概述
分区重平衡是指在一个消费组中,分区的所属权从组内其中一个消费者转移到组内另一个消费者的过程,它为消费组具备高可用和伸缩性提供保障。
消费者组和分区关系如下图所示: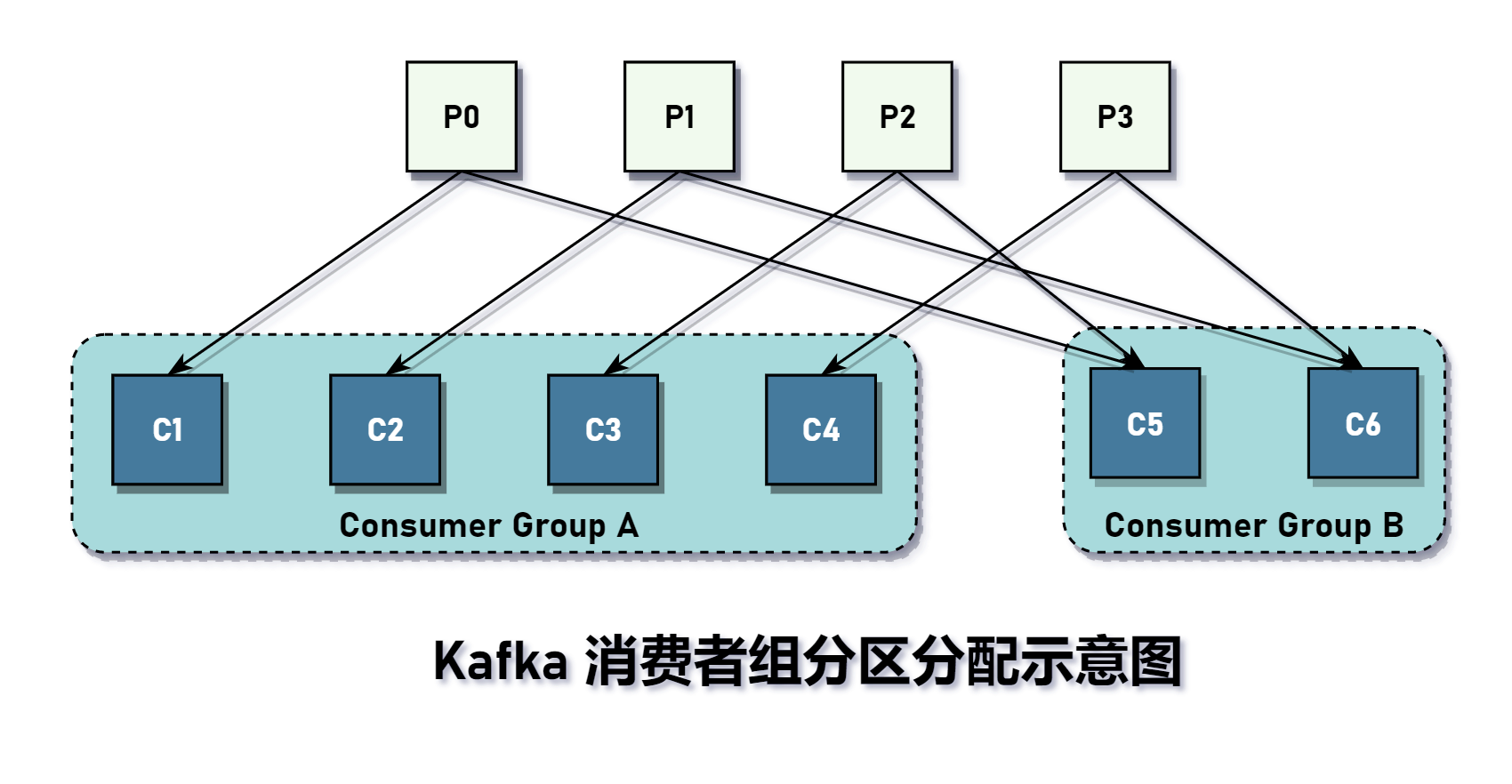
触发时机
总的来说,有以下三点是触发分区重平衡发生的条件:
| 版本 | 元数据存储位置 | 服务端如何感知消费者 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 旧版本 | Zookeeper | 通过 Zookeeper | ① 所有消费者和 ZK 建立连接,并注册一个临时节点。② 服务端通过 watch 机制监听临时节点,也就能感知消费者新增/移除事件。③ 分区元数据信息保留在 ZK 上,服务端也监听分区元数据变更事件。④ 当服务端监听到事件发生,从而使用分区分配策略为消费者组分配分区。 | 实现简单,不需要过多并发编程 | ZK 脑裂,分区分配策略更换麻烦。服务端管理所有分区,单节点导致延迟很高且易崩溃 |
| 新版本 | 内部主题 | 与消费者的心跳连接 | ① 集群有多个消费者组协调器,每个组协调器管理部分消费者组。即分而治之。② 消费者不再直连 ZK,而是和组协调器相连,通过心跳保活机制让组协调器知道消费者实时状态。③ 组协调器协调各个消费者连接、请求等服务,但不参与分区分配,而是起协调作用,在消费者组中选出一个 Leader,并将元数据告诉它,由它完成分配方案,然后再由组协调器传达给各个消费者。 | 分而治之,降低延迟和提高吞吐量。各消费者组可以根据需要个性化更新分配方案。 | 实现复杂 |
源码分析
下面,通过源码+图表方式分析 Kafka 消费者是如何完成分区重平衡操作。
阶段一:确定组协调器的位置
消费者向负载最小的节点(Node)发送
FindCoordinatorRequest请求,消费者线程会在while不断轮询直到得到响应或超时退出。// org.apache.kafka.clients.consumer.internals.AbstractCoordinator#ensureCoordinatorReady/*** 确定组协调器并建立连接。* ① 向负载最小的节点发送「获取本消费组协调器位置」请求。* ② 正常情况下,收到响应后由 {@link FindCoordinatorResponseHandler} 处理器处理,* 通过反序列化二进制数据后得到组协调器的IP+PORT信息,然后将信息放入 {@link #coordinator},* 这样,组协调器所在的节点就被找到了。* ③ 当遇到异常时,会判断是否可重试,然后在重试退避时间外再次发送请求,直到超时或成功得到组协调器位置。** 这个方法会在while循环中不断尝试,直到成功获取组协调器位置或超时。** @param timer 工具类,绑定阻塞超时时间* @return true:有且仅当broker端的消费组协调器成功并初始化TCP*/protected synchronized boolean ensureCoordinatorReady(final Timer timer) {// #1 判断组协调器是否已就绪(知道IP+PORT并且成功建立连接)if (!coordinatorUnknown())return true;do {// #2 如果之前在查找协调器过程中出现致命异常,现在向上抛出if (fatalFindCoordinatorException != null) {final RuntimeException fatalException = fatalFindCoordinatorException;fatalFindCoordinatorException = null;throw fatalException;}// #3 向负载最小的节点发送「获取本消费组的协调器位置」的请求,// 请求中包含消费组的唯一ID名称,返回一个结果凭证,这是一个异步方法final RequestFuture<Void> future = lookupCoordinator();// #4 触发I/O操作,获取响应结果client.poll(future, timer);// #5 判断是否有结果。