- 什么是 Kafka
- 消息安全
- 高可用
- 性能调优
- Kafka 重试机制
- 如何实现一个消息中间件
- RabbitMQ 概念
- Kafka 概念
- 生产者执行流程
- 消费者
- 高性能原因
- Kafka 有哪些文件
- TCP 连接
- 消费者组消费进度监控
- KafkaController
- 脚本
- Kafka 监控
- 消费组中的消费者个数如果超过 topic 的分区,那么就会有消费者消费不到数据” 这句话是否正确?如果正确,那么有没有什么 hack 的手段?
- 当你使用 kafka-topics.sh 创建(删除)了一个 topic 之后,Kafka 背后会执行什么逻辑?
- topic 的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
- 创建 topic 时如何选择合适的分区数?
- 优先副本是什么?它有什么特殊的作用?
- Kafka 有哪几处地方有分区分配的概念?简述大致的过程及原理
- 聊一聊你对 Kafka 的日志留存 Log Retention 的理解
- 聊一聊你对 Kafka 的日志压缩 Log Compaction 的理解
- 聊一聊你对 Kafka 底层存储的理解(页缓存、内核层、块层、设备层)
- 聊一聊 Kafka 的延时操作的原理 ?
- 聊一聊 Kafka 控制器的作用 ?
- 消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
- Kafka 中的幂等是怎么实现的 ?
- Kafka 中的事务是怎么实现的 ?
- Kafka 中有那些地方需要选举?这些地方的选举策略又有哪些?
- 失效副本是指什么?有那些应对措施?
- 多副本下,各个副本中的 HW 和 LEO 的演变过程 ?
- 为什么 Kafka 不支持读写分离?
- Kafka 在可靠性方面做了哪些改进?(HW, LeaderEpoch)
- Kafka 中怎么实现死信队列和重试队列?
- Kafka 中的延迟队列怎么实现(这题被问的比事务那题还要多!!!听说你会 Kafka,那你说说延迟队列怎么实现?)
- Kafka 中怎么做消息审计?
- Kafka 中怎么做消息轨迹?
- Kafka 中有那些配置参数比较有意思?聊一聊你的看法
- Kafka 中有那些命名比较有意思?聊一聊你的看法
- Kafka 有哪些指标需要着重关注?
- 怎么计算 Lag?(注意 read_uncommitted 和 read_committed 状态下的不同)
- Kafka 的那些设计让它有如此高的性能?
- Kafka 有什么优缺点?
- 还用过什么同质类的其它产品,与 Kafka 相比有什么优缺点?
- 为什么选择 Kafka?
- 在使用 Kafka 的过程中遇到过什么困难?怎么解决的?
- 怎么样才能确保 Kafka 极大程度上的可靠性?
- 聊一聊你对 Kafka 生态的理解
- 如何优化 Producer 写入速度
- 为什么分区
- poll(long) 和 poll(Duration)
- 引用
什么是 Kafka
- 分布式的发布-订阅消息引擎,也是一个分布式流处理平台。
- 提供一套 API 实现生产者-消费者。
- 实现高伸缩性架构。
-
消息安全
如何保证消息不丢失
生产者端
调用
**Producer.send(msg, callback)**。一定要使用带回调的send方法,重写里面的**onCompletion**(RecordMetadata, Exception)方法。**acks=all**,表示对 已提交 的定义。- 生产者
**retries**设置为一个较大的值。如遇到网络瞬时抖动,消息可能会发送失败,过一会儿就好了。当retries > 0能够自动重试,避免消息丢失。
Broker 端
**unclean.leader.election.enable = false**。如果一个 Broker 落后旧 Leader 太多,那么当它成为 Leader,触发日志截断操作,那么会造成消息丢失。**replication.factor >= 3**。目的是将消息多保存几份。默认值为 3。**min.insync.replicas > 1**:至少要写入多少个副本才算已提交。一般副本数为 3,这个参数设置成 2,ack 设置为 all。
消费者端
-
重复消息
生产者端
生产者重复发送消息。日志文件中本来就存在两条消息。其中原因是生产者有重试机制,比如网络波动或 GC 而导致生产者未收到 Broker 的 ACK,就会重发消息,但 Broker 已对该条消息持久化至日志文件中,只不过来不及发而已。解决方案:开启生产者幂等。
消费者端
- 在提交消费 Offset 前宕机,那么当服务器重启后,会拉取已消费过的消息重新处理。无论手动提交还是自动提交 Offset,都会存在重复消费问题。
- 服务端触发分区重平衡(Rebalance)。发生分区重平衡有三类事件:① 组成员数发生变更。② 消费者组订阅主题数发生变更。③ 订阅主题的分区数发生变更。
解决方案:通过实现业务幂等来解决消息中间件出现的重复消息问题。对于后端服务讲,通常有以下几种方式:
- 数据库唯一约束。使用几个可以唯一标识这条数据的字段组成联合索引。实现简单,业务层面代码不用改动。但缺点也明显,就是请求直穿整个链路,依赖数据库达到去重目的,对于高并发业务系统而言消耗很大,即便服务扩容,TPS(Transaction Per Second)也很难上去。
- MVCC。多版本并发控制方式。调用
