概述
这篇文件延续上一篇的 【kafka】高效的日志存储模型(一)的讲解,这篇文件会从源码的角度为大家剖析 kafka 是如何对日志文件进行追加、读取、恢复、截断和清理等操作。以及 Kafka 如何使用零拷贝等手段提升数据传输效率。
Segment
保存Producer消息
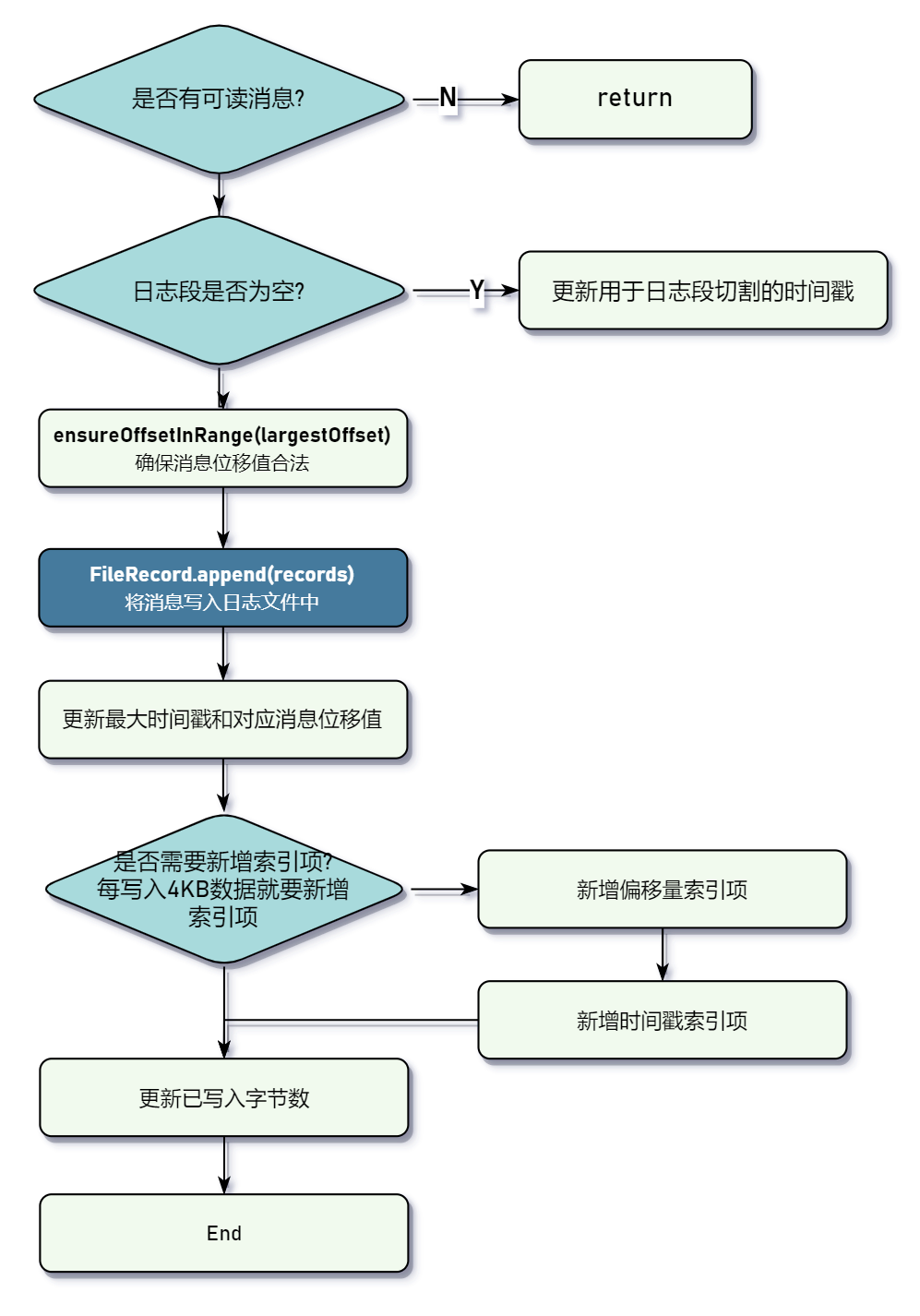
// kafka.log.LogSegment#append/*** 将生产者发送的消息追加到目标文件中** @param largestOffset 消息记录中最大位移值* @param largestTimestamp 消息记录中最大时间戳* @param shallowOffsetOfMaxTimestamp 最大时间戳所对应的位移值* @param records 待持久化的消息集合* @return 所追加的消息在文件中的物理位置* @throws LogSegmentOffsetOverflowException*/@nonthreadsafedef append(largestOffset: Long, largestTimestamp: Long, shallowOffsetOfMaxTimestamp: Long, records: MemoryRecords): Unit = {if (records.sizeInBytes > 0) {// #1 更新「rollingBasedTimestamp」,这个值后续用作日志段根据时间进行切割val physicalPosition = log.sizeInBytes()if (physicalPosition == 0) {// 仅当日志文件为空时才会更新rollingBasedTimestamp = Some(largestTimestamp)}// #2 确保输入参数最大位移值是合法的,标准是:该值与起始位移的差值是否在整数范围内ensureOffsetInRange(largestOffset)// #3 追加消息:将内存中的数据写入操作系统的页缓存中log.append(records)// #4 更新最大时间戳以及最大时间戳所对应的消息位移值。// 这个值会被用于定期删除日志时做条件判断:比如保留7天日志,那就交最大时间戳-7天的时间戳=截止时间。if (largestTimestamp > maxTimestampSoFar) {maxTimestampSoFar = largestTimestampoffsetOfMaxTimestampSoFar = shallowOffsetOfMaxTimestamp}// #5 更新索引项和写入字节数。日志段每写入4KB就要更新索引项。if (bytesSinceLastIndexEntry > indexIntervalBytes) {// #5-1 更新offsetindex索引offsetIndex.append(largestOffset, physicalPosition)// #5-2 更新时间戳索引(如有必要)timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)bytesSinceLastIndexEntry = 0}// 更新已写入字节数bytesSinceLastIndexEntry += records.sizeInBytes}}
生产的发送的二进制数据由 MemoryRecords 对象封装,内部使用 ByteBuffer 对象存储二进制数据。活跃的 LogSegment 对象将数据持久化到文件中,核心步骤是 #3,它将二进制数据写入到底层物理文件(实际上是写到操作系统的页缓存中(page cache),内核会异步将页缓存中的数据刷入磁盘)。FileRecord#append() 源码解析如下:
// org.apache.kafka.common.record.FileRecords#append/*** 向日志文件添加消息集合** @param records 待追加的消息集合* @return 成功写入底层日志文件的字节数*/public int append(MemoryRecords records) throws IOException {if (records.sizeInBytes() > Integer.MAX_VALUE - size.get())throw new IllegalArgumentException("Append of size " + records.sizeInBytes() + " bytes is too large for segment with current file position at " + size.get());// 将二进制数据写入FileChannel通道中int written = records.writeFullyTo(channel);size.getAndAdd(written);return written;}