第一次肯定不会有结果,数据都还可能未发送,// 需要不断轮询「onsumerNetworkClient.poll」从底层Socket获取数据if (!future.isDone()) {// 成功找到组协调器break;}// #6 处理异常RuntimeException fatalException = null;if (future.failed()) {if (future.isRetriable()) {// #6-1 可能由于节点出问题了(如节点故障、选举等导致响应超时),那么尝试更新一下元数据看看是否能解决问题System.out.println("Coordinator discovery failed, refreshing metadata: " + future.exception());client.awaitMetadataUpdate(timer);} else {// #6-2 遇到不可重试致命异常,日志输出fatalException = future.exception();log.info("FindCoordinator request hit fatal exception", fatalException);}} else if (coordinator != null && client.isUnavailable(coordinator)) {// #7 之前所确定的节点不可用,无法发送请求。那就重新寻找新的组协调器markCoordinatorUnknown("coordinator unavailable");timer.sleep(rebalanceConfig.retryBackoffMs);}clearFindCoordinatorFuture();if (fatalException != null)throw fatalException;} while (coordinatorUnknown() && timer.notExpired()); // 直到找到或超时才退出return !coordinatorUnknown();}
响应处理器源码如下:
// org.apache.kafka.clients.consumer.internals.AbstractCoordinator.FindCoordinatorResponseHandler/*** 「FindCoordinator」响应器*/private class FindCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {@Overridepublic void onSuccess(ClientResponse resp, RequestFuture<Void> future) {log.debug("Received FindCoordinator response {}", resp);FindCoordinatorResponse findCoordinatorResponse = (FindCoordinatorResponse) resp.responseBody();Errors error = findCoordinatorResponse.error();if (error == Errors.NONE) {synchronized (AbstractCoordinator.this) {// use MAX_VALUE - node.id as the coordinator id to allow separate connections// for the coordinator in the underlying network client layerint coordinatorConnectionId = Integer.MAX_VALUE - findCoordinatorResponse.data().nodeId();// 有了IP+端口号,可以向该节点发起连接AbstractCoordinator.this.coordinator = new Node(coordinatorConnectionId,findCoordinatorResponse.data().host(),findCoordinatorResponse.data().port());// 异步连接组协调器所在的节点client.tryConnect(coordinator);// 重置会话超时时间heartbeat.resetSessionTimeout();}future.complete(null);} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {future.raise(GroupAuthorizationException.forGroupId(rebalanceConfig.groupId));} else {log.debug("Group coordinator lookup failed: {}", findCoordinatorResponse.data().errorMessage());future.raise(error);}}@Overridepublic void onFailure(RuntimeException e, RequestFuture<Void> future) {log.debug("FindCoordinator request failed due to {}", e.toString());if (!