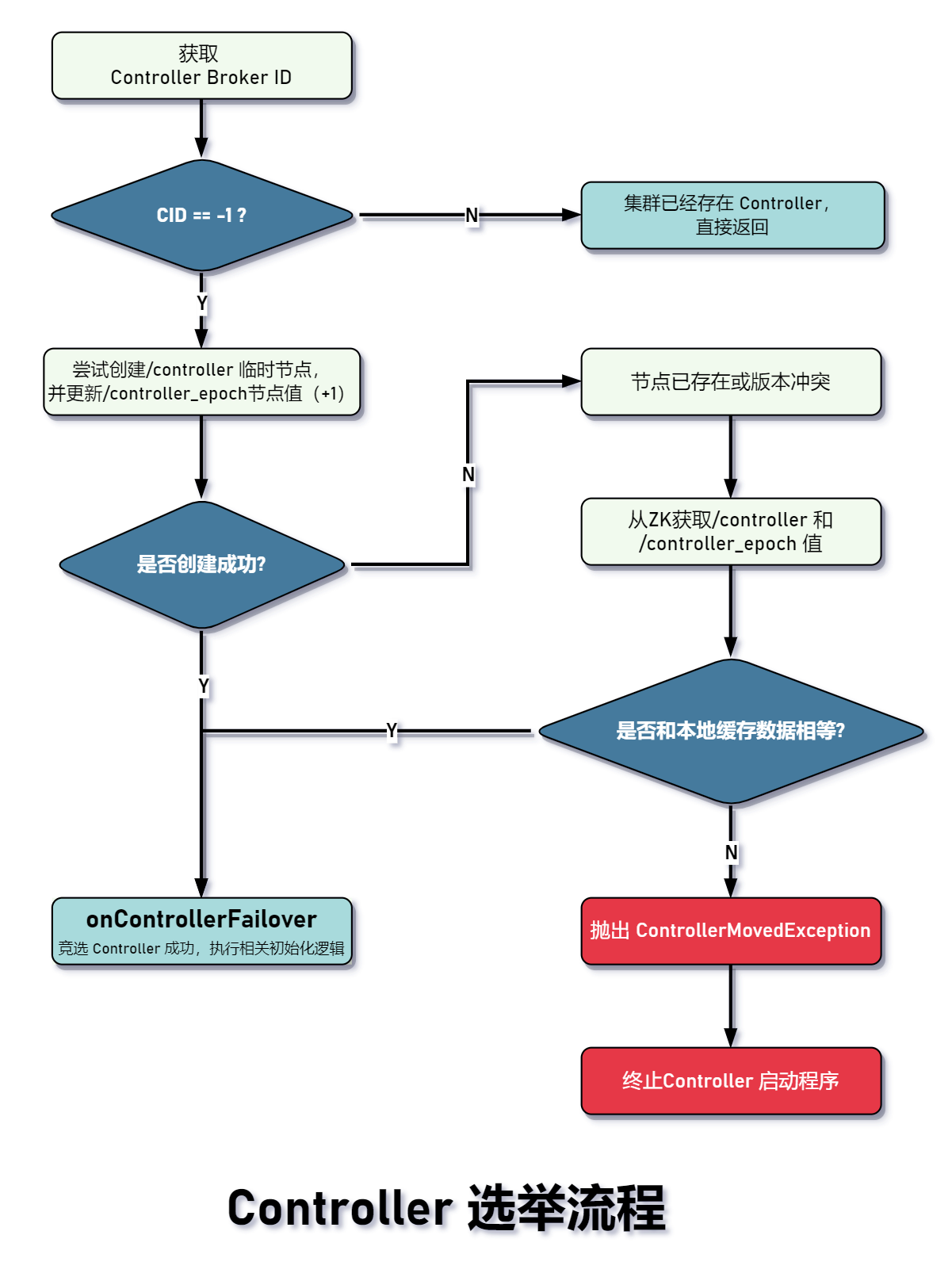
/*** 执行Controller选举操作*/private def processReelect(): Unit = {// #1 由于已经触发新的Controller选举,// 旧的Controller就需要退位了maybeResign()// #2 尝试竞选Controllerelect()}
方法 #1 移除 Zookeeper 注销相关 ChangeHandler 处理器、关闭调度器、关闭副本、分区状态机、重置 ControllerContext 的注册节点等。
方法 #2 是 controller 选举的核心方法:
/*** Controller选举核心方法:* 1.首先确认「/controller」的broker id 是否>=0,* 如果是,则说明Controller已存在,如果为-1,则需要进行接下来的选举操作(注意,并非100%竞选成功)* 2.再尝试获取两个版本号,分别是/controller_epoch的值和这个节点对应的ZK的version的值,称为zkVersion* 3.尝试创建/controller临时节点,并将版本号+1* 4.执行成功当选controller的后续逻辑(failover:故障转移)*/private def elect(): Unit = {// #1 从Zookeeper获取Controller Id,即所在的Broker ID(/controller)。// 如果没有则为-1,意味着当前此刻集群没有选出确切的controlleractiveControllerId = zkClient.getControllerId.getOrElse(-1)// #2 id 不等于-1,表示集群已经选出Controller,直接返回if (activeControllerId != -1) {debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")return}try {// #3 尝试创建/controller临时节点,并将版本号+1val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)controllerContext.epoch = epochcontrollerContext.epochZkVersion = epochZkVersionactiveControllerId = config.brokerIdinfo(s"${config.brokerId} successfully elected as the controller. Epoch incremented to ${controllerContext.epoch} " +s"and epoch zk version is now ${controllerContext.epochZkVersion}")// #4 执行成功当选controller的后续逻辑(failover:故障转移)onControllerFailover()} catch {case e: ControllerMovedException =>maybeResign()if (activeControllerId != -1)debug(s"Broker $activeControllerId was elected as controller instead of broker ${config.brokerId}", e)elsewarn("A controller has been elected but just resigned, this will result in another round of election", e)case t: Throwable =>error(s"Error while electing or becoming controller on broker ${config.brokerId}. " +s"Trigger controller movement immediately", t)triggerControllerMove()}}
/*** 创建/controller临时节点,并更新相关版本号。* 1. 从ZK中获取/controller_epoch详情,包括controller版本号和节点版本号(zkVersion),这存在以下两种情况* ① 如果/controller_epoch节点存在,直接返回* ② 如果节点不存在,则尝试创建,这一步又会出现以下情况:* 1.成功创建,则正常返回获取到的数据* 2.创建失败,说明有其它Broker抢先创建,那就就再次发送获取数据的请求并返回* 2. 创建/controller* ① 版本号+1*** Registers a given broker in zookeeper as the controller and increments controller epoch.* 将Broker ID向Zookeeper注册为Controller,且更新controller epoch* ① 获取/controller_epoch节点数据,得到(Controller版本号,ZNode版本号)。如果节点不存在,则尝试创建新的,* 如果创建新的过程中发现已经被别的Broker抢先创建,那么再次向Zookeeper发送请求获取最新的/controller_epoch节点的数据* ②***** @param controllerId Broker ID* @return Tuple变量(已更新的Controller版本号, zkVersion版本号)* @throws ControllerMovedException 创建 /controller 节点失败或增加controller epoch失败,那么抛出异常*/def registerControllerAndIncrementControllerEpoch(controllerId: Int): (Int, Int) = {val timestamp = time.milliseconds()// #1 从ZK中获取节点/controller_epoch的值和zkVersion版本号(一定可以得到确切值)。