概述
在前面讲解 Kafka Client 网络模型时了解了 Kafka 是如何基于 Java NIO 实现了自己的一套异步非阻塞的网络框架。本章节,我们探讨 Kafka Broker 端的网络模型,它是底层基于 Java NIO 开发的一套主从 Reactor 网络框架。
当 Broker 处理速度很慢,需要优化时,只有通过阅读源码明确知道哪些会出现性能瓶颈,才能给出合适的解决之道。
Broker完整的网络通信层模型图
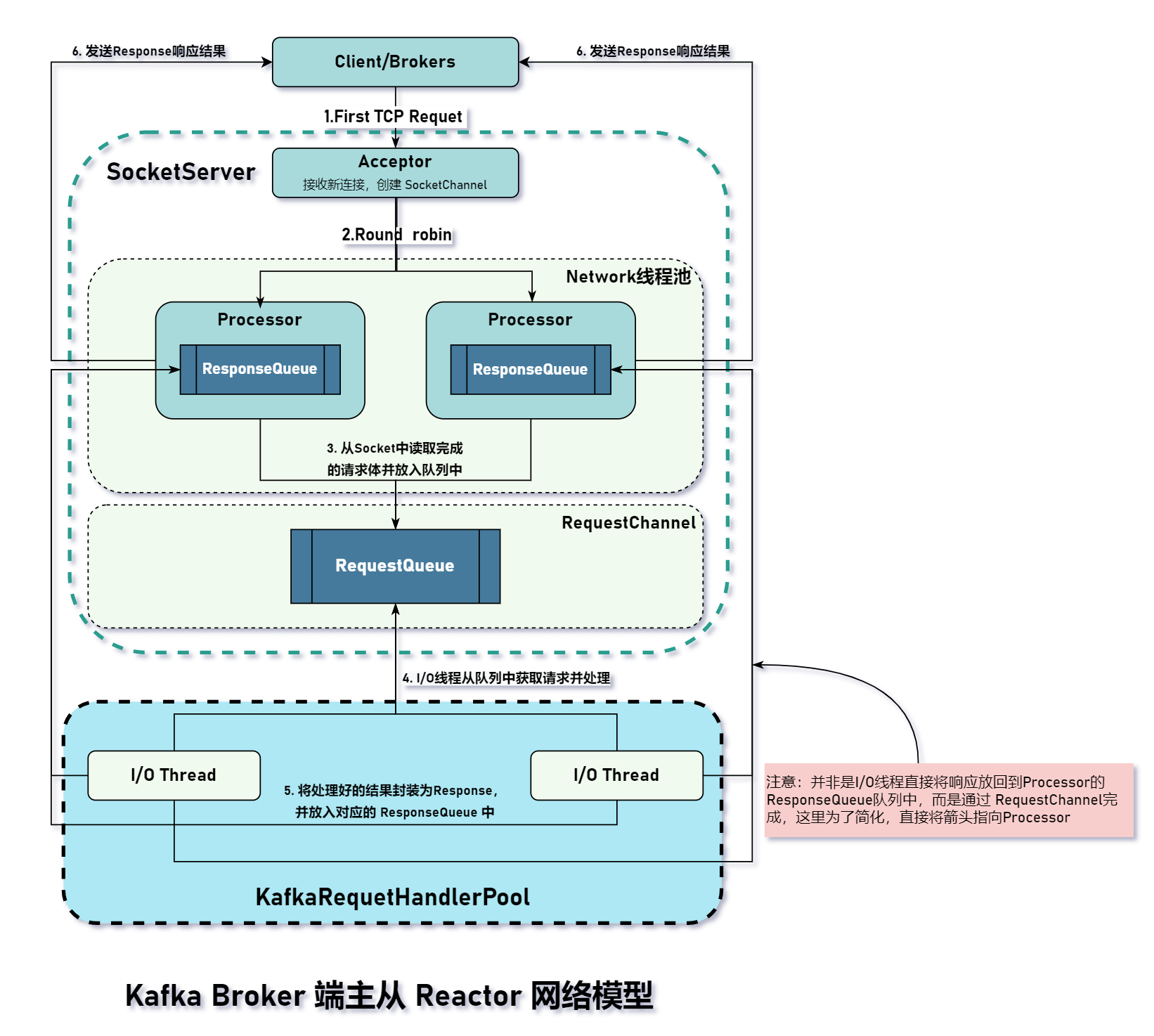
从上图可以看出,构成 Broker 端网络模型主要有两个核心组件:
- SocketServer:实现了 Reactor 模式,用于处理 Client(除了 Consumer/Producer,还应该包含其它的 Brokers)的请求,并将处理结果封装到 Response 中,返回给 Client 端。SocketServer 也是由两个核心组件和一个共享队列组成,两个核心组件构成主从 Reactor 模型,共享队列存放已接收的请求对象,这些请求对象将由 KafkaRequestHandlerPool 组件处理。
- KafkaRequestHandlerPool:即我们常说的 I/O 处理线程池,拥有若干线程不断从请求缓冲队列
RequeceQueue中获取请求并处理。
SocketServer
先看看 SocketServer 定义的重要的变量:
// kafka.network.SocketServer// 阻塞队列所能容纳最大的请求长度,由Broker端参数「queued.max.request」指定,默认值:500private val maxQueuedRequests = config.queuedMaxRequests// 数据面/*** 保存全局所有的Processor处理线程*/private val dataPlaneProcessors = new ConcurrentHashMap[Int, Processor]()/*** 保留全局的接口器对象,key:Acceptor,value:对应的Processor处理线程*/private[network] val dataPlaneAcceptors = new ConcurrentHashMap[EndPoint, Acceptor]()/*** 数据类请求队列,所有EndPoint共享一个数据类请求队列:由Processor生产出Request请求类,然后放入此队列中* 等待I/O线程拉取并消费*/val dataPlaneRequestChannel =new RequestChannel(maxQueuedRequests, DataPlaneMetricPrefix, time, apiVersionManager.newRequestMetrics)// 控制面private var controlPlaneProcessorOpt: Option[Processor] = Noneprivate[network] var controlPlaneAcceptorOpt: Option[Acceptor] = None// 控制面队列大小固定为20val controlPlaneRequestChannelOpt: Option[RequestChannel] = config.controlPlaneListenerName.map(_ =>new RequestChannel(20, ControlPlaneMetricPrefix, time, apiVersionManager.newRequestMetrics))// 下个Processor ID,全局唯一private var nextProcessorId = 0val connectionQuotas = new ConnectionQuotas(config, time, metrics)
这里控制面和数据面是什么意思呢? 默认情况下,控制类消息和数据类消息使用同一个 TCP 连接,但是控制类消息优先级是高于数据类消息的,在旧的网络模型下由于数据类消息过大而导致控制类消息发送不及时,所以 kafka 将 TCP 连接拆分成两个平面(plane):分别是控制面和数据面,分别使用独立的 TCP 连接,互不干扰。又因为控制类消息较小,所以队列默认大小为 20,且只有一个处理线程。Kafka 默认是不启用控制面。
- dataPlaneAcceptors:单独的一个线程,属于 Main Reactor 组件。它只做一件事件:两端建立 TCP 连接,并生成 SocketChannel 对象,然后将该对象交给 dataPlaneProcessor 处理。
