概述
本章节是对分区状态机的学习。分区状态机也是 Controller 特有的组件,负责管理 Kafka 分区状态的转换。和状态机设计理念高度相似,只不过分区状态数量只有 4 个,但是不代表分区状态机逻辑简单。
组件

副本状态
| 分区状态 | 说明 |
|---|---|
| NewPartition | 分区被创建后被设置成这个状态,意味着它是一个全新的分区。 处于这种状态的分区不能选举 Leader副本。 |
| OnlinePartition | 分区正式提供服务时所处的状态 |
| OfflinePartition | 分区下线后所处的状态 |
| NonExistentPartition | 分区被删除,并且从分区状态机移除后所处的状态 |
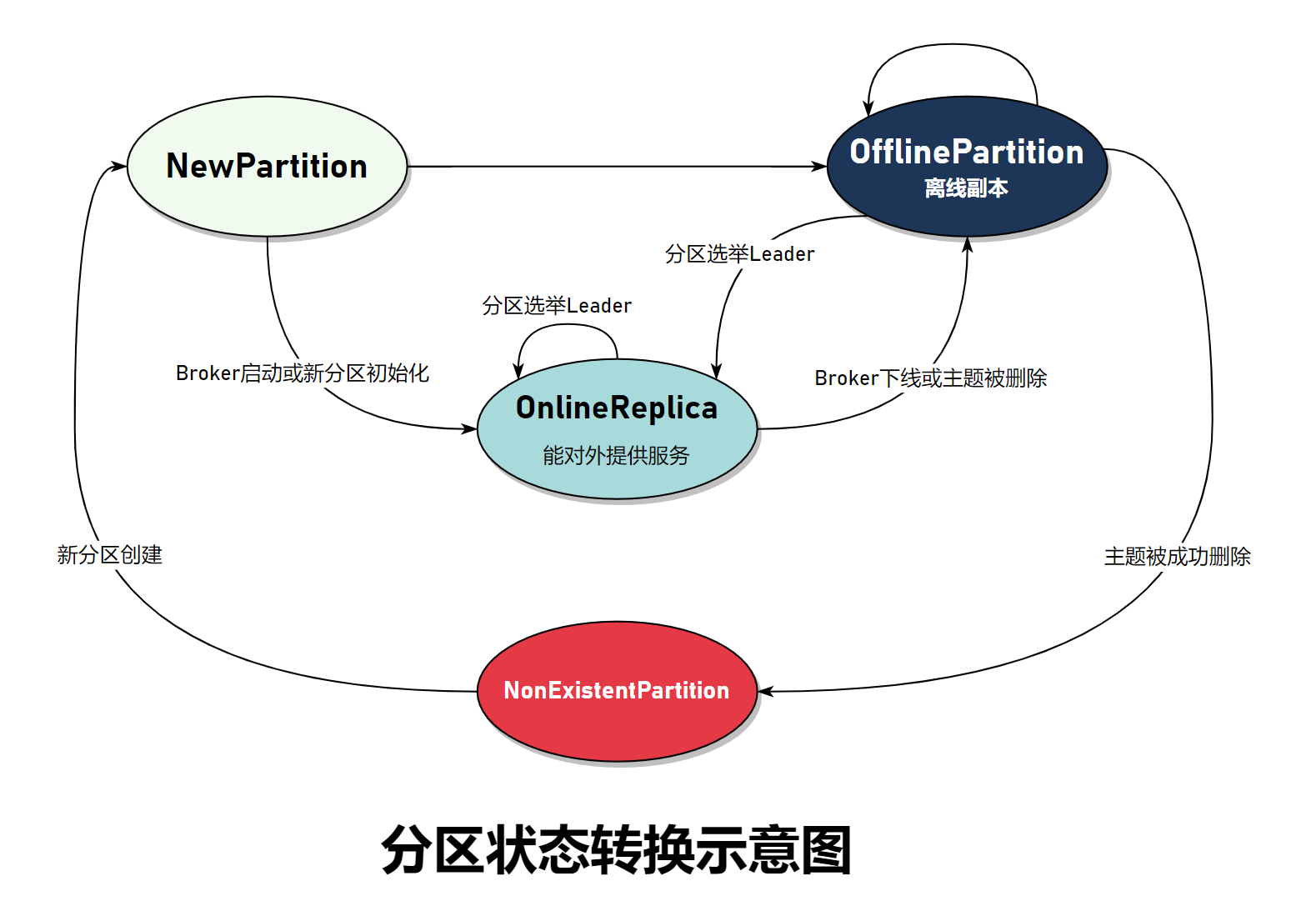
分区状态转换操作
NonExistentPartition => NewPartition
将分区状态变更为
NewPartition// #3 状态变更targetState match {// #3-1 目标状态为NewPartitioncase NewPartition =>validPartitions.foreach { partition =>stateChangeLog.info(s"Changed partition $partition state from ${partitionState(partition)} to $targetState with " +s"assigned replicas ${controllerContext.partitionReplicaAssignment(partition).mkString(",")}")controllerContext.putPartitionState(partition, NewPartition)}Map.empty
NewPartition => OnlinePartition
确认该分区的 Leader 副本和 AR 以及 ISR 集合等元数据信息。并写入 Zookeeper 节点。存活的第一个副本就是 Leader 副本,ISR 集合为存活的副本列表。
- 将分区状态变更为
OnlinePartition。 - 向所有可用的副本所在的 Broker 发送 LeaderAndIsrReqeust,指导这些 Borker 进行 Leader/Follower 的角色切换。
向集群广播 UpdateMetadataRequest 请求更新相关元数据。
// #3-2 分区上线case OnlinePartition =>// ① 获取「NewPartition」状态下的所有分区val uninitializedPartitions = validPartitions.filter(partition => partitionState(partition) == NewPartition)// ② 获取可进行 Leader选举 的分区列表(当前状态为 OfflinePartition 或 OnlinePartition 才能进行分区Leader选举)val partitionsToElectLeader = validPartitions.filter(partition => partitionState(partition) == OfflinePartition || partitionState(partition) == OnlinePartition)// ③ 