// 如果节点不存在则创建并初始化val (curEpoch, curEpochZkVersion) = getControllerEpoch.map(e => (e._1, e._2.getVersion)).getOrElse(maybeCreateControllerEpochZNode())// #2 尝试创建「/controller」节点并更新「/controller_epoch」的值,这两步是原子操作val newControllerEpoch = curEpoch + 1 // 节点「/controller_epoch」的值表示controller版本号val expectedControllerEpochZkVersion = curEpochZkVersiondebug(s"Try to create ${ControllerZNode.path} and increment controller epoch to $newControllerEpoch " +s"with expected controller epoch zkVersion $expectedControllerEpochZkVersion")/*** 之前尝试创建/controller,但是遇到NODEEXISTS或BADVERSION错误,可能/controller已经被创建了** 检查Controller和版本号* @return*/def checkControllerAndEpoch(): (Int, Int) = {// #1 从ZK中获取Controller ID,如果不存在,则抛出异常val curControllerId = getControllerId.getOrElse(throw new ControllerMovedException(s"The ephemeral node at ${ControllerZNode.path} went away while checking whether the controller election succeeds. " +s"Aborting controller startup procedure"))// #2 判断controller id和controller epoch的值是否和本地broker缓存相等,// 只要发现其中一个不相等,说明出现数据不一致,抛出异常if (controllerId == curControllerId) {// #2-1 获取「/controller_epoch」节点的值val (epoch, stat) = getControllerEpoch.getOrElse(throw new IllegalStateException(s"${ControllerEpochZNode.path} existed before but goes away while trying to read it"))// #2-2 如果和newControllerEpoch相等,说明本轮选举事务一致,// 否则是其它轮次的Controller选举向/controller_epoch写入一个更大的值,那么低于该值的其它轮次会抛出异常if (epoch == newControllerEpoch)return (newControllerEpoch, stat.getVersion)}// 抛出异常throw new ControllerMovedException("Controller moved to another broker. Aborting controller startup procedure")}
onControllerFailover
Broker 竞选 controller 成功,接下来需要做以下事情:
- 向 Zookeeper 注册各类的监听处理器,包括:
- BrokerChangeHandler
- TopicChangeHandler
- TopicDeletionHandler
- LogDirEventNotificationHandler
- IsrChangeNotificationHandler
- 删除日志路径变更事件和 ISR 副本变更通知事件
- 启动
ControllerChannelManager,用来管理和其它 Broker 的网络连接 - 启动副本状态机
ReplicaStateMachine,用来管理集群所有副本状态 - 启动分区状态机
PartitionStateMachine,用来管理集群所有分区状态 - 初始化分区重分区管理器
- 尝试为给定的分区选出一个 Leader 副本
- 启动 Controller 调度器
- 定时清理过期 token
/*** 成功当选Controller后所执行的方法逻辑,主要包含:* ① 注册各类ZK监听器* ② 删除日志路径变更和ISR副本变更通知事件* ③ 启动Controller通道管理器(即 {@link ControllerChannelManager})* ③ 启动副本状态机{@link ReplicaStateMachine}和分区状态机 {@link PartitionStateMachine}** This callback is invoked by the zookeeper leader elector on electing the current broker as the new controller.* It does the following things on the become-controller state change -** 如果这个方法出现任何异常,那么会放弃controller身份。这确保整个集群有可用的controller对象。