- dataPlaneProcessors:保存数据面的所有处理器 Processor,Processor 是一个线程,可以简单理解为和 SocketChannel 打交道(委托其它方法执行),完成对网络 IO 的读/写操作。
- dataPlaneReqeustChannel:一个缓冲队列,保存 dataPlaneProcessor 获取的完整的请求对象。
可见,SokcetServer 负责串联这些重要的组件,并控制组件的生命周期。
Acceptor 线程
// kafka.network.Acceptor/*** 主要用于接收新的TCP连接,** @param endPoint 这个就是配置文件定义的端点(比如PLAINTEXT://localhost:9092),* Acceptor需要使用端点创建ServerSocketChannel* @param sendBufferSize 默认值:102400* @param recvBufferSize 默认值:102400* @param nodeId Broker ID* @param connectionQuotas 限流* @param metricPrefix* @param time* @param logPrefix*/private[kafka] class Acceptor(val endPoint: EndPoint,val sendBufferSize: Int,val recvBufferSize: Int,nodeId: Int,connectionQuotas: ConnectionQuotas,metricPrefix: String,time: Time,logPrefix: String = "") extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup {this.logIdent = logPrefix// #1 获取JDK底层的Selector轮询器private val nioSelector = NSelector.open()// #2 为端点创建ServerSocketChannelval serverChannel = openServerSocket(endPoint.host, endPoint.port)// #3 Processor线程是在Acceptor线程管理和维护的private val processors = new ArrayBuffer[Processor]()// 判断Processor线程池是否已经启动private val processorsStarted = new AtomicBoolean// ...}
Acceptor 线程有以下几个比较重要的变量:
- endPoint:终端信息,即 kafka Broker 连接信息,比如
listeners=PLAINTEXT://192.168.59.1:9092。endPoint 包含配置文件中的主机名和端口号。 - sendBufferSize:设置
SO_SNDBUF,表示出站网络 I/O 的底层缓冲区大小。默认值是socket.send.buffer.bytes(100kb)。 - recvBufferSize:设置
SO_RCVBUF,表示入站网络 I/O 的底层缓冲区大小。默认值是socket.receive.buffer.bytes(100kb)。 - nioSelector:根据不同系统获取对应的轮询器 Selector。
- serverChannel:Acceptor 根据 endPoint 创建 ServerSocketChannel,等待客户端连接。
- processors:Processor 线程是由 Acceptor 线程管理和维护的,Processor 线程负责对 SocketChannel 进行网络 I/O 操作。
如果在生产环境中遇到 Client 和 Broker 的 RTT 时延很大,那么建议调大这两个参数。如果增大还不能解决,那也可能是 Processor 线程数太少,Kafka 支持不停机增加 Processor 线程数量。
Acceptor 定义对 Processor 线程的增加、删除、启动、停止等方法,这里就不列出来了。重点看看 Acceptor 处理逻辑,核心方法在 #run():