初始化「NewPartition」状态分区,在Zookeeper中写入Leader和ISR数据if (uninitializedPartitions.nonEmpty) {// 初始化Zookeeper节点/brokers/topics/<topic>/partitions/<partition>数据val successfulInitializations = initializeLeaderAndIsrForPartitions(uninitializedPartitions)successfulInitializations.foreach { partition =>stateChangeLog.info(s"Changed partition $partition from ${partitionState(partition)} to $targetState with state " +s"${controllerContext.partitionLeadershipInfo(partition).get.leaderAndIsr}")// NewPartition->OnlinePartitioncontrollerContext.putPartitionState(partition, OnlinePartition)}}// ...}
OnlinePartitio/OfflinePartition => OnlinePartition
根据分区选举策略对分区进行 Leader 选举,确认 Leader 和 ISR 集合,并将结果写入 Zookeeper 结点。
- 将分区状态变更为
OnlinePartition。 - 向所有可用的副本所在的 Broker 发送 LeaderAndIsrReqeust,指导这些 Borker 进行 Leader/Follower 的角色切换。
向集群广播 UpdateMetadataRequest 请求更新相关元数据。
// ④ 使用Leader副本选举策略给具备Leader选举资格的分区选举Leader副本if (partitionsToElectLeader.nonEmpty) {// 不断尝试为多个分区选举Leader,直到所有分区都成功选出Leaderval electionResults = electLeaderForPartitions(partitionsToElectLeader,partitionLeaderElectionStrategyOpt.getOrElse(throw new IllegalArgumentException("Election strategy is a required field when the target state is OnlinePartition")))// 遍历选举结果electionResults.foreach {case (partition, Right(leaderAndIsr)) =>stateChangeLog.info(s"Changed partition $partition from ${partitionState(partition)} to $targetState with state $leaderAndIsr")// ⑤ 将成功选举Leader后的分区设置成OnlinePartition状态controllerContext.putPartitionState(partition, OnlinePartition)case (_, Left(_)) => // Ignore; no need to update partition state on election error}// ⑥ 返回Leader选举结果electionResults} else {Map.empty}