* 1. Initializes the controller's context object that holds cache objects for current topics, live brokers and* leaders for all existing partitions.* 2. Starts the controller's channel manager* 3. Starts the replica state machine* 4. Starts the partition state machine* If it encounters any unexpected exception/error while becoming controller, it resigns as the current controller.* This ensures another controller election will be triggered and there will always be an actively serving controller*/private def onControllerFailover(): Unit = {maybeSetupFeatureVersioning()info("Registering handlers")// #1 将以下Handler添加到ZkClient本地缓存中,// 后续在初始化ControllerContext根据这个集合判断是否需要对节点注册Zookeeper监听器val childChangeHandlers = Seq(brokerChangeHandler,topicChangeHandler,topicDeletionHandler,logDirEventNotificationHandler,isrChangeNotificationHandler)childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)// #2 删除ZK中的日志路径变更通知事件info("Deleting log dir event notifications")zkClient.deleteLogDirEventNotifications(controllerContext.epochZkVersion)// #3 删除ZK中ISR副本变更通知事件info("Deleting isr change notifications")zkClient.deleteIsrChangeNotifications(controllerContext.epochZkVersion)// #4 初始化ControllerContext上下文,里面包含Controller关于集群的一切元数据// 注册Broker监听器,一旦Broker发生变更,当前Controller可以第一时间感知并执行handler处理逻辑initializeControllerContext()// #5 从Zookeeper获取正在删除的主题列表info("Fetching topic deletions in progress")val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()// #6 初始化主题删除管理器info("Initializing topic deletion manager")topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)// #7 向集群广播「UpdateMetadataRequest」为什么要做这一步呢?目的是接下来副本状态机和分区状态机启动做铺垫,这两个状态机会向// 有关Broker发送「LeaderAndIsrRequests」,这里Broker就因为有集群元数据就可以处理这个请求了info("Sending update metadata request")sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set.empty)// #8 启动副本状态机replicaStateMachine.startup()// #9 启动分区状态机partitionStateMachine.startup()// #10 初始化分区重分配管理器info(s"Ready to serve as the new controller with epoch $epoch")initializePartitionReassignments()// #11 恢复主题删除操作topicDeletionManager.tryTopicDeletion()// #12val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()// #13 尝试为给定的分区选出一个副本LeaderonReplicaElection(pendingPreferredReplicaElections, ElectionType.PREFERRED, ZkTriggered)// #14 启动controller调度器info("Starting the controller scheduler")kafkaScheduler.startup()if (config.autoLeaderRebalanceEnable) {// #15 每5秒钟自动执行Leader重平衡scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)}// #16 定时清理过期的tokenif (config.tokenAuthEnabled) {info("starting the token expiry check scheduler")tokenCleanScheduler.startup()tokenCleanScheduler.schedule(name = "delete-expired-tokens",fun = () => tokenManager.expireTokens(),period = config.delegationTokenExpiryCheckIntervalMs,unit = TimeUnit.MILLISECONDS)}}