// kafka.network.Acceptor#run/*** Acceptor 核心逻辑,不断轮询,建立新的[[SocketChannel]]对象*/def run(): Unit = {// #1 将ServerSocketChannel注册到轮询器SelectorserverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)// #2 表示Acceptor启动完成,意味着其它线程等待Accepotr完全启动的线程可以被唤醒startupComplete()try {// #3 不断轮询while (isRunning) {try {// #4 接收新的连接并以轮询算法分配给不同的processor处理器处理acceptNewConnections()// #5 关闭已被限流的连接closeThrottledConnections()}catch {// #6 捕获所有的异常以防止Accepotr退出case e: ControlThrowable => throw ecase e: Throwable => error("Error occurred", e)}}} finally {debug("Closing server socket, selector, and any throttled sockets.")CoreUtils.swallow(serverChannel.close(), this, Level.ERROR)CoreUtils.swallow(nioSelector.close(), this, Level.ERROR)throttledSockets.foreach(throttledSocket => closeSocket(throttledSocket.socket))throttledSockets.clear()shutdownComplete()}}
步骤 #4 是核心方法:
// kafka.network.Acceptor#acceptNewConnections/*** 接收新的连接并以轮询算法(round-robin)分配给processor* 1.每500毫秒轮询一次已就绪I/O事件* 2.ready>0,说明存在已就绪的I/O事件,* 3.通过ServerSocketChannel#accept()方法得到[[SocketChannel]]对象,设置相关配置项,比如非阻塞模式,SendBuffer、长连接模式等等* 4.通过「%processors.length」操作得到一个Processor对象,后续交由这个Processor完成对新建连的SocketChannel数据读取和发送操作。*/private def acceptNewConnections(): Unit = {// #1 每500毫秒获取一次就绪I/O事件val ready = nioSelector.select(500)if (ready > 0) {// #2 本轮有准备就绪的事件val keys = nioSelector.selectedKeys()val iter = keys.iterator()while (iter.hasNext && isRunning) {try {val key = iter.nextiter.remove()if (key.isAcceptable) {accept(key).foreach { socketChannel =>// #3 使用轮询将SocketChannel分配给Processorvar retriesLeft = synchronized(processors.length)var processor: Processor = nulldo {retriesLeft -= 1processor = synchronized {currentProcessorIndex = currentProcessorIndex % processors.lengthprocessors(currentProcessorIndex)}currentProcessorIndex += 1// 尝试将SocketChannel添加到Processor队列中,如果没有任何Processor可容纳,则线程会被阻塞} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))}} elsethrow new IllegalStateException("Unrecognized key state for acceptor thread.")} catch {case e: Throwable => error("Error while accepting connection", e)}}}}/*** 创建一个新的SocketChannel** @param key* @return*/private def accept(key: SelectionKey): Option[SocketChannel] = {val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]val socketChannel = serverSocketChannel.accept()try {connectionQuotas.inc(endPoint.listenerName, socketChannel.socket.getInetAddress, blockedPercentMeter)// 配置通道为非阻塞模式socketChannel.configureBlocking(false)socketChannel.socket().setTcpNoDelay(true)socketChannel.socket().setKeepAlive(true)if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)socketChannel.socket().setSendBufferSize(sendBufferSize)Some(socketChannel)} catch {case e: TooManyConnectionsException =>info(s"Rejected connection from ${e.ip}, address already has the configured maximum of ${e.count} connections.")close(endPoint.listenerName, socketChannel)Nonecase e: ConnectionThrottledException =>val ip = socketChannel.socket.getInetAddressdebug(s"Delaying closing of connection from $ip for ${e.throttleTimeMs} ms")val endThrottleTimeMs = e.startThrottleTimeMs + e.throttleTimeMsthrottledSockets += DelayedCloseSocket(socketChannel, endThrottleTimeMs)None}}
方法 acceptNewConnections() 是核心方法,具体逻辑已经在代码进行说明。选择合适的 Processor 是通过 %processors.length 确认的,其实就是轮询策略。当遇到某个 Processor 无法容纳新的 SocketChannel 连接,Kafka 会重试 processors.length 直到找到一个可以容纳的 Processor 为止。如果 Broker 网络负载满载情况下,重试次数降为 0,那么分配 Processor 就会被阻塞于某个 Processor,直接该 Processor 有可用的空间后被唤醒。
Processor线程
Processor 要做的有以下两件事情:
- 从管理的 SocketChannel 读取和发送数据。
- 执行已完成发送的 Response 的回调函数。
Processor 类有 3 个非常重要的变量,源码解析如下:
// kafka.network.Processor/*** 保存新创建的SocketChannel对象,这些对象等待Processor消费:* 将它们注册到自己的Selector轮询器中(调用 {@link configureNewConnections}方法完成)*/private val newConnections = new ArrayBlockingQueue[SocketChannel](connectionQueueSize)/*** 临时存放Response的队列,主要是为了执行Response的回调方法。正在发送,* 以便下次轮询可以判断是否发送完成,一旦发送完成就可以触发回调方法。*/private val inflightResponses = mutable.Map[String, RequestChannel.Response]()/*** 这个队列用于存放由 {@link kafka.server.KafkaRequestHandlerPool} I/O处理线程生成的Response,* 每个Processor都会有自己的并发队列存储Response。*/private val responseQueue = new LinkedBlockingDeque[RequestChannel.Response]()
核心逻辑是 #run() :