update语句时带上版本号更新update t set v = v + 1 where v = x。优点是提升并发响应能力,实现简单。缺点是只适用update操作,而且还是会将重复请求直达数据库。 - 状态机机制。本质是 MVCC 方案的变种,消息有多个业务状态,每次操作数据都会带上一个状态,只有上一个状态匹配的情况下都会更新数据。优点和缺点和 MVCC 大同小异,主要是解决了数据插入问题。
Token 机制。这是一种高效幂等机制实现方案之一。核心就是要求客户端每次请求里都携带一个唯一标识(比如由雪花算法生成的唯一 ID)。接着判断 ID 是否存在,如果存在则表明是一个重复请求,这个判断可以在业务层完成,也可以在网关层实现。实现对业务层无代码侵入。
消息遗漏
主要是由消费者和生产者
ACK配置相关。
生产者 ACK 配置如果
ACK不为all,那么肯定会有数据丢失的风险。
消费者
Offset 为自动提交。消费者拉取消息后过一段时间才消息,但底层线程将消费位移自动提交。假设此刻消费者宕机,那么会存在一部分消息被遗漏。
消息有序性
有序性分为分局有序和分区有序。Kafka 跨分区消费是无序的。
全局有序:全局使用一个生产者。
- 全局使用一个消费者,且仅有一个消费线程。
- 全局使用一个分区。
分区有序
Kafka 幂等 Producer 能保证单个分区内的消息有序,且不重复。
实现原理:类似于 TCP 的滑动窗口。
局限性:同一 Session,如果 Producer 意外挂掉再重启是无法保证。无法做跨分区消息顺序性。
消息堆积
原因:生产者的生产速度和消费者的消费速度不匹配。一般有以下几点:
- 消费者消费能力弱。可能处理逻辑占用时间过长。比如单条记录插入数据库改为批量操作。
- 生产者生产过快。
解决方案:
- 增大分区数量。
-
事务消息
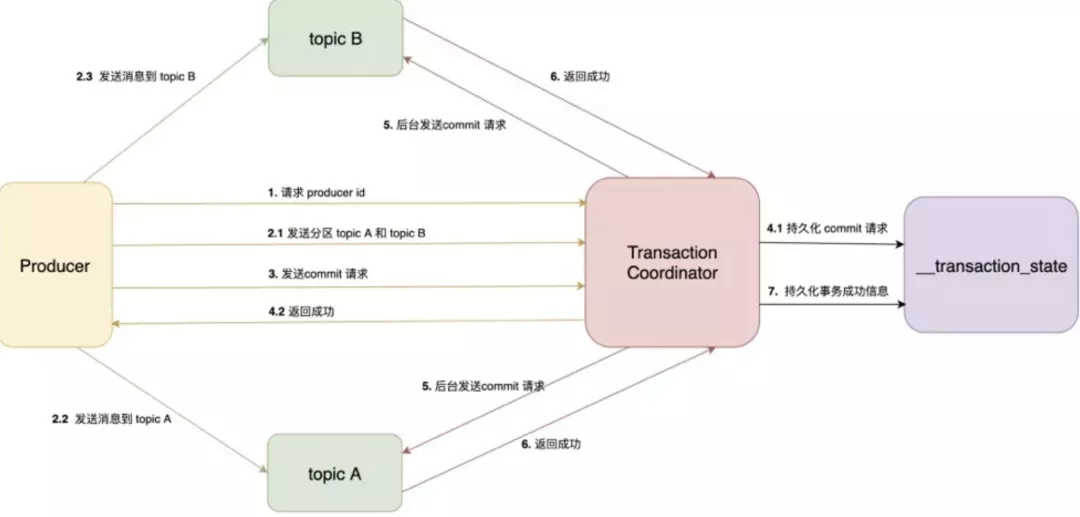
Kafka 基于 2PC 实现分布式事务。主要参与者有三个:① 生产者。② 事务协调器。③ 接收者。
- 生产者向事务协调器(TC)获取 Producer ID。这是生产者全局唯一标识。
- 将目标分区元数据发送给 TC,紧接着,就可以向目标主题发送消息。
- 接着,生产者向 TC 发送
commit请求。 - TC 收到
commit请求后,将元数据持久化至内部主题__transaction_state,并向生产者返回成功。到这里,生产者就已经完成所有事情了。 - TC 分别向参与的主题的 Broker 发送
commit请求,在收到所有参与者返回的成功消息后,再向__transaction_state持久化成功消息。
消费者重试主题
- 多级重试策略(退避策略、死信策略)。不是一个普适策略,它没有考虑到导致消费失败的两大原因:可恢复错误还是不可恢复错误。
- 不可恢复比如空指针异常,消息解码错误。我们应该解决消费者本身,而非过滤消息。
-
延时消息
Kafka 没有 RocketMQ 有现成的 API,我们可以使用一个子服务来达到这样的效果。
并非先投递到真实主题中,先投递到一些 Kafka 内部主题。这些内部主题对用户不可见。
- 然后通过一个自定义服务拉取这些内部主题的消息,并将满足条件的消息再投递到要发送的真实主题中。
- 一般将队列划分不同时间。比如 5S、10S、30S 等等。投递到同一主题的消息延时时间会被格式化。
针对不同延时级别的主题,在子服务的内部都会有单独的线程来进行消息拉取。使用
DelayedQueue暂存消息,这个队列的作用是将消息按照两次投递时间进行有序排序。重试队列
优先队列
这在 Kafka KIP 里面有提到过。
- 高优先级的消息可以插队而被立即消费。
- 对 kafka 来说,应该是一个 Topic 对应有一个优先级。
因此,我们把优先级的问题转换成不同优先级的 Consumer。
自动提交enable.auto.commit(true)->auto.commit.interval.ms(5S),消费过程出现 Rebalance手动提交commitSync()、commitAsync():可以处理异常,不会重试。一般使用异步提交规避瞬时错误,比如 Broker GC、网络抖动。通常遇到的问题是短暂并且可恢复的,因此,下次的手动位移提交操作大概率会成功,异步提交也可以提升在同步提交下的吞吐量,我们一般在关闭生产者之前调用commitSync()方法阻塞式提交位移。commitSync(Map<TopicPartition, OffsetAndMetadata>)根据消息数据提交位移。CommitFailedException
Consumer 客户端提交位移时出现错误或异常。通常是因为消费者消费数据时间过长,两次
poll操作超过了max.poll.interval.ms,因此,组协调器将该 Consumer 剔出,开启 Rebalance。官方文档有两种方式解决:① 增加max.poll..时间。② 减少poll方法一次性返回的消息数量,即设置max.poll.records。③ 多线程消费。
还有一个点是standalone consumer,在 Flink 用到。重设消费位移
两个维度:位移维度(Earliest、Latest、Current、Specified-Offset、Shift-By-N)、时间维度(DateTime、Duration)。
API:
KafkaConsumer#seek(TopicPartitoin, long)、offsetForTimeskakfa-consumer-groups脚本:--group xx --reset-offsets --all-topics --to-earliest -execute消息批次大小