(e instanceof RetriableException)) {// Remember the exception if fatal so we can ensure it gets thrown by the main threadfatalFindCoordinatorException = e;}super.onFailure(e, future);}}
处理器处理响应十分简单,主要有两步:
将 IP + PORT 构成 Node 对象存入 AbstractCoordinator.coordinator 。
然后向该节点发起 TCP 连接,这个方法是异步的。后面我们每次发送请求之前也会判断该节点状态。
阶段二:加入消费组
在成功找到组协调器所在的节点位置后,并与之建立 Socket 连接。接下来,消费者主要做以下两件事情:
向组协调器发送
JoinGroup请求,表示希望加入消费组,成员状态为PREPARING_REBALANCE。- 消费者收到
JoinGroup响应后,更改成员状态为COMPLETING_REBALANCE,然后再向组协调器发送SyncGroup请求。SyncGroup请求的响应包含该消费者的分区分配结果。
新消费者加入消费组示意图如下: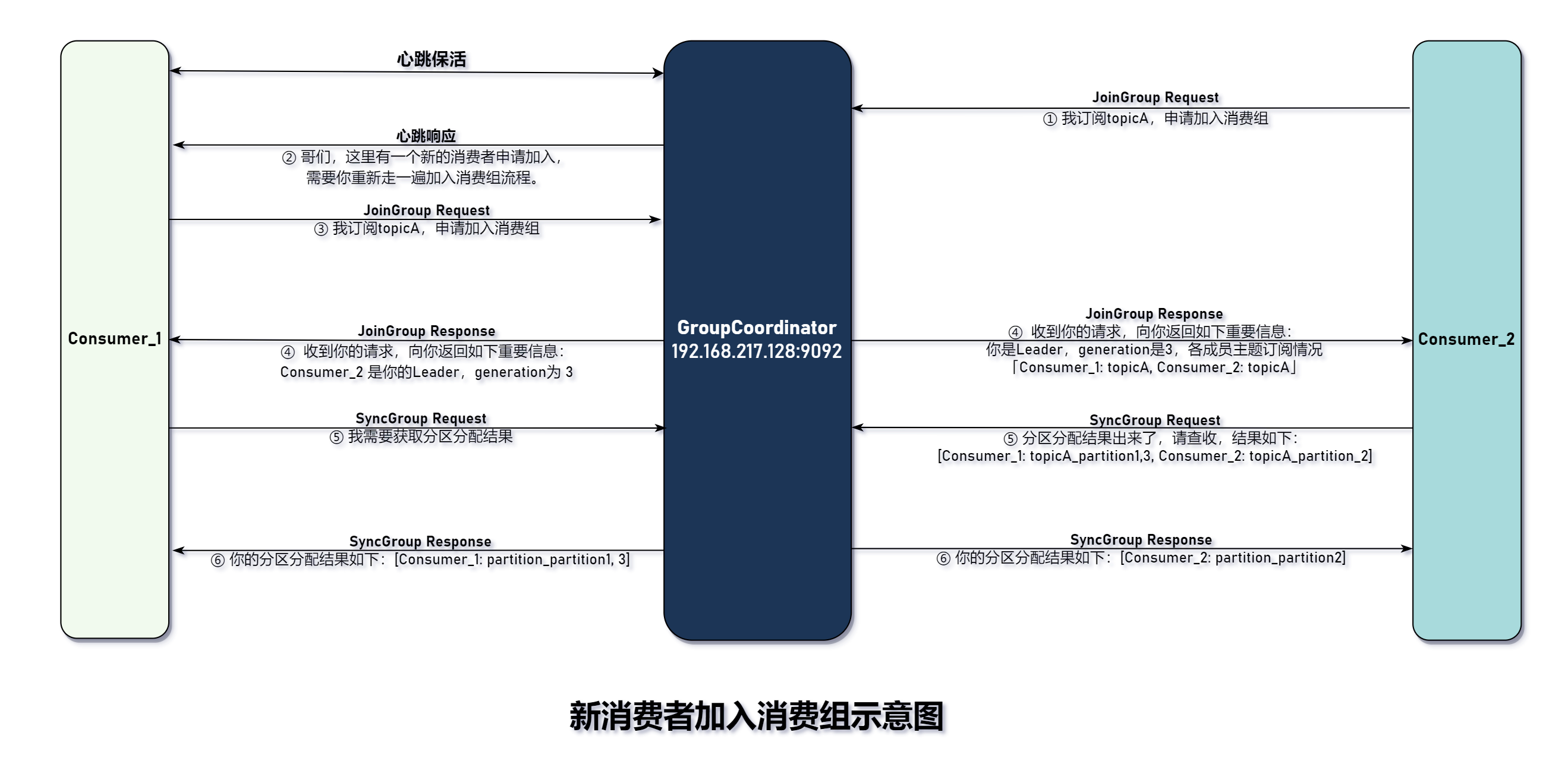
这里提以下几点注意事项:
- 已存在消费组中的消费者是通过心跳响应来感知组协调器此刻正在发生分区重平衡。组协调器以错误码
Errors.REBALANCE_IN_PROGRESS的形式返回给消费者。 - 组协调器通过
JoinGroup请求收集所有消费者,它的实现比较复杂,会新开一个章节讲解。现在只需要知道它延迟一段时间(超时时间由rebanlance.timeout.ms决定,消费者超时时间由max.poll.interval.ms最大值决定)后再向已收集到的消费者返回JoinGroup响应。 - 组协调器会在消费组中选择一个消费者 Leader,选择策略非常简单:先到先得。Leader 和其它消费者收到的
JoinGroup不一样,它会包含组内各个成员订阅主题的详情,并由它根据分配策略执行分区分配操作。 - 所有消费者收到
JoinGroup请求后,还会再发送SyncGroup请求以获得分配结果。这对组协调器来说,这也是一个延迟操作:因为需要等待 Leader 返回才能响应。
下面带大家简单过一遍与分区分配过程相关的消费者端的核心源码。
PART1 心跳线程感知消费组正在发生分区重平衡
心跳线程除了周期性向组协调器发生心跳请求外,还承担其它重要的功能。其中之一就是感知消费组正在发生分区重平衡:
心跳线程收到响应,会判断
errorCode的值,翻译后如果为Errors.REBALANCE_IN_PROGRESS错误,说明消费组正在发生分区重平衡,至于什么事件触发分区重平衡,前面已经介绍过,这里不在重复说明。
相关源码如下:
// org.apache.kafka.clients.consumer.internals.AbstractCoordinator.HeartbeatResponseHandler#handleelse if (error == Errors.REBALANCE_IN_PROGRESS) {// 协调器正在处于分区重平衡期间,暂停接收任何消费者的心跳、位移等请求。// 出现这个原因是因为其它消费加入或分区数量变化触发分区重平衡,因此,当前消费者需要重新发送「JoinGroup」请求重新申请加入消费组if (state == MemberState.STABLE) {// 如果消费者状态为「STABLE」,说明已经在消费组内,所以需要重新发送「JoinGroup」requestRejoin("group is already rebalancing");future.raise(error);} else {// 如果为其他状态,忽略即可log.debug("Ignoring heartbeat response with error {} during {} state", error, state);future.complete(null);}}