/*** Processor核心处理逻辑*/override def run(): Unit = {// #1 标记Processor线程启动完成startupComplete()try {// #2 不断轮询处理I/O的Requestwhile (isRunning) {try {// #3 将新的SocketChannel注册到SelectorconfigureNewConnections()// #4 消费「responseQueue」队列,从中获取Response并发送给"客户端(也可能是其它的Broker对象)"// 并且将Response放入「inflightResponses」队列中processNewResponses()// #5 执行I/O操作poll()// #6 处理已接收的RequestprocessCompletedReceives()// #7 处理已完成发送的Respnse(其实就是触发Response相关回调)processCompletedSends()// #8 每次轮询可能都会出现连接断开的情况,这些已断开的TCP需要快速释放资源processDisconnected()// #9 关闭超限连接,使用LRU算法移除TCP连接closeExcessConnections()} catch {// 捕获所有的异常以防止Processor线程意外退出。一般来讲,普通的异常上述方法都会捕获并处理。// 所以这个方法应该仅会捕获到ControlThrowables异常case e: Throwable => processException("Processor got uncaught exception.", e)}}} finally {debug(s"Closing selector - processor $id")// #10 Processor线程退出,释放资源:关闭Selector、关闭SocketChannel连接CoreUtils.swallow(closeAll(), this, Level.ERROR)// #11 标志Processor已完全关闭shutdownComplete()}}
- 前面说过,Acceptor 线程通过轮询确定一个 Processor,然后将该 SocketChannel 写入 Processor 内部的
newConnection阻塞队列中。步骤#3消费阻塞队列中的数据:将该 SocketChannel 注册到 Processor 自己的 Selector。Processor 就可以感知这个通道上的 I/O 事件了。 - 步骤
#4从responseQueue队列中获取待发送的 Response 响应,根据响应类型判断是否需要发送给 Client。如果需要发送响应,那么将对象封装为NetworkSend交给 Kafka Selector 处理(后面的处理逻辑在 Netty源码之知晓网络IO模型讲解过),此时还未真正触发 I/O 操作,只是将数据准备好。 - 步骤
#5才是真正触发 I/O 操作,将已就绪的数据通过 SocketChannel 发送给 Client。记住,异步 I/O 每一次发送可能会存在只发送部分数据,如果我们需要对实际发送成功的数据做判断。 - 步骤
#6也会收到来自 Client 的请求,将完整接收的请求对象放入requestChannel请求缓冲队列中。这个队列的消费者是下面要讲的KafkaReqeustHandler。 - 步骤
#7是主要是执行已完成发送的Response的回调函数。这也是变量inflightResponses存在的意义之一。
Processor 主干核心逻辑前面已经讲清楚了,其实还有限流操作,这里就不和大家细说。
KafkaRequestHandlerPool
KafkaRequestHandlerPool 是 Broker 专门用于处理 I/O 请求的线程池,线程池大小由 Broker 配置参数 num.io.threads 指定。
KafkaRequestHandlerPool 持有一个非常重量级的引用,那就是 ApiReqeustHandler,handler 从请求缓冲队列 reqeustChannel 获取请求 Reqeust,然后将请求交给 ApiReqeustHandler (这是一个接口,KafkaApis 是默认实现类)处理。KafkaApis 内部持有 RequestChannel 对象的引用,由 KafkaApis 调用 RequestChannel#sendResponse 方法将响应添加到该请求对应的 Processor,交给 Processor 将响应发送给 Client。
因为是异步编程,所以源码跟踪起来稍微有点复杂,不过底层逻辑还是比较清楚的。总的来说,KafkaRequetHandlerPool 逻辑十分简单,就是从 requetChannel 请求缓冲队列中获取 Reqeust,然后交给 KafkaApis 处理。它的逻辑十分简单,就不贴出源码了。
至于 KafkaApi ,它是整个 Broker API 路由中心,可以从这个类进行源码阅读的发散。
总结
总的来说,Kafka Broker 网络层源码并不复杂(当然也省略比如限流、身份校验等讲解),基于 Java NIO 和 主从 Reactor 设计思想构建了一套性能强劲的网络层。

若有收获,就点个赞吧
0 人点赞