MemoryRecords#writeFullyTo
// org.apache.kafka.common.record.MemoryRecords#writeFullyTopublic int writeFullyTo(GatheringByteChannel channel) throws IOException {buffer.mark();int written = 0;while (written < sizeInBytes())written += channel.write(buffer);buffer.reset();return written;}
除了将消息集合写入日志文件外,还根据索引间隔添加相关索引项,包括偏移量索引项和时间戳索引项。
从日志段中读取消息
这个操作可能来自:
- 消费者 FETCH 请求。
- Follower FETCH 请求。
// kafka.log.LogSegment#read/*** 从日志段中读取消息集(包含多条消息),消息位移offset>=startOffset。* 消息集总字节数不得超过 {@param maxSize},如果指定 {@param maxPosition} 则意味着消息位移最大值不得超过该值。** @param startOffset 将要读取的第一条消息的绝对逻辑偏移量* @param maxSize 读取的最大字节数* @param maxPosition 所能读取到的最大消息的物理偏移量* @param minOneMessage 是否允许第一条消息超出「maxSize」时返回,目的是防止消费饥饿情况出现。* 如果不跳过这一条超出「maxSize」的消息的话,后面的消息就永远不会被读取到* @return 获取的数据和相关偏移量元数据或者null*/@threadsafedef read(startOffset: Long, maxSize: Int, maxPosition: Long = size, minOneMessage: Boolean = false): FetchDataInfo = {if (maxSize < 0)throw new IllegalArgumentException(s"Invalid max size $maxSize for log read from segment $log")// #1 查找索引文件以确定待读取物理文件位置(缓存友好型的二分查找法)val startOffsetAndSize = translateOffset(startOffset)// #2 没有找到,返回nullif (startOffsetAndSize == null)return null// #3 使用「LogOffsetMetadata」包装本次读取的位移元数据val startPosition = startOffsetAndSize.positionval offsetMetadata = LogOffsetMetadata(startOffset, this.baseOffset, startPosition)val adjustedMaxSize = if (minOneMessage) math.max(maxSize, startOffsetAndSize.size) else maxSizeif (adjustedMaxSize == 0)return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)// #4 计算将要读取的总字节数// 比如 maxSize=100, maxPosition=300 startPositition=250 read = 50val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize)// #5 读取消息,使用FetchDataInfo封装消相关元数据// 调用FileRecord#slice()方法获取一个新的FileRecords对象,但共享底层二进制数据FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize), firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)}
FileRecords#slice
