概述
Kafka-producer-pref-test 和 kafka-consumer-pref-test 是对生产者和消费者做性能测试,获取一组最佳的参数值。
压测目的
- 根据不同量级的消息处理结果,评估 Kafka 的处理性能是否满足项目需求。
- 可以看出哪个地方出现瓶颈,一般有 CPU、内存、网络、磁盘 IO。一般都是网络出现瓶颈。
在高并发下,网络 IO 或磁盘 IO 成为瓶颈,产生阻塞而导致。
压测前做的事情
使用
hdparm命令测试磁盘读写速度。读在170MB~200MB/S,写为150~170MB/S。- 调优 OS。
- 页缓存:尽量分配与所有日志的激活日志段大小相同的页缓存大小。
- 文件描述符限制:10万以上。修改
/etc/security/limits.conf文件。 - 禁用 swap。
- 使用 G1 垃圾回收器。
- 分配
6~8GB堆大小内存。
基本监控
压测单分区的吞吐量。
-
计算分区数
创建只有 1 个分区的 topic。
- 压测这个 topic 的 producer 吞吐量和 consumer 吞吐量。
- 取两者最小值,设为 Tm,而目标吞吐量为 Tt,则分区数量 = Tt / Tm。分区数量一般在
3~10个。 注意,当 partition 数量等于 broker 数量时,吞吐量达到最优,后续随着 partition 数量增加,基本稳定。
计算机器数
经验公式:2 * ((峰值生产速度 副本数)/100) + 1。
- 先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署的 Kafka 数量。
比如峰值速度为
40MB/S,生产环境为三副本,则机器数 = 403 / 100 + 1 =计算副本数
副本数量多,可以增强冗余,但是会因为副本同步占用大量带宽,导致网络拥塞。
我们先取一批旧的历史数据,统计每条消息平均大小。
- 然后在此基础上,增加一点就成为
record-size,我们当时统计的是1.5KB大小的数据,为了保险起见,设置为2KB。
机器:3 台 8 核 16GB 虚拟机,磁盘容量为 6TB 的虚拟机。
测试参数
| 参数 | 描述 |
|---|---|
| —topic | 指定生产者发送消息的主题 |
| —num-records | 测试时发送消息的总记录数 |
| —payload-delimiter | 配合 —payload-file 参数使用, |
| —throughput | 每秒发送的最大消息数,-1 表示不限制 |
| —producer-props | key1=value1 key2=value2 形式存在,配置相关属性,比如 bootstrap-server 参数就可以写在这里 |
| —print-metrics | 在测试结束后打印结果 |
| —transactional-id | 配合 transaction-duration-ms 参数使用。如果参数 > 0,则使用。这个参数用于测试并发事务有用 |
| —transaction-duration-ms | 事务持续时间。也就是指业务处理时间,当业务处理完成后,才会调用 commitTransaction 提交事务。 |
| —record-size | 消息大小 |
| —payload-file | 可读的数据文件 |
[root@localhost bin]# ./kafka-producer-perf-test.sh --throughput -1 --num-records 100000 --topic james --record-size 4096 --producer-props bootstrap.servers92.168.217.130:9092 acks=-129503 records sent, 5900.6 records/sec (23.05 MB/sec), 884.0 ms avg latency, 1771.0 ms max latency.30573 records sent, 6114.6 records/sec (23.89 MB/sec), 1000.7 ms avg latency, 1884.0 ms max latency.100000 records sent, 7371.369600 records/sec (28.79 MB/sec), 787.85 ms avg latency, 1884.00 ms max latency, 691 ms 50th, 1515 ms 95th, 1835 ms 99th, 1876 ms 99.9th.