Broker启动
这个事件也比较重要,需要关注以下几点:
- Startup Event 是在什么时候向事件管理器注册的?
- 如何处理 Startup Event?
首先,Startup 是在启动 KafkaController 时向事件管理器注册,源码如下:
// kafka.server.KafkaServer#startup// 首先是入口方法,即KafkaServerkafkaController = new KafkaController(config, zkClient, time, metrics, brokerInfo, brokerEpoch, tokenManager, brokerFeatures, featureCache, threadNamePrefix)kafkaController.startup()
// kafka.controller.Startup$def startup() = {// #1 注册用于session过期后触发重新选举的handlerzkClient.registerStateChangeHandler(new StateChangeHandler {override val name: String = StateChangeHandlers.ControllerHandler/*** 在重新初始化session后做的操作:添加「RegisterBrokerAndReelect」事件*/override def afterInitializingSession(): Unit = {eventManager.put(RegisterBrokerAndReelect)}/*** 在重新初始化session前做的操作:添加「Expire」事件*/override def beforeInitializingSession(): Unit = {val queuedEvent = eventManager.clearAndPut(Expire)// Block initialization of the new session until the expiration event is being handled,// which ensures that all pending events have been processed before creating the new session// 阻塞等待时间被处理结束,session过期触发重新选举,必须等待选举这个时间完成Controller才能正常工作queuedEvent.awaitProcessing()}})// #2 将启动事件注册到事件管理器中eventManager.put(Startup)// #3 启动事件管理器eventManager.start()}
步骤 #2 就是将 Startup 事件注册到事件管理器中,随后启动Controller事件处理线程。
所有的 Controller 事件都是由 KafkaController 完成的,这个类代码量有 3275 行,着实令人心惊肉跳。但是没有关系,核心入口其实就是 kafka.controller.KafkaController#process 方法,从这里出发,就可以逐一窥探 Controller 的世界。
通过一系列的 CASE 判断,最终来到了 processStartup() 方法:
/*** Controller启动事件会触发此方法执行* ① 注册 {@link ControllerChangeHandler} 处理器* ② 执行选举*/private def processStartup(): Unit = {// #1 向ZookeeperClient注册Controller变更处理器,zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)// #2 执行Controller选举elect()}
BrokerChange事件
当集群中 Broker 上线/下线时,会产生 BrokerChange 事件。我们知道,一个 Broker 上存在多个分区的 Leader 副本,也存在 Follower 副本。当 Broker 下线时,会有:
- 触发 Leader 重分配。需要在 ISR 集合中选出一个新的 Follower 作为 Leader。
- ISR 集合扩缩容。Follower 副本下线,可能会导致部分分区的 ISR 扩缩容发生。
/*** 处理brokers数量变更,比如新增、删除broker*/private def processBrokerChange(): Unit = {if (!isActive) return// #1 从ZK中获取所有子节点/brokers/ids/<broker id>的详细数据// 返回现在存活的Broker列表val curBrokerAndEpochs = zkClient.getAllBrokerAndEpochsInClusterval curBrokerIdAndEpochs = curBrokerAndEpochs map { case (broker, epoch) => (broker.id, epoch) }val curBrokerIds = curBrokerIdAndEpochs.keySetval liveOrShuttingDownBrokerIds = controllerContext.liveOrShuttingDownBrokerIds// #2 本轮「新增」broker列表val newBrokerIds = curBrokerIds.diff(liveOrShuttingDownBrokerIds)// #3 本轮「离线」broker列表val deadBrokerIds = liveOrShuttingDownBrokerIds.diff(curBrokerIds)// #4 本轮「重启」的broker列表:通过判断Epoch值是否与controller缓存值相等,从而得出broker是否发生过重启val bouncedBrokerIds = (curBrokerIds & liveOrShuttingDownBrokerIds).filter(brokerId => curBrokerIdAndEpochs(brokerId) > controllerContext.liveBrokerIdAndEpochs(brokerId))// #5 准备数据val newBrokerAndEpochs = curBrokerAndEpochs.filter { case (broker, _) => newBrokerIds.contains(broker.id) }val bouncedBrokerAndEpochs = curBrokerAndEpochs.filter { case (broker, _) => bouncedBrokerIds.contains(broker.id) }val newBrokerIdsSorted = newBrokerIds.toSeq.sortedval deadBrokerIdsSorted = deadBrokerIds.toSeq.sorted//val liveBrokerIdsSorted = curBrokerIds.toSeq.sortedval bouncedBrokerIdsSorted = bouncedBrokerIds.toSeq.sorted// #6 为新增的broker准备网络相关的组件,这些是由「ControllerChannelManager」管理的newBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker)// #7 broker发生重启,需要先移除controller缓存数据,再新增该broker// 因为重启过的Broker可能修改了配置等信息,所以需要重新加入缓存bouncedBrokerIds.foreach(controllerChannelManager.removeBroker)bouncedBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker)// #8 移除「离线」broker 相关缓存deadBrokerIds.foreach(controllerChannelManager.removeBroker)// #9 处理新增的Brokerif (newBrokerIds.nonEmpty) {// #9-1 区分兼容的和不兼容的brokersval (newCompatibleBrokerAndEpochs, newIncompatibleBrokerAndEpochs) =partitionOnFeatureCompatibility(newBrokerAndEpochs)if (!newIncompatibleBrokerAndEpochs.isEmpty) {warn("Ignoring registration of new brokers due to incompatibilities with finalized features: " +newIncompatibleBrokerAndEpochs.map { case (broker, _) => broker.id }.toSeq.sorted.mkString(","))}// #9-2 只有新的可兼容的broker才能被添加进缓存中controllerContext.addLiveBrokers(newCompatibleBrokerAndEpochs)// #9-3 为新的broker启动相关组件(副本状态机、分区状态机、元数据更新操作)onBrokerStartup(newBrokerIdsSorted)}// #10 处理重启的Brokersif (bouncedBrokerIds.nonEmpty) {// #10-1 移除缓存controllerContext.removeLiveBrokers(bouncedBrokerIds)onBrokerFailure(bouncedBrokerIdsSorted)val (bouncedCompatibleBrokerAndEpochs, bouncedIncompatibleBrokerAndEpochs) =partitionOnFeatureCompatibility(bouncedBrokerAndEpochs)if (!bouncedIncompatibleBrokerAndEpochs.isEmpty) {warn("Ignoring registration of bounced brokers due to incompatibilities with finalized features: " +bouncedIncompatibleBrokerAndEpochs.map { case (broker, _) => broker.id }.toSeq.sorted.mkString(","))}// #10-2 重新加入controllerContext.addLiveBrokers(bouncedCompatibleBrokerAndEpochs)onBrokerStartup(bouncedBrokerIdsSorted)}// #11 处理「离线」的brokersif (deadBrokerIds.nonEmpty) {// 移除缓存、调用onBrokerFailurecontrollerContext.removeLiveBrokers(deadBrokerIds)onBrokerFailure(deadBrokerIdsSorted)}////if (newBrokerIds.nonEmpty || deadBrokerIds.nonEmpty || bouncedBrokerIds.nonEmpty) {// info(s"Updated broker epochs cache: ${controllerContext.liveBrokerIdAndEpochs}")//}}