分区 Leader 选举
分区状态机除了维护各分区状态外,还有一个功能就是分区 Leader 选举。不同场景执行不同 Leader 选举策略,选举策略一共有 4 种:
| 选举策略 | 说明 |
|---|---|
| OfflinePartitionLeaderElectionStrategy | Leader 副本离线引发分区Leader选举 |
| ReassignPartitionLeaderElectionsStrategy | 执行分区副本重分配操作而引发分区Leader选举 |
| PreferredReplicaPartitionLeaderElectionStrategy | 执行 Preferred 副本 Leader 选举 |
| ControlledShutdownPartitionLeaderElectionStrategy | 正常关闭Broker而引发分区Leader选举 |
对象 PartitionLeaderElectionAlgorithms 分别实现了这 4 种选举策略:
/*** 针对4种触发的Leader选举的场景,这个对象分别定义了4个方法,负责为每种场景选举Leader副本*/object PartitionLeaderElectionAlgorithms {/*** 场景一:由于Leader副本下线而引发分区Leader选举* 选举策略:AR集合第一个满足存在①副本在线②在ISR集合中,它就是Leader副本** @param assignment 分区副本列表,即AR(Assigned Replicas,感觉也可以称为All Replicas)* 使用Seq表示AR是有序的,但顺序不一定和ISR相同,因为ISR可能会频繁进出* @param isr 同步副本集合。注意:Leader副本也在ISR集合中。* @param liveReplicas 该分区下所有存活的副本。* @param uncleanLeaderElectionEnabled 是否允许Unclean Leader副本参与Leader选举。这可能存在数据丢失的风险* @param controllerContext Controller上下文,里面保留集群所有元数据* @return*/def offlinePartitionLeaderElection(assignment: Seq[Int],isr: Seq[Int],liveReplicas: Set[Int],uncleanLeaderElectionEnabled: Boolean,controllerContext: ControllerContext): Option[Int] = {// #1 按顺序搜索AR列表,如果同时满足①副本所在的Broker仍在运行;②副本在ISR列表中 这两个条件,则表明找到Leader副本。