Broker 端:
message.max.bytes、replica.fetch.min.bytes、replica.fetch.max.bytes、replica.fetch.response.max.bytes-
高可用
Kafka 在故障转换(failover) 期间,会出现 STW,大概会有 10 秒左右。应用程序需要显示处理,配置合理的重试次数和退避时间算法。
性能调优
确定调优目标:吞吐量、延时。
- 因为微批原因,延时比较难精确。但在实际生产环境中,愿意用较小的延时增加的代价,去换取 TPS 的显著提升。
优化漏斗:
- 应用程序层:优化消费者逻辑,使用合理的数据结构、缓存、对象池等。
- 不要频繁创建 kafkaConsumer 和 KafkaProducer 实例对象。因为开销非常大。尽量复用。
- 用完及时关闭。
- 合理使用多线程来改善性能。
- 框架层:合理设置 Kafka 集群各种参数。Kafka 提供 200 多个参数,但是核心的也只有十几个。
- Broker 端:
- 保持客户端和 Broker 端版本号一致,否则会丢失比如零拷贝收益。
- 适当增加
num.replica.fetchers,表示副本拉取消息线程数。 - 调优 GC 参数避免经常性的 Full GC。
- 生产者端:
- 适当增加
**batch.size(16KB)**的值,可以增加到1MB。 - 适当增加
**linger.ms(0)**参数,默认值表示即便批次未满,也要发出去。但现在设置 10~100,就会延时等待这些毫秒数才会发送消息。 - 压缩算法:
**compression.type=lz4/zstd**。带宽资源有限,使用zstd,压缩率高。 - 不安全配置:
ack=0/1、retries=0。 - 增加发送缓冲区
Send_Buffer大小。
- 适当增加
- 消费者端:
- 增大
fetch.min.bytes:消费者从 Broker 端获取最小字节数。 max.poll.records
- 增大
- Broker 端:
- JVM 层:Kafka 也是 Java 应用。
- 堆大小:
6~8G。可以通过jmap -histo:live <pid>手动触发 Full GC。 - 垃圾收集器:G1。因为调优参数少。
- 大对象。一般大于半个 Region。可以适当增大 Region 的大小。通过
-XX:+G1HeapRegionSize=N
- 堆大小:
- 操作系统层:这是最底层的性能优化,但是效果说实话,没有前面来得显著。
- 应用程序层:优化消费者逻辑,使用合理的数据结构、缓存、对象池等。
判断请求是否是可重试异常(
RetriableException),比如NetworkException、LeaderNotAvailableException。-
如何实现一个消息中间件
划分角色:生产者、消费者、Broker、注册中心。
- 简述数据流转过程:生产者生产消息,发送到 Broker,Broker 缓存消息。消费者通过轮询机制拉取消息。
- 注册中心:Broker 发现、生产者发现、消费者发现。
- 底层 RPC 协议通信实现,可以基于 Netty 实现底层网络通信。
- 考虑高可用。像 Kafka 使用分区概念。每个分区有多个副本。Leader 挂了怎么办,故障转移如何做。
-
RabbitMQ 概念
channel:信道是生产消费者与 RabbitMQ 通信的通道。使用多路复用。exchange:交换机。作用类似路由器,routing key就是路由键,服务器根据路由键将消息从交换器路由到队列上去。常见有direct:完全匹配。fanout:把一个消息发布到多个队列上去。topic:多个交换机路由消息到同一队列上。
queue:有两种模式,推和拉- 推模式:通过
AMQP.basic.consumer命令订阅。有消息就会自动接收,吞吐量高。但是消费者丢失主动权。 - 拉模式:通过
basic.get命令。
- 推模式:通过
- 确认机制:
- 异步处理。将一些实时性要求不要很强的业务异步处理。
- 系统解耦。将消息生产和消息消费分离,实现应用解耦。
- 削峰填谷。缓冲上下游瞬时突发的流量,特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,脆弱的下游系统就可能会直接被压垮。造成全链路雪崩。有了消息系统作为中间件,真正做到将上游的峰填满到谷中,避免流量震荡。
ISR、AR 含义
- AR(Assigned Replicas):分区中所有的副本统称为 AR。
- ISR(In Sync Replicas):所有与 Leader 副本保持正常同步的其它副本。
- OSR(Out-of-sync Repliced):与 Leader 副本出现的同步延迟超过阈值,这些副本被踢出 ISR 集合。
- AR = ISR + OSR。
ISR 的伸缩性
- ISR 的伸缩性是通过两个定时任务完成的:分别是
isr-expiration和isr-change-propagation。每隔15S检查一下。 - 收缩 ISR 条件:如果
Follower副本没有没有在replica.lag.time.max.ms(30S)以内发送 Fetch 请到 Leader 副本,那么 Leader 副本就会判定该副本没有资格在 ISR 集合中。 - 收缩 ISR 过程:① 判断,得到待收缩的副本 ID。② 向 Controller 发送 AlterIsr 请求。③ Controller 收到后,向集群广播更新元数据请求。