关键方法:
onBrokerStartup(newBrokerIdsSorted)onBrokerFailure(deadBrokerIdsSorted)
新增 Broker 逻辑:
- 向集群广播有一个新的 Broker 加入集群了,请大家同步该 Broker 的元数据。
- 向 Broker 发送 UpdateMetadata 请求,并附带集群所有分区信息。
- 将新增的 Broker 上所有副本设置为 Online 状态。
- 触发分区状态机修改相关分区状态。
- 重启之前暂停的副本迁移工作。
- 重启之前暂停主题删除操作。
为新增的Broker注册监听器。
/***** 此回调是由副本状态机的broker改变监听器调用,入参是新的brokers id 列表。* 这个方法执行以下步骤:* ① 向所有存活的或正在关闭的broker发送「updatemetadata」请求* ② 触发所有新的/离线的分区的 OnlinePartition 状态更改。* ③ 检查是否重分配的副本分配给任何新启动的brokers。如果是这样的话,它会为每个每个主题/分区执行重分配逻辑。* 请注意,此时我们不需要为所有主题/分区刷新leader/isr缓存,原因有两点:* ① 当分区状态机触发在线状态变更时,将仅刷新当前新分区的leader和ISR或离线(而不是该控制器知道的每个分区)(rather than every partition this controller is aware of)* ② 即使我们确实刷新了缓存,也不能保证在领导者和 ISR 请求到达每个代理时它仍然有效。 broker通过检查leader epoch以推断请求的合法性。*//*** 首先,我们应该对入参「newBrokers」有一个清楚的认识:它不代表是新创建的Broker,有可能之前处于离线状态,然后经过一段时间重启并重新加入集群中,它也属于newBrokers。* 所以,为什么一开始需要从「replicasOnOfflineDirs」移除缓存就是因为它们之前存在过,所以这一步是有必要的。* #2 元数据更新请求「updatemetadata」的发送也是有技巧的,kakfa将broker分为两大类,* 一类是已存在的,和新增的。前者不需要携带完整的分区状态信息,只需要发个通知告知broker有新的成员加入,* 而后者需要携带完整信息,这样就可以以最快速度让所有的broker都有完整的元数据信息。* 「newBrokers」对象可能包含副本,我们需要将这些副本对象变更为「online」以对外提供服务。* 即Leader副本对外提供读写服务,follower副本自动向Leader副本拉取消息。** @param newBrokers*/private def onBrokerStartup(newBrokers: Seq[Int]): Unit = {info(s"New broker startup callback for ${newBrokers.mkString(",")}")// 首先从replicasOnOfflineDirs缓存中移除数据,因为broker现在处于「可用」状态了newBrokers.foreach(controllerContext.replicasOnOfflineDirs.remove)val newBrokersSet = newBrokers.toSet// #1 获取「已存在」的brokersval existingBrokers = controllerContext.liveOrShuttingDownBrokerIds.diff(newBrokersSet)// #2 向已存在的brokers发送「updatemetadata」更新元数据信息请求,以至于让这些broker知道有新成员加入// 由于没有分区状态的变更,所以不需要在请求中包含任何分区状态// 这一步目的是让「已存在」的broker感知到有新的broker加入sendUpdateMetadataRequest(existingBrokers.toSeq, Set.empty)// #3 向新增的brokers发送「updatemetadata」更新元数据信息请求,请求携带集群完整的分区状态信息// 令这些新增的brokers同步集群当前所有分区数据// 当可控关闭的情况下,当一个新的broker出现时,leader不会被选出。因此,至少在觉的可控关闭情况下,元数据可以最快到达新的broker节点sendUpdateMetadataRequest(newBrokers, controllerContext.partitionsWithLeaders)// the very first thing to do when a new broker comes up is send it the entire list of partitions that it is// supposed to host. Based on that the broker starts the high watermark threads for the input list of partitionsval allReplicasOnNewBrokers = controllerContext.replicasOnBrokers(newBrokersSet)// #4 将新增broker上的所有副本设置为「online」在线状态replicaStateMachine.handleStateChanges(allReplicasOnNewBrokers.toSeq, OnlineReplica)// when