// org.apache.kafka.common.record.FileRecords#slice/*** 返回此[[FileRecords]]一个消息切片,即返回一个新的FileRecords对象,但这个对象共享底层二进制数据。* 相对于是给定的起始偏移量和读取的字节数的数据视图(view)。这个新的FileRecords限制了读取的数据范围,* 可以方便调用者读取数据。* 如果入参「size」超过文件的可读的字节数据,则以文件的可读字节数为准。** @param position 开始读操作的起始的物理偏移量* @param size 读取的字节数* @return 根据给定的起始和读取的字节数返回一个新的FileRecords对象*/public FileRecords slice(int position, int size) throws IOException {// 根据物理实际的可读字节数计算最后可读取的字节数int availableBytes = availableBytes(position, size);int startPosition = this.start + position;return new FileRecords(file, channel, startPosition, startPosition + availableBytes, true);}
日志段恢复
日志段恢复逻辑相对较复杂,主要完成的任务是:
- 清空全部索引文件。包括偏移量索引文件、时间戳索引文件和事务索引文件。
- 遍历日志段,得到消息批次,对每个消息批次进行校验。
- 在遍历批次过程中,添加偏移量索引项和时间戳索引项。
- 对于消息版本号magic >=2 的消息批次更新分区 Leader 版本号缓存。
- 更新事务Producer状态。
对于不合法的二进制数据将被截断。
// kafka.log.LogSegment#recover/*** 恢复日志段。* 1.清空索引文件* 2.重建索引文件* 3.挨个对消息批次进行校验,包括checksum、偏移量、时间戳。* 4.对日志文件进行截断操作,剔除无效的二进制数据。** @param producerStateManager 与日志段的起始偏移值(base offset)相对应的生产者状态。这是恢复事务索引所必需的* @param leaderEpochCache 可选项。缓存Leader版本号。* @return 恢复过程中不合法的字节数* @throws LogSegmentOffsetOverflowException*/@nonthreadsafedef recover(producerStateManager: ProducerStateManager, leaderEpochCache: Option[LeaderEpochFileCache] = None): Int = {// #1 清空索引文件,包括偏移量索引、时间戳索引、事务索引offsetIndex.reset()timeIndex.reset()txnIndex.reset()var validBytes = 0var lastIndexEntry = 0maxTimestampSoFar = RecordBatch.NO_TIMESTAMPtry {// #2 以批次为单位,对批次挨个进行校验for (batch <- log.batches.asScala) {// #2-1 校验「checksum」batch.ensureValid()// #2-2 校验批次的最后一条消息的偏移量// offset - baseOffset 需要在[0, Integer.MAX_VALUE]范围内才是合法值ensureOffsetInRange(batch.lastOffset)// #2-3 更新日志段目前为止遇到的时间戳的最大值,并且该时间戳所对应的消息批次最后一条消息的位移值// 以批次为单位if (batch.maxTimestamp > maxTimestampSoFar) {maxTimestampSoFar = batch.maxTimestampoffsetOfMaxTimestampSoFar = batch.lastOffset}// #2-4 重建索引,包括偏移量索引和时间戳索引if (validBytes - lastIndexEntry > indexIntervalBytes) {offsetIndex.append(batch.lastOffset, validBytes)timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)lastIndexEntry = validBytes}// #2-5 更新当前日志段的合法的消息字节数validBytes += batch.sizeInBytes()// 处理消息版本号magic>2,if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) {// #2-6 更新分区Leader版本号缓存leaderEpochCache.foreach { cache =>if (batch.partitionLeaderEpoch >= 0 && cache.latestEpoch.forall(batch.partitionLeaderEpoch > _))cache.assign(batch.partitionLeaderEpoch, batch.baseOffset)}// #2-7 更新事务Producer状态updateProducerState(producerStateManager, batch)}}} catch {case e@(_: CorruptRecordException | _: InvalidRecordException) =>warn("Found invalid messages in log segment %s at byte offset %d: %s. %s".format(log.file.getAbsolutePath, validBytes, e.getMessage, e.getCause))}// #3 得到非法的字节数,这些数据会被删除val truncated = log.sizeInBytes - validBytesif (truncated > 0)debug(s"Truncated $truncated invalid bytes at the end of segment ${log.file.getAbsoluteFile} during recovery")// #4 截断日志段文件,只保留合法的消息批次// 虽然可能会丢失消息,但是集群处于可用状态还是最迫切的log.truncateTo(validBytes)// #5 裁剪偏移量索引文件offsetIndex.trimToValidSize()// #6 添加时间戳最大值索引项timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar, skipFullCheck = true)// #7 裁剪时间戳索引文件timeIndex.trimToValidSize()// #8 返回本次恢复操作成功删除多少非法字节数truncated}
Log
一个 Log 对象管理一个分区下的所有日志段对象(LogSegment),关于 Log 对象我们重点关注:
Log 初始化逻辑。
管理分区重要的指针。包括 Log Start Offset、Log Stable Offset(LSO)、High Watermark 以及 Log End Offset。
/*** 一个Log对象管理一个分区内的所有日志段,单个日志段由[[LogSegment]]表示* 每个Log对象包含多个[[LogSegment]]对象。** @param _dir 日志段被创建的文件夹。即主题分区路径。* @param config 与日志相关的配置项,比如日志段大小、索引文件大小等等* @param logStartOffset 可以暴露给客户端最小的偏移量。下面这些操作会更新这个值:* 1.来自用户的DeleteRecordsRequest请求。* 2.Broker端日志保留策略* 3.Broker端日志截断操作* 下面这些操作会用到「logStartOffset」变量:* 1.日志删除。偏移量小于当前日志段的「logStartOffset」的消息可以被删除。如果是在活跃(active)日志段中* 删除消息,则会触发日志滚动(log rolling)。* 2.响应「ListOffsetRequest」。为避免出现「OffsetOutOfRange」异常,* 我们需要确保「logStartOffset <= log's highWatermark」* 3.其他活动(如日志清理)不受 logStartOffset 的影响。* @param recoveryPoint 开始恢复的偏移量——即尚未刷新到磁盘的第一个偏移量* @param scheduler 一个用于后台操作的调度器,比如定时清理日志就会用到这个对象* @param brokerTopicStats Broker上的主题状态* @param time 时间工具类* @param maxProducerIdExpirationMs 生产者过期时间* @param producerIdExpirationCheckIntervalMs 检查生产者过期操作时间间隔* @param hadCleanShutdown 指示上次是否干净/优雅关闭日志文件。false意味着崩溃关闭。* @param keepPartitionMetadataFile 指示partition.metadata文件是否应该保存在日志目录中。当内部版本>=Kafka2.8时才会创建* partition.metadata文件。这个文件会持久化主题ID。如果<2.8的话,当Broker重新升级会生成* 一个新的主题ID。