Kafka 0.10.0版本将replica.lag.max.messages参数被正式移除,原因是这个参数无法正确表明 Follower 当前同步状态。Leader 副本每秒能接收的数据并非固定,可大可小,那么仅通过判断 Follower 和 Leader 消息同步的lag是无法准确说明 Follower 的同步状态。在0.9版本后,就改成以下样子: Follower 同步:每隔
500ms从 Leader 副本拉取消息。HW、LW、LEO、LSO 含义
HW,High Watermark。即高水位线。ISR 集合中最小的
LEO值。- LW,Low Watermark。即低水位线。AR 集合中最小的
LEO值。 - LEO,Log End Offset。当前分区下一条待写入的消息偏移量。
- LSO,Log Stable Offset。与 Kafak 事务有关。对于未完成的事务而言,LSO 的值等于事务中第一条消息所在的位置。对于已完成的事务而言,它的值等于 HW。
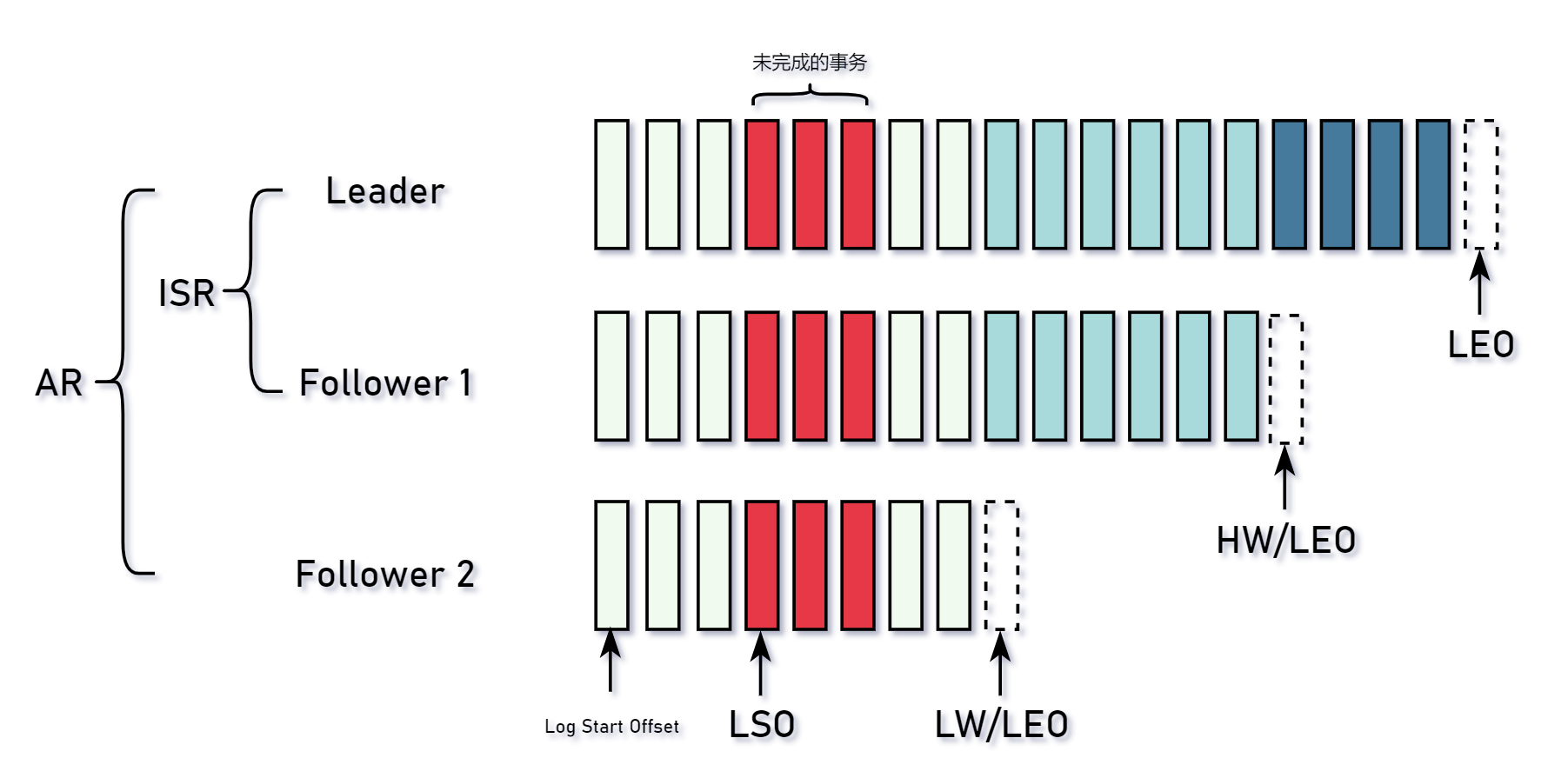
总结:HW、LW 是分区层面的概念。LEO、Log Start Offset 是单一副本日志层面的概念。LSO 是事务层面的概念。
Kafka 提供三种语义
- At most once。至多一次,存在消息丢失风险。
- At lease Once。至少一次,存在重复消息。
-
推拉模式
推模式:消息实时性高,消费者实现简单,但推送速率难以匹配消费速率。容易造成消费者崩溃。
拉模式:根据自身处理能力拉取消息,更适合批量发送。但造成消息延迟较高。
生产者执行流程
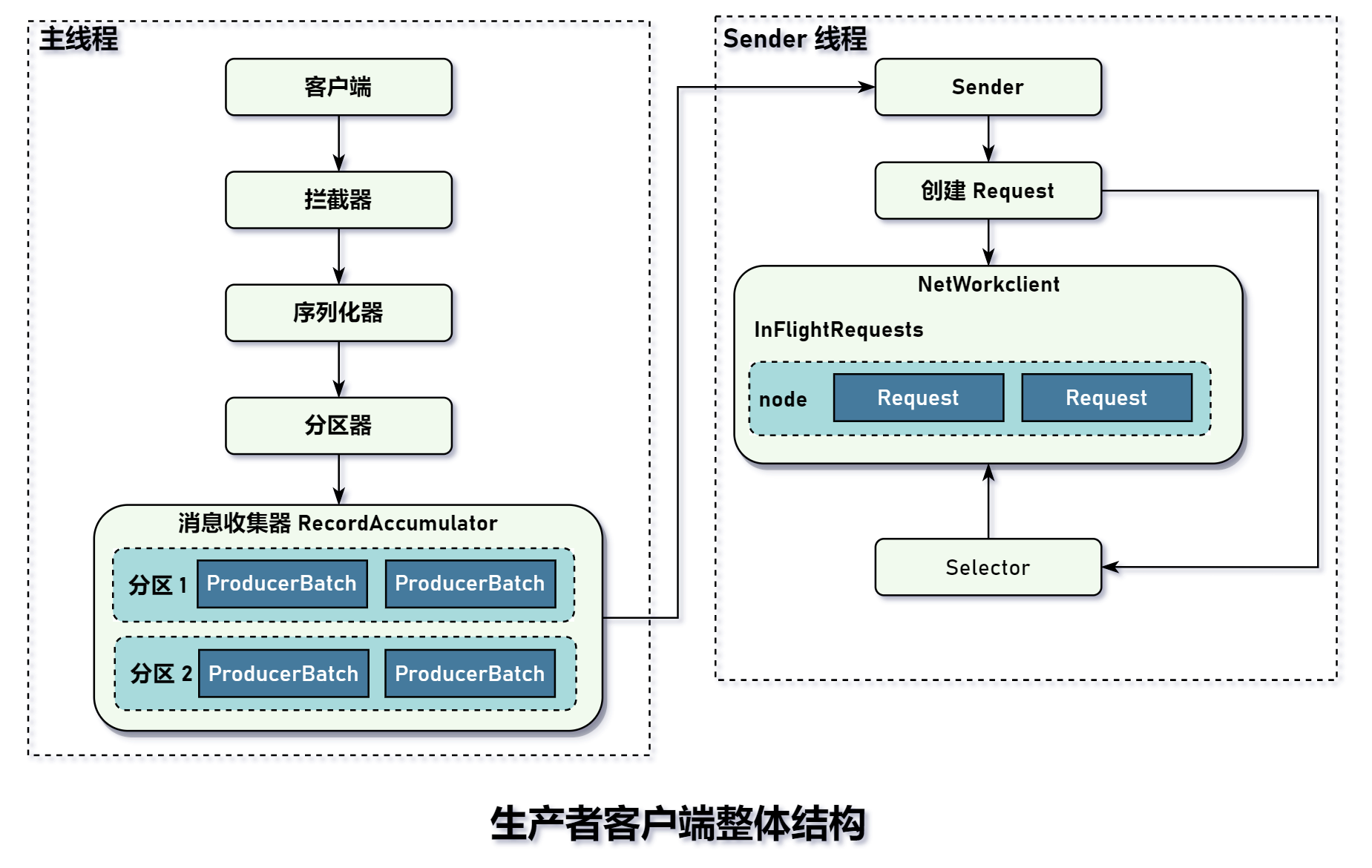
拦截器:允许用户在消息发送前做一些准备工作,比如过滤、修改等操作,从而实现个性化需求。这是 Kafka 提供的扩展能力之一。用户可以实现
ProducerInteceptor接口即可实现生产者拦截器。可以使用多个拦截器组成拦截器链。- 序列化器:将消息的 key 和 value 序列化字节数组,消费者通过反序列化器将字节数组转化成对应的对象。比如 Kafka 自带有 String 、ByteArray、ByteBuffer 等等。在生产环境中还可以选择 Avro、JSON 等通用的序列化工具实现。也可以通过实现
Serializer接口来实现个性化需求。 - 分区器:主要目的是确定消息该发往哪个分区,存在 3 种情况和 1 种优化:
- 指定
partition参数。 partition = null且存在key,则idx = hash(key) % 分区数。partition = null && key == null,旧的情况会使用Round Robin(RR)算法随机分配。现在使用StickyPartitionCache粘性分区优化。底层是使用一个 Map 存储主题和分区序号,它的目的是随机选择一个分区并尽可能坚持使用该分区。因为消息是微批处理,有助于改进消息批处理,提高负载。
- 指定
- 消息收集器:
ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches,底层的数据结构就是一个 Map,这个 Map 比较特殊,是一个写时复制的 Map,因为分区创建操作相比较少。 -
消费者
旧版 Scala 的消费者设计缺陷
消费位移保存在 ZK 中。
- 多线程模型 + 阻塞式获取机制。老版本的 Consumer 是多线程架构,每个 Consumer 实例在内部为所有订阅的主题分区创建对应的消息获取线程,即 Fetcher 线程。同时也是阻塞式的。但在很多场景下,Consumer 端有非阻塞式需求,比如在流式处理应用过程中执行
fileter、join、group by等等操作就不应是阻塞式的。 新版本 Consumer 设计了单线程 + 轮询(poll)机制,这种设计较好地实现了非阻塞式的消息获取。
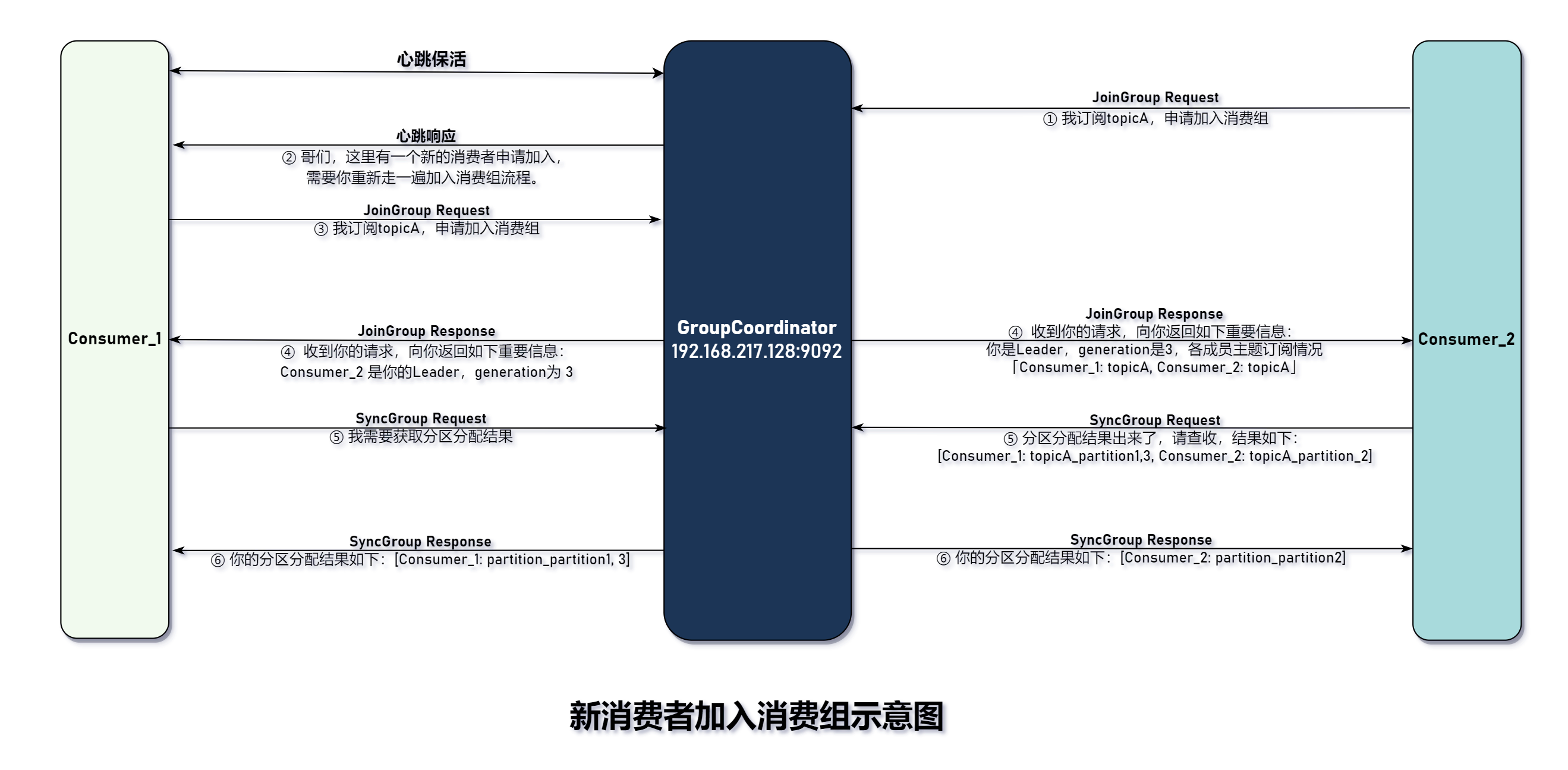
消费者重平衡
主要有两种类型的请求,分别是
**JoinGroup**和**SyncGroup**。- 下面是当有新成员加入组所触发的消费者重平衡操作:
- 新成员发送
JoinGroup请求。 - 其它成员通过与
GroupCoordinator保持心跳连接,从心跳连接中得到当前有新成员加入消费者组。 - 其它成员立即发送
JoinGroup请求。消费者组协调器等待其它组员发送完成(joinPurgatory)。 - 当收到所有成员的
JoinGroup请求后,消费者向成员返回JoinGroup响应,Leader 消费者会收到整个消费组的所有元信息,由它负责制定具体的分配方案。 - 所有消费者向消费者组发送
SyncGroup请求,Leader 消费者附带最终分配方案。 - 消费者组协调器收到后,向所有消费者响应
SyncGorup请求,里面包含整个消费者组的最终分配方案。
- 新成员发送
消费者重平衡相关问题
Rebalance 一般会有三种情况:① 新成员加入。② 成员主动离开。③ 成员线程崩溃。对于 ③ 来说是未知事件,往往就不好应对。我们需要理清 Kafka 消费者以下四个配置参数:
| 参数 | 说明 |
|---|---|
| session.timeout.ms(45S) | 组协调器用于探测客户端是否存活的,客户端周期性向组协调器发送心跳,如果在超时时间前没有收到心跳,则会剔除该客户端,并触发重平衡。 |
| heartbeat.interval.ms(3S) | 消费者心跳发送间隔。一般是 1/3 session.timeout.ms |