a new broker comes up, the controller needs to trigger leader election for all new and offline partitions// to see if these brokers can become leaders for some/all of those// #5 分区状态机变更分区状态partitionStateMachine.triggerOnlinePartitionStateChange()// check if reassignment of some partitions need to be restarted// #6 重启之前暂停副本迁移工作maybeResumeReassignments { (_, assignment) =>assignment.targetReplicas.exists(newBrokersSet.contains)}// check if topic deletion needs to be resumed. If at least one replica that belongs to the topic being deleted exists// on the newly restarted brokers, there is a chance that topic deletion can resumeval replicasForTopicsToBeDeleted = allReplicasOnNewBrokers.filter(p => topicDeletionManager.isTopicQueuedUpForDeletion(p.topic))// #7 重启之前暂停主题删除操作if (replicasForTopicsToBeDeleted.nonEmpty) {info(s"Some replicas ${replicasForTopicsToBeDeleted.mkString(",")} for topics scheduled for deletion " +s"${controllerContext.topicsToBeDeleted.mkString(",")} are on the newly restarted brokers " +s"${newBrokers.mkString(",")}. Signaling restart of topic deletion for these topics")topicDeletionManager.resumeDeletionForTopics(replicasForTopicsToBeDeleted.map(_.topic))}// #8 为新增Brokers注册「BrokerModificationsHandler」监听器,目的是监听「/brokers/ids/[broker id]」节点数据的变化registerBrokerModificationsHandler(newBrokers)}
处理离线 Broker 逻辑:
更新 ControllerContext 缓存。
- 将副本的状态变更为离线状态。
取消该节点的监听器
/*** 当一个broker关闭时,controller需要关注以下事情:* ① broker管理的副本对象 -- 置为「离线状态」* ② ZK监听器 -- 移除监听器* ③ 相关缓存 -- 移除相关缓存数据** @param deadBrokers 已终止运行的Broker ID列表*/private def onBrokerFailure(deadBrokers: Seq[Int]): Unit = {info(s"Broker failure callback for ${deadBrokers.mkString(",")}")// #1「更新Controller元数据」:将给定的Broker从「replicasOnOfflineDirs」缓存中移除deadBrokers.foreach(controllerContext.replicasOnOfflineDirs.remove)// #2 从「正在关闭中(shuttingDownBrokerIds)」移除deadBrokersval deadBrokersThatWereShuttingDown =deadBrokers.filter(id => controllerContext.shuttingDownBrokerIds.remove(id))if (deadBrokersThatWereShuttingDown.nonEmpty)info(s"Removed ${deadBrokersThatWereShuttingDown.mkString(",")} from list of shutting down brokers.")// #3 执行副本清理工作// #3-1 获取死亡brokers中所有的副本对象,由于副本所在的broker已被关闭,所以这些副本的状态需要变更为「离线」状态val allReplicasOnDeadBrokers = controllerContext.replicasOnBrokers(deadBrokers.toSet)// #3-2 变更副本的状态为「离线」onReplicasBecomeOffline(allReplicasOnDeadBrokers)// #4 注销死亡brokers注册的「BrokerModificationsHandler」监听器,// 这个监听器用来监听「/brokers/ids/[broker id]」节点数据变更的,比如broker重启就会触发此handler相关回调方法unregisterBrokerModificationsHandler(deadBrokers)}

若有收获,就点个赞吧
0 人点赞