*/@threadsafeclass Log(@volatile private var _dir: File,@volatile var config: LogConfig,@volatile var logStartOffset: Long,@volatile var recoveryPoint: Long,scheduler: Scheduler,brokerTopicStats: BrokerTopicStats,val time: Time,val maxProducerIdExpirationMs: Int,val producerIdExpirationCheckIntervalMs: Int,val topicPartition: TopicPartition,val producerStateManager: ProducerStateManager,logDirFailureChannel: LogDirFailureChannel,private val hadCleanShutdown: Boolean = true,val keepPartitionMetadataFile: Boolean = true) extends Logging with KafkaMetricsGroup {import kafka.log.Log._this.logIdent = s"[Log partition=$topicPartition, dir=${dir.getParent}] "// 全局锁,对log对象的修改都需要先获取这个锁对象private val lock = new Object/*** Kafka使用[[MappedByteBuffer]]内存映射缓冲区对索引文件进行mmap操作,加速对数据的读取。* 但这个ByteBuffer可以会被[[delete()]]或[[closeHandlers()]]两个方法关闭。* 当内存映射缓冲区关闭后,不应该对该日志进行磁盘IO操作*/@volatile private var isMemoryMappedBufferClosed = false// Cache value of parent directory to avoid allocations in hot paths like ReplicaManager.checkpointHighWatermarks@volatile private var _parentDir: String = dir.getParent// 最新一次刷盘时间private val lastFlushedTime = new AtomicLong(time.milliseconds)// 下一条待写入的消息偏移量,即Log End Offset(LEO)值@volatile private var nextOffsetMetadata: LogOffsetMetadata = _/*** 异步处理日志目录失效情况。我们需要防止状态不一致。*/@volatile private var logDirOffline = false/*** 不完整事务(incomplete transaction)的最早的偏移量。* 这个值被 [[kafka.server.ReplicaManager]] 用于计算last stable offset(LSO)。* 注意:第一个unstable offset可能会被删除(因为记录或段被删除),在这种情况下,首个unstable offset* 将会指向log start offset,这一部分的消息可能已经包含已完成的事务或不是事务的一部分。* 然而,由于我们只使用 LSO 来限制 read_committed 消费者获取决定的数据(即提交、中止或非事务),* 这种临时处理方式似乎是合理的(justifiable),并且可以避免我们在删除后扫描日志以找到第一个每个正在进行的事务的偏移量,以便计算新的第一个不稳定偏移量。* 但是,这可能会导致副本之间出现分歧(disagreement),具体取决于它们何时开始复制日志。* 在最坏的情况下,消费者可能会看到 LSO 倒退。*/@volatile private var firstUnstableOffsetMetadata: Option[LogOffsetMetadata] = None/*** 该分区的高水位(High Watermarker)元数据* [[Log]] 对象跟踪当前分区的HW,确保偏移量offset>=HW的消息是不会被删除的。* 只有当 HW=log end offset 时该日志段可以被完全清空(对于一个处于稳定负载下的分区,这可能永远不会发生)。*/@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)/*** 使用跳表存在日志段对象,<该日志段的基础偏移量, 日志段对象>* 使用跳表原因是可以快速找到小于目标偏移量的最大的基础偏移值,意味着目标消息就是在这个日志段对象中*/private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]// 缓存分区Leader版本号@volatile var leaderEpochCache: Option[LeaderEpochFileCache] = None//@volatile var partitionMetadataFile: PartitionMetadataFile = null@volatile var topicId: Uuid = Uuid.ZERO_UUID// others}