| max.poll.interval.ms(5min) | 两次调用 poll() 方法间隔时间。如果时间到了,消费端还没有消费完,组协调器会认为该消费者崩溃,触发 Rebalance |
| max.poll.records | 每次 poll() 操作拉取多少条消息。 |
Consumer 多线程消费
实现原因:Consumer 因为消费能力弱而导致任务消费过长,进而导致 Kafka 消费端吞吐量下降。为了提高吞吐量,在增加分区达到瓶颈的情况下,我们使用 Consumer 多线程消费模式。注意,KafkaConsumer 是非线程安全的。 | 方案 | 优点 | 局限性 | | —- | —- | —- | | 每线程每 KafkaConsumer 实例 | ① 粗粒度化工作,不会对任务进行分类。② 方便实现。③ 易于维护分区内消息顺序。 | ① 占用更多系统资源。② 线程数受分区数影响较大,水平扩展能力弱。 | | ① 单个/多个线程拉取消息
② 单独的线程池负责消息处理逻辑 | ① 可独立扩展消费线程数和 Woker 线程数,弹性伸缩强 | ① 实现难度较高,容易引发死锁等问题。② 难以维护分区内的消息顺序,需要业务层面进行一定规则处理。③ 处理链路较长,不易位移提交管理,可能会出现消息重复消费。 |继承 Kakfa 的
ShudownableThread,然后重写shutdown方法即可,这样应用收到kill -15信号后有机会将队列中的任务处理完后退出程序。如果出现因
OOM导致程序异常退出,上面的方法就变得不可靠。可以使用日志系统。维护一个单独的日志文件,在 commit 前写入一条日志。然后在真正执行完毕后写入一条对应的日志。也就是日志先行。当系统启动时,读取这些日志文件,将未被处理的消息重新执行一遍。还可以在后台启动一个定时任务,定期对日志文件进行压缩。也可以借助 Redis,使用Hash数据结构,提交任务的同时写入 Redis,任务执行完后删除。消费者 ACK 发送失败是如何处理的?
两种 ACK 提交模式。消费者提供两者提交 ACK 模式,一种是同步
commitSync(),另一种是异步提交:commitAsync()。- 同步默认超时时间是
60S,
高性能原因
日志模型
- 文件夹以 主题名-分区号 命名。内部再划分为多个日志段,称为
Segment。 - 每个日志段以消息起始偏移量命名,长度 20。
为了方便检查消息,Kafka 提供两种不同类型的索引文件,一是偏移量索引。二是时间戳索引。采用稀疏索引,每写入
4KB就添加一个索引项。查找定位 offset(通过 offset 查对应消息)
Kafka 使用
**ConcurrentSkipListMap**跳表存储日志段对象Segment,调用floorEntry(offset)可以在 时间范围内获取小于
时间范围内获取小于 offset的最大偏移量所对应的Segment对象。我们的消息就存在这个日志段对象中。- 我们知道,每个日志段(以
.log结尾)都有两个索引文件与之对应(稀疏索引),这里我们查找偏移量为offset的消息,所以我们需要通过索引文件.index定位消息的物理位移。由于采用稀疏索引,所以不一定直接命中,这里还会经历一小段顺序查找,直到找到偏移量所对应的物理位移。索引查找采用缓存友好型的二分查找算法,如果单纯使用二分查找,会导致系统的pageCache频繁触发缺页异常。在使用二分算法前需要定位查找的位移 offset 属于热区还是冷区。如果在热区,对热区区段使用二分查找,如果在冷区,对冷区区段进行查找,这一步可能会比较慢。 - 然后在
.log获取offset对应的消息(有可能需要顺序查找,不过速度很快)。Broker 端网络模型
基于主从 Reactor 实现。SocketServer组件,内部有一个Acceptor线程和一个工作线程池,叫网络线程池,数量由num.network.threads控制,默认为3。Acceptor使用轮询策略将新的 TCP 连接公平地分发到所有网络线程中。当网络线程池拿到请求后,它并不是直接处理,而是将请求放到一个共享请求队列中,Broker 端还有个 IO 线程池,负责从队列中取出请求,执行真正处理。由参数num.io.threads控制,默认值是 8。如果 CPU 资源充足,可以调大。请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属。多层时间轮
对象池
Kafka 有哪些文件
日志文件
| 文件类型 | 说明 |
|---|---|
| .log | 存储消息的日志文件 |
| .index | 存储<相对偏移量, 物理偏移量>索引项 |
| .timeindex | 存储<时间戳, 绝对逻辑偏移量>索引项 |
| .snapshot | 为幂等型或事务型 Producer 所做的快照文件 |
| .txnindex | 存储已终止的事务索引项 |
| .deleted | 待删除的日志段文件。删除操作是异步执行。所以这相当于是一个标识符。log cleaner 根据相关日志清理策略清理旧的日志文件。 |
| .cleaned | log compact(日志压紧)操作产生的临时文件,在进行log compact时,产生对复制旧的日志段文件,在旧的文件名基础上加上这个后缀作为新的文件名 |
| .swap | log compact(日志压紧)操作产生的临时文件,当对.cleaned完成 compact 操作后,会将文件名的后缀修改为.swap,表示可以和旧的日志段文件(.log 结尾)交换,使之成为新的日志段文件,旧的日志段文件会添加 .deleted后缀 |