只有当消费者成员状态为 MemberState.STABLE 时,才需要重新发送 JoinGroup 请求。而其它状态是不需要做任何事情。
PART2 发送 JoinGroup 请求和处理响应
// org.apache.kafka.clients.consumer.internals.AbstractCoordinator#sendJoinGroupRequestRequestFuture<ByteBuffer> sendJoinGroupRequest() {if (coordinatorUnknown())return RequestFuture.coordinatorNotAvailable();JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(new JoinGroupRequestData()// 消费组ID.setGroupId(rebalanceConfig.groupId)// 会话超时时间,默认值:30000.setSessionTimeoutMs(this.rebalanceConfig.sessionTimeoutMs)// 成员ID,首次为"",后面由协调器分配唯一ID。.setMemberId(this.generation.memberId)// 组静态ID,默认为null.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))// 协议类型。默认值:consumer.setProtocolType(protocolType())// 消费者支持分区策略。默认策略:range.setProtocols(metadata())// 重平衡超时时间,默认值:300000.setRebalanceTimeoutMs(this.rebalanceConfig.rebalanceTimeoutMs));// Note that we override the request timeout using the rebalance timeout since that is the// maximum time that it may block on the coordinator. We add an extra 5 seconds for small delays.int joinGroupTimeoutMs = Math.max(client.defaultRequestTimeoutMs(), rebalanceConfig.rebalanceTimeoutMs + JOIN_GROUP_TIMEOUT_LAPSE);return client.send(coordinator, requestBuilder, joinGroupTimeoutMs).compose(new JoinGroupResponseHandler(generation));}
JoinGroup 响应处理是由 JoinGroupResponseHandler 处理器异步完成的,源码如下:
// org.apache.kafka.clients.consumer.internals.AbstractCoordinator.JoinGroupResponseHandler#handle@Overridepublic void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {Errors error = joinResponse.error();if (error == Errors.NONE) {if (isProtocolTypeInconsistent(joinResponse.data().protocolType())) {log.error("JoinGroup failed: Inconsistent Protocol Type, received {} but expected {} ", joinResponse.data().protocolType(), protocolType());future.raise(Errors.INCONSISTENT_GROUP_PROTOCOL);} else {// 获取锁synchronized (AbstractCoordinator.this) {if (state != MemberState.PREPARING_REBALANCE) {// 如果消费者在重新平衡完成之前被唤醒,我们可能已经离开了这个消费组。