Log 对象定义了非常多的属性,其中最重要的需要记住两个就够了:dir 和 logStartOffset。
- dir:该 Log 对象管理的分区目录。
- logStartOffset:表示日志的当前最早偏移量。也是消费者可见的最小偏移量。关于日志段重要的数据指针接下来会继续讲解。
Log 内部也有重要的变量,比如 nextOffsetMetadata 可以理解为该分区的 Log End Offset(LEO),它表示下一条待写入消息的偏移量。highWatermarkMetadata 是该分区的 High Watermark(HW),意味着消费者可以看到的最大偏移量。
当然,怎么能放过最最最重要的 segments 变量呢,Segment 是每个日志段的化身,这个对象持有 .log、.index 相关文件的引用,数据的写入操作都是委托 Segment 来完成,最终它会将数据持久到物理文件中。
变量 segments 使用 Java 提供的 ConcurrentNavigableMap 跳跃表实现的,提供搜索视图的功能,可以快速找到小于目标偏移量的最大起始偏移值。比如存在 3 个日志段,起始偏移量分别是 0 15 30,我们此时寻找偏移量 16 位于哪个日志段,可以通过 ConcurrentNavigableMap#floorEntry(16) 返回起始偏移量为 15 的日志段。
Log 对象初始化
掌握了 Log 对象的相关变量,我们了解 Log 对象的初始化逻辑:
/*** Log类的初始化逻辑,*/locally {// #1 创建分区日志文件夹(如果没有存在的话)Files.createDirectories(dir.toPath)// #2 初始化分区Leader版本号缓存initializeLeaderEpochCache()// #3 初始化分区元数据(partition.metadata)initializePartitionMetadata()// #4 加载所有日志段,得到日志段对象集合列表val nextOffset = loadSegments()// #5 根据日志段计算Log End Offset值nextOffsetMetadata = LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)// #6 根据分区Leader版本号进行截断操作(如有必要的话)leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))// #7 更新Log Start OffsetupdateLogStartOffset(math.max(logStartOffset, segments.firstEntry.getValue.baseOffset))// #8 在硬故障(hard failure)期间可能不会刷新最早的leader版本号,因此在这里进行恢复操作leaderEpochCache.foreach(_.truncateFromStart(logStartOffset))// #9 任何日志段加载或恢复操作都不能使用 producerStateManager,以便我们可以从头开始构建完整状态。if (!producerStateManager.isEmpty)throw new IllegalStateException("Producer state must be empty during log initialization")// Reload all snapshots into the ProducerStateManager cache, the intermediate ProducerStateManager used// during log recovery may have deleted some files without the Log.producerStateManager instance witnessing the// deletion.