| .kafka_cleanshutdown | 是一标记文件,如果文件存在,表示Broker上次是正常关闭(clean shutdown),重启过程不需要进行恢复操作。如果文件不存在,意味着Broker由于崩溃而导致部分文件错误,需要进行恢复(recovery)操作。 |
| -delete | 当删除一个主题时,该主题的所有分区的文件夹会被添加这个后缀 |
| -future | 变更主题分区文件夹地址 |
TCP 连接
消费者
- 和负载最小的节点创建 TCP 连接,获取集群元数据信息。
- 复用 TCP 连接,发送
FindCoordinator请求。 - 和组协调器建立 TCP 连接,才能进行消息。
- 和目标 Broker 建立 TCP 连接,实际用于消息获取。
Broker.id 有几种变量:① -1 表示消费者程序首次启动,对 Kafka 集群一无所知。② 2147483645 是 Integer.MAX_VALUE - Broker ID 得到,目的是让组协调器请求和真正数据获取请求使用不同的 TCP 连接。消费者会创建 3 类 TCP 连接:① 确定组协调器和获取集群元数据。② 连接组协调器。③ 实际消息获取。
TCP 连接生命周期
自动关闭由 connection.max.idle.ms 控制,默认 9 分钟。前面的 ① 所建立的 TCP 连接会被终止,改为使用 ③ 的 TCP 连接获取集群元数据。
消费者组消费进度监控
- 滞后程度:消费者当前落后于生产者的程度。一般讨论的对象是主题,所以统计该指标时需要将主题下各分区的 lag 手动汇总合并,得到最终的 Lag 值。
- 影响:lag 过大,消息不在操作系统的 Page Cache 中,失去享有零拷贝的资格,进一步拉大差距,且出现马太效应,lag 越拉越大(强者越强,弱者越弱)。
监控方式:①
kakfa-consumer-groups。② Consumer API。③ JMX 指标(易集成到 Zabbix 或 Grafana)。提供数据冗余
- 提供高伸缩性
- 改善数据局部性。允许将数据放入与用户地址位置相近的地方,从而降低系统延时。
依赖 ZK 感知 Leader 副本挂掉 => 开启新一轮领导者选举。但是 Kafka 的追随者副本是不会向外提供服务的,Kafka 的副本既不能像 MySQL 的从库可以进行读操作,也无法将副本放到离客户端最近的地方改善数据局部性。这种副本机制带来的好处:① 方便实现 Read Your Writes。当你使用生产者向 Kafka 成功写入消息后,马上使用消费者 API 去读取刚才生产的消息。② 方便实现单调读,实现数据一致性。
延迟请求
Purgatory /ˈpɜːrɡətɔːri/ 组件。用来缓存延时请求,所谓延时请求就是那些一时半会还未满足条件不能立即处理的请求。比如 acks=all 的 PRODUCER 请求。
请求类型
PRODUCER 请求、FETCH 请求、LeaderAndIsr 请求、StopReplica 请求。
数据类请求和控制类请求。控制类请求可以直接令数据类请求失效。Kafka 2.3 正式实现将数据类请求和控制类请求分离:分别在后台创建网络线程池和 IO线程池,分别处理数据类请求和控制类请求。使用不同的网络端口,提供不同的 listeners 配置。
batch.size
RecordTooLargeException
设置了 batch.size(512000),但是没有设置 max.request.size(1048576),然后看源码,发现是首先判断是否大于 max.request.size,如果没有,则直接抛出异常,不会继续追加消息到 batch。当然,还有一个扩展参数 linger.ms,会缓存一定批次后才发送。
KafkaController
是 Kafka 核心组件,主要是依赖 Zookeeper 管理和协调整个 kafka 集群。运维指标:activeController
Zookeeper:① 临时 Node。比如 /brokers/ids 、controller ② 持久性节点 topics。③ Watch 通知功能,ZK 通过 ChangeHandler 方式显示通知客户端。
- 选举。每台 Broker 启动时就会尝试竞选成为集群的 Controller。
- 作用
- 主题管理。
kakfa-topic脚本都是由 Controller 完成。 - 分区重分配。
kafka-reassign-partitions。 - Preferred 领导者选举。
- 集群成员管理。
- 元数据服务。
- 主题管理。
- 故障转移机制
- 每个 Broker 都会在
controller节点注册监听器。
- 每个 Broker 都会在
设计原理:单线程 + 事件队列机制。② ZK 操作是异步操作。③ 控制类请求优先级。
Kafka 高水位
定义消息可见性。用来标识分区下的哪些消息是可以被消费者消费的。
- 帮助 kafka 完成副本同步。
副本对象重要属性:高水位和 LEO。
Leader 副本的高水位是指分区的高水位。
- 处理生产者请求:① 写入消息到本地磁盘。② 更新分区高水位值。2.1 获取所有远程副本的 LEO 值。2.2 获取 Leader 高水位值。2.3 更新 HW = min()
- 处理 Follower 副本拉取消息。① 读磁盘数据。② 使用 Follower 副本发送请求中的位移值更新远程副本 LEO 值。③ 更新分区高水位值。
Follower 副本:
- 从 Leader 副本拉取消息。① 写入消息到磁盘。② 更新 LEO 值。③ 更新高水位值:3.1 获取 Leader 高水位值。3.2 获取 副本 LEO。③ 更新高水位 min(..)