./kafka-producer-perf-test.sh \--throughput -1 \--num-records 500 \--topic james \--record-size 4096 \--producer-props bootstrap.servers=192.168.217.128:9092
指定不限制吞吐量(-1),总共 500 记录,每条记录大小 4096 kb。
500 records sent, 857.632933 records/sec (3.35 MB/sec), 120.67 ms avg latency, 338.00 ms max latency, 111 ms 50th, 232 ms 95th, 253 ms 99th, 338 ms 99.9th.
| 500 records sent | 发送 500 条消息 |
|---|---|
| 857.632933 records/sec (3.35 MB/sec) | 每秒发送消息记录数 |
| 120.67 ms avg latency, | 平均延迟时间 |
| 338.00 ms max latency | 最大延迟时间 |
| 111 ms 50th, 232 ms 95th, 253 ms 99th, 338 ms 99.9th. | 统计延迟时间占比 |
如果加上 --print-metrics 可以获得更详细的结果:
Metric Name Valueapp-info:commit-id:{client-id=producer-1} : 448719dc99a19793app-info:start-time-ms:{client-id=producer-1} : 1624188349464app-info:version:{client-id=producer-1} : 2.7.0kafka-metrics-count:count:{client-id=producer-1} : 114.000producer-metrics:batch-size-avg:{client-id=producer-1} : 12351.419producer-metrics:batch-size-max:{client-id=producer-1} : 12376.000producer-metrics:batch-split-rate:{client-id=producer-1} : 0.000producer-metrics:batch-split-total:{client-id=producer-1} : 0.000producer-metrics:buffer-available-bytes:{client-id=producer-1} : 33554432.000producer-metrics:buffer-exhausted-rate:{client-id=producer-1} : 0.000producer-metrics:buffer-exhausted-total:{client-id=producer-1} : 0.000producer-metrics:buffer-total-bytes:{client-id=producer-1} : 33554432.000producer-metrics:bufferpool-wait-ratio:{client-id=producer-1} : 0.000producer-metrics:bufferpool-wait-time-total:{client-id=producer-1} : 0.000producer-metrics:compression-rate-avg:{client-id=producer-1} : 1.000producer-metrics:connection-close-rate:{client-id=producer-1} : 0.000producer-metrics:connection-close-total:{client-id=producer-1} : 0.000producer-metrics:connection-count:{client-id=producer-1} : 3.000producer-metrics:connection-creation-rate:{client-id=producer-1} : 0.098producer-metrics:connection-creation-total:{client-id=producer-1} : 3.000producer-metrics:failed-authentication-rate:{client-id=producer-1} : 0.000producer-metrics:failed-authentication-total:{client-id=producer-1} : 0.000producer-metrics:failed-reauthentication-rate:{client-id=producer-1} : 0.000producer-metrics:failed-reauthentication-total:{client-id=producer-1} : 0.000producer-metrics:incoming-byte-rate:{client-id=producer-1} : 349.179producer-metrics:incoming-byte-total:{client-id=producer-1} : 10592.000producer-metrics:io-ratio:{client-id=producer-1} : 0.001producer-metrics:io-time-ns-avg:{client-id=producer-1} : 265282.863producer-metrics:io-wait-ratio:{client-id=producer-1} : 0.002producer-metrics:io-wait-time-ns-avg:{client-id=producer-1} : 635654.692producer-metrics:io-waittime-total:{client-id=producer-1} : 74371599.000producer-metrics:iotime-total:{client-id=producer-1} : 31038095.000producer-metrics:metadata-age:{client-id=producer-1} : 0.281...