// 在这种情况下,我们不希望继续进行下面的「SyncGroup」步骤。future.raise(new UnjoinedGroupException());} else {// 状态正常,更新状态为COMPLETING_REBALANCE,随后会发送「SyncGroup」请求接收分区分配结果state = MemberState.COMPLETING_REBALANCE;// 当状态为 MemberState.COMPLETING_REBALANCE 时,就可以启动心跳线程了。// 因为最终会从这个状态转移到STABLEif (heartbeatThread != null)// 开启心跳线程heartbeatThread.enable();// 记录发生分区重平衡次数(generationId)和成员唯一IDAbstractCoordinator.this.generation = new Generation(joinResponse.data().generationId(),joinResponse.data().memberId(), joinResponse.data().protocolName());// #2 Leader收到「JoinGroup」响应后,// 需要完成分区分配任务,然后把结果发送给协调器if (joinResponse.isLeader()) {onJoinLeader(joinResponse).chain(future);} else {// 其他消费者则只需要发送「SyncGroup」请求,等待协调器将结果返回onJoinFollower().chain(future);}}}}} else if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS) {future.raise(error);} else if (error == Errors.UNKNOWN_MEMBER_ID) {log.info("JoinGroup failed: {} Need to re-join the group. Sent generation was {}", error.message(), sentGeneration);if (generationUnchanged())resetGenerationOnResponseError(ApiKeys.JOIN_GROUP, error);future.raise(error);} else if (error == Errors.COORDINATOR_NOT_AVAILABLE || error == Errors.NOT_COORDINATOR) {markCoordinatorUnknown(error);log.info("JoinGroup failed: {} Marking coordinator unknown. Sent generation was {}", error.message(), sentGeneration);future.raise(error);} else if (error == Errors.FENCED_INSTANCE_ID) {log.error("JoinGroup failed: The group instance id {} has been fenced by another instance. Sent generation was {}", rebalanceConfig.groupInstanceId, sentGeneration);future.raise(error);} else if (error == Errors.INCONSISTENT_GROUP_PROTOCOL|| error == Errors.INVALID_SESSION_TIMEOUT|| error == Errors.INVALID_GROUP_ID|| error == Errors.GROUP_AUTHORIZATION_FAILED|| error == Errors.GROUP_MAX_SIZE_REACHED) {log.error("JoinGroup failed due to fatal error: {}", error.message());if (error == Errors.GROUP_MAX_SIZE_REACHED) {future.raise(new GroupMaxSizeReachedException("Consumer group " + rebalanceConfig.groupId + "already has the configured maximum number of members."));} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {future.raise(GroupAuthorizationException.forGroupId(rebalanceConfig.groupId));} else {future.raise(error);}} else if (error == Errors.UNSUPPORTED_VERSION) {log.error("JoinGroup failed due to unsupported version error. Please unset field group.instance.id and retry to see if the problem resolves");future.raise(error);} else if (error == Errors.MEMBER_ID_REQUIRED) {log.debug("JoinGroup failed due to non-fatal error: {} Will set the member id as {} and then rejoin. Sent generation was {}", error, memberId, sentGeneration);synchronized (AbstractCoordinator.this) {AbstractCoordinator.this.generation = new Generation(OffsetCommitRequest.DEFAULT_GENERATION_ID, memberId, null);}// #1requestRejoin("need to re-join with the given member-id");future.raise(error);} else if (error == Errors.REBALANCE_IN_PROGRESS) {log.info("JoinGroup failed due to non-fatal error: REBALANCE_IN_PROGRESS, which could indicate a replication timeout on the broker. Will retry.");future.raise(error);} else {// unexpected error, throw the exceptionlog.error("JoinGroup failed due to unexpected error: {}", error.message());future.raise(new KafkaException("Unexpected error in join group response: " + error.message()));}}
这里值得提一下的是关于 MEMBER_ID_REQUIRED,新的消费者是没有 MEMBER_ID,在发送 JoinGroup 的参数中 member_id 默认值是 "",随后 JoinGroup 响应体中错误码为 Errors.MEMBER_ID_REQUIRED,且附带一个唯一的 MEMBER_ID,随后消费者使用这个 MEMBER_ID 再重新发送一个 JoinGroup 请求。
代码 #2 区分 Leader 和其他组员收到 JoinGroup 做不同的处理,Leader 会调用 AbstractCoordinator#performAssignment 按照配置的分配策略给组员分配分区,而其它组员仅需要发送 SyncGroup 请求即可。
看看 Leader 是如何处理 JoinGroup 响应的:
// org.apache.kafka.clients.consumer.internals.AbstractCoordinator#onJoinLeader/*** Leader消费者收到「JoinGroup」响应后:* ① 调用 {@link #performAssignment(String, String, List)} 为组内的消费者分配分区。* ② 将结果放到 {@link SyncGroupRequest} 请求中发送给协调器** @param joinResponse JoinGroup 响应* @return*/private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {try {// #1 按配置分区策略为所有组员分配分区,默认分区策略是:rangeMap<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(),joinResponse.data().members());List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList = new ArrayList<>();for (Map.Entry<String, ByteBuffer> assignment : groupAssignment.entrySet()) {groupAssignmentList.add(new SyncGroupRequestData.SyncGroupRequestAssignment().setMemberId(assignment.getKey()).setAssignment(Utils.toArray(assignment.getValue())));}// #2 准备「SyncGroup」请求SyncGroupRequest.Builder requestBuilder =new SyncGroupRequest.Builder(new SyncGroupRequestData()// 消费组组名.setGroupId(rebalanceConfig.groupId)// 成员唯一ID.setMemberId(generation.memberId)// 协议类型,默认值:consumer.setProtocolType(protocolType())// 分区策略,默认值:range.setProtocolName(generation.protocolName).setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))// 简单理解为分区重平衡已发生次数.setGenerationId(generation.generationId)// 消费者分区分配结果.setAssignments(groupAssignmentList));// #3 发送请求return sendSyncGroupRequest(requestBuilder);} catch (RuntimeException e) {return RequestFuture.failure(e);}}
SyncGroup 响应是由 SyncGroupResponseHandler 处理,源码的细节就不带大家看了。
https://www.cnblogs.com/huxi2b/p/6223228.html
问题:
- 已存在消费组的组员如何被通知有新的消费者加入分区?
已存在消费组中的消费者是通过心跳的方式感知到需要重新发送”加入组请求”。 协调器关于消费组的状态更改,因此,协调器无法正常响应消费者发来的心跳请求,协调器通过返回错误码的方式通知消费者:此刻你所处的消费组正在发生分区重平衡,你需要发送 JoinGroup 重新加入消费组。
- 消费者重平衡是否会触发元数据更新?
- 消费组重平衡流程是怎么样的?
- 心跳线程会被阻塞么?
- 消费者在发送
JoinGroup请求之前做些清理工作:提交位移。 - 协调者通常选择第一个发送
JoinGroup请求的消费者作为 Leader 消费者。后续将由它来完成分区分配任务。 - 消费者发送
JoinGroup请求给协调器,协调器在收集完所有消费者和它们所订阅主题信息后再会返回响应给消费者,只有主消费者才会收到整个消费组的元数据信息。 - 消费者收到
JoinGroup响应后,再发送SyncGroup请求给协调者,目的是获得分区分配结果。分区分配结果由 Leader 消费者完成分配,会在SyncGroup请求中放入分配结果。协调者只有收到 Leader 消费者结果才向其他消费者返回JoinGroup响应,这个响应就包含分配结果。
每次调用 KafkaConsumer#poll() 方法时,也同时会调用 ConsumerCoordinator#poll() 方法。理解 Kafka 源码,我们要通过非阻塞思维去理解,也可以通过事件驱动理解,每次循环,就会

若有收获,就点个赞吧
0 人点赞