// 否则判断是否开启Unclean Leader选举,如果开启,则从Unclean Leader副本中选出一个作为Leader副本以保证分区可用性assignment.find(id => liveReplicas.contains(id) && isr.contains(id)).orElse {// #2 ISR集合没有可用的副本对象,查看是否允许Unclean Leader选举(即unclean.leader.election.enable=true)if (uncleanLeaderElectionEnabled) {// #3 选举当前副本列表中第一个存活副本作为Leaderval leaderOpt = assignment.find(liveReplicas.contains)if (leaderOpt.isDefined)controllerContext.stats.uncleanLeaderElectionRate.mark()leaderOpt} else {// 如果不允许Unclean Leader选举,则返回None表示无法选举LeaderNone}}}/*** 场景二:由于执行分区重分配操作而引发的分区Leader选举** @param reassignment* @param isr* @param liveReplicas* @return*/def reassignPartitionLeaderElection(reassignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {reassignment.find(id => liveReplicas.contains(id) && isr.contains(id))}/*** 场景三:由于执行Preferred副本Leader选举而引发的分区Leader选举* 出现这个选举策略是因为解决Leader分配不均的问题。* 当所有集群正常并且同时重启时,副本Leader会均匀分布,但随着时间推移,避免不了某些Broker宕机,* 这样在其它Broker的follower成为Leader,即便后续后续原有的Leader重启成功,* 即便奋起直追,加入ISR列表,它的身份也只是Follower。久而久之,就会导致整个集群的流量不均匀,加大其它Broker宕机风险。* Kakfa提供kakfa-preferred-replica-election.sh脚本去均衡分区的Leader副本,实现思路是:* 1.引入preferred-replica概念,它是指ISR列表中第一个replicaid就是preferred-replica。* 最初的Leader肯定是排在ISR列表的首位,但是Broker宕机后变成follower,但是ISR中的preferred-replica不会改变,* 执行kakfa-preferred-replica-election.sh脚本就是让preferred-replica重新成为分区Leader副本。* 这是手动触发的,也可以配置「auto.leader.rebalance.enable=true」让Kafka满足一定条件时自动触发(Kafka监控集群不均衡度达到某个阈值时自动触发preferred-replica选举操作)。** @param assignment* @param isr* @param liveReplicas* @return*/def preferredReplicaPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {// 判断第一个副本是否存活assignment.headOption.filter(id => liveReplicas.contains(id) && isr.contains(id))}/*** 