批次大小
| 序号 | batch.size | throughput |
|---|---|---|
| 1 | 5000 | 28420.39 |
| 2 | 10000 | 29985.01 |
| 3 | 20000 | 29983.21 |
| 4 | 40000 | |
| 5 | 60000 |
数量 100W,控制其它变量不变,得出以下结果:
- 批次大小到达一定值后,吞吐量会保持不变。这里是
10000。 - 吞吐量到达一定大小时,整个系统的吞吐量达到峰值,后面增大并发,系统吞吐量下降。
分区数
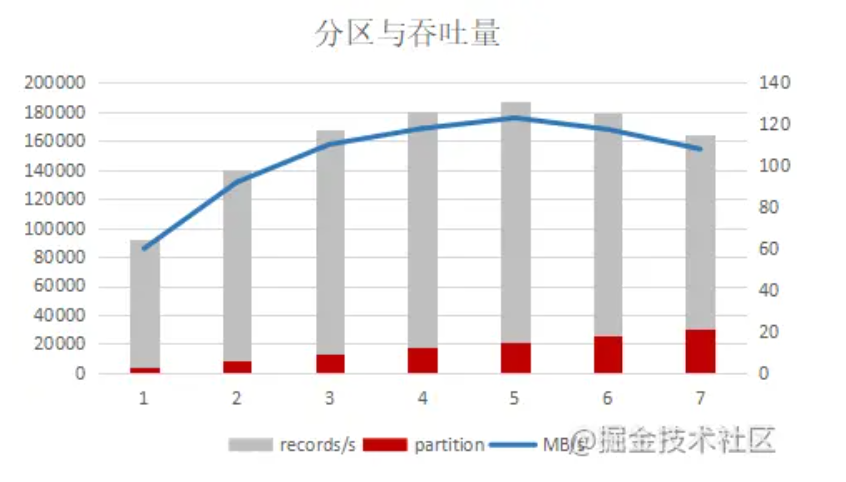
并不是分区数量越高越好,达到一定值时,吞吐量反而是下降的,一般不要超过机器数量。
生产者线程数并非越多越好,达到一定数量后,也会趋于稳定。性能瓶颈
可能会影响整体吞吐量的性能瓶颈。生产者端
| 性能瓶颈 | 说明 | | —- | —- | | thread | 测试时的单机线程数 | | batch-size | | | ack | | | message-size | | | compression-code | | | partition | | | replication | | | linger.ms | 两次发送 |
Broker 端
| 性能瓶颈 | 说明 |
|---|---|
| num.replica.fetchers | 副本抓取的相应参数,如果发生 ISR 频繁进出或 follower 无法追上 leader 的情况,应适当增加该值,默认值 1 |
| num.io.threads | Broker 处理磁盘 IO 的线程数,主要进行磁盘 IO 操作,高峰期可能出现 IO 等待。默认值:8 |
| num.network.threads | broker 处理消息的最大线程数,主要处理网络 IO,操作 SocketChannel 进行读写。默认值:3,建议调大。 |
压缩算法
推荐使用 lz4,其它的比如 snappy 和 gzip 效果一般。
Broker 端性能瓶颈
- default.replication.factor
- num.replica.fetchers
- auto.create.topics.enable
- min.insync.replicas
- unclean.leader.election.enable
- broker.rack
- log.flush.interval.messages
- log.flush.interval.ms
- unclean.leader.election.enable
- min.insync.replicas
- num.recovery.threads.per.data.dir
规划磁盘容量
- 新增消息数量
- 消息留存时间
- 平均消息大小
- 备份数
- 是否启用压缩
带宽
最大占用带宽资源:70%,超过这个阈值就可能出现丢包。
常规时间不能使用这么多资源,你必须再额外预留出2/3的资源,这是保守的做法,单台服务器使用带宽为700MB/3≈ 340Mbps,那么就可以根据带宽计算满足你目标计算值所需要的机器数量。
| 因素 | 考量点 | 建议 |
|---|---|---|
| 操作系统 | Linux 的 Epoll 模型优秀 | 建议部署在 Linux 上 |
| 磁盘 | 磁盘 IO 性能 | 普通环境使用机械硬盘,不需要搭建 RAID,分布式系统本来就提供高可用服务 |
| 磁盘容量 | 根据消息数、留存时间预估磁盘容量 | 实际使用中建议预留 20% ~ 30% 的磁盘空间 |
| 带宽 | 根据实际带宽资源和业务 SLA 预估服务器数量 | 对于千兆网络,建议每台服务器按 700Mbps 计算,避免大流量下的丢包 |

若有收获,就点个赞吧
0 人点赞