Kafka 基于 Epoch 来解决 Follower 副本和 Leader 副本因时间错配而导致可能消息丢失。
主题管理
kakfa-topic.sh --create --partition --replication-factorkafka-topic.sh --describe --topic <topic_name>kafka-topic.sh --alter --topic --partitions:分区数一定要增大,否则抛出 InvalidPartitionsException 异常。
修改主题级别配置:kafka-config --entity-type topics --entity-name <topic_name> --alter --add-config max.message.bytes=11111
变更副本数、主题迁移:kafka-reassign-partitions
- 将某些分区批量迁移到其它 Broker 上:
kafka-topic.sh
常见问题:
- 主题删除失败。原因:① Broker 宕机。② 分区正在迁移。措施:① 手动删除 ZK
/admin/delete_topics节点。② 手动删除主题在磁盘上的分区目录。③ 重新触发 Controller 选举。Kafka 动态配置
不必重启 Broker,比如调用 Broker 端各种线程池大小,实时应对突发流量。Broker 端连接信息和安全配置信息。JMX 指标收集。当 Broker 入站流量激增时,会造成 Broker 端请求积压,我们可以动态增大网络线程数和 IO 线程数,快速消耗一些积压。
实现原理:基于 Zookeeper。kafka-config.sh --add-config/--delete-config
log.retention.msnum.io.threads、num.network.threadsnum.replica.fetchers:Follower 副本拉取速度慢,可以适当增大。脚本
| 脚本 | 说明 | | —- | —- | | kafka-acls | 设置用户权限 | | kafka-broker-api-version | 验证 Kafka 版本之间适配性 | | kafka-config |--add-config--alter、--delete-config| | kafka-console.consumer | | | kakfa-console.producer | | | kafka-consumer-pref.sh | | | kakfa-producer-pref.sh | | | kafka-consumer-groups | 重设消费位移、获取 LAG | | kafka-delegation-token | | | kafka-dump-log | 查看 Kafka 消息文件内容,包括各种元数据信息,甚至是消息体本身。
以--files则查看消息批次。如果想看每条具体消息,则使用--deep-iteration,如果还想看实际数据,再加上--print-data-log| | kakfa-log-dirs | 查询 Broker、主题、包括分区文件大小、Lag | | kafka-mirror-maker | 实现 Kafka 集群间同步 | | kafka-preferred-replica-election | 执行 preferred Leader 选举 | | kafka-reassign-partitions | 执行分区副本迁移以及副本文件路径迁移 | | kafka-topics | 所有主题管理操作 | | kakfa-run-class | 执行任何带 Main 方法的 Kafka 类。 |
查看主题消息总数:
[root@localhost bin]# ./kafka-run-class.sh kafka.tools.GetOffsetShell-broker-list 192.168.217.130:9092 --time -2 --topic jamesjames:0:52560james:1:53724james:2:49948
AdminClient
运维。功能:
- 主题管理。包括创建、删除和查询主题。
- 权限管理。具体权限的配置与删除。
- 配置参数管理。
- 副本日志管理。日志路径变更和详情。
- 分区管理。创建额外的主题分配。
- 消息删除。删除指定位移前的分区消息。
- Token 管理。
- 消费者组管理。
- Preferred 选举。
执行流程:① 创建对应的请求。② 指定响应的回调逻辑。
createTopics:创建主题listConsumerGroupOffsets:获取消费者组消费位移MirrorMaker
kafka-mirror-maker.sh --consumer.config ./consumer.properties --producer.config ./producer.properties --num.streams 8 --whitelist ".*"num.streams:创建多少个KafkaConsumer实例。- Range、Round-Robin
其它同步工具:Uber 的 uReplicator、LinkedIn 的 Brookin Mirror Maker、Confluent 的 Replicator。
Kafka 监控
- 主机监控:机器负载、CPU 使用率、内存使用率、磁盘 I/O 使用率、网络 I/O 使用率、TCP 连接数、打开文件数、inode 使用情况。
- JVM 监控:JVM 进程的 Minor GC 和 Full GC 发生频率和时长、活跃对象的总大小和 JVM 上应用线程的大致总数。通过 GC 日志查看堆上的存活对象大小。建议使用 G1 GC,但是需要避免 Full GC,因为单线程回收,速率非常慢。如果发现频繁 GC,可以开启 G1 的
-XX: +PrintAdaptiveSizePolicy得到谁引发了 GC。 - 集群监控:
- Broker 是否正常启动,端口是否被占用。
- 查看 Broker 端关键日志。包括
server.log、controller.log、state-change.log - 查看 Broker 端关键线程运行状态。包括两类:
- Log Compaction 线程。2. 副本拉取消息的线程。
- JMX 指标:BytesIn/BytesOut。入站和出站字节数。
NetworkProcessorAvgIdlePercent网络线程池平均空闲比例。应该大于30%。如果小于这个值,说明网络线程池非常繁忙。UnderReplicatedPartitions:未充分备份的分区数,同步所有副本。ISRShrink/ISRExpand:ISR扩缩容频次。ActiveControllerCount:Controller 数量。
监控客户端
JMXTool:简单监控场景。
- Kafka Manager。雅虎公司开源。
-
部署方案
操作系统 Linux
- 磁盘容量:① 新增消息数。② 消息留存时间。③ 平均消息大小。④ 备份数。⑤ 是否启用压缩。
-
消费组中的消费者个数如果超过 topic 的分区,那么就会有消费者消费不到数据” 这句话是否正确?如果正确,那么有没有什么 hack 的手段?
正常来说,这是正确的。但是,kafka 留了后门,可以通过实现自定义分区分配策略,来实现个性化需求。
Leader 消费者在收到JoinGroupRequest请求后,会按照指定的分区分配策略进行分区分配,你也可以自定义分区分配策略 — 必须实现PartitionAssignor接口。用户可以通过userData来添加比如权重、IP 地址、机架、host 等元数据信息,通过这些信息进行个性化需求的实现。当你使用 kafka-topics.sh 创建(删除)了一个 topic 之后,Kafka 背后会执行什么逻辑?
在 ZK 路径
/brokers/topics节点下创建一个新的 topic 节点。- 触发 Controller 监听。
- Kafka Controller 负责 topic 创建工作,更新相关元数据缓存。
简单来说,就是在 ZK 中创建路径,从而被 Controller 感知到,随后执行真正创建主题的流程。
topic 的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加,使用以下 kafka-topic.sh 命令:
./kafka-topic.sh --bootstrap-server 192.xxx --alter --topic test --partitions 5
当变更分区数量时,订阅该分区的所有消费者组都会触发分区重平衡操作,这相当于 JVM 的 STW,对整个集群消费流量有较大的影响。分区重平衡实在太慢了,我们应该在线上环境尽量避免或减少发生的次数。
创建 topic 时如何选择合适的分区数?
- 先使用
kafka-producer-perf-test.sh和kafka-consumer-perf-test.sh分别测试生产者和消息者的性能。 - 无脑扩增分区和线程有可能会有反作用,所以,我们应该通过性能测试寻找一个平衡点。
- 基于 TPS 需求大致确定分区数,即
分区数 = TPS/min(生产者TPS, 消费者TPS)。 更多的分区意味着需要更多的系统资源。如果资源紧张,应该适量分配。
优先副本是什么?它有什么特殊的作用?