// #10 将所有的快照重新载入到ProducerStateManager缓存中,// 日志恢复过程中使用的中间ProducerStateManager可能已经删除了一些文件,而没有Log.producerStateManager实例见证删除producerStateManager.removeStraySnapshots(segments.values().asScala.map(_.baseOffset).toSeq)loadProducerState(logEndOffset, reloadFromCleanShutdown = hadCleanShutdown)// Delete partition metadata file if the version does not support topic IDs.// Recover topic ID if present and topic IDs are supported// #11 如果版本不支持主题ID,则删除分区元数据文件。如果存在并且支持主题ID,则恢复主题ID。if (partitionMetadataFile.exists()) {if (!keepPartitionMetadataFile)partitionMetadataFile.delete()elsetopicId = partitionMetadataFile.read().topicId}}
Kafka 重要的偏移量
Log Start Offset
Log Start Offset 表示消费者可以读取的最小偏移量。偏移量小于 Log Start Offset 的消息可以被删除。一般情况下,分区的 Log Start Offset 等于该分区第一个日志段的 baseOffset,但这并非是绝对成立的,因为 logStartOffset 值可以通过外部修改,包括:
- DeleteRecordsRequest 请求。
- kafka-delete-records.sh 脚本。
- 日志清理操作
- 日志截断操作
log start offset 是约束消费者可以消费的最小偏移量。上面的操作是更新相关的缓存,Kafka 还提供定时器每 60S 就会将每个分区的 Log Start Offset 持久化至 log-start-offset-checkpoint 文件中。
// kafka.log.LogManager#startupWithConfigOverridesscheduler.schedule("kafka-log-start-offset-checkpoint",checkpointLogStartOffsets _,delay = InitialTaskDelayMs,period = flushStartOffsetCheckpointMs,TimeUnit.MILLISECONDS)// kafka.log.LogManager#checkpointLogStartOffsetsInDir// 定时任务:和第一个日志段的起始偏移量比较,如果大于则更新private def checkpointLogStartOffsetsInDir(logDir: File, logsToCheckpoint: Map[TopicPartition, Log]): Unit = {try {logStartOffsetCheckpoints.get(logDir).foreach { checkpoint =>val logStartOffsets = logsToCheckpoint.collect {// 如果大于第一个日志段的起始偏移量,则更新case (tp, log) if log.logStartOffset > log.logSegments.head.baseOffset => tp -> log.logStartOffset}checkpoint.write(logStartOffsets)}} catch {case e: KafkaStorageException =>error(s"Disk error while writing log start offsets checkpoint in directory $logDir: ${e.getMessage}")}}
High Watermark
虽然读写操作都只经过 Leader 副本,但是消费者所能读取的最大偏移量是由位于 ISR(in-sync Replication) 副本参与控制。Kafka 定义了 High Watermark, HW(高水位)概念,它是一个特定的消息偏移量(offset),表示消费者只能读取到这个 offset 之前的消息。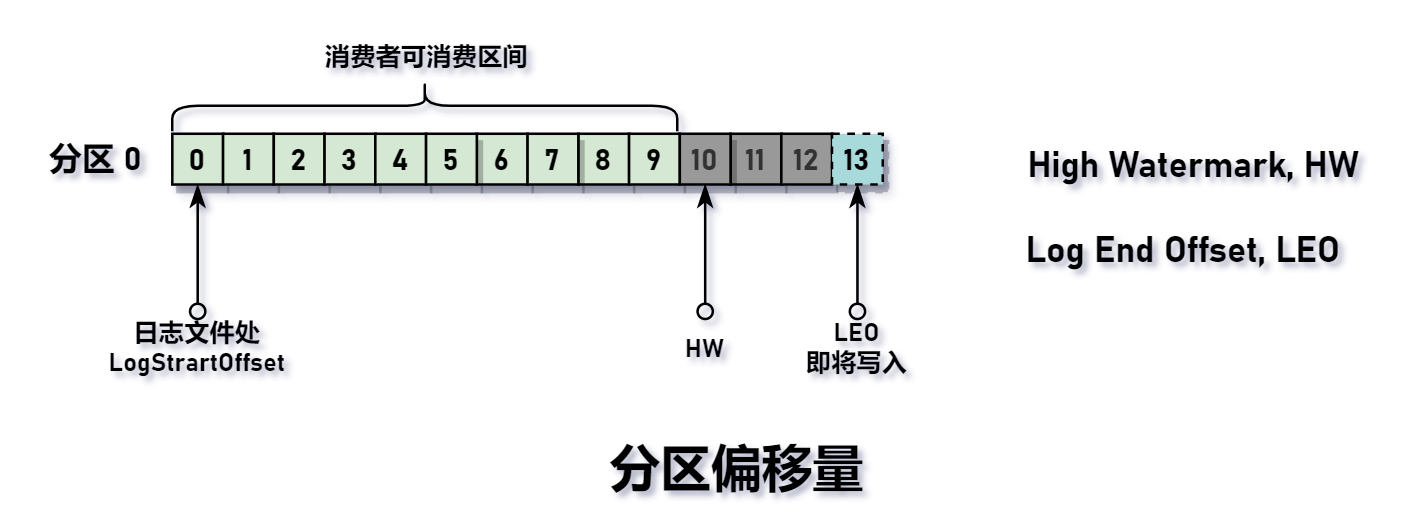
简单总结:
- 只有当 Leader 的消息完全成功同步到其他副本时,该消息才可被消费者消费。
- HW 高水位线是由 ISR 副本向前推动。
Log End Offset
标识当前日志文件中下一条待写入消息的 offset(相当于日志分区中最后一条消息的 offset 值 + 1)。分区 ISR 集合中的每个副本都会维护自身的 LEO,而 ISR 集合中最小的 LEO 即为分区的 HW,消费者只能消费 HW 之前的消息。

若有收获,就点个赞吧
0 人点赞