场景四:因为正常关闭Broker而引发分区Leader选举** @param assignment* @param isr* @param liveReplicas* @param shuttingDownBrokers* @return*/def controlledShutdownPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], shuttingDownBrokers: Set[Int]): Option[Int] = {assignment.find(id => liveReplicas.contains(id) && isr.contains(id) && !shuttingDownBrokers.contains(id))}}
Leader副本离线
当副本离线时,根据 AR 的顺序在 ISR 中第一个出现的就作为 Leader 副本。如果ISR集合为空,则会判断是否支持 un-clean Leader 选举,如果支持的话,就选举当前AR中第一个存活的副本作为 Leader 副本。这是集群为了高可用的一种妥协,因为这会导致数据丢失。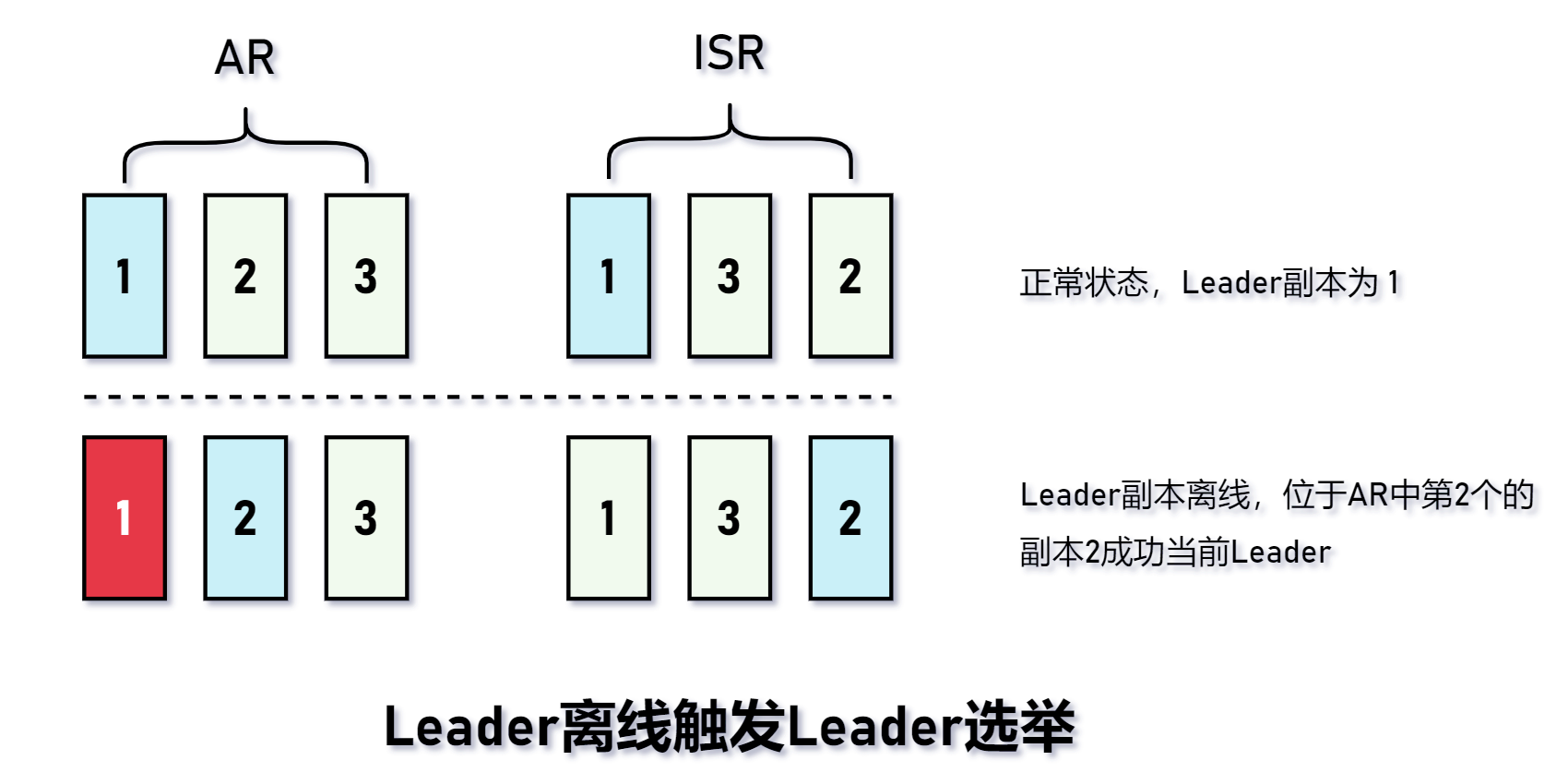
分区重分配
我们可以通过 kafka-reassign-partitions.sh 脚本对某些主题进行分区重分配,这也会导致分区进行内部的分区 Leader 选举。
和上面一样,根据 AR 的顺序在 ISR 中第一个出现的就作为 Leader 副本。但不支持 un-clean 作为 Leader 副本。
优先副本
出现这个选举策略是为了解决 Leader 分配不均的问题。当所有同时启动,副本 Leader 会均匀分布集群的 Broker 上。但随着时间推移,避免不了某些 Broker 出现意外而宕机,这样位于其它 Broker 的 follower 成为 Leader,即便后续旧 Leader 重启成功,哪怕奋起直追,加入 ISR,它的身份也只是 Follower。久而久之,就会导致整个集群的流量集中于某几台 Broker 节点,流量分配不均匀,而且还会加大其它 Broker 宕机风险。Kakfa 提供kakfa-preferred-replica-election.sh 脚本去均衡分区 Leader。
实现思路是:引入 preferred-replica 概念,它是指 AR 列表中第一个 replicaid 就是 preferred-replica。最初的 Leader 肯定是排在 AR 列表的首位,但是 Broker 宕机后变成 follower,虽然 ISR 顺序会变,数据也会变,但是 AR 集合顺序不会变,数量也不会变。执行 kakfa-preferred-replica-election.sh 脚本就是让 preferred-replica 重新成为分区Leader副本。前提条件是 preferred-replica 也要存在 ISR 集合中。
Controller关闭
Controller 关闭也会导致分区 Leader 选举,和上面一样,根据 AR 的顺序在 ISR 中第一个出现的就作为 Leader 副本。但不支持 un-clean 作为 Leader 副本。并且该 Broker 不存在正在关闭的 Broker 列表中。
总结
分区状态机只有 Controller 才会拥有,用来管理整个集群的分区状态。其中还包括非常重要的分区 Leader 选举功能。

若有收获,就点个赞吧
0 人点赞