优先副本是指
AR集合列表中第一个副本。
设定原由:涉及 Leader 负载均衡问题。从理论上讲,Kafka 集群会保证分区 Leader 在整个集群负载是均衡的,某个 Broker 既不会流量过大,也不会太小。但是由于分区重平衡存在,导致某个 Broker 承载过多 Leader 分区。Kafka 为此设置优先副本(preferred-replica)概念,它指的是一开始创建 Topic 时的 Leader 副本,那些整个分区可看作是大致均衡的状态,当然,也有可能分配不均衡。优先副本选举就是对分区 Leader 进行选举时,尽可能让优先副本成为 Leader 副本。
Kakfa 支持自动优先副本选举,默认是5分钟执行一次。但在生产环境中建议关闭,因为有可能导致服务不可用。如何真需要维护集群的负载均衡,建议在夜深人静时使用kakfa-reassign-partition.sh脚本执行个性化的分区分配方案。Kafka 有哪几处地方有分区分配的概念?简述大致的过程及原理
Kafka 一共有
3处需要进行分区分配流程。分别是:将数据分配给某个分区(生产者端)。Kafka 需要根据消息元数据(比如是否指定某个分区、是否有 key 等等)采取相应的分区分配策略。
- 将某个分区分配给某个消费者(消费者端)。Leader 副本根据分区分配策略制定整个消费者组的分配方案,由消费者组协调器传达给其它消费者。
将某个分区分配给某个 Broker(Broker 端)。比如创建一个新的主题、或使用
kakfa-reassign-partition.sh脚本用以重新将分配分配给不同的 Broker。聊一聊你对 Kafka 的日志留存 Log Retention 的理解
日志文件不可无限创建,否则磁盘空间很快就会满载。合适的日志留存策略可以保证系统长时间稳定运行。目前,与日志留存方式相关的策略类型有两种:① delete。② compact。通过
log.cleanup.policy来指定集群上所有topic默认的留存策略。当然,你也可以细粒度地为特定的 Topic 设置留存策略。
这里主要讲解delete留存策略。Kafka Broker 启动时,会开始一个定时任务:定期检查执行所有 Topic 日志留存,时间周期配置参数:
log.retention.check.interval.ms,默认是5分钟。delete基于三种对日志进行删除操作:① 时间。② 空间(磁盘大小)。③ 起始位移。- 空间维度。
log.retention.bytes = -1。一旦超过阈值,会尝试从最老的日志段开始删除,删除整个日志文件(.log)。注意,这里日志问题即便超过阈值也不会直接删除第一个日志段,而是日志总量 - 阈值 > 最旧日志段,才会执行删除操作。 - 时间维度。Kafka 定期删除超过阈值的日志段。由
log.retention.mintues/ms/hours参数配置。Kafka 为每个主题默认保存 7 天的日志。通过比较最大消息时间戳来判断该文件是否已超过 7 天。 - 起始位移。
0.11.0.0版本新增的功能。初衷是为了 Kafka 流处理应用。起始位移,就是指分区日志的当前起始位移值。这个留存机制是默认开启的。Kafka 会执行以下操作:① 获取日志段 A 的下一个日志段 B 的baseOffset。② 如果该值小于分区当前起始位移则删除日志段 A。聊一聊你对 Kafka 的日志压缩 Log Compaction 的理解
对每个消息的 key 进行整合:对于有相同的 key 的不同 value 值,只保留最后一个版本。如果一个消息的key != null && value == null,那么此消息就是墓碑消息。配置项log.cleanup.policy = compact表示开启日志压缩策略,并且还需要个性log.cleaner.enable=true。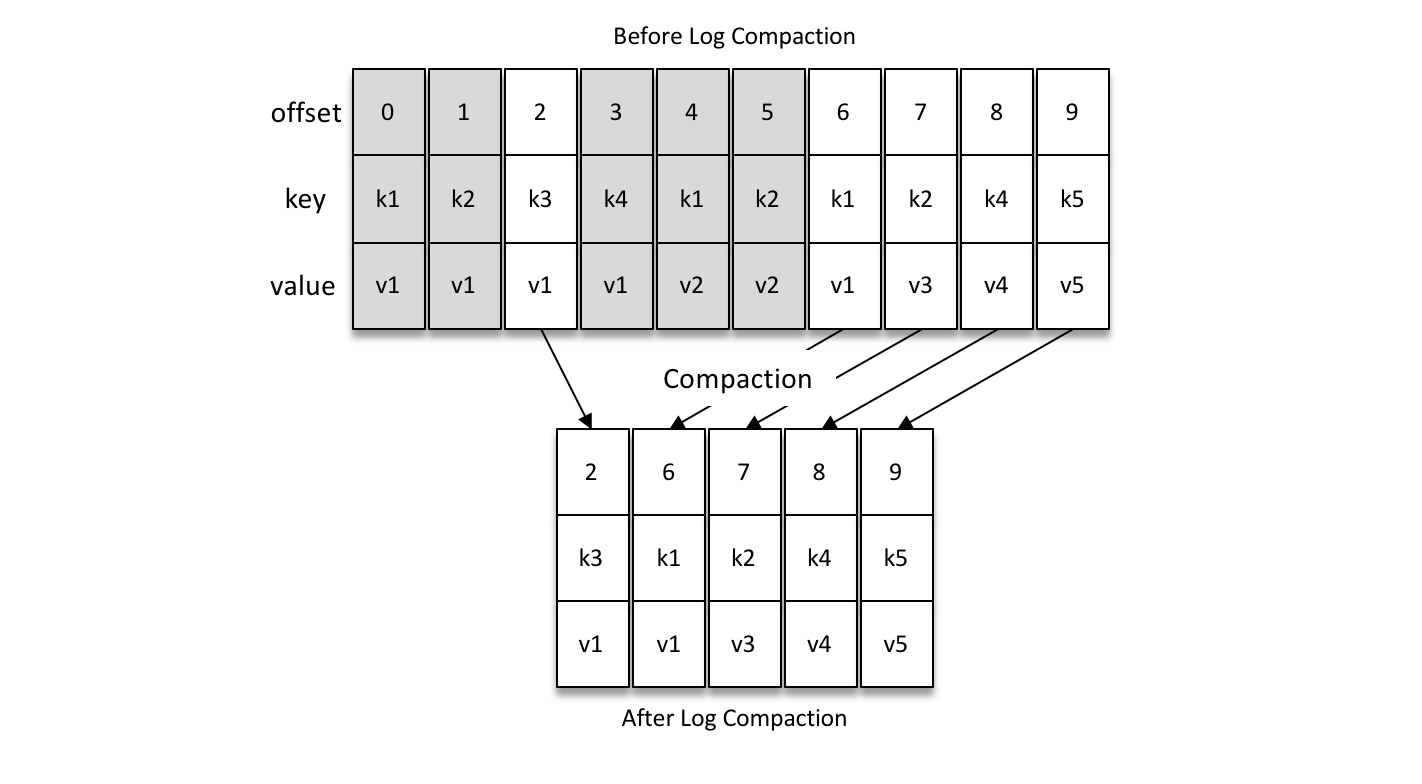
聊一聊你对 Kafka 底层存储的理解(页缓存、内核层、块层、设备层)
页缓存(Page Cache)
为了提升对文件的读写效率,Linux 内核会以页大小(4KB)为单位,将文件划分为多个数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(即页缓存)与文件中的数据块进行绑定。
- 空间维度。
聊一聊 Kafka 的延时操作的原理 ?
聊一聊 Kafka 控制器的作用 ?
消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
Kafka 中的幂等是怎么实现的 ?
Kafka 中的事务是怎么实现的 ?
Kafka 中有那些地方需要选举?这些地方的选举策略又有哪些?
失效副本是指什么?有那些应对措施?
多副本下,各个副本中的 HW 和 LEO 的演变过程 ?
为什么 Kafka 不支持读写分离?
Kafka 在可靠性方面做了哪些改进?(HW, LeaderEpoch)
Kafka 中怎么实现死信队列和重试队列?
Kafka 中的延迟队列怎么实现(这题被问的比事务那题还要多!!!听说你会 Kafka,那你说说延迟队列怎么实现?)
Kafka 中怎么做消息审计?
Kafka 中怎么做消息轨迹?
Kafka 中有那些配置参数比较有意思?聊一聊你的看法
Kafka 中有那些命名比较有意思?聊一聊你的看法
Kafka 有哪些指标需要着重关注?
怎么计算 Lag?(注意 read_uncommitted 和 read_committed 状态下的不同)
Kafka 的那些设计让它有如此高的性能?
- Page Cache
- 顺序写。基于操作系统提供的预读和写技术。磁盘的顺序写在大多数情况下比随机写内存还要快。
- 零拷贝技术。
- 批量处理。合并小的请求,然后以流的方式进行交互。
- Pull 拉模式,使用拉模式进行消息的获取消费。消费速率取决于消费者能力。
Kafka 有什么优缺点?
还用过什么同质类的其它产品,与 Kafka 相比有什么优缺点?
为什么选择 Kafka?
在使用 Kafka 的过程中遇到过什么困难?怎么解决的?
怎么样才能确保 Kafka 极大程度上的可靠性?
聊一聊你对 Kafka 生态的理解
如何优化 Producer 写入速度
- 提供负载均衡能力,实现系统的高伸缩性。不同的分区能够被放置在不同节点的机器上,而数据的读写操作也是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且可以通过添加新的节点机器来增加整体系统的吞吐量。
- 利用分区也可以实现一些业务级别的需求。比如实现业务级别的消息顺序。
存在哪些分区策略? 你可以在生产者端实现 Partition 接口,实现自己的分区策略。默认的分区策略有

若有收获,就点个赞吧
0 人点赞
